













Oggi, il mondo dei database si sta rapidamente orientando verso l’AI e l’ML, e ci si aspetta un aumento significativo del carico di lavoro dei database. Per un amministratore di database, sarà un’ulteriore responsabilità prevedere in anticipo il carico di lavoro dell’infrastruttura del database e affrontare la necessità. Man mano che i database crescono e la gestione delle risorse diventa sempre più critica, i metodi tradizionali di pianificazione della capacità spesso non sono sufficienti, portando a problemi di prestazioni e tempi di inattività non pianificati. PostgreSQL, uno dei database relazionali open-source più ampiamente utilizzati, non fa eccezione. Con l’aumento delle richieste di CPU, memoria e spazio su disco, gli amministratori di database (DBA) devono adottare approcci proattivi per prevenire i colli di bottiglia e migliorare l’efficienza.
In questo articolo, esploreremo come i modelli di machine learning Long Short-Term Memory (LSTM) possono essere applicati per prevedere il consumo di risorse nei database PostgreSQL. Questo approccio consente ai DBA di passare da una pianificazione della capacità reattiva a una predittiva, riducendo così i tempi di inattività, migliorando l’allocazione delle risorse e minimizzando i costi di sovradimensionamento.
Perché è Importante la Pianificazione della Capacità Predittiva
Sfruttando il machine learning, i DBA possono prevedere i futuri bisogni di risorse e affrontarli prima che diventino critici, con i seguenti risultati:
- Riduzione dei tempi di inattività: La rilevazione anticipata delle carenze di risorse aiuta a evitare interruzioni.
- Miglioramento dell’efficienza: Le risorse vengono allocate in base ai reali bisogni, evitando sovradimensionamenti.
- Risparmio sui costi: Negli ambienti cloud, previsioni accurate sulle risorse possono ridurre il costo dell’eccessivo provisioning.
Come il Machine Learning può ottimizzare la pianificazione delle risorse di PostgreSQL
Per prevedere accuratamente l’utilizzo delle risorse di PostgreSQL, abbiamo applicato un modello LSTM ottimizzato, un tipo di rete neurale ricorrente (RNN) che eccelle nel catturare modelli temporali nei dati in serie temporale. Le LSTM sono particolarmente adatte per comprendere dipendenze complesse e sequenze, rendendole ideali per prevedere l’utilizzo della CPU, della memoria e del disco negli ambienti di PostgreSQL.
Metodologia
Raccolta dei dati
Opzione 1
Per costruire il modello LSTM, è necessario raccogliere dati sulle prestazioni da vari comandi di sistema del server PostgreSQL e dalle viste del database, come:
pg_stat_activity(dettagli sulle connessioni attive all’interno del database di Postgres),vmstatfreedf
I dati possono essere acquisiti ogni pochi minuti per sei mesi, fornendo un dataset completo per addestrare il modello. Le metriche raccolte possono essere memorizzate in una tabella dedicata chiamata capacity_metrics.
Schema della Tabella di Esempio:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Ci sono molteplici modi per acquisire questi dati di sistema in questa tabella storica. Uno dei modi è scrivere lo script Python e pianificarlo tramite crontab per essere eseguito ogni pochi minuti.
Opzione 2
Per testare la flessibilità, possiamo generare metriche di utilizzo della CPU, della memoria e del disco utilizzando il codice (generazione di dati sintetici) ed eseguirlo utilizzando il Notebook Google Colab. Per questa analisi di test, abbiamo utilizzato questa opzione. I passaggi sono spiegati nelle sezioni seguenti.
Modello di Apprendimento Automatico: LSTM Ottimizzato
Il modello LSTM è stato selezionato per la sua capacità di apprendere dipendenze a lungo termine nei dati in serie temporale. Sono state applicate diverse ottimizzazioni per migliorarne le prestazioni:
- Strati LSTM in pila: Sono stati impilati due strati LSTM per catturare pattern complessi nei dati di utilizzo delle risorse.
- Regolarizzazione Dropout: Sono stati aggiunti strati di Dropout dopo ciascuno strato LSTM per prevenire l’overfitting e migliorare la generalizzazione.
- LSTM Bidirezionale: Il modello è stato reso bidirezionale per catturare pattern sia in avanti che all’indietro nei dati.
- Ottimizzazione del tasso di apprendimento : È stato scelto un tasso di apprendimento di 0,001 per ottimizzare il processo di apprendimento del modello.
Il modello è stato allenato per 20 epoche con una dimensione di batch di 64, e le prestazioni sono state misurate su dati di test non visti per l’utilizzo di CPU, memoria e storage (disco).
Di seguito è riportato un riepilogo dei passaggi insieme agli screenshot del Notebook di Google Colab utilizzati nella configurazione dei dati e nell’esperimento di machine learning:
Passaggio 1: Configurazione dei dati (Dati simulati sull’utilizzo di CPU, memoria e disco per 6 mesi)
Passaggio 2: Aggiungi maggiore variazione ai dati
Passaggio 3: Crea DataFrame per la visualizzazione o l’ulteriore utilizzo
Passaggio 4: Funzione per preparare i dati LSTM, allenare, prevedere e tracciare
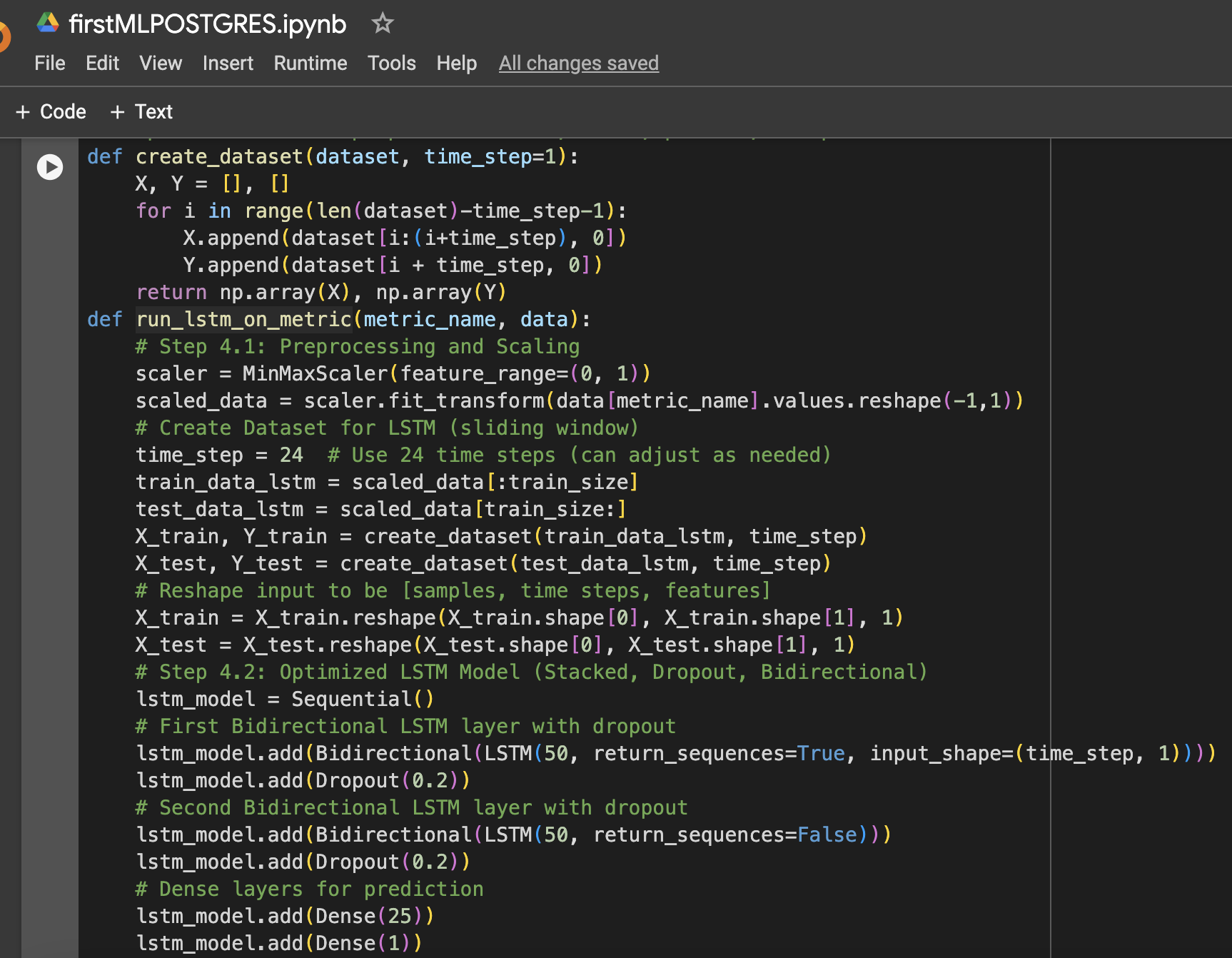
Passaggio 5: Esegui il modello per CPU, memoria e storage
Risultati
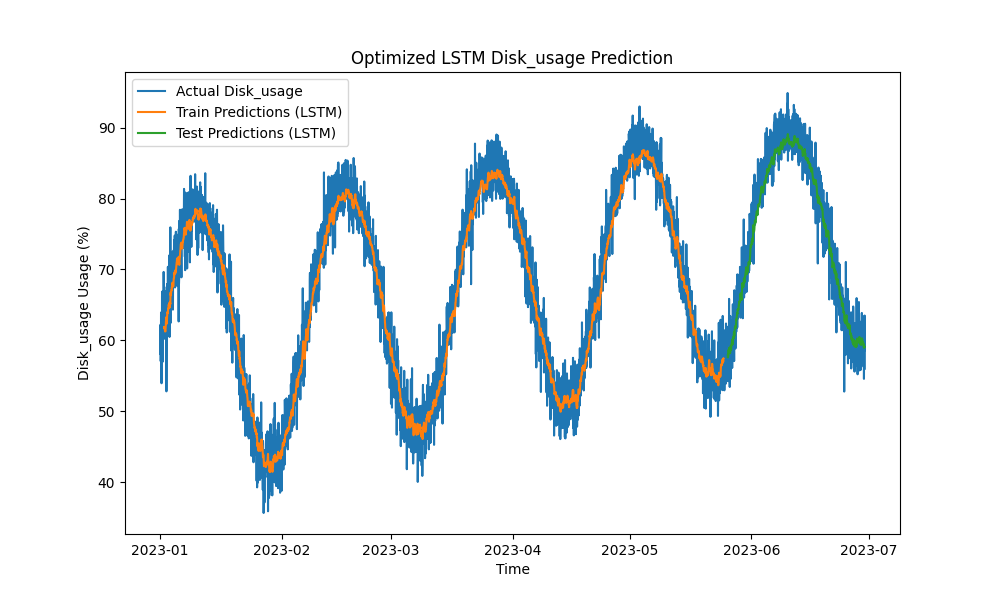
Il modello LSTM ottimizzato ha superato i metodi tradizionali come ARIMA e regressione lineare nella previsione dell’utilizzo di CPU, memoria e disco. Le previsioni hanno seguito da vicino l’utilizzo effettivo delle risorse, catturando efficacemente i pattern a breve e lungo termine.
Ecco le visualizzazioni delle previsioni LSTM:
Figura 1: Previsione dell’utilizzo di CPU LSTM ottimizzata
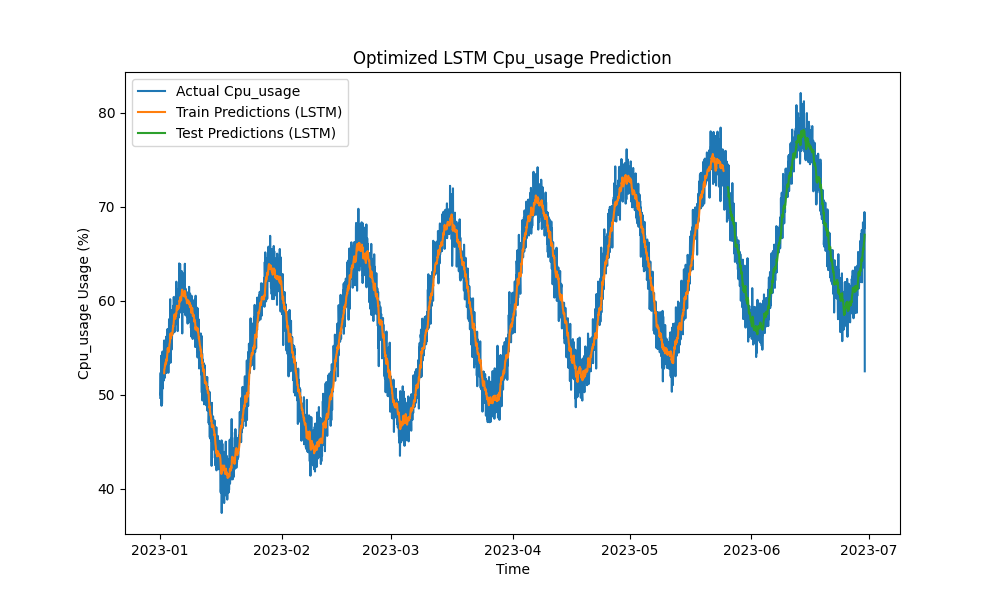
Figura 2: Previsione dell’utilizzo di memoria LSTM ottimizzata
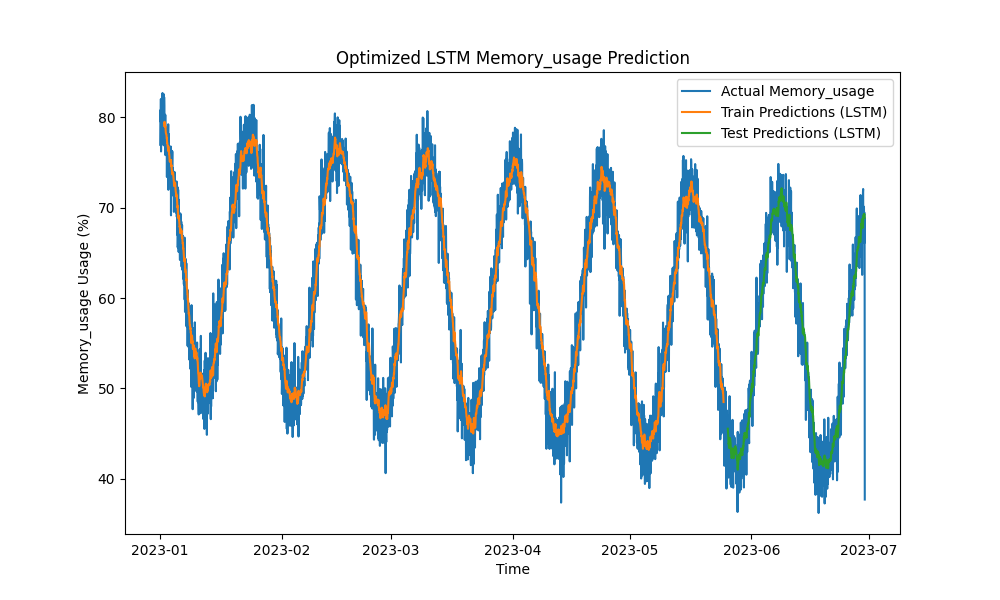
Figura 3: Previsione dell’utilizzo di disco LSTM ottimizzata
Integrazione pratica con gli strumenti di monitoraggio di PostgreSQL
Per massimizzare l’utilità del modello LSTM, è possibile esplorare varie implementazioni pratiche all’interno dell’ecosistema di monitoraggio di PostgreSQL:
- Integrazione con pgAdmin: pgAdmin può essere esteso per visualizzare le previsioni delle risorse in tempo reale insieme alle metriche effettive, consentendo ai DBA di rispondere in modo proattivo a potenziali carenze di risorse.
- Dashboard di Grafana: Le metriche di PostgreSQL possono essere integrate con Grafana per sovrapporre le previsioni LSTM sui grafici delle prestazioni. Gli avvisi possono essere configurati per notificare i DBA quando si prevede che l’utilizzo supererà le soglie predefinite.
- Monitoraggio di Prometheus: Prometheus può raccogliere le metriche di PostgreSQL e utilizzare le previsioni LSTM per allertare, generare previsioni e impostare notifiche in base al consumo previsto delle risorse.
- Scalabilità automatica in ambienti cloud: Nei casi di istanze PostgreSQL ospitate in cloud (ad esempio, AWS RDS, Google Cloud SQL), il modello LSTM può attivare servizi di autoscaling in base all’aumento previsto della domanda di risorse.
- Pipeline CI/CD: I modelli di machine learning possono essere continuamente aggiornati con nuovi dati, riaddestrati e distribuiti in tempo reale attraverso le pipeline CI/CD, garantendo che le previsioni rimangano accurate mentre i carichi di lavoro evolvono.
Conclusione
Applicando modelli di apprendimento automatico LSTM per prevedere l’utilizzo della CPU, della memoria e del disco, la pianificazione della capacità di PostgreSQL può passare da un approccio reattivo a uno proattivo. I nostri risultati mostrano che il modello LSTM ottimizzato fornisce previsioni accurate, consentendo una gestione più efficiente delle risorse e risparmi sui costi, particolarmente in ambienti ospitati su cloud.
Alla crescita degli ecosistemi dei database, questi strumenti predittivi diventano essenziali per i DBA che cercano di ottimizzare l’utilizzo delle risorse, evitare tempi di inattività e garantire la scalabilità. Se gestisci database PostgreSQL su larga scala, è ora di sfruttare l’apprendimento automatico per la pianificazione della capacità predittiva e ottimizzare la gestione delle risorse prima che si verifichino problemi di performance.
Lavoro futuro
Potenziamenti futuri potrebbero includere:
- Sperimentare con architetture aggiuntive di reti neurali (ad esempio, modelli GRU o Transformer) per gestire carichi di lavoro più volatili.
- Estendere la metodologia a distribuzioni multi-nodo e distribuite di PostgreSQL, dove il traffico di rete e l’ottimizzazione dello storage giocano anche ruoli significativi.
- Implementare avvisi in tempo reale e integrare ulteriormente le previsioni nello stack operativo di PostgreSQL per una gestione più automatizzata.
- Sperimentare con i dati di Oracle Automated Workload Repository (AWR) per le previsioni del carico di lavoro del database Oracle
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity