













Heutzutage bewegt sich die Datenbankwelt schnell in Richtung KI und ML, und die Arbeitslast von Datenbanken wird voraussichtlich erheblich zunehmen. Für einen Datenbankadministrator wird es eine zusätzliche Verantwortung sein, die Arbeitslast der Datenbankinfrastruktur im Voraus vorherzusagen und darauf einzugehen. Mit zunehmendem Skalieren von Datenbanken und der immer kritischer werdenden Ressourcenverwaltung reichen traditionelle Kapazitätsplanungsmethoden oft nicht aus, was zu Leistungsproblemen und ungeplanten Ausfallzeiten führt. PostgreSQL, eine der am weitesten verbreiteten Open-Source-Relationdatenbanken, bildet da keine Ausnahme. Mit steigenden Anforderungen an CPU, Speicher und Festplattenspeicher müssen Datenbankadministratoren (DBAs) proaktive Ansätze übernehmen, um Engpässe zu verhindern und die Effizienz zu verbessern.
In diesem Artikel werden wir untersuchen, wie Long Short-Term Memory (LSTM)-Maschinenlernmodelle zur Vorhersage des Ressourcenverbrauchs in PostgreSQL-Datenbanken angewendet werden können. Dieser Ansatz ermöglicht es DBAs, von reaktiver auf vorausschauende Kapazitätsplanung umzusteigen, um Ausfallzeiten zu reduzieren, die Ressourcenzuweisung zu verbessern und die Kosten für Überdimensionierung zu minimieren.
Warum vorausschauende Kapazitätsplanung wichtig ist
Durch den Einsatz von maschinellem Lernen können DBAs zukünftigen Ressourcenbedarf vorhersagen und darauf eingehen, bevor er kritisch wird, was zu folgendem führt:
- Reduzierte Ausfallzeiten: Frühes Erkennen von Ressourcenengpässen hilft, Unterbrechungen zu vermeiden.
- Verbesserte Effizienz: Ressourcen werden basierend auf tatsächlichen Bedürfnissen zugewiesen, um eine Überbereitstellung zu verhindern.
- Kosteneinsparungen: In Cloud-Umgebungen können genaue Ressourcenvorhersagen die Kosten für übermäßige Bereitstellung reduzieren.
Wie maschinelles Lernen die Ressourcenplanung für PostgreSQL optimieren kann
Um den PostgreSQL-Ressourcenverbrauch genau vorherzusagen, haben wir ein optimiertes LSTM-Modell angewendet, eine Art rekurrentes neuronales Netzwerk (RNN), das sich darauf spezialisiert hat, zeitliche Muster in Zeitreihendaten zu erfassen. LSTMs eignen sich gut für das Verstehen komplexer Abhängigkeiten und Sequenzen, was sie ideal für die Vorhersage der CPU-, Speicher- und Festplattennutzung in PostgreSQL-Umgebungen macht.
Methodik
Datensammlung
Option 1
Um das LSTM-Modell aufzubauen, müssen wir Leistungsdaten von verschiedenen PostgreSQL-Systemserver-OS-Befehlen und DB-Ansichten sammeln, wie z.B.:
pg_stat_activity(Details zu aktiven Verbindungen innerhalb der Postgres-Datenbank),vmstatfreedf
Die Daten können alle paar Minuten über sechs Monate erfasst werden, um einen umfassenden Datensatz für das Training des Modells bereitzustellen. Die gesammelten Metriken können in einer dedizierten Tabelle mit dem Namen capacity_metrics gespeichert werden.
Beispieltabellenschema:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Es gibt mehrere Möglichkeiten, um diese Systemdaten in diese Verlaufstabelle zu erfassen. Eine Möglichkeit besteht darin, das Python-Skript zu schreiben und über crontab für alle paar Minuten zu planen.
Option 2
Zur Flexibilität bei Tests können wir CPU-, Speicher- und Festplattenauslastungsmetriken mithilfe von Code (synthetische Datengenerierung) generieren und im Google Colab Notebook ausführen. Für die Analyse in diesem Papier haben wir diese Option verwendet. Die Schritte werden in den folgenden Abschnitten erläutert.
Machine Learning-Modell: Optimized LSTM
Das LSTM-Modell wurde aufgrund seiner Fähigkeit ausgewählt, langfristige Abhängigkeiten in Zeitreihendaten zu erlernen. Mehrere Optimierungen wurden angewendet, um die Leistung zu verbessern:
- Gestapelte LSTM-Schichten: Zwei LSTM-Schichten wurden gestapelt, um komplexe Muster in den Ressourcennutzungsdaten zu erfassen.
- Dropout-Regularisierung: Dropout-Schichten wurden nach jeder LSTM-Schicht hinzugefügt, um Überanpassung vorzubeugen und die Verallgemeinerung zu verbessern.
- Bidirektionales LSTM: Das Modell wurde bidirektional gemacht, um sowohl vorwärts als auch rückwärts Muster in den Daten zu erfassen.
- Optimierung der Lernrate: Eine Lernrate von 0,001 wurde für die Feinabstimmung des Lernprozesses des Modells gewählt.
Das Modell wurde für 20 Epochen mit einer Batch-Größe von 64 trainiert, und die Leistung wurde an nicht gesehenen Testdaten für CPU-, Speicher- und Speichernutzung gemessen.
Hier ist eine Zusammenfassung der Schritte zusammen mit Google Colab Notebook Screenshots, die bei der Dateneinrichtung und dem maschinellen Lernexperiment verwendet wurden:
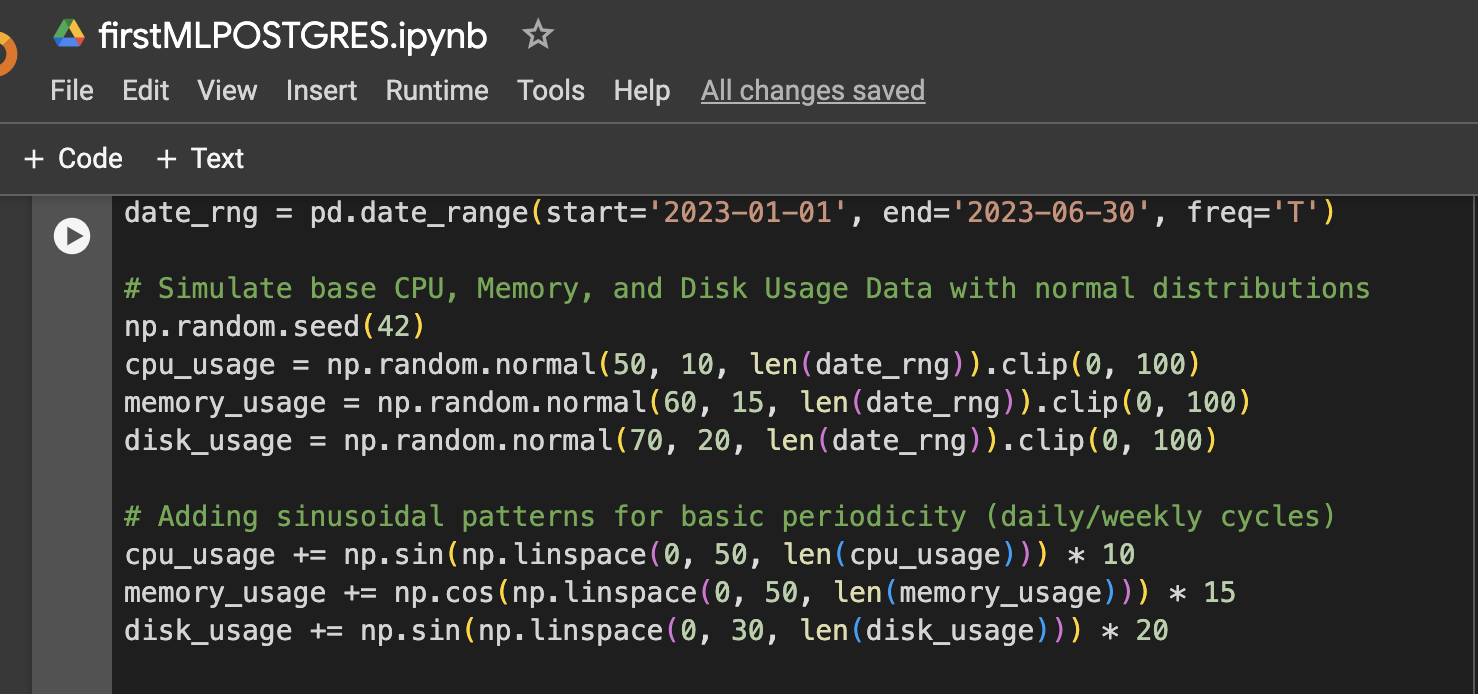
Schritt 1: Dateneinrichtung (Simulierte CPU-, Speicher- und Festplattenutzungsdaten für 6 Monate)
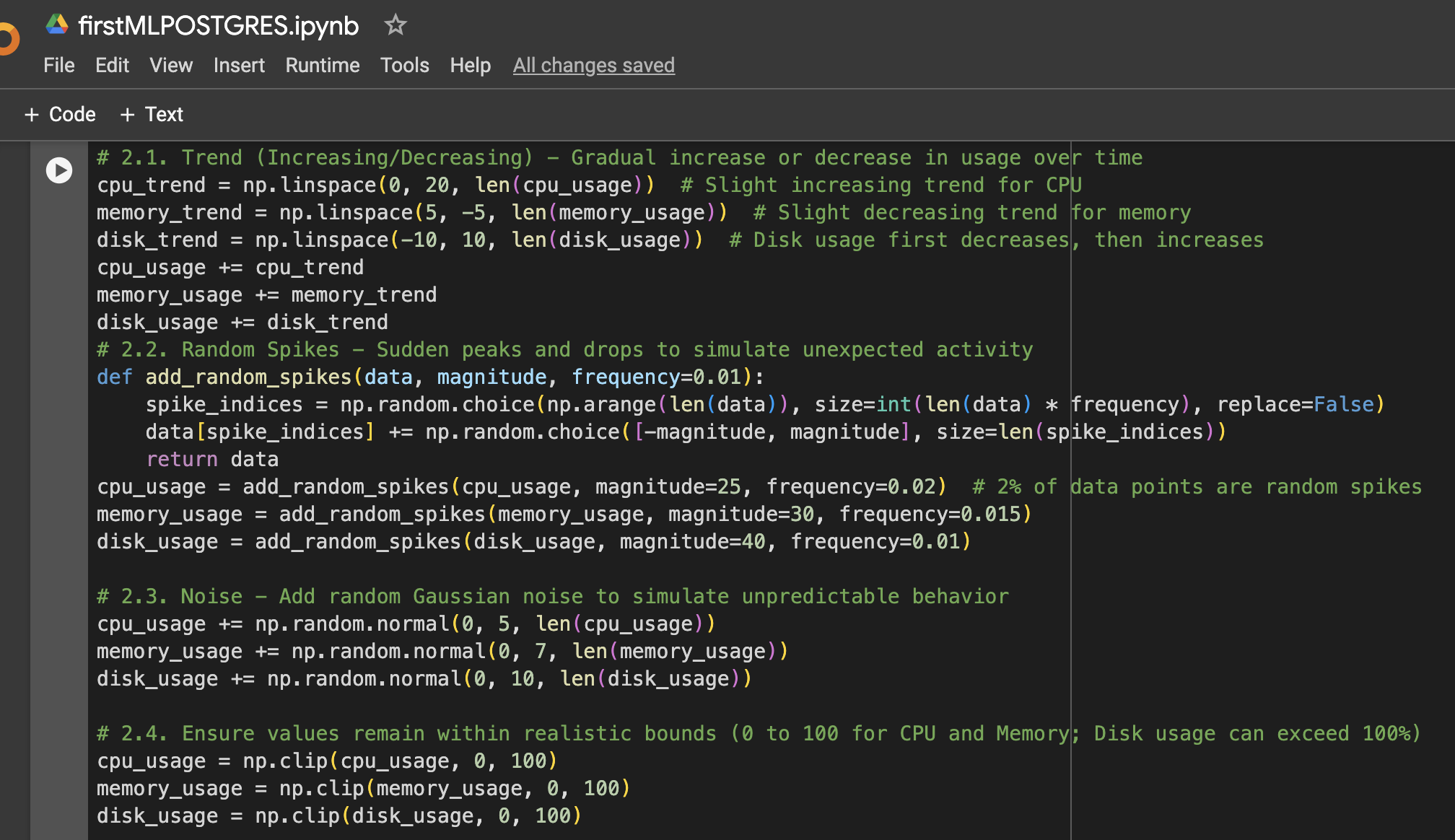
Schritt 2: Mehr Variationen zu den Daten hinzufügen
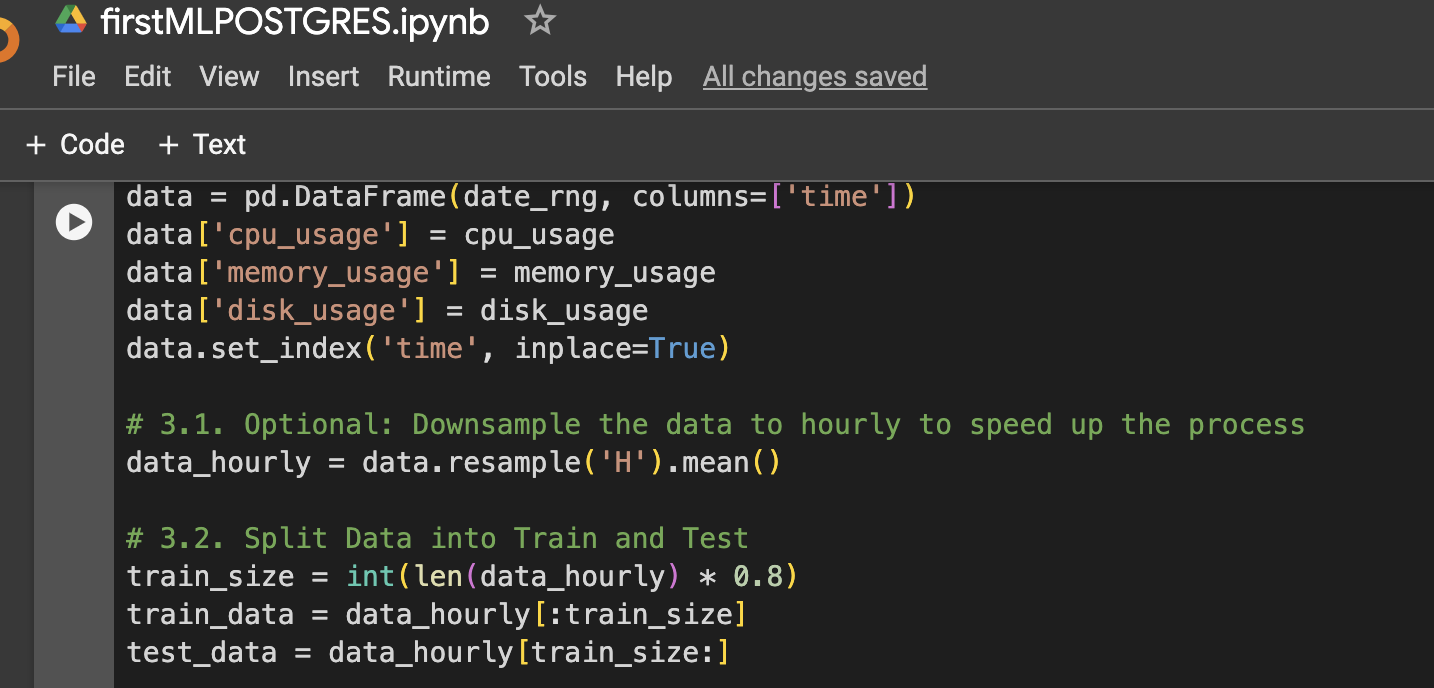
Schritt 3: DataFrame zur Visualisierung oder weiteren Verwendung erstellen
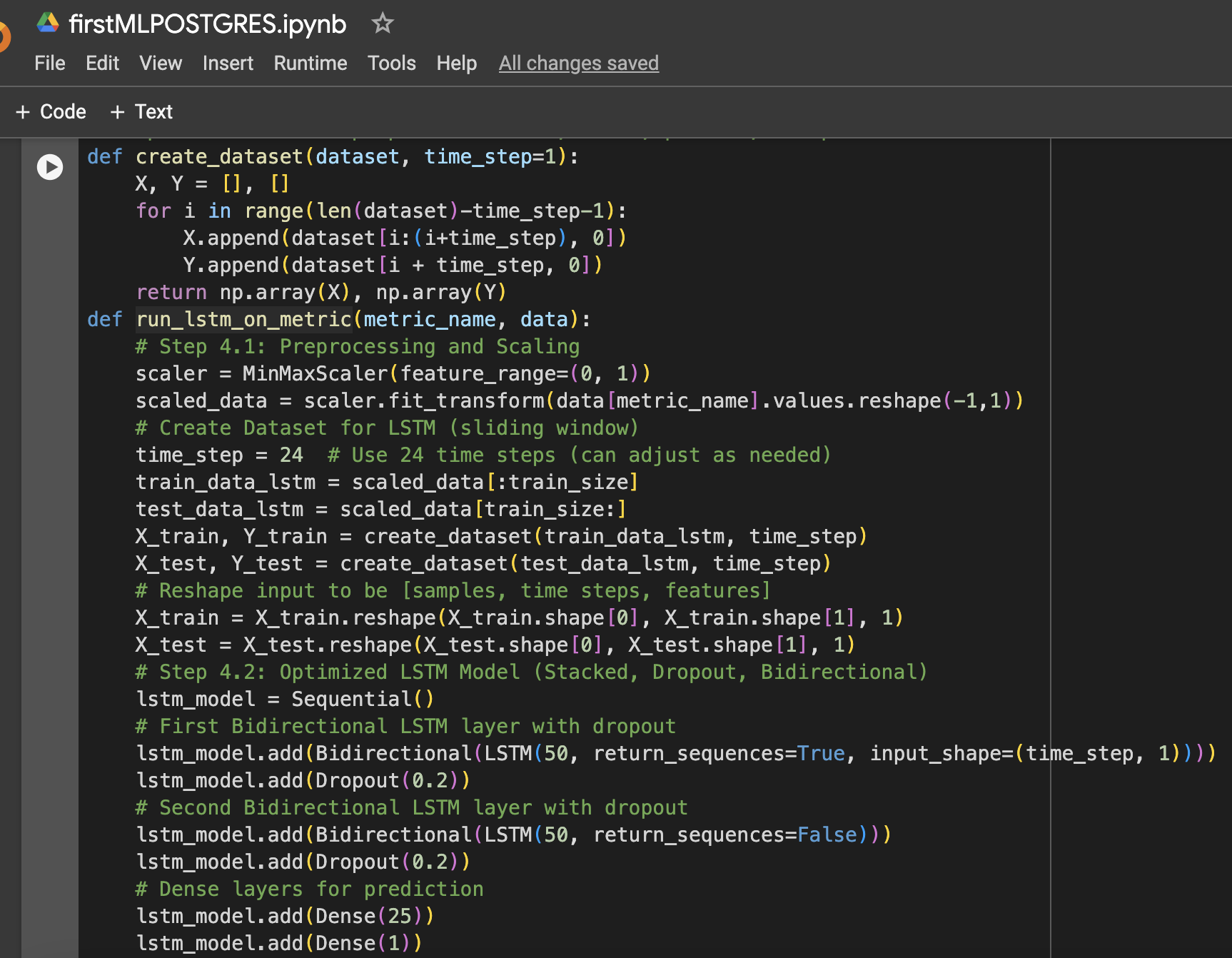
Schritt 4: Funktion zum Vorbereiten von LSTM-Daten, Trainieren, Vorhersagen und Plotten
Schritt 5: Das Modell für CPU, Speicher und Speicher ausführen
Ergebnisse
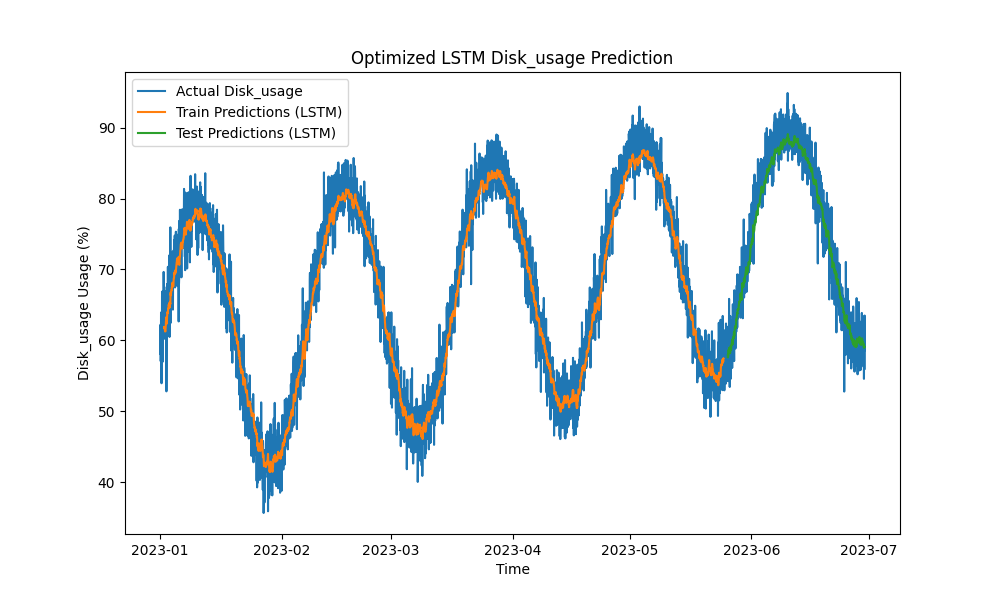
Das optimierte LSTM-Modell übertraf traditionelle Methoden wie ARIMA und lineare Regression bei der Vorhersage von CPU-, Speicher- und Festplattennutzung. Die Vorhersagen verfolgten eng die tatsächliche Ressourcennutzung und erfassten sowohl kurzfristige als auch langfristige Muster effektiv.
Hier sind die Visualisierungen der LSTM-Vorhersagen:
Abbildung 1: Optimierte LSTM-CPU-Nutzungsvorhersage
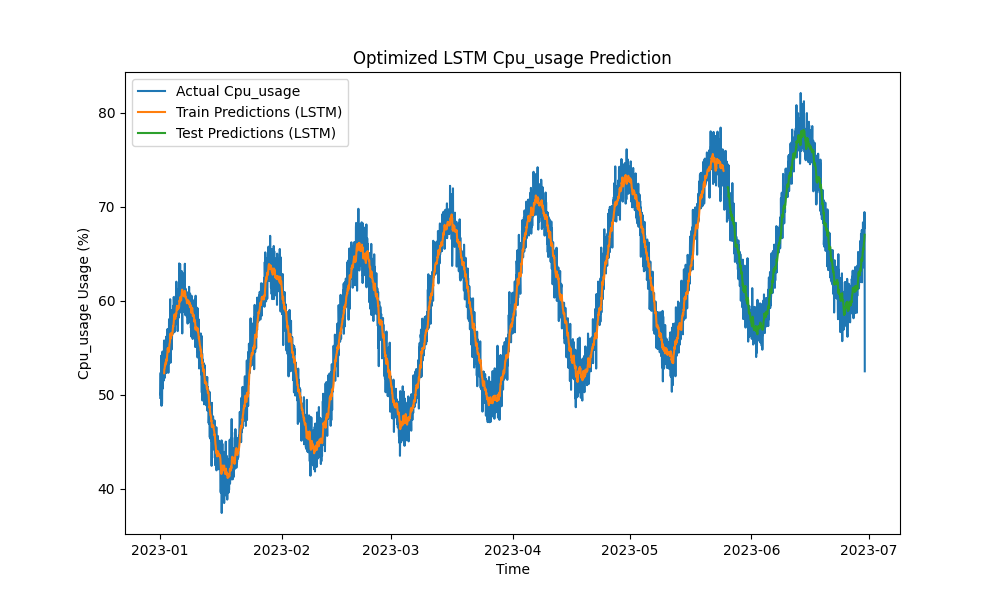
Abbildung 2: Optimierte LSTM-Speichernutzungsvorhersage
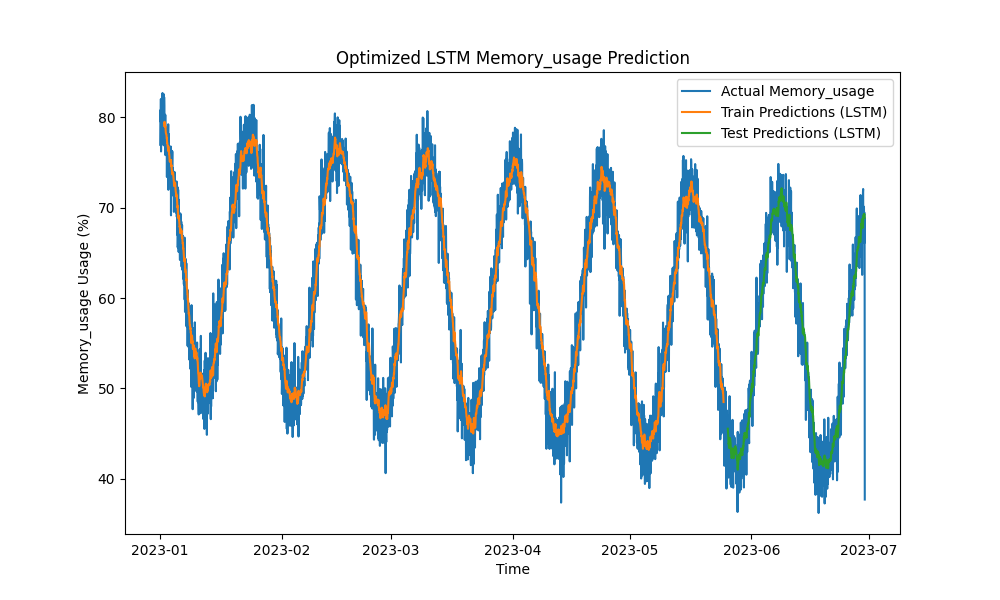
Abbildung 3: Optimierte LSTM-Festplattennutzungsvorhersage
Praktische Integration mit PostgreSQL-Überwachungstools
Um die Nützlichkeit des LSTM-Modells zu maximieren, können verschiedene praktische Umsetzungen innerhalb des Überwachungssystems von PostgreSQL erkundet werden:
- pgAdmin-Integration: pgAdmin kann erweitert werden, um Echtzeit-Ressourcenvorhersagen neben tatsächlichen Metriken zu visualisieren, sodass DBAs proaktiv auf potenzielle Ressourcenengpässe reagieren können.
- Grafana-Dashboards: PostgreSQL-Metriken können mit Grafana integriert werden, um LSTM-Vorhersagen auf Leistungsdiagrammen zu überlagern. Warnungen können konfiguriert werden, um DBAs zu benachrichtigen, wenn eine Überschreitung der vordefinierten Schwellenwerte bei der prognostizierten Nutzung erwartet wird.
- Prometheus-Überwachung: Prometheus kann PostgreSQL-Metriken abrufen und die LSTM-Vorhersagen verwenden, um bei prognostiziertem Ressourcenverbrauch Alarm zu schlagen, Prognosen zu erstellen und Benachrichtigungen einzurichten.
- Automatisches Skalieren in Cloud-Umgebungen: In cloud-basierten PostgreSQL-Instanzen (z. B. AWS RDS, Google Cloud SQL) kann das LSTM-Modell Autoscaling-Services auslösen, basierend auf prognostizierten Zunahmen der Ressourcennachfrage.
- CI/CD-Pipelines: Machine-Learning-Modelle können kontinuierlich mit neuen Daten aktualisiert, neu trainiert und in Echtzeit über CI/CD-Pipelines bereitgestellt werden, um sicherzustellen, dass Vorhersagen genau bleiben, während sich Arbeitslasten weiterentwickeln.
Abschluss
Durch die Anwendung von LSTM-Maschinenlernmodellen zur Vorhersage der CPU-, Speicher- und Festplattennutzung kann die PostgreSQL-Kapazitätsplanung von einem reaktiven zu einem proaktiven Ansatz übergehen. Unsere Ergebnisse zeigen, dass das optimierte LSTM-Modell genaue Vorhersagen liefert, die eine effizientere Ressourcenverwaltung und Kosteneinsparungen ermöglichen, insbesondere in Cloud-Umgebungen.
Da Datenbankökosysteme immer komplexer werden, sind diese Vorhersagewerkzeuge für DBAs, die die Ressourcennutzung optimieren, Ausfallzeiten verhindern und die Skalierbarkeit sicherstellen möchten, unerlässlich. Wenn Sie PostgreSQL-Datenbanken in großem Maßstab verwalten, ist jetzt der richtige Zeitpunkt, um maschinelles Lernen für die predictive Kapazitätsplanung zu nutzen und Ihre Ressourcenverwaltung zu optimieren, bevor Leistungsprobleme auftreten.
Zukünftige Arbeiten
Zukünftige Verbesserungen könnten beinhalten:
- Experimente mit zusätzlichen neuronalen Netzwerkarchitekturen (z.B. GRU- oder Transformer-Modelle) zur Bewältigung von volatileren Arbeitslasten.
- Erweiterung der Methodik auf Multi-Node- und verteilte PostgreSQL-Bereitstellungen, bei denen auch Netzwerkverkehr und Speicheroptimierung eine wichtige Rolle spielen.
- Implementierung von Echtzeitbenachrichtigungen und weitere Integration von Vorhersagen in den operationellen Stack von PostgreSQL für eine automatisiertere Verwaltung.
- Experimente mit Daten des Oracle Automated Workload Repository (AWR) für Vorhersagen der Arbeitslast in Oracle-Datenbanken.
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity