













編集部注:以下は、DZoneの2024年トレンドレポートのために書かれ、掲載された記事です。可観測性とパフォーマンス:高性能ソフトウェアシステムの構築の崖っぷち。
「品質は行為ではなく、習慣である」とアリストテレスは言いました。この原則はソフトウェアの世界でも同様に当てはまります。特に開発者にとって、ユーザー満足度を提供することは一度きりの努力ではなく、継続的なコミットメントです。このコミットメントを達成するためには、エンジニアリングチームがユーザーが期待できる基準となるパフォーマンスを明確に定義する信頼性の目標を持つ必要があります。これがまさにサービスレベル目標(SLO)が登場する場面です。
要するに、SLOはユーザーを満足させるために製品が達成すべき信頼性の目標です。これらは、抽象的な品質目標とDevOpsチームが日常的に行う運用決定との間の定量的な橋渡しをします。この重要性ゆえに、サービスに対して効果的に定義することが非常に重要です。この記事では、SLOを定義するためのステップバイステップのアプローチを例とともに紹介し、SLOに関連するいくつかの課題についても触れます。
サービスレベル目標を定義するステップ
他のプロセスと同様に、SLOを定義することは最初は圧倒的に思えるかもしれませんが、いくつかの簡単なステップに従うことで、効果的な目標を作成することができます。SLOは設定して忘れるメトリクスではないことを覚えておくことが重要です。代わりに、システムに対する洞察を深めるにつれて進化する反復プロセスの一部です。したがって、最初のSLOが完璧でなくても大丈夫です — 時間とともに改善されるべきです。
図1. SLOを定義するためのステップ
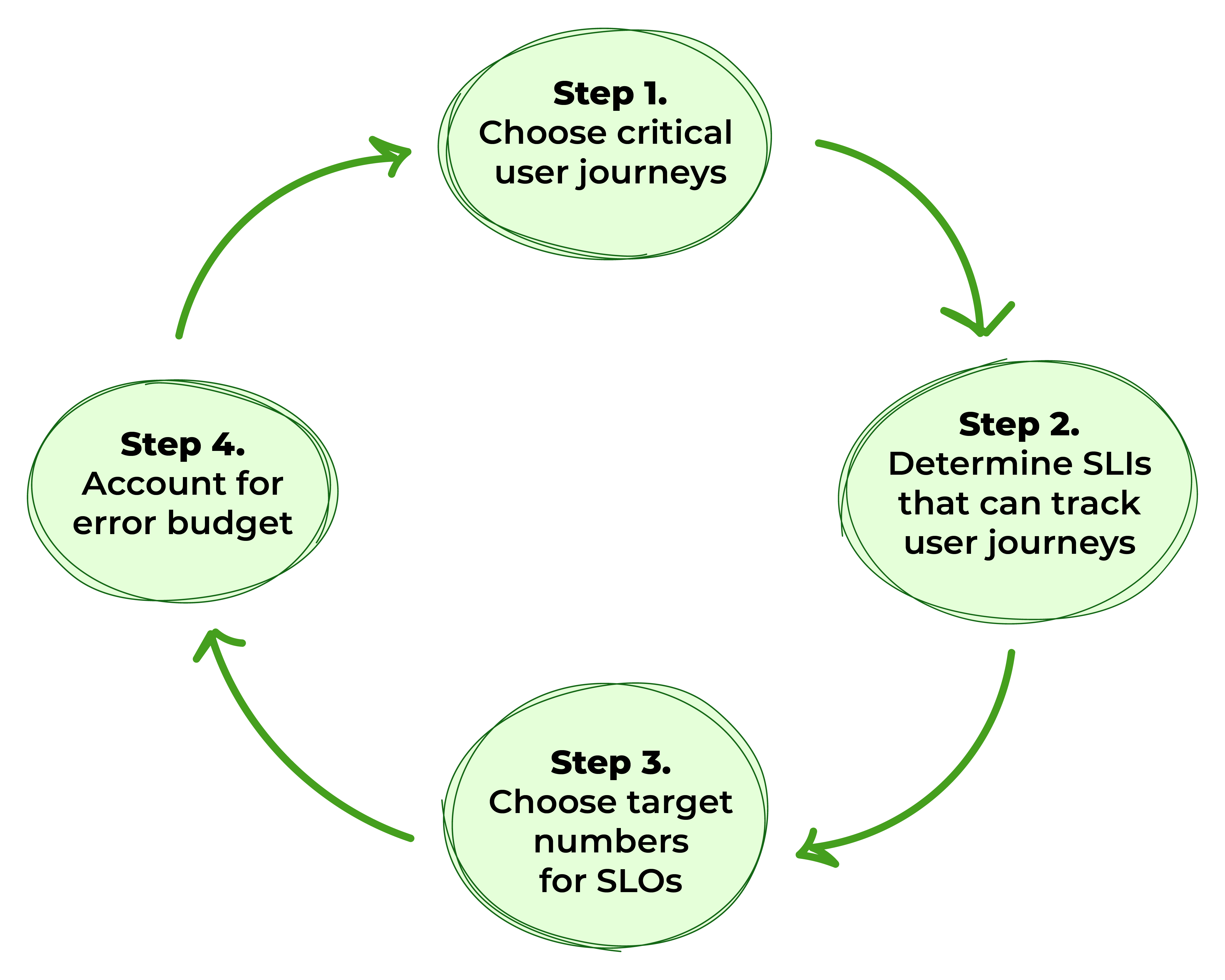
ステップ1: 重要なユーザージャーニーを選ぶ
重要なユーザージャーニーとは、ユーザーがシステムやサービス内で特定の目標を達成するために取る一連のインタラクションを指します。これらのジャーニーの信頼性を確保することが重要です because it directly impacts the customer experience. 重要なユーザージャーニーを特定する方法としては、特定のワークフローが失敗した場合の収益/ビジネスへの影響を評価することや、ユーザーアナリティクスを通じて頻繁なフローを識別することが挙げられます。
例えば、仮想マシン(VM)を作成するサービスを考えてみましょう。ユーザーがこのサービスで行うことができるアクションには、利用可能なVMの形状をブラウズすること、VMを作成するリージョンを選ぶこと、そしてVMを起動することが含まれます。開発チームがビジネスへの影響によってこれらを順位付けすると、以下のようになります:
- VMの起動これは直接的な収益への影響があるためです。ユーザーがVMを起動できない場合、サービスの核心機能が失敗していることになり、顧客満足度と収益に直接影響を及ぼします。
- リージョンの選択してVMを作成します。ユーザーは異なるリージョンでVMを作成することもできますが、リージョンに特化した好みがある場合、体験が劣化する可能性があります。この選択はパフォーマンスとコンプライアンスに影響を与えることがあります。
- VMカタログの閲覧。これは意思決定に重要ですが、ユーザーは後でVMの形状を変更できるため、ビジネスへの直接的な影響は低いです。
ステップ2: ユーザージャーニーを追跡できるサービスレベル指標を決定する
ユーザージャーニーが定義されたので、次のステップはそれらを効果的に測定することです。サービスレベル指標(SLI)は、開発者がシステムのパフォーマンスと信頼性を数量化するために使用するメトリクスです。エンジニアリングチームにとって、SLIは二重の目的を果たします:劣化を検出し、アーキテクチャの決定をガイドし、インフラストラクチャの変更を検証するための実行可能なデータを提供し、また、信頼性の目標を設定および追跡するための定量的測定を提供し、意味のあるSLOの基盤を形成します。
たとえば、VMを起動する場合、SLIの一部として可用性と遅延が挙げられます。
可用性:VMを起動するXリクエストのうち、いくつが成功しましたか?これを計算する簡単な式は:
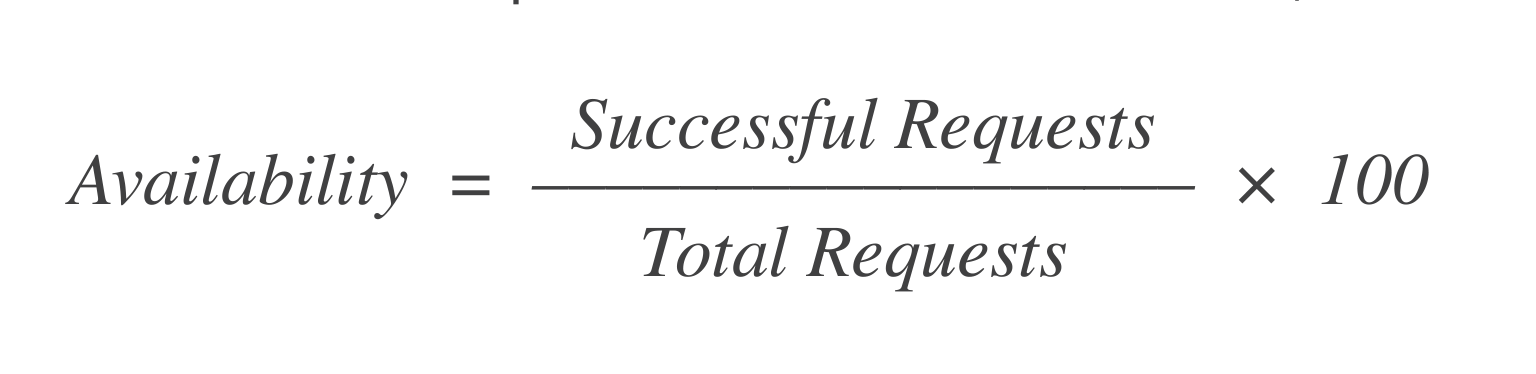
もし1,000リクエスト中998リクエストが成功した場合、可用性は=99.8%です。
遅延:VMを起動するリクエストの総数のうち、50番目、95番目、または99番目のパーセンタイルのリクエストがVMの起動にどのくらいの時間を要したか?ここでのパーセンタイルは例であり、特定のユースケースやサービスレベルの期待に応じて変動する可能性があります。
- 1000件のリクエストがあるシナリオで、900件のリクエストが5秒で完了し、残りの100件が10秒かかった場合、95パーセンタイルのレイテンシーは10秒です。
- 平均値もレイテンシーの計算に使用できますが、パーセンタイルは尾部のレイテンシーを考慮するため、ユーザーエクスペリエンスをより正確に表現するために推奨されます。
ステップ3: SLOのターゲット数を特定する
簡単に言えば、SLOは特定の時間枠内でSLIが達成すべきターゲット数です。VMのシナリオでは、SLOは以下のようになります:
- サービスの可用性は30日間のローリングウィンドウで99%以上であること。
- VMの起動における95パーセンタイルのレイテンシーは8秒を超えないこと。
これらのターゲットを設定する際に考慮すべき点は以下の通りです:
-
過去のデータを使用する。30日間のローリング期間に基づいてSLOを設定する必要がある場合は、複数の30日間のウィンドウからのデータを収集してターゲットを定義します。
- この過去のデータがない場合は、まずは毎日99%の可用性を目指すなど、より管理可能な目標から始め、情報を収集しながら時間をかけて調整します。
- 覚えておいてください、SLOは決して固定されていません。サービスと顧客の変化するニーズを反映するように継続的に進化させるべきです。
-
依存関係のSLOを考慮する。サービスは通常、データベースやロードバランサーなどの他のサービスやインフラストラクチャコンポーネントに依存しています。
-
たとえば、あなたのサービスが99.9%の可用性を持つSQLデータベースに依存している場合、あなたのサービスのSLOは99.9%を超えることはできません。これは、最大の可用性がその基盤となる依存関係の性能によって制約されており、それがより高い信頼性を保証できないためです。
-
SLOの課題
SLOを100%に設定するのは興味深いかもしれませんが、これは不可能です。たとえば、100%の可用性というのは、機能のリリースやパッチ適用、テストなどの重要な活動のための余地が全くないことを意味し、現実的ではありません。SLOを定義するには、エンジニアリング、プロダクト、オペレーション、QA、リーダーシップを含む複数のチーム間での協力が必要です。すべての関係者が一貫しており、目標に同意していることを確認することが、SLOが成功し、実行可能であるためには必須です。
ステップ4: エラーバジェットを考慮する
エラーバジェットは、システムが顧客を不快にさせず、契約上の義務を侵害せずに許容できるダウンタイムの測定です。以下はその見方の一つです:
- もしエラーバジェットがほとんど枯渇している場合、エンジニアリングチームは新しい機能のリリースよりも信頼性の向上とインシデントの削減に集中するべきです。
- もしエラーバジェットがまだ十分にある場合、システムが信頼性の目標内で良好に動作しているため、エンジニアリングチームは新しい機能のリリースを優先することができます。
エラーバジェットを測定する一般的なアプローチには、時間ベースとイベントベースの二つがあります。では、「サービスの可用性は30日間のローリングウィンドウで99%を超えるべきである」という声明がそれぞれにどのように適用されるかを見てみましょう。
時間ベースの測定
時間ベースのエラーバジェットでは、上記の声明はサービスが月に43分50秒、または年に7時間14分までダウンすることが許されることを意味します。以下はその計算方法です:
-
データポイントの数を決定します。 SLO時間ウィンドウ内の時間単位(データポイント)の数を決定することから始めます。たとえば、基準時間単位が1分でSLOウィンドウが30日の場合:
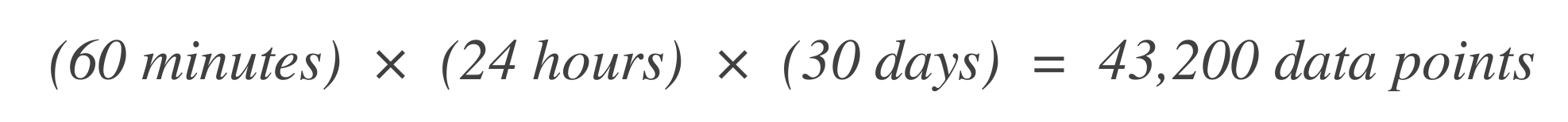
-
エラーバジェットを計算します。次に、どれだけのデータポイントが「失敗」できるか(つまり、ダウンタイム)を計算します。エラーバジェットは許容される失敗の割合です。
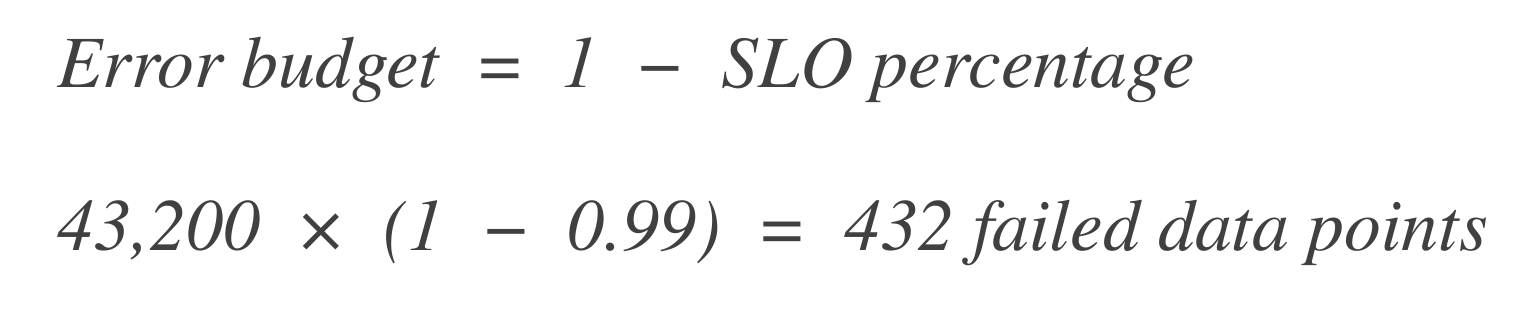
これを時間に変換します:
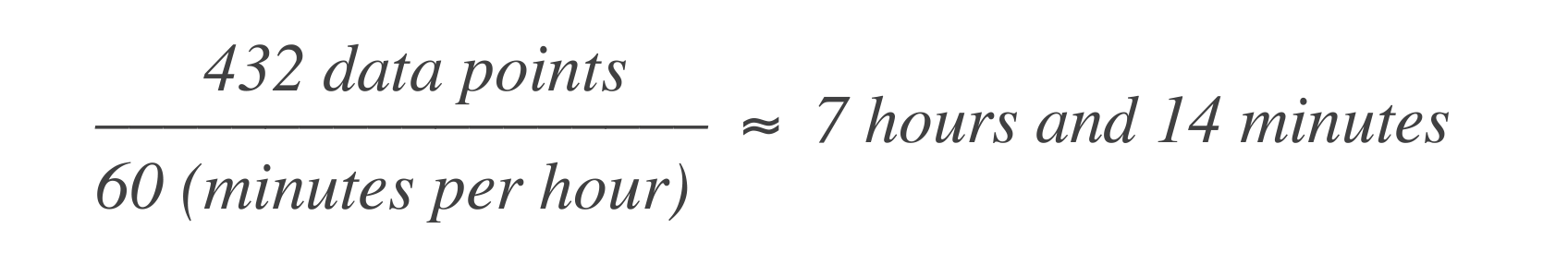
これは、システムが30日間のウィンドウで7時間14分のダウンタイムを経験できることを意味します。
最後に、残りのエラーバジェットは、総可能ダウンタイムと既に使用されたダウンタイムの差です。
イベントベースの測定
イベントベースの測定では、エラーバジェットは百分率で測定されます。上述の声明は、30日間のローリングウィンドウで1%のエラーバジェットに相当します。
たとえば、その30日間のウィンドウに43,200データポイントがあり、そのうち100が不良である場合、次の式を使用してエラーバジェットの消費量を計算できます:
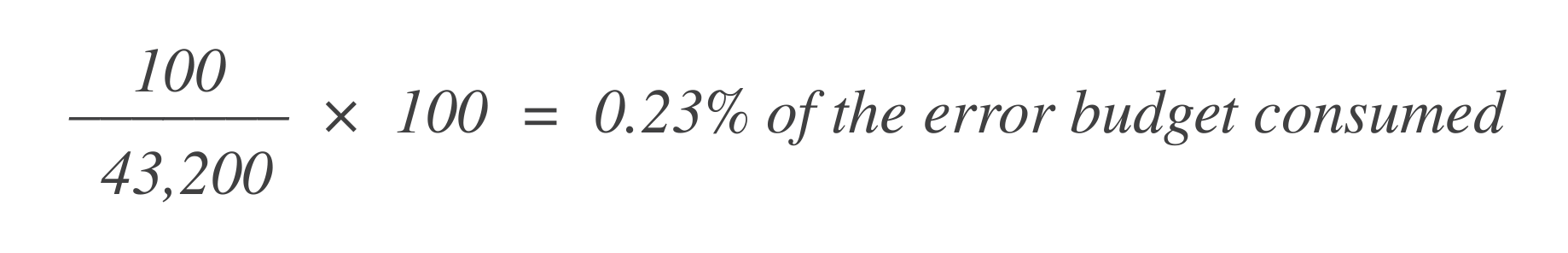
次に、残りのエラーバジェットがどれだけあるかを知るために、これを許容される総エラーバジェット(1%)から差し引きます。
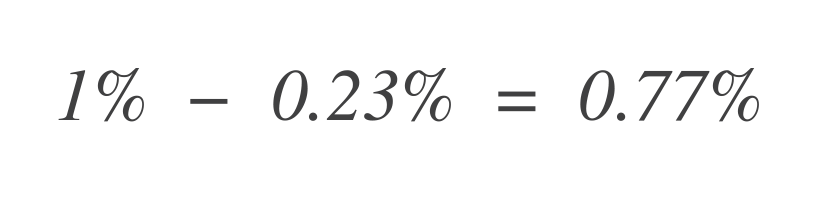
したがって、サービスはまだ0.77%の不良データポイントを許容できます。
エラーバジェットの利点
エラーバジェットは、予算の枯渇が危ぶまれる際に開発チームに通知する自動監視およびアラートの設定に利用できます。これらのアラートにより、チームはプロダクションへの変更をデプロイする際により慎重である必要があることを認識できます。機能と運用の優先順位付けについては、チームはしばしば曖昧さに直面します。エラーバジェットはこの課題に対処する一つの方法です。明確でデータ駆動型のメトリクスを提供することで、エンジニアリングチームは必要に応じて信頼性のタスクを新しい機能よりも優先することができます。エラーバジェットは、エンジニアリングチーム内の責任感と成熟度を高めるための確立された戦略の一つです。
エラーバジェットに対する注意点
予算に余裕がある場合、開発者は積極的にそれを利用するべきです。これは、カオスエンジニアリングのような技術を試してサービスの理解を深める絶好の機会です。エンジニアリングチームは、サービスがどのように反応するかを観察し、通常の運用では明らかでない隠れた依存関係を発見することができます。最後に、開発者はエラーバジェットの枯渇を closely 監視する必要があります。予期しない事象が急速にそれを消耗させる可能性があるためです。
結論
サービスレベル目標は、信頼性工学において目的地ではなく旅を表しています。これらはサービスの信頼性を測定するための重要な指標を提供しますが、その真の価値は組織内に信頼性の文化を創出することにあります。完璧を追求するのではなく、チームはSLOをサービスとともに進化するツールとして受け入れるべきです。将来を見据え、AIと機械学習の統合により、SLOは受動的な測定から予測的な手段へと変革するでしょう。
追加リソース:
-
Implementing Service Level Objectives、アレックス・ヒダルゴ、2020
-
「Service Level Objects」、クリス・ジョーンズ他、2017
-
「Implementing SLOs」、スティーブン・サーグッド他、2018
これはDZoneの2024年トレンドレポートからの抜粋です、可観測性とパフォーマンス:高性能ソフトウェアシステム構築の崖っぷち。
Source:
https://dzone.com/articles/framework-for-service-level-objectives