













היום, עולם מסדי הנתונים זז במהירות לעבר AI ו־ML, וצפוי שעומס העבודה של מסדי הנתונים יגבר באופן משמעותי. עבור מנהלי מסדי נתונים, זה יהיה אחריות נוספת לנבא את עומס העבודה של תשתיות מסדי הנתונים מראש ולטפל בצורך. בזמן שהמסדים מתרחבים וניהול משאבים הופך חיוני יותר, שיטות התכנון הקיבוליות המסורתיות לעיתים קרובות אינן מספיקות, מה שמביא לבעיות בביצועים ולזמני פסק דחיפים. PostgreSQL, אחד ממסדי הנתונים היחסיים מקור פתוח המשמש באופן נרחב, אינו חרוג. עם התנאים המתמשכים על מעבדת ה־CPU, הזיכרון ושטח הדיסק, מנהלי מסדי הנתונים (DBAs) חייבים לאמץ גישות פעילות כדי למנוע חסימות ולשפר את היעילות.
במאמר זה, נסקור כיצד דגמי למידת מכונה מסוג "זכר קצר טווח" (LSTM) יכולים להיות מיושמים כדי לנבא את צריכת המשאבים במסדי נתונים של PostgreSQL. גישה זו מאפשרת ל־DBAs לעבור מתכנון קיבולי ראקטיבי לתחזוקת תכנון פורץ מראש, ולכן להפחתת זמני הפסק, שיפור ההקצאת משאבים והפחתת עלויות יתר.
למה תכנון תכונה פורץ מראש חשוב
על ידי ניצול מערכות למידת מכונה, DBAs יכולים לנבא צרכי משאבים עתידיים ולטפל בהם לפני שהם מפגים בקריטיות, תוך יצירת:
- זמני פסק נמוכים: זיהוי מוקדם של חסימות במשאבים עוזר למנוע הפרעות.
- שיפור יעילות: משאבים מוקצים על פי הצורך האמיתי, מונעים כפיית משאבים יתר.
- חיסכון בעלויות: בסביבות עננים, ניתן להפחית את עלויות המשאבים המיותרים באמצעות ניבוי מדויק של המשאבים.
איך למידת מכונה יכולה לאופטימז תכנון משאבי PostgreSQL
כדי לנבא במדוייק את שימוש במשאבי PostgreSQL, השתמשנו בדגם LSTM מאופטימלי, סוג של רשת עצבים חוזרת (RNN) שמצוין בלכידת תבניות זמן בנתוני סדרות זמן. LSTMs מתאימים מאוד להבנת תלותים מורכבות וסדרות, ולכן הם אידיאליים לניבוי שימוש במעבד, זיכרון ושטח דיסק בסביבות PostgreSQL.
מתודולוגיה
איסוף נתונים
אפשרות 1
כדי לבנות את הדגם LSTM, יש לאסוף נתוני ביצוע מפקדי מערכת השרת של PostgreSQL שונים ותצוגת db, כמו:
pg_stat_activity(פרטי חיבורים פעילים בתוך מסד נתונים של PostgreSQL),vmstatfreedf
הנתונים ניתן לכוד כל כמה דקות למשך שישה חודשים, מספקים מערך נתונים מקיף לאימון המודל. המדדים שנאספים ניתן לאחסן בטבלה מוקדשת בשם capacity_metrics.
סכימת טבלה דוגמה:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);ישנן מספר דרכים לכידת נתוני המערכת הללו לטבלת היסטוריה הזו. אחת הדרכים היא לכתוב סקריפט בפייתון ולתזמן אותו באמצעות crontab לכל כמה דקות.
אפשרות 2
לצורך גמישות בבדיקה, אנחנו יכולים ליצור מדדים של שימוש במעבד, זיכרון ודיסק באמצעות קוד (יצירת נתונים סינתטיים) ולבצע באמצעות מחברת Google Colab. עבור ניתוח הבדיקה הזו, השתמשנו באפשרות זו. השלבים מוסברים בסעיפים הבאים.
מודל למידת מכונה: LSTM ממותג
בחרנו במודל LSTM עקב יכולתו ללמוד תלותיות לתקופה ארוכה בנתוני סדרת זמן. בוצעו מספר תכלולים כדי לשפר את ביצועיו:
- שכבות LSTM מחוברות: שתי שכבות LSTM הוסרו כדי לכוד דפוסים מורכבים בנתוני שימוש במשאבים.
- רגולריזציה של Dropout: הוספנו שכבות Dropout לאחר כל שכבת LSTM כדי למנוע על-לכת ולשפר את הכללים.
- LSTM דו-כיווני: המודל הופך להיות דו-כיווני כדי לכוד דפוסים הלוך ושוב בנתונים.
- אופטימיזצית קצב למידה: נבחר קצב למידה של 0.001 עבור תהליך הלמידה של המודל.
המודל הוכשר למשך 20 אפוקים עם גודל קבוצה של 64, וביצועים נמדדו על נתוני בדיקה שלא נראו במראש לשימוש ב-CPU, זיכרון ואחסון (דיסק).
להלן תקציר של השלבים יחד עם צילומי מסך של מחברת Google Colab שנעשו בהגדרת הנתונים והניסוי בלמידת מכונה:
שלב 1: הגדרת הנתונים (נתוני שימוש ב-CPU, זיכרון, דיסק מדומים למשך 6 חודשים)
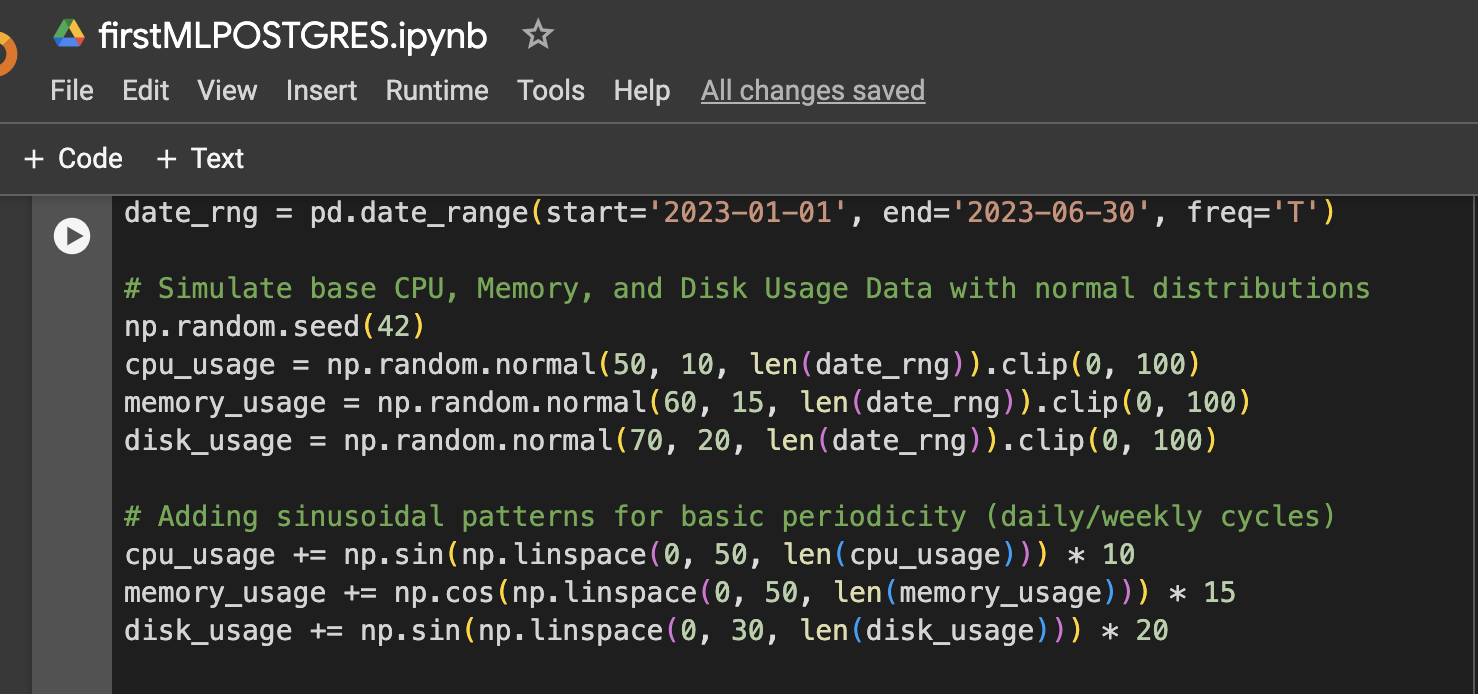
שלב 2: הוספת יותר שינוי לנתונים
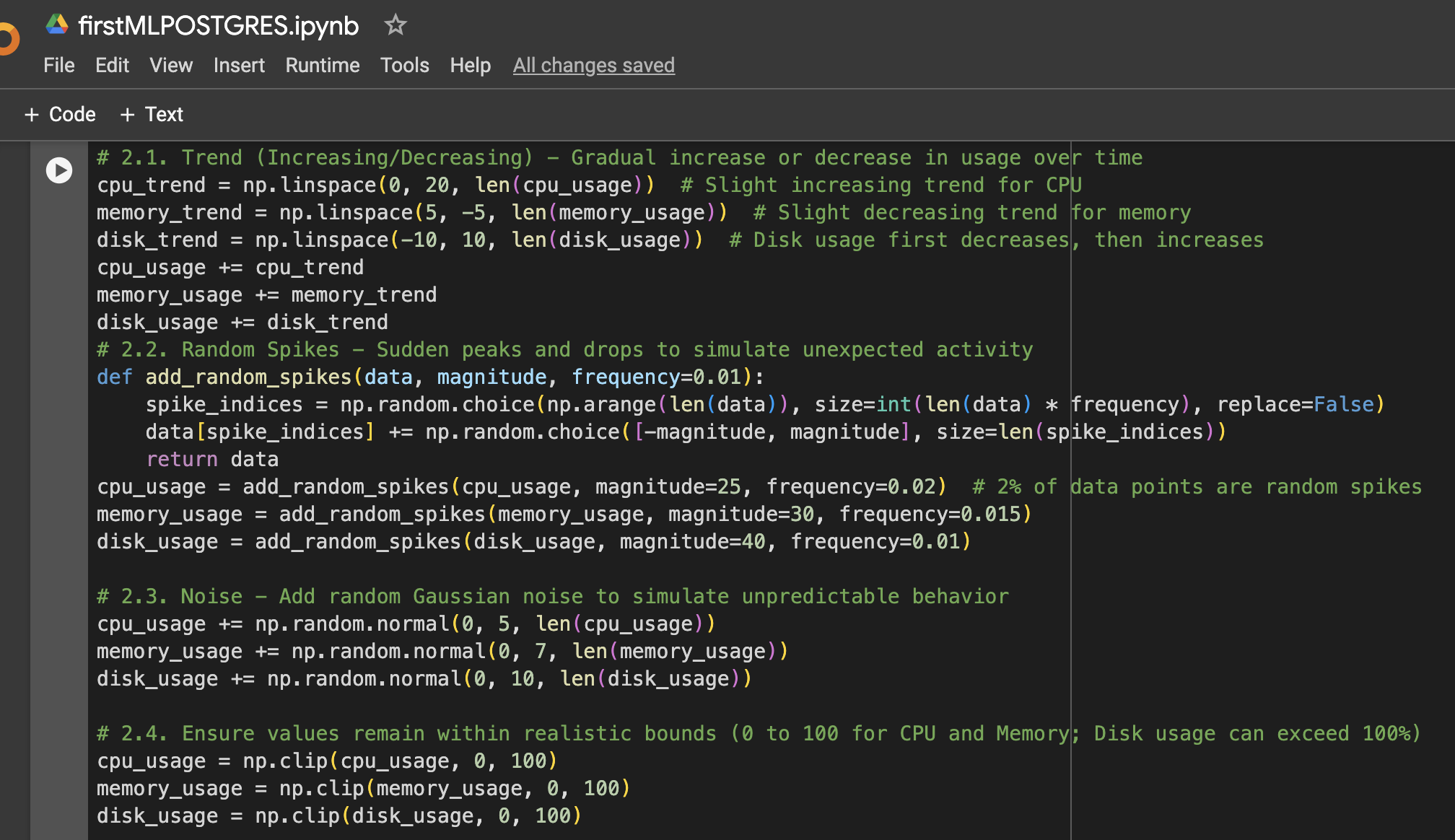
שלב 3: יצירת DataFrame לצורך ויזואליזציה או שימוש נוסף
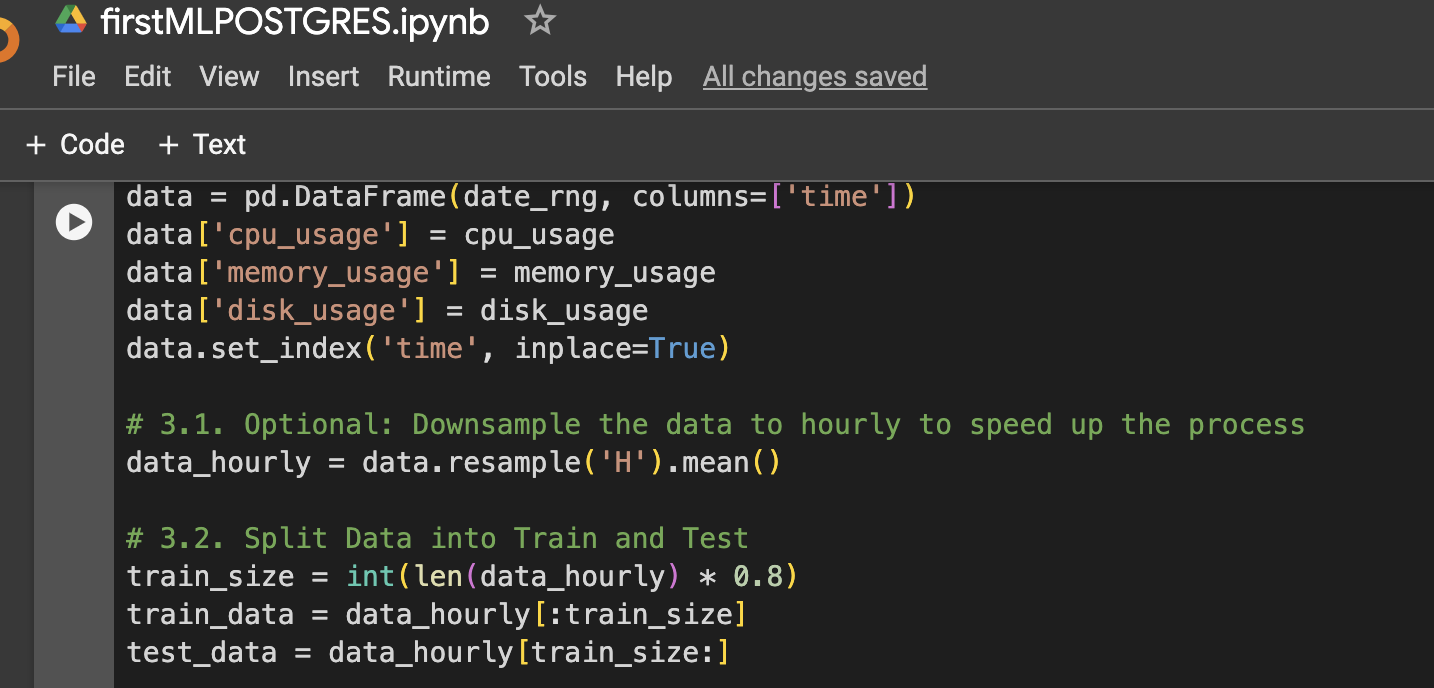
שלב 4: פונקציה להכנת נתוני LSTM, אימון, חיזוי ועיטוף
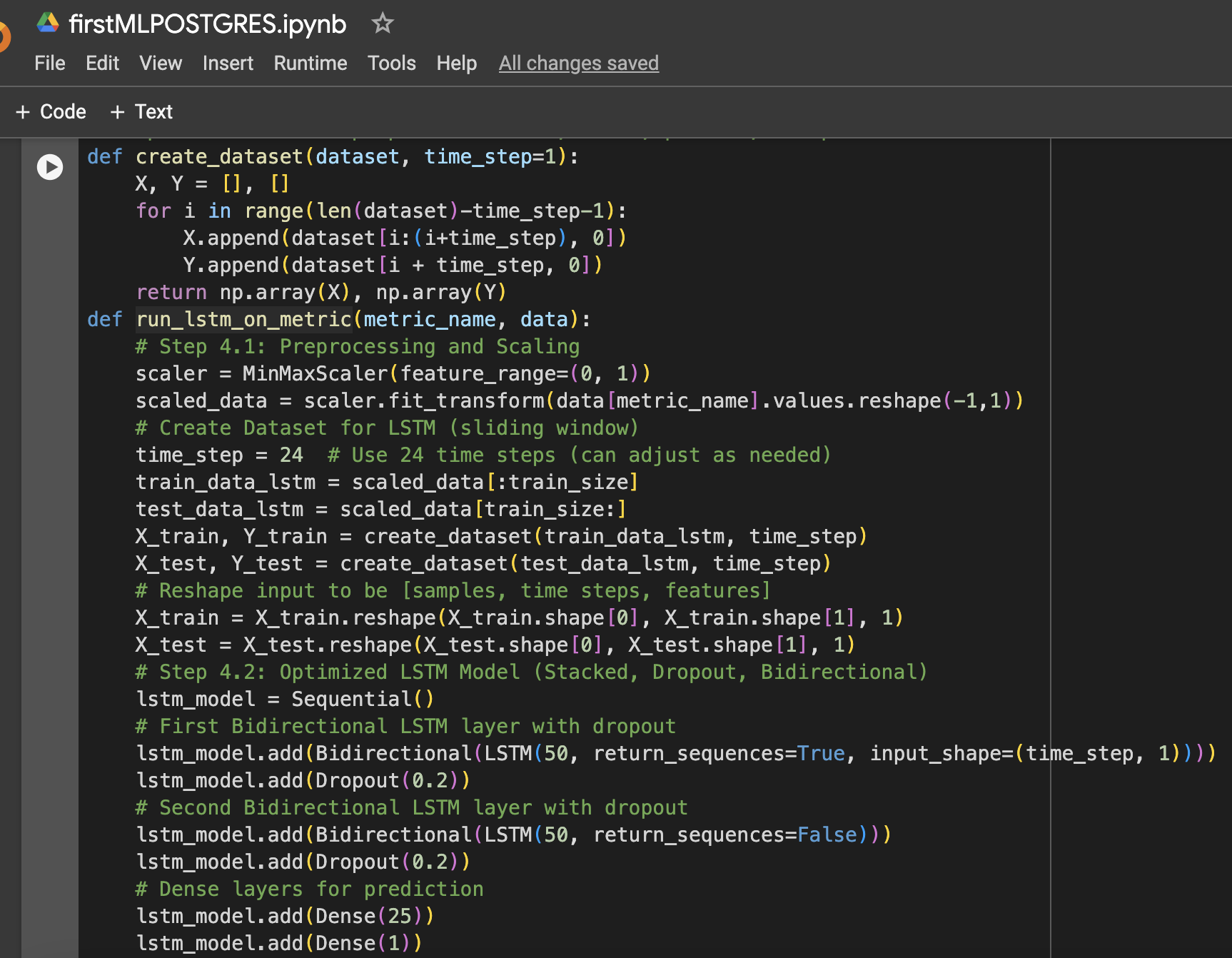
שלב 5: הרצת המודל עבור CPU, זיכרון ואחסון
תוצאות
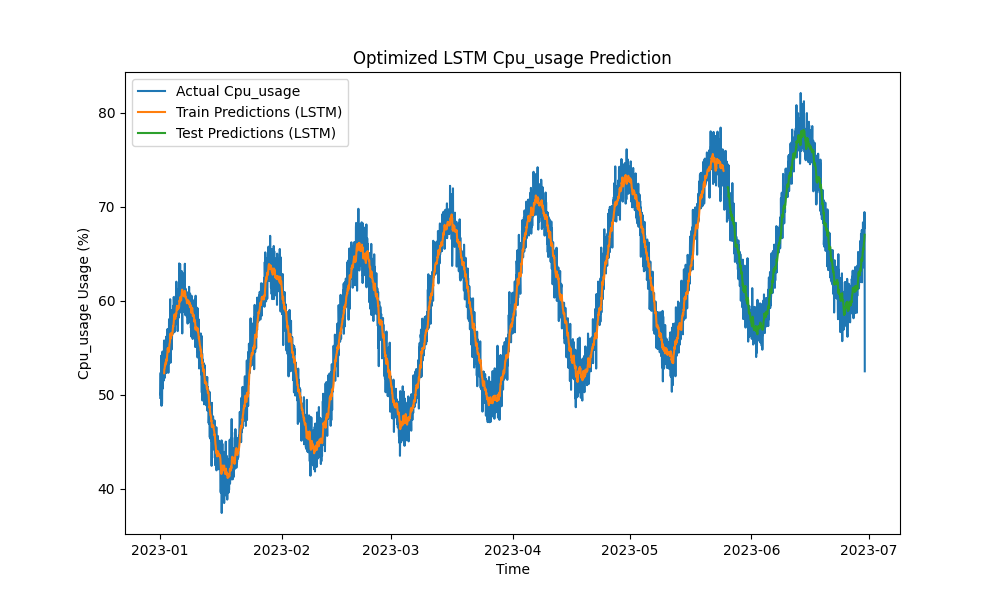
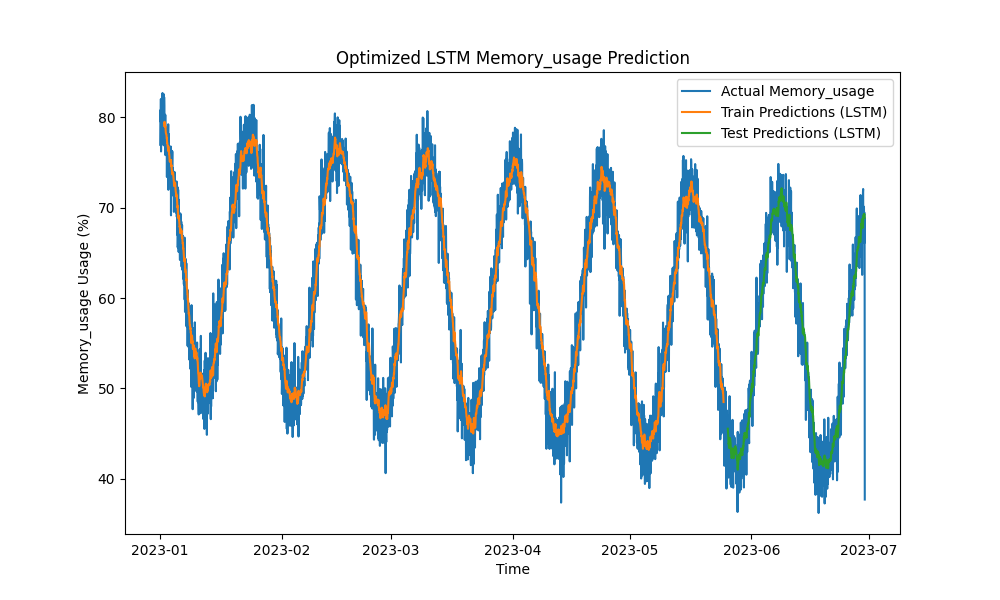
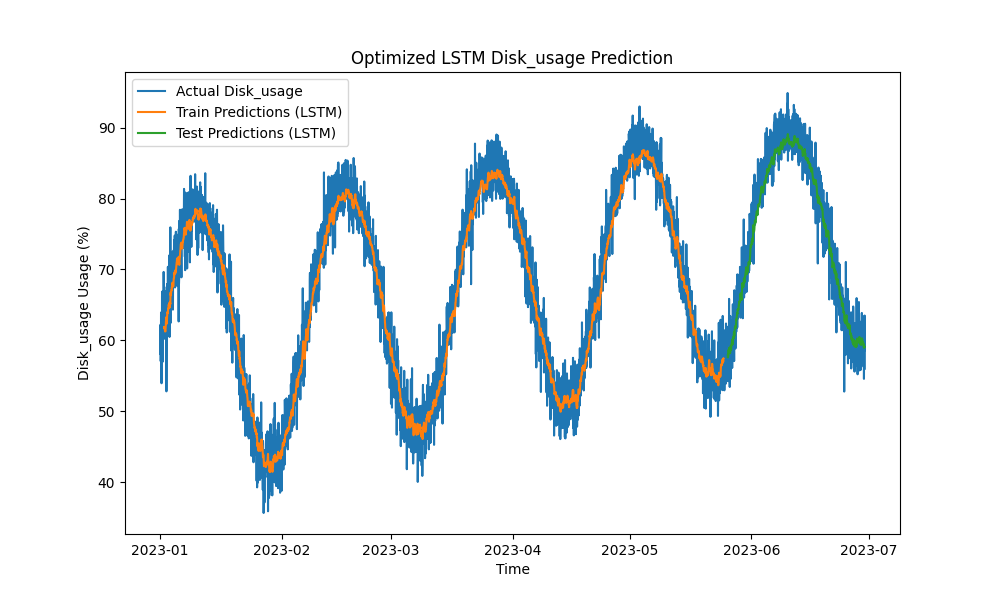
ה-מודל LSTM המאופטימלי עקף בביצועים שיטות מסורתיות כגון ARIMA ורגרסיה ליניארית בחיזוי שימוש ב-CPU, זיכרון ודיסק. החיזויים מעקבים בצורה צמודה אחרי שימוש המשאבים הממוצע, כולל את התבניות הקצרות והארוכות בצורה יעילה.
להלן הויזואליזציות של החיזויים של ה-LSTM:
תמונה 1: חיזוי שימוש ב-CPU מאופטימלי של LSTM
תמונה 2: חיזוי שימוש בזיכרון מאופטימלי של LSTM
תמונה 3: חיזוי שימוש בדיסק מאופטימלי של LSTM
אינטגרציה מעשית עם כלי מעקב PostgreSQL
כדי למקסם את יעילות דגם ה-LSTM, ניתן לחקור מגוון ביצועים פרקטיים בתוך אקוסיסטמת המעקב של PostgreSQL:
- אינטגרציה עם pgAdmin: ניתן להרחיב את pgAdmin כך שיציג תחזיות משאב תפעוליות בזמן אמת לצד מדדים אמיתיים, מאפשר למנהלי בסיסי נתונים להגיב מראש לחוסרי משאבים פוטנציאליים.
- לוחות מחוונים של Grafana: ניתן לאינטגרציה של מדדי PostgreSQL עם Grafana כדי להניף תחזיות של LSTM על גרפים ביצועים. ניתן להגדיר התראות כדי להודיע למנהלי בסיסי נתונים כאשר ניתן לצפות כי שימוש יתר יעבור על סף מוגדר מראש.
- מעקב ב-Prometheus: Prometheus יכול לנגרות מדדי PostgreSQL ולהשתמש בתחזיות ה-LSTM כדי להתריע, ליצור תחזיות, ולהגדיר התראות בהתבסס על צריכת משאבים צפויה.
- התגלגלות אוטומטית בסביבות עננים: במופעי PostgreSQL מארחים בענן (לדוגמה, AWS RDS, Google Cloud SQL), דגם ה-LSTM יכול להפעיל שירותי אוטוסקיילינג בהתבסס על צפייה בגידול צפוי בבקשות למשאבים.
- צינורות CI/CD: דגמי למידת מכונה יכולים להיות מעודכנים באופן רציף עם נתונים חדשים, להתאמת מחדש, ולהוצאה לפועל בזמן אמת דרך צינורות CI/CD, וודאי שהתחזיות נשמרות מדוייקות כשעומסי עבודה מתפתחים.
מסקנה
על ידי החלפת דגמי למידת מכונה LSTM כדי לחזות שימוש במעבד, זיכרון ואחסון, תכנון קיבולות של PostgreSQL יכול להעביר מגישה ראקטיבית לגישה פרואקטיבית. התוצאות שלנו מראות כי הדגם המתוקן של LSTM מספק תחזיות מדויקות, שמאפשרות ניהול משאבים יעיל יותר וחיסכון בעלויות, במיוחד בסביבות בענן.
כאשר אקוסיסטמות מסד נתונים מתרחבות ומורכבות יותר, הכלים החזויים אלה מתפקדים כחיוניים עבור מנהלי מסדי נתונים המחפשים לייעל את ניצול המשאבים, למנוע זמני לא פעילות ולהבטיח התרחבות. אם אתה ניהול מסדי נתונים של PostgreSQL בגדלים שונים, זה הזמן לנצל את למידת המכונה לתכנון קיבולות חזוי ולייעל את ניהול המשאבים שלך לפני שבעיות בביצועים עולות.
עבודה עתידית
שיפורים עתידיים עשויים לכלול:
- ניסויים עם ארכיטקטורות רשת עצבים נוספות (לדוגמה, דגמי GRU או Transformer) כדי להתמודד עם עומסי עבודה דינמיים יותר.
- הרחבת המתודולוגיה לפיתוחים מרובי צמתים ומחולקים של PostgreSQL, כאשר תעבורת הרשת והאופטימיזציה של אחסון משחקים גם משמעותיים.
- יישום אזהרות בזמן אמת ושילוב נוסף של תחזיות במערכת ההפעלה של PostgreSQL לניהול אוטומטי יותר.
- ניסויים עם נתוני Oracle Automated Workload Repository (AWR) לתחזיות עומס עבודה של מסד הנתונים של Oracle
Source:
https://dzone.com/articles/applying-machine-learning-for-predictive-capacity