













編者按:以下文章為DZone 2024趨勢報告而撰寫並發表,可觀察性與性能:構建高性能軟件系統的懸崖。
「質量不是一個行為,而是一種習慣,」亞里士多德說,這一原則在軟件世界同樣適用。對開發者來說,這意味著滿足用戶需求不是一次性的努力,而是一個持續的承諾。為了實現這一承諾,工程團隊需要設定明確的可靠性目標,這些目標定義了用戶可以期望的基本性能水平。這正是服務水平目標(SLO)的用武之地。
簡單來說,SLO是用於確保產品能夠滿足用戶期望的可靠性目標。它們作為抽象質量目標與日常運營決策之間的量化橋樑。正因為這一重要性,為您的服務有效定義SLO至關重要。在本文中,我們將通過一個示例逐步介紹如何定義SLO,並探討SLO的一些挑戰。
定義服務水平目標的步驟
如同任何其他流程,定義服務水平目標(SLOs)最初可能會讓人感到不知所措,但通過遵循一些簡單的步驟,您可以創建有效的目標。重要的是要記住,SLOs並非設置後就置之不理的指標。相反,它們是一個迭代流程的一部分,會隨著您對系統洞察力的增強而演變。因此,即使您最初的SLOs並不完美,也沒關係——它們可以並且應該隨時間進行優化。
圖1。 定義SLOs的步驟
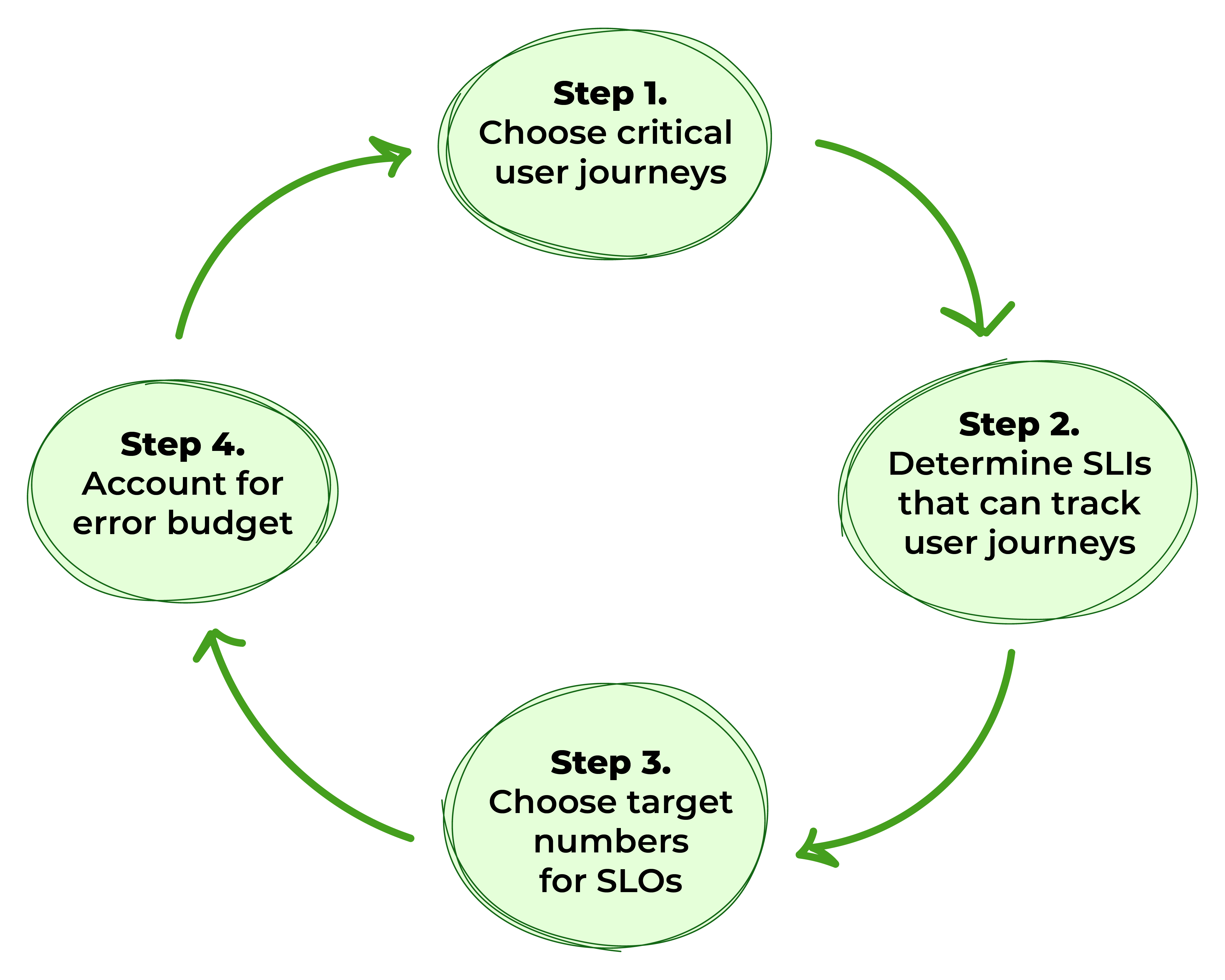
步驟1:選擇關鍵用戶旅程
關鍵用戶旅程指的是用戶在系統或服務中為實現特定目標而進行的一系列互動。確保這些旅程的可靠性很重要,因為它直接影響客戶體驗。識別關鍵用戶旅程的一些方法可以通過評估當某個工作流程失敗時對收入/業務的影響,以及通過用戶分析識別頻繁的流程。
例如,考慮一個創建虛擬機器(VMs)的服務。用戶可以在此服務上執行的一些操作包括瀏覽可用的VM形狀、選擇創建VM的地區以及啟動VM。如果開發團隊按業務影響對其進行排序,排名將是:
- 啟動VM因為這對收入有直接的影響。如果用戶無法啟動VM,那麼服務的核心功能就失敗了,直接影響客戶滿意度和收入。
- 選擇區域來創建虛擬機。雖然用戶仍然可以在不同區域創建虛擬機,但如果他們有區域偏好,這可能會導致體驗下降。這個選擇可能影響性能和合規性。
- 瀏覽虛擬機目錄。雖然這對決策很重要,但其對業務的直接影響較低,因為用戶可以後續更改虛擬機形狀。
步驟2:確定可以追踪用戶旅程的服務級指標
現在用戶旅程已經定義,下一步是有效地衡量它們。服務級指標(SLIs)是開發人員用來量化系統性能和可靠性的指標。對於工程團隊來說,SLIs有雙重目的:它們提供可操作的數據來檢測退化,指導架構決策,並驗證基礎設施變更。它們還通過提供設定和追踪可靠性目標所需的定量測量,為有意義的SLOs奠定基礎。
例如,在啟動虛擬機時,一些SLIs可以是可用性和延遲。
可用性:在X個啟動虛擬機的請求中,有多少成功?計算這個的簡單公式是:
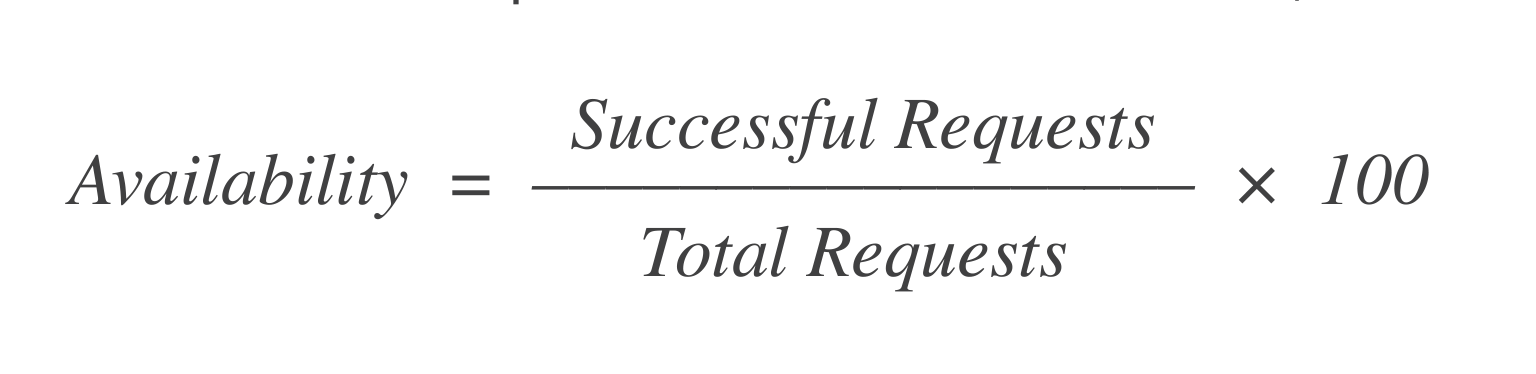
如果總共有1,000個請求,其中998個請求成功,那麼可用性等於99.8%。
延遲:在啟動虛擬機的總請求數中,第50個、95個或99個百分位的請求啟動虛擬機所需的時間是多少?這裡的百分位只是示例,可能會根據具體用例或服務級期望而變化。
- 在一個有1,000個請求的情況下,其中900個請求在5秒內完成,剩下的100個請求花了10秒,那麼95百分位延遲將會是=10秒。
- 雖然平均值也可以用來計算延遲,但通常建議使用百分位數,因為它們考慮了尾部延遲,能更準確地反映用戶體驗。
步驟3:確定SLOs的目標數字
簡單來說,SLOs就是我們希望SLIs在特定時間窗口內達到的目標數字。對於VM場景,SLOs可以是:
- 服務的可用性在30天的滾動窗口內應大於99%。
- VM啟動的95百分位延遲不應超過8秒。
在設定這些目標時,需要考慮的一些事情包括:
-
使用歷史數據。如果你需要基於30天滾動周期來設定SLOs,請收集多個30天窗口的數據來定義目標。
- 如果你缺乏這些歷史數據,可以先從一個更易管理的目標開始,例如每天目標99%的可用性,並隨著時間的推移和數據的積累進行調整。
- 請記住,SLOs不是一成不變的;它們應該持續演變,以反映服務和客戶變化的需求。
-
考慮依賴性SLO。服務通常依賴於其他服務和基礎設施組件,例如數據庫和負載均衡器。
-
例如,如果您的服務依賴於一個可用性SLO為99.9%的SQL數據庫,那麼您的服務的SLO也不能超過99.9%。這是因為最大可用性受其基礎依賴性能的限制,這些依賴無法保證更高的可靠性。
-
SLO的挑戰
將SLO設置為100%可能很有趣,但這是不可能的。例如,100%的可用性意味著沒有時間進行發布功能、打補丁或測試等重要活動,這是不現實的。定義SLO需要跨多個團隊的合作,包括工程、產品、運營、質量保證和領導層。確保所有利益相關者達成一致並同意目標對SLO的成功和可執行性至關重要。
步驟4:考慮錯誤預算
錯誤預算是指系統可以承受的停機時間,而不會讓客戶不滿或違反合同義務。以下是一種看待它的方式:
- 如果錯誤預算即將耗盡,工程團隊應該專注於提高可靠性和減少事件,而不是發布新功能。
- 如果還有大量的錯誤預算,工程團隊可以優先考慮發布新功能,因為系統在可靠性目標內表現良好。
衡量錯誤預算有兩種常見方法:基於時間和基於事件。讓我們探討一下這句話“服務的可用性應該在30天的滾動窗口內大於99%”如何應用於每種方法。
基於時間的衡量
在基於時間的錯誤預算中,上述說法轉換為服務在一個月內允許停機43分50秒,或一年內7小時14分。以下是計算方法:
-
確定數據點的數量。 首先確定在 SLO 時間窗口內的時間單位(數據點)數量。例如,如果 基本時間單位是 1 分鐘,而 SLO 窗口是 30 天:
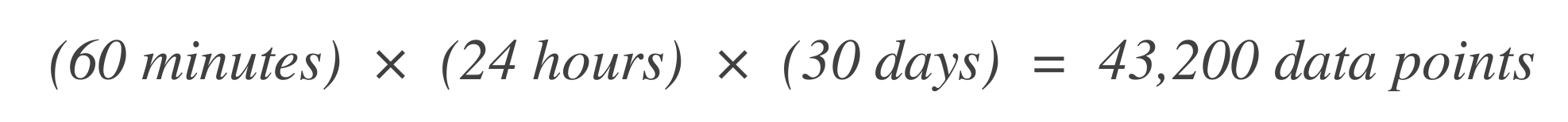
-
計算錯誤預算。接下來,計算有多少數據點可以“失敗”(即,停機時間)。錯誤預算是允許失敗的百分比。
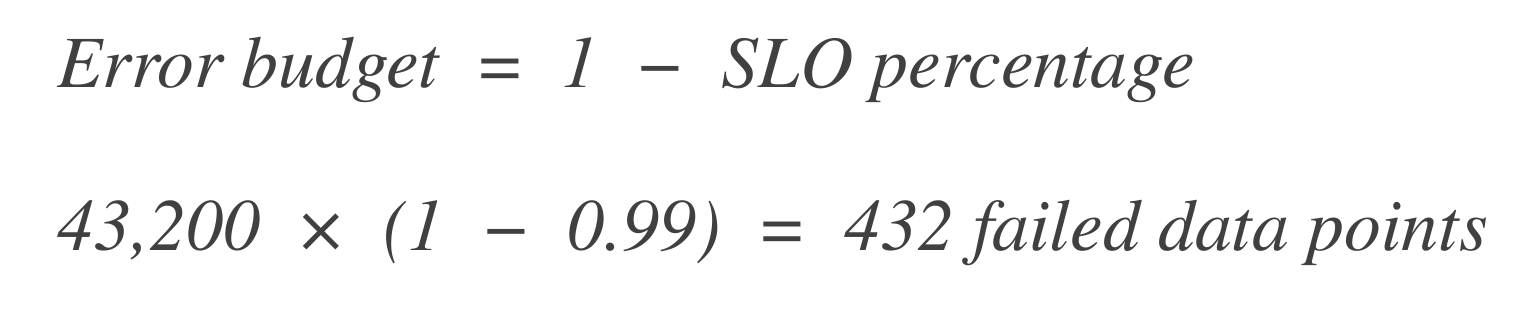
將其轉換為時間:
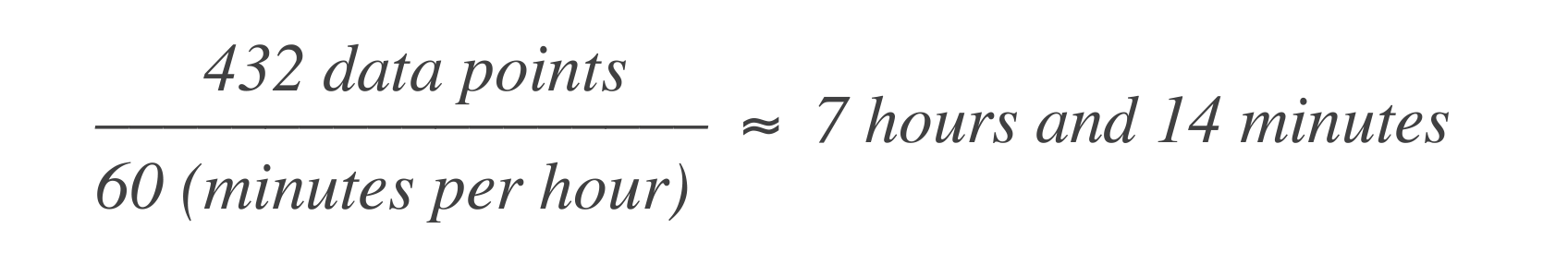
這意味著系統在 30 天窗口內可以經歷 7 小時 14 分鐘 的停機時間。
最後但同樣重要的是,剩餘的錯誤預算是總可能停機時間與已使用停機時間之差。
事件基礎測量
對於事件基礎測量,錯誤預算是按百分比來衡量的。上述聲明在 30 天滾動窗口中轉換為 1% 的錯誤預算。
假設在那 30 天窗口中有 43,200 個數據點,而 其中有 100 個是壞的。你可以使用這個公式計算已消耗的錯誤預算:
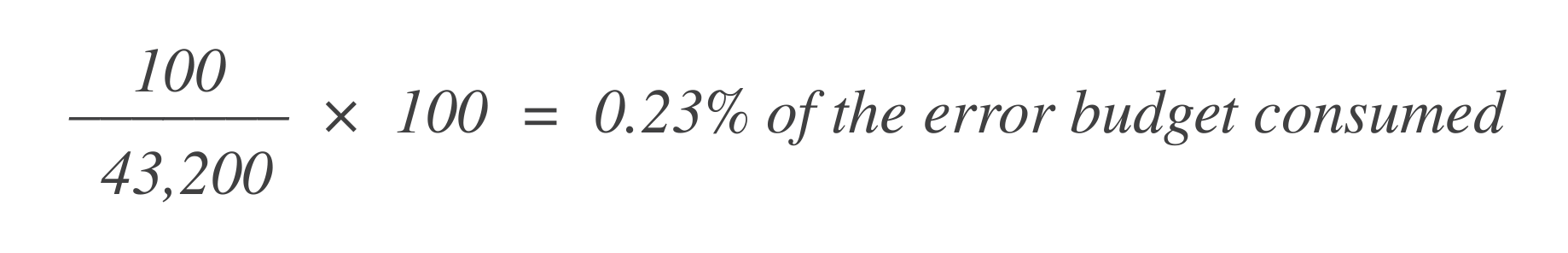
現在,要找出剩餘的錯誤預算,從總允許錯誤預算(1%)中減去這個數字:
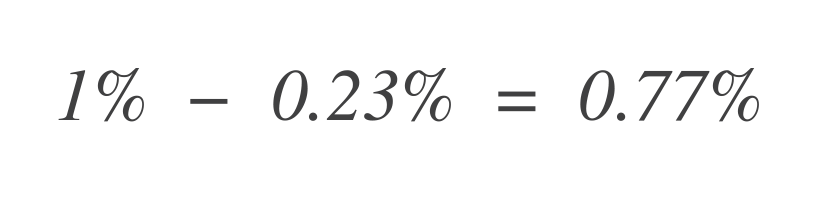
因此,該服務仍能容忍0.77%更多的錯誤數據點。
錯誤預算的優勢
錯誤預算可以用於設置自動監控和警報,當預算有耗盡風險時通知開發團隊。這些警報使他們能夠識別在部署到生產環境時需要更加謹慎的情況。團隊在優先考慮功能與運營之間往往面臨模糊不清的狀況。錯誤預算可以是一種解決這一挑戰的方法。通過提供清晰、數據驅動的指標,工程團隊能夠在必要的時候優先考慮可靠性任務而非新功能。錯誤預算屬於提升工程團隊責任感和成熟度的成熟策略之一。
使用錯誤預算時需注意的事項
當有額外預算時,開發人員應積極探索使用它。這是通過混亂工程等技術深入理解服務的絕佳機會。工程團隊可以觀察服務的響應情況,並發現正常運營中可能不明显的隱藏依賴關係。最後但同樣重要的是,開發人員必須密切監控錯誤預算的耗盡情況,因為意外事件可能迅速耗盡它。
結論
服務等級目標在可靠性工程中代表的是一個旅程而非終點。雖然它們提供了衡量服務可靠性的重要指標,但其真正價值在於在組織內創造一種可靠性文化。團隊應該將SLO視為與其服務共同演進的工具,而不是追求完美。展望未來,人工智能和機器學習的整合有望將SLO從被動的衡量轉變為預測性工具,使組織能夠預見並防止故障在影響用戶之前發生。
額外資源:
這是來自 DZone 2024 趨勢報告的摘錄,可觀察性和性能:構建高性能軟件系統的峭壁。
Source:
https://dzone.com/articles/framework-for-service-level-objectives