













Hinweis der Redaktion: Der folgende Artikel wurde für den DZone 2024 Trend Report verfasst und veröffentlicht,Beobachtbarkeit und Leistung: Der Höhepunkt beim Aufbau hochperformanter Softwaresysteme.
„Qualität ist keine Handlung, sondern eine Gewohnheit“, sagte Aristoteles, ein Grundsatz, der auch in der Softwarewelt wahr ist. Speziell für Entwickler bedeutet dies, dass die Erfüllung der Benutzerzufriedenheit keine einmalige Anstrengung, sondern eine fortlaufende Verpflichtung ist. Um diese Verpflichtung zu erreichen, müssen Engineering-Teams Zuverlässigkeitsziele haben, die die Grundlinienleistung klar definieren, die Benutzer erwarten können. Genau hier kommen Service-Level-Ziele (SLOs) ins Spiel.
SLOs sind Zuverlässigkeitsziele, die Produkte erreichen müssen, um Benutzer zufriedenzustellen. Sie dienen als quantifizierbare Brücke zwischen abstrakten Qualitätszielen und den operativen Entscheidungen, die DevOps-Teams im Alltag treffen müssen. Aufgrund dieser enormen Bedeutung ist es entscheidend, sie effektiv für Ihren Service zu definieren. In diesem Artikel werden wir einen schrittweisen Ansatz zur Definition von SLOs mit einem Beispiel durchgehen, gefolgt von einigen Herausforderungen im Umgang mit SLOs.
Schritte zur Definition von Service-Level-Zielen
Wie bei jedem anderen Prozess kann es anfangs überwältigend erscheinen, SLOs zu definieren, aber indem Sie einige einfache Schritte befolgen, können Sie effektive Ziele erstellen. Es ist wichtig zu bedenken, dass SLOs keine festgelegten und vergessenen Metriken sind. Stattdessen sind sie Teil eines iterativen Prozesses, der sich weiterentwickelt, während Sie mehr Einblick in Ihr System gewinnen. Selbst wenn Ihre anfänglichen SLOs nicht perfekt sind, ist das in Ordnung – sie können und sollten im Laufe der Zeit verfeinert werden.
Abbildung 1. Schritte zur Definition von SLOs
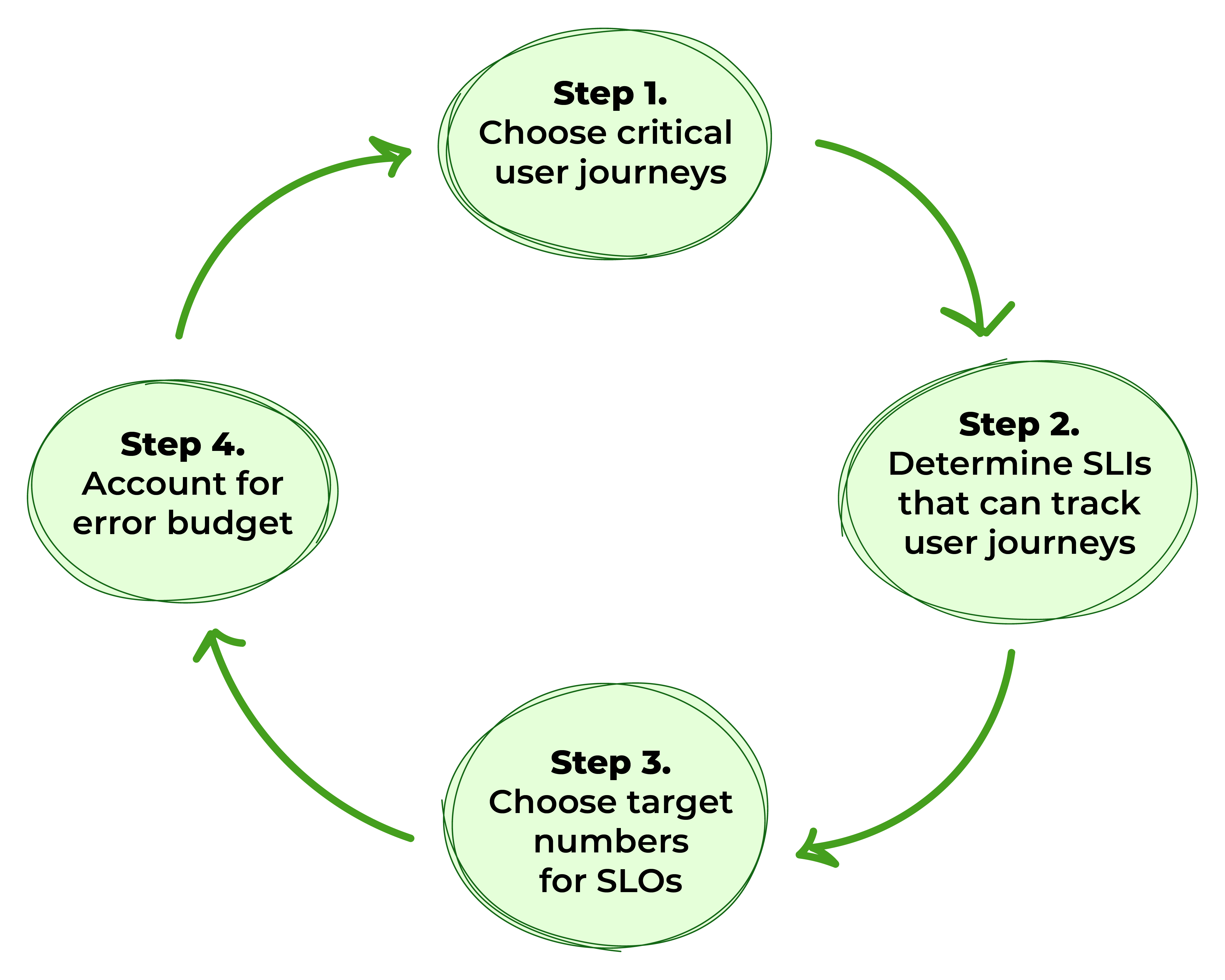
Schritt 1: Kritische Benutzererlebnisse auswählen
Ein kritischer Benutzerweg bezieht sich auf die Abfolge von Interaktionen, die ein Benutzer durchführt, um ein bestimmtes Ziel innerhalb eines Systems oder eines Dienstes zu erreichen. Die Zuverlässigkeit dieser Wege zu gewährleisten ist wichtig, da sie direkt die Kundenerfahrung beeinflusst. Einige Möglichkeiten, kritische Benutzerwege zu identifizieren, können darin bestehen, den Umsatz/Geschäftsauswirkungen zu bewerten, wenn ein bestimmter Arbeitsablauf fehlschlägt, und häufige Abläufe durch Benutzeranalysen zu identifizieren.
Zum Beispiel, nehmen Sie einen Dienst, der virtuelle Maschinen (VMs) erstellt. Einige Aktionen, die Benutzer auf diesem Dienst ausführen können, sind das Durchsuchen der verfügbaren VM-Formen, die Auswahl einer Region, um die VM zu erstellen, und das Starten der VM. Wenn das Entwicklungsteam sie nach Geschäftsauswirkungen ordnen würde, wäre die Rangfolge:
- Starten der VM, weil dies direkte Einnahmeauswirkungen hat. Wenn Benutzer keine VM starten können, ist die Kernfunktionalität des Dienstes fehlgeschlagen, was sich direkt auf die Kundenzufriedenheit und die Einnahmen auswirkt.
- Auswahl einer Region zum Erstellen der VM. Benutzer können zwar immer noch eine VM in einer anderen Region erstellen, dies kann jedoch zu einer beeinträchtigten Erfahrung führen, wenn sie eine regionale Präferenz haben. Diese Wahl kann sich auf Leistung und Compliance auswirken.
- Durchsuchen des VM-Katalogs. Obwohl dies für Entscheidungen wichtig ist, hat es einen geringeren direkten Einfluss auf das Geschäft, da Benutzer die VM-Form später ändern können.
Schritt 2: Bestimmen von Service-Level-Indikatoren, die Benutzerreisen verfolgen können
Jetzt, da die Benutzerreisen definiert sind, ist der nächste Schritt, sie effektiv zu messen. Service-Level-Indikatoren (SLIs) sind die Metriken, die Entwickler verwenden, um die Leistung und Zuverlässigkeit des Systems zu quantifizieren. Für Engineering-Teams erfüllen SLIs einen doppelten Zweck: Sie bieten handlungsorientierte Daten zur Erkennung von Degradierungen, leiten architektonische Entscheidungen und validieren Infrastrukturänderungen. Sie bilden auch die Grundlage für aussagekräftige SLOs, indem sie die quantitativen Messungen bereitstellen, die benötigt werden, um Zuverlässigkeitsziele festzulegen und zu verfolgen.
Beispielsweise können bei der Einführung einer VM einige der SLIs Verfügbarkeit und Latenz sein.
Verfügbarkeit: Von den X Anfragen zum Starten einer VM, wie viele waren erfolgreich? Eine einfache Formel zur Berechnung ist:
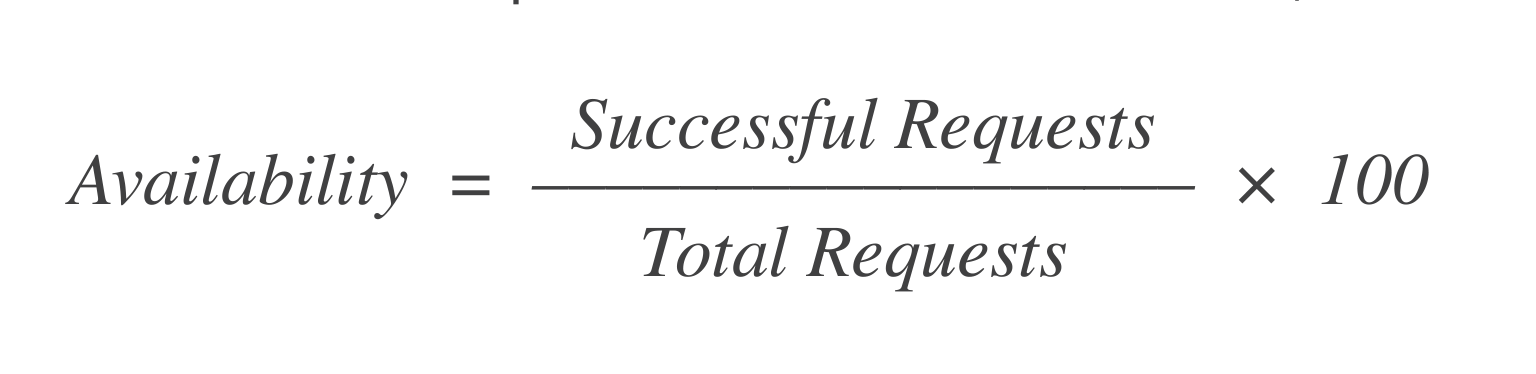
Wenn es 1.000 Anfragen gab und 998 davon erfolgreich waren, dann beträgt die Verfügbarkeit = 99,8%.
Latenz: Von der Gesamtanzahl der Anfragen zum Starten einer VM, wie lange dauerte es, bis die 50., 95. oder 99. Perzentile der Anfragen zum Starten der VM abgeschlossen waren? Die Perzentile sind hier nur Beispiele und können je nach spezifischem Anwendungsfall oder den erwarteten Service-Level-Erwartungen variieren.
- In einem Szenario mit 1.000 Anfragen, bei dem 900 Anfragen in 5 Sekunden abgeschlossen wurden und die verbleibenden 100 Anfragen 10 Sekunden dauerten, würde die Latenz im 95. Perzentil = 10 Sekunden betragen.
- Obwohl auch Durchschnittswerte zur Berechnung von Latenzen verwendet werden können, werden in der Regel Perzentile empfohlen, da sie Schwachstellenlatenzen berücksichtigen und so eine genauere Darstellung der Benutzererfahrung bieten.
Schritt 3: Zielzahlen für SLOs identifizieren
Kurz gesagt sind SLOs die Zielzahlen, die wir möchten, dass unsere SLIs in einem bestimmten Zeitfenster erreichen. Für das VM-Szenario können die SLOs wie folgt lauten:
- Die Verfügbarkeit des Dienstes sollte über einem rollierenden 30-Tage-Fenster größer als 99% sein.
- Die Latenz im 95. Perzentil für das Starten der VMs sollte nicht mehr als acht Sekunden betragen.
Beim Festlegen dieser Ziele sollten einige Dinge beachtet werden:
-
Verwendung historischer Daten. Wenn Sie SLOs basierend auf einem rollierenden 30-Tage-Zeitraum festlegen müssen, sammeln Sie Daten aus mehreren 30-Tage-Fenstern, um die Ziele zu definieren.
- Fehlen Ihnen diese historischen Daten, beginnen Sie mit einem realistischeren Ziel, wie z.B. dem Ziel, täglich eine Verfügbarkeit von 99% anzustreben, und passen Sie es im Laufe der Zeit an, wenn Sie mehr Informationen sammeln.
- Denken Sie daran, dass SLOs nicht in Stein gemeißelt sind; sie sollten sich kontinuierlich weiterentwickeln, um den sich ändernden Anforderungen Ihres Dienstes und Ihrer Kunden gerecht zu werden.
-
Berücksichtigung von Abhängigkeit-SLOs. Dienste sind typischerweise auf andere Dienste und Infrastrukturkomponenten angewiesen, wie z. B. Datenbanken und Lastenausgleicher.
-
Wenn Ihr Dienst beispielsweise von einer SQL-Datenbank mit einem Verfügbarkeits-SLO von 99,9 % abhängt, kann das SLO Ihres Dienstes 99,9 % nicht überschreiten. Dies liegt daran, dass die maximale Verfügbarkeit durch die Leistung der zugrunde liegenden Abhängigkeiten eingeschränkt ist, die keine höhere Zuverlässigkeit garantieren können.
-
Herausforderungen von SLOs
Es könnte interessant sein, das SLO auf 100% festzulegen, aber das ist unmöglich. Eine Verfügbarkeit von 100%, zum Beispiel, bedeutet, dass es keinen Spielraum für wichtige Aktivitäten wie das Versenden von Funktionen, das Patchen oder das Testen gibt, was unrealistisch ist. Die Definition von SLOs erfordert Zusammenarbeit zwischen mehreren Teams, einschließlich Engineering, Produkt, Betrieb, QA und Führung. Sicherzustellen, dass alle Beteiligten auf die Ziele abgestimmt sind und diesen zustimmen, ist entscheidend, damit das SLO erfolgreich und umsetzbar ist.
Schritt 4: Berücksichtigung des Fehlerbudgets
Ein Fehlerbudget ist das Maß für die Ausfallzeit, die ein System sich leisten kann, ohne die Kunden zu verärgern oder vertragliche Verpflichtungen zu verletzen. Unten ist eine Möglichkeit, dies zu betrachten:
- Wenn das Fehlerbudget nahezu erschöpft ist, sollte sich das Engineering-Team darauf konzentrieren, die Zuverlässigkeit zu verbessern und Vorfälle zu reduzieren, anstatt neue Funktionen zu veröffentlichen.
- Wenn noch viel Fehlerbudget übrig ist, kann sich das Engineering-Team leisten, die Priorität auf das Versenden neuer Funktionen zu legen, da das System gut innerhalb seiner Zuverlässigkeitsziele funktioniert.
Es gibt zwei gängige Ansätze zur Messung des Fehlerbudgets: zeitbasiert und ereignisbasiert. Lassen Sie uns erkunden, wie die Aussage „Die Verfügbarkeit des Dienstes sollte über einen Zeitraum von 30 Tagen mehr als 99% betragen“ auf jede dieser Methoden zutrifft.
Zeitbasierte Messung
In einem zeitbasierten Fehlerbudget bedeutet die obige Aussage, dass der Dienst für 43 Minuten und 50 Sekunden in einem Monat oder 7 Stunden und 14 Minuten in einem Jahr ausfallen darf. So berechnet man es:
-
Bestimmen Sie die Anzahl der Datenpunkte. Beginnen Sie damit, die Anzahl der Zeitintervalle (Datenpunkte) im Zeitfenster des SLO zu bestimmen. Wenn z.B. die Grundzeitintervall 1 Minute beträgt und das SLO-Fenster 30 Tage beträgt:
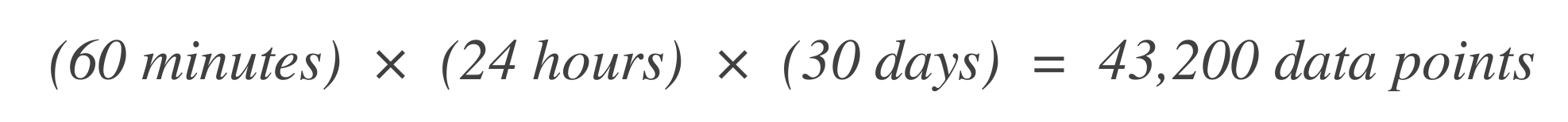
-
Berechnen Sie das Fehlertoleranzbudget. Berechnen Sie als Nächstes, wie viele Datenpunkte „fehlschlagen“ können (d. h. Ausfallzeiten). Das Fehlertoleranzbudget ist der Prozentsatz des zulässigen Ausfalls.
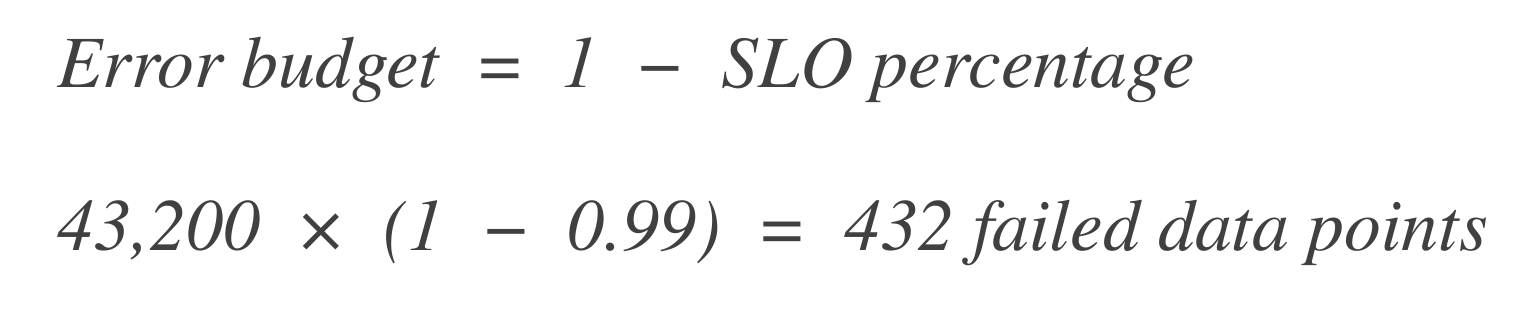
Wandeln Sie dies in Zeit um:
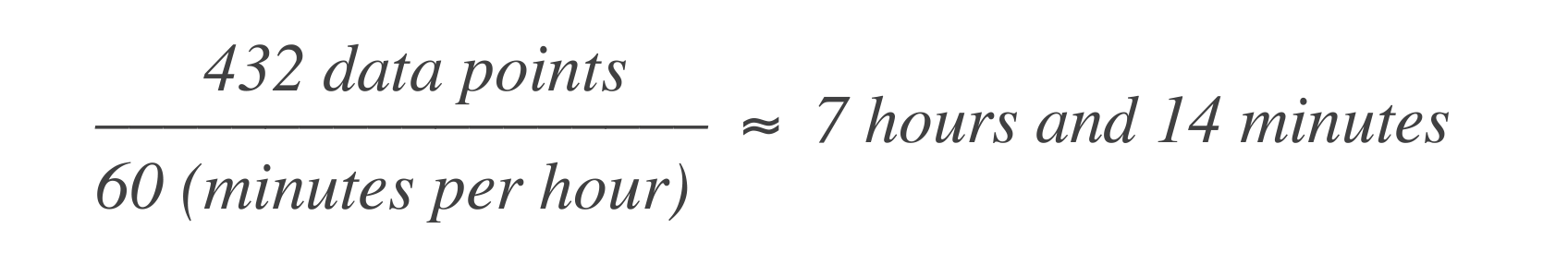
Dies bedeutet, dass das System in einem 30-tägigen Zeitfenster 7 Stunden und 14 Minuten Ausfallzeit haben kann.
Zu guter Letzt ist das verbleibende Fehlertoleranzbudget der Unterschied zwischen der gesamten möglichen Ausfallzeit und der bereits verwendeten Ausfallzeit.
Ereignisbasierte Messung
Bei ereignisbasierter Messung wird das Fehlertoleranzbudget in Prozent gemessen. Die oben genannte Aussage entspricht einem Fehlertoleranzbudget von 1 % in einem rollenden 30-Tage-Zeitfenster.
Angenommen, es gibt 43.200 Datenpunkte in diesem 30-Tage-Zeitfenster, und 100 davon sind schlecht. Sie können berechnen, wie viel vom Fehlertoleranzbudget mit folgender Formel verbraucht wurde:
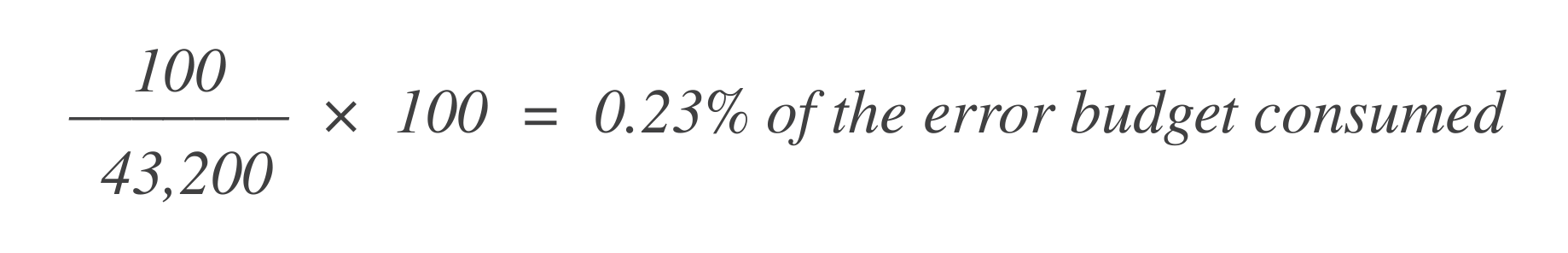
Um nun herauszufinden, wie viel Fehlertoleranzbudget noch übrig ist, subtrahieren Sie dies vom insgesamt erlaubten Fehlertoleranzbudget (1 %):
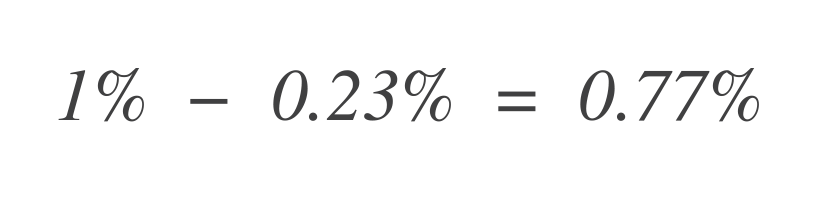
Daher kann der Service weiterhin 0,77% mehr fehlerhafte Datenpunkte tolerieren.
Vorteile des Fehlerbudgets
Fehlerbudgets können genutzt werden, um automatisierte Überwachungen und Benachrichtigungen einzurichten, die die Entwicklungsteams informieren, wenn das Budget gefährdet ist. Diese Benachrichtigungen ermöglichen es ihnen, zu erkennen, wann beim Bereitstellen von Änderungen in der Produktion größere Vorsicht geboten ist. Teams stehen oft vor Unklarheiten, wenn es darum geht, Funktionen gegenüber Operationen zu priorisieren. Das Fehlerbudget kann eine Möglichkeit sein, diese Herausforderung anzugehen. Durch die Bereitstellung klarer, datengestützter Kennzahlen sind die Ingenieurteams in der Lage, Zuverlässigkeitsaufgaben gegenüber neuen Funktionen nach Bedarf zu priorisieren. Das Fehlerbudget gehört zu den etablierten Strategien zur Verbesserung der Verantwortlichkeit und Reife innerhalb der Ingenieurteams.
Vorsichtsmaßnahmen im Umgang mit Fehlerbudgets
Wenn zusätzliches Budget verfügbar ist, sollten Entwickler aktiv in Betracht ziehen, es zu nutzen. Dies ist eine hervorragende Gelegenheit, das Verständnis des Dienstes zu vertiefen, indem Techniken wie Chaos-Engineering ausprobiert werden. Die Ingenieurteams können beobachten, wie der Dienst reagiert, und verborgene Abhängigkeiten aufdecken, die während des normalen Betriebs möglicherweise nicht offensichtlich sind. Nicht zuletzt müssen die Entwickler die Verringerung des Fehlerbudgets genau überwachen, da unerwartete Vorfälle es schnell aufbrauchen können.
Fazit
Service-Level-Objektive stellen eine Reise dar, anstatt ein Ziel in der Zuverlässigkeitstechnik zu sein. Während sie wichtige Metriken zur Messung der Dienstzuverlässigkeit bieten, liegt ihr eigentlicher Wert darin, eine Kultur der Zuverlässigkeit innerhalb von Organisationen zu schaffen. Anstatt nach Perfektion zu streben, sollten Teams SLOs als Werkzeuge betrachten, die sich zusammen mit ihren Diensten weiterentwickeln. Ein Blick in die Zukunft zeigt, dass die Integration von KI und maschinellem Lernen verspricht, SLOs von reaktiven Messungen in prädiktive Instrumente zu verwandeln, wodurch Organisationen in der Lage sind, Ausfälle vorherzusehen und zu verhindern, bevor sie sich auf Benutzer auswirken.
Zusätzliche Ressourcen:
-
Implementierung von Service-Level-Objektiven, Alex Hidalgo, 2020
-
„Service-Level-Objekte,“ Chris Jones et al., 2017
-
„Implementierung von SLOs,“ Steven Thurgood et al., 2018
Dies ist ein Auszug aus dem Trendbericht von DZone 2024, Beobachtbarkeit und Leistung: Der Abgrund des Aufbaus von hochperformanten Softwaresystemen.
Source:
https://dzone.com/articles/framework-for-service-level-objectives