













長年にわたり、JDBCとODBCはデータベースとのインタラクションにおいて一般的に採用されてきた規範であった。しかし、今やデータの世界が広がりを見せ、データサイエンスやデータ湖分析の台頭により、より大きなデータセットが登場している。それに応じて、より高速なデータの読み込みと伝送が求められるようになり、JDBCやODBCよりも優れた解決策を探し始める。そこで、Apache Doris 2.1にArrow Flight SQLプロトコルを取り入れ、データ転送の速度を数十倍に向上させる。
Arrow Flight SQLに基づく高速データ転送
列指向のデータ倉庫であるApache Dorisは、クエリ結果を列形式のデータブロックとして配置している。バージョン2.1以前では、ブロックはMySQLクライアントやJDBC/ODBCドライバを介して宛先クライアントに転送される前に、行指向の形式でバイト列にシリアル化される必要があった。さらに、宛先クライアントが列データベースやPandasのような列指向のデータサイエンスコンポーネントである場合、データは逆シリアル化されるべきである。シリアル化・デシリアル化のプロセスは、データ伝送の速度を低下させる要因となっていた。
Apache Doris 2.1は、Arrow Flight SQLをベースとしたデータ伝送チャネルを備えています。(Apache Arrowは、システムや言語間でのデータ移動効率を高めるために設計されたソフトウェア開発プラットフォームであり、Arrowフォーマットは高性能で損失のないデータ交換を目指しています。)これにより、様々なメインストリームプログラミング言語を使用してDorisから高速かつ大規模なデータをSQLで読み取ることができます。Arrowフォーマットもサポートするターゲットクライアントの場合、シリアル化/デシリアル化のプロセスがないため、パフォーマンスの損失がありません。さらに、Arrow Flightはマルチノードおよびマルチコアアーキテクチャを活用し、並列データ転送を実現できるため、高いデータスループットのもう一つの促進要因となります。
例えば、PythonクライアントがApache Dorisからデータを読み取る場合、Dorisはまず列指向のBlocksをArrow RecordBatchに変換します。そしてPythonクライアントでは、Arrow RecordBatchをPandas DataFrameに変換します。これらの変換はすべて列指向であるため、高速です。
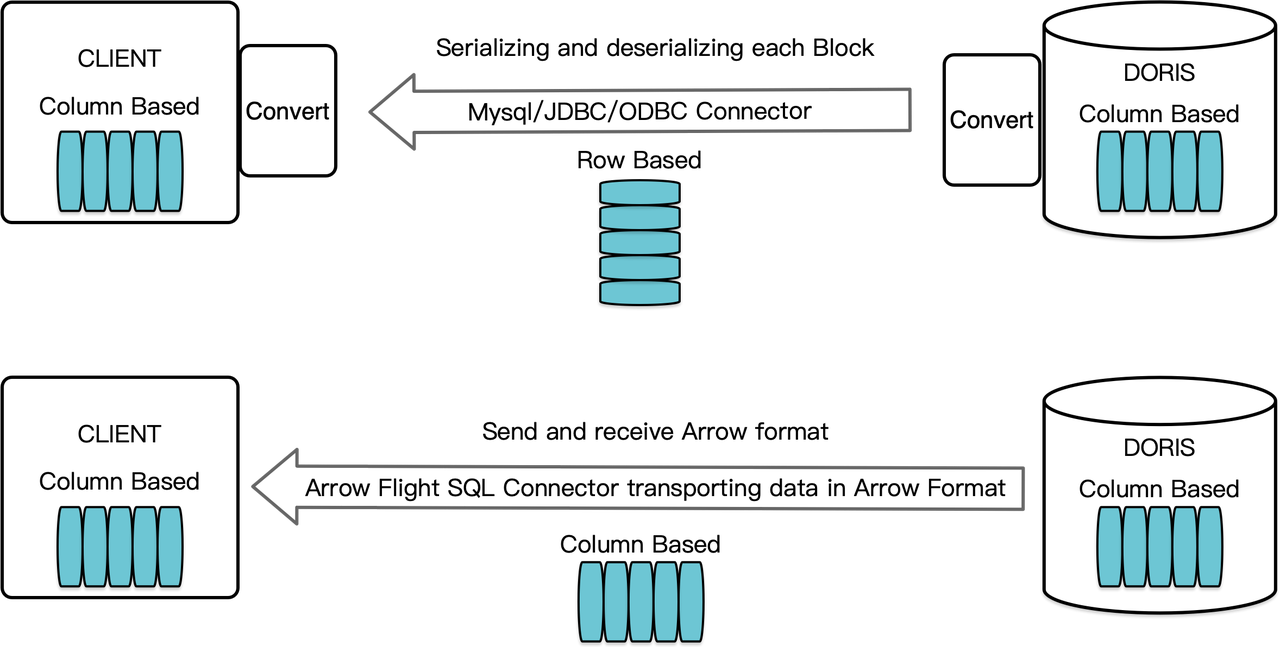
さらに、Arrow Flight SQLは、Arrow Flight SQLプロトコルをサポートするデータベースとの間でシームレスな通信を容易にする一般的なJDBCドライバーを提供しています。これにより、Dorisの接続可能性が広がり、より多くのケースで使用できる可能性が開かれます。
パフォーマンステスト
“10倍の速度向上”という結論は、ベンチマークテストに基づいています。Dorisからデータを読み取るためにPyMySQL、Pandas、およびArrow Flight SQLを使用して試しました。それぞれの期間を記録しました。テストデータはClickBenchデータセットです。

さまざまなデータタイプの結果は以下の通りです:
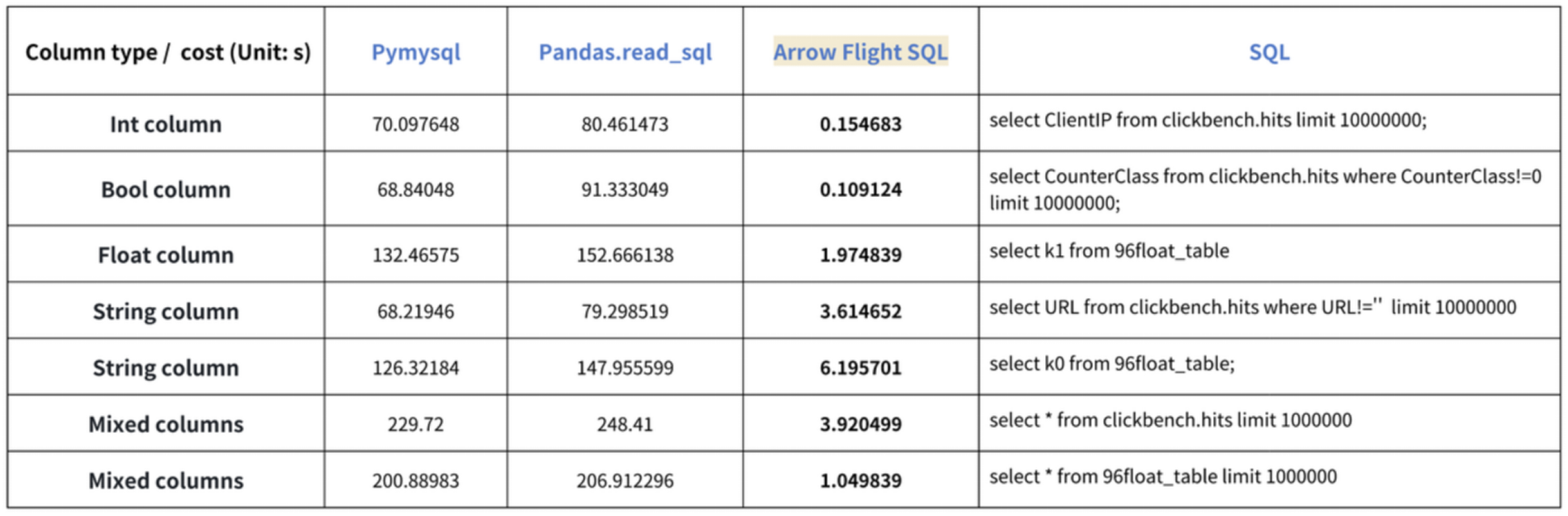
示されているように、Arrow Flight SQLはPyMySQLおよびPandasをすべてのデータタイプにおいて20倍から数百倍の係数で上回っています。
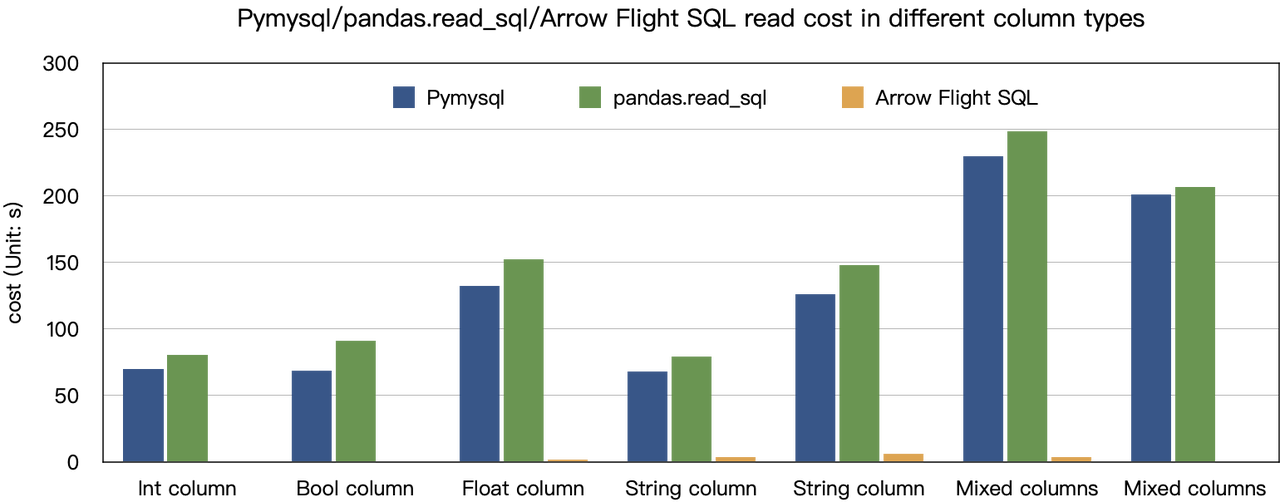
使用方法
Arrow Flight SQLをサポートするApache Dorisは、Python ADBCドライバを活用して高速なデータ読み取りを行うことができます。DDL、DML、セッション変数の設定、およびshowステートメントを含む、Python ADBCドライバ(バージョン3.9以降)を使用して実行されるいくつかの一般的なデータベース操作を紹介します。
1. ライブラリのインストール
関連するライブラリはPyPIに既に公開されており、次のように簡単にインストールできます:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlインストールされたライブラリと対話するために、以下のモジュール/ライブラリをインポートしてください:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Dorisへの接続
Doris Arrow Flight SQLサービスと対話するためのクライアントを作成します。前提条件には、Dorisフロントエンド(FE)ホスト、Arrow Flightポート、ログインユーザー名/パスワードが含まれます。
Dorisフロントエンド(FE)およびバックエンド(BE)のパラメータを設定します:
- Dorisフロントエンド(FE)の
fe/conf/fe.confで、arrow_flight_sql_portを使用可能なポート(例:9090)に設定します。 - Dorisバックエンド(BE)の
be/conf/be.confで、arrow_flight_portを使用可能なポート(例:9091)に設定します。
仮定として、DorisインスタンスのArrow Flight SQLサービスがFEとBEに対してそれぞれポート9090と9091で動作するとし、Dorisのユーザー名/パスワードが”user”および”pass”である場合、接続プロセスは以下の通りです。
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. テーブルの作成とメタデータの取得
Pass the query to the cursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. データの取り込み
Execute an INSERT INTO statement to load test data into the table created:
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 05. クエリの実行
Perform queries on the above table, such as aggregation, sorting, and session variable setting.
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. コードの完了
# Doris Arrow Flight SQLテスト
# ステップ1、ライブラリはPyPIでリリースされ、簡単にインストールできます。
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# ステップ2、Doris Arrow Flight SQLサービスと対話するクライアントを作成します。
# fe/conf/fe.confのarrow_flight_sql_portを使用可能なポートに変更、例えば9090。
# be/conf/be.confのarrow_flight_portを使用可能なポートに変更、例えば9091。
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# DorisをSQLを使ってカーソル経由で対話
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# ステップ3、DDLステートメントを実行、データベース/テーブルの作成、stmtの表示。
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# ステップ4、insert into
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# ステップ5、クエリの実行、集計、ソート、セッション変数の設定
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# ステップ6、カーソルの閉じる
cursor.close()大規模データ転送の例
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here’s how:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# ADBC Driver Manager用のPEP 249 (DB-API 2.0) APIラッパー。
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBCはデータをpandasデータフレームに読み込み、fetchallarrowを先に実行してからto_pandasに変換するよりも高速です。
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# 複数のパーティションを並列に読み込むことができます。
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1
2. JDBC
このドライバの使用方法はMySQLプロトコルのドライバを使用するのに似ています。接続URL内のjdbc:mysqlをjdbc:arrow-flight-sqlに置き換えるだけです。返される結果はJDBC ResultSetデータ構造になります。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.
// 方法一
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery、二つのステップ:
// 1. クエリを実行して返されたFlightInfoを取得;
// 2. FlightInfoReaderを作成して各Endpointを順番に走査;
QueryResult queryResult = stmt.executeQuery()
// 方法二
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// クエリを実行し、FlightInfo内の各Endpointを解析し、LocationとTicketを使用してPartitionDescriptorを構築
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
// 各PartitionDescriptorに対してArrowReaderを作成してデータを読み取る
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.
トレンドトレインに乗る
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That’s high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.
Source:
https://dzone.com/articles/data-warehouse-for-data-science-adopting-arrow