













Сегодня мир баз данных стремительно движется в направлении искусственного интеллекта и машинного обучения, и ожидается значительное увеличение нагрузки на базы данных. Для администратора баз данных это будет дополнительная ответственность – предсказывать нагрузку на инфраструктуру баз данных заранее и удовлетворять потребности. Поскольку базы данных масштабируются, и управление ресурсами становится все более критическим, традиционные методы планирования мощности часто оказываются неэффективными, что приводит к проблемам с производительностью и не запланированным простоям. PostgreSQL, одна из самых широко используемых открытых реляционных баз данных, не является исключением. С увеличением требований к ЦП, памяти и дисковому пространству администраторы баз данных (DBA) должны принять проактивные подходы для предотвращения узких мест и улучшения эффективности.
В этой статье мы рассмотрим, как модели машинного обучения с долгой краткосрочной памятью (LSTM) могут быть применены для прогнозирования потребления ресурсов в базах данных PostgreSQL. Такой подход позволяет администраторам баз данных перейти от реактивного к прогностическому планированию мощности, что в свою очередь снижает время простоя, улучшает распределение ресурсов и минимизирует издержки на избыточное обеспечение.
Зачем важно прогностическое планирование мощности
Используя машинное обучение, администраторы баз данных могут предсказывать будущие потребности в ресурсах и реагировать на них до того, как они станут критическими, что приводит к:
- Сокращению времени простоя: Раннее обнаружение нехватки ресурсов помогает избежать сбоев.
- Повышенная эффективность: Ресурсы выделяются на основе реальных потребностей, что предотвращает избыточное предоставление.
- Экономия затрат: В облачных средах точные прогнозы ресурсов могут снизить издержки из-за избыточного предоставления.
Как машинное обучение может оптимизировать планирование ресурсов PostgreSQL
Для точного прогнозирования использования ресурсов PostgreSQL мы применили оптимизированную модель LSTM, тип рекуррентной нейронной сети (RNN), которая отлично справляется с захватом временных паттернов в данных временных рядов. LSTM хорошо подходят для понимания сложных зависимостей и последовательностей, что делает их идеальными для прогнозирования использования ЦП, памяти и диска в средах PostgreSQL.
Методология
Сбор данных
Вариант 1
Для построения модели LSTM нам необходимо собирать данные о производительности из различных команд ОС сервера системы PostgreSQL и представлений базы данных, таких как:
pg_stat_activity(детали активных подключений в базе данных Postgres),vmstatfreedf
Данные могут быть записаны каждые несколько минут в течение шести месяцев, обеспечивая полный набор данных для обучения модели. Собранные метрики могут быть сохранены в специальной таблице с именем capacity_metrics.
Пример схемы таблицы:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Существует несколько способов записи этих системных данных в эту историческую таблицу. Один из способов – написать сценарий на Python и запланировать его через crontab на каждые несколько минут.
Вариант 2
Для проверки гибкости мы можем генерировать метрики использования ЦП, памяти и диска с помощью кода (генерация синтетических данных) и выполнять их с помощью блокнота Google Colab. Для анализа тестирования в данной работе мы использовали этот вариант. Шаги объяснены в следующих разделах.
Модель машинного обучения: Оптимизированный LSTM
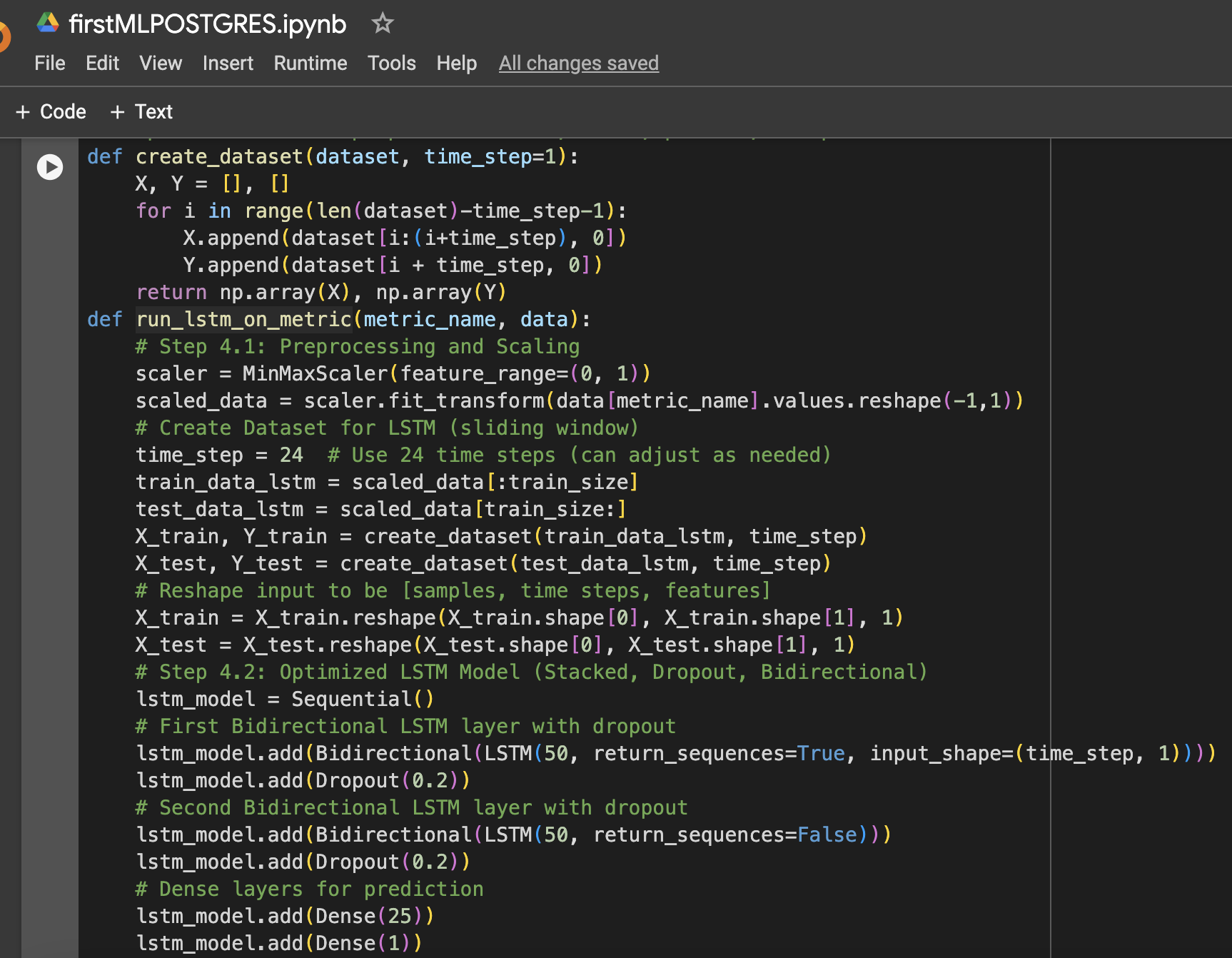
Модель LSTM была выбрана из-за ее способности обучаться длительным зависимостям в данных временных рядов. Несколько оптимизаций были применены для улучшения ее производительности:
- Несколько слоев LSTM: Было добавлено два слоя LSTM для захвата сложных паттернов в данных использования ресурсов.
- Регуляризация Dropout: После каждого слоя LSTM были добавлены слои Dropout для предотвращения переобучения и улучшения обобщения.
- Бидирекциональный LSTM: Модель была сделана бидирекциональной для захвата как прямых, так и обратных паттернов в данных.
- Оптимизация скорости обучения: Для настройки процесса обучения модели была выбрана скорость обучения 0,001.
Модель обучалась в течение 20 эпох с размером пакета 64, а производительность измерялась на невидимых тестовых данных для использования ЦП, памяти и хранилища (диска).
Ниже приведено краткое изложение шагов вместе с скриншотами блокнота Google Colab, использованными в настройке данных и эксперименте по машинному обучению:
Шаг 1: Настройка данных (Симулированные данные использования ЦП, памяти, диска за 6 месяцев)
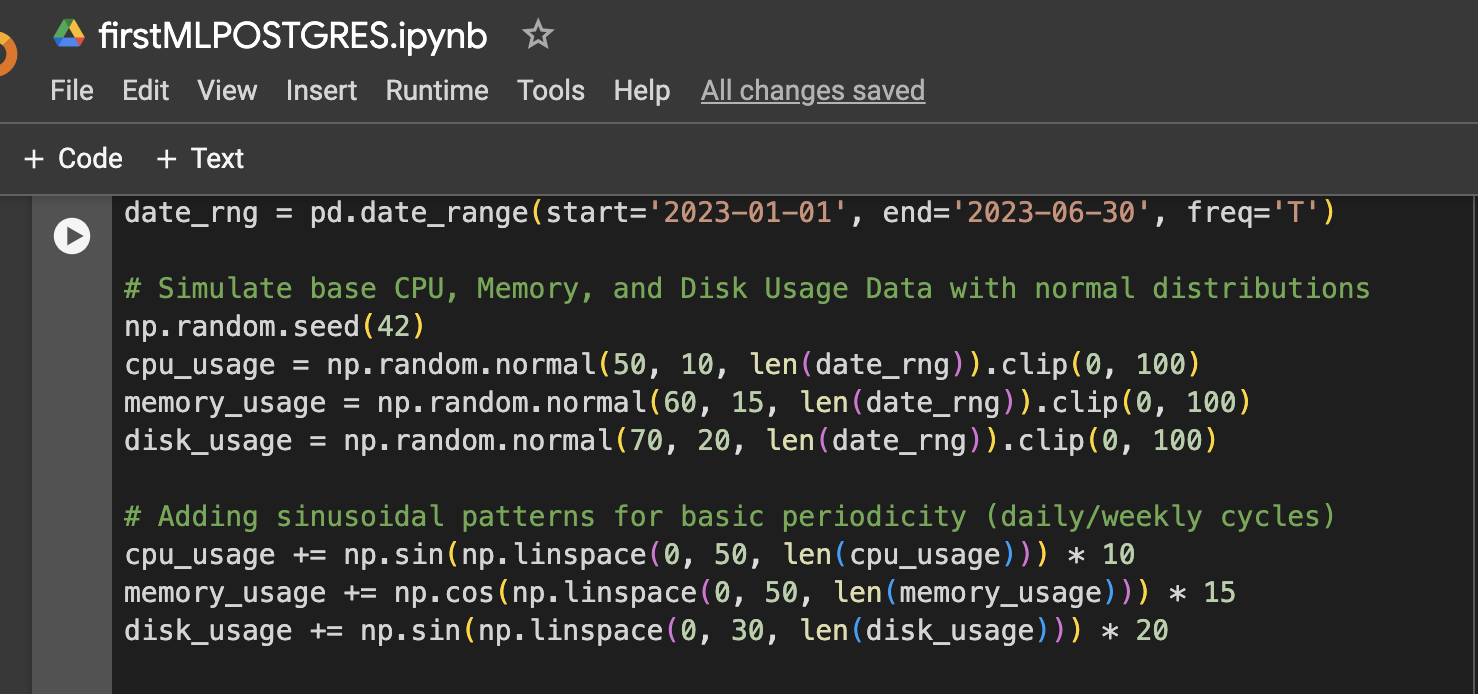
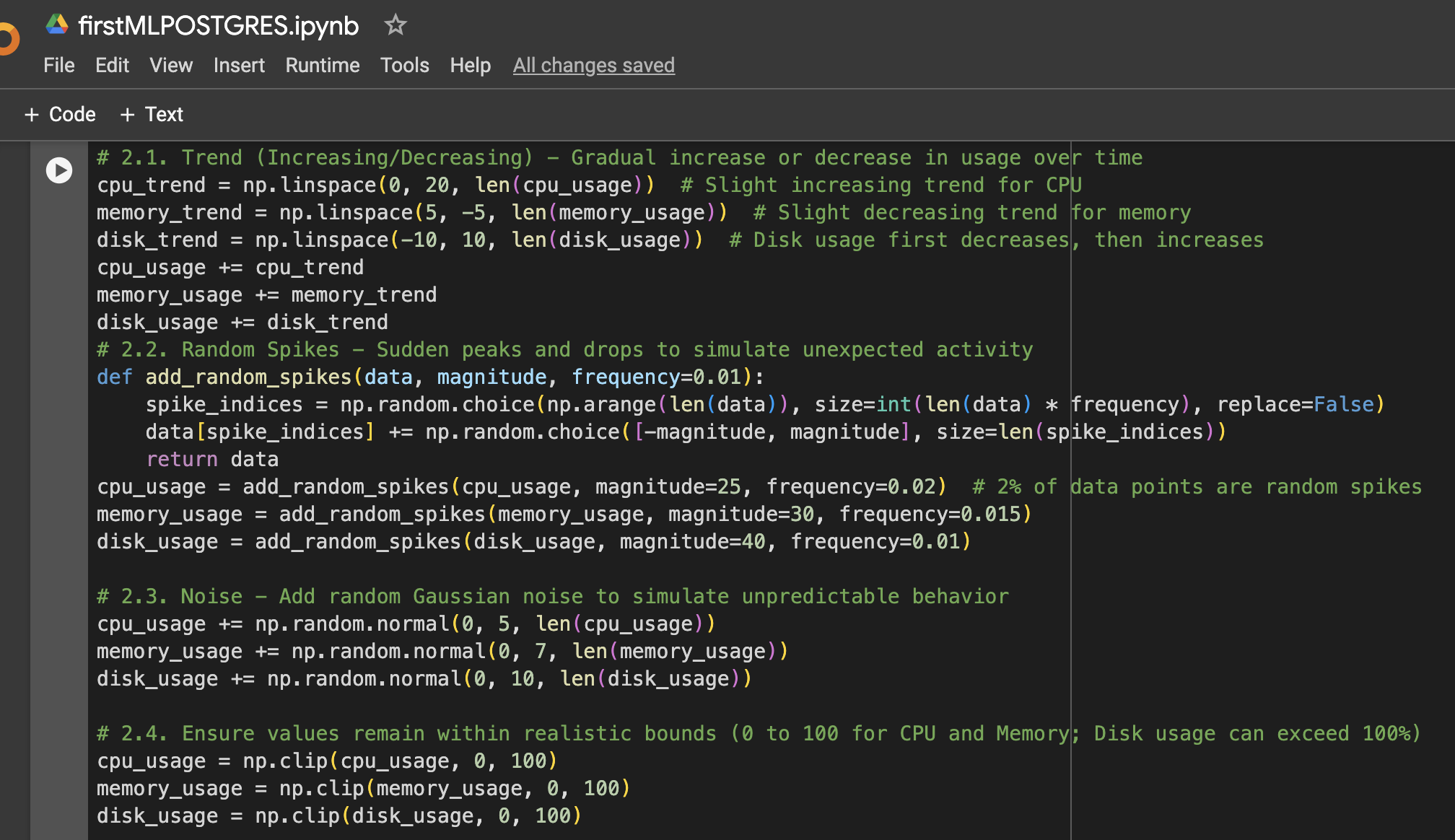
Шаг 2: Добавление большего разнообразия в данных
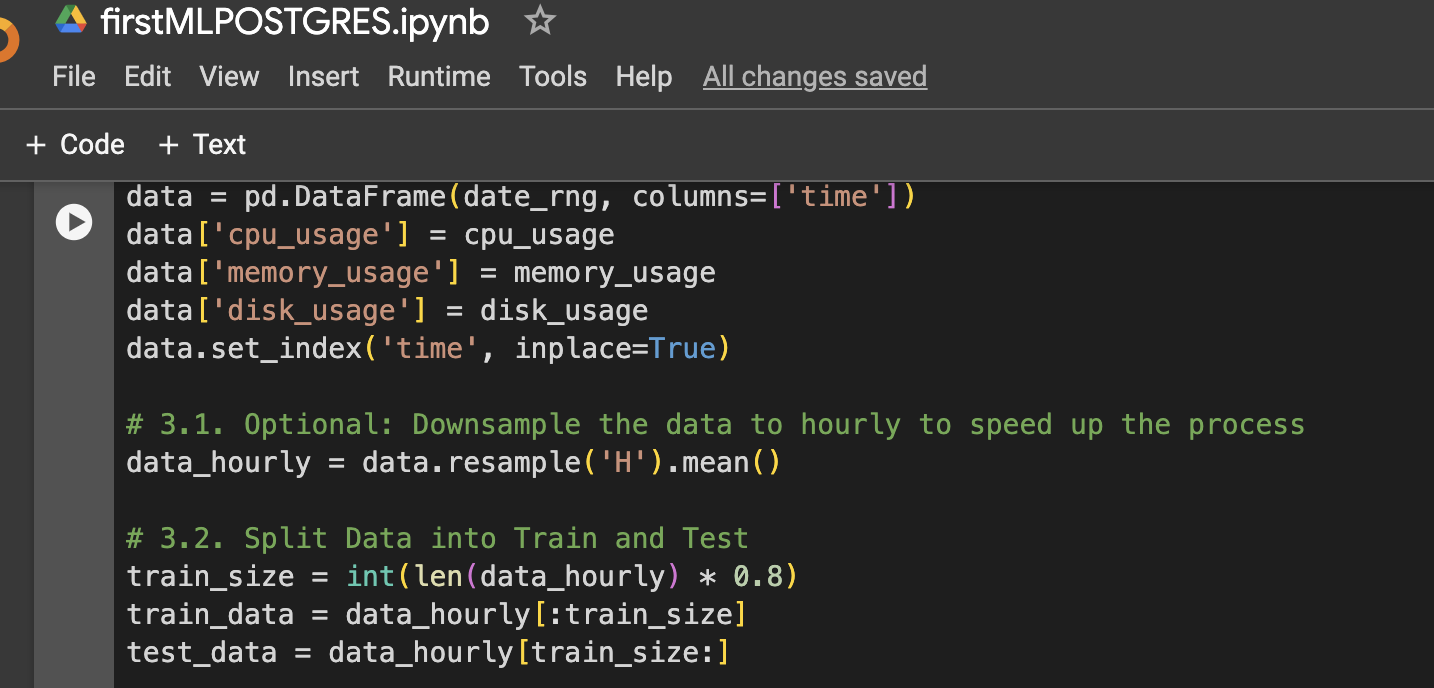
Шаг 3: Создание фрейма данных для визуализации или дальнейшего использования
Шаг 4: Функция для подготовки данных LSTM, обучения, предсказания и построения графика
Шаг 5: Запуск модели для ЦП, памяти и хранилища
Результаты
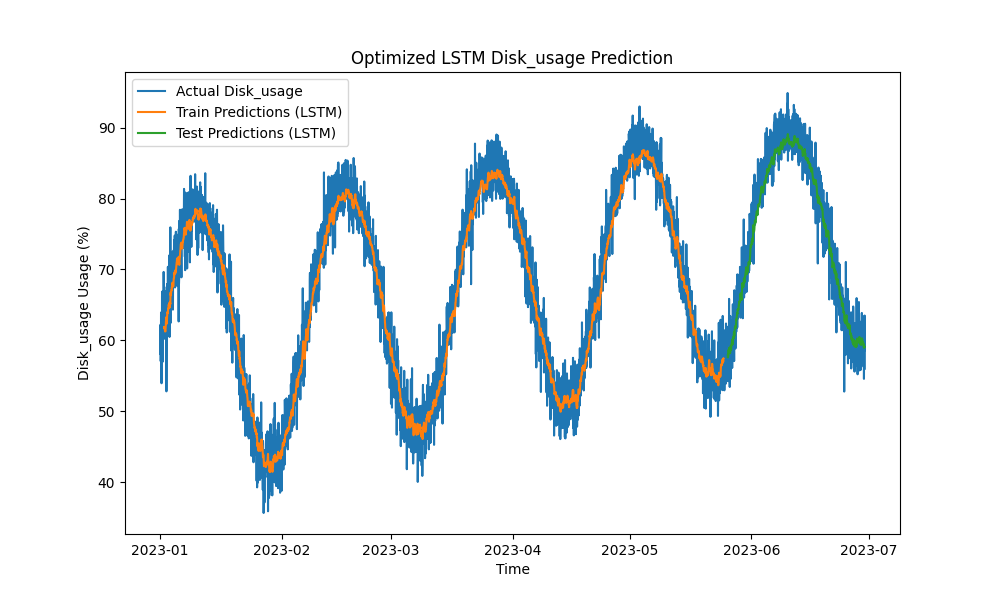
Оптимизированная модель LSTM превзошла традиционные методы, такие как ARIMA и линейная регрессия, в предсказании использования ЦП, памяти и диска. Прогнозы тесно отслеживали фактическое использование ресурсов, эффективно улавливая как краткосрочные, так и долгосрочные паттерны.
Вот визуализации прогнозов LSTM:
Рисунок 1: Оптимизированное прогнозирование использования ЦП LSTM
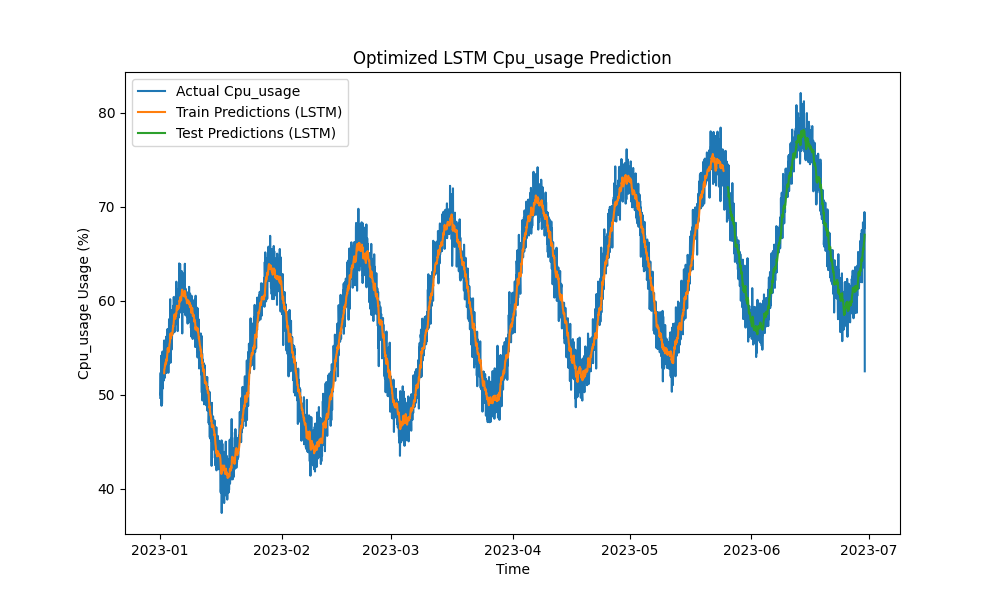
Рисунок 2: Оптимизированное прогнозирование использования памяти LSTM
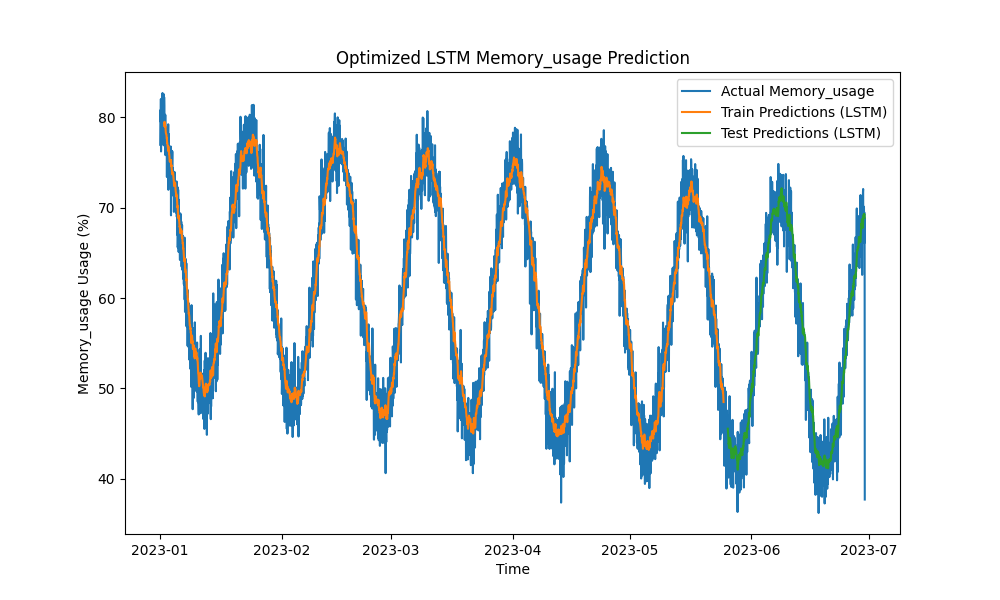
Рисунок 3: Оптимизированное прогнозирование использования диска LSTM
Практическая интеграция с инструментами мониторинга PostgreSQL
Для максимизации полезности модели LSTM можно исследовать различные практические реализации в экосистеме мониторинга PostgreSQL:
- Интеграция с pgAdmin: pgAdmin может быть расширен для визуализации предсказаний ресурсов в реальном времени наряду с фактическими метриками, позволяя администраторам баз данных реагировать проактивно на потенциальный дефицит ресурсов.
- Панели управления Grafana: Метрики PostgreSQL могут быть интегрированы с Grafana для накладывания предсказаний LSTM на графики производительности. Могут быть настроены оповещения, уведомляющие администраторов баз данных, когда предполагается, что использование превысит заранее определенные пороги.
- Мониторинг Prometheus: Prometheus может собирать метрики PostgreSQL и использовать предсказания LSTM для оповещений, создания прогнозов и настройки уведомлений на основе прогнозируемого потребления ресурсов.
- Автоматическое масштабирование в облачных средах: В хостинге PostgreSQL в облаке (например, в AWS RDS, Google Cloud SQL) модель LSTM может запускать службы автомасштабирования на основе прогнозируемого роста спроса на ресурсы.
- Циклы CI/CD: Модели машинного обучения могут быть непрерывно обновляться новыми данными, переобучаться и развертываться в реальном времени через циклы CI/CD, обеспечивая точность предсказаний при изменении рабочих нагрузок.
Заключение
Применяя модели машинного обучения LSTM для прогнозирования использования ЦП, памяти и диска, планирование емкости PostgreSQL может перейти от реактивного к проактивному подходу. Наши результаты показывают, что оптимизированная модель LSTM обеспечивает точные прогнозы, что позволяет более эффективно управлять ресурсами и экономить средства, особенно в облачных средах.
Поскольку экосистемы баз данных становятся все более сложными, эти предсказательные инструменты становятся необходимыми для администраторов баз данных, стремящихся оптимизировать использование ресурсов, предотвращать простои и обеспечивать масштабируемость. Если вы управляете базами данных PostgreSQL в больших объемах, сейчас самое время использовать машинное обучение для предсказательного планирования емкости и оптимизировать управление ресурсами до возникновения проблем с производительностью.
Будущая работа
Будущие улучшения могут включать:
- Эксперименты с дополнительными архитектурами нейронных сетей (например, GRU или моделями Transformer) для обработки более нестабильных нагрузок.
- Расширение методологии на многоузловые и распределенные развертывания PostgreSQL, где сетевой трафик и оптимизация хранения также играют значительную роль.
- Внедрение оповещений в реальном времени и дальнейшая интеграция прогнозов в операционную стек PostgreSQL для более автоматизированного управления.
- Эксперименты с данными Oracle Автоматизированного репозитория нагрузки (AWR) для прогнозирования нагрузки баз данных Oracle.
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity