













人工智慧(AI)的快速進化導致大型語言模型(LLM)與AI代理之間產生強大的协同作用。這種活的交互作用就像是大卫與歌利亞的故事(但不包括戰鬥),其中靈活的AI代理增強並放大了巨大LLM的能力。
本手册將探讨如何AI代理(類似於大卫)正在為LLM(我們現代的哥利亞)注入強大力量,以幫助革新各種行業和科學領域。
目錄
-
第3章:AI代理最耀眼之處
語言模型中AI代理的出現
AI代理是設計來感知它們的環境、作出決策並執行行為以達到特定目標的自動系統。當與LLM結合時,這些代理可以執行複雜任務、對信息進行推理並產生創新解決方案。
這種結合已在多個領域帶來重要進步,從軟件開發到科學研究。
在各行業中的革命性影響
AI代理與LLM的結合對各種行業產生了深遠的影響:
-
軟件開發:如GitHub Copilot等AI驱动的編程助手已經展示出能夠生成高达40%的代碼,從而使得開發速度显著提升了55%。
-
教育:AI驱动的学习助手已經在減少平均課程完成時間27%方面显示出前景,有潛在的革命性地改变了教育領域。
-
運輸
: 預測顯示到2030年將有10%的車輛實現無人駕駛,自動駕駛汽車中的自動化AI代理即將改變運輸產業的格局。
AI代理和大型語言模型在科學研究中最令人興奮的應用之一是:
藥物發現
: AI代理通过分析大量數據集并預測潛在的藥物候選物,加快藥物發現過程,明顯縮短了與傳統方法相關的時間和成本。
-
粒子物理:在CERN的大型強子對撞機上,AI代理商被用於分析粒子對撞數據,利用異常檢測來識別可能有潛在粒子存在的线索。
-
科學研究:AI代理商透過分析過去的研究、識別出人意料的聯繫,並提出新的實驗提案,提升科學發現的速率和範圍。
人工智能代理人和大型語言模型(LLM)的融合正在推動人工智能進入一個前所未有的能障新时期。這本綜合手冊探討了這兩種技術之間动态的交互作用,揭示它們结合起来革新技术行業和解決複雜問題的潛在威力。
我們將追溯到AI的起源直到自主代理和精密LLM的崛起。我們還將探索道德考慮,這是负责任的AI發展的基礎。這將幫助我們確保這些技術與我們的人類價值和社會福祉保持一致。
到這本手冊結束時,您將對AI代理人和LLM的协同力量有深刻的理解,以及 leverag 這項前沿技術的知識和工具。
第1章:AI代理人和語言模型简介
AI代理人和大型語言模型是什麼?
人工智慧(AI)的快速發展帶來了大型語言模型(LLM)和AI代理人之間的革命性协同效应。
人工智能代理人 是設計用來感知它們的環境、作出決策並執行行為以實現特定目標的 autonomy 系統。它們展現出如自主性、感知、反應性、推理、決策、學習、溝通和目標導向等特點。
另一方面,LLM 是複雜的人工智能系統,它們使用深度學習技術和大量數據集來理解、生成和預測似人文本。
這些模型,如 GPT-4、Mistral、LLama,在自然語言處理任務中,包括文本生成、語言翻譯和對話代理,展現出出色的能力。
AI 代理人的關鍵特性
AI 代理人擁有多個定義他們與傳統軟體不同的特點:
-
自主性:它們可以獨立操作,而不需要不斷的人工干預。
-
感知:代理人可以通過各種輸入感知和解釋它們的環境。
-
反應性:它們積極地對環境中的變化作出反應。
-
推理與決策:代理可以分析數據並做出明智的選擇。
-
學習:透過經驗,它們隨時間提高自己的性能。
-
溝通:代理可以通過不同的方法與其他代理或人類互動。
-
目標導向:它們被設計來實現特定的目標。
大型語言模型的功能
大型語言模型已展現出廣泛的功能,包括:
-
文字生成:LLM可以根據提示產生一致且相關的文本。
-
語言翻譯:它們可以高精度地在不同語言之間翻譯文字。
-
簡化和
摘要:LLM可以將長文本簡化為扼要的摘要,同時保留重要信息。
- 問題回答:它們可以基於其庞大的知識庫提供準確的回答。
- 情感分析:LLM可以分析並確定給定文本中所表達的情感。
- 程式碼生成:它們可以根據自然語言描述生成程式片段或整個函數。
AI代理商的等級
AI代理商可以根據其能力與複雜性被分類為不同等級。根據arXiv上的一篇論文,AI代理商被分類為五個等級:
- 等級1 (L1):作為研究助手之AI代理商,科學家設定假設並指派任務以實現目標。
-
第2層(L2)
: 能夠自決進行特定任務的人工智慧代理,這些任務局限在定義好的範圍內,例如數據分析或簡單的決策。
-
第3層(L3): 能夠從經驗學習並適應新情境的人工智慧代理,從而提高其決策過程。
-
第4層(L4): 擁有進階推理和問題解決能力的人工智慧代理,能夠處理複雜的、多步的任务。
-
第5層(L5): 完全自主的人工智慧代理,能夠在动态环境中独立操作,无需人类干预即可做出决策和采取行动。
大型語言模型的限制
訓練成本和資源限制
像GPT-3和PaLM這樣的大型語言模型(LLM)透過 leveraging 深度學習技巧和大量數據集,已經革新了自然語言處理(NLP)。
這些進步代價高昂。訓練LLMs需要大量的計算資源,經常涉及數千個GPU和大量的能源消耗。
根據OpenAI的首席執行官Sam Altman表示,GPT-4的訓練成本超過了1億美元。這與報導中該模型的規模和複雜性相吻合,估計其具有約1兆個參數。然而,其他來源則提供了不同的數字:
-
一份洩露的報告指出,考慮到計算能力和訓練時間,GPT-4的訓練成本約為6300萬美元。
-
截至2023年中期,一些估計表示,訓練一個類似於GPT-4的模型可能需要約2000萬美元,並耗時約55天,這反映了效率方面的進步。
训緓和維護大型语言模型的高昂成本限制了它們的廣泛採用和擴展性。
數據限制和偏見
大型语言模型的表現严重取決於訓練數據的質量和多元性。儘管在巨量數據上進行訓練,大型语言模型仍然可能展示數據中存在的偏見,導致歪曲或不適當的輸出。這些偏見可以以各種形式展現,包括性別、種族和文化偏見,這可能促進有成見和错误信息的流传。
此外,訓練數據的靜態性意味著大型语言模型可能不會紧跟最新信息,這限制了它們在动态环境中的效果。
专业化與複雜性
雖然大型语言模型在一般任務上表現出色,但它们往往在需要特定領域知識和高級複雜性的專業任務上遇到困難。
例如,醫學、法律和科學研究等領域的任務需要對专业化術語有深入理解以及细微推理能力,這可能不是大型语言模型天生所具备的。這個限制ecessitates將额外的專業知識層融入並微調大型语言模型,以使其在專業應用中有效。
輸入和感官限制
LLM 主要處理基於文字的輸入,這限制了他們以多模態方式與世界互動的能力。雖然他們可以生成和理解文字,但他們缺乏直接處理視覺、聽覺或感官輸入的能力。
這限制妨碍了它们在需要綜合感官整合的領域中的应用,如机器人學和自動系統。例如,LLM 無法在没有額外處理層的情況下解讀相机捕獲的視覺數據或麦克風收集的聽覺數據。
溝通與互動限制
LLM 目前的溝通能力主要基於文字,這限制了他們參與更加沉浸式和互動形式的溝通的能力。
例如,雖然LLM可以生成文字响应,但它们不能产生视频内容或全息图,这在虚拟现实和增强现实应用中变得越来越重要(在此阅读更多)。这一限制降低了LLM在需要丰富、多模态互动的环境中的效果。
如何通过 AI 代理克服限制
AI 代理是为了解决 LLM 面临的许多限制而有希望的一个解决方案。这些代理被设计为自主操作,感知它们的环境,做出决定,并执行行动以实现特定目标。通过将 AI 代理与 LLM 整合,可以增强它们的 capabilities 并解决它们固有的限制。
-
增強上下文和記憶:AI代理可以在多次互動中保持上下文,從而能夠提供更連貫和相關的回應。這種能力在需要長期記憶和連續性的應用中特別有用,例如客戶服務和個人助理。
-
多模態整合:AI代理可以整合來自各種來源的感官輸入,如攝像頭、麥克風和傳感器,使LLM能夠處理和回應視覺、聽覺和感知數據。這種整合對於機器人和自主系統的應用至關重要。
-
專業知識和專長: AI 代理人可以经过精细化调优,加入特定領域的知識,提升 LLM 執行專業任務的能力。這種方法容許創造出能夠處理醫學、法律和科學研究等领域複雜問題的專家系統。
-
互動與沉浸式溝通: AI 代理人可以通過生成影片內容、控制全息顯示和與虛擬和增強现实環境互動,促進更沉浸式形式的溝通。這種能力 expands the application of LLMs in fields that require rich, multimodal interactions.
大型語言模型的服务能力虽然在自然語言處理方面展現出顯著的能力,但它們並不是沒有局限性。訓練成本高昂、數據偏見、专业化困難、感官限制和沟通能力限制等問題,為它們的應用帶來了重大障礙。
然而,AI代理的整合提供了一個可行的途徑來克服這些限制。通過運用AI代理的優勢,可以提高語言模型的功能性、適應性和應用性,為更先进多功能的AI系統开辟道路。
第2章:人工智慧歷史與AI代理
人工智慧的源起
人工智慧(AI)的觀念遠遠超越了現代數位時代。創造類似於人類推理能力的機器這個想法可以追溯到古代的神話和哲學之争。但作為科學學科的人工智慧正式的創始是在20世紀中葉。
1956年達特茅斯會議,由約翰·麥卡錫(John McCarthy)、馬文·米斯基(Marvin Minsky)、內森尼尔·羅切斯特(Nathaniel Rochester)和克勞德·香農(Claude Shannon)組織,被廣泛認為是人工智慧作為一门研究领域出生的地方。這個開創性的活動集結了頂尖研究者來探索創造能模擬人類智能的機械的潛力。
早期的樂觀與人工智慧寒冬
人工智慧研究的早期年頭充滿了無顧忌的樂觀。研究人員在開發能夠解決數學問題、玩遊戲,甚至進行初步的自然語言處理的程式的領域取得了重大進步。
但這種初始的熱情被創造真正智能機械的複雜性遠比最初预期的要複雜的現實所平市。
1970年代和1980年代經歷了一段對AI研究資金和興趣減少的日子,通常被稱為 “人工智慧寒冬“。這種衰退主要是由於AI系統未能達到早期先鋒设定的高昂期望所引起。
從基於規則的系統到機器學習
专家系统时代
1980年代,AI的興趣主要受到專家系統發展推動的復興。這些基於規則的程式被設計來模擬特定領域的人类專家 decision-making 過程。
Expert Systems 在各種領域中找到了應用,包括醫學、金融和工程。但它們受到無法從經驗中學習或適應其程序規則之外的新情況的的限制。
機器學習的興起
基於規則的系統的限制為機器學習的思維方式奠定了基礎。這種方法在1990年代和2000年代變得突出,著重於開發能夠從數據中學習並根據數據進行預測或決策的算法。
機器學習技術,如神經網絡和支持向量機,在手勢識別和數據分類等任務中展現出驚人的成效。大数据的到來和計算能力的增強進一步加快了機器學習算法的发展和應用。
自立AI代理的出現
從窄AI到通用AI
隨著AI技術的繼續發展,研究人員開始探索創造更多功能和自立系統的可能性。這意味著從為特定任務設計的窄AI转向追求人工通用智能(AGI)的轉變。
AGI旨在開發能夠執行人類所能執行的任何智能任務的系統。雖然真正的AGI仍然是一個遥遠的目標,但在創造更加靈活和適應性強的AI系統方面已經取得了重大進步。
深度學習和神經網絡的角色
深度學習的出現,這是一種基於人工神經網絡的機器學習子集中的學習方法,對AI領域的進步起了重要作用。
深度學習算法,灵感來自於人腦的結構和功能,在像圖像和語音識別、自然語言處理和遊戲玩法等領域已經顯示出出色的能力。這些進步為更複雜的自主AI代理的發展奠定了基礎。
AI代理的特性和類型
AI代理是能夠感知其環境、做出決定並執行行為以實現特定目標的自律系統。它們具有特點,如自律、感知、反應性、推理、決策、學習、溝通和目標導向。
有幾種類型的AI代理,每個都有獨特的功能:
-
簡單反射代理:基於預先定義的規則對特定的刺激做出反應。
-
基於模型的反射代理人:維護環境的內部模型以進行決策。
-
目標基礎代理人:執行行為以實現特定的目標。
-
util-based agent:考慮潛在的結果並選擇最大化预期util的行為。
-
學習代理人:通過機器學習技術隨時間提高決策。
挑戰和伦理考慮
隨著AI系統變得越來越先進和自動化,它們帶來了关键的考慮,以確保其使用保持在社會接受的範圍內。
特別是大型語言模型(LLM)作為生產力的超级充電器。但這 raises a crucial question: 這些系統將supercharge什麼—好意圖或壞意圖?當使用AI的動機是惡意的時,這些系統使用各種NLP技術或其他可用的工具來检测這種錯誤使用變得至关重要的。
LLM工程师可以使用各種工具和方法來解決這些挑戰:
-
情感分析:通過運用情感分析,LLM可以評估文本的情感基调以檢測具有傷害性或攻击性的語言,幫助在通訊平台上識別潛在的錯誤使用。
-
內容過濾:像關鍵詞過濾和模式匹配這樣的工具可以用來防止生成或傳播有害內容,如仇恨言論、誤導信息或露骨內容。
-
偏見檢測工具:實施偏見檢測框架,如IBM的AI公正360或Google的公正指標,可以幫助識別和減輕語言模型的偏見,確保AI系統公正且公平地運行。
-
解釋技術
: 透過使用像LIME(本地解釋性模型中立解釋)或SHAP(Shapley加成解釋)這樣解釋性工具,工程師可以理解和解釋大型語言模型(LLM)的決策過程,這使得更容易發現和解決非意料之中的行為。
-
抗測驗: 透過模擬惡意攻擊或有害輸入,工程師可以使用如TextAttack或抗御性強度工具箱之類的工具對LLM進行壓力測試,發現可能被用於惡意目的的漏洞。
-
倫理AI指導原則與框架: 採取如IEEE或AI夥伴關係提供的倫理AI開發指導原則,可以指導创建地把社會福祉放在首位的負責任AI系統。
除了這些工具外,这就是为什么我们需要专门的红队对AI进行测试——专门的红队推 LLMs 到极限以检测其防线的漏洞。红队模拟对抗性场景并揭示可能被忽视的弱点。
但重要的是要认识到,产品背后的人对它的影响最大。我们今天面临的许多攻击和挑战在LLM开发之前就已经存在,这突显了确保AI道德和负责任使用的人的因素仍然至关重要。
将这些工具和技术整合到开发管道中,同时拥有警惕的红队,对于确保LLM被用来增强积极成果同时检测和预防其滥用至关重要。
第三章:AI代理最闪耀的地方
AI代理的独特优势
AI代理之所以突出,是因为他们能够自主地感知环境、做出决策并执行行动来实现特定目标。这种自主性,结合先进的机器学习能力,使AI代理能够执行对于人类来说过于复杂或过于重复的任务。
以下是讓AI代理人展現光采的關鍵优势:
-
自主性与效率:AI代理人可以獨立運營,無需不斷的人工干預。這種自主性讓它们能夠24/7處理任務,顯著提高效率和生產力。例如,AI驅動的聊天机器人可以處理多达80%的例行客戶諮詢,減少營運成本並提高回應時間。
-
進階決策能力:AI代理人可以分析大量的數據來做出明智的決策。這種能力在金融等领域尤其有價值,其中AI交易机器人可以大幅提高交易效率。
-
學習與適應能力:AI 代理人能從經驗中學習並適應新情況。這種持續的進步使他們能夠隨時間提高表現。例如,AI 健康助手能幫助減少診斷錯誤,提高醫療結果。
-
个性化:AI 代理人能通過分析用戶行為和偏好提供个性化體驗。亞馬遜的推薦引擎,該引擎推動了其35%的銷售,是AI代理人如何提高用戶體驗和增加收入的一個典型例子。
为何 AI 代理人是解決方案
AI agents 提供了許多傳統软件和由人員操作的系統所面臨挑戰的解決方案。以下是它們成為首选選擇的原因:
-
可擴展性:AI 代理人可以在不成比例地增加成本的情況下擴展操作。這種可擴展性對於希望增長而不 significantly 增加其員工或操作開支的企業來說是至关重要的。
-
一致性和可靠性:與人相比,AI 代理人不會受到疲勞或不一致的影響。他們可以以高精度和高可靠性執行重複任務,確保一致的性能。
-
數據驅動的洞見:AI 代理人可以處理和分析大量數據集,以發現可能被人類錯過的模式和見解。這種能力對於財務、醫療保健和市場決策等領域的決策來說是无價的。
-
節省成本:通過自動化例行任務,AI AGENT 能夠減少对人力的需求,從而達到顯著節省成本。例如,AI 动了欺騙侦測系統可以通過減少欺騙活動,每年節省数十億美元。
AI AGENT 表現良好的必要條件
为确保 AI AGENT 成功部署和表現,必須滿足某些條件:
-
明確目標和使用案例:為 AI AGENT 有效部署設定具體目標和使用案例至關重要。這種清晰性有助於設定期待值和衡量成功。例如,設定將客戶服務反饋時間減少50%的目標,可以指導 AI 聊天機器人的部署。
-
品質數據:AI代理倚賴高品質的數據進行訓練和運營。確保數據的準確性、相關性及更新性對於代理能夠作出明智的決策並有效地執行至关重要的。
-
與既有系統的整合:無縫整合既有系統和工作流程對於AI代理能最 optimizeally 地发挥作用是必要的。這種整合確保AI代理可以存取必要的數據並與其他系統互動來執行它们的任務。
-
持續監控和優化:定期監控和優化AI代理對於維護其性能是 crucial 的。這涉及追蹤关键性能指標(KPIs)並根據反饋和性能數據做出必要的調整。
-
伦理考慮與偏見減緩:解決伦理考慮並減輕AI代理的偏見是確保公正與包容的關鍵。实施檢測和預防偏見的措施有助於建立信任並確保负责任的部署。
部署AI代理的最佳實踐
部署AI代理時,遵循最佳實踐可以確保其成功和有效性:
-
定義目標和用例:清晰地标识部署AI代理的目標和用例。這有助於設定期望並衡量成功。
-
選擇合適的 AI 平台
: 選擇與您的目標、應用案例和既有基礎設施對齊的 AI 平台。考慮像集成能力、可擴展性和成本等因子。
-
建立全面的知識庫: 建立結構良好且準確的知識庫,以讓 AI 代理能提供相關且可靠的回應。
-
確保无缝整合: 將 AI 代理與既有系統如 CRM 和客服中心技術整合,以提供统一的客戶體驗。
-
訓練和最佳化 AI 代理: 使用互動數據不斷訓練和最佳化 AI 代理。監控性能,識別改進領域,並 correspondingly更新模型。
-
实施適當的升級程序:建立 Transfer complex or emotional calls to human agents 的協議,確保平滑的移交和有效的解決方案。
-
監控和分析性能:追蹤重要的性能指標(KPIs),如来电解决率、平均处理时间和客户满意度评分。使用分析工具进行数据驱动的洞察和决策。
-
確保数据隐私和安全性:強大的安全措施是關鍵,例如讓數據匿名、確保人工監督、設定數據留存政策,並實施強烈的加密措施來保護客戶數據和維護隱私。
AI 代理 + 大型语言模型:智能软件新时代
想象一下,一款不僅理解你的請求,還能執行它們的軟件。這是將AI代理與大型語言模型(LLM)結合的承諾。這對強大的組合正在創造出一種比以前更直觀、更有能力且更具影響力的應用程序新種類。
AI代理:不僅僅是執行簡單任務
雖然常與數位助手相比,但AI代理遠遠超過了 glorified script followers 的範圍。它們涵蓋了廣泛的复杂技術,并在一個使能動態決策和採取行動的架構上運行。
-
架構:典型的AI代理由幾個重要組件組成:
-
感測器:這些允許代理感知其環境,從各種來源如感測器、API或使用者輸入收集數據。
-
信念狀態:這代表代理對世界的理解,基於收集到的數據。它會隨著新信息的出現而不斷更新。
-
推理引擎:這是代理決策過程的core。它使用算法,通常基於強化學習或計劃技術,根據其當前信念和目標來確定最佳行動方案。
-
執行器:這些是代理與世界互動的工具。它們可以從發送API調用控制实体经济机器人。
-
-
挑戰:傳統 AI 代理,雖然在處理明確定義的任務方面熟練,但往往面臨以下困難:
-
自然語言理解:解釋細微的人類語言、處理模棱兩可的情況並從上下文中提取意義仍然是重大挑戰。
-
常識推理:目前的 AI 代理往往缺乏人們視為理所當然的常識知識和推理能力。
-
泛化:訓練代理在未見過的任務上表現良好或適應新環境仍然是研究的重點領域。
-
LLM:解鎖語言理解和生成的能力
LLM以其十億個参数內嵌的大量知識,為我們帶來前所未有的語言能力:
-
變壓器結構:大多數現代LLM的基礎是變壓器結構,这是一种 neural network 設計,擅长處理如文字的序列數據。這讓LLM能夠捕捉語言中的長距依賴,使它們能夠理解上下文並生成连贯且與上下文相關的文本。
-
能力:LLM在各種語言基礎任務上表現出色:
-
文字生成:從寫創意小說到生成多種程式設計語言的代碼,LLM展現出驚人的流暢和創意。
-
問題回答:它們可以提供簡潔準確的答案,即使信息散布在長篇文件中。
-
摘要在:LLM可以將大量文字浓缩成簡潔的摘要在,抽取關鍵信息並丢弃不相關詳細信息。
-
-
限制:儘管它們的表現出色,LLM 仍有局限:
-
缺乏真實世界的基础:LLM 主要在文字領域操作,並缺乏直接與实体经济互動的能力。
-
潛在偏见和虚构:由於是在大量未經過濾的數據上訓練,LLM 可能會繼承數據中的偏見,且有時生成的信息事实不正確或無意義。
-
語境與行為之間的橋樑:結合AI代理和LLM
AI代理與LLM的結合解決了彼此的限制,創造了既智慧又能够的作者系統:
-
LLM作為解讀者和計劃者:LLM可將自然語言指示翻譯成AI代理能理解的格式,從而使人与计算机的互动更为直观。它們还可以利用其知識协助代理计划复杂任务,通过将它们分解成更小、更易于管理的步骤。
-
AI 代理作為執行者和學習者: AI 代理為 LLM 提供了與世界互動、收集信息和對其行為作出反饋的能力。這種現實基礎可以帮助 LLM 從經驗中學習並隨著時間提高其表現。
這種強大的协同作用正在推動新一代應用程序的發展,這些應用程序比以前任何时候都更加直觀、適應性強且能夠胜任。隨著 AI 代理和 LLM 技術的持續進步,我們可以期待看到更多創新和有影響的應用程序出現,重塑軟體開發和人機互動的格局。
現實案例:改造行業
這種強大的組合已經在各種行業中引起了震動:
-
客戶服務:以情境意識解決問題
- 例子:想像一位客戶向在線零售商反映一笔訂單的配送延誤。一個由LLM驅動的AI代理可以理解客戶的挫折感,訪問他們的訂單歷史,實時追踪包裹,並積極提供解決方案,例如加快配送或在下一次購買時提供折扣。
-
內容創作者:大量創建高品質內容
- 例子:一個市場團隊可以利用AI代理+LLM系統來生成目標明確的社交媒體帖子、撰寫產品描述,甚至是創建影片script。LLM確保內容具有吸引力和 Informative,而AI代理則處理發布和 分發過程。
-
軟件開發:加速編程和除錯
- 例子:開發者可以通過自然語言描述他們想要建造的軟件功能。LLM可以然後生成的代碼片段,識別潛在錯誤,並建議改進,顯著加快開發過程。
-
醫療:個人化治療和提高病人護理
- 例子:一個拥有病人歷史病情數據並搭載LLM的AI代理可以回答他們的健康相關問題,提供個人化的藥物提醒,甚至根據症狀提供初步診斷。
-
法律:簡化法律研究和文件起草
- 示例:律師需要草擬一份具有特定條款和法律先例的合同。由LLM提供動力的AI代理可以分析律師的指示,搜索廣泛的法律數據庫,識別相關條款和先例,甚至草擬合同的某些部分,大大節省所需的时间和精力。
-
視頻創作:輕鬆生成引人入勝的視頻
- 示例:一個市場營銷團隊想要創作一段解釋產品功能的短視頻。他們可以提供AI代理+LLM系統一份腳本大綱和視覺風格偏好。LLM然後生成一份詳細腳本,建議合適的音樂和視覺元素,甚至編輯視頻,自動化視頻創作過程的許多部分。
-
建築:使用AI emotion Insights設計建築物
- 示例:一位建築師正在設計一幢新的辦公室建築。他們可以利用AI代理商+ LLM系統來輸入他們的设计目標,例如最大化自然光源和優化空間利用。LLM可以然後分析這些目標,產生不同的設計選項,甚至模擬建築在不同環境條件下的表現。
-
建设中:改善工地安全與效率
- 示例:配備相機和感應器的AI代理可以監控建築工地上的安全风险。如果工人沒有穿戴正確的安全装备或設備被留在危險的位置,LLM可以分析情況,警告工地監督員,甚至在必要時自動中止運作。
未來已來:軟體開發的新紀元
AI代理和LLM的会说合标志着軟體開發的一大跃進。隨著這些技術的持續發展,我們可以期待看到更多创新的應用出現,转变行業,簡化 workflow,並為人機互動創造全新的可能性。
AI代理在需要處理大量數據、自動化重覆任務、進行複雜決策和提供个性化體驗的領域中表現出色。通過滿足必要條件並遵循最佳實踐,組織可以充分利用AI代理的潛力來推動創新、效率和增長。
第四章:智能系統的哲學基礎
智能系統的發展,特別是人工智慧(AI)領域,需要對哲學原則有深入的了解。這一章深入探讨構成AI設計、開發和使用核心的思想 philosophical ideas。它強調了技术人员進程與道德價值對齐的重要性。
智能系統的哲學基礎不僅是一個理論上的練習——它是一個至关重要的框架,確保AI技術造福於人類。通過促進公正性、包容性,並提高生活質量,這些原則幫助指導AI服务于我们的最佳利益。
AI發展中的道德考慮
隨著AI系統日益融入人類生活的各个方面,從醫療保健和教育到金融和治理,我們需要嚴格檢查並实施指導其設計和部署的道德原則。
基本的道德問題圍繞著如何使AI体现和维护人類價值和道德原則。這個問題是AI將如何塑造全球社會未來的核心。
這種道德討論的的核心是仁慈的原則,这是道德哲學的基石,规定行為應該旨在做好事,增強個人和社會的福祉(Floridi & Cowls, 2019)。
在人工智能的領域中, beneficence translates into designing systems that actively contribute to human flourishing—systems that improve healthcare outcomes, augment educational opportunities, and facilitate equitable economic growth.
但人工智能中 beneficence 的應用遠非直觀。它需要一個纤细的方法,謹慎地权衡人工智能的潛在益處與可能的風險和傷害。
應用仁慈原則於人工智能開發的關鍵挑戰之一是需要在創新與安全之間取得微妙的平衡。
人工智慧有潜力革命化如醫學等領域,預測算法可以比人類醫生更早且更準確地診斷疾病。但沒有嚴格的伦理監督,這些相同技術可能會加剧既有不平等。
例如,如果它們主要在富裕地區部署,而未受服務的社區繼續缺乏基本的醫療保健 accessibility。
由於这一点,伦理人工智能開發不僅需要關注益處的最大化,也需要積極的風險减灾方法。這涉及實施堅實的保護措施以防止AI的滥用以確保這些技術不會意外地導致伤害。
人工智能的伦理框架也必須本质上是包容性的,確保AI的益處均等地分佈於所有社會團體,包括那些 traditionally marginalized。這需要對正義和公平的承諾,確保AI不僅是重申现状,而是積極地工作情况系統性不平等。
例如,由AI推动的工作自動化具有提高生產力和經濟增長的潜力。但它也可能導致重大的職位 displacement, disproportionately 影響到低收入工人。
所以如你所見,一個道徳上站的住的AI框架必須包括道徳上平等的好處分享策略和支持系統,以應對AI進步對那些不良影響。
AI的倫理發展需要持續地和不同的利害關係人互動,包括倫理学家、技術專家、政策制定者和最受這些技術影響的社區。這種跨學科合作確保了AI系統並不是在真空環境下開發的,而是由廣泛的觀點和經驗塑造而成。
正是通過這種集體努力,我們才能創建不僅反映而且支持定義我們人道主义的價值觀——同情心、公平、尊重自主權和對公共利益的承諾。
AI開發中的倫理考慮不僅是指導原則,也是決定AI是否成為世界上一股善良力量的基本要素。通過將AI建立在善良、正義和包容的原則上,並通過维持對創新和風險平衡的警覺方法,我們可以確保AI開發不僅推動技術進步,也提升社會所有成員的生活質量。
隨著我們繼續探索AI的潛能,這倫理考慮必須繼續是我们努力的前沿,引導我們走向一個AI真正有益於人類的未來。
人性为本的AI設計 imperative
人性为本的AI設計不僅僅是技術上的考慮。它植根於深層的哲學原則,這些原則將人類尊嚴、自主性和行動能力放在首位。
這種AI發展方法根本地扎根於康德的倫理框架,康德 Asserted that ( humans ) 必須被視為自身目的,而不只是作為達到其他目標的工具 (Kant, 1785)。
這種原則對AI設計的影響深遠,要求AI系統必須以堅定地集中在服務人類興趣、保護人類行動能力及尊重個體自主性。
以人性为本的原則的技術實施
通過AI增強人類自主性:在AI系統中,自主性的概念尤為重要,尤其是在確保這些技術賦予用戶力量,而非控制或過度影響他們。
從技術術語來看,這涉及設計AI系統,這些系統通過提供用戶所需的工具和信息來優先考慮用戶的自主性,使他们能夠作出明智的決定。這要求AI模型必須是上下文意識的,意味著它們必須理解決策所涉及的具體背景,並据此調整其建議。
從系統設計的視角來看,這涉及將上下文智能整合到AI模型中,使這些系統能夠根據用戶的環境、偏好和需求 dynamically adapt。
例如,在醫療領域,一個辅助醫生進行診斷的 AI 系統必須考慮病人的獨特的醫療歷史、目前的症狀,甚至心理狀態,以提供支持醫生專業知識的建議,而不是取代它。
這種情境適應確保了 AI 继续保持為一個支持性的工具,增強,而不是減少,人的自主權。
確保透明的決策過程:AI 系統的透明度是確保用戶可以信任和理解這些技術所做的決策的基本要求。從技術上來說,這意味著需要可解釋 AI(XAI),這涉及開發能夠清楚地表達其決策背后的邏輯的算法。
這在金融、醫療和刑事司法等領域尤其重要,在这些領域中,不清透明的決策過程可能會導致 mistrust 和伦理問題。
可解释性可以通过几种技术方法实现。一种常见的方法是事後解釋性,即在決策做出之后,AI 模型生成的解釋。這可能涉及將決策分解为其组成部分因素,並顯示每個因素如何對最終結果做出貢獻。
另一种方法是 inherently interpretable models,這是一種設計方式,使其決定 transparency by default。例如,像決策樹和線性模型這樣的模型是 natural interpretable,因為它們的決策過程很容易 follow and understand。
在實施解釋性 AI 的挑戰在於 balance transparency with performance。經常地,更複雜的模型(如深層神經網絡) interpretable but more accurate。因此,以人为中心的 AI 設計必須考慮模型解釋性及其預測能力之間的 trade-off,確保用戶可以信任並理解 AI 決定,而不牺牲準確性。
Enabling Meaningful Human Oversight: Meaningful human oversight is critical in ensuring that AI systems operate within ethical and operational boundaries. This oversight involves designing AI systems with fail-safes and override mechanisms that allow human operators to intervene when necessary.
人 oversee 的技術實現可以 several ways.
One approach is to incorporate human-in-the-loop systems, where AI decision-making processes are continuously monitored and evaluated by human operators. These systems are designed to allow human intervention at critical junctures, ensuring that AI does not act autonomously in situations where ethical judgments are required.
舉例來說,在自制武器系統的情況下,人的監督是防止AI在無人類輸入的情況下作出生死決策的關鍵。這可能涉及設定嚴格的操作邊界,AI無法越過需人類授權,從而將道德保壘嵌入系統中。
另一個技術考慮因素是開發审计追蹤,這是AI系統所作的所有決策和行為的記錄。這些追蹤提供一個透明的歷史,可以由人員操作員复查,以确保符合道德標準。
审计追蹤在金融和法律等領域尤其重要,在这些領域中,決策必須被記錄並有根據,以維持公眾信任和滿足法規要求。
自治與控制的平衡:以人为中心的AI的關鍵技術挑戰之一是找到自治和控制的正確平衡。雖然AI系統在许多情境中都被設計為能夠自主運營,但這種 autonomy 不應 undermine 人的控制或監督。
這種平衡可以通过實施自治等級来实现,這些等級规定了AI在做出決策時具有的多大獨立性。
例如,在半自主系統如自动驾驶汽車中,自治等級從基本的駕駛輔助(在此情況下,人類駕駛員保持在完全控制之中)到完全自動化(在此情況下,AI負責所有駕駛任務)。
這些系統的設計必須確保,在任何給定的自主層次上,人類操作員都 retains 能夠介入和覆寫 AI 的大小。這需要複雜的控制接口和決策支持系統,使人類在需要時能夠快速有效地恢復控制。
另外, Establishing ethical AI frameworks is essential for guiding the autonomous actions of AI systems. 這些框架是一套規則和指導原則,嵌入在 AI 之中,指示它應該在伦理上将如何複雜的情況下行為。
例如,在醫療保健領域,一個道德的 AI 框架可能包括有關病患同意書、隱私和基於醫療需求而非財務考慮的治療優先順序等規則。
通過將這些道德原則直接嵌入 AI 的決策過程中,開發者可以確保系統的自主性是以符合人類價值的方式行使的。
將以人为本的原則整合到 AI 設計中不僅是一個哲學理想,也是一個技術必要。通過提高人類自主性、確保透明度、實現有意義的監督,以及謹慎地將自主性与控制在之間保持平衡,可以開發出真正為人類服务的 AI 系統。
這些技術考慮是創建不僅增強人類能力,也尊重和維護我們社會的基本價值的 AI 的關鍵。
隨著 AI 繼續演變,對以人为本設計的承諾對於確保這些強大技術道德地和安全地使用將至關重要。
如何確保 AI 造福人類:提升生活質量
當你參與 AI 系統的開發時, essential to ground your efforts in the ethical framework of utilitarianism — a philosophy that emphasizes the enhancement of overall happiness and well-being.
在這個環境下,AI 擁有解決關鍵社會挑戰的潜力,特別是 在醫療保健、教育和環境可持續性等領域。
目標是創造能顯著提升所有人生活質量 的技術。但這種追求帶來了複雜性。utilitarianism offers a compelling reason to deploy AI widely, but it also brings to the fore important ethical questions about who benefits and who might be left behind, especially among vulnerable populations.
為了處理這些挑戰,我们需要 sophisticated, technically informed approach — one that balances the broad pursuit of societal good with the need for justice and fairness.
當將 utilitarian principles 應用於 AI 时,你的關注重点應該是 在特定領域優化結果。例如在醫療保健領域,AI-driven diagnostic tools have the potential to vastly improve patient outcomes by enabling earlier and more accurate diagnoses. These systems can analyze extensive datasets to detect patterns that might elude human practitioners, thus expanding access to quality care, particularly in under-resourced settings.
然而,部署這些技術需要謹慎考慮,以避免加深既有的不平等。訓練人工智能模型的數據在各地區之間有著顯著差異,影響了這些系統的準確性和可靠度。
這種差異凸顯了建立堅實數據治理框架的重要性,以確保你的人工智能醫療解決方案既有代表性又公平。
在教育領域,人工智能實現个性化學習的潛力是Promising。人工智能系統可以調整教育內容以符合個別學生的特定需求,從而提升學習成果。通過分析學生性能和行為的數據,人工智能可以確定學生可能在哪些方面遇到困難並提供針對性支持。
但当你朝着這些益處工作时,認識風險至關重要—如加深偏見或边缘化不符合典型學習模式的学生。
緩解這些風險需要將公平機制整合到人工智慧模型的建设中,確保它們不會意外地偏袒某些群體。而保持教育工作者的角色是关键。他們的判斷和經驗在使人工智能工具真正有效和支持性方面不可或缺。
在環境可持續性方面,人工智能的潛力是顯著的。人工智能系統可以優化資源使用,監控環境變化,並以前所未有的準確度預測氣候變化的影響。
例如,的人工智能可以分析大量的環境數據來預測天氣模式、優化能源消費,以及最小化浪費 — 這些行為有助於當前和未來世代的福祉。
但這種技術進步伴隨著它自己的一套挑戰,特別是關於人工智能系統本身的環境影響。
運營大規模的人工智能系統所需的能耗可能會抵消他們旨在實現的環境益處。因此,開發能源效率高的人工智能系統對於確保它們對可持續性的正面影響不受損害至關重要。
當您開發以功利目標為导向的人工智能系統時,同時考慮對社會正義的影響也很重要。功利主義著重於最大化整體幸福,但並未本質上解決益處和傷害在不同的社會群體之間的分配問題。
這 raises the potential for AI systems to disproportionately benefit those who are already privileged, while marginalized groups may see little to no improvement in their circumstances.
為了對抗這點,您的人工智能開發過程應該 incorporation equity-focused principles, ensuring that the benefits are distributed fairly and that any potential harms are addressed. 这可能涉及設計旨在減少偏見的算法,並讓 diversity range of perspectives 者在開發過程中參與。
在開發旨在提升生活品質的 AI 系統時,必須要在最大化福祉的功利目標與正義和平衡需求之間取得平衡。這需要一種细微、基於技術的方法的考慮,這考慮到 AI 部署的更廣泛影響。
通過謹慎設計既有效又公平的 AI 系統,您可以為一個未來做出貢獻,在這個未來中,技術進步真正服務於社會的多元需求。
实施對潛在風險的保護
開發 AI 技術時,您必須認識到潛在風險的本質,並積極建立強大的保護措施以減輕這些風險。這種責任 deeply rooted in deontological ethics(道 德 倫 理)。這 種 倫 理 emanates from the moral duty to adhere to established rules and ethical standards, ensuring that the technology you create aligns with fundamental moral principles(坚守既定的規則和倫理標準,確保您創造的技術與基本道德原則一致)。
實施嚴格的安 全協定不僅是一種預防措施,也是一道道德責任。這些協定應包括全面的偏見測試、算法過程的透明度以及明確的责任機制。
這種保護措施是防止 AI 系統造成无意間損害的關鍵,無論是通過偏見的決策過程、過程不透明或缺乏監督。
在實踐中,實施這些保護措施需要對 AI 的技術和道德层面都有深入的理解。
偏見測試,例如,不只是識別和糾正數據和算法中的偏見,還要理解這些偏見在更廣泛社會層面的影響。
您必須確保人工智能模型在多樣化、具有代表性的數據集上進行訓練,並定期評估以檢測和糾正可能隨時間出現的任何偏見。
另一方面,透明度要求人工智能系統設計得讓其決策過程能夠被用戶和利益相關者輕鬆理解並審查。這涉及開發可解釋的人工智能模型,提供清晰、可解釋的輸出,讓用戶了解決策是如何做出的,並確保這些決策是合理且公平的。
此外,責任追究機制對於保持信任並確保人工智能系統負責任地使用至關重要。這些機制應包括對AI決策結果負責的清晰指導原則,以及處理和糾正可能發生的損害的程序。
您必須建立一個框架,在人工智能開發的每個階段都融入道德考量,從初始設計到部署甚至更久之後。這不僅僅是遵循道德準則,還要持續監控和調整與現實世界互動的人工智能系統。
通過將這些保護措施嵌入人工智能開發的基礎之中,您可以幫助確保技術進步為了更大的善,而不導致意外的負面後果。
人在AI系統中的監督是確保道德AI部署的重要組件。責任原則支撐了持續人類參與AI運作的必要性,尤其是在醫療和刑事司法等高風險環境中。
反饋迴路,即使用人類輸入來精煉和改進AI系統,對於保持責任性和適應性至關重要(Raji等,2020年)。這些迴路使得能夠糾正錯誤並將新的道德考量整合進來,隨著社會價值的演變。
通過將人類監督嵌入AI系統中,開發者可以創造出不僅有效,而且符合道德規範和人類期望的技術。
編碼道德:將哲學原則轉譯到AI系統中
將哲學原則轉譯到AI系統中是一項複雜但必要的任務。這個過程涉及將道德考量嵌入驅動AI算法的代碼之中。
如公平、正義和自主等概念必須在AI系統中編碼,以確保它們的運作反映出社會價值。這需要一個跨學科的方法,讓倫理學家、工程師和社會科學家合作定義並實施編碼過程中的道德準則。
目標是創造出不僅技術上熟練,而且在道德上也健全的AI系統,能夠做出尊重人類尊嚴和促進社會公益的決策(Mittelstadt等,2016年)。
在AI的開發和部署中促進包容性和公平的訪問
包容性和公平访问是AI道德發展的基础。羅爾斯的 “正義作為公平” 概念為確保AI系統是以造福社會所有成員的方式設計和部署提供哲學基础上,特別是那些最脆弱成員(羅爾斯,1971)。
這包括積極努力在開發過程中纳入多樣化的視角,特别是来自代表性不足群體和全球南部。
通過纳入這些多樣化的觀點,AI開發者可以創造出更具包容性和更能滿足更廣泛用戶需求的系統。另外,確保AI技術的公平訪問對防止加剧既有社會不平等至關重要。
解決算法偏见和公平性
算法偏見是AI開發中的重要道德問題,因為有偏见的算法可能會 perpetuate 既有社會不平等,甚至加剧。解決此問題需要對程序正義的承諾,確保AI系統是通過公正的過程開發,考慮所有利害關係人的影響(尼森鮑姆,2001)。
這包括識別和減輕訓練數據中的偏見,開發透明和可解釋的算法,並在AI生命週期中實施公平性檢查。
通過解決算法偏見,開發者可以創造出有助于創造一個更加公正和包容的社會的AI系統,而不是加剧既有的不平等等。
在AI開發中纳入多樣化視角
將多樣化的觀點整合入AI開發中對於創造包容且公正的系統至關重要。來自代表性不足群體的声援確保了AI技術不僅僅反映社会上一个小範圍群體的價值觀和優先順序。
這種方法與深思慎議的民主哲學原則相吻合,該原則強調包容和參與性決策過程的重要性(Habermas, 1996)。
通過促進AI開發中的多樣化參與,我們可以確保這些技術是設計來服務全人类的利益,而非僅僅是有 privilegled 幾個人的利益。
弥合AI分歧的策略
AI分歧,特點是對AI技術和其好處的不平等接入,對全球公平构成了顯著挑戰。弥合這一分歧需要承諾于分配正義,確保AI的好處廣泛地分佈在不同社會經濟群體和地區之間(Sen, 2009)。
我們可以通過促進AI教育和資源在未曾被服务等社區的計劃,以及支持AI驅動經濟得益平等分佈的策略來實現這一目標。通過解決AI分歧,我們可以確保AI以一種包容和公正的方式為全球發展做出貢獻。
在創新追求與道德約束之間保持平衡
在追求創新與道德約束之間保持平衡對於負責任的AI進步至關重要。在前瞻性原則的背景下,建議在面對不確定性時採取謹慎態度,这在AI開發中尤為相關(Sandin, 1999)。
創新雖然推動進步,但必須经过道德考量以防止潛在的危害。這需要仔細評估新的人工智能技術的風險和裨益,以及實施管制框架來確保維護道德標準。
通過在創新與道德約束之間取得平衡,我們可以促進人工智能技術的發展,這不僅是前沿的,也符合社會福祉的更廣泛目標。
正如你所見,智能系統的哲學基礎為確保人工智能技術以道 德、包容和有益於全人类的方式開發和部署提供了一個關鍵框架。
將人工智能開發植根於這些哲學原則,我們可以創造出不僅促進技術能力提升,也提升生活質量、促進正義並確保人工智能的好處平等地惠及社會各阶层的人工智能系統。
第五章:AI代理人作為LLM增強器
AI代理人与大型語言模型(LLM)的融合代表了人工智能的根本轉變,解決了限制LLM廣泛應用的重要限制。
這種整合使機器能夠超越傳統角色,從被动的文字生成器進步到能夠進行动态推理和決策的自主系統。
隨著人工智能系統逐漸推動各個領域的關鍵過程,了解AI代理人是如何填補LLM功能缺口對於實現其全部潛力至關重要。
覆蓋LLM功能上的缺口
虽然在功能上強大,LLM(大規模語言模型)的天生局限在於它們所接受的訓練數據以及它們架构的靜態性。這些模型在固定的參數集中操作,通常這些參數集是由它們在訓練階段所用到的文本 corpora 所定義。
這意味著LLM無法自動尋找新信息或是在訓練後更新它們的知识庫。因此,LLM經常過時,且缺乏提供需要實時數據或洞察力、超出它們初始訓練數據的相關回應的能力。
AI代理通過动态整合外部数据源,弥补這些缺口,這可以延長LLM的功能范围。
例如,一個直到2022年為止以金融數據為基礎訓練的LLM可能會提供準確的歷史分析,但它可能會難以生成更新的市場預測。一個AI代理可以通過從金融市場引入實時數據來增強這個LLM,並將這些輸入應用於生成更相關和當前的分析。
這種动态整合確保了产出不僅在歷史上準確,而且在當前環境下也適合。
提升決策自主性
LLM的另一個顯著局限是它们缺乏自動決策能力。LLM擅長生成語言基礎的輸出,但在需要複雜決策的任務上表現不佳,特別是當環境存在不確定性和變化時。
這種短處主要歸咎於模型的依賴於既有的數據以及部署後無法從新經驗中適配推理或學習的機制。
人工智能代理解決這問題,通過提供自主決策所需的基礎設施。它們可以將長遠生成器(LLM)的靜態輸出通過Advanced推理框架如基于规则的系統、算法或強制學習模型進行處理。
例如,在醫療環境中,LLM可能會根據病人的症狀和醫療歷史生成的潛在診斷清單。但没有人工智能代理,LLM無法对这些选项进行权衡或推荐行动方案。
人工智能代理可以介入,对这些诊断根据当前的医学文献、病人数据和上下文因素进行评估,最终做出更明智的决定并建议可行的下一步行动。这种协同作用将LLM的输出生从简单的建议转变为可执行的、上下文相关的决策。
解决完整性和一致性问题
在复杂推理任务中,完整性和一致性是确保LLM输出的可靠性的关键因素。由于它们是参数化的,LLM经常生成的响应要么是不完整的,要么是缺乏逻辑连贯性,尤其是在处理多步骤过程或需要跨多个领域全面理解的时候。
这些问题源于LLM运作的孤立环境,它们无法跨引用或根据外部标准或额外信息验证其输出。
AI代理在减轻這些問題方面扮演著关键角色,通過引入迭代反饋機制和驗證層。
例如,在法律領域,一個LLM可能會根據其訓練數據起草一份法律簡報的初步版本。但這個草稿可能忽視某些先例,或者未能有逻辑地結構化论点。
一個AI代理可以查看這個草稿,確保它滿足所需的完整性標準,通過與外部法律數據庫交叉參考,檢查逻辑一致性,並在必要時索取額外信息或澄清。
這種迭代過程使 Production of a more robust and reliable document that meets the stringent requirements of legal practice.
通過集成克服孤立
LLM的最重要的局限之一是其與其他系統和知識來源的固有孤立。
按照設計,LLM是封閉系統,不會與外部環境或數據庫原生互動。這種孤立大幅限制了它們適應新信息或實時操作的能力,使它們在需要動態互動或實時決策的應用中效果不佳。
AI代理通過作為integrative platforms來克服這種孤立,將LLM與更廣泛的數據來源和計算工具生態系統連接起來。通過API和其他集成框架,AI代理可以訪問實時數據,與其他AI系統合作,甚至與物理設備接口。
例如,在客戶服務應用中,一個 LLM 可能根據預先訓練的腳本生成標準化回答。但這些回答可能是靜態的,並且缺乏進行有效客戶參與所需的个性化。
一個 AI 代理可以通過整合來自客戶檔案、以前交談和情感分析工具的實時數據來豐富這些互動,這有助於生成不僅在語境上相關,而且是根據客戶特定需求定制的回答。
這種整合將客戶體驗從一系列預先编排的互動转变为動態、个性化對話。
擴展創造力和問題解決能力
雖然 LLM 是生成內容的強大工具,但它們的創造力和問題解決能力本质上市由它們訓練時所用數據所限制。這些模型通常無法將理論概念應用於新或在預見之外的挑戰,因為它們的問題解決能力受限于既有的知識和訓練參數。
AI 代理通過 leveraging 先進推理技術和更廣泛的分析工具,增強了 LLM 的創造力和問題解決潛力。這種能力使得 AI 代理能夠超越 LLM 的限制,以創新方式將理論框架應用於實際問題。
例如,考慮在社交媒體平台上應對錯誤信息的問題。一個 LLM 可能根據文字分析識別誤信息的模式,但它可能難以開發一套全面的策略來減少虚假信息的傳播。
AI代理可以汲取這些洞見,應用來自社會學、心理學、網絡理論等領域的跨學科理論,並開發出健壯、多面向的方法,包括實時監控、用戶教育和自動化管理技術。
這種合成多種理論框架並將其應用於現實挑戰的能力,展現了AI代理人在解决问题的增强能力。
更具体的例子
AI代理以其與多種系統互動、訪問實時數據和執行行為的能力,直面這些局限性,將LLM從強大但被动的自然語言模型轉變為積極动态的实战問題解決者。讓我們来看一些例子:
1.從靜態數據到動態洞見:讓LLM与时俱进
-
問題: 想像一下,你向於2023年前訓練的LLM问道:“目前在癌症治療方面有哪些最新突破?” 它的知識将会过时。
-
AI代理解决方案: AI代理可以将LLM連接到医学期刊、研究數據庫和新闻资讯。现在,LLM可以提供有关最新臨床試驗、治療选项和研究发现的最新信息。
2.從分析到行動:基於LLM洞察的自動化任務
-
問題:一個监控品牌社交媒体的大型語言模型可能會發現负面情绪的湧升,但無法採取任何行動來解決問題。
-
人工智慧代理解決方案:一個連接品牌社交媒体帳號且配有预先批准回应的人工智慧代理可以自動解決疑虑、回答問題,甚至將複雜問題轉交給人類代表。
3.從初稿到光滑產品:確保質量和準確性
-
問題:一個被指派翻譯技術手冊的大型語言模型可能會產生語法正確但技術上不準確的翻譯,這由於它缺乏特定領域知識。
-
AI代理解決方案:AI代理可以將LLM與專業詞典、詞表甚至連接到相關領域專家提供即時反饋,確保最終的翻譯既語法正確又技術上正確。
4. 打破障礙:將LLM連接到現實世界
-
問題:設計用於智能家庭控制的LLM可能會 struggle to adapt to a user’s changing routines and preferences.
-
AI代理解決方案:AI代理可以將LLM連接到感應器、智能設備和用戶日曆。通過分析用戶行為模式,LLM可以學習預測需求、自動調整照明和溫度設定,甚至根據時間和用戶活動建議個人化音樂播放列表。
5.從模仿到創新:扩展LLM創造力
-
問題:被指派創作音樂的LLM可能會創造出听起来似曾相识或缺乏情緒深度的作品,因為它主要依賴於其在訓練數據中發現的模式。
-
AI代理解決方案:AI代理可以將LLM連接到測量作曲家對不同音樂元素的情緒反應的生物反馈感測器。通過融合這種實時反饋,LLM可以創造不僅技術上精通,而且情緒上也引人入胜且原创的音乐。
人工智慧代理作為長篇語句模型的 Enhancer,不僅是 incremental 的改善,更是對人工智慧所能達成的 fundamental 扩展。透過解決傳統長篇語句模型的限制,如靜態知識庫、有限的決策自主性和封閉的操作環境,人工智慧代理使這些模型能夠充分发挥其潛力。
隨著人工智慧技術的持續發展,人工智慧代理在提升長篇語句模型方面的作用將變得越來越重要,不僅在扩展這些模型的功能,也在重新定義人工智慧的界限。這種融合正在為下一代人工智慧系統开辟道路,這一代系統將能夠進行自動推理、實時適應和新颖問題解決,迎接不斷變化的世界。
第六章:將人工智慧代理與長篇語句模型整合的建築設計
將人工智慧代理與長篇語句模型整合取決於建築設計,這對於提高決策、適應性和可擴展性至關重要。建築設計需要精心打造,以實現人工智慧代理與長篇語句模型之間的無縫互動,確保每個组件都能最优 functionality。
一個模組化建築設計,其中人工智慧代理作為 orchestrator,指導長篇語句模型的能力,是一種支持動態任務管理的做法。這種設計充分利用了長篇語句模型在自然語言處理方面的優勢,同時讓人工智慧代理負責管理更複雜的任務,例如在實際環境中進行多步推理或情境決策。
hybrid model’, 结合了LLM與专门精調的模型,提供了靈活性,使得AI代理人能夠將任務委派給最合適的模型。這種方法在各種應用中優化性能和提高效率,特别是在多樣化和變化的操作環境中,使其尤為有效(Liang等,2021)。

訓練方法與最佳實踐
將LLM與AI代理人結合在一起的訓練需要一種systematic方法,它在泛化與任務特定的優化之間保持平衡。
轉移學習是這裡的关键技術,它讓已經在大量多樣化的語料庫上預訓練的LLM能夠在與AI代理人的任務相關的領域specific數據上進行fine-tuning。這種方法保留了LLM的廣泛知識基礎,同時使它能夠在特定應用中专业化,從而提高整體系統效果。
此外, reinforcement learning (RL)在這裡扮演著至關重要的角色,特別是當AI代理人必須適應不斷變化的環境時。通過與環境互動,AI代理人可以不斷提高其決策過程,變得更加擅長處理新挑戰。
為了確保在不同情境下都有可靠的性能,严謹的評價指標是必不可少的。這些應該包括標準benchmarks和任務specific標準,確保系統的訓練是堅實和全面的(Silver等,2016)。
大語言模型(LLM)的精調 Introducing Fine-Tuning and Reinforcement Learning Concepts
這份代碼展示了各種 machine learning 和自然語言處理 (NLP) 技術,著重於為特定任務微調大型語言模型 (LLM) 以及實現 reinforcement learning (RL) 代理。該代碼涵蓋了幾個關鍵領域:
-
為 LLM 微調: 使用如 BERT 的預訓練模型進行情感分析等任務,並使用 Hugging Face 的
transformers庫。這涉及將數據集分詞並使用訓練參數來指導微調過程。 -
Reinforcement Learning (RL): 介紹 RL 的基本概念,並示例一個簡單的 Q 學習代理,代理通過與環境互動并通过 Q 表更新其知識進行學習。
-
使用 OpenAI API 的獎勵建模: 一個概念性的方法,使用 OpenAI 的 API 向 RL 代理提供動態的獎勵信號,讓語言模型評估行為。
-
模型評估與日誌记录: 使用如
scikit-learn等庫來通過準確度與 F1 得分評估模型性能,並用 PyTorch 的SummaryWriter來可视化訓練进度。 -
進階 RL 概念: 實現如策略梯度網絡、課程學習以及早停法等進階概念,以提升模型訓練效率。
這種全方位方法涵蓋了監督學習(含情感分析微調)以及強制學習,提供了現代 AI 系統是如何建造、評估及優化的洞見。
程式碼示例
步驟 1:導入必要的庫
在進入模型微調和代理實施之前, setting up the necessary libraries and modules 是不可或缺的。這段代碼包含了從如Hugging Face的 transformers 和 PyTorch 等著名庫的導入,以處理神經網絡、scikit-learn 以評估模型性能,以及如 random 和 pickle 的一般用途模塊。
-
Hugging Face 庫: 這些允許你使用和微調從模型存儲庫中選擇的預訓練模型和分詞器。
-
PyTorch: 這是用於操作的core deep learning framework,包括神經網絡層和優化器。
-
scikit-learn: 提供如準確性和F1分數等指標來評估模型性能。
-
OpenAI API: 通過此API存取OpenAI的語言模型,以進行如獎勵建模等各種任務。
-
TensorBoard: 用於可视化訓練進度。
以下是导入必要庫的代碼:
# 導入 random 模塊用於生成隨機數字。
import random
# 從 transformers 庫導入必要的模塊。
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# 導入 load_dataset 模塊用於上加載數據集。
from datasets import load_dataset
# 導入 metrics 模塊用於評估模型性能。
from sklearn.metrics import accuracy_score, f1_score
# 導入 SummaryWriter 模塊用於記錄訓練進程。
from torch.utils.tensorboard import SummaryWriter
# 導入 pickle 模塊用於保存和上加載訓練好的模型。
import pickle
# 導入 openai 模塊用於使用 OpenAI 的 API(需要 API 匙)。
import openai
# 導入 PyTorch 模塊用於深度學習操作。
import torch
# 從 PyTorch 導入神經網絡模塊。
import torch.nn as nn
# 從 PyTorch 導入優化器模塊(本例中直觀使用)。
import torch.optim as optim
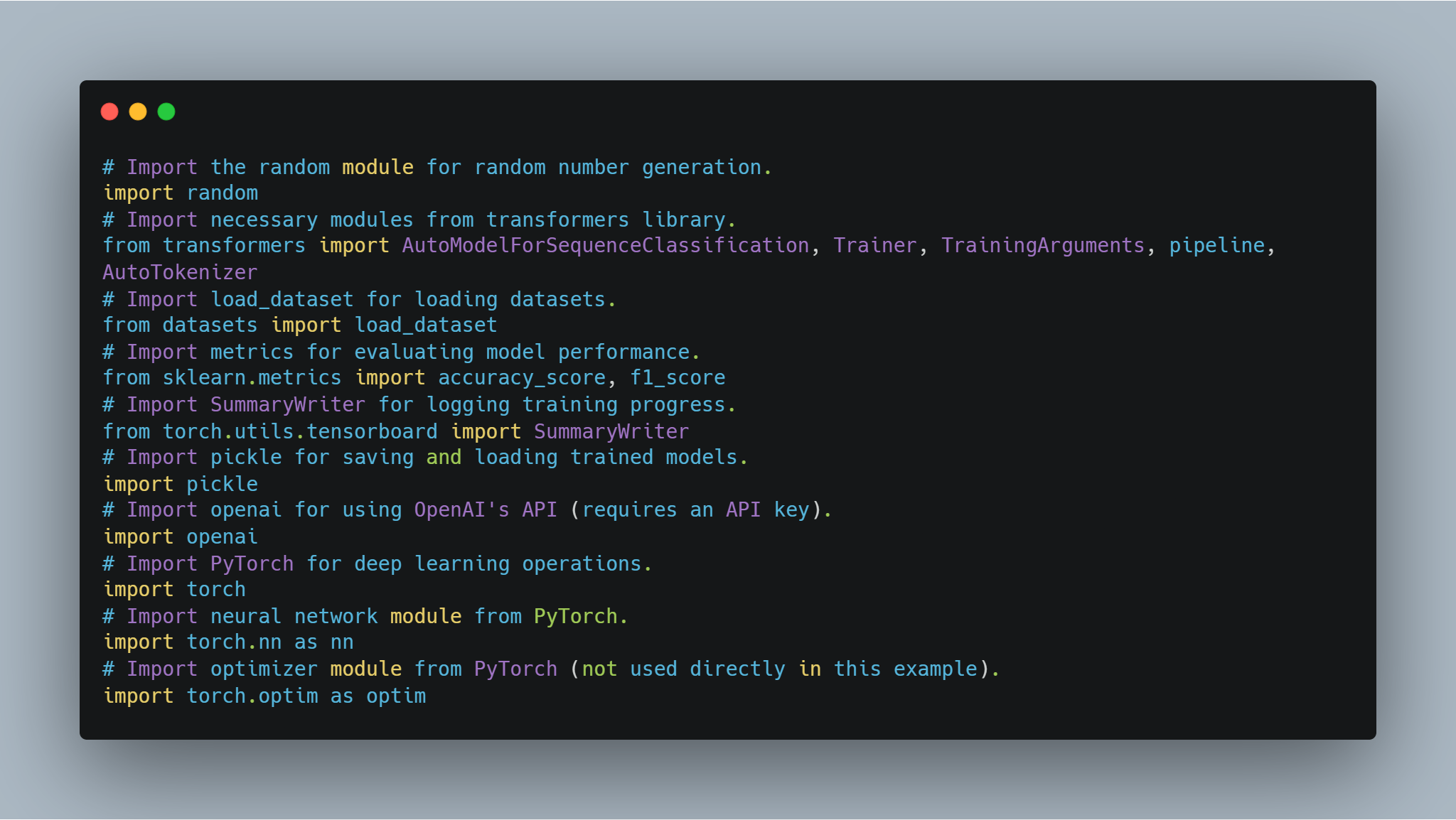
這些導入每個都在代碼的不同部分扮演著重要的角色,從模型訓練和評估到記錄結果和與外部 API 互動。
步驟 2:為情感分析微調語言模型
為特定任務如情感分析微調預訓練模型涉及加載預訓練模型,為輸出標籤數量(本例中為正面/負面)進行調整,並使用合適的數據集。
在這個示例中,我們使用從 `transformers` 庫来的 `AutoModelForSequenceClassification`,並用 IMDB 數據集。這個預訓練模型可以者在數據集較小的部分上進行微調以節省計算時間。模型然後使用自訂的訓練參數進行訓練,包括河谷期數和批次大小。
以下是用於加載和微調模型的代碼:
# 指定從 Hugging Face Model Hub 的預訓練模型名稱。
model_name = "bert-base-uncased"
# 用指定了類別數量來加載預訓練模型。
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 為模型加載分詞器。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 使用 Hugging Face Datasets 加載 IMDB 數據集,只用 10% 作為訓練。
dataset = load_dataset("imdb", split="train[:10%]")
# 分詞數據集。
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 将數據集映射到分詞輸入。
tokenized_dataset = dataset.map(tokenize_function, batched=True)
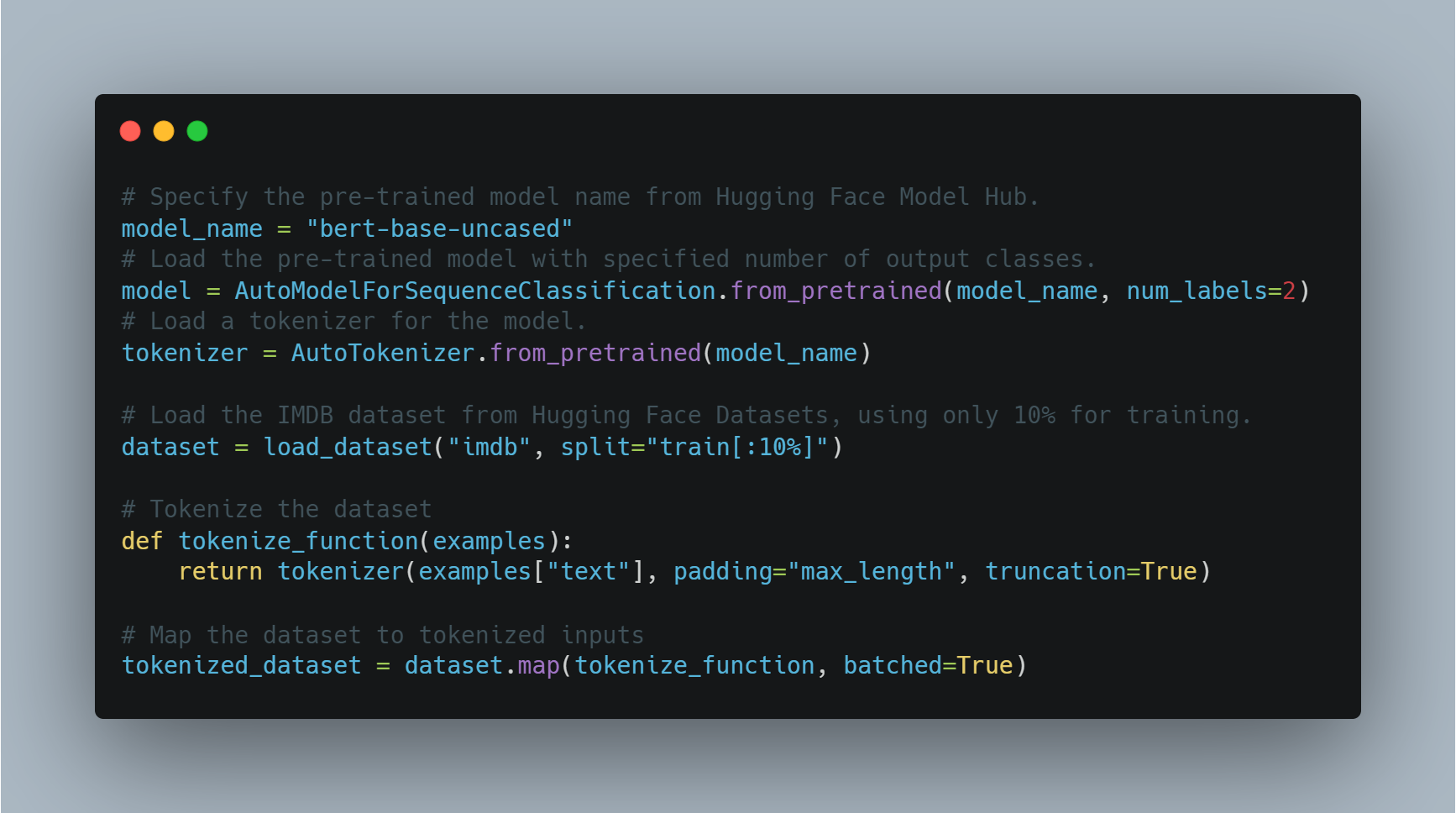
在這裡,我們使用以 BERT 作為基礎結構來加載模型,並為訓練準備數據集。接下來的,我們定義訓練參數並初始化 Trainer。
# 定義訓練參數。
training_args = TrainingArguments(
output_dir="./results", # 指定保存模型的輸出目錄。
num_train_epochs=3, # 設定訓練回合數。
per_device_train_batch_size=8, # 設定每個設備的批次大小。
logging_dir='./logs', # 存放日誌的目錄。
logging_steps=10 # 每10步記錄一次日誌。
)
# 使用模型、訓練參數和數據集初始化 Trainer。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# 開始訓練過程。
trainer.train()
# 保存微調後的模型。
model.save_pretrained("./fine_tuned_sentiment_model")

步驟 3:實現一個簡單的 Q 學習代理
Q 學習是一種強化學習技術,其中代理學習以最大化累計獎勵的方式採取行動。
在這個示例中,我們定義了一個基本的 Q 學習代理,該代理在 Q 表中存儲狀態-行動對。代理可以隨機探索或根據 Q 表利用最好的行動。在每次行動後,Q 表使用學習率和折扣因子更新,以權衡未來獎勵。
以下是實現此 Q 學習代理的代碼:
# 定義 Q-learning 嗅探器類別。
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# 初始化 Q-table。
self.q_table = {}
# 儲存可能的行動。
self.actions = actions
# 設定探索率。
self.epsilon = epsilon
# 設定學習率。
self.alpha = alpha
# 設定折現因子。
self.gamma = gamma
# 定義 get_action 方法,根據當前狀態選擇行動。
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# 隨機探索。
return random.choice(self.actions)
else:
# 利用最佳行動。
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
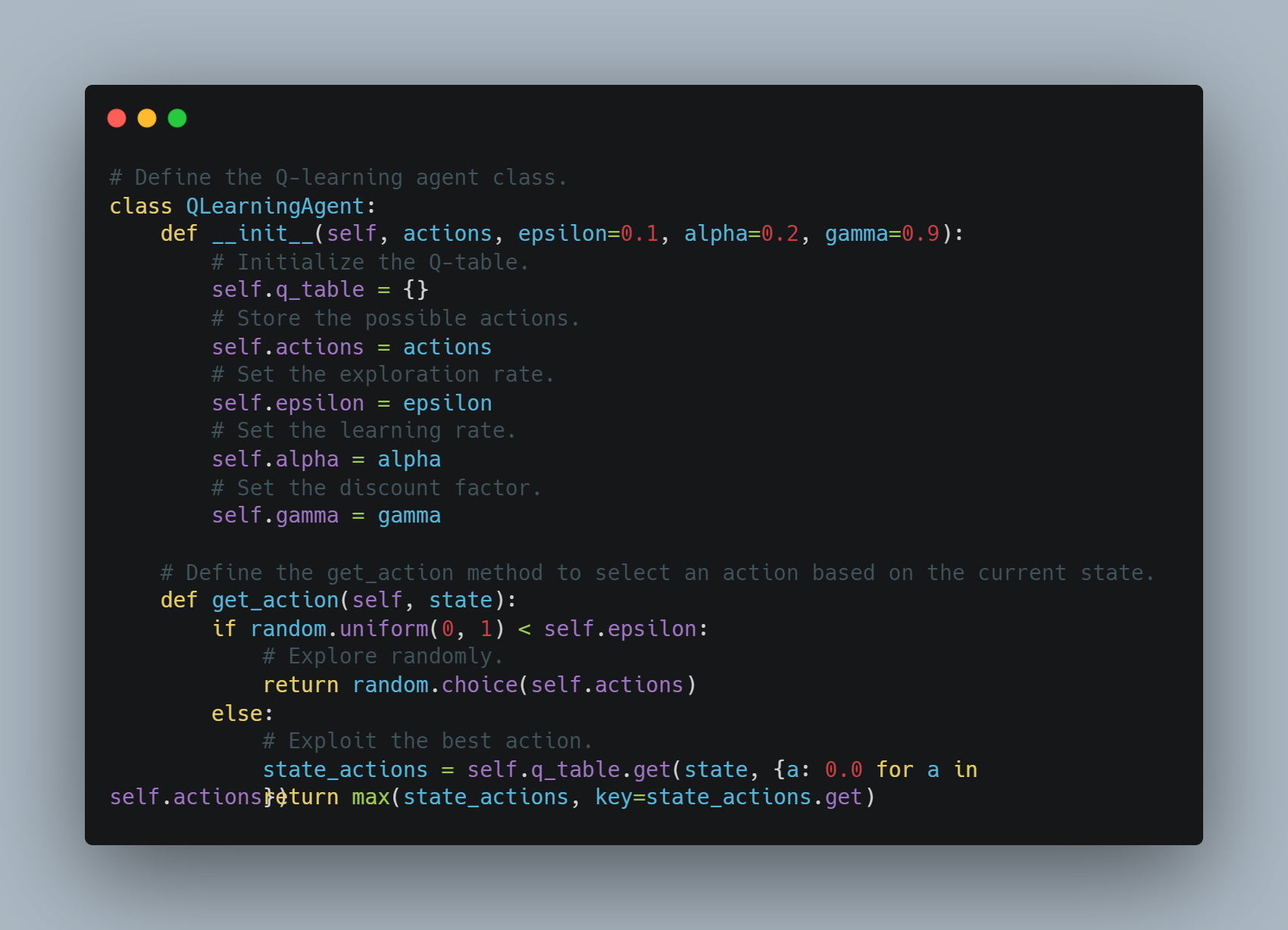
該嗅探器根據探索或利用選擇行動,並在每步後更新 Q 值。
# 定義 update_q_table 方法以更新 Q-table。
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
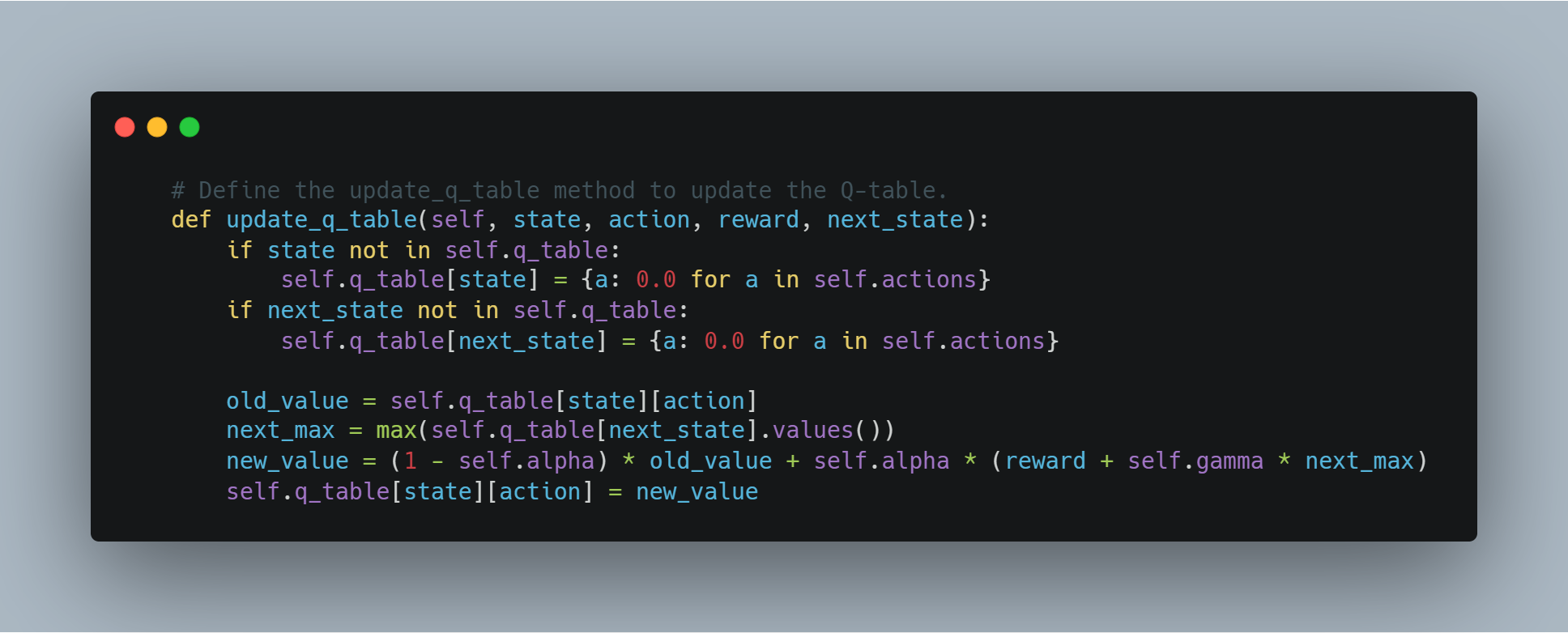
步驟 4:使用 OpenAI 的 API 進行獎勵建模
在某些情境下,我們可以不定义手動獎勵函數,而是使用像 OpenAI 的 GPT 這樣強大的語言模型來評估代理所採取行動的質量。
在這個例子中,get_reward 函數將狀態、行動和下一狀態發送到 OpenAI 的 API 以接收獎勵分數,使我們能夠利用大型語言模型理解複雜的獎勵結構。
# 定義 get_reward 函數以從 OpenAI 的 API 獲取獎勵信號。
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # 更換為您實際的 OpenAI API 金鑰。
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
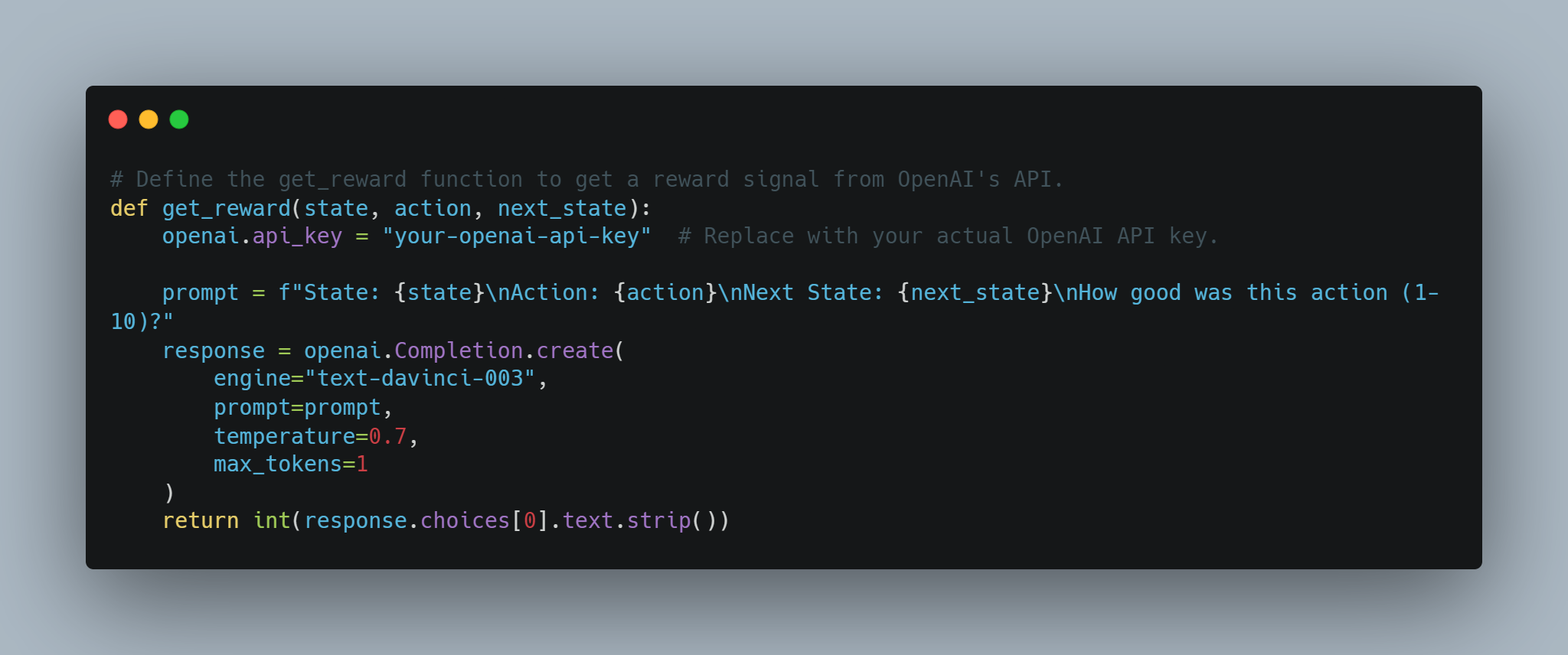
這讓概念化的方法成為可能,等奖励系統透過 OpenAI 的 API 動態決定,這對於獎勵難以定義的複雜任務來說可能有用。
步驟 5:評估模型表現
一旦 machine learning 模型被訓練,透過準確度和 F1 分会數等標準指標來評估其表現是根本的。
此節通過真實和預測的標籤來計算這兩者。準確度提供正確性的整體衡量,而 F1 分会數则在失衡的數據集中的精度和召回率之間取得平衡,特別有用。
以下是評估模型表現的代碼:
# 定義評估用的真實標籤。
true_labels = [0, 1, 1, 0, 1]
# 定義評估用的預測標籤。
predicted_labels = [0, 0, 1, 0, 1]
# 計算準確度分數。
accuracy = accuracy_score(true_labels, predicted_labels)
# 計算 F1 分会數。
f1 = f1_score(true_labels, predicted_labels)
# 打印準確度分數。
print(f"Accuracy: {accuracy:.2f}")
# 打印 F1 分会數。
print(f"F1-Score: {f1:.2f}")
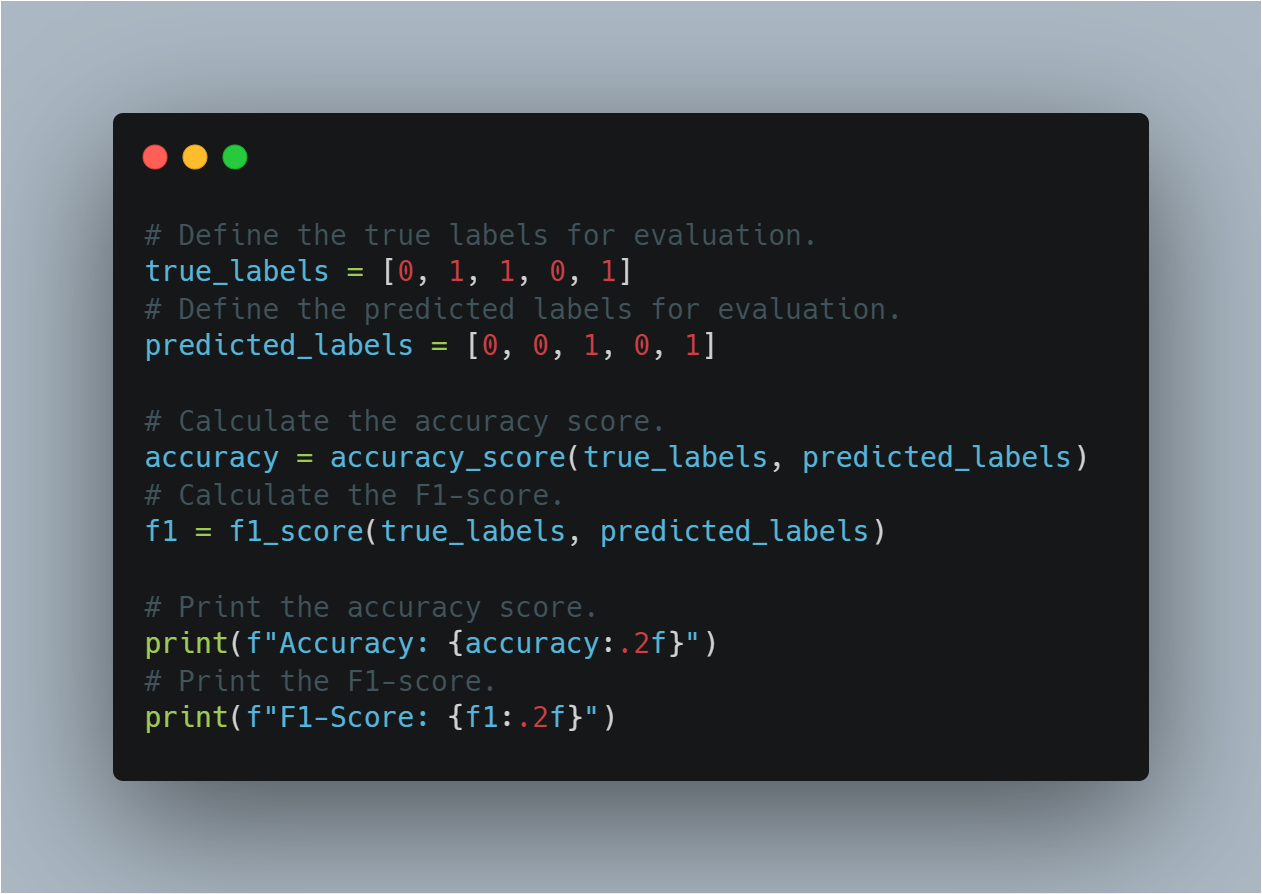
此節透過使用已被确立的評估指標,有助於評估模型對於未見過的數據的一般化能力。
步驟 6:基本策略梯度代理 (使用 PyTorch)
在強化學習中,策略梯度方法直接通過最大化期望獎勵來優化策略。
本節展示了一個使用PyTorch实现的簡單策略網絡,可用於RL中的決策。策略網絡使用線性層來輸出不同行為的機率,並應用softmax確保這些輸出形成一個有效的機率分布。
以下是为定義一個基本的策略梯度代理的概念性代碼:
# 定義策略網絡類。
class PolicyNetwork(nn.Module):
# 初始化策略網絡。
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# 定義線性層。
self.linear = nn.Linear(input_size, output_size)
# 定義網絡的前向傳遞。
def forward(self, x):
# 將線性層的輸出應用softmax。
return torch.softmax(self.linear(x), dim=1)
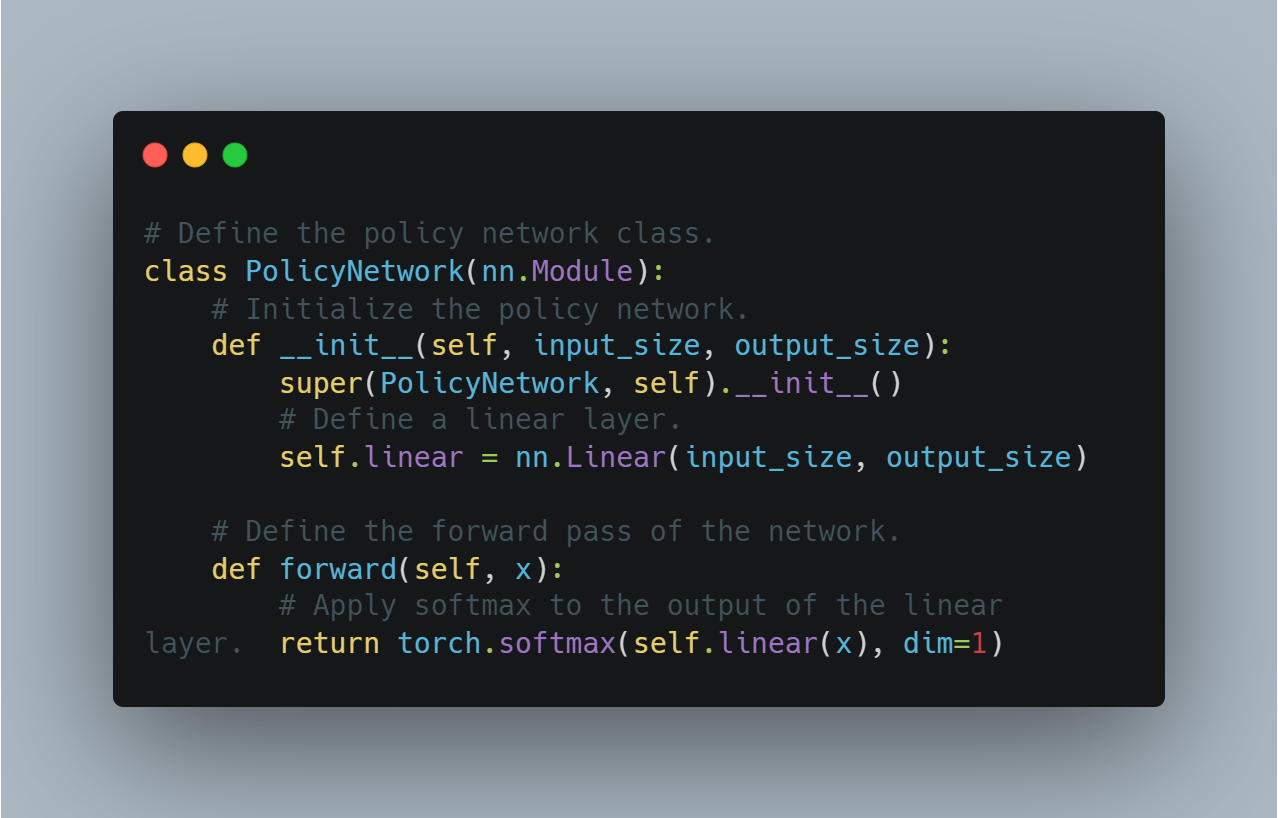
這為實現使用策略優化的更進階的強制學習算法奠定了基礎。
步驟7:使用TensorBoard可视化訓練進度
可视化訓練指標,如損失和準確度,對於了解模型性能随時間是如何變化的至關重要。TensorBoard,一個流行的工具,可用來記錄指標並實時可视化它們。
在這一節中,我們創建了一個SummaryWriter實例,並記錄隨機值來模擬者在訓練過程中跟踪損失和準確度的過程。
以下是如何使用TensorBoard記錄和可视化訓練進度的方法:
# 建立一個 SummaryWriter 實例。
writer = SummaryWriter()
# TensorBoard 可視化的示例訓練循環:
num_epochs = 10 # 定義迭代的回合數。
for epoch in range(num_epochs):
# 模擬隨機的損失和準確度值。
loss = random.random()
accuracy = random.random()
#將損失和準確度記錄到 TensorBoard。
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# 關閉 SummaryWriter。
writer.close()
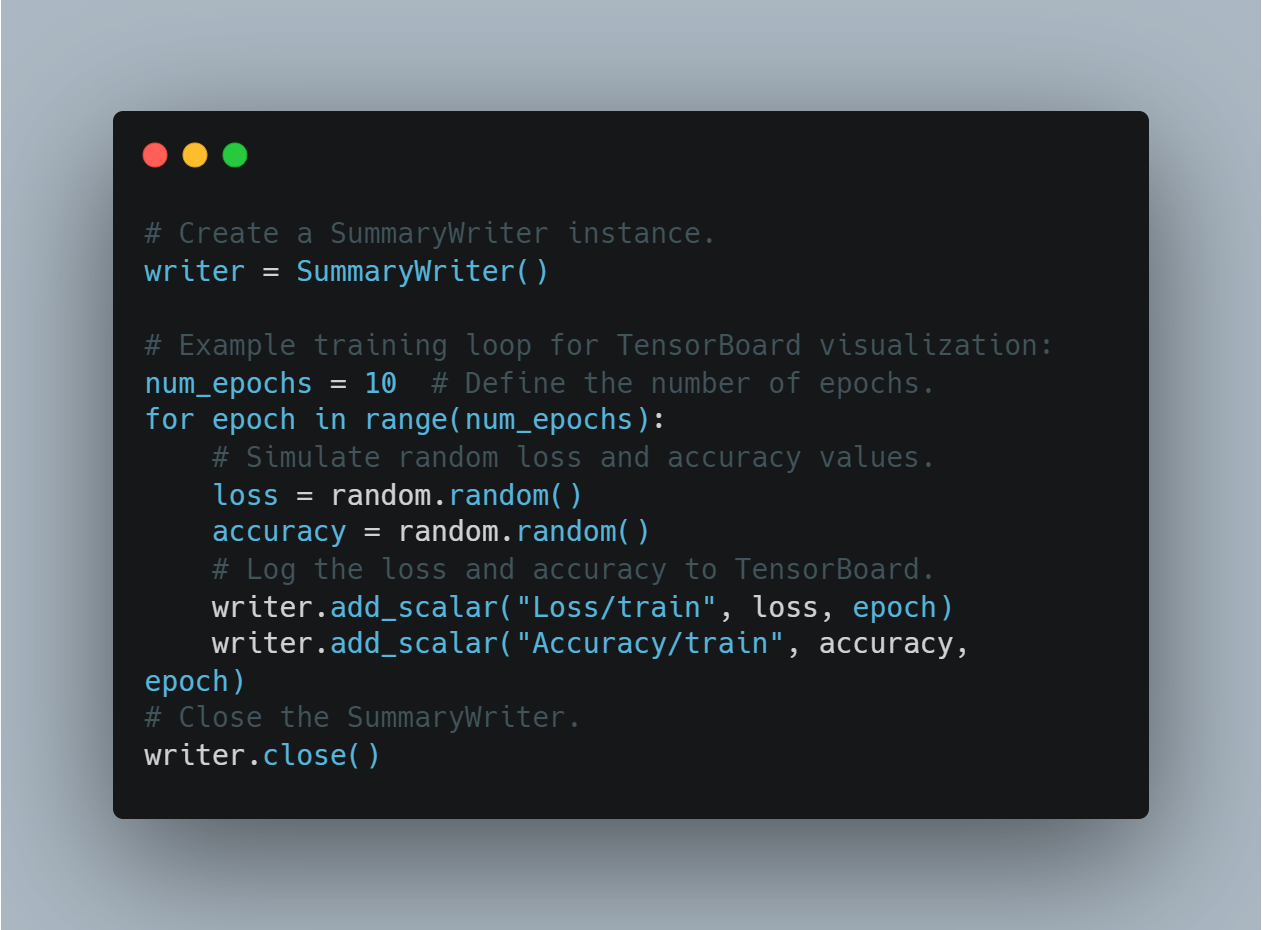
這讓用戶能夠監視模型的訓練並根據視覺反饋進行實時調整。
步驟 8:保存和載入訓練好的代理節點快照
训緈一个代理后,保存其学到的状态(例如,Q值或模型权重)是非常重要的,这样它可以在以后重新使用或评估。
本节将介绍如何使用Python的pickle模块保存训练好的代理,以及如何从磁盘重新加载它。
以下是保存和加载训练好的Q学习代理的代码:
# 创建Q学习代理的一个实例。
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# 训练代理(此处未展示)。
# 保存代理。
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# 加载代理。
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
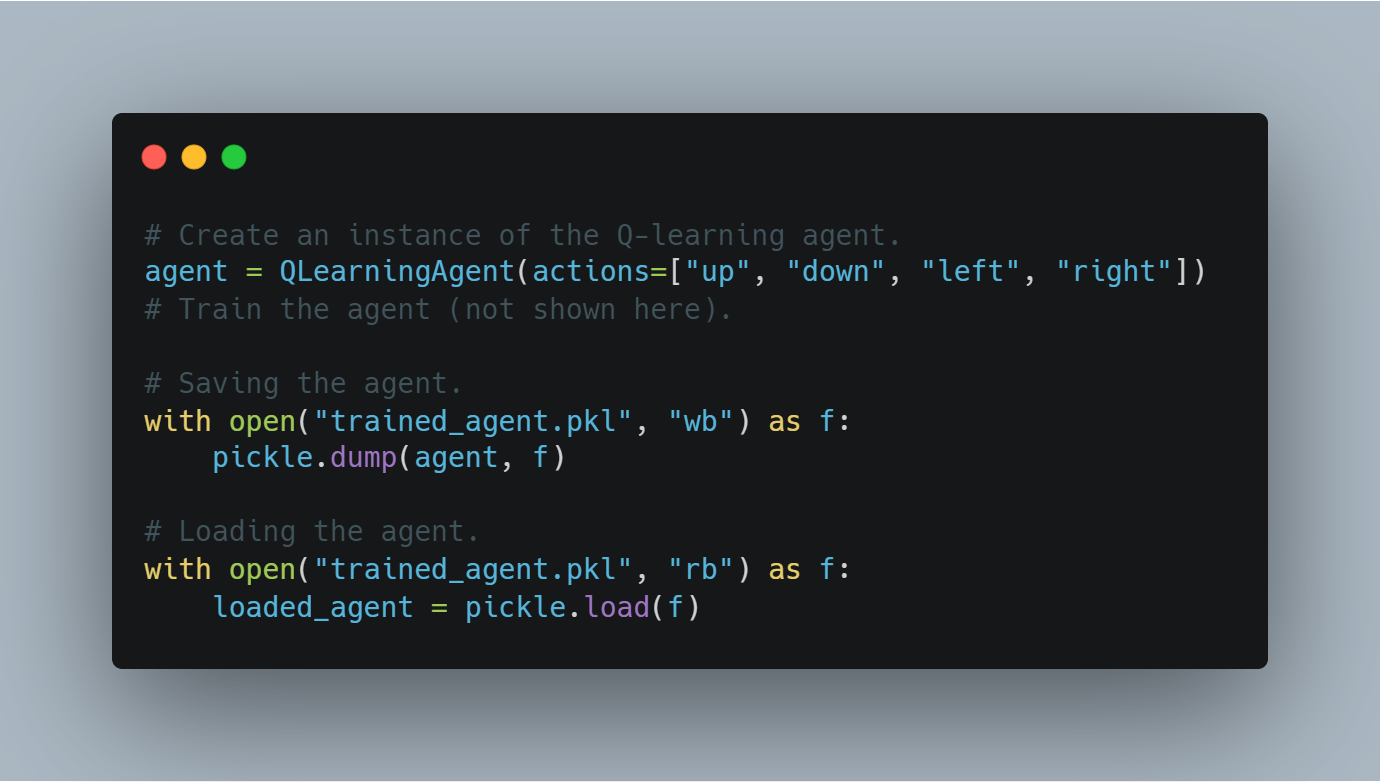
这种检查点的过程确保了训练进度不会丢失,模型可以在未来的实验中重复使用。
步驟 9:課程學習
课程學習包含逐步提高模型接收到的任務難度,從較易的例證開始,逐漸 transition 至更具挑戰性的案例。這可以幫助在訓練過程中提高模型的表現和穩定性。
以下是一個在訓練循環中使用課程學習的示例:
# 設定初始任務難度。
initial_task_difficulty = 0.1
# 具有課程學習的訓練循環示例:
for epoch in range(num_epochs):
# 逐步提高任務難度。
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# 生成調整難度的訓練數據。
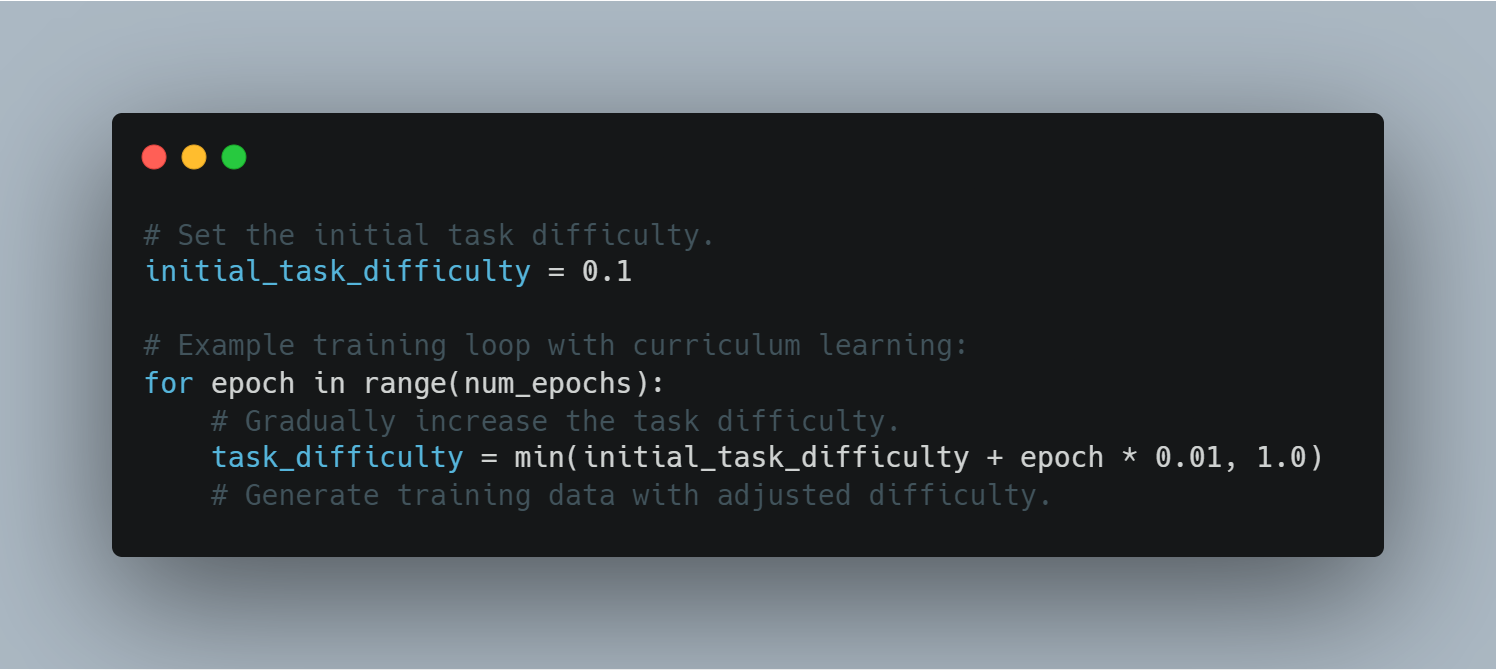
通過控制任務難度,代理可以逐步處理更複雜的挑戰,從而提高學習效率。
步驟 10:實現早停
早停是一種技術,可在训緓过程中防止过拟合,通过在一定数量的轮次(耐心度)内,如果验证损失没有改善就停止过程。
本节将展示如何在训练循环中实现早停,使用验证损失作为关键指标。
以下是实现早停的代码:
# 初始化最佳验证损失為無窮大。
best_validation_loss = float("inf")
# 設定耐心值(沒有改進的數據回合數)。
patience = 5
# 初始化没有改進的回合計數器。
epochs_without_improvement = 0
# 带有早期停止的訓練循环示例:
for epoch in range(num_epochs):
# 模擬隨機的驗證损失。
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

早期停止通過防止不必要的訓練來提高模型的泛化能力,防止模型過度擬合。
步驟11:使用預訓練的LLM進行零样本任務轉移
在零样本任務轉移中,將預訓練的模型應用於其特別未進行微調的任務。
使用Hugging Face的pipeline,本節展示如何不用額外的訓練,將預訓練的BART模型用於摘要在內,阐述轉移學習的概念。
以下是使用預訓練LLM進行摘要在内的代碼:
# 載入一個預訓練的摘要有道pipe。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# 定義要摘要在内的文本。
text = "This is an example text about AI agents and LLMs."
# 生成摘要在内。
summary = summarizer(text)[0]["summary_text"]
# 打印摘要在内。
print(f"Summary: {summary}")
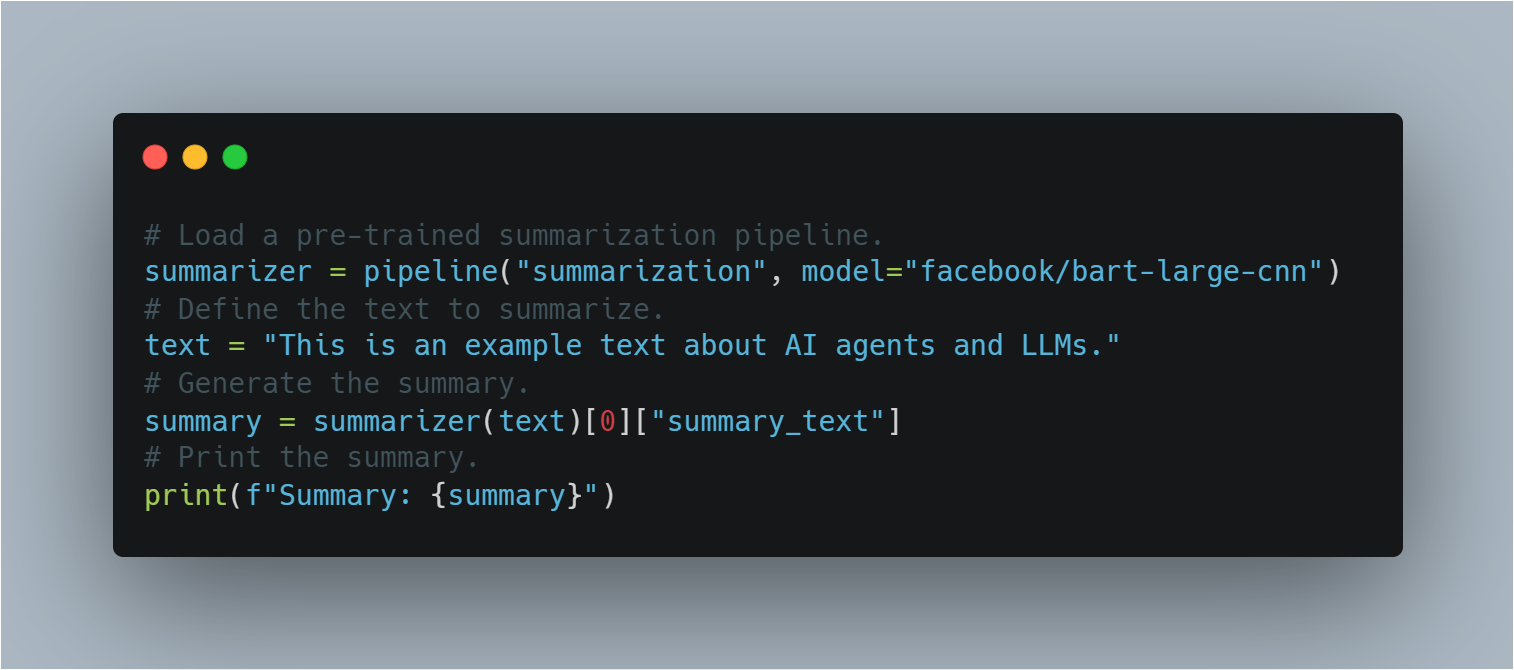
這展示了LLM在不需要進一步訓練的情況下執行多樣任務的靈活性,借鑒其既有的知識。
完整代碼示例
# 導入隨機模組以生成隨機數。
import random
# 從 transformers 庫導入必要的模組。
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# 導入 load_dataset 以加載數據集。
from datasets import load_dataset
# 導入 metrics 以評估模型性能。
from sklearn.metrics import accuracy_score, f1_score
# 導入 SummaryWriter 以記錄訓練進度。
from torch.utils.tensorboard import SummaryWriter
# 導入 pickle 以保存和加載訓練好的模型。
import pickle
# 導入 openai 以使用 OpenAI 的 API(需要 API 密鑰)。
import openai
# 導入 PyTorch 以進行深度學習操作。
import torch
# 從 PyTorch 導入神經網絡模組。
import torch.nn as nn
# 從 PyTorch 導入優化器模組(在此示例中未直接使用)。
import torch.optim as optim
# --------------------------------------------------
# 1. 微調 LLM 以進行情感分析
# --------------------------------------------------
# 指定來自 Hugging Face 模型庫的預訓練模型名稱。
model_name = "bert-base-uncased"
# 加載具有指定輸出類別數的預訓練模型。
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 為模型加載一個分詞器。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 從 Hugging Face 數據集中加載 IMDB 數據集,只用 10% 進行訓練。
dataset = load_dataset("imdb", split="train[:10%]")
# 對數據集進行分詞
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 將數據集映射到分詞輸入
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 定義訓練參數。
training_args = TrainingArguments(
output_dir="./results", # 指定保存模型的輸出目錄。
num_train_epochs=3, # 設定訓練的迭代次數。
per_device_train_batch_size=8, # 設定每個設備的批次大小。
logging_dir='./logs', # 用於存儲日誌的目錄。
logging_steps=10 # 每 10 步記錄一次。
)
# 用模型、訓練參數和數據集初始化訓練器。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# 開始訓練過程。
trainer.train()
# 保存微調後的模型。
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. 實現簡單的 Q-學習代理
# --------------------------------------------------
# 定義 Q-學習代理類。
class QLearningAgent:
# 用行動、epsilon(探索率)、alpha(學習率)和 gamma(折扣因子)初始化代理。
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# 初始化 Q-表。
self.q_table = {}
# 存儲可能的行動。
self.actions = actions
# 設定探索率。
self.epsilon = epsilon
# 設定學習率。
self.alpha = alpha
# 設定折扣因子。
self.gamma = gamma
# 定義 get_action 方法以根據當前狀態選擇行動。
def get_action(self, state):
# 以 epsilon 機率隨機探索。
if random.uniform(0, 1) < self.epsilon:
# 返回一個隨機行動。
return random.choice(self.actions)
else:
# 根據 Q-表利用最佳行動。
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# 定義 update_q_table 方法以在採取行動後更新 Q-表。
def update_q_table(self, state, action, reward, next_state):
# 如果狀態不在 Q-表中,則添加它。
if state not in self.q_table:
# 為新狀態初始化 Q-值。
self.q_table[state] = {a: 0.0 for a in self.actions}
# 如果下一個狀態不在 Q-表中,則添加它。
if next_state not in self.q_table:
# 為新的下一狀態初始化 Q-值。
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# 獲取狀態-行動對的舊 Q-值。
old_value = self.q_table[state][action]
# 獲取下一個狀態的最大 Q-值。
next_max = max(self.q_table[next_state].values())
# 計算更新的 Q-值。
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# 用新的 Q-值更新 Q-表。
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. 使用 OpenAI 的 API 進行獎勵建模(概念性)
# --------------------------------------------------
# 定義 get_reward 函數以從 OpenAI 的 API 獲取獎勵信號。
def get_reward(state, action, next_state):
# 確保 OpenAI API 密鑰設置正確。
openai.api_key = "your-openai-api-key" # 用你的實際 OpenAI API 密鑰替換。
# 為 API 調用構造提示。
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# 向 OpenAI 的完成端點發送 API 調用。
response = openai.Completion.create(
engine="text-davinci-003", # 指定要使用的引擎。
prompt=prompt, # 傳遞構建的提示。
temperature=0.7, # 設定溫度參數。
max_tokens=1 # 設定生成的最大標記數。
)
# 從 API 回應中提取並返回獎勵值。
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. 評估模型性能
# --------------------------------------------------
# 定義評估的真實標籤。
true_labels = [0, 1, 1, 0, 1]
# 定義評估的預測標籤。
predicted_labels = [0, 0, 1, 0, 1]
# 計算準確率得分。
accuracy = accuracy_score(true_labels, predicted_labels)
# 計算 F1 得分。
f1 = f1_score(true_labels, predicted_labels)
# 打印準確率得分。
print(f"Accuracy: {accuracy:.2f}")
# 打印 F1 得分。
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. 基本策略梯度代理(使用 PyTorch)- 概念性
# --------------------------------------------------
# 定義策略網絡類。
class PolicyNetwork(nn.Module):
# 初始化策略網絡。
def __init__(self, input_size, output_size):
# 初始化父類。
super(PolicyNetwork, self).__init__()
# 定義線性層。
self.linear = nn.Linear(input_size, output_size)
# 定義網絡的前向傳播。
def forward(self, x):
# 對線性層的輸出應用 softmax。
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. 使用 TensorBoard 可視化訓練進度
# --------------------------------------------------
# 創建 SummaryWriter 實例。
writer = SummaryWriter()
# TensorBoard 可視化的示例訓練循環:
# num_epochs = 10 # 定義迭代次數。
# for epoch in range(num_epochs):
# # ... (在這裡進行你的訓練循環)
# loss = random.random() # 示例:隨機損失值。
# accuracy = random.random() # 示例:隨機準確率值。
# # 記錄損失到 TensorBoard。
# writer.add_scalar("Loss/train", loss, epoch)
# # 記錄準確率到 TensorBoard。
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (記錄其他指標)
# # 關閉 SummaryWriter。
# writer.close()
# --------------------------------------------------
# 7. 保存和加載訓練的代理檢查點
# --------------------------------------------------
# 示例:
# 創建 Q-學習代理的實例。
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (訓練你的代理)
# # 保存代理
# # 以二進制寫入模式打開文件。
# with open("trained_agent.pkl", "wb") as f:
# # 將代理保存到文件中。
# pickle.dump(agent, f)
# # 加載代理
# # 以二進制讀取模式打開文件。
# with open("trained_agent.pkl", "rb") as f:
# # 從文件中加載代理。
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. 課程學習
# --------------------------------------------------
# 設定初始任務難度。
initial_task_difficulty = 0.1
# 具有課程學習的示例訓練循環:
# for epoch in range(num_epochs):
# # 逐步提高任務難度。
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (生成調整難度的訓練數據)
# --------------------------------------------------
# 9. 實現提前停止
# --------------------------------------------------
# 將最佳驗證損失初始化為無限大。
best_validation_loss = float("inf")
# 設定耐心值(在沒有改進的情況下的迭代次數)。
patience = 5
# 初始化沒有改進的迭代計數器。
epochs_without_improvement = 0
# 具有提前停止的示例訓練循環:
# for epoch in range(num_epochs):
# # ... (訓練和驗證步驟)
# # 計算驗證損失。
# validation_loss = random.random() # 示例:隨機驗證損失。
# # 如果驗證損失改善。
# if validation_loss < best_validation_loss:
# # 更新最佳驗證損失。
# best_validation_loss = validation_loss
# # 重置計數器。
# epochs_without_improvement = 0
# else:
# # 增加計數器。
# epochs_without_improvement += 1
# # 如果在 '耐心' 迭代中沒有改進。
# if epochs_without_improvement >= patience:
# # 打印一條消息。
# print("提前停止觸發!")
# # 停止訓練。
# break
# --------------------------------------------------
# 10. 使用預訓練 LLM 進行零樣本任務轉移
# --------------------------------------------------
# 加載預訓練的摘要管道。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# 定義要摘要的文本。
text = "This is an example text about AI agents and LLMs."
# 生成摘要。
summary = summarizer(text)[0]["summary_text"]
# 打印摘要。
print(f"Summary: {summary}")

部署和擴展與長時間語料庫結合的AI代理商 significant technical and operational challenges
部署和擴展 Integrated AI agents 配合 LLMs 遇上了重大的技術和運營挑戰。其中一個主要的挑戰是計算成本,特別是當 LLMs 的大小和複雜性增加時。
解決這個問題需要像模型修剪、量化以及分散計算等資源效率策略。這些方法能有助於減少計算負擔,同時不牺牲性能。
在 realistic applications 保持可靠性和強度也是非常重要的,這需要持續監控、定期更新以及开发 fail-safe mechanisms 来处理意外的输入或系统故障。
當这些系统在各个行业中部署时,遵守道德标准—包括公正性、透明度和责任制—变得越来越重要。这些考虑是系统接受和长期成功的核心,影响公众信任以及 AI-driven decisions 在各种社会情境中的道德含义(Bender 等人,2021)。
與 LLMs 结合的 AI 代理商的技術实施涉及仔细的架构設計、嚴格的訓練方法以及 deployment challenges 的深思熟虑。
這些系統在 realistic environments 中的效果和可靠性与 Addressing both technical and ethical concerns 有关,确保 AI 技术在各种应用中平滑且负责任地运行。
第 7 章:AI 代理商和 LLMs 的未来
LLMs 与增强學習的融合
當你探索人工智慧代理和大型語言模型(LLM)的未来時,LLM與要强化學習的会说合被視為一個特別 transformative 發展。這種整合將傳統AI的界限推得更遠,不僅讓系統能夠生成和理解語言,還讓它們能夠從实时交互中學習。
通過要强化學習,人工智慧代理可以根據環境的反馈 Adaptively 修改它們的策略,從而不斷精炼它們的決策過程。這意味著,与静态模型不同,用要强化學習加强的AI系統能夠以最少的人類監督處理日益複雜和动态的任务。
這樣的系統的含义深遠:在從自主任務机器人到個人化教育等應用中,AI代理將能夠随时间自主提高其性能,使其更有效率且更能响应其操作环境的不断变化需求。
示例:基于文本的游戏玩法
想象一個AI代理在玩基于文本的冒险游戏。
-
環境:游戏本身(規則、状态描述等)
-
LLM:处理游戏的文本,理解当前情境,并生成可能的行为(例如,“向北走”,“拿起剑”)。
-
獎勵:遊戲根據行為結果授予(例如,找到宝藏獲取正面獎勵,失去血量獲得負面獎勵)。
代碼示例(使用Python和OpenAI API的概念性示例):
import openai
import random
# ... (遊戲環境邏輯 - 這裡未展示) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (RL訓練循環 - 簡化) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (根據獎勵更新RL代理 - 這裡未展示) ...
state = next_state
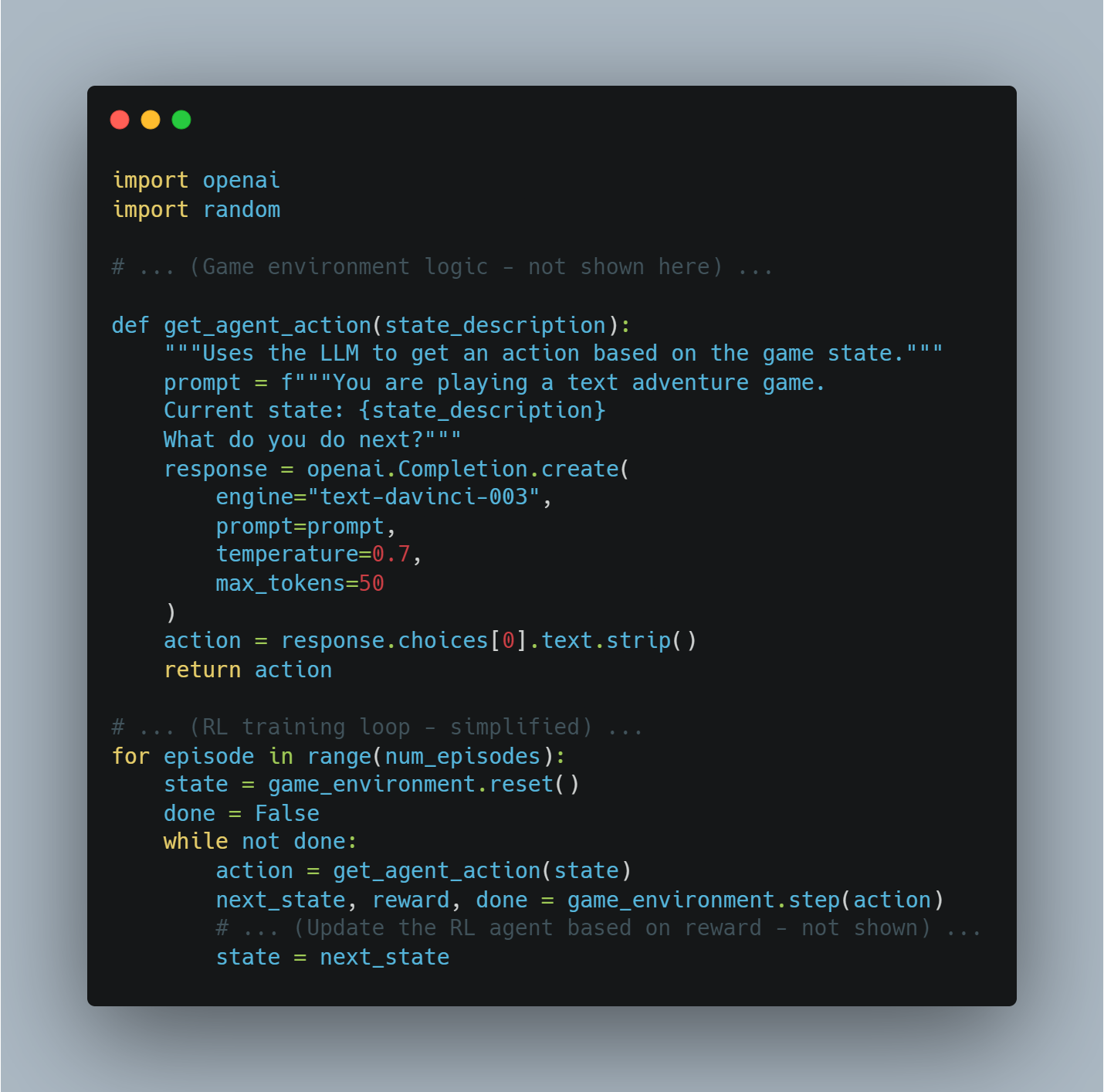
多模态AI整合
另一項形塑AI代理未來的重要趨勢是多模態AI的整合。通過讓系統能夠處理和結合來自各種來源的數據 – 例如文字、圖片、音頻和感官輸入,多模態AI為這些系統操作的環境提供更加全面的理解。
例如,在自動駕駛車輛中,AI能夠合成的視覺數據(來自攝影機)、情境數據(來自地圖)和实时交通更新,使AI能夠做出更加明智和安全的駕駛決定。
這種能力也 extends 到其他領域,如醫療,其中一個 AI 代理人可以整合來自醫療記錄、診斷成像和遺傳信息的病患數據,以提供更加精準和個人化的治療建議。
這裡的挑戰在於无缝整合和实时處理各種數據流,這需要模型結構和數據融合技術的進步。
成功地克服這些挑戰對於部署真正智能且能在複雜、现实世界中運作的 AI 系統將至關重要。
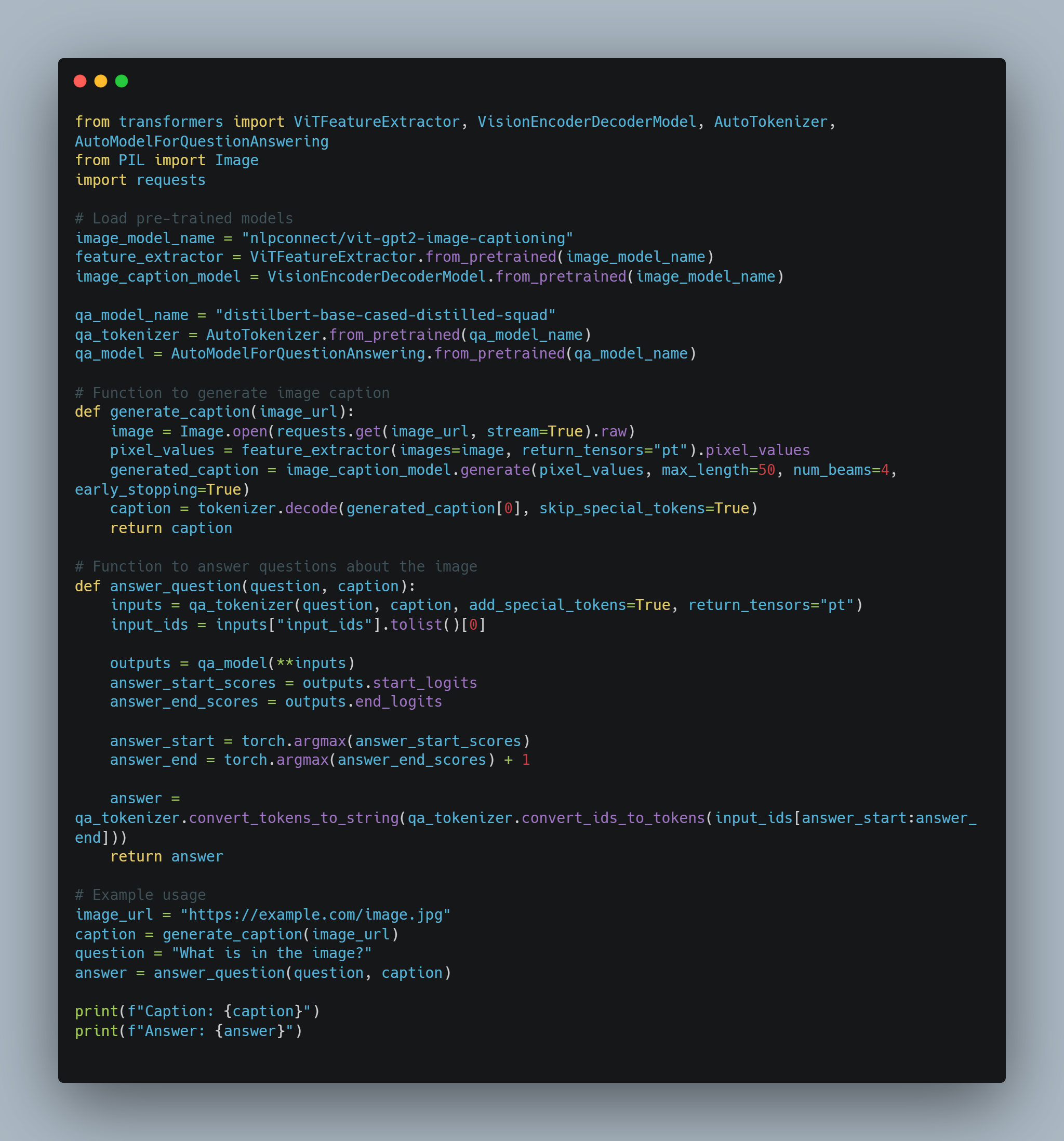
多模态 AI 示例 1:視覺問題回答的圖像配字
- 目標:一個能回答關於圖像問題的 AI 代理人。
-
模態:圖像, 文字
-
過程:
- 圖像 特徵提取:使用預訓練的卷積神經網絡 (CNN) 從圖像中提取特徵。
- 圖像 生成:使用像變壓器模型這樣的 LLM 根據提取的特徵生成人對圖像的描述。
- 問題回答:使用另一個 LLM 處理問題和生成的圖像描述,提供答案。
代碼示例(使用Python和Hugging Face Transformers概念性示例):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# 加載預訓練模型
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# 生成圖像標題的函數
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# 回答有關圖像的問題的函數
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# 示例用法
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
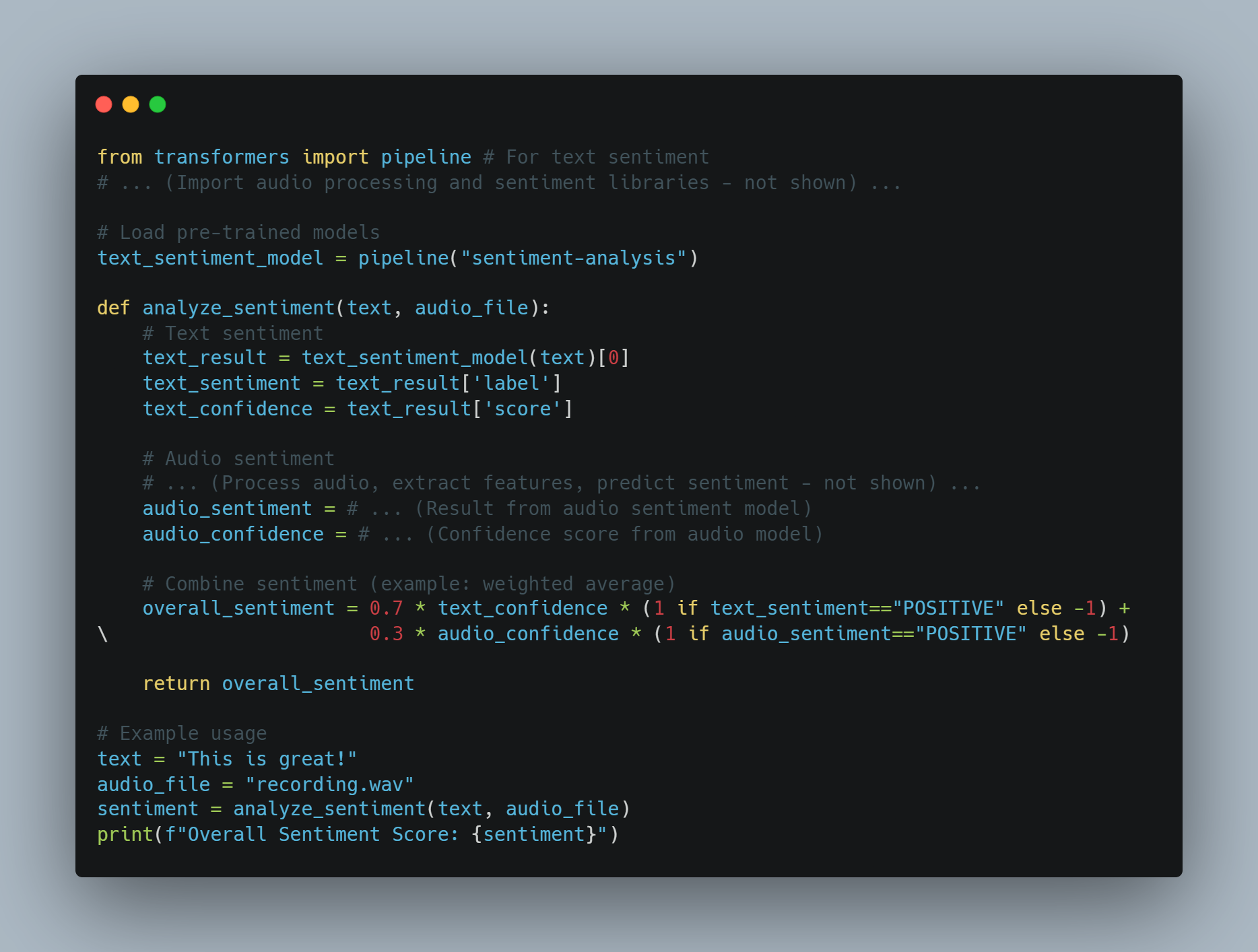
多模態AI示例2:從文本和音頻進行情緒分析
-
目標:一個AI代理,可以從信息的文本和語氣中分析情緒。
-
媒介:
文字, 音頻
-
處理:
-
文字情緒: 使用預先訓練的情緒分析模型的文字。
-
音頻情緒: 使用音頻處理模型的 tone 和 pitch 等特徵,然後使用這些特徵來預測情緒。
-
融合: 結合文字和音頻情緒分數(例如,加权平均)來獲得整體情緒。
-
代碼示例 (概念性地使用 Python):
from transformers import pipeline # 文字情感
# ... (音頻處理和情感庫 - 未顯示) ...
# 載入預訓練模型
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# 文字情感
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# 音頻情感
# ... (音頻處理、提取特徵、預測情感 - 未顯示) ...
audio_sentiment = # ... (來自音頻情感模型的結果)
audio_confidence = # ... (音頻模型的信心得分)
# 結合情感 (示例: 加权平均)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# 示例用法
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
挑戰和考慮因素:
-
數據对企业: 確保不同模態的數據同步和对齐至關重要。
-
模型複雜性: 多模態模型難以訓練,需要大型、多樣化的數據庫。
-
融合技術: 選擇正確的方法來結合不同模態的資訊很重要,且問題特定的。
多模AI是一個迅速進化的領域,有潛力革新一種AI代理人是如何感知和與世界互動的方式。
分佈式AI系統和邊緣計算
望向AI基礎設施的演變,由集中的AI系統轉變為由邊緣計算所支持的 分佈式AI系統,代表了一項顯著的進步。
分佈式AI系統通過在源头附近—如IoT設備或本地的伺服器—進行數據處理,將計算任務去中心化,而不是依賴於集中的雲資源。這種方法不僅减少了延遲,這對於无人機或工業自動化等時間敏感應用來說非常關鍵,同時也通過保持敏感信息在地端而增強了數據隐私和安全性。
此外,分佈式AI系統還提高了可擴展性,使得AI可以在如智慧城市等廣大網絡中部署,而不會使集中的數據中心不堪重負。
分佈式AI系統技術挑戰包括確保在不同節點之間的一致性和協調,以及優化資源分配以在多樣且可能受限的環境中维持性能。
當您開發和部署AI系統時,拥抱分佈式架構將是創造健壯、高效且可擴展的AI解決方案,以滿足未來應用需求的關鍵。
分的的人工智能系統和邊緣計算示例1:為保護隱私進行共享模型訓練的联邦學習
-
目標: 在不直接共享敏銳用戶數據的情況下,在多個設備(例如,智慧手機)上訓練共享模型。
-
方法:
-
本地訓練: 每個設備在其自身數據上訓練本地模型。
-
參數聚合: 設備將模型更新(梯度或參數)發送至中心服務器。
-
全局模型更新: 服務器聚合更新,優化全局模型,并将更新后的模型发回给设备。
-
代碼示例(使用Python和PyTorch的概念性):
import torch
import torch.nn as nn
import torch.optim as optim
# ...(設備與伺服器之間的通信代碼 - 未顯示)...
class SimpleModel(nn.Module):
# ...(在這裡定義你的模型架構)...
# 設備端訓練功能
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # 從全局模型開始
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ...(在device_data上訓練local_model)...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# 伺服器端聚合功能
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ...(主要的聯邦學習迴圈 - 簡化)...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

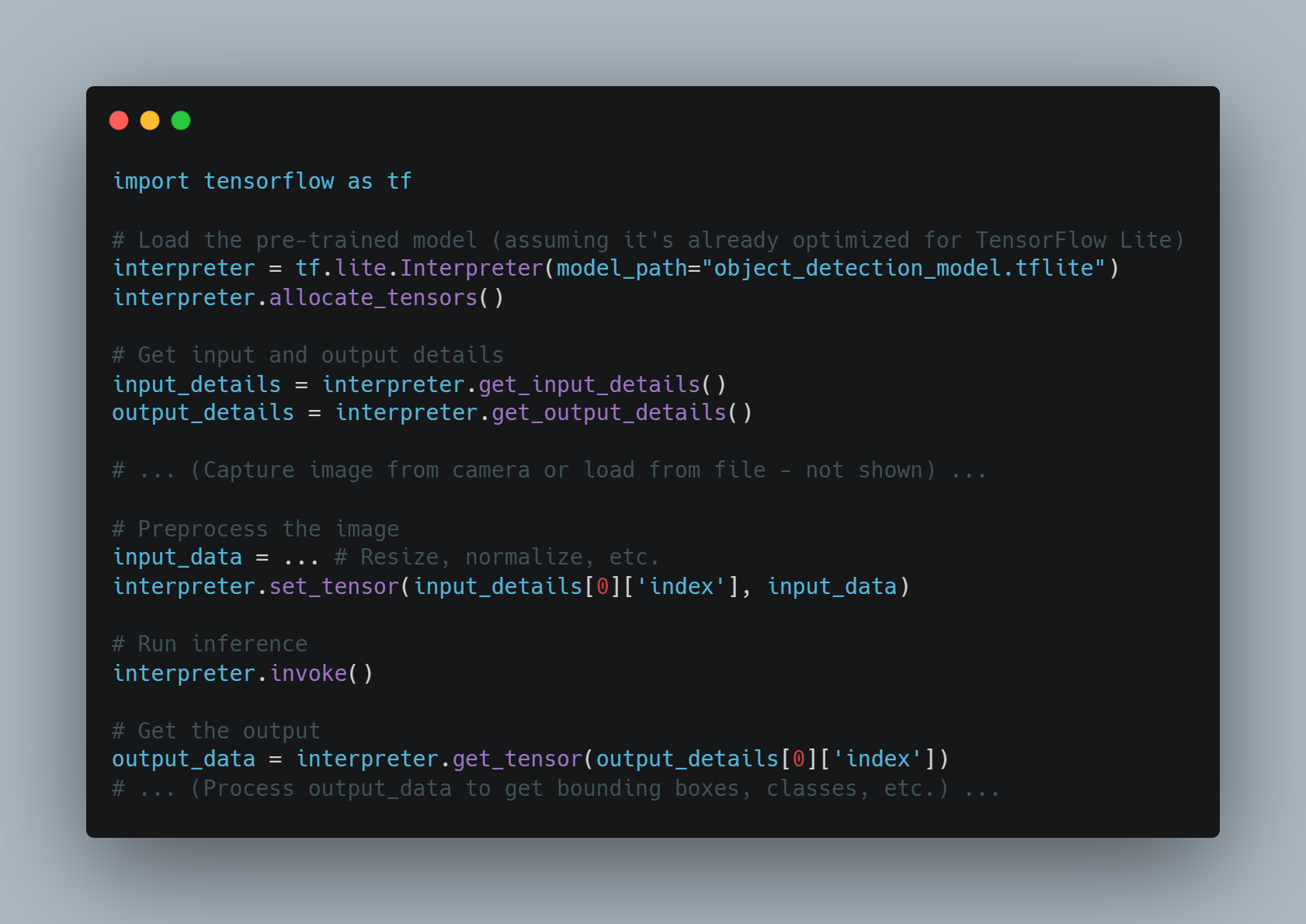
示例2:邊緣設備上的實時物件檢測
-
目標: 在資源受限的設備上部署物件檢測模型(例如,Raspberry Pi),以進行實時推理。
-
方法:
-
模型優化: 使用如模型量化或修剪等技術來減少模型大小和計算需求。
-
邊緣部署: 將優化後的模型部署到邊緣設備。
-
本地主體侦測: 設備在本地上進行物件偵測,減少延遲和对雲通信的依賴。
-
代碼示例 (概念性使用Python和TensorFlow Lite):
import tensorflow as tf
# 載入預訓練模型(假設它已經為TensorFlow Lite進行了優化)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# 獲取輸入和輸出詳細信息
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (從相机捕获影像或從文件上加載 - 未顯示) ...
# 預處理影像
input_data = ... # 縮放、標準化等
interpreter.set_tensor(input_details[0]['index'], input_data)
# 進行推理
interpreter.invoke()
# 獲取輸出
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (處理 output_data 以獲取邊界框、類別等) ...
挑戰和考慮因素:
-
通信開銷: 高效地協調和通信對於分布式節點是關鍵。
-
資源管理: 跨設備優化資源分配(CPU、記憶體、帶寬)是重要的。
-
安全性: 保護 分佈式系統的安全和數據隱私是首要關注的問題。
分佈式人工智能和边缘計算是建构可擴展、高效且注重隱私的 AI 系統的關鍵,特別是當我們朝着数十億個互相連接的設備未來迈进時。
自然語言處理的進步
自然語言處理(NLP)繼續是 AI 進步的前沿,推動了机器如何理解、生成和與人類語言互動的顯著改善。
近來 NLP 的發展,如變壓器(transformers)和注意力機制(attention mechanisms)的演進,已顯著提升了 AI 處理複雜語言結構的能力,使互動更加自然和上下文意識。
這一口頭使得 AI 系統能夠理解细微末節、情緒,甚至是文本中的文化參考,從而導致通信更加準確和有意义。
例如,在客戶服務方面,进階的 NLP 模型的不僅能精準地處理查詢,還能從客戶那裡檢測到情緒的信號,使 responses 更加共鳴和有效。
向前看,NLP 模型的多語言功能和更深入的语义理解的整合将进一步扩大其适用性,使得跨不同語言和方言的通信无缝进行,甚至使 AI 系统能够在多元的全球环境中作为实时翻译器服务。
自然语言处理(NLP)正在迅速发展,变压器模型和注意力机制等领域的突破。以下是这些进步的一些示例和代码片段:
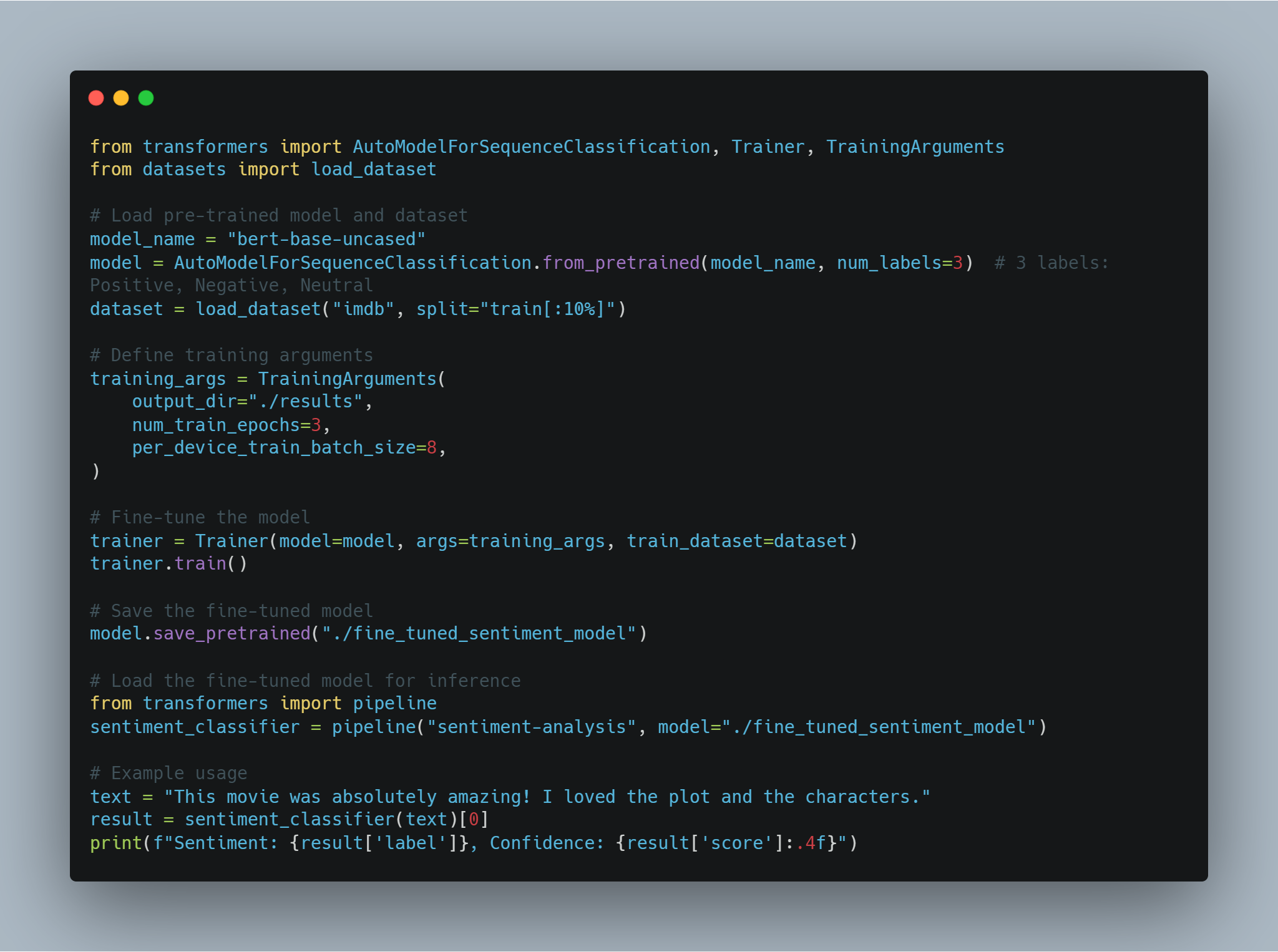
NLP示例1:使用微調的變压器進行情感分析
-
目標:以高精度分析文本情感,捕捉细微差别和语境。
-
方法:在情感分析数据集上微調预训练的變压器模型(如BERT)。
Python代碼示例(使用Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 加载预训练模型和数据集
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3个标签:正面、负面、中性
dataset = load_dataset("imdb", split="train[:10%]")
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# 微調模型
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# 保存微調后的模型
model.save_pretrained("./fine_tuned_sentiment_model")
# 加载微調后的模型进行推理
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# 示例用法
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
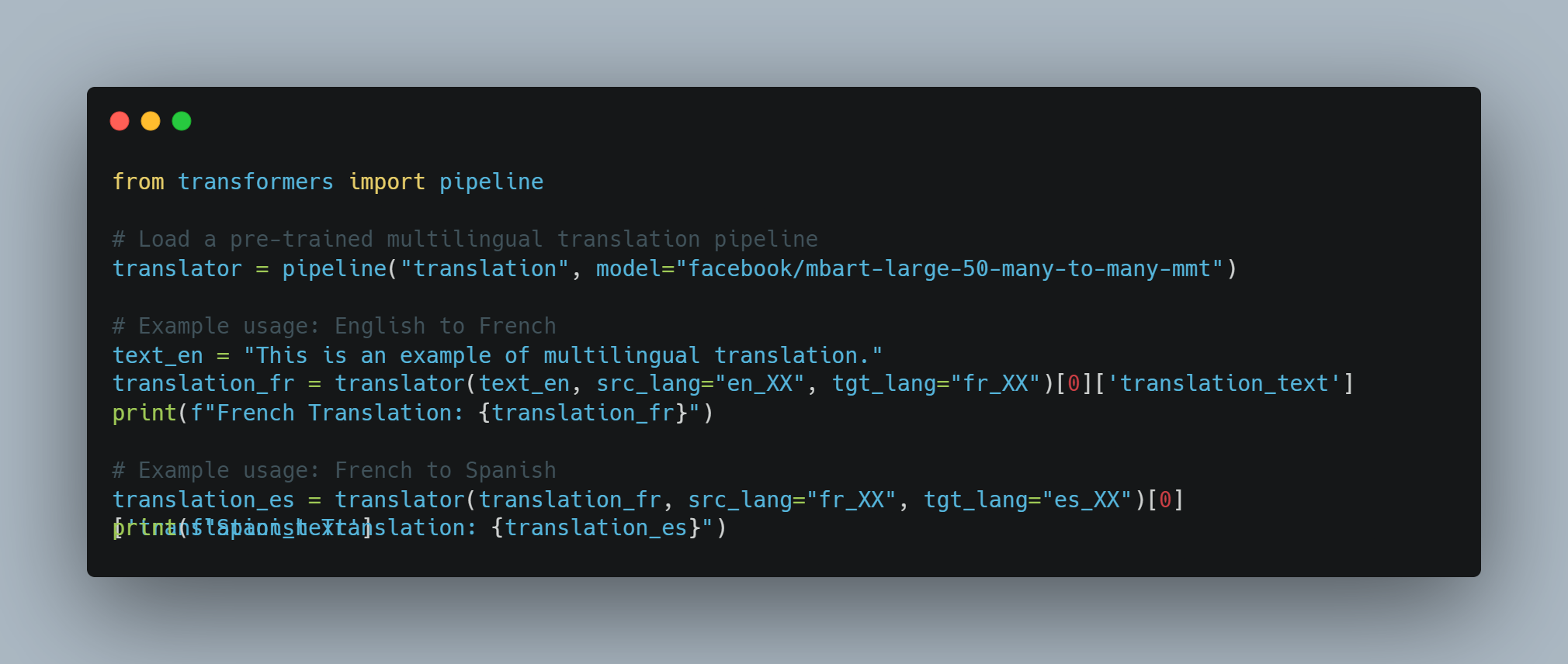
NLP示例2:使用单个模型进行多语言机器翻译
-
目标:使用单个模型进行多语言翻译,利用共享的语言表示。
-
方法:
使用大型、多语言的变压器模型(如 mBART 或 XLM-R),該模型已在多種語言的巨量平行文本數據集上進行訓練。
代码示例(使用 Python 和 Hugging Face Transformers):
from transformers import pipeline
# 加载一个预训练的多语言翻译管道
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# 示例使用:英语到法语
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# 示例使用:法语到西班牙语
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
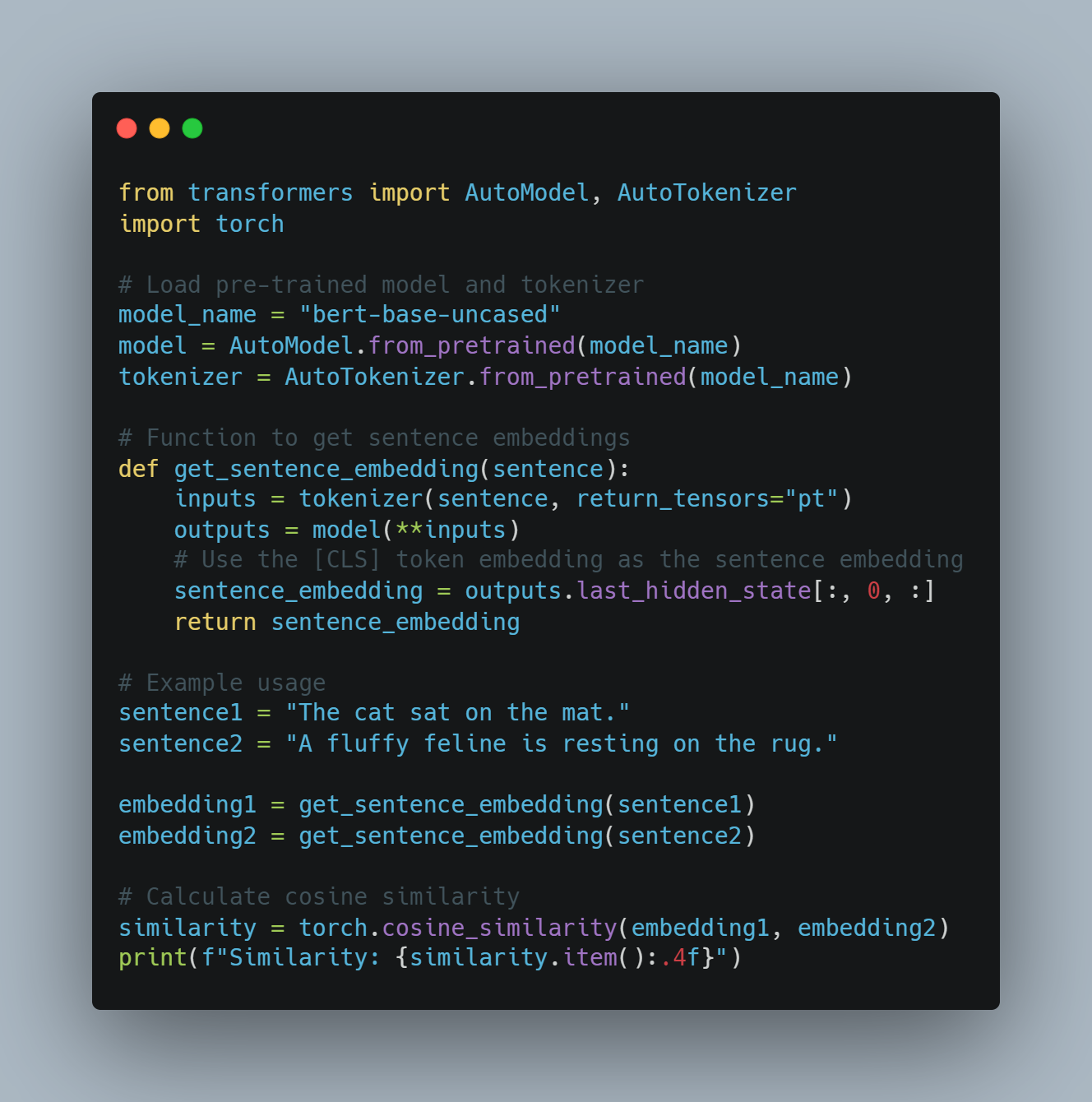
NLP 示例 3:语境词嵌入用于语义相似性
-
目标: 考虑上下文确定单词或句子的相似性。
-
方法: 使用变压器模型(如 BERT)生成上下文词嵌入,这些嵌入捕获特定句子中单词的意义。
代码示例(使用 Python 和 Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# 載入預訓練模型和分詞器
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 獲取句子嵌入的函數
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# 使用[CLS] tokens嵌入作為句子嵌入
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# 示例使用
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# 計算余弦相似度
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
挑戰與未來方向:
-
偏見與公正: NLP模型可能會從其訓練數據中繼承偏見,導致不公或歧視性結果。解決偏見至關重要。
-
常識推理: LLMs仍然在常識推理和理解潛在信息上遇到困難。
-
解釋性: 複雜的NLP模型的決策過程可能是不透明的,使得難以理解它們為什麼会产生某些輸出。
面對這些挑戰,自然語言處理(NLP)仍在快速進步。多模態信息的整合、常識推理的進步和解釋能力的提升是正在進行的研究關鍵領域,將進一步革新人工智能與人類語言的互動方式。
个性化AI助手
个性化AI助手的未來將變得越來越複雜,不僅僅是基礎任務管理,而是真正直覺、主动地根據個人需求提供支持。
這些助手將利用先進的機器學習算法,不斷地從你的行為、偏好和例行活动中學習,提供 increasingly 个性化推荐並自動化更複雜的任务。
例如,一個个性化AI助手不僅可以管理你的日程,還可以通過建議相關資源或根據你的情緒或過去偏好調整你的環境來預測你的需求。
隨著AI助手 increasingly 融入日常生活,它們在適應不斷变化的背景并提供无缝、跨平台支持的能力將成為关键區分因素。挑戰在于平衡个性化與隱私,需要強大的數據保護机制,以确保敏感信息被安全地管理同時還能提供深度个性化體驗。
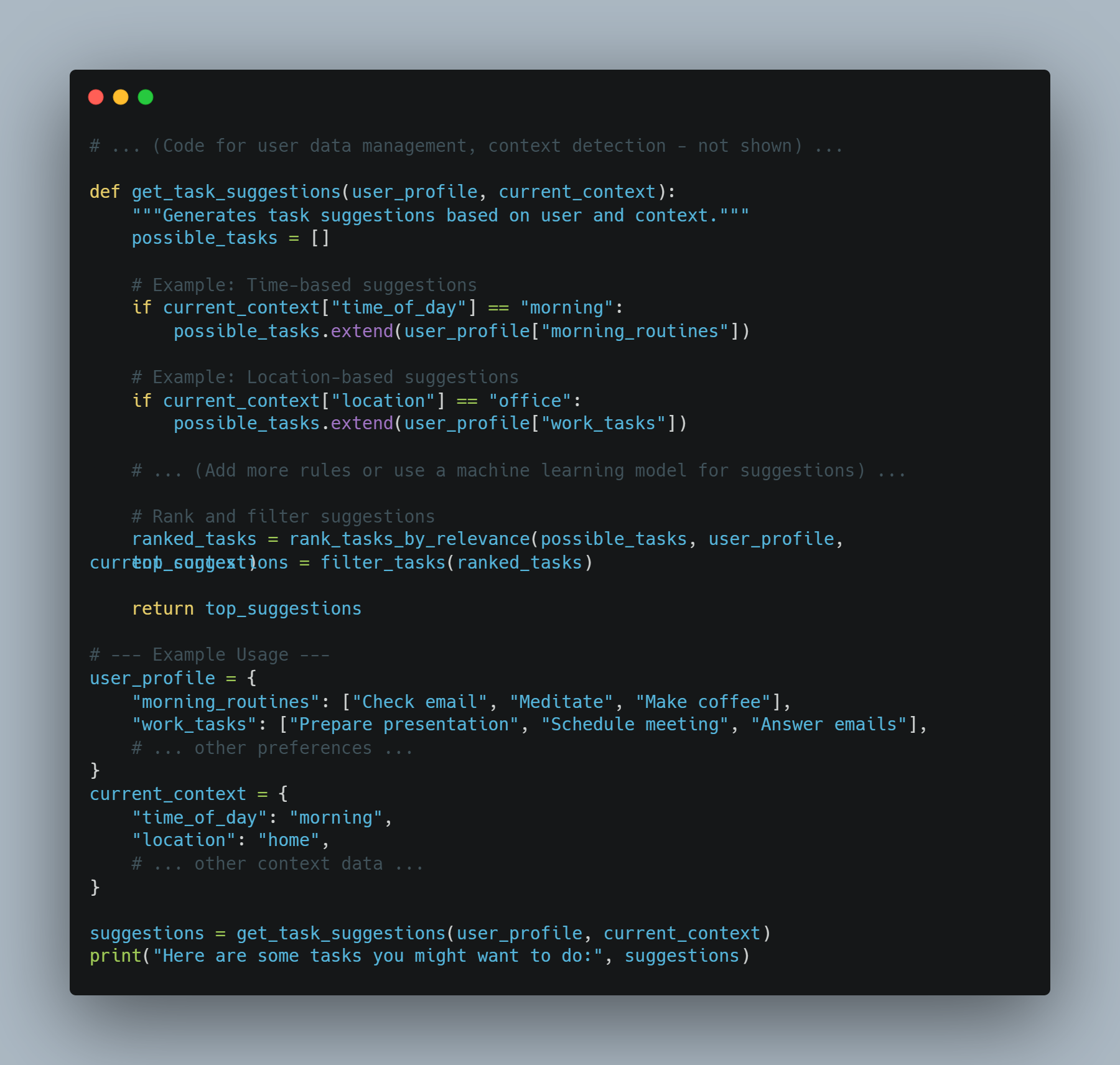
AI助手示例1:情境感知任務建議
-
目標:一個根據用戶當前情境(位置、時間、過去行為)建議任務的助手。
-
方法:結合用戶數據、背景信號和任務推薦模型。
程式示例(概念性 Python 程式碼):
# ... (用戶數據管理、背景检测的程式碼 - 未展示) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# 示例: 基於時間的建議
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# 示例: 基於位置的建議
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (增加更多規則或使用機器學習模型進行建議) ...
# 對建議進行排名和過濾
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- 示例使用 ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... 其它偏好 ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... 其它背景數據 ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
AI 助手示例 2: 積極的資訊傳達
-
目標:一個積極地根據用戶的时间表和偏好提供相關信息的助手。
-
方法:整合日曆數據、用戶興趣和內容捞取系統。
Python 代碼示例(概念性使用 Python):
# ... (日曆訪問、用戶興趣剖面 - 未展示) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (捞取公司資訊、參與者檔案等) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (捞取航班状态、目的地等信息) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- 示例使用 ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... 其它偏好 ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

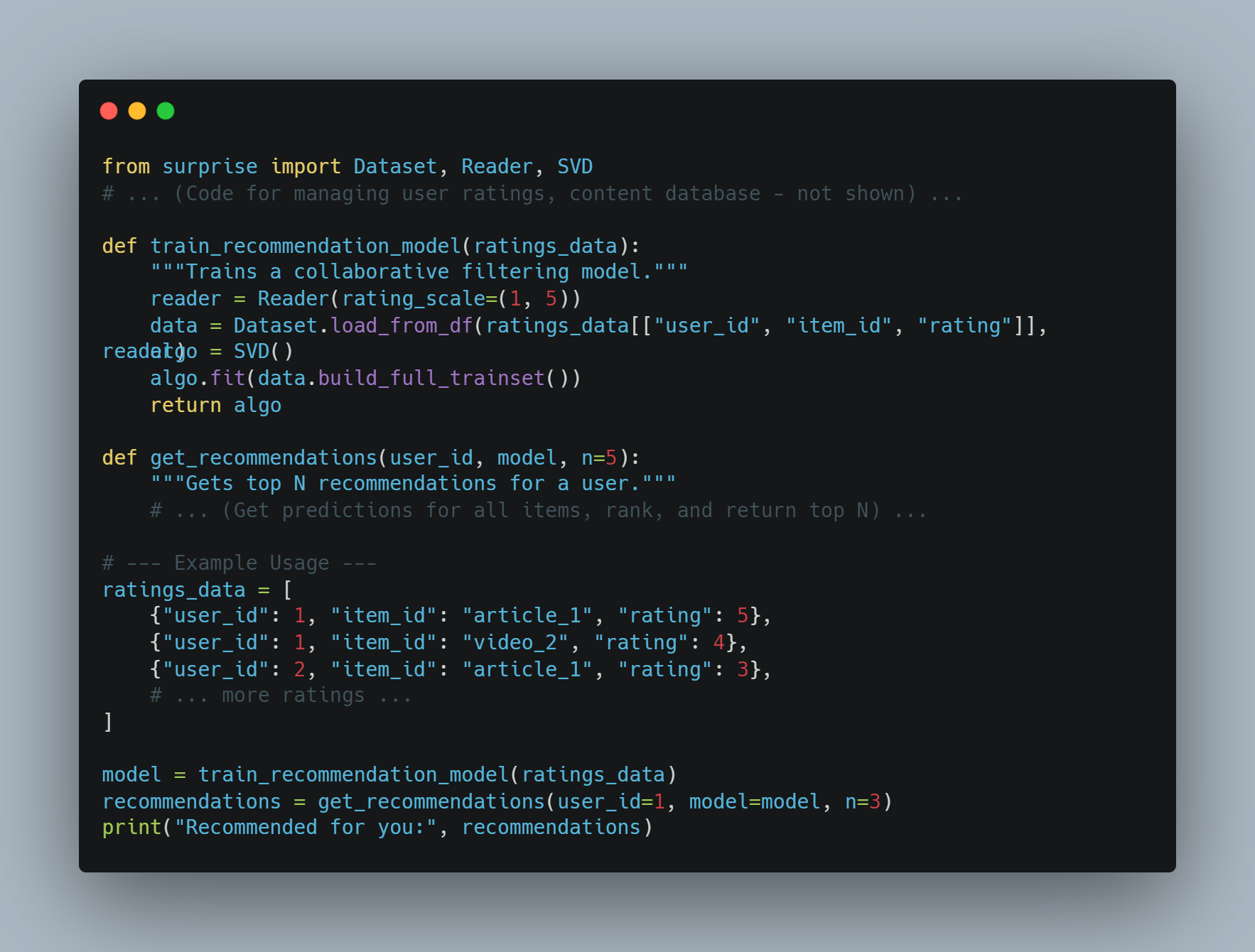
AI 助手示例 3: 個人化內容推薦
-
目標: 一個根據用戶偏好推薦內容(文章、影片、音樂)的助手。
-
方法: 使用协同過濾或基於內容的推薦系統。
Python 代碼示例(概念性使用 Python 及類似 Surprise 的庫):
from surprise import Dataset, Reader, SVD
# ... (用戶評分、內容數據庫管理代碼 - 未展示) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (為所有項目獲取預測、排名並返回前N個) ...
# --- 使用示例 ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... 更多的評分 ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
挑戰與倫理考慮:
-
數據隱私:負責任及透明地處理用戶數據非常關鍵。
-
偏見與公正:个性化不應擴大既有的偏見。
-
用戶控制:用戶應有权控制其數據及个性化設定。
建立个性化AI助手需要仔細考慮技術和倫理方面,以創造有益、值得信賴且尊重用戶隱私的系統。
創意思維產業中的AI
AI正在積極打入創意思維產業,改變藝術、音樂、電影和文學的生產與消費方式。隨著生成模型的進步,如生成對抗網絡(GANs)和變压器基礎模型的應用,AI如今能夠生成與人類創造力不相上下的內容。
進行創意音樂作曲、模擬著名畫家風格的數位藝術創作,甚至為電影和小說編寫劇情梗概。
在廣告業界,AI 被用來生成與個別消費者產生共鳴的個性化內容,以提升參與度和效果。
但 AI 在創意領域的崛起也引發了關於作者權、原創性和人類創造力作用的問題。當您在這些領域與 AI 互動時,探索 AI 如何與人類創造力相輔相成而非取而代之將至關重要,通過人機合作產生創新和有影響力的內容。
以下是 GPT-4 如何被整合到 Python 專案中用於創意任務的例子,特別是在寫作領域。這段代碼演示了如何利用 GPT-4 的功能生成創意文本格式,如詩歌。
import openai
# 設定您的 OpenAI API 金鑰
openai.api_key = "YOUR_API_KEY"
# 定義一個生成詩歌的函數
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# 使用範例
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
讓我們看看這裡發生了什麼:
-
導入 OpenAI 圖書館: 代碼首先導入
openai圖書館以訪問 OpenAI API。 -
設定 API 金鑰: 將
"YOUR_API_KEY"替換為您實際的 OpenAI API 金鑰。 -
定義
generate_poetry函數:此函數接收詩的topic和style作為輸入並使用 OpenAI 的 ChatCompletion API 來生成詩。 -
構造提示:提示將
topic和style結合成一個清晰的指示給 GPT-4。 -
將提示發送給 GPT-4:程式碼使用
openai.ChatCompletion.create將提示發送給 GPT-4 並將生成的詩作為回應接收。 -
回傳詩:然後從回應中提取生成的詩並由函數返回。
-
示例用法:該代码展示了如何使用特定主题和风格调用
generate_poetry函數。生成的詩然後打印到控制台。
AI驱动的虛擬世界
AI驱动的虛擬世界代表了沉浸式體驗的重大跃進,其中AI代理可以創造、管理並演進 interactives 和 responsive 的虛擬環境。
這些由AI驅動的虛擬世界可以模擬複雜的生態系統、社會互動和动态叙事情節,為用戶提供 deeply engaging 和 personalized 的體驗。
例如,在遊戲行業中,AI可以用來創造 learn from player behavior 的非玩家人數(NPCs),他們的行為和策略會根據玩家的表現進行調整,以提供更有挑戰性和realistic 的體驗。
超出遊戲范畴,AI驱动的虛擬世界在教育領域也有潛在的應用,其中虛擬课堂可以根据學生的學習風格和進度進行定制,或者在企業培訓中, realistic 的模擬可以準備員工应对各种情况。
這些虛擬環境的未來將取決於AI在real-time generate and manage vast, complex digital ecosystems 的能力提升,以及围绕用戶數據和高度沉浸式體驗的心理学影響的伦理考慮。
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# 初始化代理
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# 在环境中分配随机位置
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# 创建并添加代理
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# 移动代理(為示例簡化的移動)
for agent in self.agents:
agent.move(self.environment)
# 待办:為互動、環境變動等實現更複雜的邏輯
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# 確定移動方向(本例中為隨機)
direction = random.choice(['N', 'S', 'E', 'W'])
# 根據方向應用移動
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# 更新環境以反映代理的新位置
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# 示例使用
if __name__ == "__main__":
# 定義世界參數
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# 創建虛擬世界
world = VirtualWorld(environment_size, agent_types, agent_properties)
# 為數步驟仿真世界
for _ in range(10):
world.update()
world.display()
print() # 加入空行以提高可讀性
以下是这段代码所做的事情:
-
虛擬世界類別:
-
定義虛擬世界的核心。
-
包含環境格网、代理清單以及代理人相關資訊。
-
__init__(): 根據大小、代理人型態與屬性初始化世界。 -
add_agent(): 向世界中添加指定型態的新代理人。 -
update(): 對世界進行單一時間步長的更新。- 目前僅移動代理人,但您可以添加複雜的代理人相互作用、環境變化等邏輯。
-
display(): 列印環境的基本表示。
-
-
代理類:
-
代表世界中的個體代理。
-
__init__():用代理的類型、位置和屬性來初始化代理。 -
move():處理代理的移動,更新其在環境中的位置。此方法目前提供簡單的隨機移動,但可以擴展以包括複雜的人工智能行為。
-
-
用法示例:
-
設定世界参数如大小、代理类型及其属性。
-
建立一個 VirtualWorld 物件。
-
多次執行
update()方法以模擬世界的演變。 -
每次更新後呼叫
display()以視覺化變化。
-
提升:
-
更複雜的代理 AI:為代理行為實現更複雜的 AI。您可以使用:
-
路径尋找算法:幫助代理有效地在台环境中導航。
-
決策樹/機器學習:讓代理根據其周圍環境和目標做出更聪明的決策。
-
強化學習:教導代理随時間学习和适应其行为。
-
-
環境互動:為環境添加更多动态元素,如障碍物、資源或興趣點。
-
代理間互動:實現代理之間的互動,如通信、戰鬥或合作。
-
視覺表示:使用Pygame或Tkinter等庫創建虛擬世界的視覺表示。
這個例子是創建一個由 AI 驅動的虛擬世界的基本基礎。複雜性和 sophistication 程度可以進一步擴展,以符合您的特定需求和創造目標。
類神经計算和 AI
類神经計算,由人腦的結構和功能靈感而來,準備革新一種有效且並行處理信息的 AI 方法。
與傳統計算結構不同,類神经系統設計來模擬大腦的神經網絡,使 AI 能以更快的速度和更高的能效執行诸如模式識別、感觀處理和決策制定的任務。
這種技術為開發能更具適應性、從少量數據中學習並有效率地在實時環境中運作的 AI 系統展現了巨大前景。
例如,在机器人技術中,類神经積體可能使机器人以current architectures 無法比拟的效率和速度處理感觀輸入和作出決策。
未來的挑戰將是將類神经計算擴展以處理大規模 AI 應用程序的複雜性,並將其與現有的 AI 框架結合以充分利用其潛力。
太空探索中的 AI 代理商
AI agents are increasingly playing a crucial role in space exploration, where they are tasked with navigating harsh environments, making real-time decisions, and conducting scientific experiments autonomously.
随着任务 venture further into deep space,對 AI 系統的 needs 變得更加迫切,使其能夠在不受地球控制的情况下独立操作。未來的 AI 代理將被設計來處理太空的不可预見性,例如未預期的障碍、任務參數的變化,或是自我修復的需求。
例如,AI 可以用來指導火星探測車 autonomous exploration, identifies scientifically valuable sites,甚至 minimal input from mission control。這些 AI 代理還可以管理長期任务的生命支持系統, optimize energy usage,並适应宇航员的 psychological needs,提供陪伴和心理刺激。
AI 在太空探索中的整合不僅增强了任務能力,也开辟了人類探索宇宙的新可能性,在這個過程中,AI 將成为理解我們宇宙的不可或缺的伙伴。
Chapter 8: AI Agents in Mission-Critical Fields
Healthcare
在醫療保健領域,AI 代理不僅是支持角色,而且正在成為整個病人照顧 continuum 的核心部分。其在 telemedicine 的影響最為明顯,AI 系統已重新定義了遠距醫療照護的 approach。
通过使用進階的自然語言處理(NLP)和機器學習算法,這些系統執行诸如症狀分院和初步數據收集等複雜任務,精度非常高。它們實時分析病人報告的症狀和醫療歷史,將這些資訊與廣泛的醫療數據庫交叉對照以識別潛在的症狀或警戒信号。
這讓醫療提供者能更快地做出明智的決定,減少治療時間,有潛在拯救生命。此外, medical imaging 的 AI-driven diagnostic tools 正在改變放射科,通過在 X-rays、MRIs 和 CT scans 中侦測到模式和異常,這些可能對人眼不可見。
這些系統在包括數百萬個註釋圖像的大型數據集中進行訓練,使它們不僅能夠複製,而且通常超越了人類診斷能力。
AI 融入醫療 also 延伸到行政任務,其中自動化任命排程、藥物提醒和病人跟進顯著減少了醫療人員的操作負擔,讓他們能把更多focus on 病人照护的更重要方面。
財務
在財務領域,AI 代理人通過引入前所未有的效率和精度,改變了操作。
仰賴 AI 的算法交易已改變財務市場中交易的執行方式。
這些系統能夠在毫秒级别分析大量數據集,識別市場趨勢,並在最優 moment 執行交易,以最大化利润和最小化風險。它們利用複雜的算法,這些算法包括機器學習、深度學習和強制學習技術,以適應不斷變化的市場環境,作出人類交易者無法匹敵的 Split-second 決策。
除了交易之外,AI 在風險管理方面扮演著關鍵角色,通過評估信用風險和 detect fraudulent activities 具有驚人的準確性。AI 模型使用預測分析來評估借用者的 default 可能性,通過分析信用歷史、交易行為和其他相關因素的模式。
另外,在法規遵循領域,AI 自動化交易監控,以 detect 和報告可疑活動,確保金融機構遵守嚴格的法規要求。這種自動化不僅減少了人類錯誤的風險,還簡化了遵從流程,降低了成本並提高了效率。
應急管理局
AI 在應急管理局的角色是革新性的,根本性地改變了危机的預測、管理和缓解方式。
在災難應對方面,AI 代理從多個來源(從衛星影像到社交媒體Feed)處理大量數據,以提供實時 comprehensive overview 的情况。機器學習算法分析這些數據以識別模式並預測事件的進程,使應急回應者能夠更有效地分配資源並在外壓下做出明智的決定。
在自然災害如颱風發生時,AI系統可以預測風暴的路徑和強度,使得當局能夠發布及時的撤離命令並將資源部署到最脆弱的地區。
在預測分析中,AI模型通過分析歷史數據與實時輸入,用於預測潛在的緊急狀況,從而實施主動措施以防止災害發生或減輕其影響。
AI驅動的公共通訊系統在確保準確及時的信息傳達給受影響的人群方面也發揮了關鍵作用。這些系統能夠生成並傳播緊急警報,跨多個平台傳達信息,根據不同人群特徵定制警報內容,確保理解和遵守。
AI還通過使用生成模型創建高度逼真的訓練模擬,提高緊急救援人員的準備程度。這些模擬複製了現實世界中緊急狀況的複雜性,讓救援人員能夠磨練技能,提高對實際事件的應對準備。
交通運輸
AI系統在交通運輸領域變得不可或缺,它們提高了安全、效率和可靠性,涵蓋了航空交通管制、自動駕駛車輛和公共交通等領域。
在航空交通管制中,AI代理在優化飛行路徑、預測潛在衝突和管理機場運營方面發揮了重要作用。這些系統利用預測分析預見潛在的航空交通瓶頸,並實時重新規劃飛行路線,以確保安全和效率。
在自動車的領域中,人工智慧是使車輛能處理感應器數據並在複雜環境中做出瞬間決策的core。這些系統使用在大量數據集上訓練深的學習模型來解釋視覺、聽覺和空間數據,使得在動態和不可預測的情況下安全導航。
公共交通系統也因人工智慧而受益,通過優化路线規劃、預測車輛維護和管理工作流。通過分析歷史和實時數據,人工智慧系統可以調整交通時間表、預測和防止車輛故障、及在尖峰時段管理人潮,從而提升交通網絡的整體效率和可靠度。
能源部門
人工智慧在能源 sector中发挥着重要作用,特别是在电网管理、可再生能源优化和故障检测。
在电网管理方面,人工智能代理通过分析分布在网络各处的传感器实时数据来监控和控制电力电网。这些系统利用预测性分析来优化能源分配,确保供应满足需求同时最小化能源浪费。人工智能模型还预测电网可能的故障,使得可以进行预防性维护并减少停电风险。
在可再生能源领域,人工智能系统被用来预测天气模式,这对于优化太阳能和风能生产是至关重要的。这些模型分析气象数据来预测阳光强度和风速,使得可以更准确地预测能源生产和更好地将可再生能源整合到电网中。
故障检测是人工智能作出重要貢獻的另一個領域。人工智能系統分析變壓器、渦輪機和發電機等設備的感應器數據,以識別磨損或潛在故障的迹象,before they lead to failures. 這種預測性維護方法不僅延長了設備的壽命,也確保了持續可靠 energy supply.
网络安全
在網絡安全領域,人工智能代理對於維護數字基礎設施的完整性和安全性至關重要。這些系統被設計用來不斷監控網絡流量,使用機器學習算法來檢測可能表示安全違規的異常。
通過實時分析大量數據,人工智能代理可以識別惡意行為的模式,例如異常登入嘗試、數據洩露活動或惡意軟件的存在。一旦檢測到潛在威脅,人工智能系統可以自動引發應對措施,例如隔離受影響的系統和部署修補程序,以防止進一步的損害。
漏洞評估是人工智能在网络安全中的另一個關鍵應用。由人工智能驅動的工具分析代碼和系統配置,以在攻擊者 exploit them before they can 之前識別潛在的安全弱點。這些工具使用靜態和動態分析技術來評估軟件和硬件部件的安全态势,為網絡安全團隊提供可行的洞見。
這些過程的自動化不僅提高了威脅侦測和應對的速度與準確性,還減少了人類分析師的工作負荷,讓他們能夠專注於更複雜的安全挑戰。
製造
在製造業中,人工智能正在推動質量控制、預測性維護和供應鏈優化等方面的顯著進步。由人工智能驅動的電腦視覺系統現在能夠以遠超人類能力的速度和準確性檢查產品缺陷。這些系統使用在数千張圖片上訓練深的學習算法來侦測產品中的最小瑕疵,確保在高產量生產環境中產品質量的一致性。
預測性維護是人工智能產生深远影響的另一個領域。通過分析嵌入在工作機械中的感測器數據,人工智能模型可以預測設備何時可能失效,使得維護工作可以在 breakdown 發生前安排。這種方法不僅減少停機時間,還延長了設備的壽命,導致顯著的成本節省。
在供應鏈管理中,人工智能代理通過分析整個供應鏈中的數據來優化庫存水平和物流,包括需求預測、生產計劃和運輸路徑。通過對庫存和物流計劃進行實時調整,人工智能確保生產過程平順進行,將延誤降到最低,並減少成本。
這些應用示範了人工智能在提高製造業操作效率和可靠性的關鍵作用,使其成為公司在快速變化的行業中保持競爭力的不可或缺工具。
結論
人工智慧代理與大型語言模型(LLMs)的整合標誌著人工智慧演進中的重要里程碑,開啟了跨越各個行業和科學領域的前所未有能力。這種協同作用增強了人工智慧系統的功能性、適應性和應用性,解決了LLMs的固有限制,並使決策過程更具動態性、上下文感知性和自主性。
從改革醫療保健和金融業到改變交通運輸和應急管理,人工智慧代理推動創新和效率,為AI技術深入融入我們日常生活的未來鋪平了道路。
隨著我們不斷探索人工智慧代理和LLMs的潛力,將它們的發展基於優先考慮人類福祉、公平和包容性的道德原則至關重要。通過確保這些技術被負責任地設計和部署,我們可以充分利用它們的潛力,改善生活質量,促進社會正義,應對全球挑戰。
人工智慧的未來在於先進人工智慧代理與複雜LLMs的無縫整合,創造出不僅能增強人類能力,而且還堅守我們人性價值的智能系統。
人工智慧代理和LLMs的融合代表著人工智慧中的一個新範式,敏捷和強大之間的協作打開了無限可能的領域。通過利用這種協同作用的力量,我們可以推動創新,推進科學發現,為所有人創造一個更加公平和繁榮的未來。
關於作者
我是Vahe Aslanyan,位在電腦科學、數據科學與人工智能的交界面。請造訪vaheaslanyan.com,看看一個证實精準與進步的個人投資組合。我的經驗横跨全站開發與人工智能產品優化,並由解決問題的新方法所驅動。
我的專業領域涵蓋创办領先的數據科學提速營和與業界頂尖專家合作,我的焦點仍然在於提升技術教育至 universial 標準。
如何能夠更深入學習?
在閱讀本指南後,如果您想要更深入了解,並且偏好有結構的學習方式,欢迎加入我們在LunarTech的學習,我們提供個別課程和數據科學、機器學習和人工智能提速營。
我們提供全面的課程,讓您深入了解理論、實作 Implementation、廣泛練習材料,並提供針對性的面試準備,讓您在各个階段準備成功。
您可以參加我們的終極數據科學训练营並加入免费試用,親身體驗內容。這已經獲得了2023年最佳數據科學训练营的評價,並被福布斯、雅虎、創業家等受人尊敬的媒體报导。這是您成為一個充滿創新和知識的社群的一部分的機會。以下是歡迎信息!
与我聯繫

關注我的领英,獲得大量的免费的電腦科學、機器學習和人工智能資源
-
訂閱我的數據科學與人工智慧通讯
如果你想要了解更多關於數據科學、機器學習和人工智慧的職業生涯,以及學習如何獲得一份數據科學工作,你可以下載這份免费的數據科學與人工智慧職業手冊。
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/