













Durante años, JDBC y ODBC han sido normas comúnmente adoptadas para la interacción con bases de datos. Ahora, al contemplar la vasta extensión del ámbito de los datos, el auge de la ciencia de datos y el análisis de data lakes trae conjuntos de datos cada vez más grandes. En consecuencia, necesitamos lecturas y transmisiones de datos cada vez más rápidas, por lo que comenzamos a buscar mejores respuestas que JDBC y ODBC. Por ello, incluimos el protocolo Arrow Flight SQL en Apache Doris 2.1, que proporciona aceleraciones de decenas de veces en la transferencia de datos.
Transmisión de Datos de Alta Velocidad Basada en Arrow Flight SQL
Como almacén de datos orientado a columnas, Apache Doris organiza sus resultados de consulta en forma de Bloques de datos en formato columnar. Antes de la versión 2.1, los Bloques debían serializarse en bytes en formatos orientados a filas antes de poder transferirse a un cliente objetivo a través de un cliente MySQL o un controlador JDBC/ODBC. Además, si el cliente objetivo es una base de datos columnar o un componente de ciencia de datos orientado a columnas como Pandas, los datos deben entonces ser deserializados. El proceso de serialización-deserialización es un obstáculo para la transmisión de datos.
Apache Doris 2.1 cuenta con un canal de transmisión de datos construido sobre Arrow Flight SQL. (Apache Arrow es una plataforma de desarrollo de software diseñada para una alta eficiencia en la movilización de datos entre sistemas y lenguajes, y el formato Arrow busca una alta eficiencia en el intercambio de datos sin pérdidas). Permite la lectura de datos a gran velocidad y en gran escala desde Doris mediante SQL en varios lenguajes de programación principales. Para clientes de destino que también admiten el formato Arrow, todo el proceso estará libre de serialización/deserialización, por lo que no habrá pérdida de rendimiento. Otra ventaja es que Arrow Flight puede aprovechar al máximo la arquitectura multinodo y multicore e implementar la transferencia de datos en paralelo, lo que es otro activador de alta tasa de transferencia de datos.
Por ejemplo, si un cliente Python lee datos de Apache Doris, Doris primero convertirá los Bloques orientados a columnas en RecordBatch de Arrow. Luego, en el cliente Python, RecordBatch de Arrow se convertirá en DataFrame de Pandas. Ambas conversiones son rápidas porque los Bloques de Doris, RecordBatch de Arrow y DataFrame de Pandas son todos orientados a columnas.
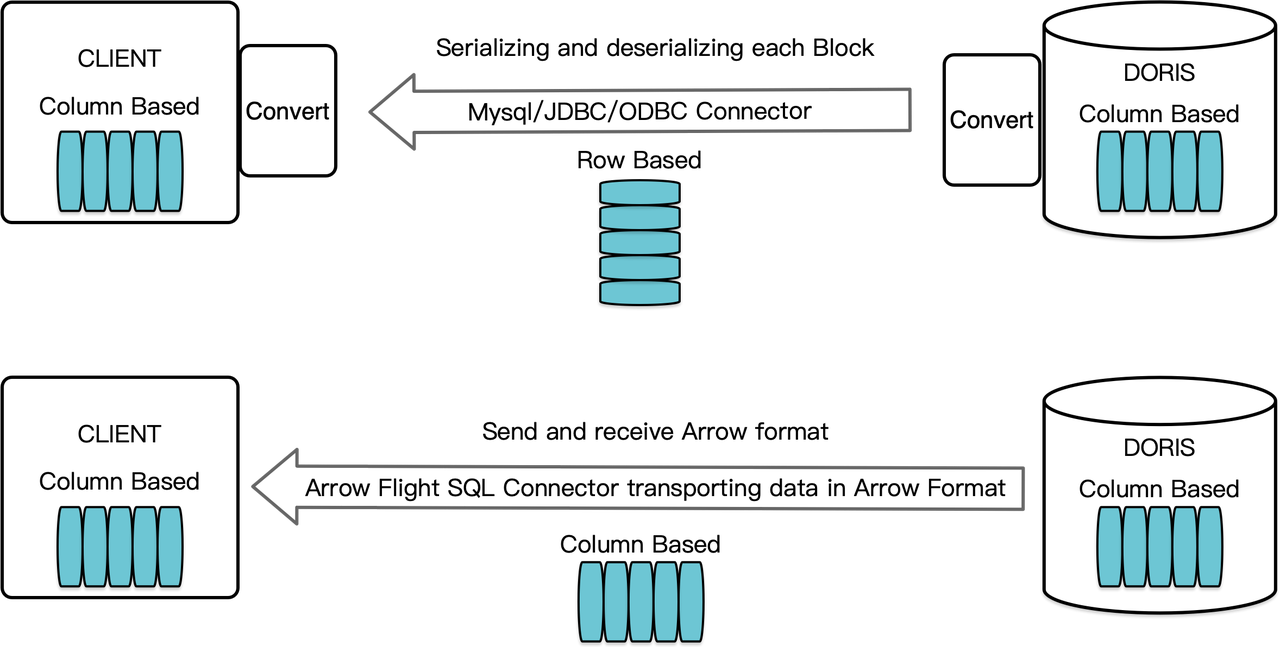
Además, Arrow Flight SQL proporciona un controlador JDBC general para facilitar la comunicación sin problemas entre bases de datos que admiten el protocolo Arrow Flight SQL. Esto desbloquea el potencial de Doris para conectarse a un ecosistema más amplio y ser utilizado en más casos.
Prueba de Rendimiento
La conclusión de “aceleraciones de diez veces” se basa en nuestras pruebas de referencia. Intentamos leer datos de Doris utilizando PyMySQL, Pandas y Arrow Flight SQL, y registramos los tiempos respectivamente. Los datos de prueba son el conjunto de datos ClickBench.

Los resultados en varios tipos de datos son los siguientes:
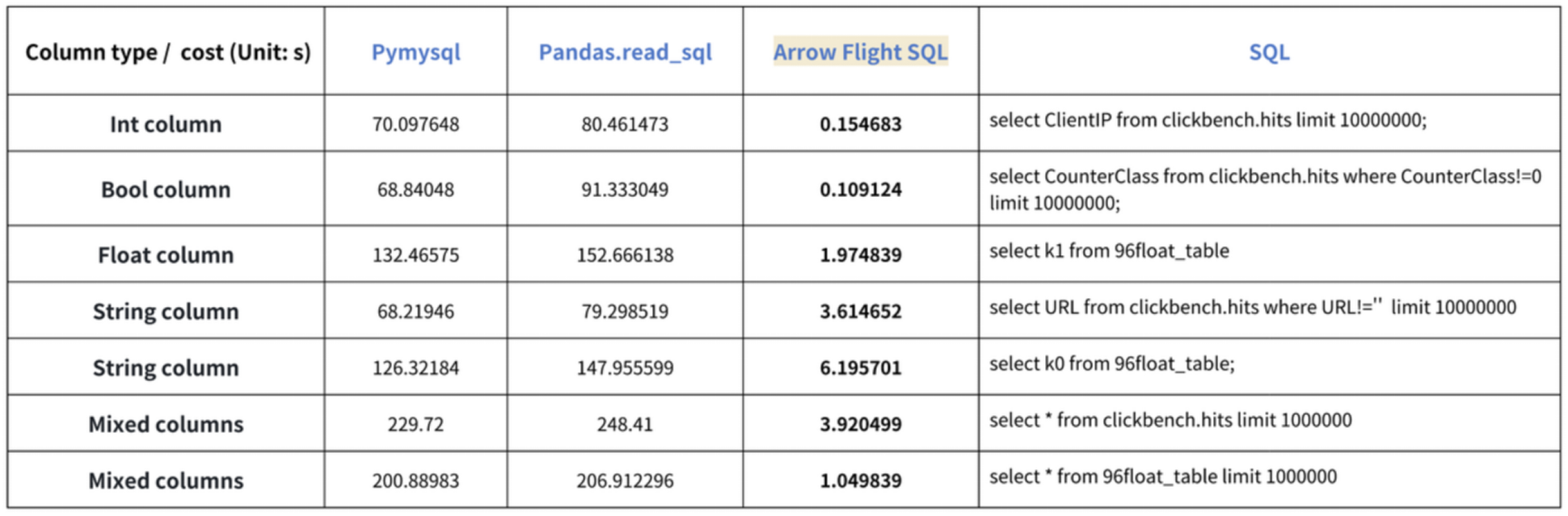
Como se muestra, Arrow Flight SQL supera a PyMySQL y Pandas en todos los tipos de datos por un factor que varía de 20 a varios cientos.
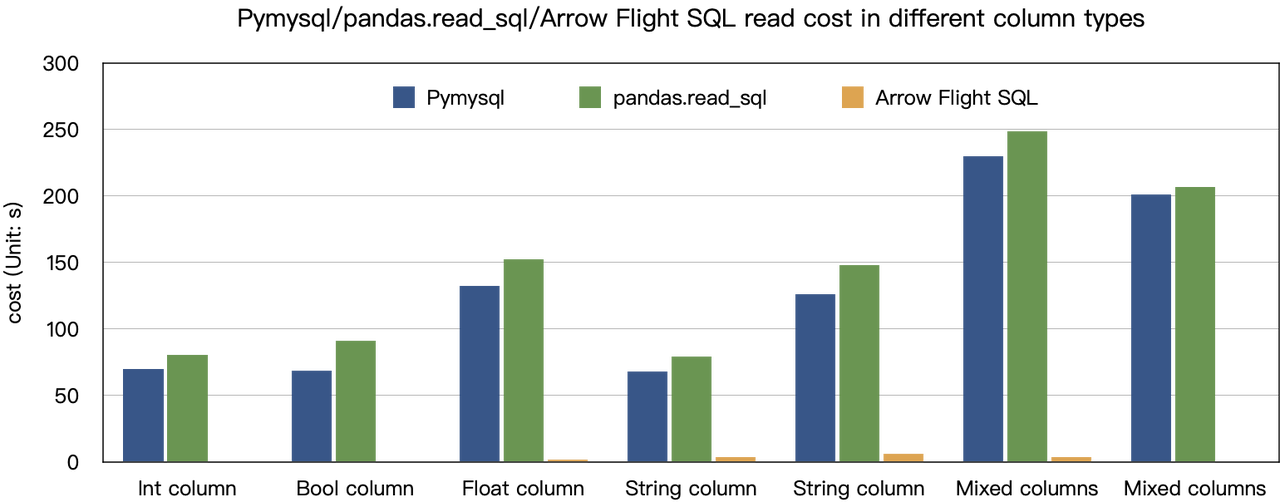
Uso
Con soporte para Arrow Flight SQL, Apache Doris puede aprovechar el Conductor ADBC de Python para leer datos rápidamente. Mostraré algunas operaciones de base de datos ejecutadas con frecuencia utilizando el Conductor ADBC de Python (versión 3.9 o posterior), incluidos DDL, DML, configuración de variables de sesión y show sentencias.
1. Instalar Biblioteca
La biblioteca relevante ya está publicada en PyPI. Puede instalarse simplemente de la siguiente manera:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImporte el siguiente módulo/biblioteca para interactuar con la biblioteca instalada:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Conectar a Doris
Cree un cliente para interactuar con el servicio Arrow Flight SQL de Doris. Los requisitos previos incluyen host frontal (FE) de Doris, puerto Arrow Flight y nombre de usuario/contraseña de inicio de sesión.
Configure parámetros para el frontal (FE) y el backend (BE) de Doris:
- En
fe/conf/fe.conf, establezcaarrow_flight_sql_porten un puerto disponible, como 9090. - En
be/conf/be.conf, establezcaarrow_flight_porten un puerto disponible, como 9091.
Supongamos que los servicios de SQL de Arrow Flight para la instancia de Doris se ejecutarán en los puertos 9090 y 9091 para FE y BE respectivamente, y el nombre de usuario/contraseña de Doris es “user” y “pass”, el proceso de conexión sería:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Crear una Tabla y Recuperar Metadatos
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Ingerir Datos
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Ejecutar Consultas
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Código Completo
# Prueba de Arrow Flight SQL de Doris
# paso 1, la biblioteca se publica en PyPI y se puede instalar fácilmente.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# paso 2, crear un cliente que interactúa con el servicio de Arrow Flight SQL de Doris.
# Modificar arrow_flight_sql_port en fe/conf/fe.conf a un puerto disponible, como 9090.
# Modificar arrow_flight_port en be/conf/be.conf a un puerto disponible, como 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interactuar con Doris a través de SQL usando Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# paso3, ejecutar declaraciones DDL, crear base de datos/tabla, mostrar stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# paso4, insertar en
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# paso5, ejecutar consultas, agregación, orden, establecer variable de sesión
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# paso6, cerrar cursor
cursor.close()Ejemplos de Transmisión de Datos a Gran Escala
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# Wrapper de la API PEP 249 (DB-API 2.0) para el Administrador de Controladores ADBC.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC lee datos en dataframe de pandas, lo que es más rápido que fetchallarrow primero y luego to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Puede leer múltiples particiones en paralelo.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
El uso de este controlador es similar al utilizado para el protocolo MySQL. Solo necesitas reemplazar jdbc:mysql en la URL de conexión con jdbc:arrow-flight-sql. El resultado devuelto estará en la estructura de datos ResultSet de JDBC.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// método uno
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, dos pasos:
// 1. Ejecutar consulta y obtener FlightInfo devuelto;
// 2. Crear FlightInfoReader para recorrer secuencialmente cada Endpoint;
QueryResult queryResult = stmt.executeQuery()
// método dos
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Ejecutar consulta y analizar cada Endpoint en FlightInfo, y usar la Localidad y el Billete para construir un PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// Crear ArrowReader para cada PartitionDescriptor para leer datos
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Subir al Tren de la Tendencia
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow