













今日、データベースの世界は急速にAIとMLに向かっており、データベースのワークロードは大幅に増加すると予想されています。データベース管理者にとって、データベースインフラのワークロードを事前に予測し、必要に応じて対処する追加の責任が生じます。データベースがスケーリングし、リソース管理がますます重要になるにつれて、従来の容量計画手法はしばしば不十分であり、パフォーマンスの問題や計画外のダウンタイムを引き起こすことがあります。広く使用されているオープンソースのリレーショナルデータベースであるPostgreSQLも例外ではありません。CPU、メモリ、およびディスクスペースへの要求が増加するにつれて、データベース管理者(DBA)はボトルネックを防ぎ、効率を向上させるために積極的なアプローチを取らなければなりません。
この記事では、Long Short-Term Memory(LSTM)機械学習モデルを使用して、PostgreSQLデータベースのリソース消費を予測する方法について探っていきます。このアプローチにより、DBAはリアクティブから予測的な容量計画に移行し、ダウンタイムを減らし、リソース割り当てを改善し、過剰なプロビジョニングコストを最小限に抑えることができます。
予測的な容量計画が重要な理由
機械学習を活用することで、DBAは将来のリソース需要を予測し、それに対処することができ、以下の結果が得られます:
- ダウンタイムの削減:リソース不足を早期に検知することで、中断を回避できます。
- 効率の向上: リソースは実際のニーズに基づいて割り当てられ、過剰なプロビジョニングを防ぎます。
- コスト削減: クラウド環境では、正確なリソースの予測により余分なプロビジョニングコストを削減できます。
機械学習がPostgreSQLリソース計画を最適化する方法
PostgreSQLリソース使用量を正確に予測するために、時間系列データの時間パターンをキャプチャするのに優れた最適化されたLSTMモデル、再帰型ニューラルネットワーク (RNN) を適用しました。 LSTMs は、複雑な依存関係やシーケンスを理解するのに適しており、PostgreSQL環境でのCPU、メモリ、およびディスク使用量を予測するのに理想的です。
方法論
データ収集
オプション1
LSTMモデルを構築するために、PostgreSQLシステムサーバーOSコマンドとdbビューからのパフォーマンスデータを収集する必要があります。たとえば以下のものがあります:
pg_stat_activity(Postgresデータベース内のアクティブな接続の詳細),vmstatfreedf
データは6ヶ月間、数分ごとに収集され、モデルのトレーニングに使用する包括的なデータセットを提供します。収集されたメトリクスは、capacity_metricsという専用のテーブルに保存することができます。
サンプルテーブルスキーマ:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);システムデータをこの履歴テーブルにキャプチャする方法は複数あります。その1つは、Pythonスクリプトを記述し、数分ごとにcrontabを介してスケジュールする方法です。
オプション2
柔軟性をテストするために、CPU、メモリ、およびディスクの利用率メトリクスをコードを使用して生成し(合成データ生成)、Google Colab Notebookを使用して実行することができます。この論文のテスト分析では、このオプションを使用しました。手順は以下のセクションで説明されています。
機械学習モデル: 最適化されたLSTM
LSTMモデルは、時系列データの長期依存関係を学習する能力から選択されました。パフォーマンスを向上させるためにいくつかの最適化が適用されました:
- スタックされたLSTMレイヤー: 2つのLSTMレイヤーがスタックされ、リソース使用データの複雑なパターンをキャプチャします。
- ドロップアウト正則化: 各LSTMレイヤーの後にドロップアウトレイヤーが追加され、過学習を防ぎ、汎化を向上させます。
- 双方向LSTM: モデルは双方向になり、データの前方および後方のパターンをキャプチャするようになりました。
- 学習率の最適化:モデルの学習プロセスを微調整するために、学習率0.001が選択されました。
モデルはバッチサイズ64で20エポック学習され、CPU、メモリ、ストレージ(ディスク)の使用に関して見えないテストデータでパフォーマンスが測定されました。
以下は、データのセットアップと機械学習実験に使用された手順の要約とGoogle Colab Notebookのスクリーンショットです:
ステップ1:データのセットアップ(6ヶ月分のシミュレートされたCPU、メモリ、ディスク使用データ)
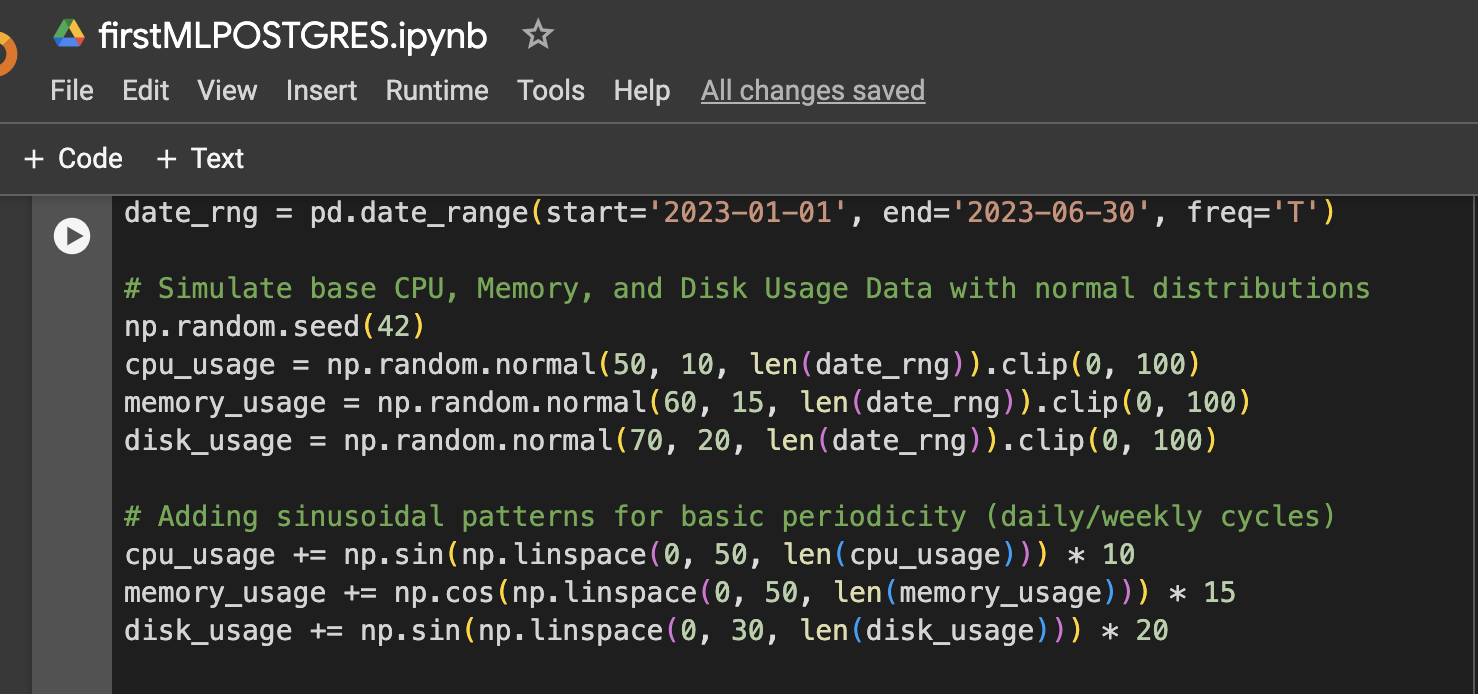
ステップ2:データにさらなる変動を追加
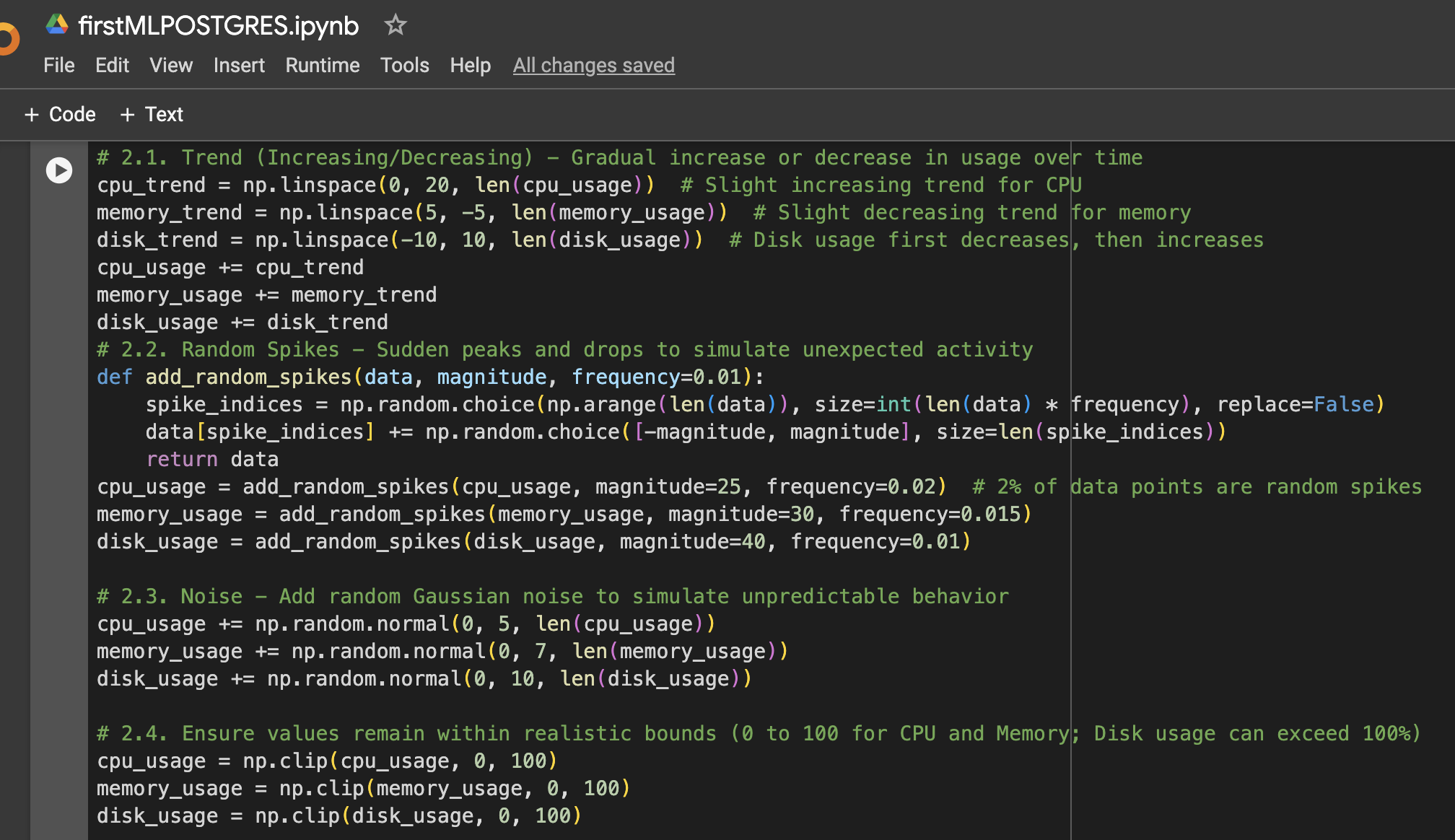
ステップ3:可視化またはさらなる使用のためのデータフレームの作成
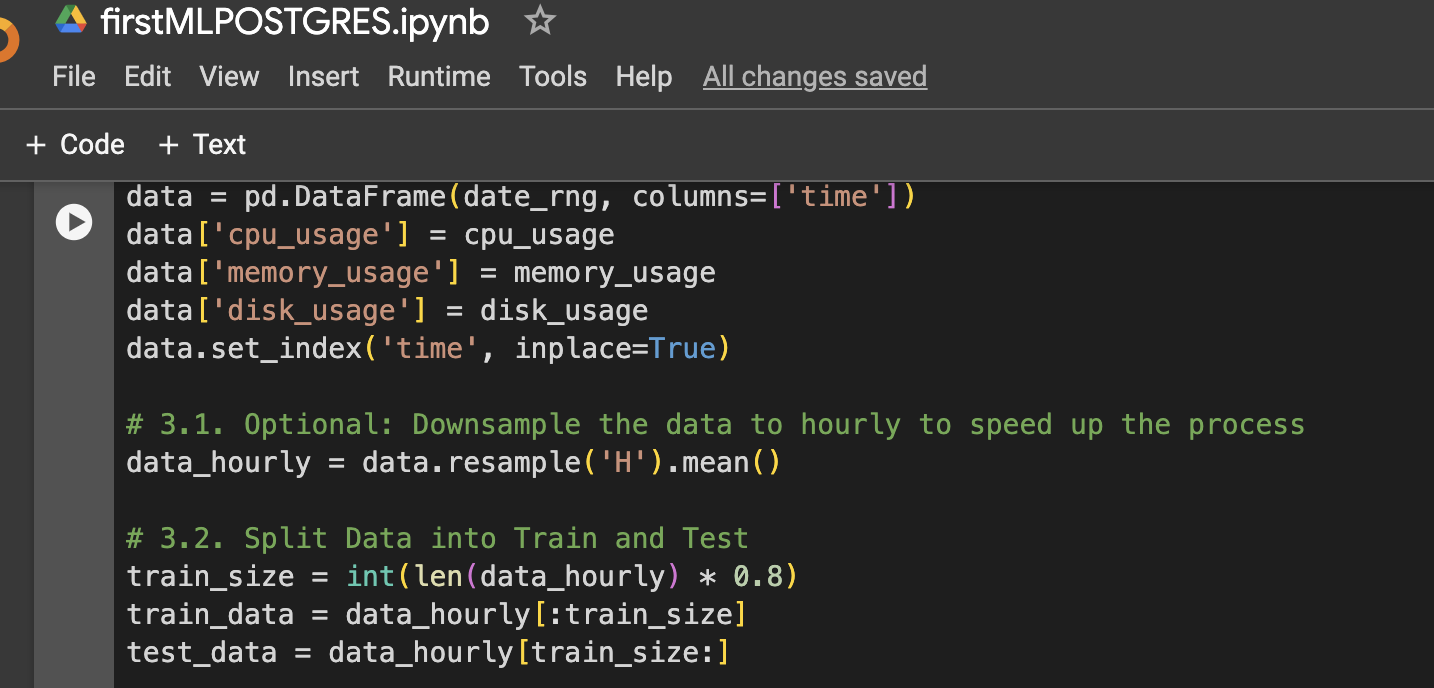
ステップ4:LSTMデータの準備、トレーニング、予測、およびプロットのための関数
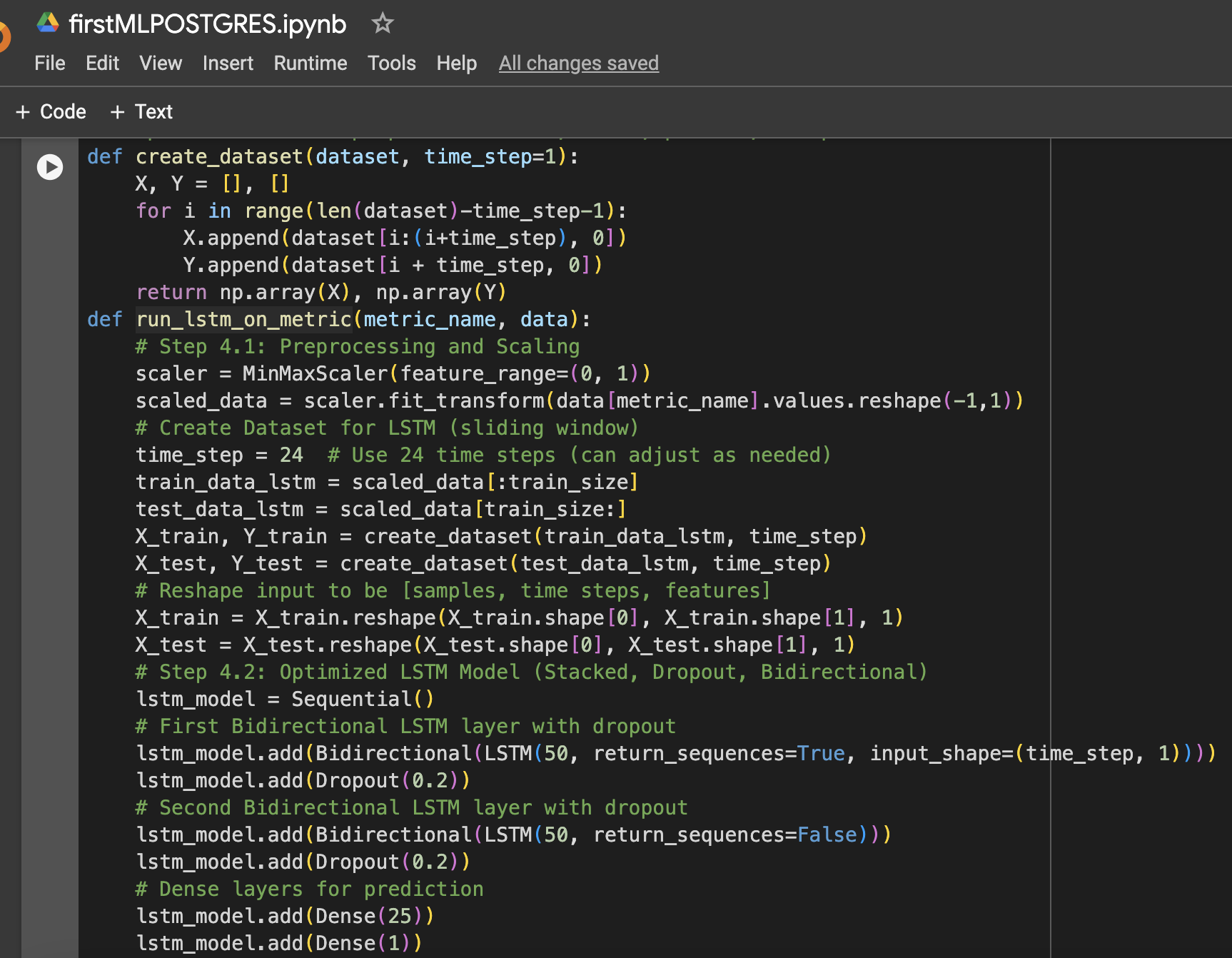
ステップ5:CPU、メモリ、ストレージのモデルを実行
結果
最適化されたLSTMモデルは、CPU、メモリ、ディスクの使用を予測する際に、ARIMAや線形回帰などの従来の手法を凌駕しました。予測は実際のリソース使用を正確に追跡し、短期および長期のパターンを効果的に捉えました。
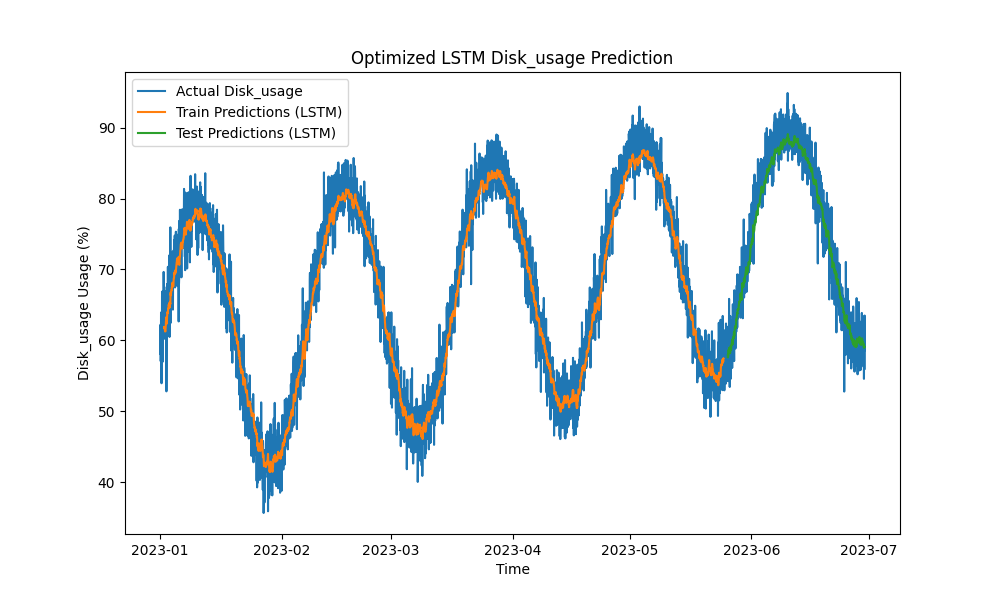
以下は、LSTMの予測の視覚化です:
図1:最適化されたLSTM CPU使用量の予測
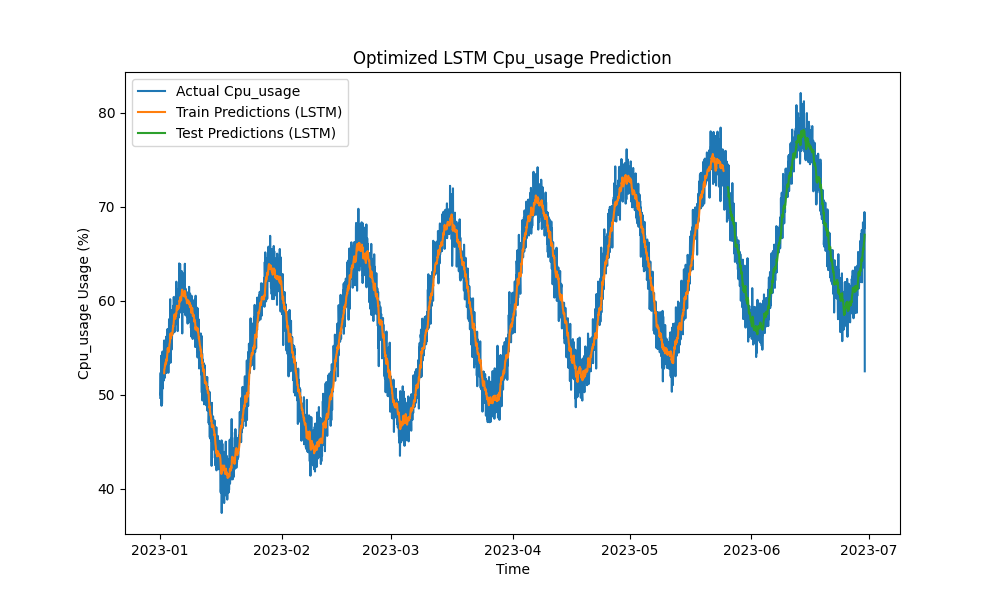
図2:最適化されたLSTMメモリ使用量の予測
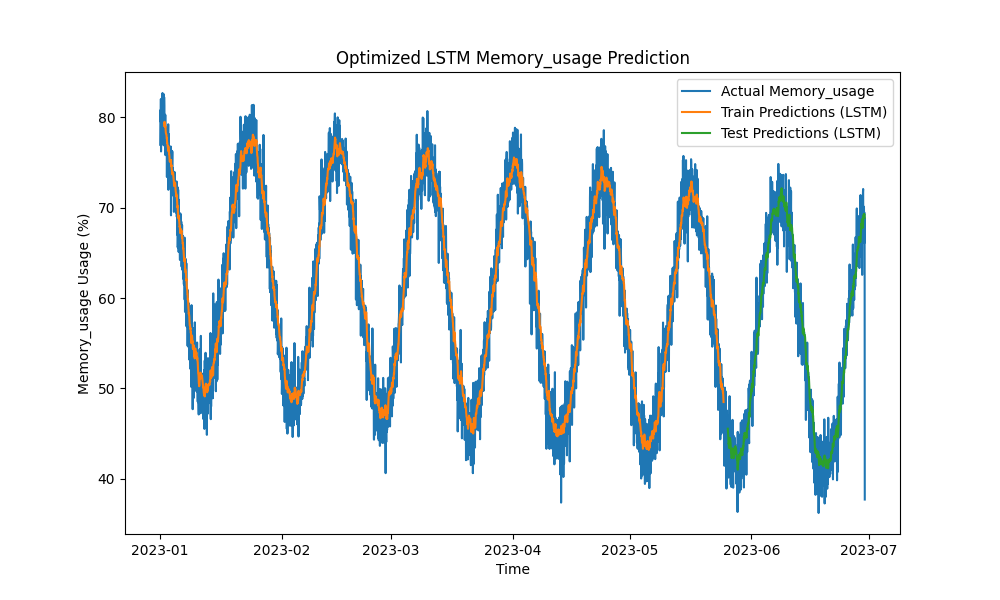
図3:最適化されたLSTMディスク使用量の予測
PostgreSQL監視ツールとの実用的な統合
LSTMモデルの有用性を最大限に引き出すために、PostgreSQLのモニタリングエコシステム内でさまざまな実用的な実装が探究されることがあります:
- pgAdmin 統合: pgAdmin は、実際のメトリクスとリアルタイムのリソース予測を視覚化するために拡張されることができ、DBAが潜在的なリソース不足に積極的に対応できるようにします。
- Grafana ダッシュボード: PostgreSQLのメトリクスを Grafana と統合し、パフォーマンスグラフにLSTMの予測をオーバーレイすることができます。予測される使用量が事前に定義されたしきい値を超えると予測される場合、アラートを設定してDBAに通知することができます。
- Prometheus モニタリング: Prometheus は、PostgreSQLのメトリクスをスクレイプし、LSTMの予測を使用して、予測されるリソース消費に基づいてアラートを生成し、予測を作成し、通知を設定することができます。
- クラウド環境での自動スケーリング: クラウドホスティングされたPostgreSQLインスタンス(例: AWS RDS、Google Cloud SQL)では、予測されるリソース需要の増加に基づいてオートスケーリングサービスをトリガーすることができます。
- CI/CD パイプライン: 機械学習モデルは新しいデータで継続的に更新され、再トレーニングされ、CI/CD パイプラインを通じてリアルタイムで展開されることができます。これにより、予測が正確であることが保証され、ワークロードが進化しても正確性が保たれます。
結論
LSTM(Long Short-Term Memory)機械学習モデルを適用して、CPU使用率、メモリ使用率、およびディスク使用率を予測することで、PostgreSQLの容量計画は反応型から予防的なアプローチへと移行することができます。当社の結果は、最適化されたLSTMモデルが正確な予測を提供し、より効率的なリソース管理とコスト削減を実現することを示しています、特にクラウドホステッド環境において。
データベースエコシステムがより複雑になるにつれて、これらの予測ツールは、リソースの利用を最適化し、ダウンタイムを防止し、拡張性を確保したいDBAにとって必須となります。規模の大きなPostgreSQLデータベースを管理している場合は、今こそ機械学習を活用して予測的な容量計画を行い、パフォーマンスの問題が発生する前にリソース管理を最適化する時です。
将来の展望
将来の改善点には、以下が含まれます:
- より不安定なワークロードを扱うために追加のニューラルネットワークアーキテクチャ(例:GRUまたはTransformerモデル)を試験すること。
- ネットワークトラフィックやストレージ最適化も重要な役割を果たす、マルチノードおよび分散PostgreSQL展開に方法論を拡張すること。
- リアルタイムアラートの実装および予測をPostgreSQLの運用スタックにさらに統合して、より自動化された管理を実現すること。
- Oracle Automated Workload Repository(AWR)データを使用してOracleデータベースのワークロード予測を試みること
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity