













Al jarenlang zijn JDBC en ODBC gemeengoedgeworden normen voor database-interactie. Nu, terwijl we naar het enorme uitgestrektheid van het data-domein kijken, brengt de opkomst van data science en data lake analytics steeds groter en groter datasets voort. Daarom hebben we steeds snellere data-lezing en -overdracht nodig, dus gaan we op zoek naar betere antwoorden dan JDBC en ODBC. Daarom voegen we het Arrow Flight SQL-protocol in Apache Doris 2.1 toe, wat snelheden voor dataoverdracht biedt die een tiental keren hoger zijn.
Hoge Snelheid Dataoverdracht Gebaseerd op Arrow Flight SQL
Als een kolomgeoriënteerde datawarehouse, rangschikt Apache Doris zijn queryresultaten in de vorm van data Blocks in een kolomformaat. Voor versie 2.1 moesten de Blocks eerst worden gedeserialiseerd in rij-georiënteerde formaten voordat ze konden worden overgedragen naar een doelclient via een MySQL-client of JDBC/ODBC-driver. Bovendien, als de doelclient een kolomdatabase of een kolomgeoriënteerde data science-component is zoals Pandas, moet de data vervolgens worden gedeserialiseerd. Het serialisatie-deserialisatieproces is een snelheidsremmer voor dataoverdracht.
Apache Doris 2.1 beschikt over een gegevensoverdrachtskanaal gebouwd op Arrow Flight SQL. (Apache Arrow is een softwareontwikkelingsplatform ontworpen voor hoge gegevensoverdrachtsefficiëntie tussen systemen en talen, en het Arrow-formaat is gericht op hoge-prestaties, verliesvrije gegevensuitwisseling.) Het maakt het mogelijk om snel en op grote schaal gegevens uit Doris te lezen via SQL in verschillende populaire programmeertalen. Voor doelclients die ook het Arrow-formaat ondersteunen, zal het hele proces vrij zijn van serialisatie/deserialisatie, waardoor er geen prestatieverlies optreedt. Een ander voordeel is dat Arrow Flight optimaal gebruik kan maken van een multi-node en multi-core architectuur en parallelle gegevensoverdracht kan implementeren, wat een andere stimulans is voor hoge gegevensdoorvoer.
Bijvoorbeeld, als een Python-client gegevens leest uit Apache Doris, zal Doris eerst de gerichte kolomblokken converteren naar Arrow RecordBatch. Vervolgens zal in de Python-client Arrow RecordBatch worden omgezet in een Pandas DataFrame. Beide conversies zijn snel omdat de Doris-blokken, Arrow RecordBatch en Pandas DataFrame allemaal kolomgericht zijn.
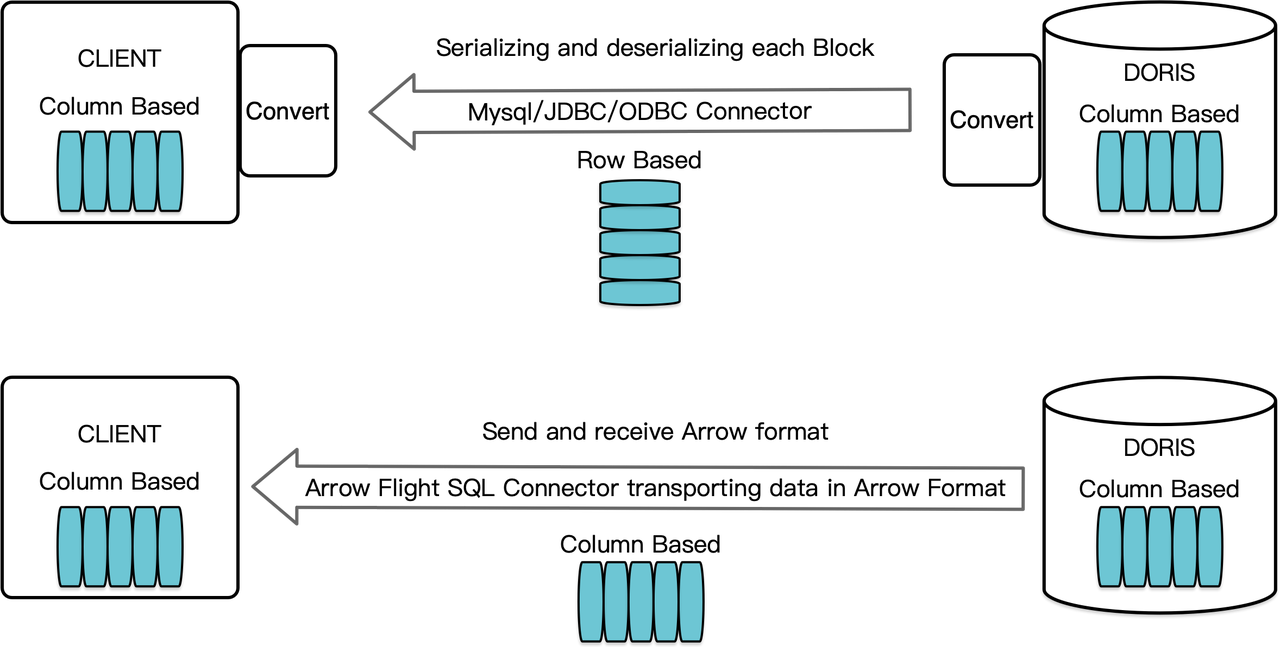
Daarnaast biedt Arrow Flight SQL een algemene JDBC-driver om soepele communicatie te faciliteren tussen databases die het Arrow Flight SQL-protocol ondersteunen. Dit stelt Doris in staat om verbinding te maken met een groter ecosysteem en in meer gevallen te worden gebruikt.
Prestatietest
De “tienduizendvoudige snelheidsverbeteringen” conclusie is gebaseerd op onze benchmarktests. We hebben geprobeerd gegevens uit Doris te lezen met behulp van PyMySQL, Pandas en Arrow Flight SQL, en de duur genoteerd, respectievelijk. De testgegevens zijn de ClickBench-dataset.

De resultaten voor verschillende gegevenstypen zijn als volgt:
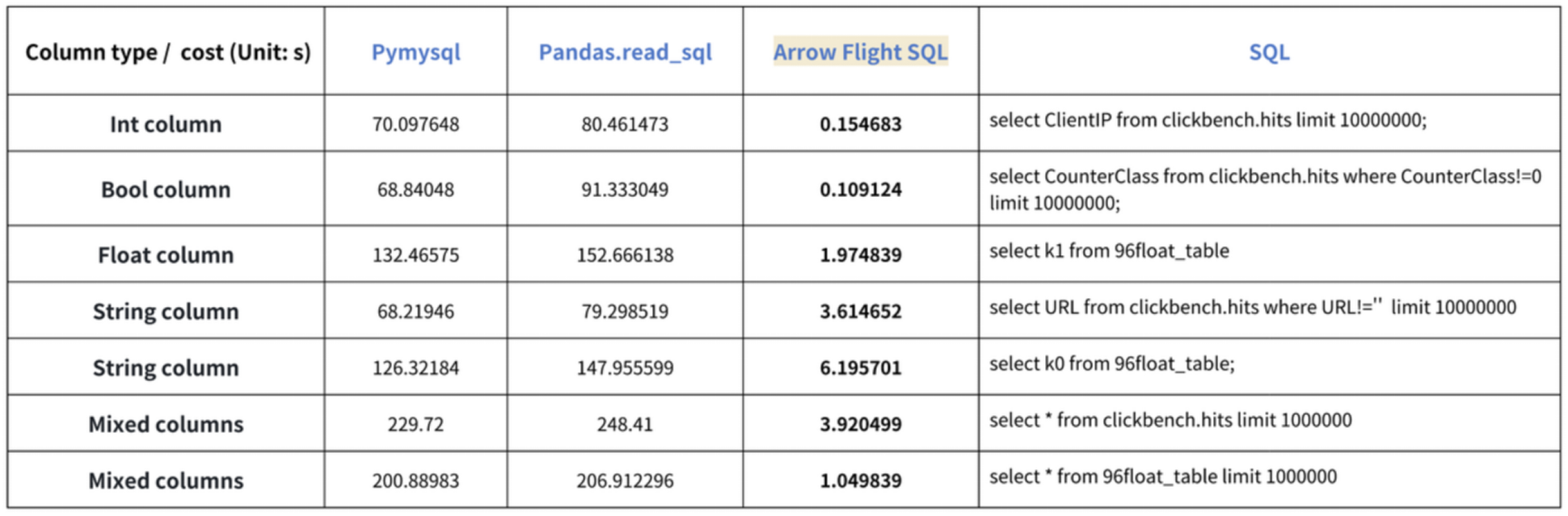
Zoals te zien is, overtreedt Arrow Flight SQL PyMySQL en Pandas op alle gegevenstypen met een factor variërend van 20 tot enkele honderden.
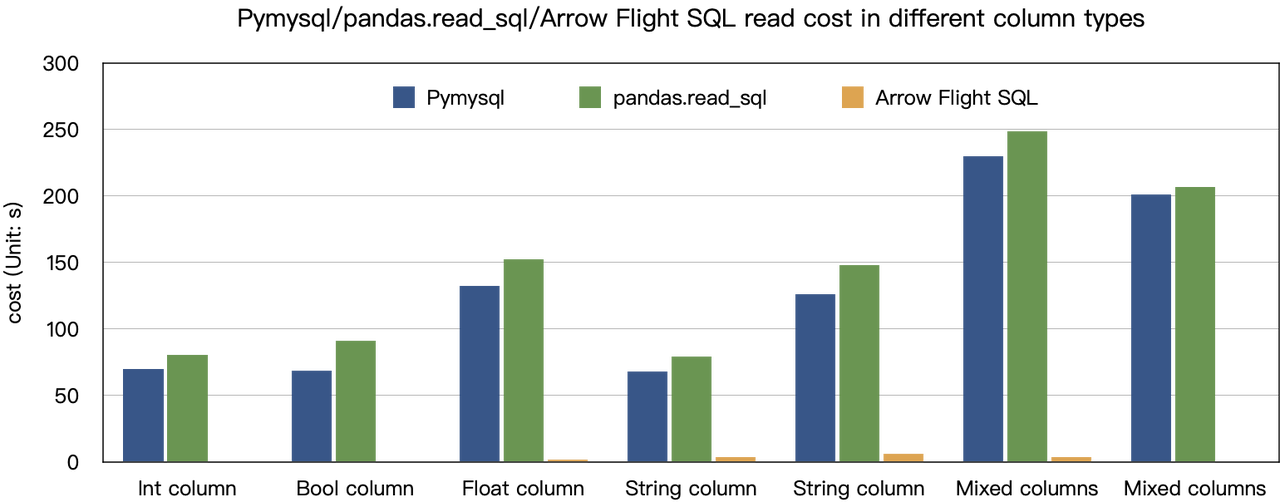
Gebruik
Met ondersteuning voor Arrow Flight SQL, kan Apache Doris de Python ADBC Driver gebruiken voor snelle gegevenslezing. Ik zal een aantal vaak uitgevoerde databasebewerkingen demonstreren met behulp van de Python ADBC Driver (versie 3.9 of hoger), inclusief DDL, DML, sessievariabele instellingen en show instructies.
1. Bibliotheek installeren
De relevante bibliotheek is al gepubliceerd op PyPI. Het kan eenvoudig worden geïnstalleerd als volgt:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImporteer de volgende module/bibliotheek om te communiceren met de geïnstalleerde bibliotheek:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Verbinding maken met Doris
Maak een client voor interactie met de Doris Arrow Flight SQL-service. Voorwaarden zijn Doris frontend (FE) host, Arrow Flight poort en login gebruikersnaam/wachtwoord.
Configureer parameters voor Doris frontend (FE) en backend (BE):
- In
fe/conf/fe.conf, stelarrow_flight_sql_portin op een beschikbare poort, zoals 9090. - In
be/conf/be.conf, stelarrow_flight_portin op een beschikbare poort, zoals 9091.
Stel dat de Arrow Flight SQL-services voor de Doris-instantie zullen draaien op poorten 9090 en 9091 voor respectievelijk FE en BE, en het Doris-gebruikersnaam/wachtwoord is “user” en “pass”, dan zou het aansluitingsproces zijn:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Een tabel maken en metadata ophalen
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Gegevens inslikken
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. Query’s uitvoeren
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Compleet code
# Doris Arrow Flight SQL Test
# stap 1, de bibliotheek is uitgebracht op PyPI en kan eenvoudig worden geïnstalleerd.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# stap 2, een client maken die interactie aangaat met de Doris Arrow Flight SQL-service.
# Wijzig arrow_flight_sql_port in fe/conf/fe.conf naar een beschikbare poort, zoals 9090.
# Wijzig arrow_flight_port in be/conf/be.conf naar een beschikbare poort, zoals 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interactie met Doris via SQL met behulp van Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# stap3, DDL-instructies uitvoeren, database/tabel maken, show stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# stap4, insert into
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# stap5, query's uitvoeren, aggregatie, sorteren, sessievariabele instellen
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# stap6, cursor sluiten
cursor.close()Voorbeelden van schaalbare gegevensoverdracht
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# PEP 249 (DB-API 2.0) API wrapper voor de ADBC Driver Manager.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC leest gegevens in een pandas dataframe, wat sneller is dan fetchallarrow eerst en vervolgens to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Kan meerdere partities parallel lezen.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
Het gebruik van deze driver is vergelijkbaar met het gebruik voor het MySQL-protocol. Je hoeft alleen jdbc:mysql in de verbindings-URL te vervangen door jdbc:arrow-flight-sql. Het teruggegeven resultaat zal zijn in de JDBC ResultSet-gegevensstructuur.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// methode één
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, twee stappen:
// 1. Voer Query uit en ontvang teruggegeven FlightInfo;
// 2. Creëer FlightInfoReader om elk Endpoint opeenvolgend te doorlopen;
QueryResult queryResult = stmt.executeQuery()
// methode twee
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Voer Query uit en parseer elk Endpoint in FlightInfo, en gebruik de Locatie en Ticket om een PartitionDescriptor te construeren
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// Creëer ArrowReader voor elke PartitionDescriptor om gegevens te lezen
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
Ga aan boord van de Trend Train
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow