













Vandaag de dag beweegt de wereld van databases zich snel richting AI en ML, en de werklast van databases zal naar verwachting aanzienlijk toenemen. Voor een databasebeheerder wordt het een extra verantwoordelijkheid om de werklast van de database-infrastructuur van tevoren te voorspellen en aan de behoefte te voldoen. Naarmate databases opschalen en het beheer van middelen steeds kritischer wordt, vallen traditionele capaciteitsplanningsmethoden vaak tekort, wat leidt tot prestatieproblemen en ongeplande uitvaltijd. PostgreSQL, een van de meest gebruikte open-source relationele databases, is hierop geen uitzondering. Met de toenemende vraag naar CPU, geheugen en schijfruimte moeten databasebeheerders (DBA’s) proactieve benaderingen aannemen om knelpunten te voorkomen en de efficiëntie te verbeteren.
In dit artikel zullen we onderzoeken hoe Long Short-Term Memory (LSTM) machine learning-modellen kunnen worden toegepast om het middelenverbruik in PostgreSQL-databases te voorspellen. Deze benadering stelt DBA’s in staat om over te schakelen van reactieve naar voorspellende capaciteitsplanning, wat resulteert in minder uitvaltijd, een betere toewijzing van middelen en een minimalisatie van overprovisioneringskosten.
Waarom voorspellende capaciteitsplanning belangrijk is
Door gebruik te maken van machine learning kunnen DBA’s de toekomstige middelenbehoeften voorspellen en deze aanpakken voordat ze kritiek worden, wat leidt tot:
- Verminderde uitvaltijd: Vroegtijdige detectie van middelengebrek helpt om verstoringen te voorkomen.
- Verbeterde efficiëntie: Middelen worden toegewezen op basis van werkelijke behoeften, waardoor overprovisioning wordt voorkomen.
- Kostenbesparingen: In cloudomgevingen kunnen nauwkeurige voorspellingen van middelen de kosten van overmatige provisioning verlagen.
Hoe Machine Learning PostgreSQL Resource Planning kan Optimaliseren
Om PostgreSQL-hulpmiddelen nauwkeurig te voorspellen, hebben we een geoptimaliseerd LSTM-model toegepast, een type terugkerend neuraal netwerk (RNN) dat uitblinkt in het vastleggen van temporele patronen in tijdreeksgegevens. LSTMs zijn goed geschikt voor het begrijpen van complexe afhankelijkheden en sequenties, waardoor ze ideaal zijn voor het voorspellen van CPU-, geheugen- en schijfgebruik in PostgreSQL-omgevingen.
Methode
Gegevensverzameling
Optie 1
Om het LSTM-model te bouwen, moeten we prestatiegegevens verzamelen van verschillende PostgreSQL-systeemserver OS-opdrachten en db-weergaven, zoals:
pg_stat_activity(actieve verbindingsdetails binnen de Postgres-database),vmstatfreedf
De gegevens kunnen elke paar minuten gedurende zes maanden worden vastgelegd, wat een uitgebreide dataset oplevert voor het trainen van het model. De verzamelde metrics kunnen worden opgeslagen in een speciale tabel genaamd capacity_metrics.
Voorbeeld Tabel Schema:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Er zijn meerdere manieren om deze systeemgegevens in deze geschiedenis tabel vast te leggen. Een van de manieren is om het Python-script te schrijven en dit via crontab elke paar minuten te plannen.
Optie 2
Voor testflexibiliteit kunnen we CPU-, geheugen- en schijfgebruikmetrics genereren met behulp van code (synthetische gegevensgeneratie) en uitvoeren met de Google Colab Notebook. Voor deze papertests analyse hebben we deze optie gebruikt. De stappen worden in de volgende secties uitgelegd.
Machine Learning Model: Geoptimaliseerde LSTM
Het LSTM-model werd geselecteerd vanwege zijn vermogen om langetermijnafhankelijkheden in tijdreeksen te leren. Verschillende optimalisaties zijn toegepast om de prestaties te verbeteren:
- Gestapelde LSTM-lagen: Twee LSTM-lagen zijn gestapeld om complexe patronen in de resourcegebruikgegevens vast te leggen.
- Dropout-regularisatie: Dropout-lagen werden toegevoegd na elke LSTM-laag om overfitting te voorkomen en de generalisatie te verbeteren.
- Bidirectionele LSTM: Het model werd bidirectioneel gemaakt om zowel voorwaartse als achterwaartse patronen in de gegevens vast te leggen.
- Optimalisatie van leersnelheid: Een leersnelheid van 0,001 werd gekozen voor het verfijnen van het leerproces van het model.
Het model werd getraind gedurende 20 epochs met een batchgrootte van 64, en de prestaties werden gemeten op ongeziene testgegevens voor CPU, geheugen en opslag (schijf) gebruik.
Hieronder volgt een samenvatting van de stappen samen met Google Colab Notebook schermafbeeldingen die zijn gebruikt bij de gegevensopzet en het machine learning-experiment:
Stap 1: Gegevensopzet (gesimuleerde CPU-, geheugen- en schijfgebruiksgegevens voor 6 maanden)
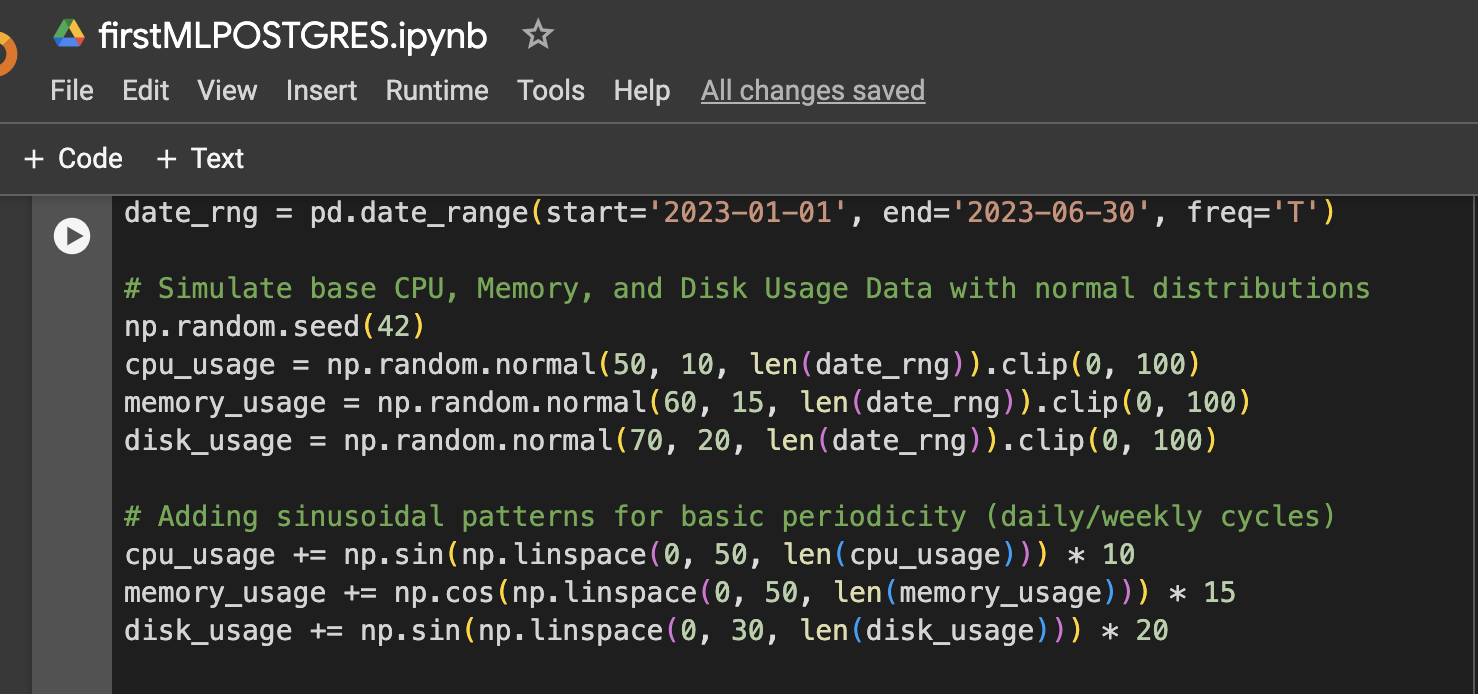
Stap 2: Meer variatie toevoegen aan de gegevens
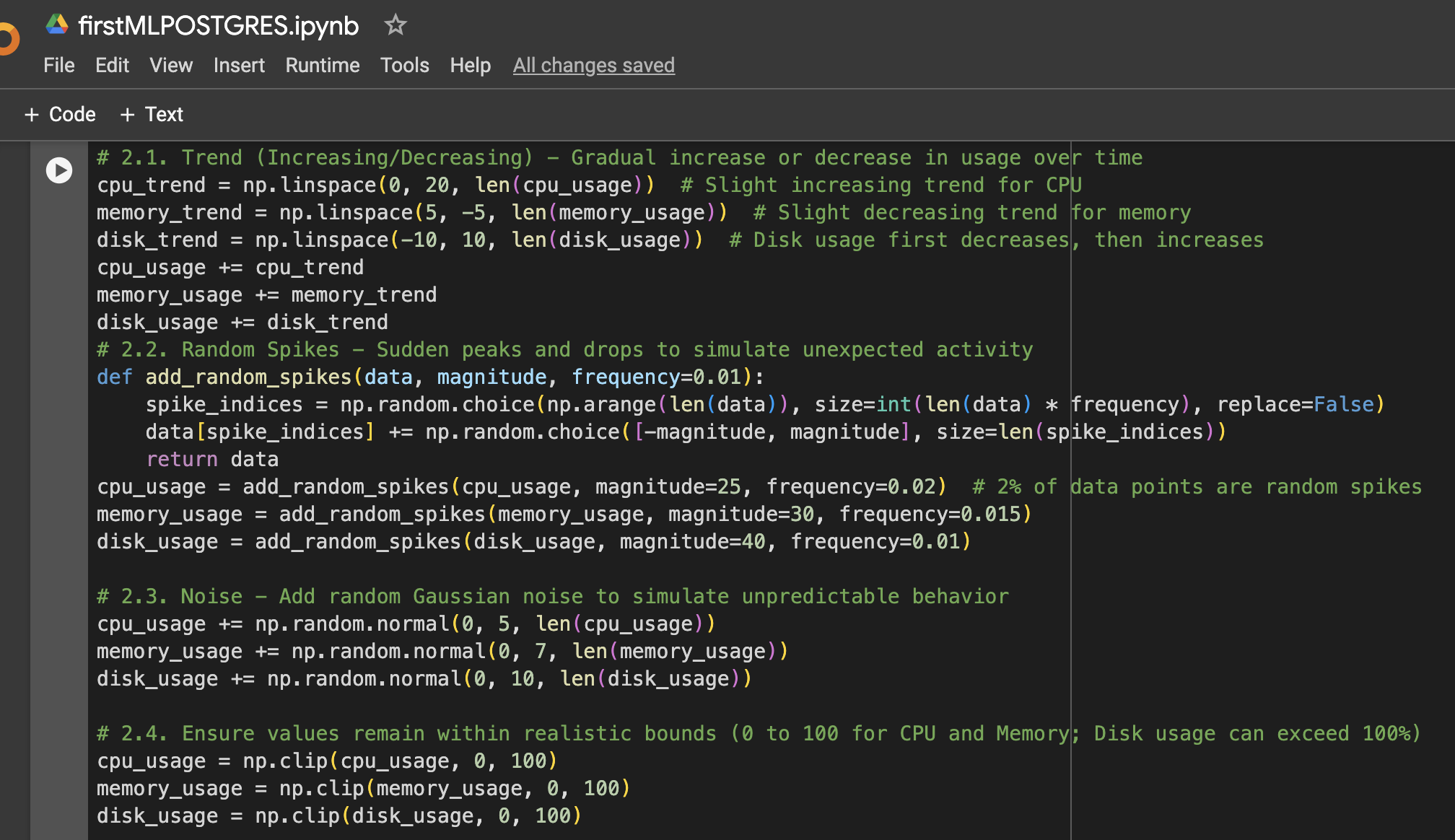
Stap 3: DataFrame maken voor visualisatie of verdere gebruik
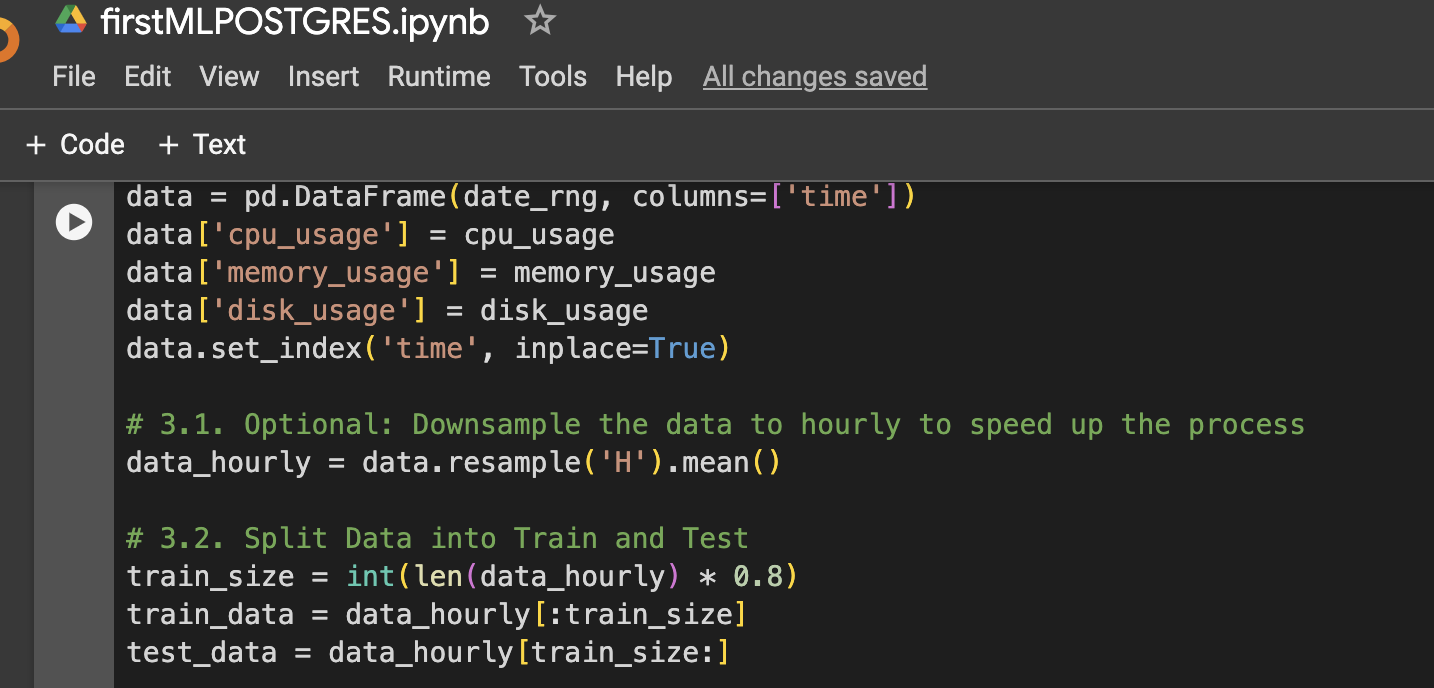
Stap 4: Functie om LSTM-gegevens voor te bereiden, te trainen, voorspellen en plotten
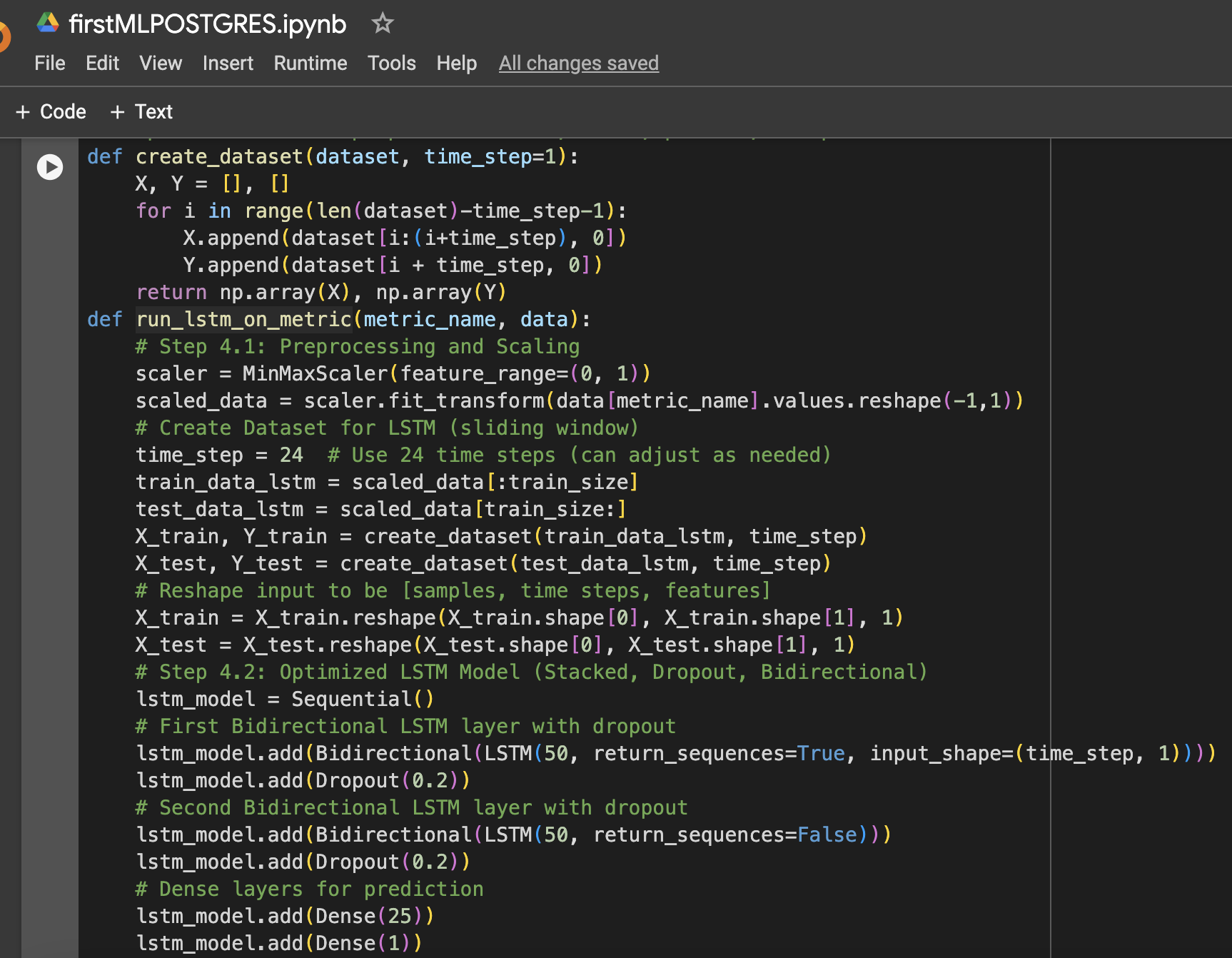
Stap 5: Voer het model uit voor CPU, geheugen en opslag
Resultaten
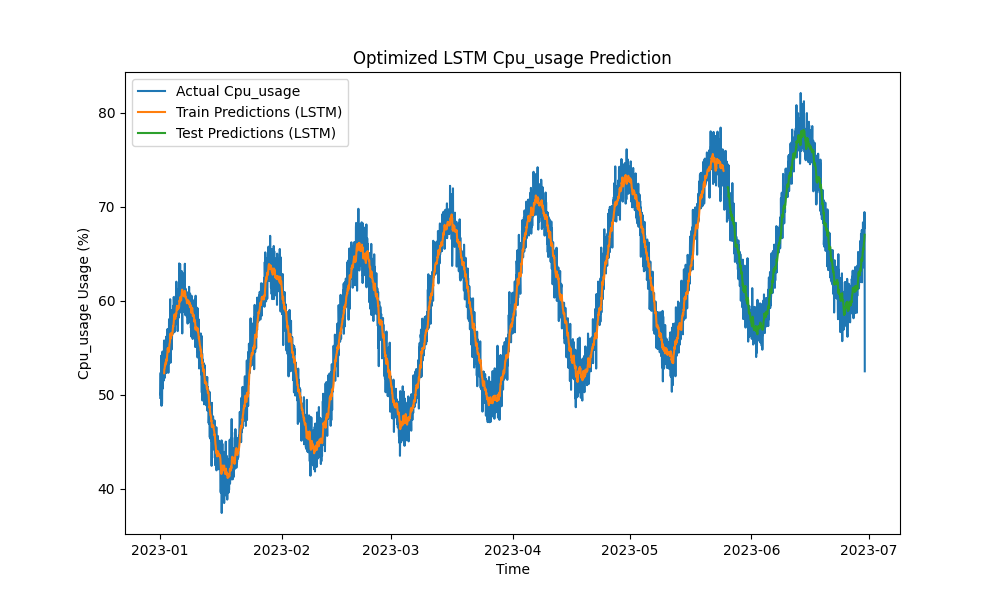
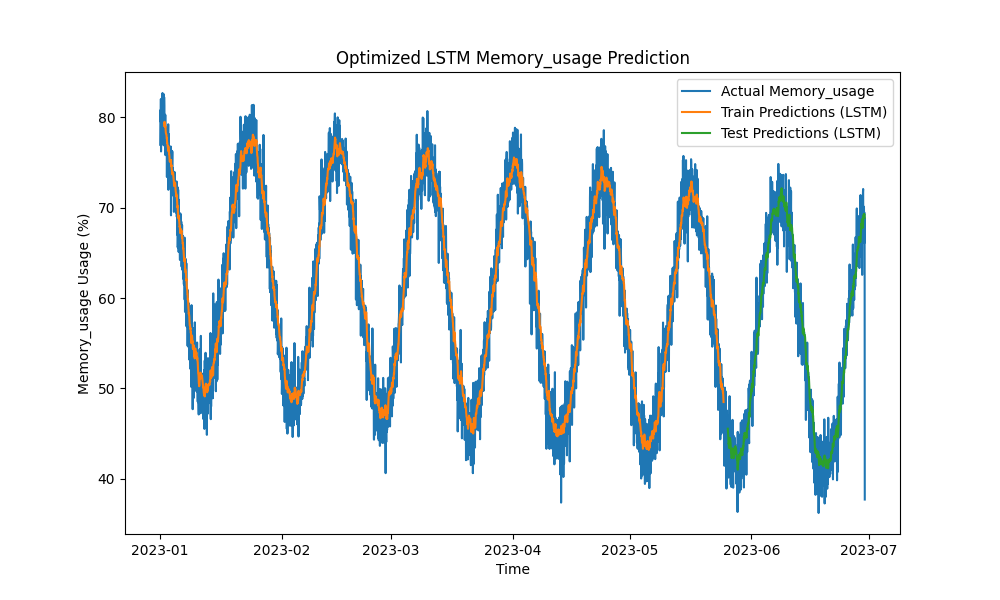
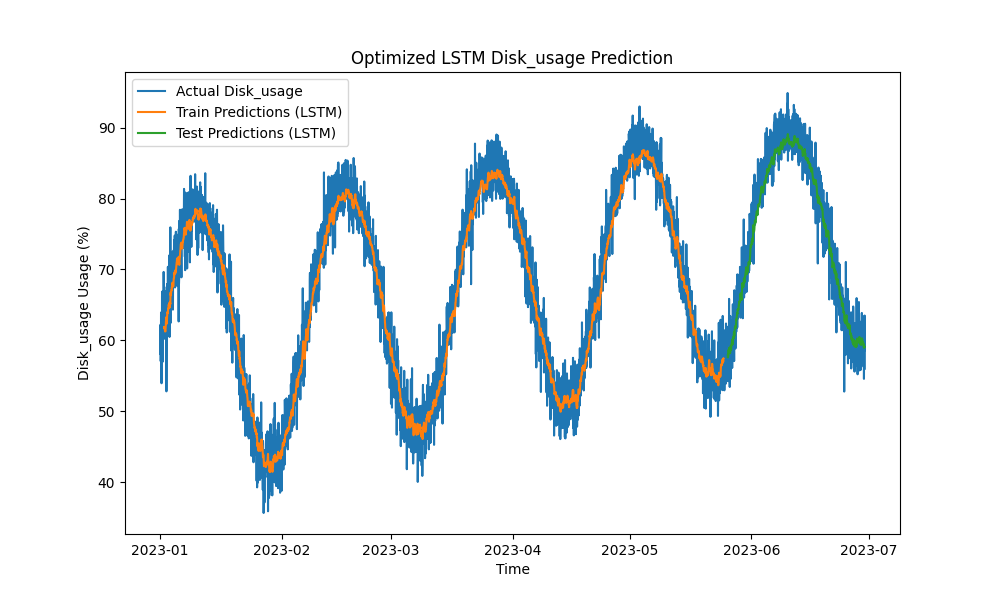
Het geoptimaliseerde LSTM-model presteerde beter dan traditionele methoden zoals ARIMA en lineaire regressie bij het voorspellen van CPU-, geheugen- en schijfgebruik. De voorspellingen volgden nauwkeurig het daadwerkelijke gebruik van hulpbronnen en legden zowel de korte- als langetermijnpatronen effectief vast.
Hier zijn de visualisaties van de LSTM-voorspellingen:
Figuur 1: Geoptimaliseerde LSTM-voorspelling van CPU-gebruik
Figuur 2: Geoptimaliseerde LSTM-voorspelling van geheugengebruik
Figuur 3: Geoptimaliseerde LSTM-voorspelling van schijfgebruik
Praktische integratie met PostgreSQL Monitoringtools
Om het nut van het LSTM-model te maximaliseren, kunnen verschillende praktische implementaties binnen het monitoring-ecosysteem van PostgreSQL worden verkend:
- pgAdmin-integratie: pgAdmin kan worden uitgebreid om realtime resource voorspellingen naast daadwerkelijke metingen te visualiseren, waardoor DBA’s proactief kunnen reageren op mogelijke resource tekorten.
- Grafana dashboards: PostgreSQL-metrieken kunnen worden geïntegreerd met Grafana om LSTM-voorspellingen te tonen op prestatiegrafieken. Waarschuwingen kunnen worden geconfigureerd om DBA’s op de hoogte te stellen wanneer wordt verwacht dat het voorspelde gebruik de vooraf gedefinieerde drempels zal overschrijden.
- Prometheus monitoring: Prometheus kan PostgreSQL-metrieken schrapen en de LSTM-voorspellingen gebruiken om waarschuwingen te genereren, voorspellingen te maken en meldingen in te stellen op basis van voorspelde resourceconsumptie.
- Geautomatiseerd schalen in cloudomgevingen: In cloud-gehoste PostgreSQL-instanties (bijv. AWS RDS, Google Cloud SQL) kan het LSTM-model autoscaling-services activeren op basis van voorspelde toenames in de resourcevraag.
- CI/CD-pipelines: Machine learning-modellen kunnen continu worden bijgewerkt met nieuwe gegevens, opnieuw worden getraind en in realtime worden ingezet via CI/CD-pipelines, waardoor wordt gegarandeerd dat voorspellingen accuraat blijven naarmate workloads evolueren.
Conclusie
Door LSTM-machine learningmodellen toe te passen om CPU-, geheugen- en schijfgebruik te voorspellen, kan de capaciteitsplanning van PostgreSQL verschuiven van een reactieve naar een proactieve aanpak. Onze resultaten tonen aan dat het geoptimaliseerde LSTM-model nauwkeurige voorspellingen biedt, waardoor efficiënter resourcebeheer en kostenbesparingen mogelijk zijn, vooral in cloud-gehoste omgevingen.
Naarmate database-ecosystemen complexer worden, worden deze voorspellende tools essentieel voor DBA’s die resourcegebruik willen optimaliseren, downtime willen voorkomen en schaalbaarheid willen waarborgen. Als je PostgreSQL-databases op grote schaal beheert, is het nu de tijd om machine learning te benutten voor voorspellende capaciteitsplanning en je resourcebeheer te optimaliseren voordat prestatiedoelstellingen in gevaar komen.
Toekomstig Werk
Toekomstige verbeteringen kunnen onder meer omvatten:
- Experimenteren met aanvullende neurale netwerkarchitecturen (bijv. GRU- of Transformer-modellen) om meer volatiele werklasten aan te kunnen.
- De methodologie uitbreiden naar multi-node en gedistribueerde PostgreSQL-implementaties, waar netwerkverkeer en opslagoptimalisatie ook een significante rol spelen.
- Real-time waarschuwingen implementeren en voorspellingen verder integreren in de operationele stack van PostgreSQL voor meer geautomatiseerd beheer.
- Experimenteren met Oracle Automated Workload Repository (AWR)-gegevens voor voorspellingen van werklasten van Oracle-databases.
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity