













Seit Jahren sind JDBC und ODBC weit verbreitete Normen für die Interaktion mit Datenbanken. Nun, wenn wir auf die unermessliche Weite des Datenbereichs blicken, bringen der Aufstieg der Data-Science und die Analyse von Data-Lakes immer größere Datensätze mit sich. Entsprechend benötigen wir schnellere und schnellere Datenlesung und -übertragung, weshalb wir nach besseren Lösungen als JDBC und ODBC suchen. Daher integrieren wir das Arrow Flight SQL-Protokoll in Apache Doris 2.1, das eine Steigerung der Datenübertragungsgeschwindigkeit um ein Vielfaches ermöglicht.
Hochgeschwindigkeits-Datenübertragung basierend auf Arrow Flight SQL
Als ein Spalten-orientiertes Data-Warehouse arrangiert Apache Doris seine Abfrageergebnisse in Form von Datenblöcken im spaltenbasierten Format. Vor Version 2.1 mussten die Blöcke vor ihrer Übertragung an ein Ziel-Client über einen MySQL-Client oder JDBC/ODBC-Treiber zunächst in zeilenorientierten Formaten serialisiert werden. Darüber hinaus, wenn der Ziel-Client eine spaltenorientierte Datenbank oder ein spaltenbasiertes Data-Science-Komponente wie Pandas ist, müssen die Daten anschließend de-serialisiert werden. Der Serialisierungs-De-Serialisierungs-Prozess stellt eine Geschwindigkeitsbegrenzung für die Datenübertragung dar.
Apache Doris 2.1 verfügt über einen Datenübertragungskanal, der auf Arrow Flight SQL basiert. (Apache Arrow ist eine Softwareentwicklungsplattform, die für eine hohe Datenübertragungseffizienz zwischen Systemen und Sprachen entwickelt wurde, und das Arrow-Format zielt auf eine hochleistungsfähige, verlustfreie Datenaustausch.) Es ermöglicht die hochgeschwindigkeitsmäßige, großskalige Datenlesung aus Doris über SQL in verschiedenen etablierten Programmiersprachen. Für Zielclients, die ebenfalls das Arrow-Format unterstützen, wird der gesamte Prozess frei von Serialisierung/Deserialisierung sein, wodurch kein Leistungsverlust auftritt. Ein weiterer Vorteil ist, dass Arrow Flight die Vorteile von Multinode- und Multikernarchitekturen voll ausschöpfen und parallele Datenübertragung implementieren kann, was ein weiterer Treiber für hohe Datendurchsatz ist.
Zum Beispiel, wenn ein Python-Client Daten aus Apache Doris liest, wird Doris zunächst die blockorientierten Blöcke in Arrow RecordBatch konvertieren. Anschließend wird im Python-Client der Arrow RecordBatch in Pandas DataFrame konvertiert. Beide Konvertierungen sind schnell, da die Doris-Blöcke, der Arrow RecordBatch und der Pandas DataFrame alle blockorientiert sind.
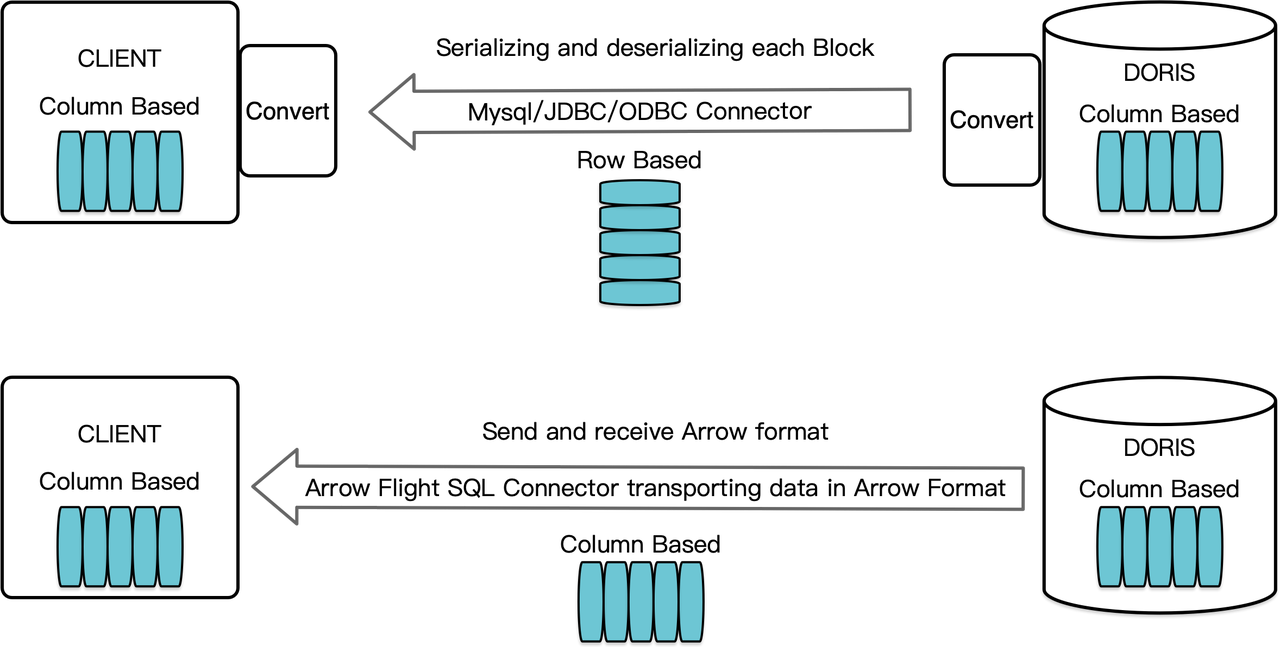
Darüber hinaus bietet Arrow Flight SQL einen allgemeinen JDBC-Treiber, um nahtlose Kommunikation zwischen Datenbanken zu ermöglichen, die das Arrow Flight SQL-Protokoll unterstützen. Dies erschließt das Potenzial von Doris, an ein breiteres Ökosystem angeschlossen zu werden und in mehr Anwendungsfällen eingesetzt zu werden.
Leistungstest
Das „zehnfache Beschleunigung“ Ergebnis basiert auf unseren Benchmarks. Wir haben versucht, Daten aus Doris mit PyMySQL, Pandas und Arrow Flight SQL zu lesen und die Dauern entsprechend aufgeschrieben. Das Testdaten-Set ist ClickBench.

Die Ergebnisse für verschiedene Datentypen sind wie folgt:
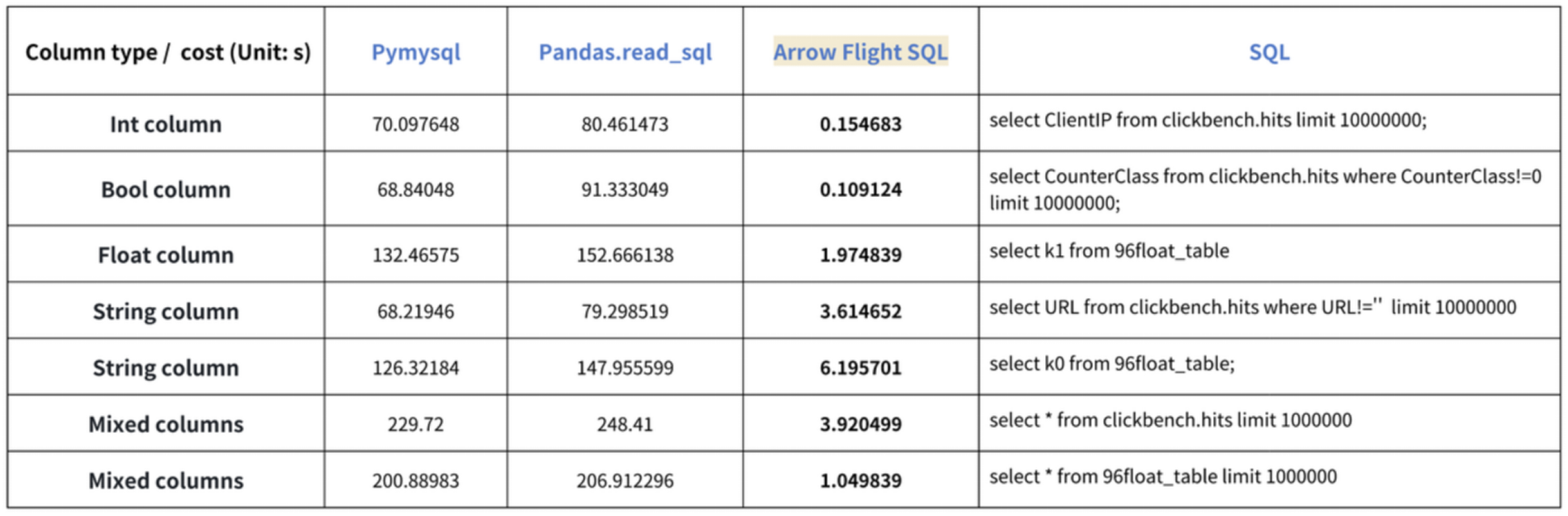
Wie zu sehen ist, übertrifft Arrow Flight SQL PyMySQL und Pandas bei allen Datentypen um einen Faktor von 20 bis zu mehreren hundert.
Verwendung
Mit Unterstützung für Arrow Flight SQL kann Apache Doris die Python ADBC Treiber für schnelles Datenlesen nutzen. Ich werde einige häufig ausgeführte Datenbankoperationen mit dem Python ADBC Treiber (Version 3.9 oder später) zeigen, einschließlich DDL, DML, Sitzungsvariablen-Einstellung und show Anweisungen.
1. Bibliothek installieren
Die entsprechende Bibliothek ist bereits auf PyPI veröffentlicht. Sie kann einfach wie folgt installiert werden:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImportieren Sie das folgende Modul/die Bibliothek, um mit der installierten Bibliothek zu interagieren:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Mit Doris verbinden
Erstellen Sie einen Client für die Interaktion mit dem Doris Arrow Flight SQL Service. Voraussetzungen sind der Doris-Frontend (FE) Host, der Arrow Flight Port und der Login-Benutzername/Kennwort.
Konfigurieren Sie die Parameter für das Doris-Frontend (FE) und Backend (BE):
- In
fe/conf/fe.confsetzen Siearrow_flight_sql_portauf einen verfügbaren Port, wie z.B. 9090. - In
be/conf/be.confsetzen Siearrow_flight_portauf einen verfügbaren Port, wie z.B. 9091.
Angenommen, die Arrow Flight SQL-Dienste für die Doris-Instanz laufen auf den Ports 9090 und 9091 für FE und BE entsprechend, und der Doris-Benutzername/Passwort ist „user“ und „pass“, wäre der Verbindungsprozess wie folgt:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Tabellenerstellung und Abrufen von Metadaten
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Datenaufnahme
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Abfrageausführung
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Abschließender Code
# Doris Arrow Flight SQL Test
# Schritt 1, die Bibliothek ist auf PyPI veröffentlicht und kann leicht installiert werden.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# Schritt 2, Erstellung eines Clients, der mit dem Doris Arrow Flight SQL-Dienst interagiert.
# Ändern Sie arrow_flight_sql_port in fe/conf/fe.conf in einen verfügbaren Port, z.B. 9090.
# Ändern Sie arrow_flight_port in be/conf/be.conf in einen verfügbaren Port, z.B. 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# Interaktion mit Doris über SQL mit Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# Schritt3, Ausführung von DDL-Anweisungen, Erstellung von Datenbank/Tabelle, Zeige Anweisung.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# Schritt4, Einfügen in
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# Schritt5, Ausführung von Abfragen, Aggregation, Sortierung, Sitzungsvariable setzen
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# Schritt6, Cursor schließen
cursor.close()Beispiele für Datenübertragung im Großmaßstab
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# PEP 249 (DB-API 2.0) API-Wrapper für den ADBC Driver Manager.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC liest Daten in pandas DataFrame, was schneller ist als fetchallarrow zuerst und dann to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Kann mehrere Partitionen parallel lesen.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
Die Verwendung dieses Treibers ähnelt der Verwendung für das MySQL-Protokoll. Sie müssen lediglich jdbc:mysql in der Verbindungs-URL durch jdbc:arrow-flight-sql ersetzen. Das zurückgegebene Ergebnis wird in der JDBC ResultSet-Datenstruktur sein.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// Methode eins
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, zwei Schritte:
// 1. Abfrage ausführen und zurückgegebene FlightInfo erhalten;
// 2. FlightInfoReader erstellen, um jeden Endpunkt sequentiell zu durchlaufen;
QueryResult queryResult = stmt.executeQuery()
// Methode zwei
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Abfrage ausführen und jeden Endpunkt in FlightInfo analysieren, und die Location und Ticket verwenden, um ein PartitionDescriptor zu konstruieren
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// ArrowReader für jedes PartitionDescriptor erstellen, um Daten zu lesen
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Mit dem Trendzug fahren
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow