













На протяжении многих лет JDBC и ODBC являлись общепринятыми стандартами для взаимодействия с базами данных. Теперь, глядя на обширное пространство данных, рост наук о данных и аналитики в data lake приводит к появлению все больших и больших наборов данных. Соответственно, нам требуется все более быстрое чтение и передача данных, поэтому мы начинаем искать лучшие решения, чем JDBC и ODBC. Таким образом, мы включаем протокол Arrow Flight SQL в Apache Doris 2.1, который обеспечивает ускорение передачи данных в десятки раз.
Высокоскоростная передача данных на основе Arrow Flight SQL
Как столбцовая система управления базами данных, Apache Doris организует результаты запросов в виде данных Blocks в столбцовом формате. До версии 2.1, Blocks должны были сериализоваться в байты в строчном формате перед передачей на целевой клиент через клиент MySQL или драйвер JDBC/ODBC. Более того, если целевой клиент является столбцовой базой данных или столбцовой наукой о данных компонентом, таким как Pandas, данные затем должны быть десериализованы. Процесс сериализации-десериализации является препятствием для передачи данных.
Apache Doris 2.1 оснащен каналом передачи данных, построенным на Arrow Flight SQL. (Apache Arrow представляет собой платформу разработки программного обеспечения, предназначенную для эффективной передачи данных между системами и языками программирования, а формат Arrow нацелен на высокопроизводительный, безпотерьный обмен данными.) Это позволяет осуществлять высокоскоростное чтение больших объемов данных из Doris с помощью SQL на различных популярных языках программирования. Для целевых клиентов, которые также поддерживают формат Arrow, весь процесс будет свободен от сериализации/десериализации, что исключает потери производительности. Еще одним преимуществом является то, что Arrow Flight может полностью использовать многоузловое и многоядерное архитектурное решение и реализовать параллельную передачу данных, что является дополнительным фактором высокой пропускной способности данных.
Например, если клиент на Python считывает данные из Apache Doris, Doris сначала преобразует ориентированные на столбцы блоки в Arrow RecordBatch. Затем в клиенте Python Arrow RecordBatch преобразуется в Pandas DataFrame. Оба преобразования выполняются быстро, поскольку блоки Doris, Arrow RecordBatch и Pandas DataFrame все ориентированы на столбцы.
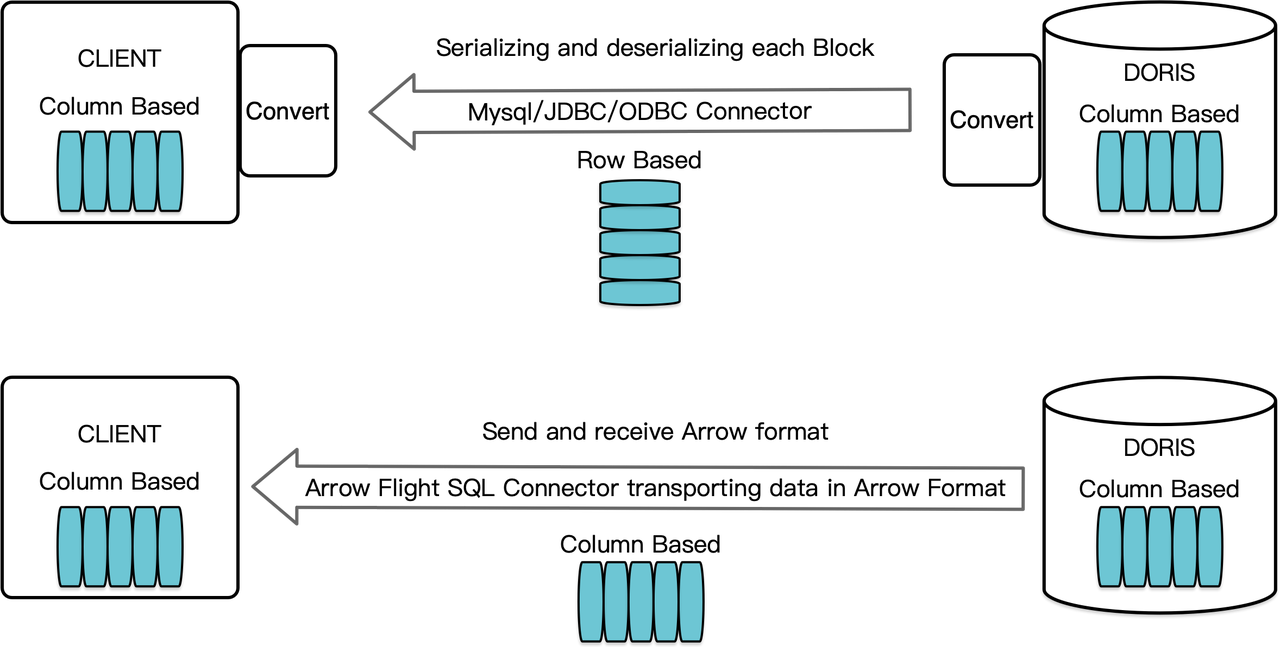
Кроме того, Arrow Flight SQL предоставляет универсальный драйвер JDBC для облегчения бесшовного взаимодействия между базами данных, которые поддерживают протокол Arrow Flight SQL. Это раскрывает потенциал Doris для подключения к более широкому экосистеме и использования в большем количестве случаев.
Тестирование производительности
Вывод о “ускорении в десять раз” основан на наших тестовых проверках. Мы пробовали читать данные из Doris с использованием PyMySQL, Pandas и Arrow Flight SQL, и записывали длительности соответственно. Данные для теста взяты из набора ClickBench.

Результаты для различных типов данных следующие:
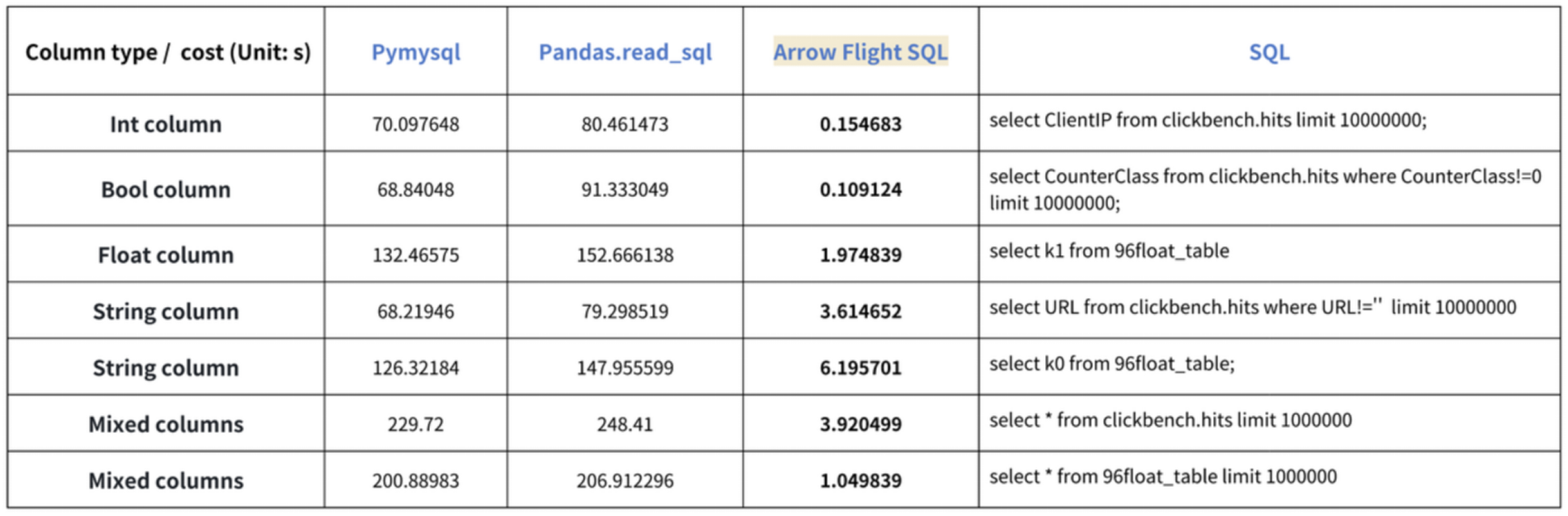
Как показано, Arrow Flight SQL превосходит PyMySQL и Pandas по всем типам данных в диапазоне от 20 до нескольких сотен.
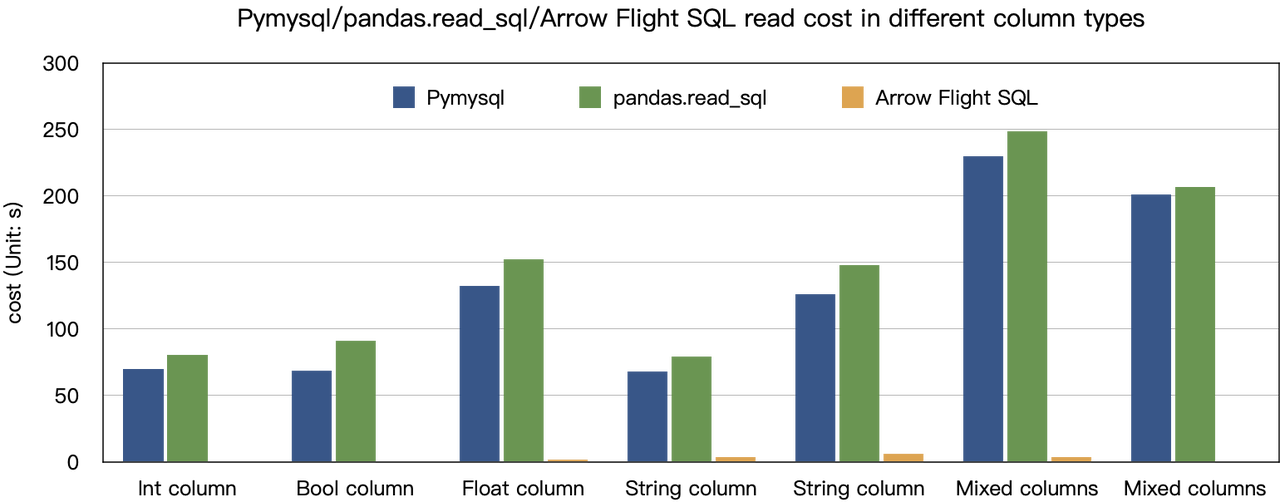
Использование
С поддержкой Arrow Flight SQL, Apache Doris может использовать драйвер Python ADBC для быстрого чтения данных. Я продемонстрирую несколько часто выполняемых операций с базой данных с использованием драйвера Python ADBC (версия 3.9 и выше), включая DDL, DML, настройку переменных сессии и show команды.
1. Установка библиотеки
Соответствующая библиотека уже опубликована на PyPI. Её можно установить следующим образом:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlИмпортируйте следующий модуль/библиотеку для взаимодействия с установленной библиотекой:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Подключение к Doris
Создайте клиент для взаимодействия с сервисом Arrow Flight SQL в Doris. Предварительные условия включают хост фронтенда (FE) Doris, порт Arrow Flight и имя пользователя/пароль для входа.
Настройте параметры для фронтенда (FE) и бэкенда (BE) Doris:
- В
fe/conf/fe.confустановитеarrow_flight_sql_portна доступный порт, например, 9090. - В
be/conf/be.confустановитеarrow_flight_portна доступный порт, например, 9091.
Предположим, что сервисы SQL Arrow Flight для экземпляра Doris будут работать на портах 9090 и 9091 для FE и BE соответственно, а имя пользователя/пароль для Doris – “user” и “pass”. Процесс подключения будет выглядеть следующим образом:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Создание таблицы и извлечение метаданных
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Загрузка данных
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Выполнение запросов
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Завершение кода
# Тест SQL Arrow Flight для Doris
# шаг 1, библиотека выпущена на PyPI и может быть легко установлена.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# шаг 2, создание клиента для взаимодействия с сервисом Doris Arrow Flight SQL.
# Измените arrow_flight_sql_port в файле fe/conf/fe.conf на доступный порт, например, 9090.
# Измените arrow_flight_port в файле be/conf/be.conf на доступный порт, например, 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# взаимодействие с Doris через SQL с использованием Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# шаг3, выполнение DDL-операций, создание базы данных/таблицы, отображение операций.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# шаг4, вставка данных
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# шаг5, выполнение запросов, агрегация, сортировка, установка сессионных переменных
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# шаг6, закрытие курсора
cursor.close()Примеры масштабного передачи данных
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# Обертка API PEP 249 (DB-API 2.0) для менеджера драйверов ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC считывает данные в dataframe pandas, что быстрее, чем fetchallarrow сначала, а затем to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Возможность считывать несколько партиций параллельно.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
Использование этого драйвера аналогично использованию драйвера для протокола MySQL. Вам просто нужно заменить jdbc:mysql в URL подключения на jdbc:arrow-flight-sql. Возвращаемый результат будет в структуре данных JDBC ResultSet.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// метод один
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, два шага:
// 1. Выполнить запрос и получить возвращенную FlightInfo;
// 2. Создать FlightInfoReader для последовательного перебора каждого Endpoint;
QueryResult queryResult = stmt.executeQuery()
// метод два
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Выполнить запрос и разобрать каждый Endpoint в FlightInfo, и использовать Location и Ticket для создания PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
//Создать ArrowReader для каждого PartitionDescriptor для чтения данных
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Соскучиться по поездке на поезде трендов
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow