













Ao longo dos anos, JDBC e ODBC tornaram-se normas amplamente adotadas para interação com bancos de dados. Agora, enquanto observamos a vastidão do universo dos dados, o surgimento da ciência de dados e a análise de data lakes trouxeram conjuntos de dados cada vez maiores. Consequentemente, precisamos de leitura e transmissão de dados cada vez mais rápidas, então começamos a buscar respostas melhores do que JDBC e ODBC. Dessa forma, incluímos o protocolo Arrow Flight SQL em Apache Doris 2.1, o que proporciona acelerações de dezenas de vezes na transferência de dados.
Transferência de Dados de Alta Velocidade Baseada em Arrow Flight SQL
Como um data warehouse orientado a colunas, o Apache Doris organiza seus resultados de consulta na forma de Blocos de dados em formato columnar. Antes da versão 2.1, esses Blocos precisavam ser serializados em bytes em formatos orientados a linhas antes de serem transferidos para um cliente de destino por meio de um cliente MySQL ou driver JDBC/ODBC. Além disso, se o cliente de destino for um banco de dados columnar ou um componente de ciência de dados orientado a colunas como o Pandas, os dados devem ser desserializados. O processo de serialização-desserialização representa um entrave à velocidade na transmissão de dados.
O Apache Doris 2.1 possui um canal de transmissão de dados construído em Arrow Flight SQL. (Apache Arrow é uma plataforma de desenvolvimento de software projetada para alta eficiência na movimentação de dados entre sistemas e linguagens, e o formato Arrow visa a troca de dados de alta performance e sem perdas.) Ele permite a leitura de dados em alta velocidade e em grande escala a partir de Doris via SQL em várias linguagens de programação principais. Para clientes de destino que também suportam o formato Arrow, todo o processo será livre de serialização/desserialização, portanto, sem perda de desempenho. Outra vantagem é que o Arrow Flight pode aproveitar a arquitetura multinó e multicore e implementar a transferência de dados em paralelo, o que é outro facilitador de alta taxa de transferência de dados.
Por exemplo, se um cliente Python lê dados do Apache Doris, Doris primeiro converterá os Blocos orientados a coluna em RecordBatch Arrow. Em seguida, no cliente Python, o RecordBatch Arrow será convertido em DataFrame Pandas. Ambas as conversões são rápidas porque os Blocos de Doris, o RecordBatch Arrow e o DataFrame Pandas são todos orientados a coluna.
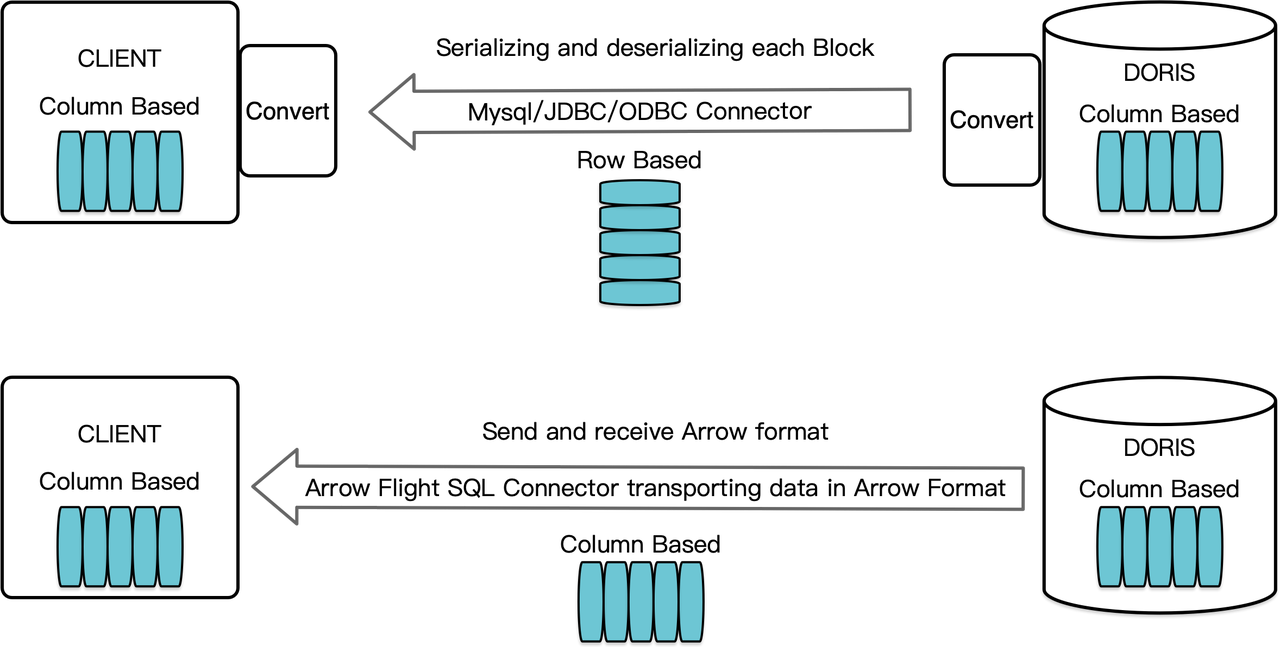
Além disso, o Arrow Flight SQL fornece um driver JDBC genérico para facilitar a comunicação sem fim entre bancos de dados que suportam o protocolo Arrow Flight SQL. Isso desbloqueia o potencial de Doris para ser conectado a uma eco-sistema mais amplo e ser usado em mais casos.
Teste de Desempenho
A conclusão sobre “acelerações de dez vezes” baseia-se em nossos testes de benchmark. Tentamos ler dados do Doris usando PyMySQL, Pandas e Arrow Flight SQL, e anotamos as durações, respectivamente. Os dados de teste são do conjunto de dados ClickBench.

Os resultados em vários tipos de dados são os seguintes:
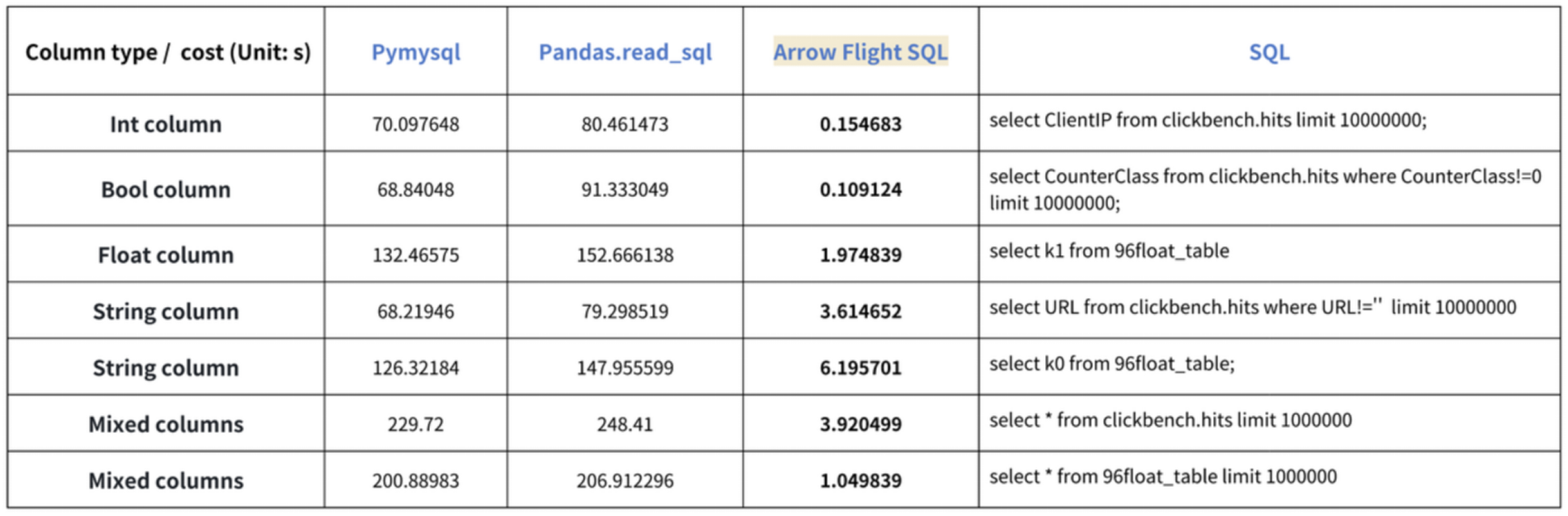
Como mostra, o Arrow Flight SQL supera o PyMySQL e o Pandas em todos os tipos de dados por um fator que varia de 20 a várias centenas.
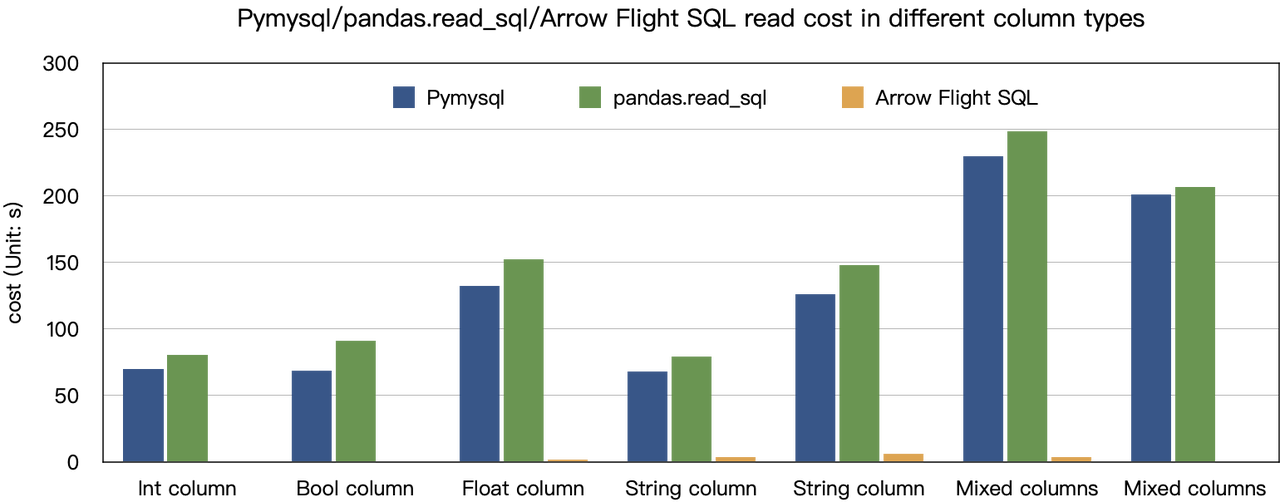
Uso
Com suporte para Arrow Flight SQL, o Apache Doris pode aproveitar o Driver Python ADBC para leitura de dados rápida. Vou mostrar algumas operações de banco de dados executadas com frequência usando o Driver Python ADBC (versão 3.9 ou posterior), incluindo DDL, DML, configuração de variáveis de sessão e show instruções.
1. Instalar Biblioteca
A biblioteca relevante já foi publicada no PyPI. Pode ser instalada simplesmente da seguinte forma:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImporte o seguinte módulo/biblioteca para interagir com a biblioteca instalada:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Conectar ao Doris
Crie um cliente para interagir com o serviço de Arrow Flight SQL do Doris. Pré-requisitos incluem host frontend (FE) do Doris, porta Arrow Flight e nome de usuário/senha de login.
Configure parâmetros para o frontend (FE) e backend (BE) do Doris:
- Em
fe/conf/fe.conf, definaarrow_flight_sql_portpara uma porta disponível, como 9090. - Em
be/conf/be.conf, definaarrow_flight_portpara uma porta disponível, como 9091.
Suponha que os serviços SQL do Arrow Flight para a instância do Doris serão executados nas portas 9090 e 9091 para FE e BE respectivamente, e o nome de usuário/senha do Doris é “user” e “pass”, o processo de conexão seria:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Criar uma Tabela e Recuperar Metadados
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Ingerir Dados
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Executar Consultas
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Código Completo
# Teste SQL do Arrow Flight do Doris
# passo 1, a biblioteca é lançada no PyPI e pode ser facilmente instalada.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# passo 2, criar um cliente que interage com o serviço SQL do Arrow Flight do Doris.
# Modificar arrow_flight_sql_port em fe/conf/fe.conf para uma porta disponível, como 9090.
# Modificar arrow_flight_port em be/conf/be.conf para uma porta disponível, como 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interagindo com o Doris via SQL usando Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# passo3, executar declarações DDL, criar banco de dados/tabela, mostrar stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# passo4, inserir em
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# passo5, executar consultas, agregação, ordenação, definir variável de sessão
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# passo6, fechar cursor
cursor.close()Exemplos de Transmissão de Dados em Escala
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# Wrapper da API PEP 249 (DB-API 2.0) para o Gerenciador de Driver ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC lê dados em dataframe do pandas, o que é mais rápido que fetchallarrow primeiro e depois to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Pode ler múltiplas partições em paralelo.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
O uso deste driver é semelhante ao utilizado para o protocolo MySQL. Basta substituir jdbc:mysql na URL de conexão por jdbc:arrow-flight-sql. O resultado retornado estará na estrutura de dados JDBC ResultSet.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// método um
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, duas etapas:
// 1. Executar a Query e obter o retorno FlightInfo;
// 2. Criar FlightInfoReader para percorrer sequencialmente cada Endpoint;
QueryResult queryResult = stmt.executeQuery()
// método dois
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Executar a Query e analisar cada Endpoint em FlightInfo, e usar a Localização e o Ingresso para construir um PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// Criar ArrowReader para cada PartitionDescriptor para ler os dados
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Embarque no Trem da Moda
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow