













لسنوات عديدة، تم اعتماد JDBC و ODBC كمعايير شائعة للتفاعل مع القواعد البيانات. الآن، وننظر إلى المجال الواسع للبيانات، نشأة علم البيانات وتحليل بحيرة البيانات يجلب مجموعات بيانات أكبر وأكبر. وعلى التوالي، نحتاج إلى قراءة ونقل البيانات أسرع وأسرع، لذا نبدأ في البحث عن إجابات أفضل من JDBC و ODBC. وهكذا، ندرج بروتوكول Arrow Flight SQL في أباتشي دوريس 2.1، الذي يوفر تسعين مرة من تحسين السرعة في نقل البيانات.
نقل البيانات عالي السرعة مبني على Arrow Flight SQL
كمخزن بيانات عمودي، يرتب أباتشي دوريس نتائج الاستعلام بصيغة عناقيد بيانات في شكل عمودي. قبل الإصدار 2.1، يجب تجميع الكتل إلى بايتات بصيغة تتبع الصف قبل نقلها إلى العميل المستهدف عبر عميل MySQL أو برنامج تحكم JDBC/ODBC. علاوة على ذلك، إذا كان العميل المستهدف قاعدة بيانات عمودية أو مكون علم البيانات تتبع العمود مثل بانداس، يجب تحليل البيانات. عملية التجميع والتحليل تمثل عقبة سرعة في نقل البيانات.
أباتشي دوريس 2.1 يحتوي على وصلة نقل البيانات بناءً على Arrow Flight SQL. (أباتشي آررو هو منصة تطوير البرامج مصممة لتحسين كفاءة نقل البيانات بشكل عالٍ عبر الأنظمة واللغات، وتهدف تنسيق آررو إلى تبادل بيانات عالية الأداء بدون فقدان.) ويسمح بقراءة البيانات الكبيرة الحجم بسرعة عالية من دوريس عبر SQL في اللغات الشائعة المختلفة. بالنسبة للعملاء الهدف الذين يدعمون أيضًا تنسيق آررو، سيكون العملية بأكملها خالية من التحويل التسلسلي/التحويل التسلسلي العكسي، وبالتالي لا يوجد فقدان في الأداء. كميزة أخرى، يمكن لـ Arrow Flight الاستفادة الكاملة من هيكل العقد المتعدد والأبعاد المتعددة وتنفيذ نقل البيانات الموازي، وهو محفز آخر لتسريع سرعة البيانات.
على سبيل المثال، إذا قرأ عميل Python البيانات من أباتشي دوريس، سيقوم دوريس أولاً بتحويل الكتل الموجهة للأعمدة إلى Arrow RecordBatch. ثم في عميل Python، سيتم تحويل Arrow RecordBatch إلى Pandas DataFrame. كلا التحويلين سريع لأن الكتل الموجهة للأعمدة بدوريس، Arrow RecordBatch، و Pandas DataFrame كلها موجهة للأعمدة.
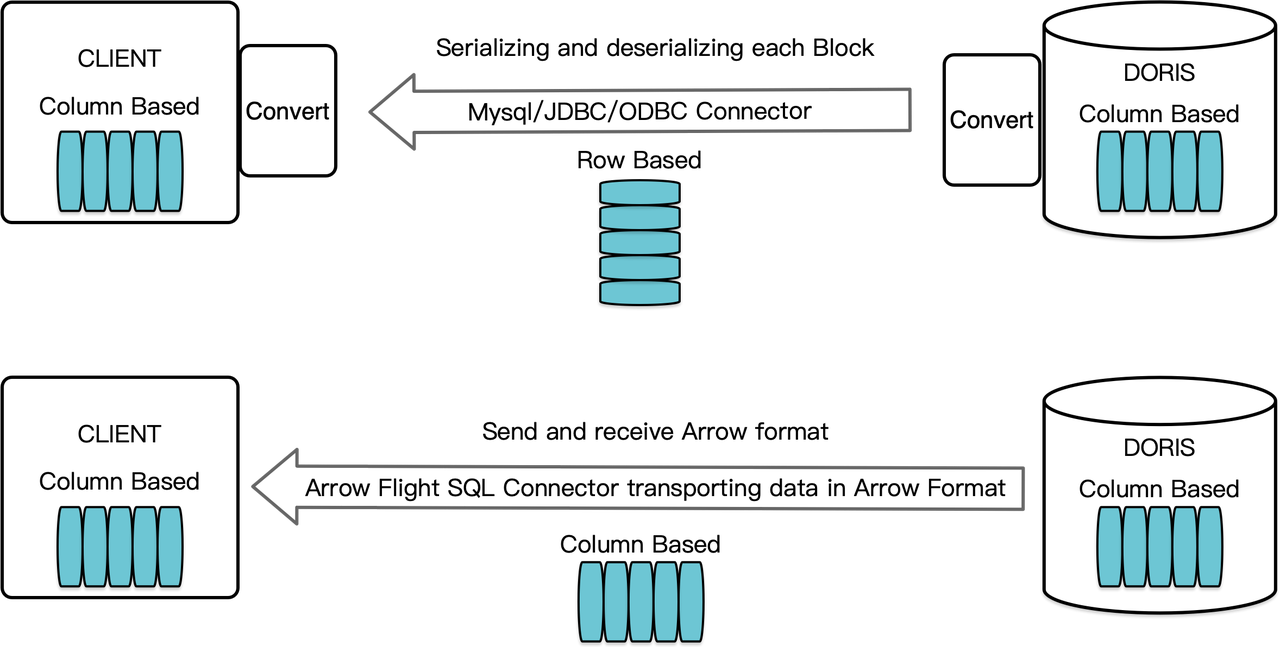
بالإضافة إلى ذلك، يوفر Arrow Flight SQL برنامج تشغيل JDBC عام لتسهيل التواصل السلس بين قواعد البيانات التي تدعم протокол Arrow Flight SQL. وهذا يحرر إمكانات دوريس للتواصل مع مجتمع أكبر واستخدامه في حالات أكثر.
اختبار الأداء
استنادًا إلى نتائج اختبارات المعيار التي أجريناها، وصلنا إلى استنتاج “تسعين مرة السرعة”. جربنا قراءة البيانات من Doris باستخدام PyMySQL وPandas وArrow Flight SQL، وسجلنا مدد الزمن على التوالي. بيانات الاختبار هي مجموعة ClickBench.

النتائج على أنواع البيانات المختلفة كما يلي:
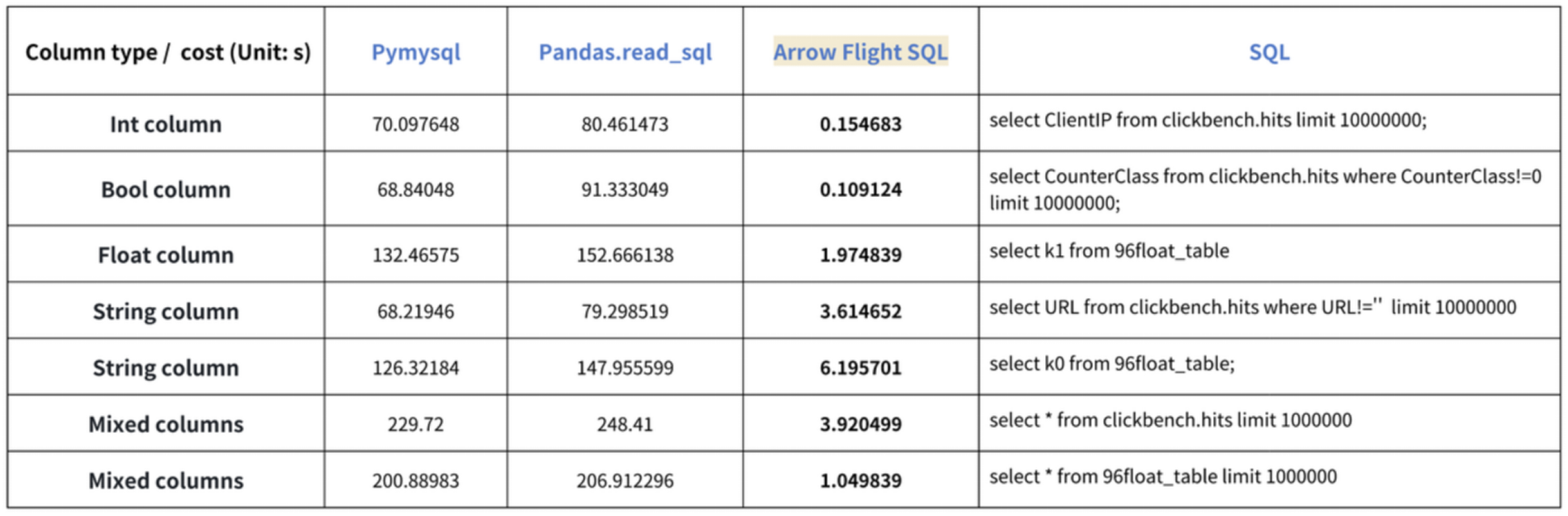
كما هو موضح، يتفوق Arrow Flight SQL على PyMySQL وPandas في جميع أنواع البيانات بعامل تتراوح بين 20 وعدد مئات.
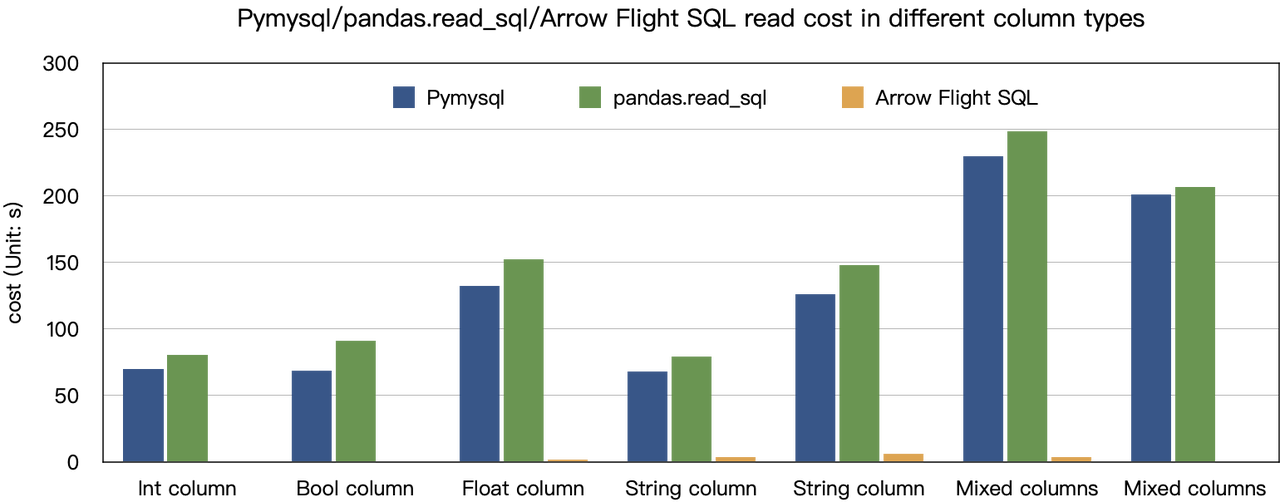
الاستخدام
بدعم Arrow Flight SQL، يمكن لـ Apache Doris الاستفادة من برنامج تشغيل Python ADBC لقراءة البيانات بسرعة. سأقوم بعرض بعض عمليات القواعد البيانية التي يتم تنفيذها بشكل متكرر باستخدام برنامج تشغيل Python ADBC (إصدار 3.9 أو أحدث)، بما في ذلك DDL وDML وتعيين متغيرات الجلسة وعبارات show.
1. تثبيت المكتبة
تم نشر المكتبة المعنية على PyPI. يمكن تثبيتها ببساطة كما يلي:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlاستيراد الوحدة/المكتبة التالية للتفاعل مع المكتبة المثبتة:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. الاتصال بـ Doris
إنشاء عميل للتفاعل مع خدمة Doris Arrow Flight SQL. الشروط الأساسية تشمل مضيف FE (frontend) Doris ومنفذ Arrow Flight واسم المستخدم/كلمة المرور للدخول.
تكوين المعلمات لمضيف FE (frontend) وBE (backend) Doris:
- في
fe/conf/fe.conf، تعيينarrow_flight_sql_portإلى منفذ متاح، مثل 9090. - في
be/conf/be.conf، تعيينarrow_flight_portإلى منفذ متاح، مثل 9091.
افترض أن خدمات SQL لـ Arrow Flight للمثيل Doris ستعمل على المنافذ 9090 و 9091 لـ FE و BE على التوالي، واسم المستخدم/كلمة المرور في Doris هما “user” و “pass”، سيكون عملية الاتصال كما يلي:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. إنشاء جدول واسترداد البيانات الوصفية
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. تحميل البيانات
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. تنفيذ الاستعلامات
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. اكتمال الكود
# اختبار SQL لـ Doris Arrow Flight
# الخطوة 1، المكتبة متاحة على PyPI ويمكن تثبيتها بسهولة.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# الخطوة 2، إنشاء عميل يتفاعل مع خدمة Doris Arrow Flight SQL.
# تعديل arrow_flight_sql_port في fe/conf/fe.conf إلى منفذ متاح، مثل 9090.
# تعديل arrow_flight_port في be/conf/be.conf إلى منفذ متاح، مثل 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# التفاعل مع Doris عبر SQL باستخدام Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# الخطوة 3، تنفيذ عبارات DDL، إنشاء قاعدة بيانات/جدول، عرض العبارة.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# الخطوة 4، إدراج في
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# الخطوة 5، تنفيذ الاستعلامات، التجميع، الفرز، تعيين متغير الجلسة
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# الخطوة 6، إغلاق Cursor
cursor.close()أمثلة على نقل البيانات على نطاق واسع
1. بايثون
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# WRAPPER API لـ PEP 249 (DB-API 2.0) لإدارة السائق ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC يقرأ البيانات إلى إطار بيانات pandas، وهو أسرع من fetchallarrow ثم to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# يمكن قراءة قوائم متعددة في التوازي.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
استخدام هذا السائق مشابه لاستخدامه مع بروتوكول MySQL. تحتاج فقط لاستبدال jdbc:mysql في عنوان URL الاتصال بـ jdbc:arrow-flight-sql. ستكون النتيجة المرتجعة في بنية البيانات JDBC ResultSet.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// طريقة واحدة
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery، خطوتين:
// 1. تنفيذ الاستعلام والحصول على FlightInfo المرتجعة;
// 2. إنشاء FlightInfoReader للتنقل بالتتابع في كل Endpoint;
QueryResult queryResult = stmt.executeQuery()
// طريقة الثانية
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// تنفيذ الاستعلام وتحليل كل Endpoint في FlightInfo، واستخدام الموقع والتذكرة لبناء PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// إنشاء ArrowReader لكل PartitionDescriptor لقراءة البيانات
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
انضم إلى قطار الاتجاهات
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow