













اليوم، العالم قاعدة البيانات يتجه بسرعة نحو الذكاء الاصطناعي وتعلم الآلة، ومن المتوقع أن تزيد أعباء العمل لدى قواعد البيانات بشكل كبير. بالنسبة لمسؤول قاعدة البيانات، سيكون من المسؤولية الإضافية توقع أعباء العمل لبنية قاعدة البيانات مسبقًا ومعالجة الحاجة. مع توسيع قواعد البيانات وأصبح إدارة الموارد أمرًا حرجًا بشكل متزايد، غالبًا ما تفشل الأساليب التقليدية لتخطيط السعة، مما يؤدي إلى مشاكل الأداء وتوقف غير مخطط له. PostgreSQL، واحدة من أوسع قواعد البيانات العلاقية مفتوحة المصدر استخدامًا، ليست استثناءً. مع الطلب المتزايد على وحدة المعالجة المركزية والذاكرة ومساحة القرص، يجب على مسؤولي قواعد البيانات (DBAs) اعتماد نهج استباقي لمنع حدوث Englishtlenecks وتحسين الكفاءة.
في هذه المقالة، سنستكشف كيف يمكن تطبيق نماذج تعلم الآلة “الذاكرة القصيرة الطويلة (LSTM)” لتوقع استهلاك الموارد في قواعد بيانات PostgreSQL. يتيح هذا النهج لـ DBAs التحول من التخطيط السعة ردًا على الأحداث إلى التخطيط التنبؤي، مما يقلل من الوقت التوقف، ويحسن توزيع الموارد، ويقلل من تكاليف الإفراط في التوفير.
لماذا يهم التخطيط السعة التنبؤي
من خلال استغلال تعلم الآلة، يمكن لـ DBAs توقع الاحتياجات المستقبلية للموارد ومعالجتها قبل أن تصبح حرجة، مما يؤدي إلى:
- تقليل الوقت التوقف: الكشف المبكر عن نقص الموارد يساعد على تجنب الانقطاعات.
- زيادة الكفاءة: يتم تخصيص الموارد استنادًا إلى الاحتياجات الحقيقية، مما يمنع التوفير الزائد.
- توفير التكاليف: في بيئات السحابة، يمكن أن تقلل توقعات الموارد الدقيقة من تكلفة التوفير الزائد.
كيف يمكن لتعلم الآلة تحسين تخطيط موارد PostgreSQL
للتنبؤ بشكل دقيق باستخدام الموارد في PostgreSQL، قمنا بتطبيق نموذج LSTM محسن، نوع من الشبكة العصبية التكرارية (RNN) الذي يتفوق في التقاط الأنماط الزمنية في البيانات الخاصة بسلاسل الزمن. تعتبر الـ LSTMs مناسبة تمامًا لفهم التبعيات المعقدة والسلاسل، مما يجعلها مثالية لتوقع استخدام وحدة المعالجة المركزية والذاكرة والقرص في بيئات PostgreSQL.
المنهجية
جمع البيانات
الخيار 1
لبناء نموذج الـ LSTM، نحتاج إلى جمع بيانات الأداء من مختلف أوامر نظام خادم PostgreSQL وعرض قاعدة البيانات، مثل:
pg_stat_activity(تفاصيل الاتصالات النشطة داخل قاعدة بيانات Postgres),vmstatfreedf
يمكن التقاط البيانات كل بضع دقائق لمدة ستة أشهر، مما يوفر مجموعة بيانات شاملة لتدريب النموذج. يمكن تخزين المقاييس المجمعة في جدول مخصص يسمى capacity_metrics.
مثال على هيكل الجدول:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);هناك طرق متعددة لالتقاط بيانات النظام هذه في هذا الجدول التاريخي. أحد الطرق هو كتابة نص برمجي باستخدام لغة Python وجدولته باستخدام crontab كل بضع دقائق.
الخيار 2
من أجل مرونة الاختبار، يمكننا توليد مقاييس استخدام وحدة المعالجة المركزية والذاكرة والقرص باستخدام الشفرة (توليد بيانات صناعية) وتنفيذها باستخدام دفتر ملاحظات Google Colab. لهذا التحليل التجريبي، استخدمنا هذا الخيار. يتم شرح الخطوات في الأقسام التالية.
نموذج التعلم الآلي: LSTM المحسن
تم اختيار نموذج LSTM لقدرته على تعلم التبعيات طويلة المدى في بيانات السلاسل الزمنية. تم تطبيق العديد من التحسينات لتحسين أدائه:
- طبقات LSTM المكدسة: تم تكديس طبقتي LSTM لالتقاط الأنماط المعقدة في بيانات استخدام الموارد.
- تنظيم الإسقاط (Dropout): تمت إضافة طبقات Dropout بعد كل طبقة LSTM لمنع الإفراط في التصاق النموذج وتحسين التعميم.
- LSTM ثنائي الاتجاه: تم جعل النموذج ثنائي الاتجاه لالتقاط الأنماط في البيانات من الاتجاهين الأمامي والخلفي.
- تحسين معدل التعلم: تم اختيار معدل تعلم قيمته 0.001 لضبط دقيق في عملية تعلم النموذج.
تم تدريب النموذج لمدة 20 دورة مع دفعة بحجم 64، وتم قياس الأداء على البيانات الاختبارية غير المرئية لاستخدام وحدة المعالجة المركزية والذاكرة والتخزين (القرص).
أدناه ملخص للخطوات جنبًا إلى جنب مع لقطات شاشة دفتر ملاحظات Google Colab المستخدمة في إعداد البيانات وتجربة التعلم الآلي:
الخطوة 1: إعداد البيانات (بيانات محاكاة لاستخدام وحدة المعالجة المركزية والذاكرة والقرص لمدة 6 أشهر)
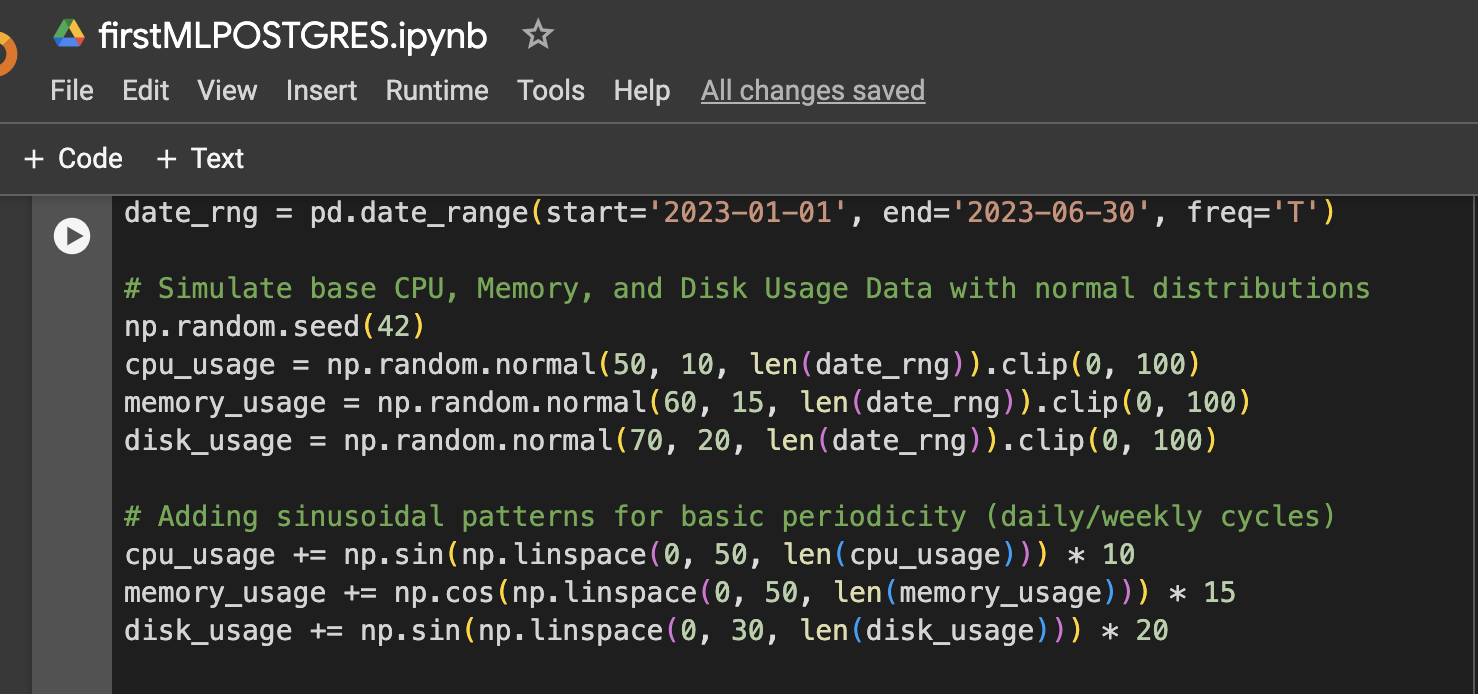
الخطوة 2: إضافة مزيد من التباين إلى البيانات
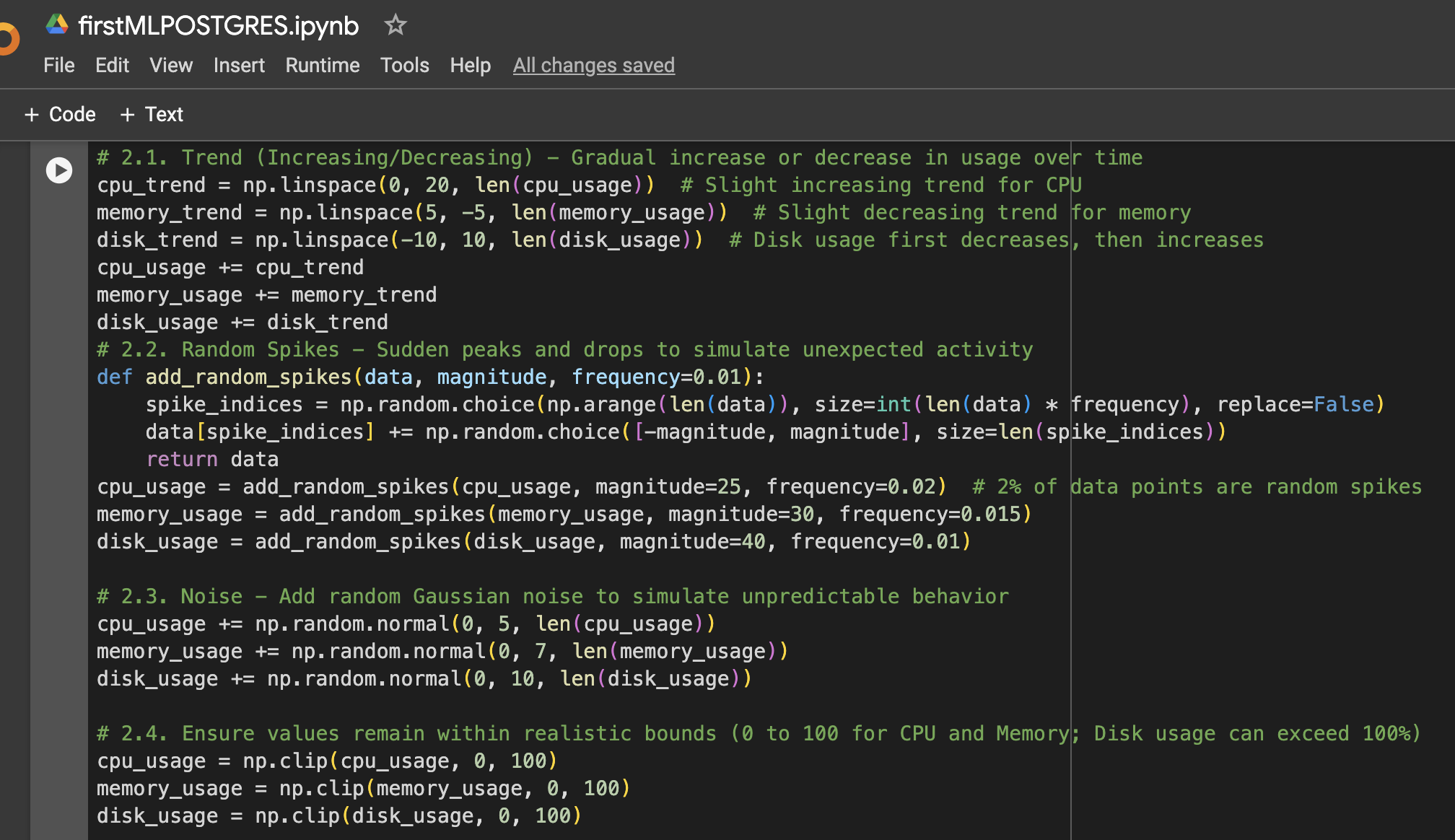
الخطوة 3: إنشاء إطار بيانات للتصور أو الاستخدام اللاحق
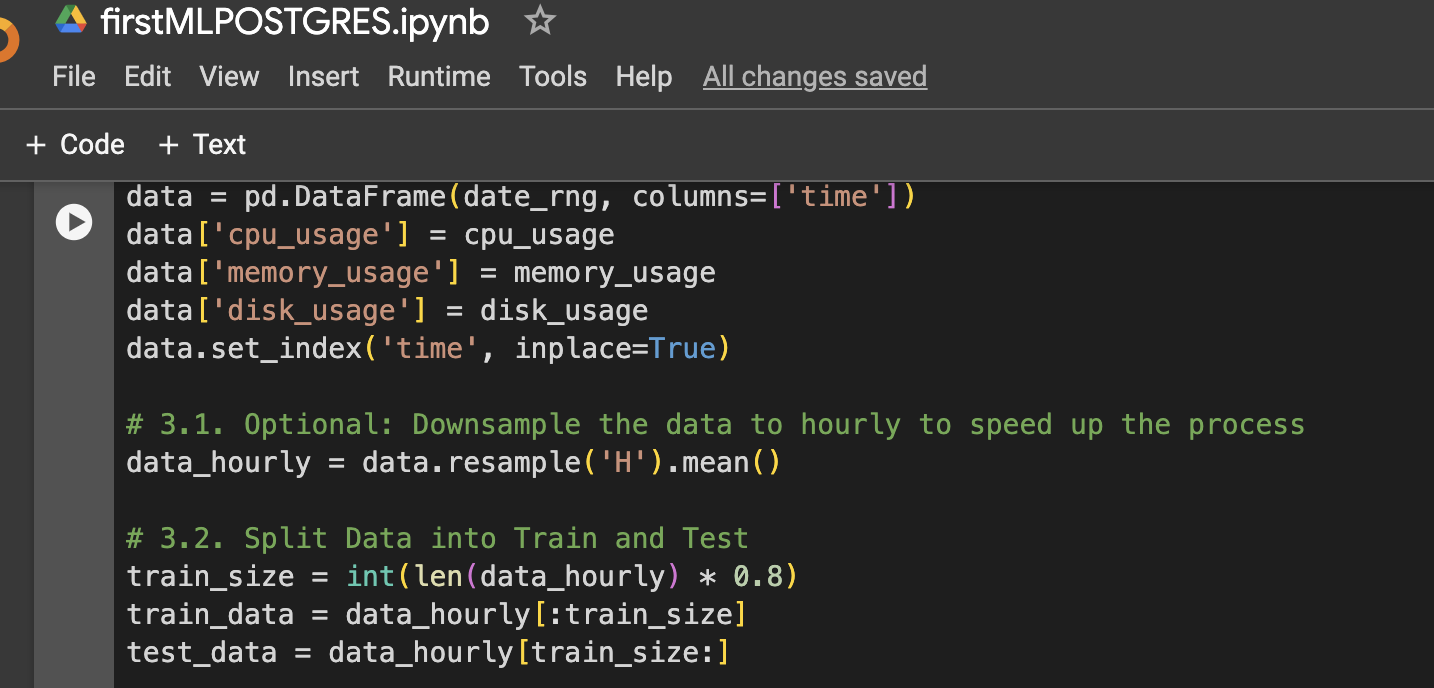
الخطوة 4: وظيفة لإعداد بيانات LSTM، التدريب، التنبؤ، والرسم
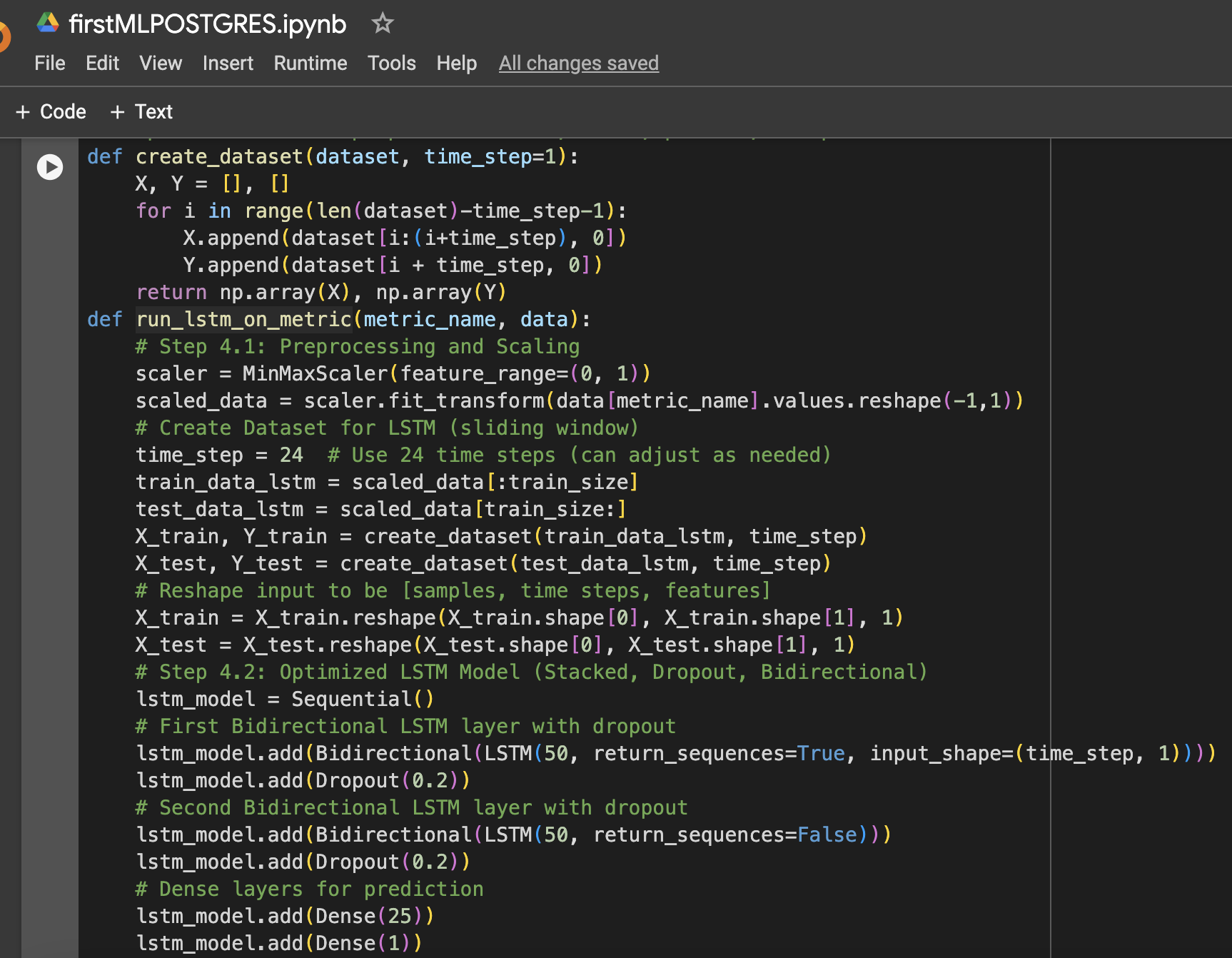
الخطوة 5: تشغيل النموذج لوحدة المعالجة المركزية والذاكرة والتخزين
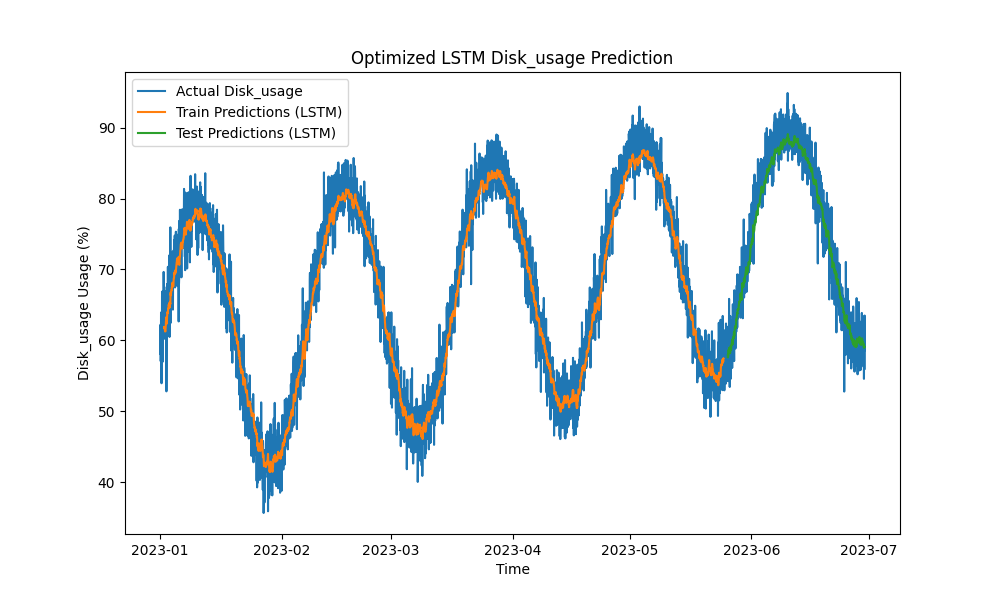
النتائج
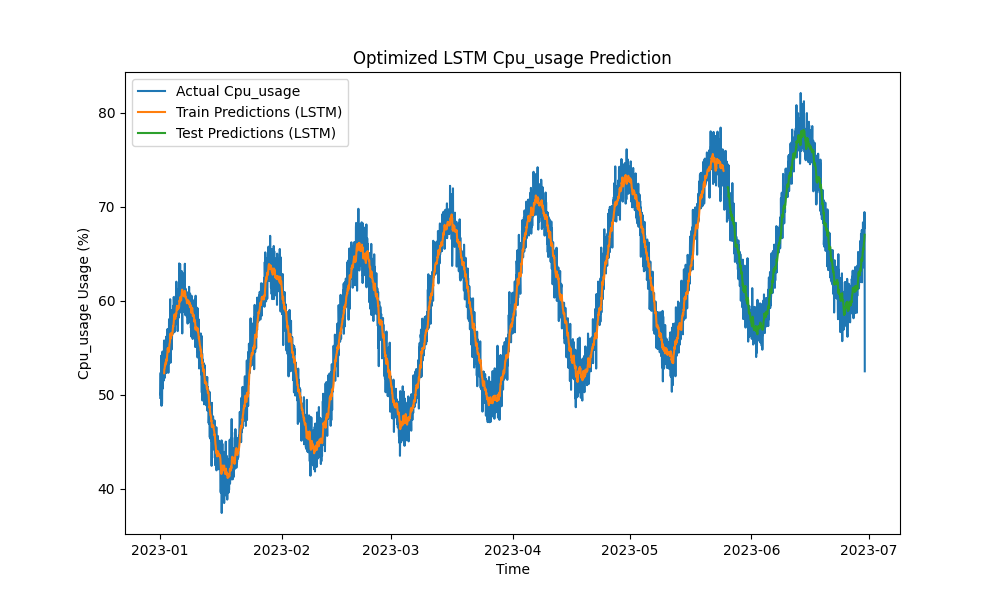
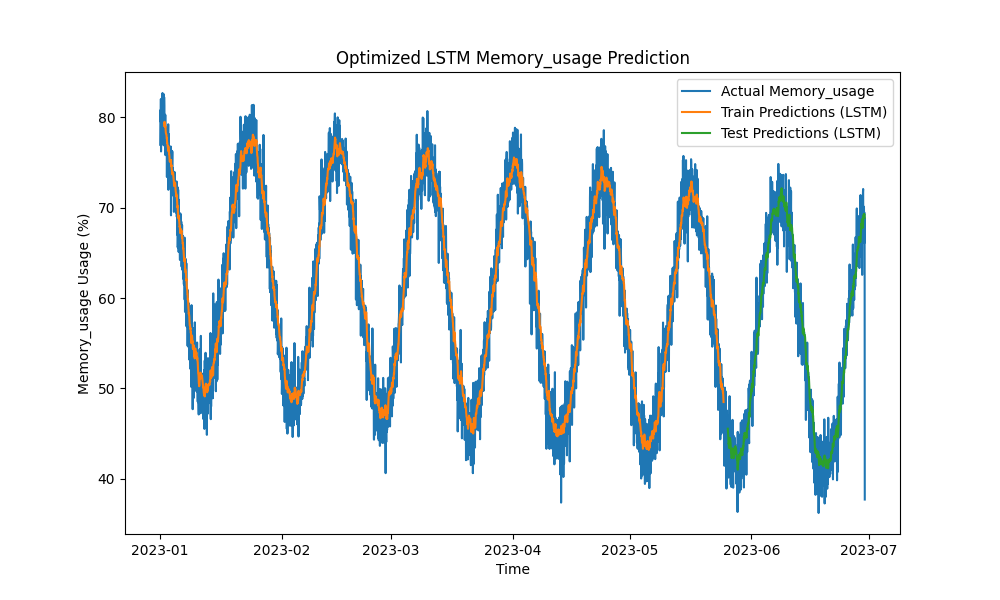
نموذج LSTM المحسن تفوق على الأساليب التقليدية مثل ARIMA والانحدار الخطي في توقع استخدام وحدة المعالجة المركزية والذاكرة والقرص. تتبعت التوقعات عن كثب استخدام الموارد الفعلية، وقامت بالتقاط الأنماط القصيرة والطويلة الأمد بفعالية.
إليك تصورات التوقعات LSTM:
الشكل 1: توقعات استخدام وحدة المعالجة المركزية بتحسين LSTM
الشكل 2: توقعات استخدام الذاكرة بتحسين LSTM
الشكل 3: توقعات استخدام القرص بتحسين LSTM
التكامل العملي مع أدوات مراقبة PostgreSQL
لتعظيم فائدة نموذج LSTM ، يمكن استكشاف تنفيذات عملية مختلفة ضمن نظام رصد PostgreSQL:
- التكامل مع pgAdmin: يمكن توسيع pgAdmin لتصوير توقعات الموارد في الوقت الحقيقي جنبًا إلى جنب مع المقاييس الفعلية، مما يمكن مسؤولي قواعد البيانات من الاستجابة بشكل استباقي لنقص الموارد المحتمل.
- لوحات تحكم Grafana: يمكن دمج مقاييس PostgreSQL مع Grafana لترسيم توقعات LSTM على الرسوم البيانية الأدائية. يمكن تكوين تنبيهات لإعلام مسؤولي قواعد البيانات عندما يتوقع تجاوز الاستخدام المتوقع الحدود المحددة مسبقًا.
- رصد Prometheus: يمكن لـ Prometheus جمع مقاييس PostgreSQL واستخدام توقعات LSTM لتنبيه، وإنشاء توقعات، وإعداد إشعارات استنادًا إلى تنبؤات استهلاك الموارد.
- التحجيم التلقائي في بيئات السحابة: يمكن للنموذج LSTM تشغيل خدمات التحجيم التلقائي استنادًا إلى التوقعات المتزايدة للطلب على الموارد في حالات PostgreSQL المستضافة في السحابة (على سبيل المثال، AWS RDS، Google Cloud SQL).
- أنابيب CI/CD: يمكن تحديث نماذج التعلم الآلي بشكل مستمر بالبيانات الجديدة، وإعادة تدريبها، ونشرها في الوقت الحقيقي من خلال أنابيب CI/CD، مما يضمن دقة التوقعات وتطور الأعباء.
الاستنتاج
من خلال تطبيق نماذج التعلم الآلي LSTM للتنبؤ باستخدام وحدة المعالجة المركزية والذاكرة واستخدام القرص، يمكن لتخطيط سعة PostgreSQL التحول من نهج ردود الفعل إلى نهج استباقي. تظهر نتائجنا أن النموذج المحسّن LSTM يوفر تنبؤات دقيقة، مما يمكن من إدارة الموارد بكفاءة أكبر وتوفير التكاليف، خاصة في بيئات السحابة.
مع تزايد تعقيد بيئات قواعد البيانات، تصبح هذه الأدوات التنبؤية أساسية لمسؤولي قواعد البيانات الذين يسعون إلى تحسين استخدام الموارد، ومنع التوقف، وضمان التوسع. إذا كنت تدير قواعد بيانات PostgreSQL بشكل كبير، فالآن هو الوقت المناسب للاستفادة من التعلم الآلي لتخطيط السعة التنبؤي وتحسين إدارة الموارد الخاصة بك قبل حدوث مشكلات الأداء.
العمل المستقبلي
يمكن أن تشمل التحسينات المستقبلية:
- التجربة باستخدام تصميمات شبكات عصبية إضافية (مثل نماذج GRU أو Transformer) للتعامل مع أعباء عمل أكثر تقلبًا.
- توسيع المنهجية إلى نشرات PostgreSQL متعددة العقد وموزعة، حيث تلعب حركة المرور عبر الشبكة وتحسين التخزين أدوارًا هامة أيضًا.
- تنفيذ تنبيهات فورية ودمج التنبؤات بشكل أعمق في مجموعة PostgreSQL التشغيلية لإدارة أكثر تلقائية.
- التجربة باستخدام بيانات Oracle مستودع عمليات Oracle التلقائي (AWR) لتوقعات أعباء عمل قواعد البيانات Oracle
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity