













Na minha jornada de uma década pela finança quantitativa, encontrei inúmeras distribuições estatísticas, mas poucas se mostraram tão intrigantemente nomeadas e, ao mesmo tempo, valiosas na prática quanto a distribuição binomial negativa. Ao analisar padrões de negociação e modelos de risco, descobri que essa distribuição, apesar de seu nome aparentemente pessimista, oferece insights sobre processos de contagem que muitos modelos mais simples falham em capturar.
A distribuição binomial negativa fornece uma estrutura sofisticada para modelar tais cenários, oferecendo maior flexibilidade do que seus equivalentes mais simples, como a distribuição de Poisson. Ela serve como uma extensão natural da distribuição binomial, adaptando-se a situações em que precisamos modelar o número de tentativas até que um certo número de eventos ocorra, em vez do número de eventos em um número fixo de tentativas.
Neste guia abrangente, exploraremos as fundações matemáticas da distribuição binomial negativa, suas aplicações práticas e a implementação em Python e R. Começando por suas propriedades básicas e avançando para aplicações mais complexas, construiremos uma compreensão completa desta poderosa ferramenta estatística.
O que é a Distribuição Binomial Negativa?
A distribuição binomial negativa originou-se no século 18 através do estudo da probabilidade em jogos de azar. Esta distribuição de probabilidade discreta modela o número de falhas em uma sequência de testes de Bernoulli independentes antes de alcançar um número predefinido de sucessos. Cada teste deve ser independente e ter a mesma probabilidade de sucesso.
Para entender essa distribuição de forma intuitiva, considere um experimento simples: entrevistar candidatos até encontrar três qualificados para uma posição. A distribuição modelaria o número de entrevistas malsucedidas (falhas) necessárias antes de encontrar esses três candidatos qualificados (sucessos). Isso difere fundamentalmente da distribuição binomial, que modela o número de sucessos em um número fixo de testes – como o número de candidatos qualificados encontrados em exatamente 20 entrevistas.
Então, você pode ver, mesmo que o nome “binomial negativa” possa levantar sobrancelhas, isso não implica nada negativo no sentido convencional. O aspecto “negativo” deriva de sua origem histórica envolvendo expoentes negativos.
Onde a Distribuição Binomial Negativa é Usada
A distribuição binomial negativa é usada de muitas maneiras diferentes. Ela é utilizada em finanças, que é onde eu mais a coloco, onde modela cenários como o número de dias de negociação até alcançar um nível de lucro alvo, ou o número de solicitações de crédito analisadas antes de encontrar um certo número de mutuários qualificados.
De maneira mais geral, a distribuição binomial negativa também se mostrou valiosa para modelar dados de contagem quando a variância excede a média, um fenômeno conhecido como sobredispersão. Enquanto a distribuição de Poisson assume que a média é igual à variância, dados de contagem do mundo real frequentemente apresentam maior variabilidade. Por exemplo, na epidemiologia, o número de casos de doenças muitas vezes varia mais do que um modelo de Poisson preveria, tornando a distribuição binomial negativa mais apropriada para modelar a propagação de doenças.
Geneticistas confiam nessa distribuição ao analisar dados de sequenciamento. Em experimentos de sequenciamento de RNA, os genes mostram níveis de expressão variados com alta variabilidade. A binomial negativa modela o número de leituras de sequência mapeadas a cada gene, levando em conta tanto a variação técnica quanto a biológica. Isso ajuda a identificar genes diferencialmente expressos com mais precisão do que métodos que assumem variância constante.
Em estudos ecológicos, os pesquisadores o utilizam para modelar a abundância de espécies. Considere estudar populações de pássaros: algumas áreas podem ter poucos pássaros enquanto outras têm grandes aglomerados, criando uma variância maior do que o esperado. A binomial negativa modela efetivamente essas distribuições agrupadas, ajudando os ecologistas a entender a dinâmica populacional e planejar esforços de conservação.
Características da Distribuição Binomial Negativa
A distribuição binomial negativa é caracterizada por dois parâmetros-chave que determinam sua forma e comportamento. Entender esses parâmetros e a representação matemática nos ajuda a compreender como essa distribuição modela fenômenos do mundo real. Vamos explorar essas características de forma sistemática.
Representação matemática e parâmetros
A distribuição binomial negativa possui dois parâmetros fundamentais:
- r – O número alvo de sucessos (um inteiro positivo)
- p – A probabilidade de sucesso em cada tentativa (entre 0 e 1)
Esses parâmetros moldam o comportamento da distribuição. Considere acompanhar o número de chamadas de vendas necessárias para garantir cinco novos clientes (r = 5) quando cada chamada tem uma chance de 20% de sucesso (p = 0,2). O valor de r determina nosso ponto de parada, enquanto p influencia quanto tempo podemos esperar continuar fazendo chamadas.
Quando aumentamos r mantendo p constante, a distribuição se desloca para a direita e se torna mais espalhada, refletindo que precisamos de mais tentativas para alcançar mais sucessos. Por outro lado, quando aumentamos p mantendo r constante, a distribuição se desloca para a esquerda e se torna mais concentrada, indicando que menos tentativas são geralmente necessárias quando o sucesso é mais provável.
Função de massa de probabilidade (PMF) e função de distribuição acumulada (CDF)
A função de massa de probabilidade nos dá a probabilidade de precisar exatamente de k falhas antes de alcançar r sucessos. Para a distribuição binomial negativa, a PMF é:
Onde:
- X representa o número de falhas antes de alcançar r sucessos
- (k+r-1 escolher k) é o coeficiente binomial, representando o número de maneiras de organizar k falhas e r-1 sucessos
- p é a probabilidade de sucesso
- r é o número desejado de sucessos
- K é o número de falhas
Exemplo: No controle de qualidade, se precisamos de 3 unidades defeituosas (r = 3) e cada unidade tem uma chance de 10% de ser defeituosa (p = 0,1), podemos calcular probabilidades específicas. Por exemplo, a probabilidade de obter exatamente 5 unidades não defeituosas (k = 5) antes de encontrar a terceira unidade defeituosa é:
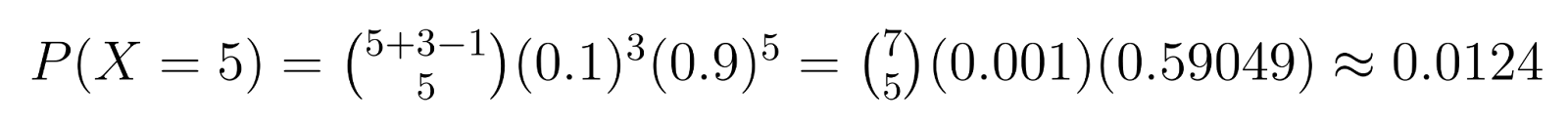
Esse cálculo mostra uma chance de cerca de 1,24% de precisar exatamente de 5 unidades não defeituosas antes de encontrar a terceira unidade defeituosa.
A função de distribuição acumulada (CDF) se baseia na PMF, nos dando a probabilidade de requerer k ou menos falhas antes de alcançar nosso número alvo de sucessos:
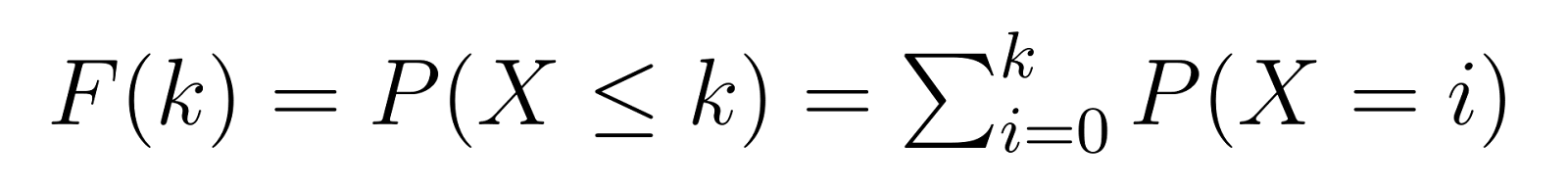
Isso significa que F(k) nos dá a probabilidade de precisar de no máximo k unidades não defeituosas antes de encontrar nossa terceira unidade defeituosa. Por exemplo, F(5) nos daria a probabilidade de precisar de 5 ou menos unidades não defeituosas.
Média e variância
A média (valor esperado) e a variância da distribuição binomial negativa têm fórmulas elegantes que revelam propriedades importantes sobre a média (μ) e a variância (σ²).
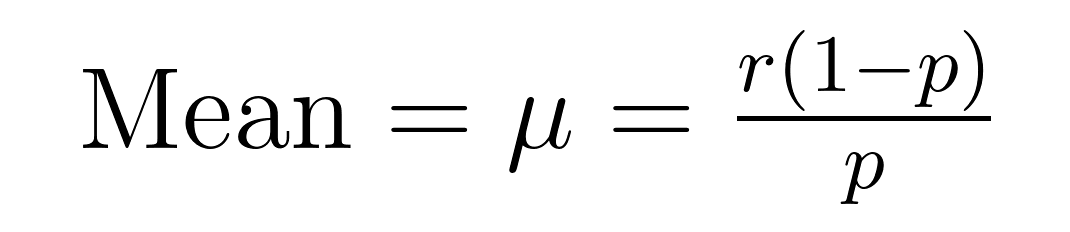
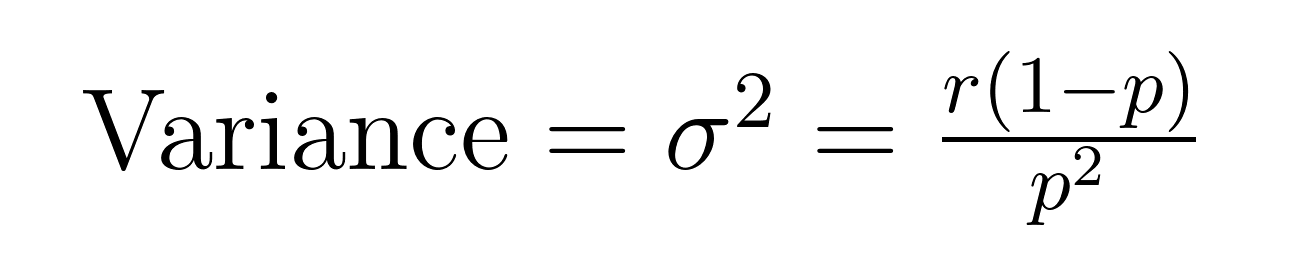
Essas fórmulas demonstram por que essa distribuição se destaca na modelagem de dados sobre-dispersos. Note que a variância é sempre maior que a média por um fator de 1/p. Essa propriedade embutida a torna naturalmente adequada para conjuntos de dados onde a variabilidade excede a média.
Por exemplo, se estamos modelando chamadas de atendimento ao cliente onde esperamos resolver 5 casos (r = 5) com uma taxa de sucesso de 20% por tentativa (p = 0,2), o número esperado de tentativas fracassadas seria:
- Média = 5(1-0,2)/0,2 = 20 falhas
- Variância = 5(1-0,2)/0,2² = 100
Essa maior variância explica a realidade de que alguns casos podem ser resolvidos rapidamente, enquanto outros requerem muitos mais tentativas, um padrão frequentemente observado em cenários do mundo real.
Compreender essas características nos ajuda a reconhecer quando aplicar a distribuição binomial negativa e como interpretar seus resultados de forma eficaz. Essas bases matemáticas preparam o terreno para aplicações práticas e implementação, que exploraremos nas seções seguintes.
Implementação em Python e R
Vamos validar nosso exemplo anterior: calcular a probabilidade de obter exatamente 5 unidades não defeituosas antes de encontrar a terceira unidade defeituosa (r=3, p=0.1).
Implementação em Python
import scipy.stats as stats import math def calculate_nb_pmf(k, r, p): # Calcular coeficiente binomial (k+r-1 escolher k) binom_coef = math.comb(k + r - 1, k) # Calcular p^r * (1-p)^k prob = (p ** r) * ((1 - p) ** k) return binom_coef * prob # Nossos parâmetros de exemplo k = 5 # falhas (unidades não defeituosas) r = 3 # sucessos (unidades defeituosas) p = 0.1 # probabilidade de sucesso (defeituosa) # Calcular usando nossa função prob_manual = calculate_nb_pmf(k, r, p) print(f"Manual calculation: {prob_manual:.4f}") # Verificar usando scipy prob_scipy = stats.nbinom.pmf(k, r, p) print(f"SciPy calculation: {prob_scipy:.4f}")
O trecho de código acima deve produzir o seguinte:
Manual calculation: 0.0124 SciPy calculation: 0.0124
Implementação em R
# Calcular função de massa de probabilidade k <- 5 # falhas (unidades não defeituosas) r <- 3 # sucessos (unidades defeituosas) p <- 0.1 # probabilidade de sucesso (defeituosa) # Usando dnbinom prob_r <- dnbinom(k, size = r, prob = p) print(sprintf("R calculation: %.4f", prob_r)) # Cálculo manual para verificação manual_calc <- choose(k + r - 1, k) * p^r * (1-p)^k print(sprintf("Manual calculation: %.4f", manual_calc))
O trecho de código acima deve gerar os mesmos números que nosso exemplo em Python:
R calculation: 0.0124 Manual Calculation: 0.0124
Ambas as implementações confirmam nossa probabilidade calculada anteriormente de aproximadamente 0,0124 ou 1,24%.
Relação com Outras Distribuições
Entender como a distribuição binomial negativa se relaciona com outras distribuições de probabilidade ajuda a esclarecer quando usar cada uma. A distribuição binomial negativa tem conexões únicas com várias distribuições importantes na estatística.
Distribuição binomial negativa vs. distribuição binomial
A distribuição binomial serve como um ponto de partida fundamental. Enquanto a distribuição binomial conta sucessos em um número fixo de tentativas, a distribuição binomial negativa inverte esse conceito ao contar as tentativas necessárias para um número fixo de sucessos. Essas distribuições são complementares – se você precisa exatamente de 3 sucessos e quer saber a probabilidade de alcançar isso em exatamente 8 tentativas, use a distribuição binomial. Se você quer saber a probabilidade de precisar exatamente de 8 tentativas para obter 3 sucessos, use a binomial negativa.
Distribuição binomial negativa vs. distribuição de Poisson
A distribuição de Poisson é frequentemente comparada à binomial negativa ao modelar dados de contagem. Ambas lidam com eventos discretos, mas diferem em suas suposições sobre variância. A característica definidora da distribuição de Poisson é que sua média é igual à sua variância. No entanto, dados de contagem do mundo real frequentemente exibem sobredispersão, onde a variância excede a média. A distribuição binomial negativa acomoda naturalmente essa variabilidade extra, tornando-a mais adequada para fenômenos como:
- Padrões de surtos de doenças onde alguns casos levam a muitas mais infecções
- Dados de reclamações de clientes onde alguns problemas geram várias reclamações relacionadas
- Picos de tráfego do site onde certos eventos causam níveis elevados de atividade
Distribuição binomial negativa vs. distribuição geométrica
A distribuição geométrica emerge como um caso especial da binomial negativa quando definimos r=1, o que significa que estamos esperando apenas um sucesso. Isso a torna perfeita para modelar cenários como:
- Número de tentativas até o primeiro sucesso
- Tempo até a primeira falha em testes de confiabilidade
- Número de tentativas até o primeiro avanço na pesquisa
Distribuição binomial negativa como uma mistura Gamma-Poisson
Finalmente, a binomial negativa pode ser derivada como uma mistura Gamma-Poisson, fornecendo uma base teórica para sua capacidade de lidar com sobredispersão. Essa relação ajuda a explicar por que a distribuição binomial negativa funciona bem em modelos hierárquicos onde as taxas individuais de ocorrência variam de acordo com uma distribuição gamma.
Vantagens e Limitações
A distribuição binomial negativa oferece vantagens distintas que a tornam valiosa para modelar fenômenos do mundo real, ao mesmo tempo que possui limitações importantes que os cientistas de dados devem considerar.
A regressão binomial negativa estende a regressão tradicional para dados de contagem, especialmente quando os dados apresentam sobredispersão. Enquanto a regressão de Poisson assume que a média é igual à variância, a regressão binomial negativa relaxa essa restrição, tornando-a mais adequada para aplicações do mundo real.
Considere um cenário de call center: queremos prever o número de chamadas de atendimento ao cliente por hora. Nossos preditores podem incluir:
- Hora do dia
- Dia da semana
- Status de feriado
- Atividade de campanha de marketing
- Condições climáticas
A regressão Poisson padrão pode subestimar a variação nos volumes de chamadas, especialmente durante horários de pico ou eventos especiais. A regressão binomial negativa leva em conta essa variabilidade extra, proporcionando previsões e intervalos de confiança mais realistas.
Conclusão
Através de sua capacidade de modelar dados de contagem complexos e lidar com sobredispersão, a distribuição binomial negativa continua sendo uma ferramenta essencial para entender e prever fenômenos do mundo real. Como você viu, ela se destaca na modelagem de dados sobredispersos, oferece flexibilidade para modelar uma grande variedade de cenários diferentes e se estende naturalmente à análise de regressão.
Se você está interessado em aprofundar seu entendimento sobre distribuições de probabilidade e suas aplicações, nossos Cursos de Probabilidade e Estatística oferecem uma cobertura abrangente desses tópicos. Nossos cursos incluem exercícios práticos com conjuntos de dados do mundo real, ajudando você a dominar tanto os conceitos teóricos quanto as implementações práticas em Python e R. Além disso, considere nossa trilha de Cientista de Aprendizado de Máquina em Python. Eu prometo que você aprenderá muito.
Source:
https://www.datacamp.com/tutorial/negative-binomial-distribution