













多年来,JDBC和ODBC一直是数据库交互中广泛采用的标准。如今,随着我们面对数据领域的广阔天地,数据科学和数据湖分析的兴起带来了越来越庞大的数据集。相应地,我们需要更快速的数据读取和传输,因此我们开始寻找比JDBC和ODBC更优的解决方案。为此,我们在Apache Doris 2.1中引入了Arrow Flight SQL协议,该协议为数据传输提供了数十倍的速度提升。
基于Arrow Flight SQL的高速数据传输
作为一款列式数据仓库,Apache Doris将其查询结果以列式格式的数据块形式排列。在2.1版本之前,这些数据块必须先序列化成行式格式的字节流,然后才能通过MySQL客户端或JDBC/ODBC驱动传输给目标客户端。此外,如果目标客户端是列式数据库或如Pandas这样的列式数据科学组件,数据还需要进行反序列化。这种序列化-反序列化过程成为了数据传输中的速度瓶颈。
Apache Doris 2.1采用了基于Arrow Flight SQL的数据传输通道。Apache Arrow作为一个专为跨系统和语言实现高效数据传输而设计的软件开发平台,其格式追求高性能、无损的数据交换。该通道支持通过SQL从Doris高速读取大规模数据,并且适用于多种主流编程语言。对于同样支持Arrow格式的目标客户端,整个过程无需进行序列化/反序列化,从而避免了性能损耗。此外,Arrow Flight能够充分利用多节点和多核架构,实现并行数据传输,这也是提升数据吞吐量的另一关键因素。
例如,当Python客户端从Apache Doris读取数据时,Doris首先将列式Blocks转换为Arrow RecordBatch。随后,在Python客户端中,Arrow RecordBatch被快速转换为Pandas DataFrame。这两次转换都极为迅速,因为Doris Blocks、Arrow RecordBatch和Pandas DataFrame均为列式结构。
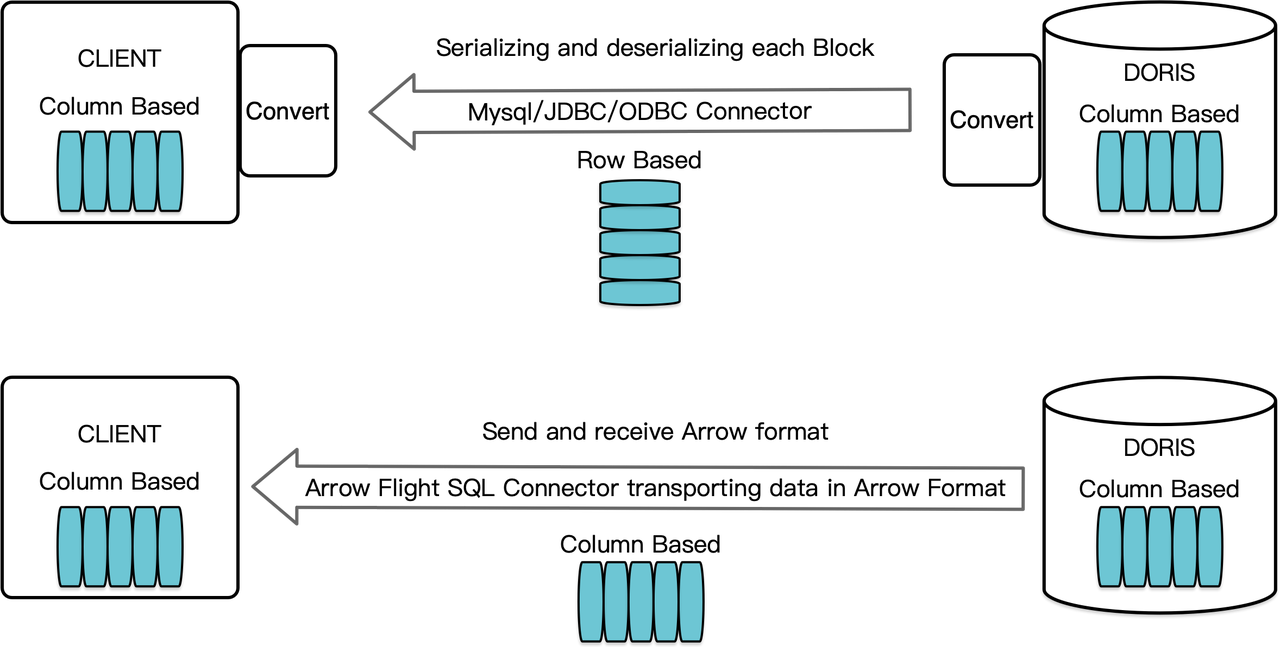
同时,Arrow Flight SQL提供了一个通用的JDBC驱动,方便支持Arrow Flight SQL协议的数据库之间实现无缝通信,进一步拓展了Doris的连接潜力,使其能够接入更广泛的生态系统,并应用于更多场景。
性能测试
“数十倍加速”的结论源自我们的基准测试。我们尝试使用PyMySQL、Pandas和Arrow Flight SQL从Doris读取数据,并分别记录了耗时。测试数据集为ClickBench。

各类数据类型的测试结果如下:
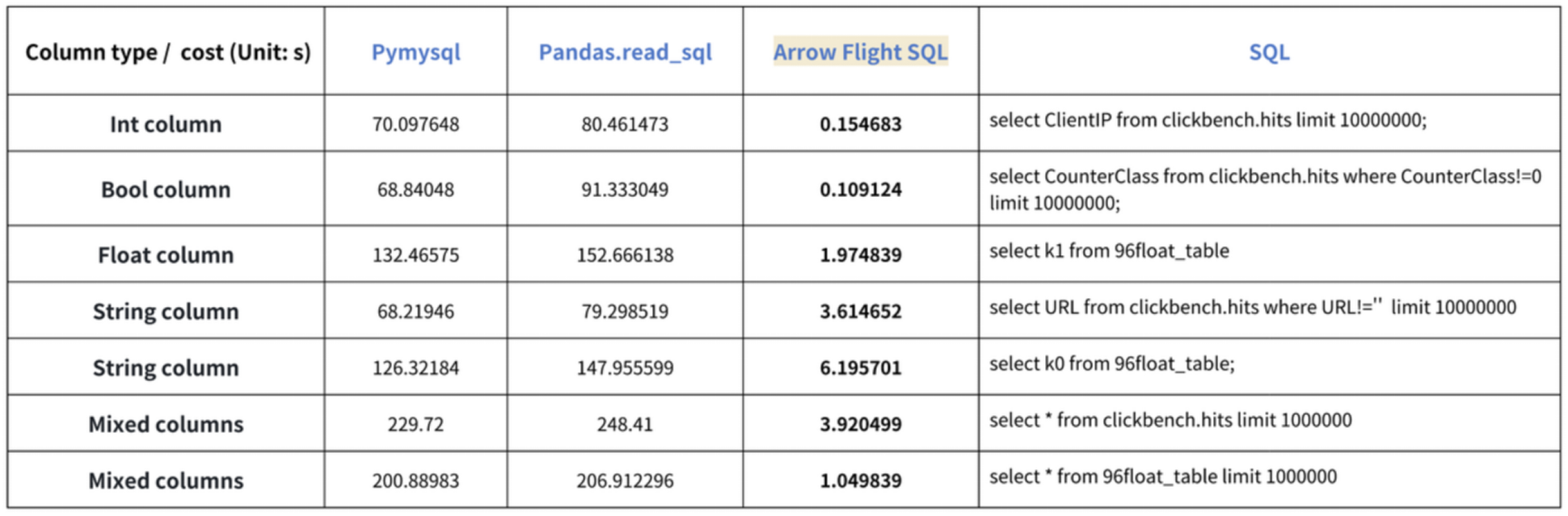
如图所示,Arrow Flight SQL在所有数据类型上均优于PyMySQL和Pandas,性能提升幅度从20倍到数百倍不等。
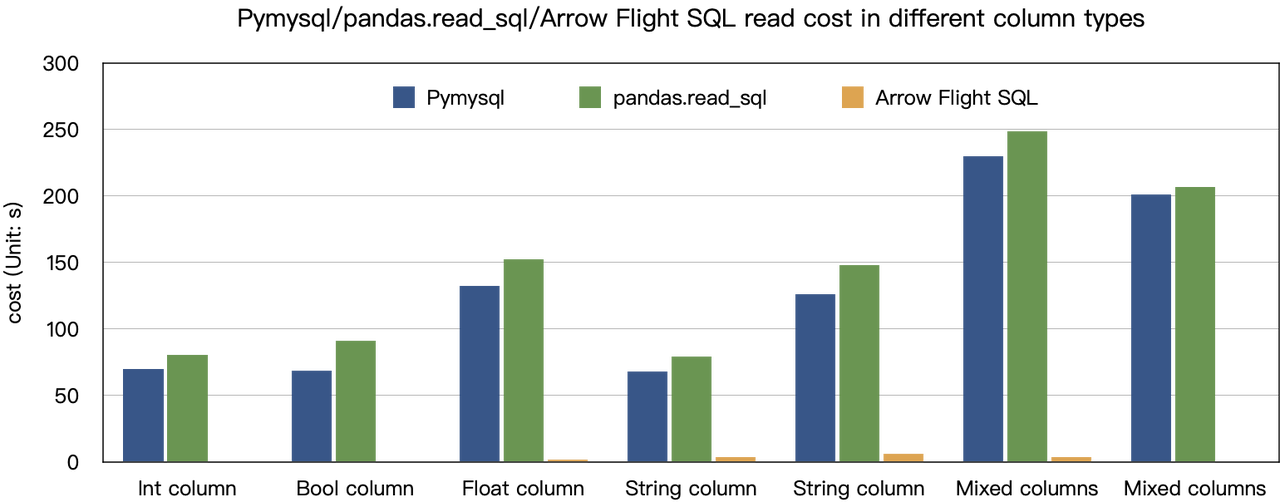
使用方法
借助对Arrow Flight SQL的支持,Apache Doris能够利用Python ADBC驱动程序实现快速数据读取。接下来,我将展示几种常用的数据库操作,均使用Python ADBC驱动程序(版本3.9及以上),包括DDL、DML、会话变量设置以及show语句。
1. 安装库
相关库已在PyPI发布,安装方法如下:
pip install adbc_driver_manager
pip install adbc_driver_flightsql导入以下模块/库以与已安装的库交互:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. 连接至Doris
创建一个客户端以与Doris的Arrow Flight SQL服务交互。前提条件包括Doris前端(FE)主机、Arrow Flight端口以及登录用户名/密码。
配置Doris前端(FE)和后端(BE)的参数:
- 在
fe/conf/fe.conf中,将arrow_flight_sql_port设置为可用端口,例如9090。 - 在
be/conf/be.conf中,将arrow_flight_port设置为可用端口,例如9091。
假设为Doris实例配置的Arrow Flight SQL服务将在FE和BE端口上分别运行于9090和9091,用户名/密码为”user”和”pass”,连接流程如下:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. 创建表并检索元数据
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. 导入数据
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. 执行查询
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. 完整代码
# Doris Arrow Flight SQL测试
# 步骤1,库已发布在PyPI,可轻松安装。
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# 步骤2,创建与Doris Arrow Flight SQL服务交互的客户端。
# 修改fe/conf/fe.conf中的arrow_flight_sql_port为可用端口,例如9090。
# 修改be/conf/be.conf中的arrow_flight_port为可用端口,例如9091。
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# 通过SQL使用Cursor与Doris交互
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# 步骤3,执行DDL语句,创建数据库/表,显示语句。
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# 步骤4,插入数据
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# 步骤5,执行查询,聚合,排序,设置会话变量
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# 步骤6,关闭Cursor
cursor.close()大规模数据传输示例
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# ADBC Driver Manager的PEP 249(DB-API 2.0)API包装器。
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC将数据读入pandas dataframe,比先fetchallarrow再to_pandas更快。
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# 可并行读取多个分区。
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
使用此驱动程序与使用MySQL协议的驱动程序类似。只需将连接URL中的jdbc:mysql替换为jdbc:arrow-flight-sql。返回的结果将以JDBC ResultSet数据结构呈现。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// 方法一
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery,分两步:
// 1. 执行查询并获取返回的FlightInfo;
// 2. 创建FlightInfoReader以顺序遍历每个Endpoint;
QueryResult queryResult = stmt.executeQuery()
// 方法二
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// 执行查询并解析FlightInfo中的每个Endpoint,利用Location和Ticket构建PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// 为每个PartitionDescriptor创建ArrowReader以读取数据
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
紧跟潮流趋势
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow