













今天,数据库世界正迅速朝着人工智能和机器学习发展,数据库的工作负载预计将大幅增加。对于数据库管理员来说,预测数据库基础设施的工作负载并及时解决需求将是额外的责任。随着数据库规模的扩大和资源管理变得日益关键,传统的容量规划方法通常效果不佳,导致性能问题和未经计划的停机时间。作为最广泛使用的开源关系型数据库之一,PostgreSQL也不例外。随着对CPU、内存和磁盘空间需求的增加,数据库管理员(DBAs)必须采取主动的方法来预防瓶颈并提高效率。
在本文中,我们将探讨如何将长短期记忆(LSTM)机器学习模型应用于预测PostgreSQL数据库中的资源消耗。这种方法使得DBAs能够从被动转变为预测性容量规划,从而减少停机时间、改善资源分配并降低过度配置成本。
为什么预测性容量规划很重要
通过利用机器学习,DBAs可以在资源需求变得关键之前预测未来的资源需求并加以解决,从而实现:
- 减少停机时间:早期发现资源短缺有助于避免中断。
- 提高效率: 根据实际需求分配资源,避免过度配置。
- 节约成本: 在云环境中,准确的资源预测可以减少过度配置的成本。
机器学习如何优化PostgreSQL资源规划
为了准确预测PostgreSQL资源使用情况,我们应用了一种优化的LSTM模型,一种擅长捕捉时间序列数据中时间模式的循环神经网络(RNN)。LSTMs非常适合理解复杂的依赖关系和序列,使其成为在PostgreSQL环境中预测CPU、内存和磁盘使用情况的理想选择。
方法论
数据收集
选项1
为构建LSTM模型,我们需要从各种PostgreSQL系统服务器操作系统命令和数据库视图中收集性能数据,例如:
pg_stat_activity(Postgres数据库中活动连接的详细信息),vmstatfreedf
数据可以每隔几分钟捕获一次,为期六个月,提供了一个全面的数据集来训练模型。收集的指标可以存储在一个名为capacity_metrics的专用表中。
示例表结构:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);有多种方法可以将系统数据捕获到这个历史表中。其中一种方法是编写Python脚本,并通过crontab每隔几分钟调度一次。
选项2
为了测试灵活性,我们可以使用代码生成CPU、内存和磁盘利用率指标(合成数据生成),并在Google Colab Notebook中执行。对于这个论文测试分析,我们使用了这个选项。具体步骤将在以下部分中解释。
机器学习模型:优化的LSTM
选择LSTM模型是因为它能够学习时间序列数据中的长期依赖关系。为了提高其性能,采取了几种优化措施:
- 堆叠的LSTM层:堆叠了两个LSTM层,以捕获资源使用数据中的复杂模式。
- Dropout正则化:在每个LSTM层后面添加了Dropout层,以防止过拟合并提高泛化能力。
- 双向LSTM:模型被设置为双向,以捕获数据中的正向和反向模式。
- 学习率优化:选择了学习率为0.001,用于微调模型的学习过程。
模型使用批量大小为64进行了20个epochs的训练,并在未见过的测试数据上测量了CPU、内存和存储(磁盘)的性能使用情况。
以下是在数据设置和机器学习实验中使用的步骤摘要以及Google Colab Notebook的截图:
步骤1:数据设置(模拟CPU、内存、磁盘使用数据,为期6个月)
步骤2:为数据添加更多变化
步骤3:创建用于可视化或进一步使用的DataFrame
步骤4:准备LSTM数据、训练、预测和绘图的功能
步骤5:运行CPU、内存和存储模型
结果
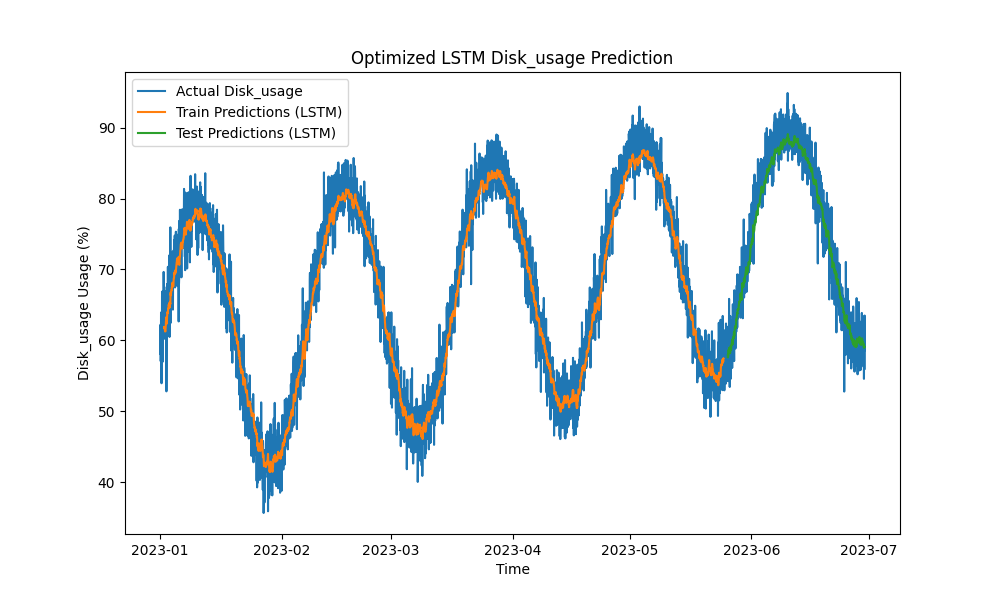
优化后的LSTM模型在预测CPU、内存和磁盘使用方面优于传统方法,如ARIMA和线性回归。预测结果紧密跟踪实际资源使用情况,有效捕捉了短期和长期模式。
以下是LSTM预测的可视化:
图1:优化后的LSTM CPU使用预测
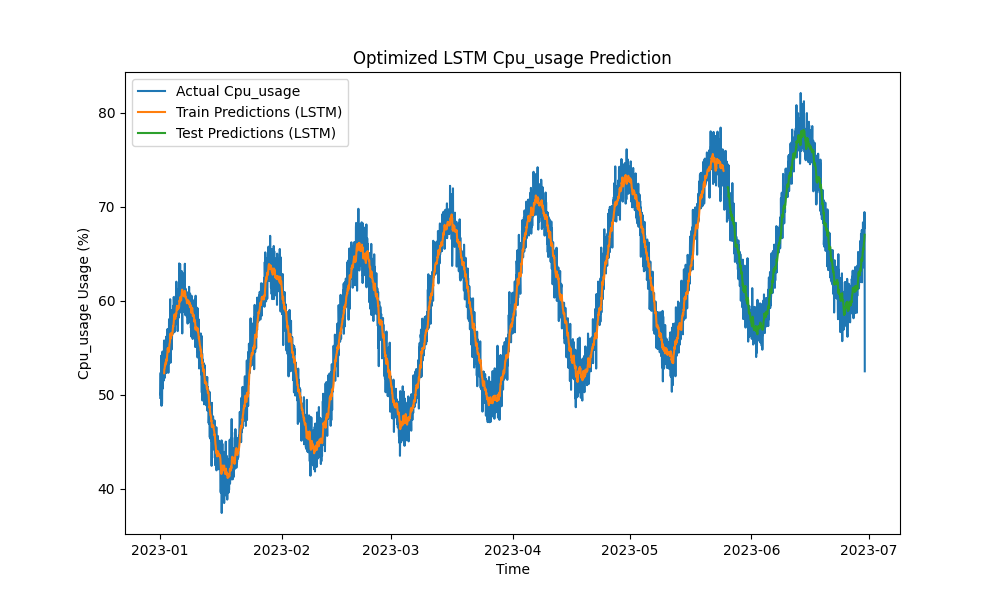
图2:优化后的LSTM内存使用预测
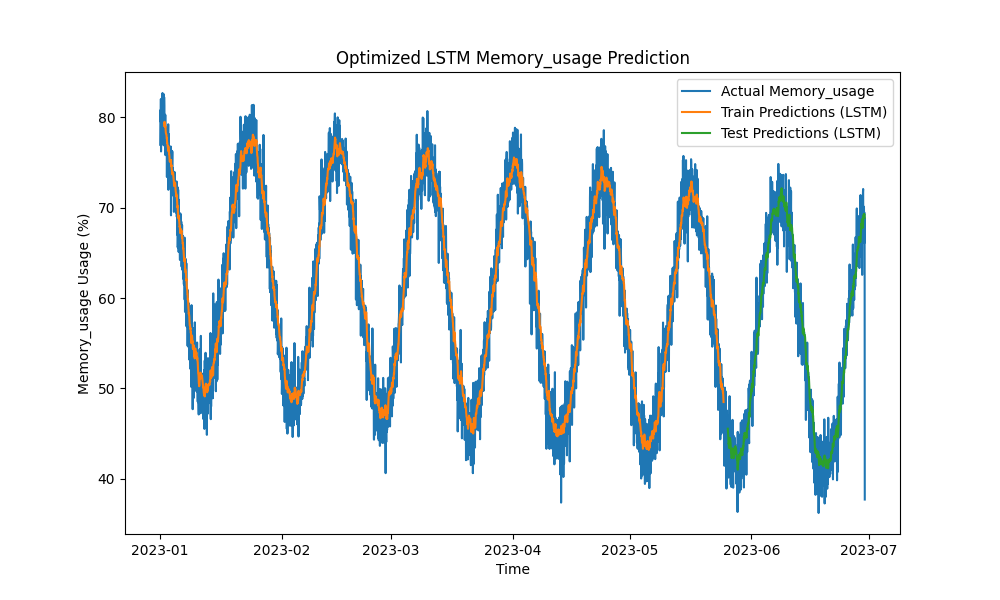
图3:优化后的LSTM磁盘使用预测
与PostgreSQL监控工具的实际集成
为了最大化LSTM模型的效用,可以探索在PostgreSQL监控生态系统中的各种实际实现:
- pgAdmin集成:pgAdmin可以扩展为可视化实时资源预测与实际指标并存,并使数据库管理员能够主动应对潜在的资源短缺。
- Grafana仪表盘:PostgreSQL指标可以与Grafana集成,将LSTM预测叠加在性能图表上。可以配置警报,通知数据库管理员当预测使用量预计超过预定义阈值时。
- Prometheus监控:Prometheus可以抓取PostgreSQL指标,并使用LSTM预测进行警报、生成预测,并根据预测的资源消耗设置通知。
- 云环境中的自动扩展:在云托管的PostgreSQL实例(例如AWS RDS,Google Cloud SQL)中,LSTM模型可以基于预测的资源需求增加来触发自动扩展服务。
- CI/CD流水线:机器学习模型可以通过CI/CD流水线持续更新新数据、重新训练,并实时部署,确保预测在工作负载演变时保持准确。
结论
通过将LSTM机器学习模型应用于预测CPU、内存和磁盘使用情况,PostgreSQL容量规划可以从被动转变为主动的方式。我们的结果显示,优化后的LSTM模型提供了准确的预测,实现更高效的资源管理和成本节约,特别是在云托管环境中。
随着数据库生态系统变得越来越复杂,这些预测工具对于希望优化资源利用、预防停机并确保可伸缩性的数据库管理员至关重要。如果您正在大规模管理PostgreSQL数据库,现在是利用机器学习进行预测性容量规划并在出现性能问题之前优化资源管理的时候了。
未来工作
未来的改进可能包括:
- 尝试使用其他神经网络架构(例如GRU或Transformer模型)来处理更加波动的工作负载。
- 将方法扩展到多节点和分布式的PostgreSQL部署,其中网络流量和存储优化也起着重要作用。
- 实现实时警报,并将预测进一步整合到PostgreSQL的运营堆栈中,实现更自动化的管理。
- 尝试使用Oracle 自动工作负载存储库(AWR)数据进行Oracle数据库工作负载预测
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity