













Negli anni, JDBC e ODBC sono stati norme comunemente adottate per l’interazione con i database. Ora, mentre osserviamo la vasta estensione del mondo dei dati, l’ascesa della scienza dei dati e dell’analisi dei data lake porta a set di dati sempre più grandi. Di conseguenza, abbiamo bisogno di lettura e trasmissione dei dati sempre più veloci, quindi iniziamo a cercare risposte migliori di quelle offerte da JDBC e ODBC. Pertanto, includiamo il protocollo Arrow Flight SQL in Apache Doris 2.1, che fornisce velocizzazioni di decine di volte per il trasferimento dei dati.
Trasferimento Dati ad Alta Velocità Basato su Arrow Flight SQL
Come data warehouse orientato alle colonne, Apache Doris organizza i risultati delle query sotto forma di Blocchi di dati in formato colonnare. Prima della versione 2.1, i Blocchi dovevano essere serializzati in byte in formati orientati a righe prima di poter essere trasferiti a un client target tramite un client MySQL o un driver JDBC/ODBC. Inoltre, se il client target è un database colonnare o un componente di data science orientato alle colonne come Pandas, i dati devono poi essere deserializzati. Il processo di serializzazione-deserializzazione rappresenta un ostacolo per la trasmissione dei dati.
Apache Doris 2.1 dispone di un canale di trasmissione dati costruito su Arrow Flight SQL. (Apache Arrow è una piattaforma di sviluppo software progettata per garantire un’alta efficienza nel movimento dei dati attraverso sistemi e linguaggi diversi, e il formato Arrow mira a un’alta prestazione e uno scambio di dati senza perdite.) Consente la lettura di grandi quantità di dati ad alta velocità da Doris tramite SQL in vari linguaggi di programmazione di uso comune. Per i client target che supportano anche il formato Arrow, l’intero processo sarà privo di serializzazione/deserializzazione, quindi senza perdita di prestazioni. Un altro vantaggio è che Arrow Flight può sfruttare appieno l’architettura multinodo e multicore e implementare il trasferimento dati parallelo, che è un altro fattore di attivazione dell’alto throughput dei dati.
Ad esempio, se un client Python legge dati da Apache Doris, Doris convertirà prima i Blocchi orientati a colonna in RecordBatch di Arrow. Quindi, nel client Python, Arrow RecordBatch verrà convertito in DataFrame di Pandas. Entrambe le conversioni sono veloci perché i Blocchi di Doris, Arrow RecordBatch e Pandas DataFrame sono tutti orientati a colonna.
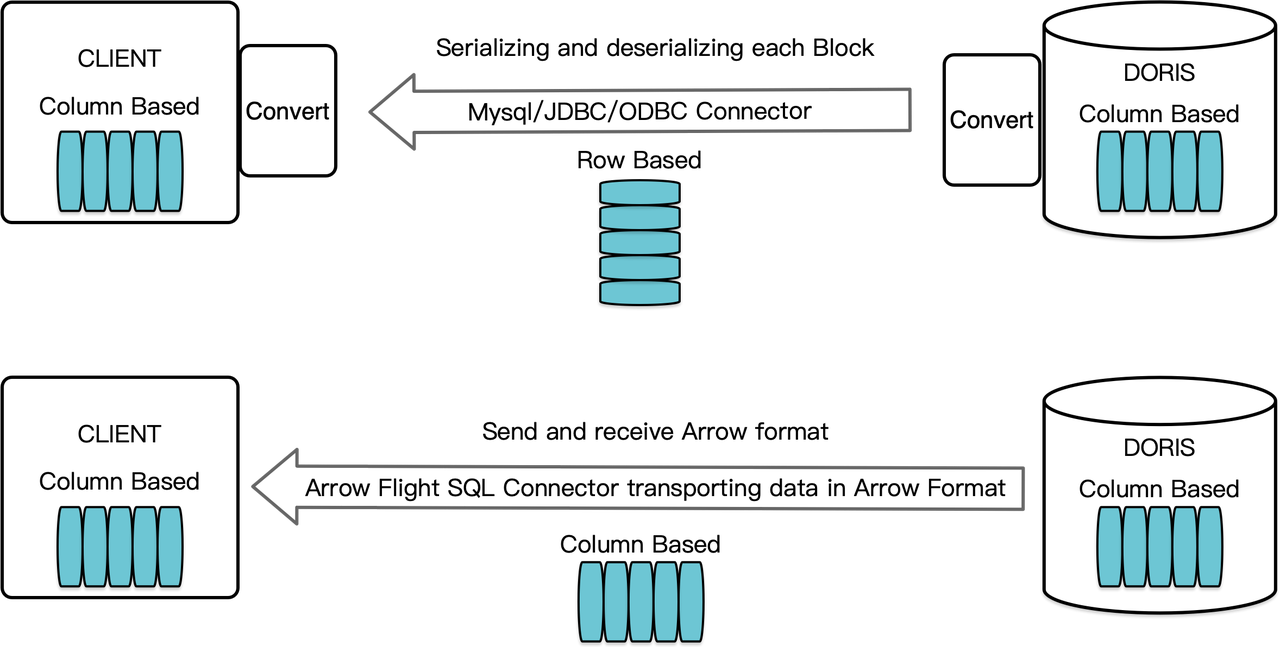
Inoltre, Arrow Flight SQL fornisce un driver JDBC generico per facilitare la comunicazione senza soluzione di continuità tra database che supportano il protocollo Arrow Flight SQL. Questo sblocca il potenziale di Doris per essere connesso a un ecosistema più ampio e per essere utilizzato in più casi.
Test di Prestazioni
La conclusione delle “accelerazioni di dieci volte” si basa sui nostri test di benchmark. Abbiamo provato a leggere i dati da Doris utilizzando PyMySQL, Pandas e Arrow Flight SQL, e abbiamo annotato i tempi rispettivamente. I dati di test sono il set di dati ClickBench.

I risultati su vari tipi di dati sono i seguenti:
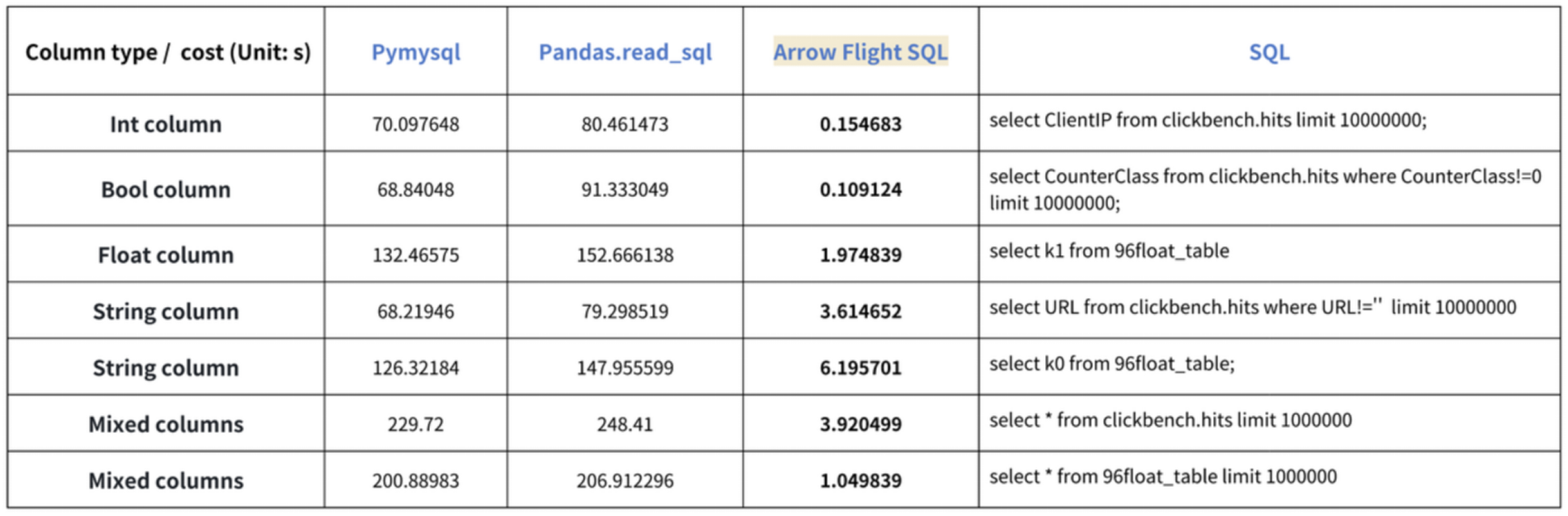
Come mostrato, Arrow Flight SQL supera PyMySQL e Pandas in tutti i tipi di dati con un fattore che va da 20 a diverse centinaia.
Utilizzo
Con il supporto per Arrow Flight SQL, Apache Doris può sfruttare il Driver ADBC Python per la lettura dei dati veloce. Mostrerò alcune operazioni database eseguite frequentemente utilizzando il Driver ADBC Python (versione 3.9 o successiva), tra cui DDL, DML, impostazione delle variabili di sessione e show statement.
1. Installare la libreria
La libreria pertinente è già pubblicata su PyPI. Può essere installata semplicemente come segue:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImportare il seguente modulo/libreria per interagire con la libreria installata:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Connettersi a Doris
Creare un client per interagire con il servizio Arrow Flight SQL di Doris. I prerequisiti includono host frontend (FE) di Doris, porta Arrow Flight e nome utente/password di accesso.
Configurare i parametri per il frontend (FE) e il backend (BE) di Doris:
- In
fe/conf/fe.conf, impostarearrow_flight_sql_portsu una porta disponibile, come 9090. - In
be/conf/be.conf, impostarearrow_flight_portsu una porta disponibile, come 9091.
Supponiamo che i servizi SQL di Arrow Flight per l’istanza di Doris funzionino sui porte 9090 e 9091 rispettivamente per FE e BE, e che il nome utente/password di Doris sia “user” e “pass”, il processo di connessione sarebbe:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Creare una Tabella e Recuperare la Metadati
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Inserire Dati
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Eseguire Consulti
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Codice Completo
# Test di Doris Arrow Flight SQL
# Passo 1, la libreria è distribuita su PyPI e può essere facilmente installata.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# Passo 2, creare un client che interagisce con il servizio Doris Arrow Flight SQL.
# Modificare arrow_flight_sql_port in fe/conf/fe.conf in una porta disponibile, come 9090.
# Modificare arrow_flight_port in be/conf/be.conf in una porta disponibile, come 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# Interagire con Doris tramite SQL utilizzando Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# Passo3, eseguire istruzioni DDL, creare database/tabella, mostrare stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# Passo4, inserire in
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# Passo5, eseguire consulti, aggregazione, ordinamento, impostare variabile di sessione
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# Passo6, chiudere cursor
cursor.close()Esempi di Trasmissione Dati su Grande Scala
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- codifica: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# Wrapper API PEP 249 (DB-API 2.0) per il Driver Manager ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC legge i dati in dataframe pandas, che è più veloce di fetchallarrow prima e poi to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Può leggere più partizioni in parallelo.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
L’utilizzo di questo driver è simile all’uso di quello per il protocollo MySQL. Basta sostituire jdbc:mysql nell’URL di connessione con jdbc:arrow-flight-sql. Il risultato restituito sarà nella struttura dei dati ResultSet JDBC.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// metodo uno
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, due passaggi:
// 1. Esegui la Query e ottieni il ritorno FlightInfo;
// 2. Crea FlightInfoReader per attraversare sequenzialmente ogni Endpoint;
QueryResult queryResult = stmt.executeQuery()
// metodo due
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Esegui la Query e analizza ogni Endpoint in FlightInfo, e usa la Location e il Ticket per costruire un PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// Crea ArrowReader per ogni PartitionDescriptor per leggere i dati
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Salta sul Treno delle Tendenze
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow