













Hoje, o mundo dos bancos de dados está se movendo rapidamente em direção à IA e ao ML, e espera-se que a carga de trabalho dos bancos de dados aumente significativamente. Para um administrador de banco de dados, será uma responsabilidade adicional prever a carga de trabalho da infraestrutura do banco de dados com antecedência e atender a essa necessidade. À medida que os bancos de dados escalam e a gestão de recursos se torna cada vez mais crítica, os métodos tradicionais de planejamento de capacidade frequentemente falham, levando a problemas de desempenho e interrupções não planejadas. O PostgreSQL, um dos bancos de dados relacionais de código aberto mais amplamente utilizados, não é uma exceção. Com o aumento das demandas de CPU, memória e espaço em disco, os administradores de banco de dados (DBAs) devem adotar abordagens proativas para prevenir gargalos e melhorar a eficiência.
Neste artigo, exploraremos como modelos de aprendizado de máquina Long Short-Term Memory (LSTM) podem ser aplicados para prever o consumo de recursos em bancos de dados PostgreSQL. Essa abordagem permite que os DBAs passem de um planejamento de capacidade reativo para um planejamento preditivo, reduzindo assim o tempo de inatividade, melhorando a alocação de recursos e minimizando os custos de sobrecarga.
Por que o Planejamento de Capacidade Preditivo é Importante
Ao aproveitar o aprendizado de máquina, os DBAs podem prever as necessidades futuras de recursos e abordá-las antes que se tornem críticas, resultando em:
- Redução do tempo de inatividade: A detecção precoce de escassez de recursos ajuda a evitar interrupções.
- Eficiência aprimorada: Recursos são alocados com base em necessidades reais, evitando o provisionamento excessivo.
- Economia de custos: Em ambientes de nuvem, previsões precisas de recursos podem reduzir o custo do provisionamento excessivo.
Como o Aprendizado de Máquina Pode Otimizar o Planejamento de Recursos do PostgreSQL
Para prever com precisão o uso de recursos do PostgreSQL, aplicamos um modelo LSTM otimizado, um tipo de rede neural recorrente (RNN) que se destaca em capturar padrões temporais em dados de séries temporais. LSTMs são bem adequados para entender dependências e sequências complexas, tornando-os ideais para prever o uso de CPU, memória e disco em ambientes PostgreSQL.
Metodologia
Coleta de Dados
Opção 1
Para construir o modelo LSTM, precisamos coletar dados de desempenho de vários comandos do sistema operacional do servidor PostgreSQL e visualizações de banco de dados, como:
pg_stat_activity(detalhes das conexões ativas dentro do Banco de Dados Postgres),vmstatfreedf
Os dados podem ser capturados a cada poucos minutos por seis meses, fornecendo um conjunto abrangente de dados para treinar o modelo. As métricas coletadas podem ser armazenadas em uma tabela dedicada chamada capacity_metrics.
Esquema de Tabela de Exemplo:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);Há várias maneiras de capturar esses dados do sistema nesta tabela de histórico. Uma das maneiras é escrever o script Python e agendá-lo através do crontab para ser executado a cada poucos minutos.
Opção 2
Para testar a flexibilidade, podemos gerar métricas de utilização de CPU, memória e disco usando código (geração de dados sintéticos) e executar usando o Google Colab Notebook. Para esta análise de teste, usamos esta opção. Os passos são explicados nas seguintes seções.
Modelo de Aprendizado de Máquina: LSTM Otimizado
O modelo LSTM foi selecionado por sua capacidade de aprender dependências de longo prazo em dados de séries temporais. Foram aplicadas várias otimizações para melhorar seu desempenho:
- Camadas LSTM Empilhadas: Duas camadas LSTM foram empilhadas para capturar padrões complexos nos dados de uso de recursos.
- Regularização de Dropout: Camadas de Dropout foram adicionadas após cada camada LSTM para evitar overfitting e melhorar a generalização.
- LSTM Bidirecional: O modelo foi tornando bidirecional para capturar padrões tanto para frente quanto para trás nos dados.
- Otimização da taxa de aprendizado: Foi escolhida uma taxa de aprendizado de 0,001 para ajustar finamente o processo de aprendizado do modelo.
O modelo foi treinado por 20 épocas com um tamanho de lote de 64, e o desempenho foi medido em dados de teste não vistos para o uso de CPU, memória e armazenamento (disco).
Abaixo está um resumo dos passos juntamente com capturas de tela do Google Colab Notebook usadas na configuração de dados e experimento de aprendizado de máquina:
Passo 1: Configuração de Dados (Dados Simulados de Uso de CPU, Memória e Disco por 6 Meses)
Passo 2: Adicionar Mais Variação aos Dados
Passo 3: Criar DataFrame para Visualização ou Uso Adicional
Passo 4: Função para Preparar Dados de LSTM, Treinar, Prever e Plotar
Passo 5: Executar o Modelo para CPU, Memória e Armazenamento
Resultados
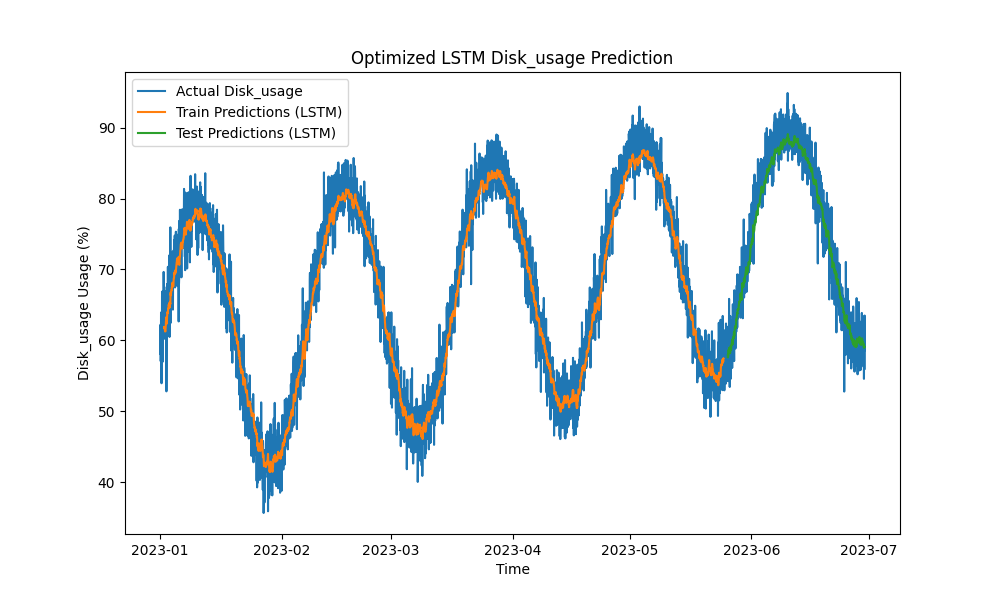
O modelo LSTM otimizado superou métodos tradicionais como ARIMA e regressão linear na previsão de uso de CPU, memória e disco. As previsões acompanharam de perto o uso real de recursos, capturando efetivamente os padrões de curto e longo prazo.
Aqui estão as visualizações das previsões de LSTM:
Figura 1: Previsão de Uso de CPU otimizada por LSTM
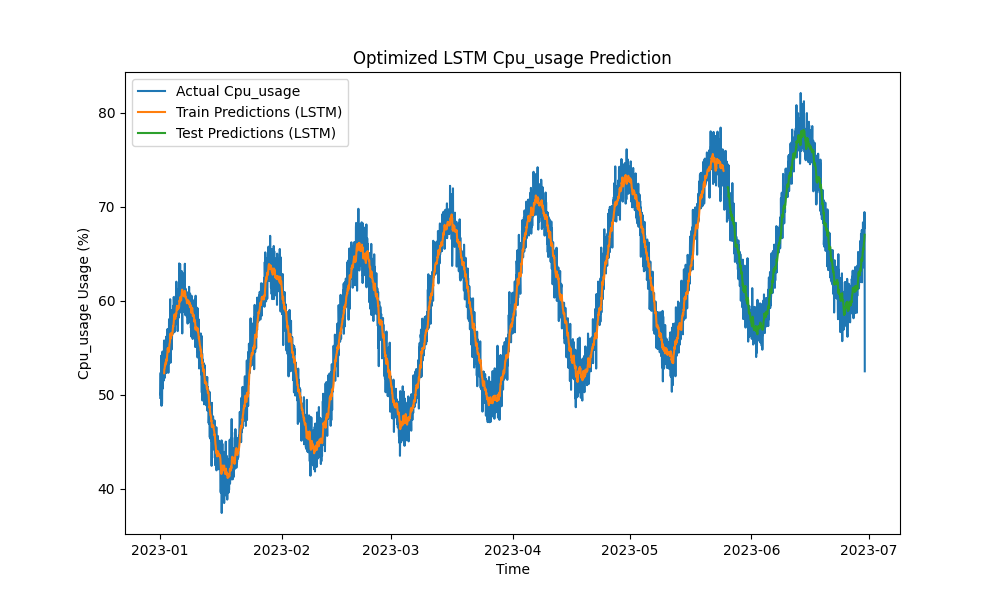
Figura 2: Previsão de Uso de Memória otimizada por LSTM
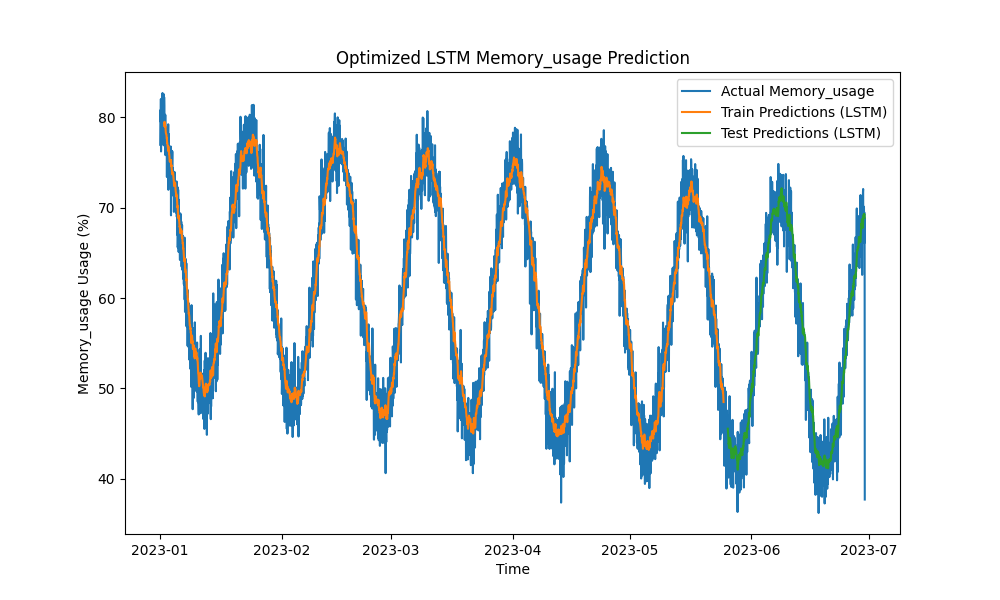
Figura 3: Previsão de Uso de Disco otimizada por LSTM
Integração Prática com Ferramentas de Monitoramento do PostgreSQL
Para maximizar a utilidade do modelo LSTM, diversas implementações práticas dentro do ecossistema de monitoramento do PostgreSQL podem ser exploradas:
- Integração com o pgAdmin: O pgAdmin pode ser estendido para visualizar previsões de recursos em tempo real ao lado de métricas reais, permitindo que os DBAs respondam proativamente a possíveis escassez de recursos.
- Painéis do Grafana: As métricas do PostgreSQL podem ser integradas ao Grafana para sobrepor as previsões do LSTM em gráficos de desempenho. Alertas podem ser configurados para notificar os DBAs quando o uso previsto estiver prestes a exceder os limites predefinidos.
- Monitoramento com o Prometheus: O Prometheus pode coletar métricas do PostgreSQL e utilizar as previsões do LSTM para alertar, gerar previsões e configurar notificações com base no consumo previsto de recursos.
- Dimensionamento automatizado em ambientes de nuvem: Em instâncias do PostgreSQL hospedadas na nuvem (por exemplo, AWS RDS, Google Cloud SQL), o modelo LSTM pode acionar serviços de dimensionamento automático com base em previsões de aumento na demanda de recursos.
- Pipelines CI/CD: Os modelos de aprendizado de máquina podem ser continuamente atualizados com novos dados, retreinados e implantados em tempo real por meio de pipelines CI/CD, garantindo que as previsões permaneçam precisas conforme as cargas de trabalho evoluem.
Conclusão
Ao aplicar modelos de aprendizado de máquina LSTM para prever o uso de CPU, memória e disco, o planejamento de capacidade do PostgreSQL pode mudar de uma abordagem reativa para uma abordagem proativa. Nossos resultados mostram que o modelo LSTM otimizado fornece previsões precisas, permitindo um gerenciamento de recursos mais eficiente e economia de custos, especialmente em ambientes hospedados na nuvem.
À medida que os ecossistemas de bancos de dados se tornam mais complexos, essas ferramentas preditivas se tornam essenciais para os DBAs que buscam otimizar a utilização de recursos, prevenir tempos de inatividade e garantir escalabilidade. Se você está gerenciando bancos de dados PostgreSQL em grande escala, agora é o momento de aproveitar o aprendizado de máquina para o planejamento de capacidade preditiva e otimizar o gerenciamento de recursos antes que ocorram problemas de desempenho.
Trabalho Futuro
As melhorias futuras poderiam incluir:
- Experimentar com arquiteturas adicionais de redes neurais (por exemplo, modelos GRU ou Transformer) para lidar com cargas de trabalho mais voláteis.
- Estender a metodologia para implantações de PostgreSQL em vários nós e distribuídas, onde o tráfego de rede e a otimização de armazenamento também desempenham papéis significativos.
- Implementar alertas em tempo real e integrar ainda mais as previsões na pilha operacional do PostgreSQL para um gerenciamento mais automatizado.
- Experimentar com dados do Repositório de Cargas de Trabalho Automatizado do Oracle para previsões de carga de trabalho do banco de dados Oracle.
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity