













Aujourd’hui, le monde des bases de données se tourne rapidement vers l’IA et le ML, et la charge de travail des bases de données devrait augmenter de manière significative. Pour un administrateur de base de données, il sera de sa responsabilité supplémentaire de prédire la charge de travail de l’infrastructure de la base de données à l’avance et de répondre aux besoins. À mesure que les bases de données évoluent et que la gestion des ressources devient de plus en plus cruciale, les méthodes traditionnelles de planification des capacités sont souvent insuffisantes, entraînant des problèmes de performance et des temps d’arrêt non planifiés. PostgreSQL, l’une des bases de données relationnelles open-source les plus largement utilisées, ne fait pas exception. Avec une demande croissante en CPU, en mémoire et en espace disque, les administrateurs de bases de données (DBA) doivent adopter des approches proactives pour prévenir les goulots d’étranglement et améliorer l’efficacité.
Dans cet article, nous explorerons comment les modèles d’apprentissage automatique Long Short-Term Memory (LSTM) peuvent être appliqués pour prédire la consommation de ressources dans les bases de données PostgreSQL. Cette approche permet aux DBA de passer d’une planification des capacités réactive à prédictive, réduisant ainsi les temps d’arrêt, améliorant l’allocation des ressources et minimisant les coûts de sur-provisionnement.
Pourquoi la Planification des Capacités Prédictive Est Importante
En exploitant l’apprentissage automatique, les DBA peuvent prédire les besoins futurs en ressources et les anticiper avant qu’ils ne deviennent critiques, ce qui entraîne :
- Moins de temps d’arrêt : La détection précoce des pénuries de ressources permet d’éviter les perturbations.
- Amélioration de l’efficacité : Les ressources sont allouées en fonction des besoins réels, évitant ainsi la surprovision.
- Économies de coûts : Dans les environnements cloud, des prédictions précises des ressources peuvent réduire le coût de la surprovision.
Comment l’apprentissage automatique peut optimiser la planification des ressources PostgreSQL
Pour prédire avec précision l’utilisation des ressources PostgreSQL, nous avons appliqué un modèle LSTM optimisé, un type de réseau de neurones récurrent (RNN) qui excelle dans la capture des schémas temporels dans les données de séries chronologiques. Les LSTMs sont bien adaptés pour comprendre les dépendances complexes et les séquences, ce qui les rend idéaux pour prédire l’utilisation du CPU, de la mémoire et du disque dans les environnements PostgreSQL.
Méthodologie
Collecte de données
Option 1
Pour construire le modèle LSTM, nous devons collecter des données de performance à partir de diverses commandes système du serveur PostgreSQL et des vues de la base de données, telles que :
pg_stat_activity(détails des connexions actives dans la base de données Postgres),vmstatfreedf
Les données peuvent être capturées toutes les quelques minutes pendant six mois, fournissant un ensemble de données complet pour l’entraînement du modèle. Les mesures collectées peuvent être stockées dans une table dédiée nommée capacity_metrics.
Exemple de schéma de table:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Il existe plusieurs façons de capturer ces données système dans cette table d’historique. L’une des façons est d’écrire le script Python et de le planifier via crontab toutes les quelques minutes.
Option 2
Pour tester la flexibilité, nous pouvons générer des métriques d’utilisation de CPU, de mémoire et de disque en utilisant du code (génération de données synthétiques) et l’exécuter en utilisant le Notebook Google Colab. Pour cette analyse de test, nous avons utilisé cette option. Les étapes sont expliquées dans les sections suivantes.
Modèle d’apprentissage automatique : LSTM optimisé
Le modèle LSTM a été sélectionné pour sa capacité à apprendre des dépendances à long terme dans les données de séries temporelles. Plusieurs optimisations ont été appliquées pour améliorer ses performances :
- Couches LSTM empilées : Deux couches LSTM ont été empilées pour capturer des schémas complexes dans les données d’utilisation des ressources.
- Régularisation de la désactivation aléatoire : Des couches de désactivation ont été ajoutées après chaque couche LSTM pour éviter le surajustement et améliorer la généralisation.
- LSTM bidirectionnel : Le modèle a été rendu bidirectionnel pour capturer à la fois les schémas avant et arrière dans les données.
- Optimisation du taux d’apprentissage : Un taux d’apprentissage de 0,001 a été choisi pour affiner le processus d’apprentissage du modèle.
Le modèle a été entraîné pendant 20 époques avec une taille de lot de 64, et les performances ont été mesurées sur des données de test non vues pour l’utilisation du CPU, de la mémoire et du stockage (disque).
Voici un résumé des étapes ainsi que des captures d’écran du cahier Google Colab utilisé pour la configuration des données et l’expérience d’apprentissage automatique :
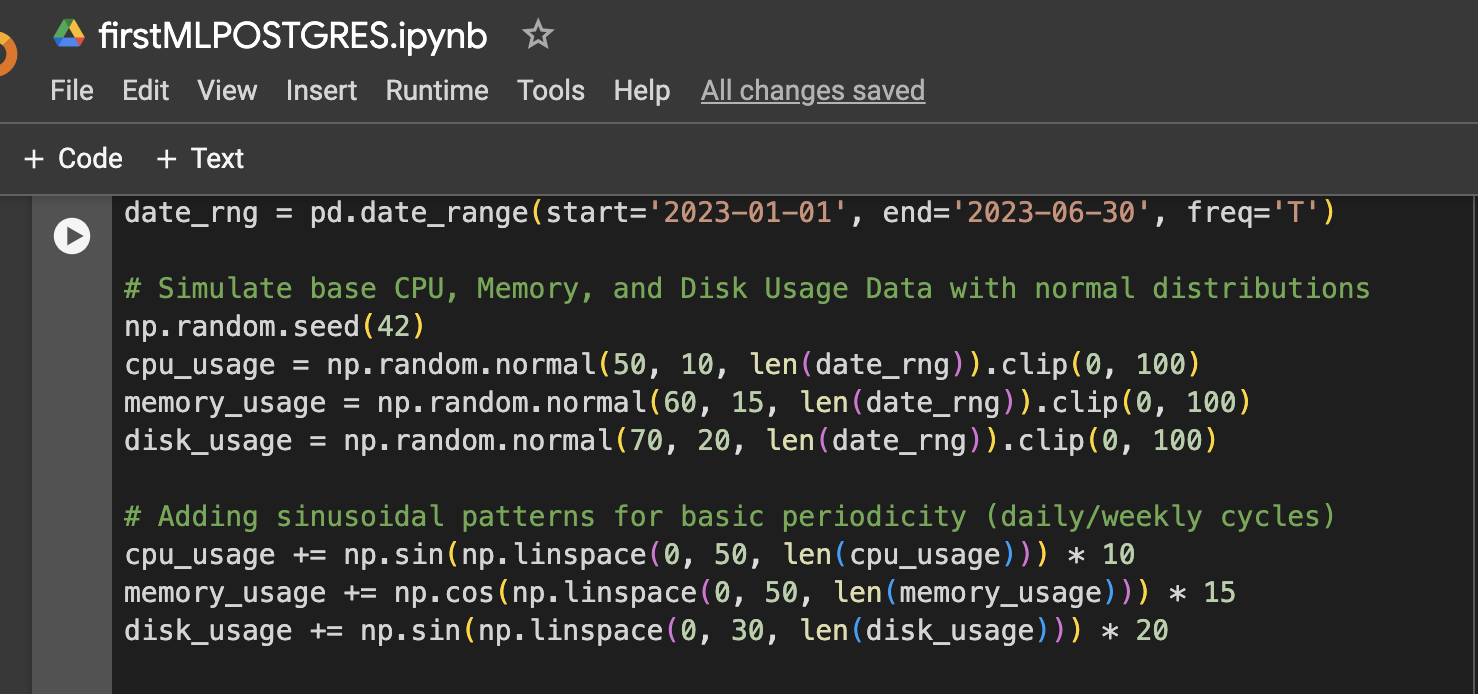
Étape 1 : Configuration des données (Données simulées d’utilisation du CPU, de la mémoire et du disque pendant 6 mois)
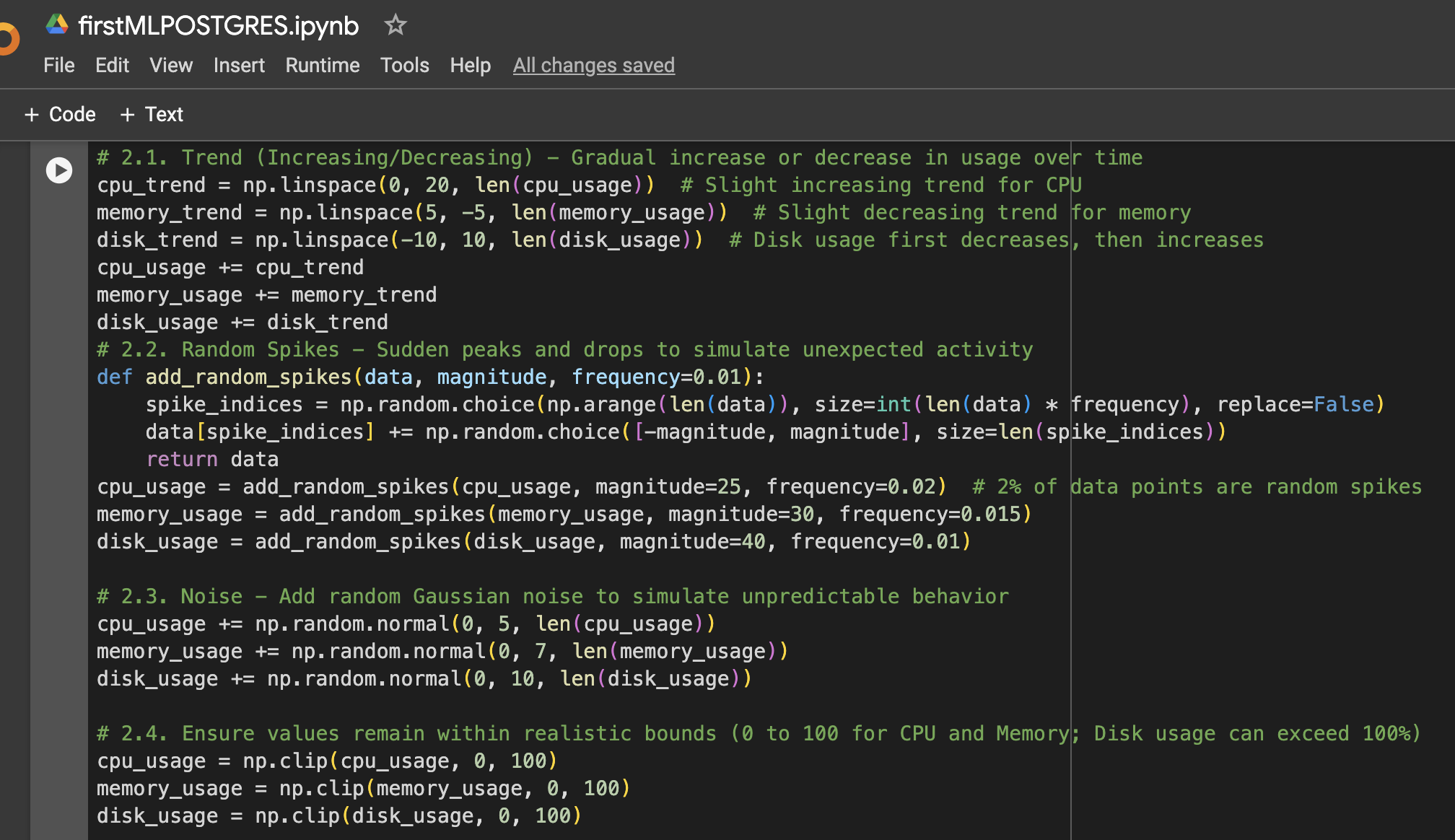
Étape 2 : Ajouter plus de variation aux données
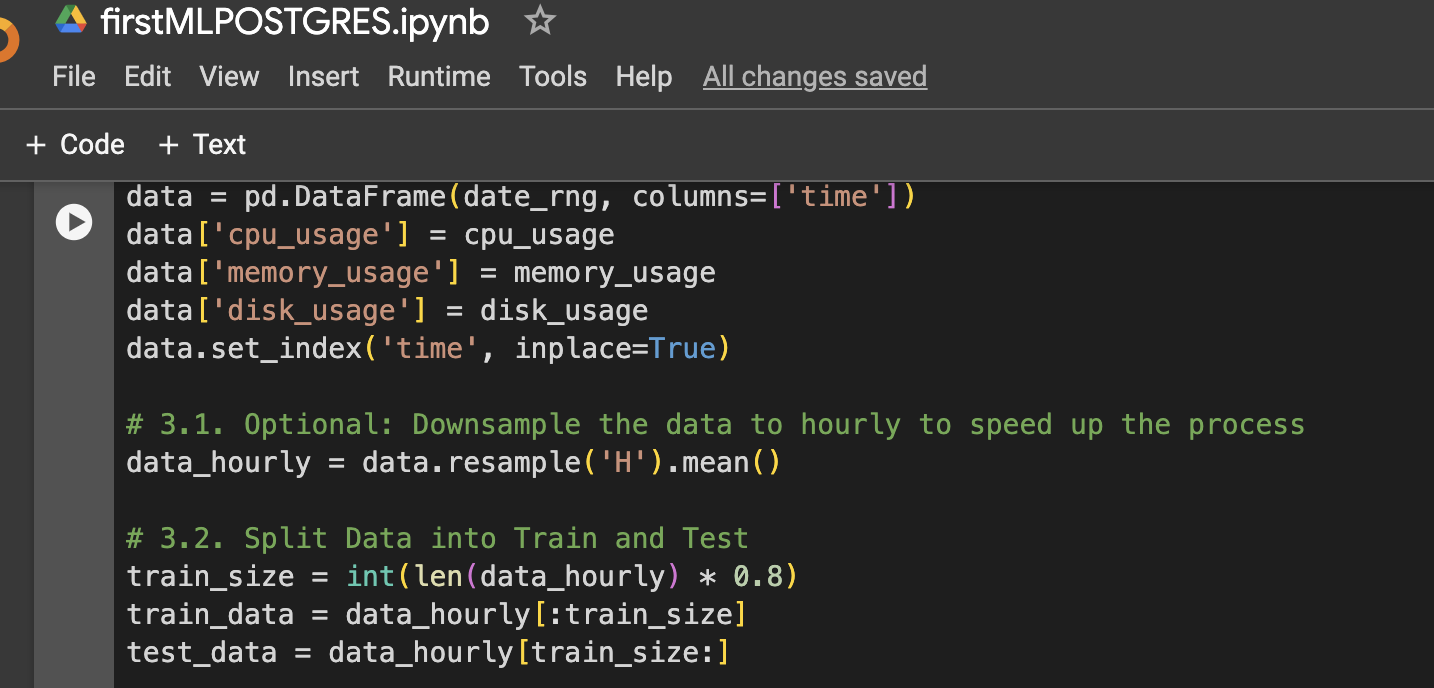
Étape 3 : Créer un DataFrame pour la visualisation ou une utilisation ultérieure
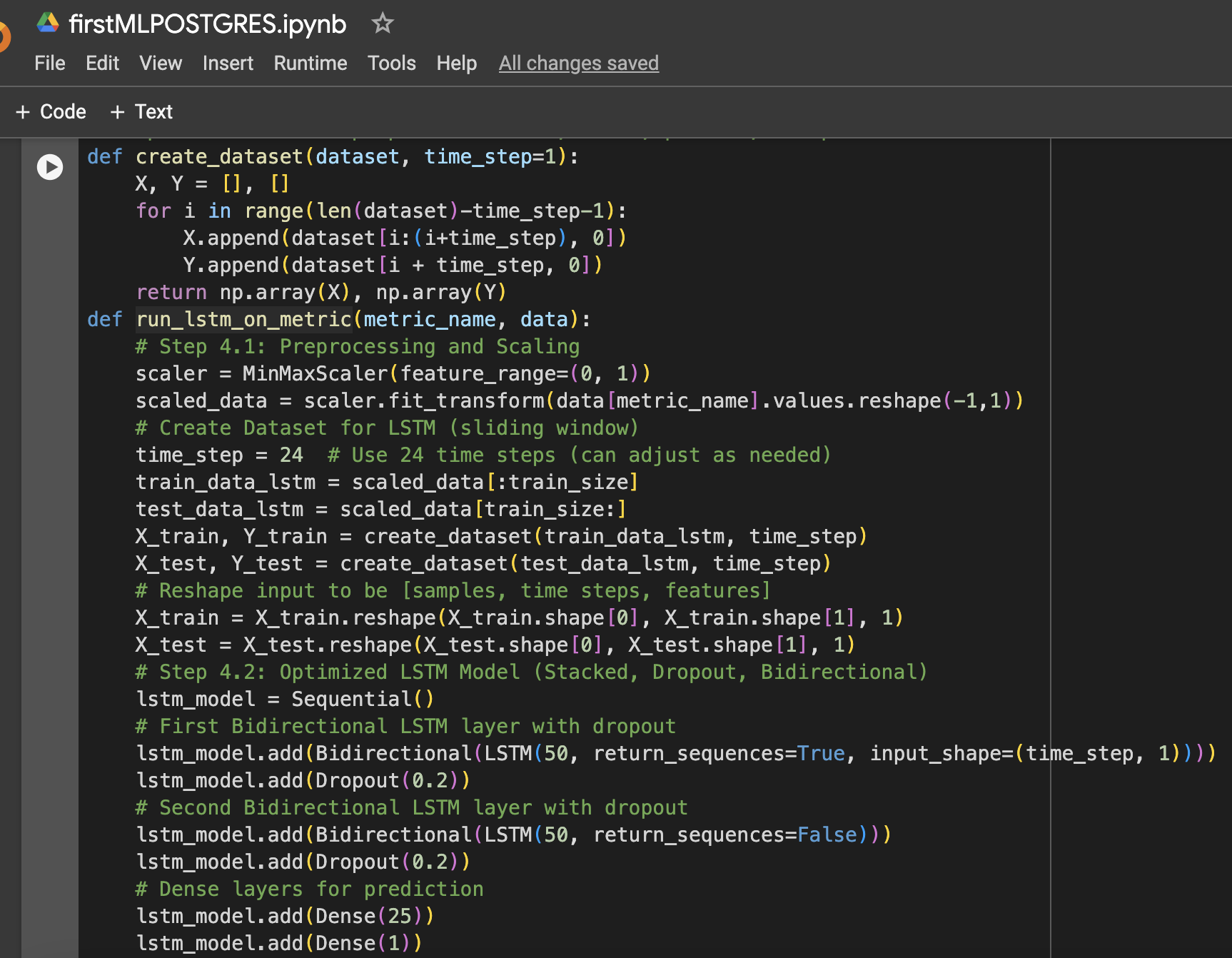
Étape 4 : Fonction pour préparer les données LSTM, entraîner, prédire et tracer
Étape 5 : Exécuter le modèle pour le CPU, la mémoire et le stockage
Résultats
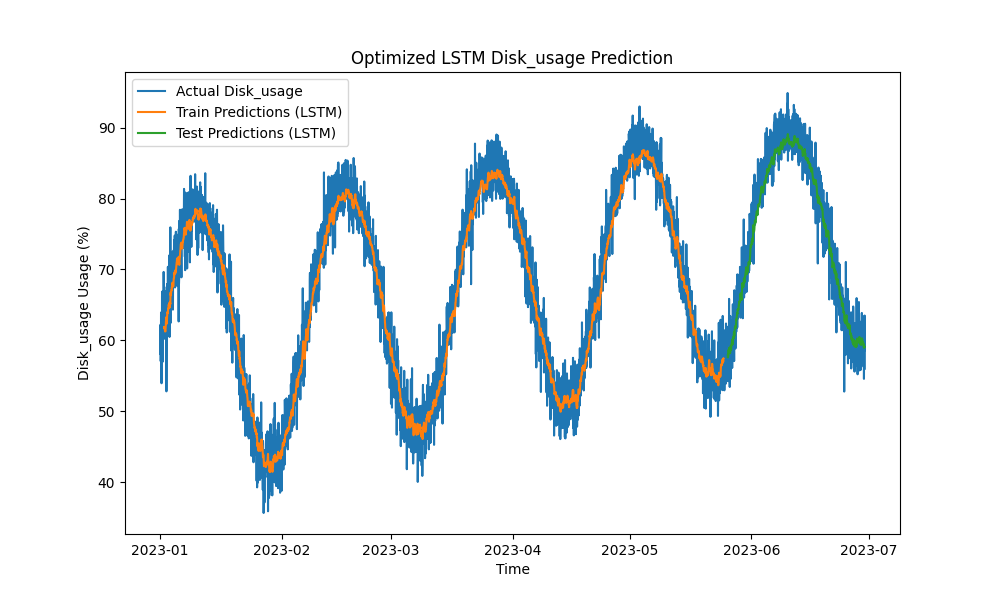
Le modèle LSTM optimisé a surpassé les méthodes traditionnelles telles que ARIMA et la régression linéaire dans la prédiction de l’utilisation du CPU, de la mémoire et du disque. Les prédictions ont suivi de près l’utilisation réelle des ressources, capturant efficacement les motifs à court et à long terme.
Voici les visualisations des prédictions LSTM :
Figure 1 : Prédiction optimisée de l’utilisation du CPU par le LSTM
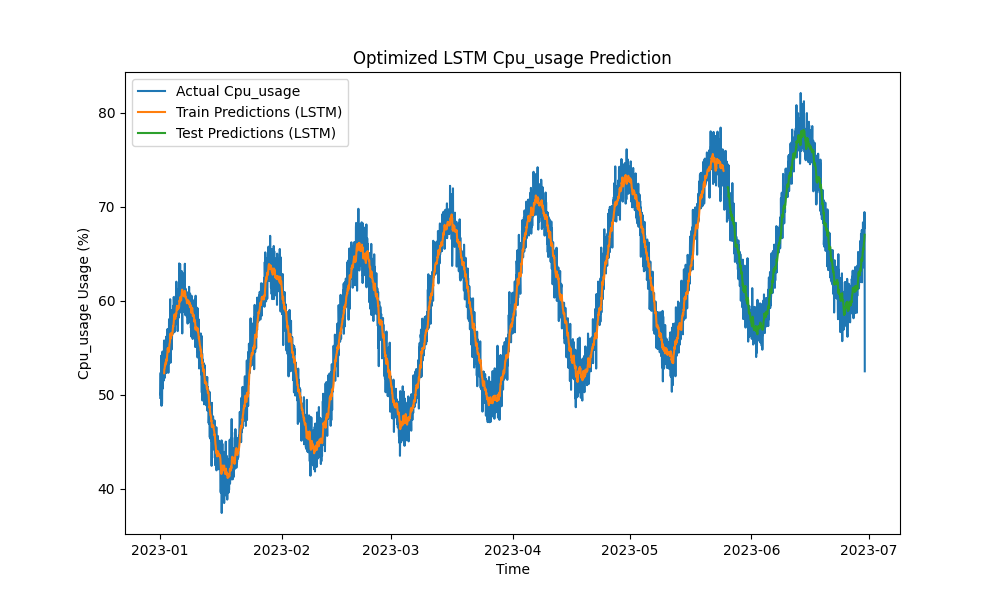
Figure 2 : Prédiction optimisée de l’utilisation de la mémoire par le LSTM
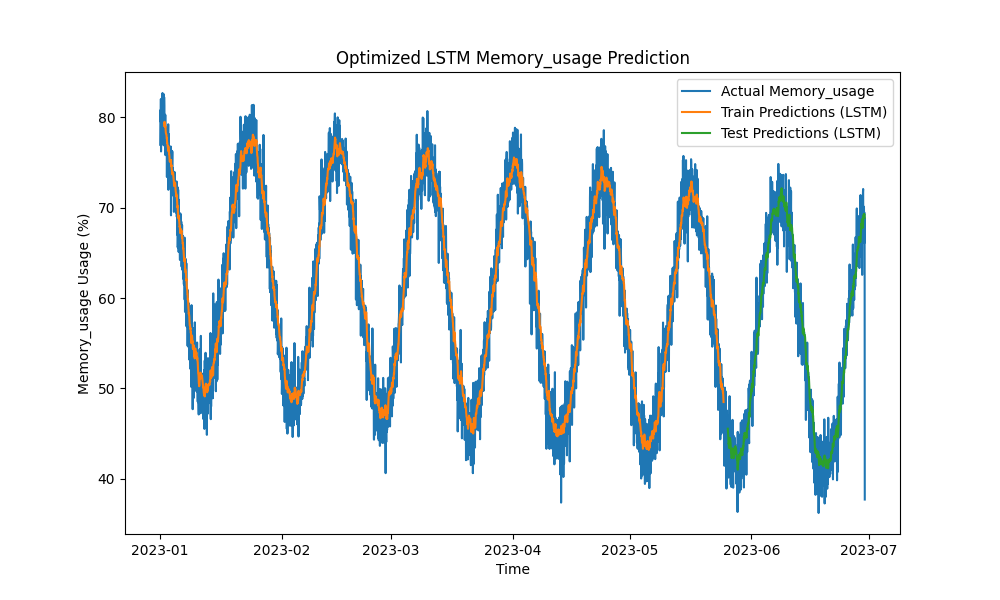
Figure 3 : Prédiction optimisée de l’utilisation du disque par le LSTM
Intégration pratique avec les outils de surveillance PostgreSQL
Pour maximiser l’utilité du modèle LSTM, différentes implémentations pratiques au sein de l’écosystème de surveillance de PostgreSQL peuvent être explorées :
- Intégration de pgAdmin : pgAdmin peut être étendu pour visualiser les prédictions de ressources en temps réel aux côtés des indicateurs réels, permettant aux administrateurs de base de données de réagir de manière proactive aux éventuelles pénuries de ressources.
- Tableaux de bord Grafana : Les indicateurs de PostgreSQL peuvent être intégrés avec Grafana pour superposer les prédictions LSTM sur les graphiques de performance. Des alertes peuvent être configurées pour notifier les administrateurs de base de données lorsque l’utilisation prévue est susceptible de dépasser les seuils prédéfinis.
- Surveillance Prometheus : Prometheus peut extraire les indicateurs de PostgreSQL et utiliser les prédictions LSTM pour alerter, générer des prévisions et mettre en place des notifications basées sur la consommation de ressources prévue.
- Redimensionnement automatisé dans les environnements cloud : Dans des instances PostgreSQL hébergées dans le cloud (par exemple, AWS RDS, Google Cloud SQL), le modèle LSTM peut déclencher des services d’auto-scaling sur la base d’augmentations prévues de la demande en ressources.
- Pipelines CI/CD : Les modèles d’apprentissage automatique peuvent être continuellement mis à jour avec de nouvelles données, retravaillés et déployés en temps réel via des pipelines CI/CD, garantissant que les prédictions restent précises à mesure que les charges de travail évoluent.
Conclusion
En appliquant des modèles d’apprentissage automatique LSTM pour prédire l’utilisation du CPU, de la mémoire et du disque, la planification de capacité de PostgreSQL peut passer d’une approche réactive à une approche proactive. Nos résultats montrent que le modèle LSTM optimisé fournit des prédictions précises, permettant une gestion des ressources plus efficace et des économies de coûts, notamment dans les environnements hébergés sur le cloud.
À mesure que les écosystèmes de bases de données deviennent plus complexes, ces outils prédictifs deviennent essentiels pour les DBA cherchant à optimiser l’utilisation des ressources, à prévenir les temps d’arrêt et à garantir la scalabilité. Si vous gérez des bases de données PostgreSQL à grande échelle, c’est le moment d’utiliser l’apprentissage automatique pour la planification de capacité prédictive et d’optimiser votre gestion des ressources avant que des problèmes de performance ne surviennent.
Travaux futurs
Des améliorations futures pourraient inclure :
- Expérimenter avec des architectures de réseaux neuronaux supplémentaires (par exemple, les modèles GRU ou Transformer) pour gérer des charges de travail plus volatiles.
- Étendre la méthodologie aux déploiements PostgreSQL multi-nœuds et distribués, où le trafic réseau et l’optimisation du stockage jouent également un rôle important.
- Mettre en place des alertes en temps réel et intégrer davantage les prédictions dans la pile opérationnelle de PostgreSQL pour une gestion plus automatisée.
- Expérimenter avec les données du Référentiel de Charge de Travail Automatisé Oracle (AWR) pour des prédictions de charges de travail de base de données Oracle
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity