













今天,數據庫世界正迅速邁向人工智能和機器學習,數據庫的工作量預計將顯著增加。對於數據庫管理員來說,預測數據庫基礎設施的工作量並應對相應需求將成為一項額外責任。隨著數據庫規模擴大和資源管理變得日益關鍵,傳統的容量規劃方法通常會有所不足,導致性能問題和計劃外停機。PostgreSQL,作為最廣泛使用的開源關係數據庫之一,也不例外。隨著對CPU、內存和磁盤空間需求的增加,數據庫管理員(DBA)必須採取主動方法來防止瓶頸並提高效率。
在本文中,我們將探討如何應用長短期記憶(LSTM)機器學習模型來預測PostgreSQL數據庫中的資源消耗。這種方法使DBA能夠從被動轉為主動的容量規劃,從而減少停機時間,改善資源分配,並降低過度配置成本。
為什麼預測容量規劃很重要
通過利用機器學習,DBA可以在資源變得關鍵之前預測未來的資源需求並加以應對,帶來以下好處:
- 減少停機時間:早期檢測資源短缺有助於避免中斷。
- 提高效率:根據實際需求分配資源,避免過度配置。
- 節省成本:在雲環境中,準確的資源預測可以降低過度配置的成本。
機器學習如何優化 PostgreSQL 資源規劃
為了準確預測 PostgreSQL 的資源使用情況,我們應用了一種優化的 LSTM 模型,一種遞歸神經網絡(RNN),它擅長捕捉時間序列數據中的時間模式。 LSTMs 非常適合理解複雜的依賴關係和序列,使其成為預測 PostgreSQL 環境中的 CPU、內存和磁碟使用情況的理想選擇。
方法論
數據收集
選項 1
為了構建 LSTM 模型,我們需要從各種 PostgreSQL 系統伺服器 OS 命令和數據庫視圖中收集性能數據,例如:
pg_stat_activity(Postgres 數據庫中的活動連接詳細信息),vmstatfreedf
數據可以每幾分鐘捕獲一次,為訓練模型提供全面的數據集,持續六個月。收集到的指標可以存儲在名為capacity_metrics的專用表中。
樣本表結構:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);有多種方法可以將系統數據捕獲到歷史表中。其中一種方法是編寫Python腳本並通過crontab設置每幾分鐘運行一次。
選擇2
為了測試靈活性,我們可以使用代碼(合成數據生成)生成CPU、內存和磁盤使用率指標,並在Google Colab Notebook上執行。在這篇論文的測試分析中,我們使用了這個選項。具體步驟將在下面的章節中解釋。
機器學習模型: 優化的LSTM
選擇LSTM模型是因為它能夠學習時間序列數據中的長期依賴關係。為了提高其性能,應用了幾個優化措施:
- 堆疊的LSTM層:堆疊了兩個LSTM層,以捕獲資源使用數據中的複雜模式。
- Dropout正則化:在每個LSTM層後添加了Dropout層,以防止過擬合並提高泛化能力。
- 雙向LSTM:使模型具有雙向性,以捕獲數據中的正向和反向模式。
- 學習率優化:選擇了學習率為0.001,用於微調模型的學習過程。
模型使用批量大小為64進行了20個時代的訓練,並在未見測試數據上測量了CPU、內存和存儲(磁盤)的性能。
以下是步驟摘要,以及用於數據設置和機器學習實驗的Google Colab Notebook截圖:
步驟1:數據設置(模擬CPU、內存、磁盤使用數據為期6個月)
步驟2:為數據添加更多變化
步驟3:創建用於可視化或進一步使用的DataFrame
步驟4:準備LSTM數據、訓練、預測和繪圖的函數
步驟5:運行CPU、內存和存儲模型
結果
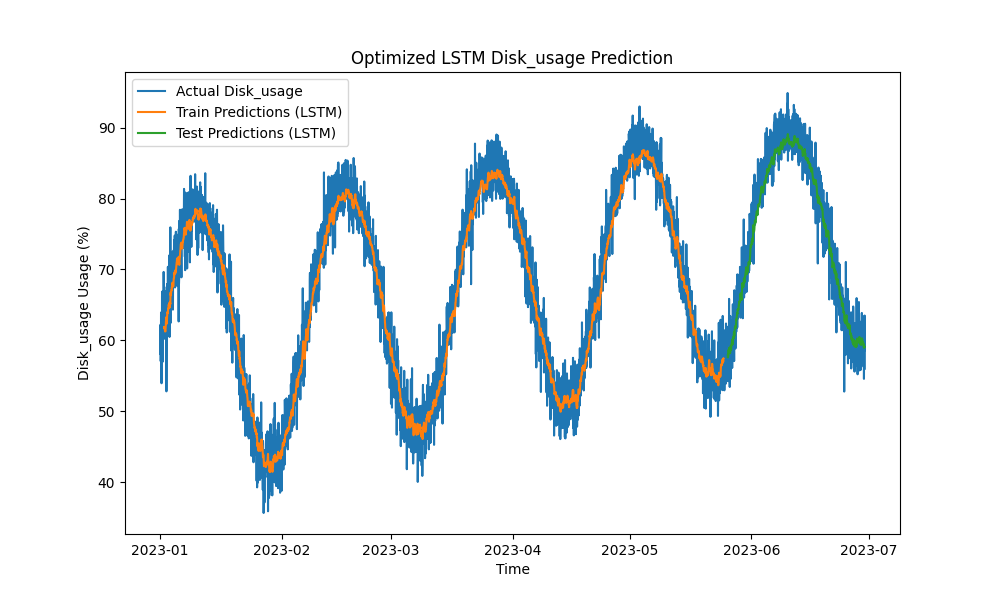
優化的LSTM模型在預測CPU、內存和磁盤使用方面優於ARIMA和線性回歸等傳統方法。預測緊密跟踪實際資源使用情況,有效捕捉了短期和長期模式。
以下是LSTM預測的可視化:
圖1:優化的LSTM CPU使用率預測
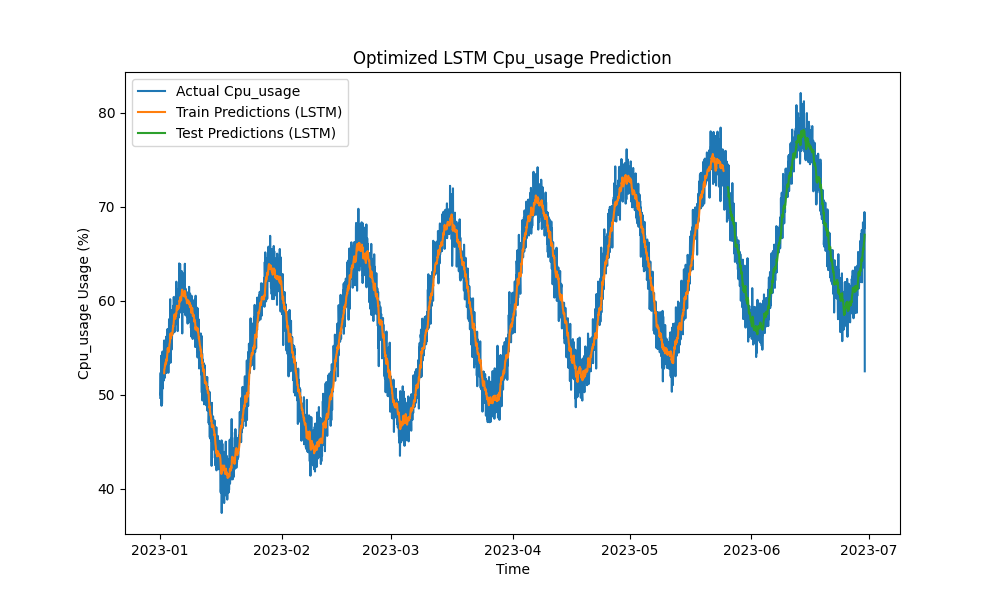
圖2:優化的LSTM內存使用率預測
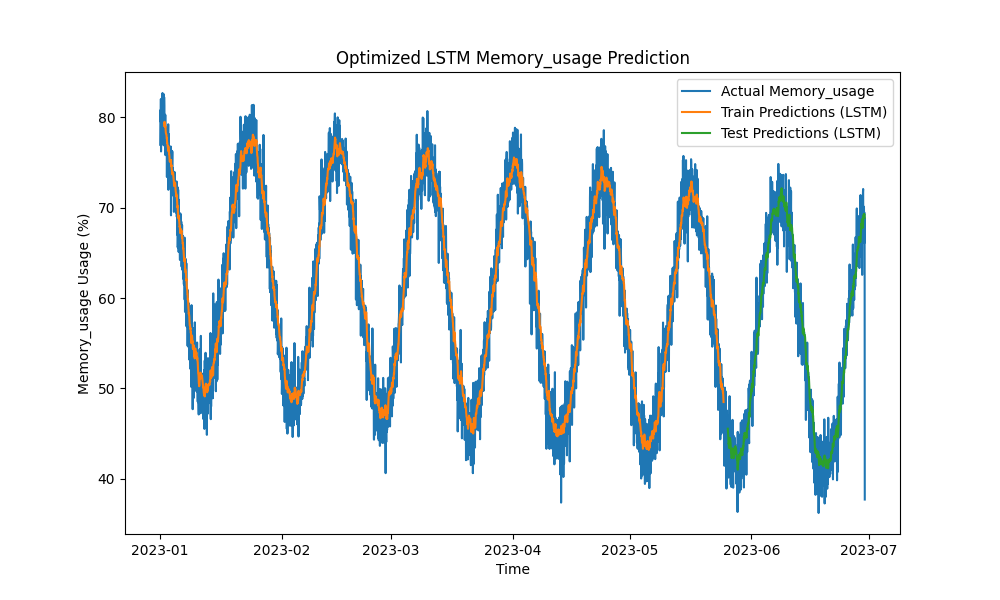
圖3:優化的LSTM磁盤使用率預測
與PostgreSQL監控工具的實際整合
為了最大化LSTM模型的效用,可以探索在PostgreSQL監控生態系統中實現各種實際應用:
- pgAdmin整合:pgAdmin可以擴展以在實際指標旁視覺化即時資源預測,讓資料庫管理員主動應對潛在的資源不足。
- Grafana儀表板:PostgreSQL指標可以與Grafana集成,將LSTM預測覆蓋在性能圖上。可以配置警報,通知資料庫管理員當預測使用量預計超過預定閾值時。
- Prometheus監控:Prometheus可以採集PostgreSQL指標並使用LSTM預測來警報、生成預測,並基於預測的資源消耗設置通知。
- 雲環境中的自動擴展:在雲端託管的PostgreSQL實例中(例如AWS RDS、Google Cloud SQL),LSTM模型可以基於預測的資源需求增加來觸發自動擴展服務。
- CI/CD流水線:機器學習模型可以通過CI/CD流水線持續使用新數據進行更新、重新訓練並實時部署,確保預測隨著工作量演變而保持準確。
結論
通過應用LSTM機器學習模型來預測CPU、內存和磁盤使用情況,PostgreSQL容量規劃可以從被動轉為主動。我們的結果顯示,優化的LSTM模型提供準確的預測,使得更有效的資源管理和成本節省成為可能,特別是在雲端環境中。
隨著數據庫生態系統變得更加複雜,這些預測工具對於希望優化資源利用、防止停機並確保可擴展性的數據庫管理員至關重要。如果您正在大規模管理PostgreSQL數據庫,現在是利用機器學習進行預測容量規劃並在性能問題出現之前優化資源管理的時候。
未來工作
未來的改進可能包括:
- 嘗試使用其他神經網絡架構(例如GRU或Transformer模型)來應對更加波動的工作負載。
- 將方法擴展到多節點和分佈式的PostgreSQL部署中,其中網絡流量和存儲優化也發揮重要作用。
- 實施實時警報,並將預測進一步整合到PostgreSQL的運營堆棧中,以便進行更自動化的管理。
- 嘗試使用Oracle 自動工作負載存儲庫(AWR)數據來進行Oracle數據庫工作負載預測
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity