













Metaflow 是一個強大的框架,用於構建和管理數據工作流程。在本教程中,您將學習如何開始使用。具體來說,我們將涉及:
- 安裝過程
- 構建基本工作流程
- 核心概念
- 最佳實踐
在本文結束時,您將擁有有效簡化和擴展工作流程所需的技能!
什麼是 Metaflow?

來源: 為什麼選擇 Metaflow?
Metaflow 是一個旨在幫助管理數據科學項目的 Python 框架。Netflix 最初開發這個工具是為了提高數據科學家和機器學習工程師的生產力。它通過簡化複雜的任務來實現這一目標,例如工作流程編排,確保過程從開始到結束順利進行。
Metaflow 的主要特性包括自動數據版本控制,這可以追踪工作流程的變化,以及支持可擴展的工作流程,使得用戶能夠處理更大數據集和更複雜的任務。
Metaflow 的另一個優勢是它能輕鬆整合 AWS。這意味著用戶可以利用雲資源進行存儲和計算能力。此外,它友好的 Python API 使得初學者和有經驗的用戶都能輕鬆使用。
讓我們開始設置它。
設置 Metaflow
Metaflo 建議用戶為新項目安裝 Python 3,而不是 Python 2.7。文檔中指出:“Python 3 的錯誤更少,並且對已淘汰的 Python 2.7 的支持更好。”
下一步是創建一個虛擬環境來管理您的項目依賴。請運行以下命令來完成:
python -m venv venv source venv/bin/activate
這將創建並啟用虛擬環境。一旦啟用,您就可以安裝 Metaflow。
Metaflow 可作為 MacOS 和 Linux 的 Python 套件使用。 最新版本可以通過運行以下命令從 Metaflow Github 倉庫 或 PyPi 安裝:
pip install metaflow
不幸的是,在撰寫本文時,Metaflow 尚未為 Windows 用戶提供原生支持。不過,使用 Windows 10 的用戶可以使用 WSL(Windows 子系統 for Linux)來安裝 Metaflow,這使他們能夠在 Windows 操作系統內運行 Linux 環境。請查看 文檔,以獲取在 Windows 10 上安裝 Metaflow 的逐步指南。
AWS 整合(可選)
Metaflow 與 AWS 之間提供無縫整合,這讓用戶能夠利用雲端基礎設施擴展他們的工作流程。要整合 AWS,您需要設置您的 AWS 憑證。
注意:這些步驟假設您已經擁有 AWS 帳戶並安裝了 AWS CLI。詳細資訊, 請遵循 AWS 文件 的指示。
- 首先,通過運行以下命令安裝 AWS CLI:
pip install awscli
- 通過運行以下命令配置 AWS
aws configure
從這裡開始,您將被提示輸入您的 AWS 存取金鑰 ID 和密鑰存取金鑰—這些僅僅是 AWS CLI 用來驗證您對 AWS 請求的憑證。請注意,您也可能會被提示輸入您的地區和輸出格式。
一旦您輸入這些詳細信息,瞧!Metaflow 將自動使用您的 AWS 憑證來運行工作流程。
使用 Metaflow 建立您的第一個工作流程
現在 Metaflow 已經設置完成,是時候建立您的第一個工作流程。在這部分中,我將帶您了解創建流程、運行流程以及如何理解 Metaflow 中任務和步驟的組織方式的基本知識。
在這部分結束時,您將擁有一個處理數據並執行簡單操作的工作流程。讓我們開始吧!
Metaflow 流程概覽
Metaflow 使用 資料流範式,這種範式 將程式表示為操作的有向圖。這種方法非常適合建立資料處理管道,特別是在 機器學習 中。
在 Metaflow 中,操作的圖被稱為 流程。一個流程由一系列被拆分為步驟的任務組成。請注意,每個步驟可以被視為一個操作,表示為一個節點,步驟之間的過渡則作為圖的邊。
Metaflow 基本線性過渡 | 來源: Metaflow 文件
在 Metaflow 中,流程有幾個結構規則。例如,每個流程必須包含一個 開始 步驟和一個 結束 步驟。當一個流程執行時,稱為 運行,它從開始步驟開始,並且如果在沒有錯誤的情況下到達結束步驟,則被視為成功。
開始與結束之間發生的事情完全取決於你——正如你將在下一段中看到的。
撰寫你的第一個流程
這是一個簡單的流程,讓你開始使用。注意:該代碼可以在DataLab中運行。
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # 示例數據集 self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # 簡單數據處理 print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
在這個流程中:
start()步驟初始化工作流程並定義數據集。- 該
process_data()步驟通過將每個元素加倍來處理數據。 - 該
end()步驟完成流程。
每個步驟都使用 @step 裝飾器,您可以使用 self.next() 來定義流程順序並連接這些步驟。
運行您的流程
在編寫完您的流程後,將其保存為 my_first_flow.py。通過命令行運行它,使用:
py -m my_first_flow.py run
在 Metaflow 2.12 中新增了一個功能,使得用戶可以在筆記本中開發和執行流程。
要在指定的儲存格中執行流程,您只需在該儲存格的最後一行添加 NBRunner 的單行代碼。例如:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # 示例數據集 self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # 簡單數據處理 print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
如果您遇到以下錯誤:
“Metaflow 無法根據環境變數($USERNAME 等)確定您的用戶名”
在執行 Metaflow 之前,請將以下內容添加到您的代碼中:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
在這兩種情況下,Metaflow 將逐步執行流程。也就是說,它將在終端顯示每個步驟的輸出,如下所示:
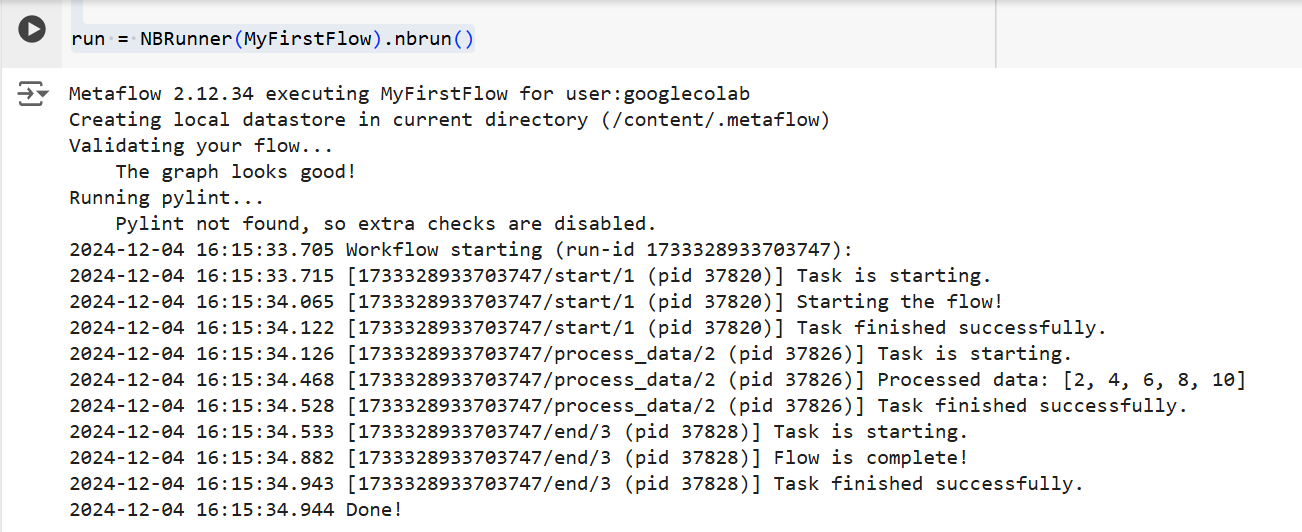
上述代碼的輸出 | 來源: 作者提供的圖片
Metaflow 的核心概念
理解 Metaflow 的核心概念對於構建高效且可擴展的數據工作流程至關重要。在本節中,我將介紹三個基本概念:
- 步驟與分支
- 數據工件
- 版本控制
這些元素構成了Metaflow結構和工作流程執行的骨幹,使您能夠輕鬆管理複雜的過程。
步驟和分支
我們在文章早些時候簡要提到過步驟,但為了清楚起見,我們將再次回顧它們。關於Metaflow工作流程,最重要的理解是它們是圍繞步驟構建的。
步驟代表工作流程中的每一個獨立任務。換句話說,每個步驟將執行特定的操作(例如數據加載、處理、建模等)。
我們在「寫你的第一個流程」中創建的示例是一個線性轉換。除了順序步驟,Metaflow 還使得用戶能夠 分支工作流程。分支工作流程允許你通過創建單獨的執行路徑來並行運行多個任務。
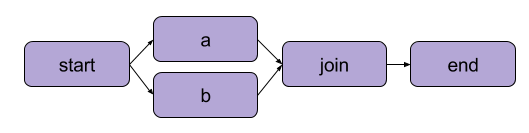
以下是分支的示例 | 來源:Metaflow 文檔
分支的主要好處是性能。分支意味著 Metaflow 可以在多個 CPU 核心或雲端實例上執行各種步驟。
以下是分支在代碼中的樣子:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # 範例資料集 self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # 分支 1 的程式碼 print("This is branch 1") self.next(self.join) @step def branch2(self): # 分支 2 的程式碼 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # 合併分支 print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡摘要:分支允許用戶設計複雜的工作流程,可以同時處理多個任務。 |
數據工件
數據 工件 是變數,允許您在工作流程的步驟之間存儲和傳遞數據。這些工件將一個步驟的輸出持久化到下一步——這就是數據如何為後續步驟提供可用性。
基本上,當你在 Metaflow 類別中的某個步驟裡將數據指派給 self 時,你將其保存為一個工件,然後這個工件可以被流程中的任何其他步驟訪問(請參見代碼中的註解)。
class ArtifactFlow(FlowSpec): @step def start(self): # 步驟 1:初始化數據 print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # 範例數據集作為工件保存 self.next(self.process_data) @step def process_data(self): # 步驟 2:處理來自 'start' 步驟的數據 self.processed_data = [x * 2 for x in self.data] # 處理工件數據 print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # 步驟 3:保存處理後的數據工件 self.results = sum(self.processed_data) # 將最終結果保存為工件 print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # 最終步驟 print("Flow is complete!") print(f"Final result: {self.results}") # 在最終步驟中訪問工件
為什麼工件是 Metaflow 的核心概念?因為它們有多種用途:
- 自動化數據流管理,消除手動加載和存儲數據的需求。
- 啟用持久性(稍後將詳細介紹),這意味著它們允許用戶使用客戶端 API 進行後續分析、使用卡片進行可視化,並在流程之間重用。
- 在本地和雲端環境之間保持一致性。這消除了明確數據傳輸的需求。
- 允許用戶在故障之前檢查數據,並在修復錯誤後恢復執行。
版本控制和持久性
Metaflow 自動處理 版本控制,以管理您的工作流程。這意味著每當執行一個流程時,它都會被追蹤為一個獨特的運行。換句話說,每次運行都有其自己的版本,讓您能夠輕鬆回顧和重現過去的運行。
Metaflow 通過為每次運行分配唯一的標識符並保留該執行的數據和工件來實現這一點。這種持久性確保了在運行之間不會丟失任何數據。過去的工作流程可以輕鬆地重新訪問和檢查,並且如有需要,可以重新運行特定步驟。因此,除錯和迭代開發變得更加高效,維持可重現性也變得簡單。
實用範例:訓練機器學習模型
在本節中,我將引導您使用 Metaflow 訓練機器學習模型。您將學習如何:
- 定義一個加載數據的工作流
- 訓練一個機器學習模型
- 跟蹤結果
到最後,您將更好地了解如何使用 Metaflow 來高效地結構化和運行機器學習工作流。讓我們開始吧!
首先,我們將創建一個基本的流程,該流程加載數據集、進行訓練並輸出模型的結果。
注意:該代碼可以在DataLab中運行。
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # 載入並拆分數據集 print("Loading data...") self.data = [1, 2, 3, 4, 5] # 替換為實際的數據載入邏輯 self.labels = [0, 1, 0, 1, 0] # 替換為標籤 self.next(self.train_model) @step def train_model(self): # 訓練一個簡單的模型(例如,線性回歸) print("Training the model...") self.model = sum(self.data) / len(self.data) # 替換為實際的模型訓練 print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # 最後一步 print("Training complete. Model ready for deployment!")f
在這段代碼中,我們定義了三個步驟:
start(): 載入並拆分數據集。在現實世界的場景中,您會從實際來源(例如,文件或數據庫)載入數據。train_model(): 模擬模型的訓練。在這裡,執行的是簡單的平均計算,而不是實際的機器學習算法,但您可以用任何您需要的訓練代碼來替換它。end():標誌著流程的結束,並表示模型已準備好進行部署。
一旦您定義了流程,您可以使用以下命令來運行它:
run = NBRunner(TrainModelFlow) run.nbrun()
請注意,此代碼僅在筆記本中有效(所有代碼必須在同一單元格中)。
如果您想將此代碼作為腳本運行,請移除NBRunner命令,並將以下內容附加到您的腳本末尾,然後保存(例如,“metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
然後,為了運行腳本,請導航到命令行並運行以下命令:
py -m metaflow_ml_model.py
Metaflow 自動追蹤每次運行並讓您通過 Metaflow UI 可視化結果。
使用 Metaflow 的最佳實踐
那麼,我們如何充分利用 Metaflow 的功能呢?以下是幾個最佳實踐,可以幫助您在優化工作流程的同時實現這一目標:
從小流開始
如果您是 Metaflow 的新手,建議您從簡單的工作流程開始,以便熟悉其 API。從小開始將幫助您理解框架的運作方式,並在進入更複雜的項目之前建立對其能力的信心。這種方法可以降低學習曲線,確保您的基礎穩固。
利用 Metaflow 的 UI 進行除錯
Metaflow 包含一個強大的使用者介面,這對於除錯和追蹤工作流程非常有幫助。使用 UI 來監控運行,檢查每個步驟的輸出,並識別可能出現的問題。可視化您的數據和日誌使得在執行流程期間更容易識別和修復問題。
利用 AWS 來擴展性
當您首次安裝 Metaflow 時,它會以本地模式運行。在此模式下,工件和元數據會保存在本地目錄中,計算則使用本地進程運行。這種設置適合個人使用,但如果您的項目涉及協作或大型數據集,建議配置 Metaflow 以利用 AWS 以獲得更好的擴展性。這裡的好處是 Metaflow 提供了與 AWS 的極佳整合。
結論
在本教程中,我們探討了如何開始使用 Metaflow,從安裝到構建您的第一個數據科學工作流程。我們涵蓋了核心概念,例如定義步驟、使用數據工件在步驟之間傳遞數據,以及版本控制以跟蹤和重現運行。我們還通過一個實際示例來演示訓練機器學習模型,展示了如何定義、運行和監控您的工作流程。最後,我們提到了幾些最佳實踐,以幫助您充分利用 Metaflow。
要繼續學習 MLOps,請查看以下資源: