













Depuis des années, JDBC et ODBC ont été des normes couramment adoptées pour l’interaction avec les bases de données. Aujourd’hui, en contemplant l’immensité du domaine des données, l’essor de la science des données et des analyses de data lake apporte des jeux de données de plus en plus volumineux. Par conséquent, nous avons besoin de lectures et de transmissions de données de plus en plus rapides, nous cherchons donc des réponses plus efficaces que JDBC et ODBC. C’est ainsi que nous intégrons le protocole Arrow Flight SQL dans Apache Doris 2.1, offrant ainsi des accélérations d’un facteur dizaine pour le transfert de données.
Transfert de Données Haute Vitesse Basé sur Arrow Flight SQL
En tant que système de gestion de base de données orienté colonne, Apache Doris organise ses résultats de requête sous forme de blocs de données dans un format orienté colonne. Avant la version 2.1, ces blocs devaient être sérialisés en octets dans des formats orientés ligne avant d’être transférés à un client cible via un client MySQL ou un pilote JDBC/ODBC. De plus, si le client cible est une base de données orientée colonne ou un composant de science des données orienté colonne comme Pandas, les données doivent ensuite être désérialisées. Le processus de sérialisation-désérialisation constitue un frein à la transmission des données.
Apache Doris 2.1 dispose d’un canal de transmission de données construit sur Arrow Flight SQL. (Apache Arrow est une plateforme de développement logiciel conçue pour une efficacité élevée dans le transfert de données entre systèmes et langages, et le format Arrow vise à une échange de données de haute performance, sans perte d’information.) Il permet la lecture de données à grande vitesse et à grande échelle à partir de Doris via SQL dans divers langages de programmation principaux. Pour les clients cibles qui prennent également en charge le format Arrow, tout le processus sera dénué de sérialisation/désérialisation, et donc sans perte de performance. Un autre avantage est que Arrow Flight peut tirer pleinement parti d’une architecture multi-nœuds et multi-cœurs et mettre en œuvre le transfert de données parallèle, ce qui est un autre vecteur de haut débit de données.
Par exemple, si un client Python lit des données à partir d’Apache Doris, Doris convertira d’abord les blocs orientés colonnes en RecordBatch Arrow. Ensuite, dans le client Python, RecordBatch Arrow sera converti en DataFrame Pandas. Les deux conversions sont rapides car les blocs Doris, RecordBatch Arrow et DataFrame Pandas sont tous orientés colonnes.
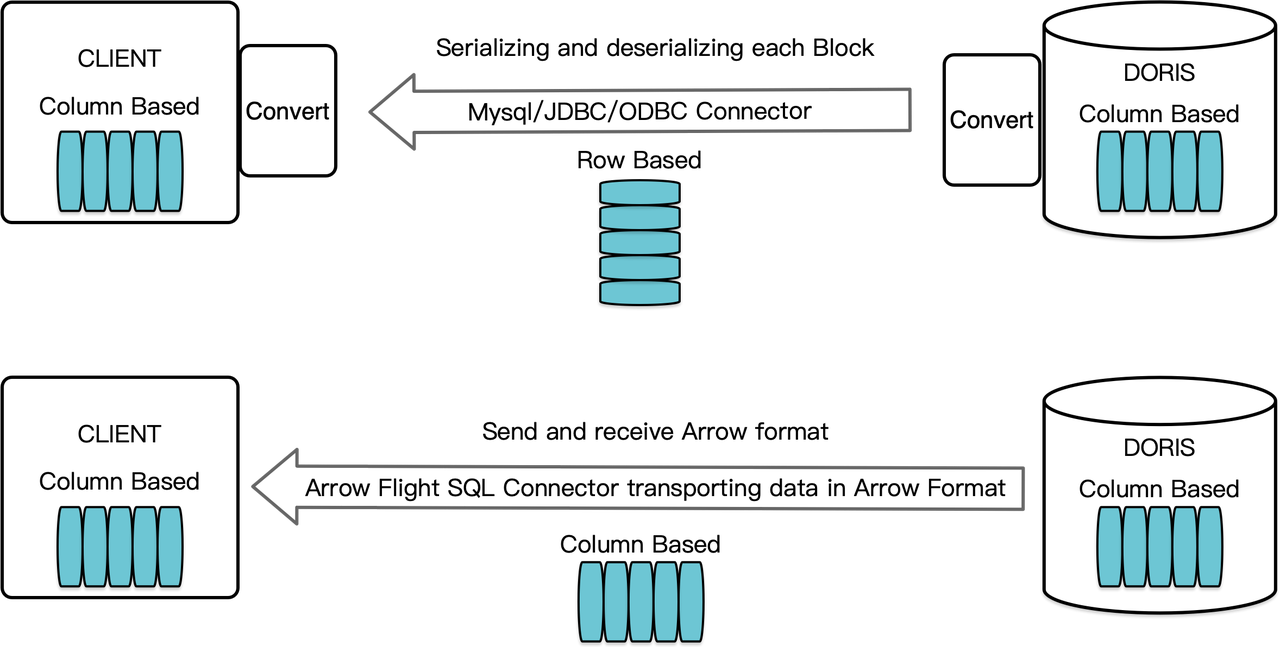
De plus, Arrow Flight SQL fournit un pilote JDBC générique pour faciliter la communication transparente entre les bases de données qui prennent en charge le protocole Arrow Flight SQL. Cela libère le potentiel de Doris pour être connecté à un écosystème plus large et pour être utilisé dans plus de cas.
Test de Performance
La conclusion des « accélérations dix fois plus rapides » est basée sur nos tests de référence. Nous avons essayé de lire des données à partir de Doris en utilisant PyMySQL, Pandas et Arrow Flight SQL, et avons noté les durées, respectivement. Les données de test sont le jeu de données ClickBench.

Les résultats sur divers types de données sont les suivants:
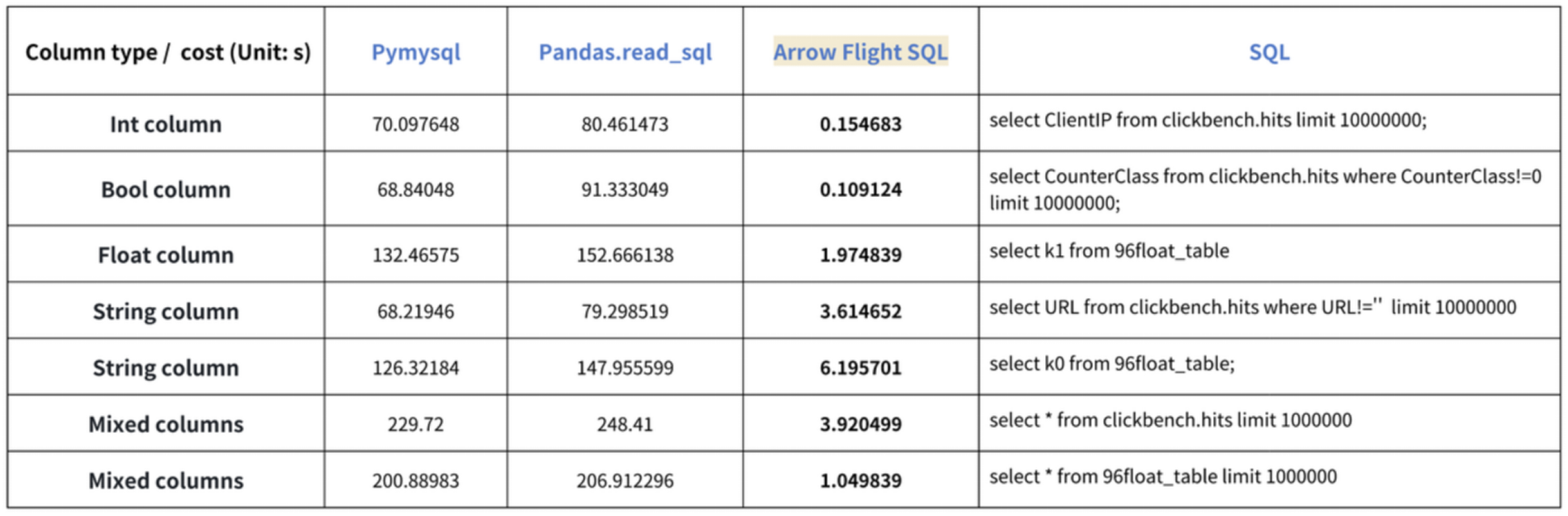
Comme le montre, Arrow Flight SQL surpasse PyMySQL et Pandas pour tous les types de données, avec un facteur allant de 20 à plusieurs centaines.
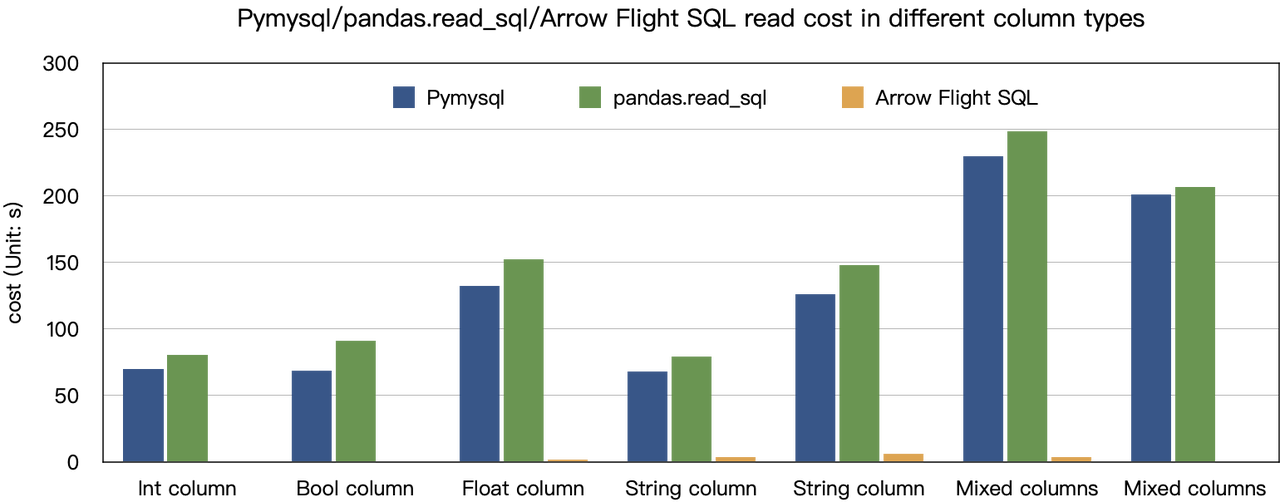
Utilisation
Avec le support pour Arrow Flight SQL, Apache Doris peut tirer parti du pilote Python ADBC pour une lecture de données rapide. Je vais présenter quelques opérations de base de données fréquemment exécutées en utilisant le pilote Python ADBC (version 3.9 ou ultérieure), y compris DDL, DML, paramétrage de variable de session, et show instructions.
1. Installer la bibliothèque
La bibliothèque pertinente est déjà publiée sur PyPI. Elle peut être installée simplement comme suit:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImporter le module/bibliothèque suivant pour interagir avec la bibliothèque installée:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Se connecter à Doris
Créer un client pour interagir avec le service Doris Arrow Flight SQL. Les prérequis incluent l’hôte frontal (FE) de Doris, le port Arrow Flight et le nom d’utilisateur/mot de passe de connexion.
Configurer les paramètres pour l’hôte frontal (FE) et l’arrière-plan (BE) de Doris:
- Dans
fe/conf/fe.conf, définissezarrow_flight_sql_portsur un port disponible, tel que 9090. - Dans
be/conf/be.conf, définissezarrow_flight_portsur un port disponible, tel que 9091.
Supposons que les services Arrow Flight SQL pour l’instance Doris fonctionneront sur les ports 9090 et 9091 respectivement pour FE et BE, et que le nom d’utilisateur/mot de passe Doris est « user » et « pass », le processus de connexion serait :
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Créer une table et récupérer les métadonnées
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Ingestion de données
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Exécution des requêtes
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Code final
# Test Arrow Flight SQL Doris
# Étape 1, la bibliothèque est publiée sur PyPI et peut être facilement installée.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# Étape 2, créer un client qui interagit avec le service Arrow Flight SQL Doris.
# Modifier arrow_flight_sql_port dans fe/conf/fe.conf vers un port disponible, tel que 9090.
# Modifier arrow_flight_port dans be/conf/be.conf vers un port disponible, tel que 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# Interagir avec Doris via SQL en utilisant Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# Étape 3, exécuter des instructions DDL, créer base de données/table, montrer stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# Étape 4, insérer dans
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# Étape 5, exécuter des requêtes, agrégation, tri, définir variable de session
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# Étape 6, fermer le curseur
cursor.close()Exemples de transmission de données à grande échelle
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# Wrapper API PEP 249 (DB-API 2.0) pour le gestionnaire de pilotes ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC lit les données dans un dataframe pandas, ce qui est plus rapide que fetchallarrow d'abord puis to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Peut lire plusieurs partitions en parallèle.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
L’utilisation de ce pilote est similaire à celle pour le protocole MySQL. Il vous suffit de remplacer jdbc:mysql dans l’URL de connexion par jdbc:arrow-flight-sql. Le résultat retourné sera dans la structure de données JDBC ResultSet.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// méthode une
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, deux étapes:
// 1. Exécutez la requête et obtenez le FlightInfo retourné;
// 2. Créez un FlightInfoReader pour parcourir séquentiellement chaque Endpoint;
QueryResult queryResult = stmt.executeQuery()
// méthode deux
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Exécutez la requête et parsez chaque Endpoint dans FlightInfo, et utilisez la Location et le Ticket pour construire un PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// Créez un ArrowReader pour chaque PartitionDescriptor pour lire les données
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Montez à bord du train de la tendance
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow