













למרות שבמשך שנים, JDBC ו-ODBC היו הנורמות הנפוצות לאינטראקציה עם מסדי נתונים, כיום, כשאנו מביטים במרחב העצום של ממלכת הנתונים, העליה במדעי הנתונים וניתוחי ערימת הנתונים מביאה לנו קבצי נתונים גדולים יותר ויותר. בהתאמה, אנו זקוקים לקריאת נתונים והעברתם מהירים יותר, ולכן אנו מחפשים תשובות טובות יותר מאשר JDBC ו-ODBC. כתוצאה מכך, אנו מכלילים את פרוטוקול Arrow Flight SQL ב-Apache Doris 2.1, שמספק עידודים של עשרות פקטורים להעברת נתונים.
העברת נתונים מהירה מבוססת Arrow Flight SQL
ככברת מידע מבוססת עמודות, Apache Doris מסדרת את תוצאות השאילתה בצורה של בלוקים נתונים בפורמט עמודתי. לפני גרסה 2.1, הבלוקים מושלכים לתבניות בפורמט עמודות כדי שיוכלו להעבר ללקוח יעד דרך לקוח MySQL או נהג JDBC/ODBC. יתרה מכך, אם הלקוח היעד הוא מסד נתונים עמודתי או רכיב מדעי הנתונים עמודתי כמו Pandas, הנתונים יש להפוך אותם מחדש. תהליך הסידור והפיכת הסידור הוא מכשול בהעברת הנתונים.
Apache Doris 2.1 מציעה ערוץ מעבר נתונים שמבוסס על Arrow Flight SQL. (Apache Arrow הוא פלטפורמת פיתוח תוכנה שתוכננה לשיגור נתונים ביעילות גבוהה בין מערכות ושפות, ופורמט Arrow מטרתו היא מיחסרון במידה מקסימלית והחלפת נתונים ביעילות גבוהה.) הוא מאפשר קריאת נתונים גדולה ומהירה מ-Doris באמצעות SQL בשפות תכנות רווחות. עבור לקוחות יעד שגם הם תומכים בפורמט Arrow, כל התהליך יהיה חסר שלבי המחשה/המחשה הפוכה, ולכן לא תהיה הפסדי ביצועים. עוד יתרון הוא ש-Arrow Flight יכול להשתמש לחלוטין בארכיטקטורת מרובת צמתים ומרובת תאים וליישם העברת נתונים מקבילית, מה שהופך אותו למניע נוסף לעבודה בזרימת נתונים גבוהה.
לדוגמה, אם לקוח Python קורא נתונים מ-Apache Doris, Doris ימיר תחילה את הבלוקים מסוג בלוקים מכוונים לעמודות ל-Arrow RecordBatch. לאחר מכן, בלקוח Python, Arrow RecordBatch ימיר ל-Pandas DataFrame. שתי ההמרות מהירות מכיוון שהבלוקים של Doris, Arrow RecordBatch ו-Pandas DataFrame כולם מכוונים לעמודות.
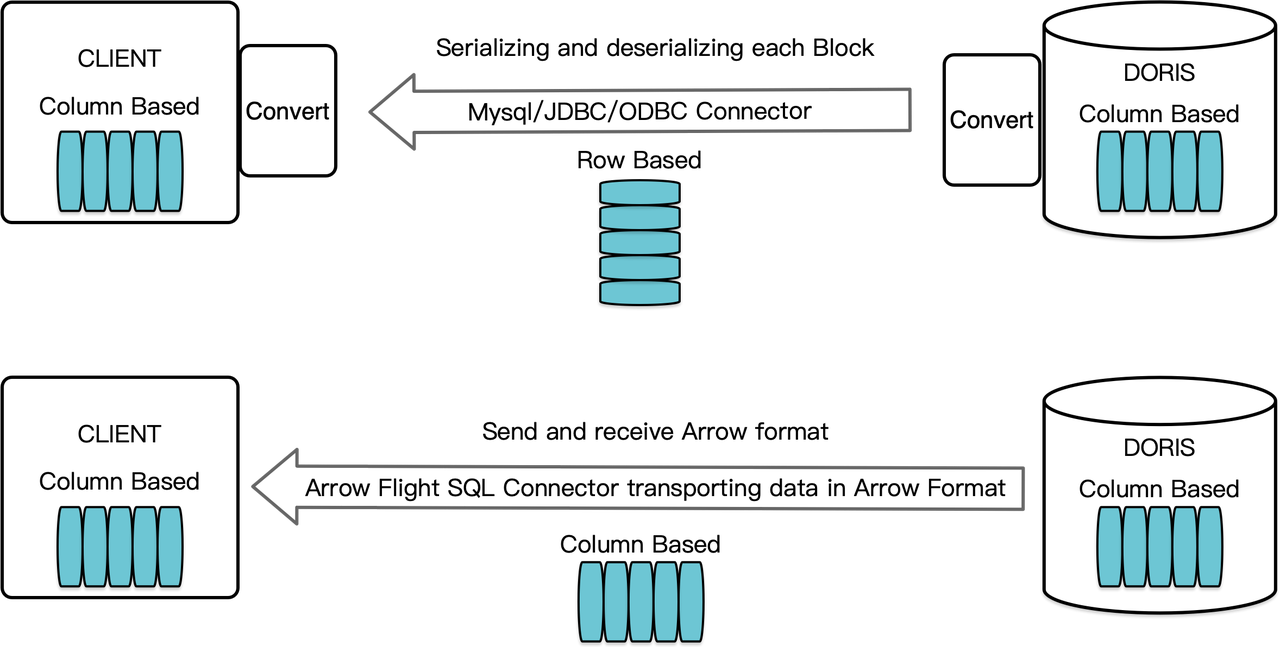
בנוסף, Arrow Flight SQL מספק כלי נהלים כללי JDBC כדי לקלות בתקשורת חלופית בין מסדי נתונים התומכים בפרוטוקול Arrow Flight SQL. זה משחרר את הפוטנציאל של Doris לחיבור לסביבה רחבה יותר ושימוש במקרים רבים יותר.
בדיקת ביצועים
מסקנת ה"הגברה עשרות כפולות במהירות" מבוססת על בדיקות הבנק שלנו. ניסינו לקרוא נתונים מדוריס באמצעות PyMySQL, Pandas ו-Arrow Flight SQL, ורשמנו את משך הזמן בהתאמה. נתוני המבחן הם מאגר ClickBench.

התוצאות על סוגי נתונים שונים הם כדלקמן:
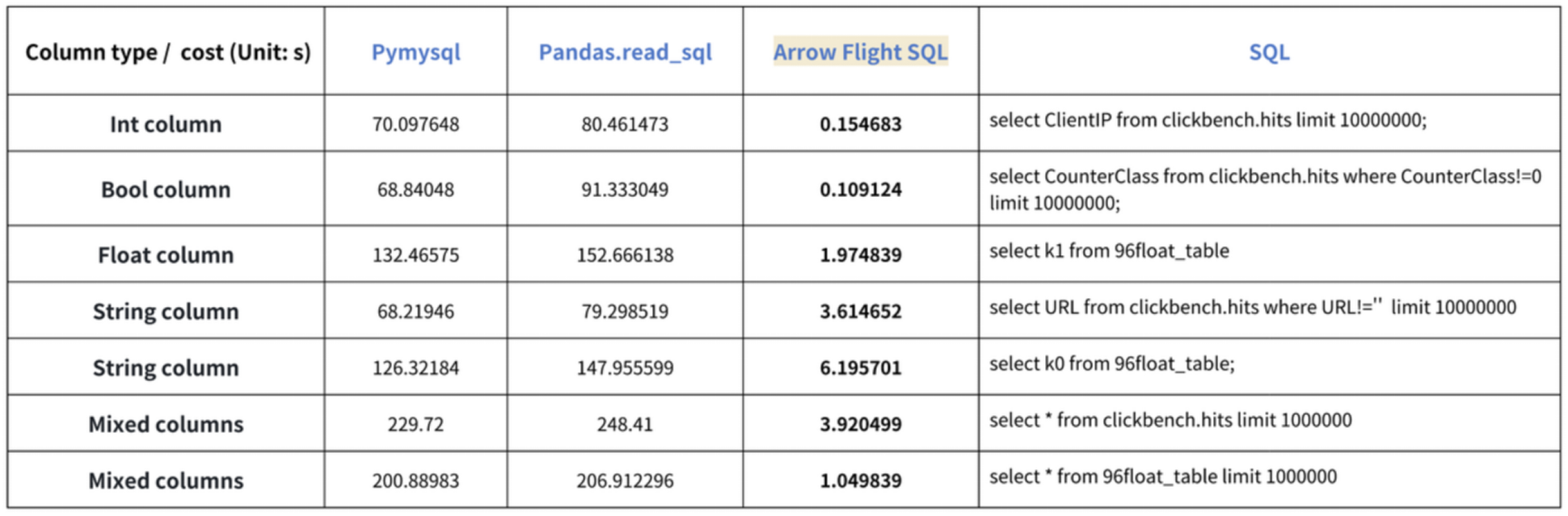
כפי שניתן לראות, Arrow Flight SQL עולה על PyMySQL ו-Pandas בכל סוגי הנתונים בגורם הנע בין 20 לכמה מאות.
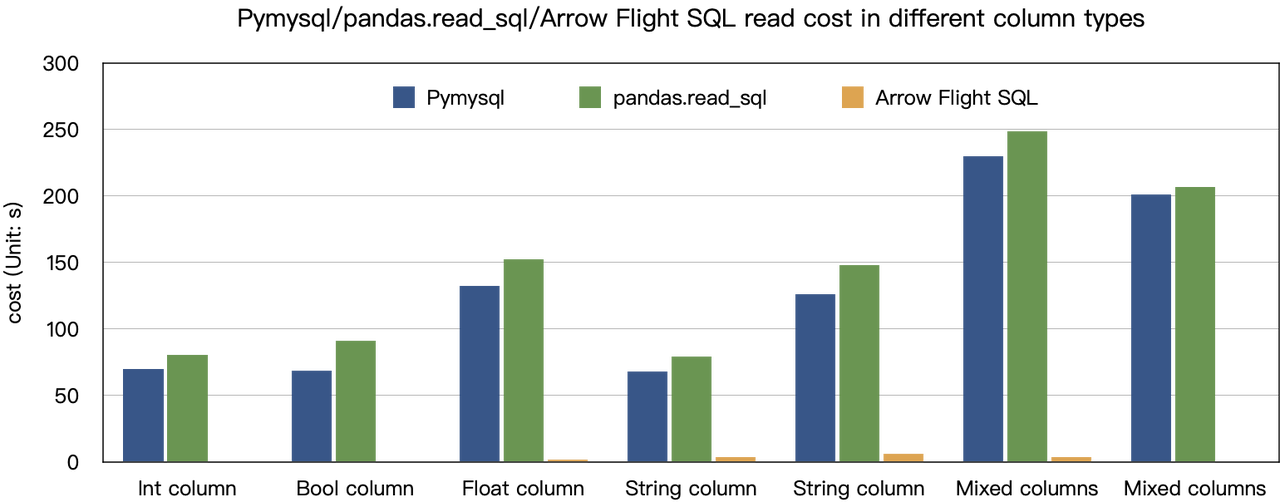
שימוש
בעזרת התמיכה ב-Arrow Flight SQL, Apache Doris יכולה לנצל את נהל הרוכש Python ADBC לקריאת נתונים מהירה. אציג כמה פעולות מ敎ריבליות שמבוצעות לעתים קרובות באמצעות נהל הרוכש ה-Python ADBC (גרסה 3.9 ומעלה), כולל DDL, DML, הגדרת משתני מסחר, ופקודות show.
1. התקנת ספרייה
הספרייה הרלוונטית כבר פורסמה ב-PyPI. ניתן להתקין אותה בקלות כך:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlהיכנס למודול/ספרייה הבאים כדי לתקשר עם הספרייה המותקנת:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. חיבור לדוריס
צור לקוח כדי לתקשר עם שירות Doris Arrow Flight SQL. דרישות קדם כוללות כתובת שרת הקדם של Doris (FE), מספר פורט Arrow Flight ושם משתמש/סיסמה.
הגדר פרמטרים עבור שרת הקדם (FE) והאחורי (BE) של Doris:
- ב
fe/conf/fe.conf, הגדר אתarrow_flight_sql_portלפורט זמין, כגון 9090. - ב
be/conf/be.conf, הגדר אתarrow_flight_portלפורט זמין, כגון 9091.
נניח ששירותי SQL של Arrow Flight עבור המופע של Doris יפעלו בין ערכי 9090 ו-9091 לצד FE ו-BE בהתאמה, וששם המשתמש והסיסמא של Doris הם "user" ו-"pass", התהליך הקשור לחיבור יהיה:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. יצירת טבלה והשגת מטמונית
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. הכנסת נתונים
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. ביצוע שאילתות
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. סיום הקוד
# בדיקת SQL של Doris Arrow Flight
# שלב 1, הספרייה משוחררת ב-PyPI וניתן להתקין אותה בקלות.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# שלב 2, יצירת לקוח שמתקשר עם שירות Doris Arrow Flight SQL.
# שינוי של arrow_flight_sql_port ב-fe/conf/fe.conf לפורט זמין, כגון 9090.
# שינוי של arrow_flight_port ב-be/conf/be.conf לפורט זמין, כגון 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# אינטראקציה עם Doris באמצעות SQL באמצעות עמוד החיצוני
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# שלב 3, ביצוע הצהרות DDL, יצירת מסד נתונים/טבלה, הצגת הצהרה.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# שלב 4, הכנסה
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# שלב 5, ביצוע שאילתות, אינגרציה, סידור, הגדרת משתנה של מסגרת
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# שלב 6, סגירת עמוד החיצוני
cursor.close()דוגמאות להעברת נתונים בקנה מידה
1. פייתון
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here's how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# WRAPPER API של PEP 249 (DB-API 2.0) עבור מנהל הדרייברים ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC קורא נתונים לתבנית נתונים של pandas, מהר יותר מאשר fetchallarrow ראשון ולאחר מכן to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# יכול לקרוא מספר חלוניות במקביל.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
שימוש בדרייקר זה דומה לשימוש בדרייקר עבור פרוטוקול MySQL. אתה רק צריך להחליף את jdbc:mysql בכתובת החיבור ב-URL ב- jdbc:arrow-flight-sql. התוצאה שתחזור תהיה במבנה הנתונים JDBC ResultSet.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// שיטה אחת
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, שני שלבים:
// 1. ביצוע שאילתה וקבלת החזרת FlightInfo;
// 2. יצירת FlightInfoReader לעבור בצורה רצופה על כל Endpoint;
QueryResult queryResult = stmt.executeQuery()
// שיטה שתיים
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// ביצוע שאילתה וניתוח כל Endpoint ב-FlightInfo, ושימוש במיקום וכרטיס ליצירת PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// יצירת ArrowReader לכל PartitionDescriptor לקרוא את הנתונים
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
קפוץ על רכבת המגמה
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That's high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow