













Redactionele opmerking: Het volgende is een artikel geschreven voor en gepubliceerd in de Trendrapport 2024 van DZone, Observability and Performance: Het Precipice van het Bouwen van Zeer Performante Software Systemen.
“Kwaliteit is geen daad, het is een gewoonte,” zei Aristoteles, een principe dat ook geldt in de softwarewereld. Specifiek voor ontwikkelaars betekent dit dat het leveren van gebruikerstevredenheid geen eenmalige inspanning is, maar een voortdurende toewijding. Om deze toewijding te bereiken, moeten engineeringteams betrouwbaarheidsdoelen hebben die duidelijk het basisprestatieniveau definiëren dat gebruikers kunnen verwachten. Hier komt precies het belang van service-level objectives (SLO’s) naar voren.
In eenvoudige bewoordingen zijn SLO’s betrouwbaarheidsdoelen die producten moeten behalen om gebruikers tevreden te houden. Ze dienen als de kwantificeerbare brug tussen abstracte kwaliteitsdoelen en de dagelijkse operationele beslissingen die DevOps-teams moeten nemen. Vanwege dit grote belang is het cruciaal om ze effectief te definiëren voor uw service. In dit artikel zullen we een stapsgewijze aanpak doorlopen om SLO’s te definiëren met een voorbeeld, gevolgd door enkele uitdagingen met SLO’s.
Stappen om Service-Level Objectives te Definiëren
Zoals bij elk ander proces kan het definiëren van SLO’s in het begin overweldigend lijken, maar door enkele eenvoudige stappen te volgen, kunt u effectieve doelstellingen creëren. Het is belangrijk om te onthouden dat SLO’s geen “instellen en vergeten” -metingen zijn. In plaats daarvan maken ze deel uit van een iteratief proces dat evolueert naarmate u meer inzicht krijgt in uw systeem. Dus zelfs als uw oorspronkelijke SLO’s niet perfect zijn, is dat prima – ze kunnen en moeten in de loop van de tijd worden verfijnd.
Afbeelding 1. Stappen om SLO’s te definiëren
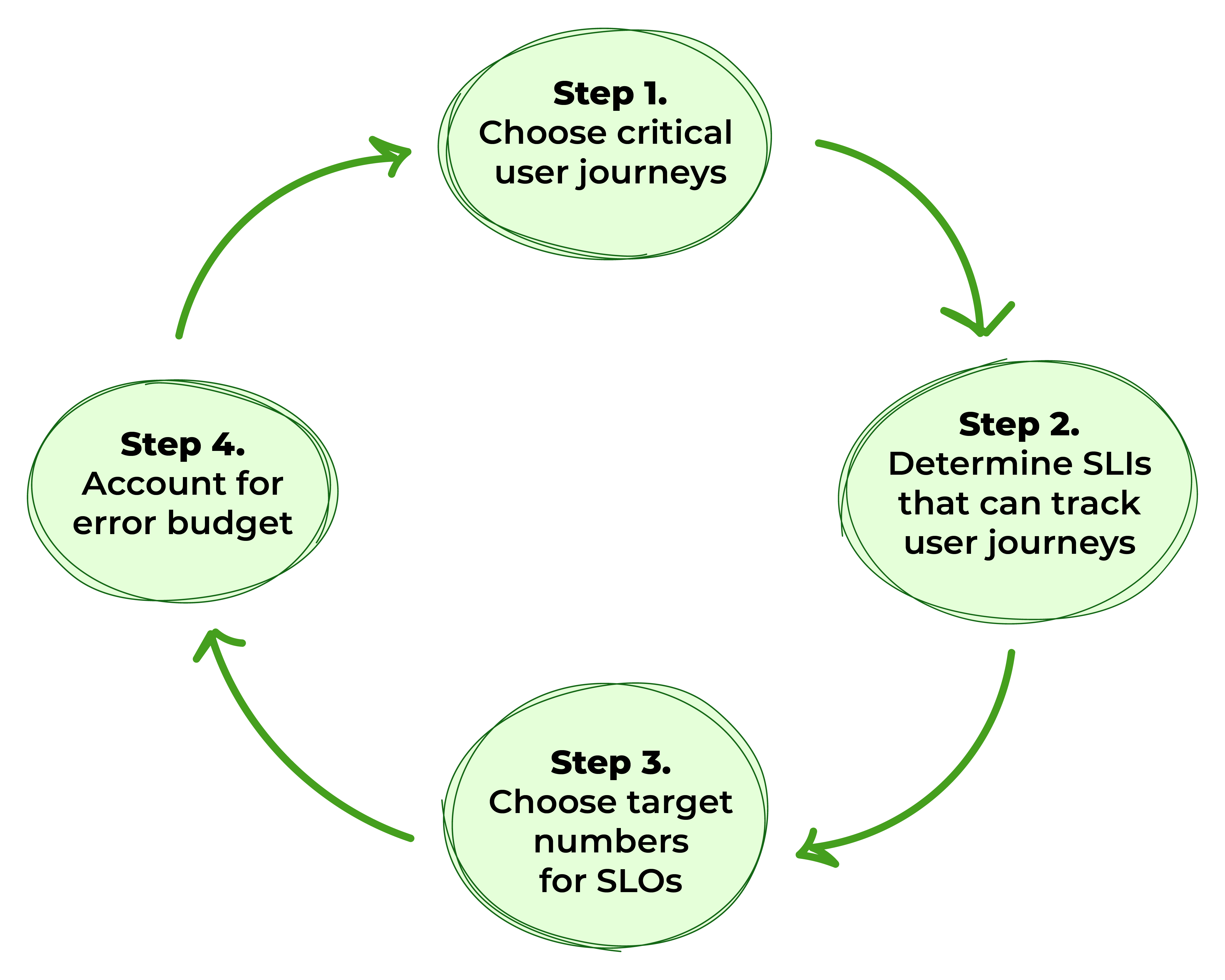
Stap 1: Kies Kritieke Gebruikerspaden
Een kritieke gebruikersreis verwijst naar de reeks interacties die een gebruiker onderneemt om een specifiek doel binnen een systeem of een service te bereiken. Het waarborgen van de betrouwbaarheid van deze reizen is belangrijk omdat dit rechtstreeks van invloed is op de klantervaring. Enkele manieren om kritieke gebruikersreizen te identificeren, zijn door de omzet/bedrijfseffect te evalueren wanneer een bepaalde workflow mislukt en door frequente stromen te identificeren via gebruikersanalyse.
Bijvoorbeeld, overweeg een service die virtuele machines (VM’s) maakt. Enkele van de acties die gebruikers op deze service kunnen uitvoeren, zijn bladeren door de beschikbare VM-vormen, een regio kiezen om de VM in te maken en de VM starten. Als het ontwikkelingsteam ze zou ordenen op bedrijfseffect, zou de rangorde zijn:
- De VM starten omdat dit een directe omzimpact heeft. Als gebruikers een VM niet kunnen starten, is de kernfunctionaliteit van de service mislukt, wat de klanttevredenheid en omzet direct beïnvloedt.
- Het kiezen van een regio om de VM te maken. Hoewel gebruikers nog steeds een VM in een andere regio kunnen maken, kan dit leiden tot een verminderde ervaring als ze een regionale voorkeur hebben. Deze keuze kan van invloed zijn op de prestaties en naleving.
- Bladeren door de VM-catalogus. Hoewel dit belangrijk is voor het nemen van beslissingen, heeft het een minder directe invloed op het bedrijf omdat gebruikers later de VM-vorm kunnen wijzigen.
Stap 2: Bepaal Service-Level Indicatoren Die Gebruikersreizen Kunnen Volgen
Nu de gebruikersreizen zijn gedefinieerd, is de volgende stap om ze effectief te meten. Service-level indicatoren (SLI’s) zijn de metingen die ontwikkelaars gebruiken om systeemprestaties en betrouwbaarheid te kwantificeren. Voor engineeringteams dienen SLI’s een tweeledig doel: ze leveren bruikbare gegevens om degradatie te detecteren, architectonische beslissingen te sturen en infrastructuurwijzigingen te valideren. Ze vormen ook de basis voor zinvolle SLO’s door de kwantitatieve metingen te leveren die nodig zijn om betrouwbaarheidsdoelen vast te stellen en bij te houden.
Bijvoorbeeld, bij het lanceren van een VM kunnen enkele van de SLI’s beschikbaarheid en latentie zijn.
Beschikbaarheid: Van de X verzoeken om een VM te starten, hoeveel zijn er gelukt? Een eenvoudige formule om dit te berekenen is:
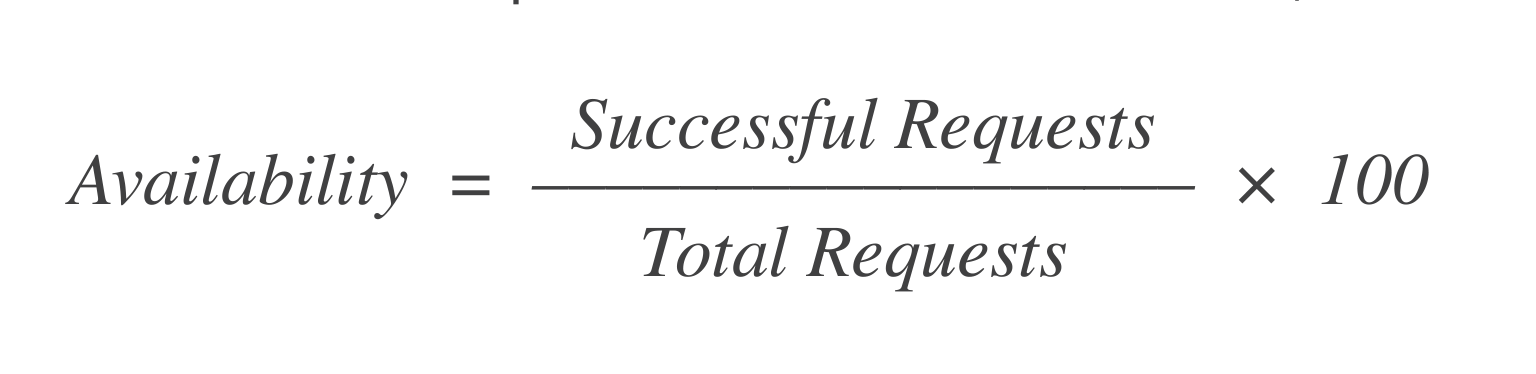
Als er bijvoorbeeld 1.000 verzoeken waren en 998 ervan slaagden, dan is de beschikbaarheid = 99,8%.
Latentie: Van het totale aantal verzoeken om een VM te starten, hoe lang duurde het voordat het 50ste, 95ste of 99ste percentiel van verzoeken nodig had om de VM te starten? De percentielen hier zijn slechts voorbeelden en kunnen variëren afhankelijk van het specifieke gebruiksscenario of de verwachtingen op het niveau van de dienstverlening.
- In een scenario met 1.000 verzoeken waarbij 900 verzoeken in 5 seconden werden voltooid en de overige 100 10 seconden in beslag namen, zou de latentie van het 95e percentiel = 10 seconden zijn.
- Gemiddelden kunnen ook worden gebruikt om latenties te berekenen, maar percentielen worden meestal aanbevolen omdat ze rekening houden met staartlatenties en daardoor een nauwkeuriger beeld van de gebruikerservaring bieden.
Stap 3: Identificeer Doelgetallen voor SLO’s
Kort gezegd zijn SLO’s de doelgetallen die we willen behalen met onze SLI’s binnen een specifiek tijdsbestek. Voor het VM-scenario kunnen de SLO’s zijn:
- De beschikbaarheid van de service moet groter zijn dan 99% over een 30-daags voortschrijdend venster.
- De latentie van het 95e percentiel voor het starten van de VM’s mag niet meer bedragen dan acht seconden.
Bij het instellen van deze doelen is het belangrijk om rekening te houden met enkele zaken:
-
Gebruik van historische gegevens. Als je SLO’s moet instellen op basis van een 30-daagse voortschrijdende periode, verzamel dan gegevens uit meerdere periodes van 30 dagen om de doelen te definiëren.
- Als je niet over deze historische gegevens beschikt, begin dan met een meer haalbaar doel, zoals streven naar 99% beschikbaarheid elke dag, en pas dit in de loop van de tijd aan naarmate je meer informatie verzamelt.
- Onthoud, SLO’s zijn niet in beton gegoten; ze zouden voortdurend moeten evolueren om de veranderende behoeften van je service en klanten te weerspiegelen.
-
Rekening houdend met afhankelijkheid SLO’s. Diensten steunen doorgaans op andere diensten en infrastructuurcomponenten, zoals databases en load balancers.
-
Als uw dienst bijvoorbeeld afhankelijk is van een SQL-database met een beschikbaarheid SLO van 99,9%, dan kan het SLO van uw dienst niet hoger zijn dan 99,9%. Dit komt doordat de maximale beschikbaarheid beperkt is door de prestaties van de onderliggende afhankelijkheden, die geen hogere betrouwbaarheid kunnen garanderen.
-
Uitdagingen van SLO’s
Het kan intrigerend zijn om de SLO op 100% te stellen, maar dit is onmogelijk. Een beschikbaarheid van 100%, bijvoorbeeld, betekent dat er geen ruimte is voor belangrijke activiteiten zoals het verzenden van functies, patchen of testen, wat niet realistisch is. Het definiëren van SLO’s vereist samenwerking tussen meerdere teams, waaronder engineering, product, operaties, QA en leiderschap. Zorgen dat alle belanghebbenden op één lijn zitten en het eens zijn over de doelstellingen is essentieel voor het succes en de haalbaarheid van de SLO.
Stap 4: Rekening houden met het Foutenbudget
Een foutenbudget is de maat voor de downtime die een systeem zich kan veroorloven zonder klanten te verstoren of contractuele verplichtingen te schenden. Hieronder is een manier om ernaar te kijken:
- Als het foutenbudget bijna op is, moet het engineeringteam zich richten op het verbeteren van de betrouwbaarheid en het verminderen van incidenten in plaats van nieuwe functies uit te brengen.
- Als er voldoende foutenbudget over is, kan het engineeringteam zich veroorloven om prioriteit te geven aan het verzenden van nieuwe functies, aangezien het systeem goed presteert binnen de betrouwbaarheiddoelstellingen.
Er zijn twee gangbare benaderingen voor het meten van het foutenbudget: tijdgebaseerd en gebeurtenisgebaseerd. Laten we onderzoeken hoe de uitspraak, “De beschikbaarheid van de dienst moet hoger zijn dan 99% over een periode van 30 dagen”, van toepassing is op elk van beide.
Tijdgebaseerde Meting
In een tijdgebaseerd foutenbudget vertaalt de bovenstaande uitspraak zich naar de dienst die maximaal 43 minuten en 50 seconden in een maand, of 7 uur en 14 minuten in een jaar uitgeschakeld mag zijn. Hier is hoe je dit berekent:
-
Bepaal het aantal datapunten. Begin met het bepalen van het aantal tijdseenheden (datapunten) binnen het SLO-tijdvenster. Bijvoorbeeld, als de basis tijdseenheid 1 minuut is en het SLO-venster 30 dagen:
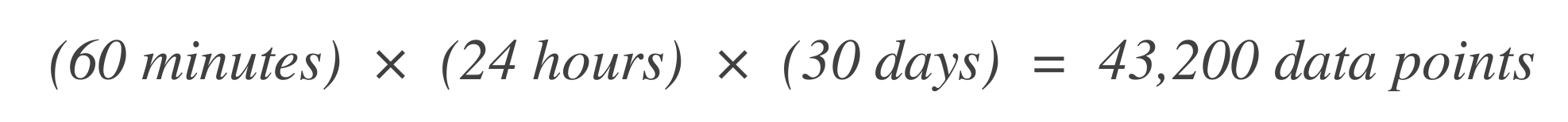
-
Bereken het foutbudget. Vervolgens, bereken hoeveel datapunten “kunnen falen” (d.w.z. downtime). Het foutbudget is het percentage van toegestane fouten.
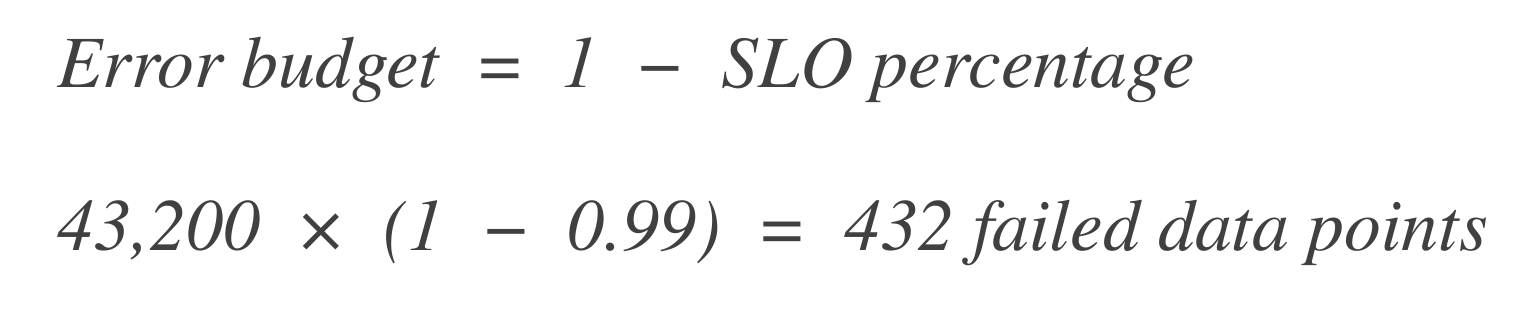
Converteer dit naar tijd:
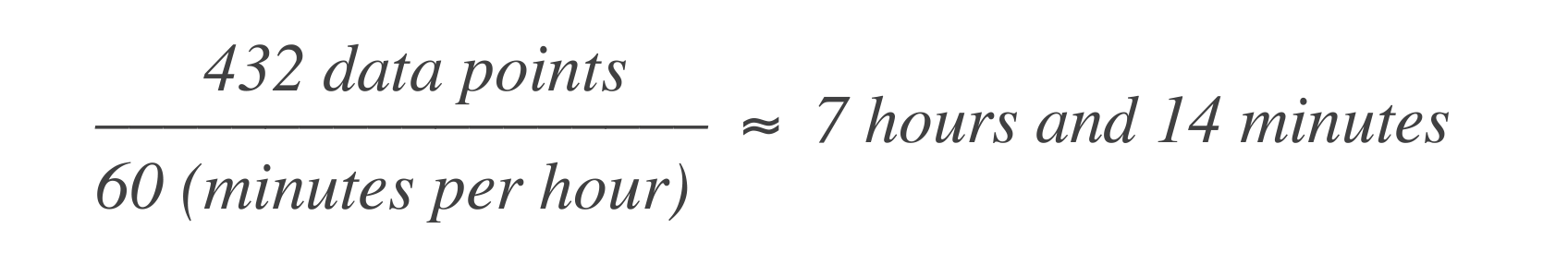
Dit betekent dat het systeem 7 uren en 14 minuten downtime kan ervaren in een periode van 30 dagen.
Last but not least, het resterende foutbudget is het verschil tussen de totale mogelijke downtime en de al gebruikte downtime.
Evenementgebaseerde meting
Voor evenementgebaseerde meting wordt het foutbudget gemeten in termen van percentages. De bovenstaande verklaring vertaalt zich naar een foutbudget van 1% in een rollend tijdvenster van 30 dagen.
Laten we zeggen dat er 43.200 datapunten in dat 30-dagen venster zijn, en 100 daarvan zijn slecht. Je kunt berekenen hoeveel van het foutbudget is verbruikt met behulp van deze formule:
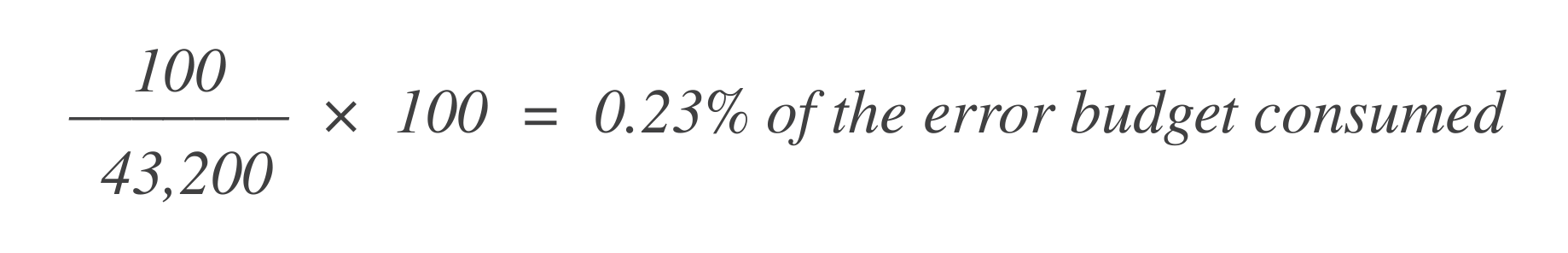
Nu, om te ontdekken hoeveel foutbudget er nog over is, trek dit af van het totale toegestane foutbudget (1%):
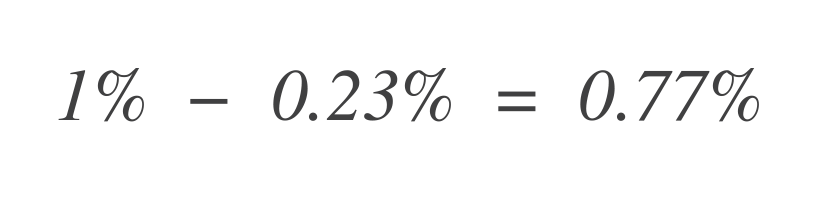
Zo kan de service nog 0,77% meer slechte gegevenspunten tolereren.
Voordelen van Foutenbudget
Foutenbudgetten kunnen worden gebruikt om geautomatiseerde monitors en waarschuwingen op te zetten die ontwikkelingsteams op de hoogte stellen wanneer het budget dreigt op te raken. Deze waarschuwingen stellen hen in staat te herkennen wanneer er meer voorzichtigheid nodig is bij het implementeren van wijzigingen in de productieomgeving. Teams worden vaak geconfronteerd met ambiguïteit als het gaat om het prioriteren van functies ten opzichte van operaties. Het foutenbudget kan een manier zijn om deze uitdaging aan te gaan. Door duidelijke, op gegevens gebaseerde metrics te verstrekken, kunnen engineeringteams betrouwbaarheidstaken boven nieuwe functies prioriteren wanneer dat nodig is. Het foutenbudget behoort tot de gevestigde strategieën om verantwoordelijkheid en volwassenheid binnen de engineeringteams te verbeteren.
Waarschuwingen bij het Gebruik van Foutenbudgetten
Wanneer er extra budget beschikbaar is, moeten ontwikkelaars actief overwegen om het te gebruiken. Dit is een uitgelezen kans om het begrip van de service te verdiepen door te experimenteren met technieken zoals chaos engineering. Engineeringteams kunnen observeren hoe de service reageert en verborgen afhankelijkheden blootleggen die tijdens normale operaties mogelijk niet duidelijk zijn. Last but not least moeten ontwikkelaars de depletie van het foutenbudget nauwlettend in de gaten houden, omdat onverwachte incidenten het snel kunnen uitputten.
Conclusie
Service-leveldoelen vertegenwoordigen een reis in plaats van een bestemming in betrouwbaarheidstechniek. Hoewel ze belangrijke metrics bieden voor het meten van servicebetrouwbaarheid, ligt hun ware waarde in het creëren van een cultuur van betrouwbaarheid binnen organisaties. In plaats van perfectie na te streven, zouden teams SLO’s moeten omarmen als hulpmiddelen die zich ontwikkelen samen met hun diensten. Vooruitkijkend belooft de integratie van AI en machine learning SLO’s te transformeren van reactieve metingen naar voorspellende instrumenten, waardoor organisaties in staat worden gesteld om storingen te anticiperen en te voorkomen voordat ze invloed hebben op gebruikers.
Aanvullende bronnen:
-
Implementing Service Level Objectives, Alex Hidalgo, 2020
-
“Service Level Objects,” Chris Jones et al., 2017
-
“Implementing SLOs,” Steven Thurgood et al., 2018
Dit is een uittreksel uit het Trendrapport 2024 van DZone, Observability en Performance: De Afgrond van het Bouwen van Zeer Prestatieve Software Systemen.
Source:
https://dzone.com/articles/framework-for-service-level-objectives