













En mi viaje de una década a través de las finanzas cuantitativas, he encontrado numerosas distribuciones estadísticas, pero pocas han demostrado ser tan intrigantemente nombradas y, al mismo tiempo, valiosas en la práctica como la distribución binomial negativa. Al analizar patrones de trading y modelos de riesgo, descubrí que esta distribución, a pesar de su nombre aparentemente pesimista, ofrece información sobre procesos de conteo que muchos modelos más simples no logran capturar.
La distribución binomial negativa proporciona un marco sofisticado para modelar tales escenarios, ofreciendo mayor flexibilidad que sus contrapartes más simples como la distribución de Poisson. Sirve como una extensión natural de la distribución binomial, adaptándose a situaciones donde necesitamos modelar el número de ensayos hasta que ocurra un cierto número de eventos, en lugar del número de eventos en un número fijo de ensayos.
En esta guía completa, exploraremos los fundamentos matemáticos de la distribución binomial negativa, sus aplicaciones prácticas y su implementación en Python y R. Comenzando desde sus propiedades básicas y avanzando hacia aplicaciones avanzadas, construiremos una comprensión exhaustiva de esta poderosa herramienta estadística.
¿Qué es la Distribución Binomial Negativa?
La distribución binomial negativa se originó en el siglo XVIII a través del estudio de la probabilidad en juegos de azar. Esta distribución de probabilidad discreta modela el número de fracasos en una secuencia de pruebas de Bernoulli independientes antes de lograr un número predeterminado de éxitos. Cada prueba debe ser independiente y tener la misma probabilidad de éxito.
Para entender esta distribución de manera intuitiva, considera un experimento simple: entrevistar candidatos hasta encontrar tres calificados para un puesto. La distribución modelaría el número de entrevistas sin éxito (fracasos) necesarias antes de encontrar estos tres candidatos calificados (éxitos). Esto difiere fundamentalmente de la distribución binomial, que en cambio modela el número de éxitos en un número fijo de pruebas, como el número de candidatos calificados encontrados exactamente en 20 entrevistas.
Como puedes ver, aunque el nombre “binomial negativa” pueda levantar cejas, no implica nada negativo en el sentido convencional. El aspecto “negativo” proviene de su derivación histórica que implica exponentes negativos.
Dónde se Utiliza la Distribución Binomial Negativa
La distribución binomial negativa se utiliza de muchas maneras diferentes. Se utiliza en finanzas, que es donde más la ubico, donde modela escenarios como el número de días de negociación hasta alcanzar un nivel de beneficio objetivo, o el número de solicitudes de crédito revisadas antes de encontrar cierto número de prestatarios calificados.
Más generalmente, la distribución binomial negativa también ha demostrado ser valiosa para modelar datos de conteo cuando la varianza supera la media, un fenómeno conocido como sobredispersión. Mientras que la distribución de Poisson asume que la media es igual a la varianza, los datos de conteo del mundo real a menudo muestran una mayor variabilidad. Por ejemplo, en epidemiología, el número de casos de enfermedad a menudo varía más de lo que un modelo de Poisson predeciría, lo que hace que la distribución binomial negativa sea más apropiada para modelar la propagación de enfermedades.
Los genetistas confían en esta distribución al analizar datos de secuenciación. En experimentos de secuenciación de ARN, los genes muestran niveles de expresión variables con alta variabilidad. La binomial negativa modela el número de lecturas de secuencia asignadas a cada gen, teniendo en cuenta tanto la variación técnica como biológica. Esto ayuda a identificar genes diferencialmente expresados de manera más precisa que los métodos que asumen una varianza constante.
En estudios ecológicos, los investigadores lo utilizan para modelar la abundancia de especies. Al estudiar poblaciones de aves: algunas áreas pueden tener pocas aves mientras que otras tienen grandes conglomerados, creando una varianza mayor de lo esperado. La distribución binomial negativa modela eficazmente estas distribuciones agrupadas, ayudando a los ecologistas a comprender la dinámica de la población y planificar esfuerzos de conservación.
Características de la Distribución Binomial Negativa
La distribución binomial negativa se caracteriza por dos parámetros clave que determinan su forma y comportamiento. Comprender estos parámetros y la representación matemática nos ayuda a entender cómo esta distribución modela fenómenos del mundo real. Vamos a explorar estas características sistemáticamente.
Representación matemática y parámetros
La distribución binomial negativa tiene dos parámetros fundamentales:
- r – El número de éxitos deseado (un número entero positivo)
- p – La probabilidad de éxito en cada prueba (entre 0 y 1)
Estos parámetros determinan cómo se comporta la distribución. Considera el seguimiento del número de llamadas de ventas necesarias para asegurar cinco nuevos clientes (r = 5) cuando cada llamada tiene una probabilidad de éxito del 20% (p = 0.2). El valor de r determina nuestro punto de parada, mientras que p influye en cuánto tiempo podríamos esperar seguir haciendo llamadas.
Cuando aumentamos r manteniendo constante p, la distribución se desplaza hacia la derecha y se vuelve más dispersa, reflejando que necesitamos más pruebas para lograr más éxitos. Por el contrario, cuando aumentamos p manteniendo constante r, la distribución se desplaza hacia la izquierda y se vuelve más concentrada, lo que indica que generalmente se necesitan menos pruebas cuando el éxito es más probable.
Función de masa de probabilidad (PMF) y función de distribución acumulativa (CDF)
La función de masa de probabilidad nos da la probabilidad de requerir exactamente k fallos antes de lograr r éxitos. Para la distribución binomial negativa, la PMF es:
Donde:
- X representa el número de fallos antes de lograr r éxitos
- (k+r-1 elige k) es el coeficiente binomial, que representa el número de formas de organizar k fallos y r-1 éxitos
- p es la probabilidad de éxito
- r es el número deseado de éxitos
- K es el número de fallos
Ejemplo: En el control de calidad, si necesitamos 3 unidades defectuosas (r = 3) y cada unidad tiene un 10% de probabilidad de ser defectuosa (p = 0.1), podemos calcular probabilidades específicas. Por ejemplo, la probabilidad de obtener exactamente 5 unidades no defectuosas (k = 5) antes de encontrar la tercera defectuosa es:
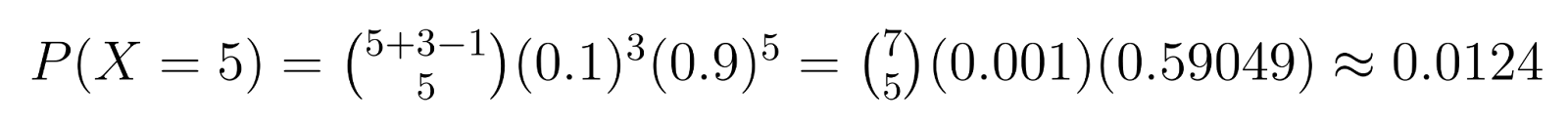
Este cálculo muestra alrededor de un 1.24% de probabilidad de necesitar exactamente 5 unidades no defectuosas antes de encontrar la tercera defectuosa.
La función de distribución acumulativa (CDF) se basa en la PMF, dándonos la probabilidad de necesitar k o menos fallos antes de lograr nuestro número objetivo de éxitos:
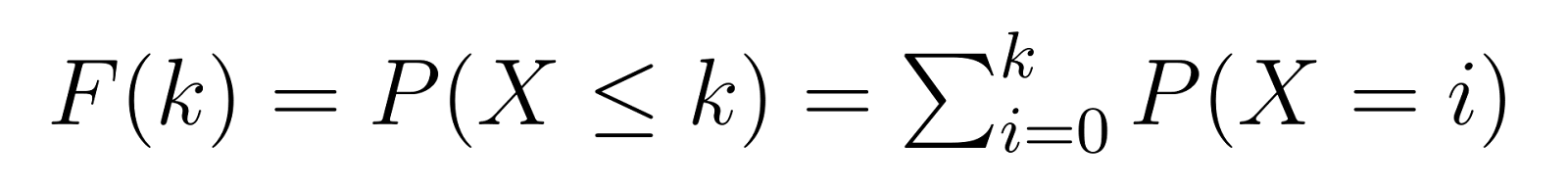
Esto significa que F(k) nos da la probabilidad de necesitar como máximo k unidades no defectuosas antes de encontrar nuestra tercera defectuosa. Por ejemplo, F(5) nos daría la probabilidad de necesitar 5 o menos unidades no defectuosas.
Media y varianza
La media (valor esperado) y la varianza de la distribución binomial negativa tienen fórmulas elegantes que revelan propiedades importantes sobre la media (μ) y la varianza (σ²).
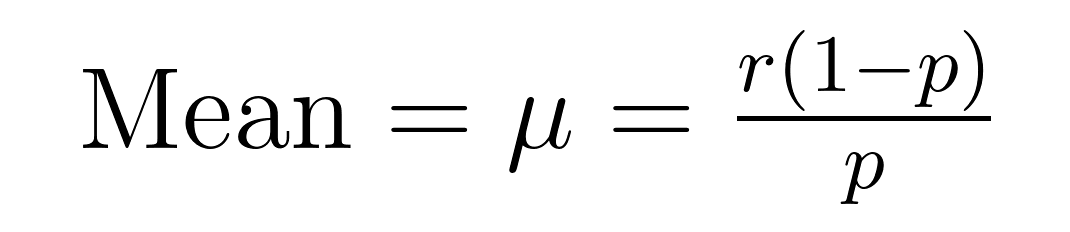
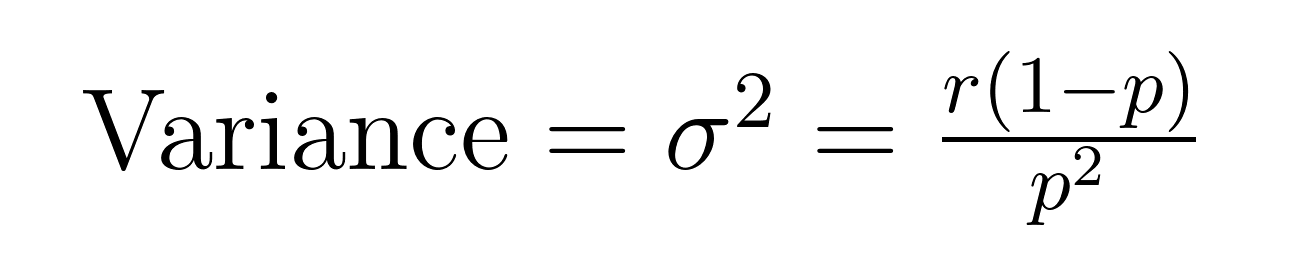
Estas fórmulas demuestran por qué esta distribución destaca en la modelización de datos sobredispersos. Observa que la varianza siempre es mayor que la media por un factor de 1/p. Esta propiedad incorporada la hace naturalmente adecuada para conjuntos de datos donde la variabilidad supera la media.
Por ejemplo, si estamos modelando llamadas de servicio al cliente donde esperamos resolver 5 casos (r = 5) con una tasa de éxito del 20% por intento (p = 0.2), el número esperado de intentos fallidos sería:
- Media = 5(1-0.2)/0.2 = 20 fallos
- Varianza = 5(1-0.2)/0.2² = 100
Esta mayor varianza explica la realidad de que algunos casos pueden resolverse rápidamente mientras que otros requieren muchos más intentos, un patrón a menudo observado en escenarios del mundo real.
Comprender estas características nos ayuda a reconocer cuándo aplicar la distribución binomial negativa y cómo interpretar sus resultados de manera efectiva. Estos fundamentos matemáticos preparan el escenario para aplicaciones prácticas e implementación, que exploraremos en secciones posteriores.
Implementación en Python y R
Validemos nuestro ejemplo anterior: calcular la probabilidad de obtener exactamente 5 unidades no defectuosas antes de encontrar la tercera defectuosa (r=3, p=0.1).
Implementación en Python
import scipy.stats as stats import math def calculate_nb_pmf(k, r, p): # Calcular el coeficiente binomial (k+r-1 elegir k) binom_coef = math.comb(k + r - 1, k) # Calcular p^r * (1-p)^k prob = (p ** r) * ((1 - p) ** k) return binom_coef * prob # Nuestros parámetros de ejemplo k = 5 # fracasos (unidades no defectuosas) r = 3 # éxitos (unidades defectuosas) p = 0.1 # probabilidad de éxito (defectuosa) # Calcular usando nuestra función prob_manual = calculate_nb_pmf(k, r, p) print(f"Manual calculation: {prob_manual:.4f}") # Verificar usando scipy prob_scipy = stats.nbinom.pmf(k, r, p) print(f"SciPy calculation: {prob_scipy:.4f}")
El fragmento de código anterior debería producir la siguiente salida:
Manual calculation: 0.0124 SciPy calculation: 0.0124
R implementación
# Calcular la función de masa de probabilidad k <- 5 # fracasos (unidades no defectuosas) r <- 3 # éxitos (unidades defectuosas) p <- 0.1 # probabilidad de éxito (defectuosa) # Usando dnbinom prob_r <- dnbinom(k, size = r, prob = p) print(sprintf("R calculation: %.4f", prob_r)) # Cálculo manual para verificación manual_calc <- choose(k + r - 1, k) * p^r * (1-p)^k print(sprintf("Manual calculation: %.4f", manual_calc))
El fragmento de código anterior debería mostrar los mismos números que nuestro ejemplo en Python:
R calculation: 0.0124 Manual Calculation: 0.0124
Ambas implementaciones confirman nuestra probabilidad calculada anteriormente de aproximadamente 0.0124 o 1.24%.
Relación con Otras Distribuciones
Entender cómo la distribución binomial negativa se relaciona con otras distribuciones de probabilidad ayuda a aclarar cuándo usar cada una. La distribución binomial negativa tiene conexiones únicas con varias distribuciones importantes en estadística.
Distribución binomial negativa vs. distribución binomial
La distribución binomial sirve como punto de partida fundamental. Mientras que la distribución binomial cuenta los éxitos en un número fijo de ensayos, la binomial negativa invierte este concepto contando los ensayos necesarios para un número fijo de éxitos. Estas distribuciones son complementarias: si necesitas exactamente 3 éxitos y quieres saber la probabilidad de lograr esto en exactamente 8 ensayos, utiliza la distribución binomial. Si quieres saber la probabilidad de necesitar exactamente 8 ensayos para obtener 3 éxitos, utiliza la binomial negativa.
Distribución binomial negativa vs. distribución de Poisson
La distribución de Poisson se suele comparar con la binomial negativa al modelar datos de recuento. Ambas manejan eventos discretos, pero difieren en sus suposiciones de varianza. La característica definitoria de la distribución de Poisson es que su media es igual a su varianza. Sin embargo, los datos de recuento del mundo real frecuentemente muestran sobredispersión, donde la varianza supera la media. La distribución binomial negativa acomoda naturalmente esta variabilidad adicional, haciéndola más adecuada para fenómenos como:
- Patrones de brote de enfermedades donde algunos casos llevan a muchas más infecciones
- Datos de quejas de clientes donde algunos problemas generan múltiples quejas relacionadas
- Picos de tráfico en el sitio web donde ciertos eventos causan niveles elevados de actividad
Distribución binomial negativa vs. distribución geométrica
La distribución geométrica surge como un caso especial de la binomial negativa cuando establecemos r=1, lo que significa que estamos esperando solo un éxito. Esto la hace perfecta para modelar escenarios como:
- Número de intentos hasta el primer éxito
- Tiempo hasta la primera falla en pruebas de confiabilidad
- Número de pruebas hasta el primer avance en la investigación
Distribución binomial negativa como una mezcla Gamma-Poisson
Finalmente, la binomial negativa puede derivarse como una mezcla Gamma-Poisson, proporcionando una base teórica para su capacidad de manejar la sobredispersión. Esta relación ayuda a explicar por qué la distribución binomial negativa funciona bien en modelos jerárquicos donde las tasas individuales de ocurrencia varían de acuerdo a una distribución gamma.
Ventajas y Limitaciones
La distribución binomial negativa ofrece ventajas distintas que la hacen valiosa para modelar fenómenos del mundo real, aunque también tiene limitaciones importantes que los científicos de datos deben considerar.
La regresión binomial negativa extiende la regresión tradicional a datos de conteo, particularmente cuando los datos muestran sobredispersión. Mientras que la regresión de Poisson asume que la media es igual a la varianza, la regresión binomial negativa relaja esta restricción, haciéndola más adecuada para aplicaciones del mundo real.
Consideremos un escenario de centro de llamadas: queremos predecir el número de llamadas de servicio al cliente por hora. Nuestros predictores podrían incluir:
- Hora del día
- Día de la semana
- Estado de festivo
- Actividad de campaña de marketing
- Condiciones meteorológicas
La regresión de Poisson estándar podría subestimar la variación en los volúmenes de llamadas, especialmente durante las horas pico o eventos especiales. La regresión binomial negativa tiene en cuenta esta variabilidad adicional, proporcionando predicciones más realistas e intervalos de confianza.
Conclusión
Gracias a su capacidad para modelar datos de recuento complejos y manejar la sobredispersión, la distribución binomial negativa sigue siendo una herramienta esencial para comprender y predecir fenómenos del mundo real. Como has visto, sobresale en el modelado de datos sobredispersos, brinda flexibilidad para modelar una gran cantidad de escenarios diferentes e incluso se extiende naturalmente al análisis de regresión.
Si estás interesado en profundizar tu comprensión de las distribuciones de probabilidad y sus aplicaciones, nuestros cursos de Probabilidad y Estadística ofrecen una cobertura exhaustiva de estos temas. Nuestros cursos incluyen ejercicios prácticos con conjuntos de datos del mundo real, que te ayudarán a dominar tanto los conceptos teóricos como las implementaciones prácticas en Python y R. Además, considera nuestra trayectoria profesional de Científico del Aprendizaje Automático en Python. Te prometo que aprenderás mucho.
Source:
https://www.datacamp.com/tutorial/negative-binomial-distribution