













Metaflow is een krachtig framework voor het bouwen en beheren van datastromen. In deze tutorial leer je hoe je aan de slag kunt gaan. Namelijk, we zullen het hebben over:
- Het installatieproces
- Een basisworkflow bouwen
- Belangrijke concepten
- Beste praktijken
Aan het einde van dit artikel beschik je over de nodige vaardigheden om je workflows efficiënt te stroomlijnen en op te schalen!
Wat is Metaflow?

Bron: Waarom Metaflow?
Metaflow is een Python-framework dat is ontworpen om te helpen bij het beheren van data science-projecten. Netflix heeft het hulpmiddel oorspronkelijk ontwikkeld om data scientists en machine learning-engineers productiever te maken. Het bereikt dit doel door complexe taken te vereenvoudigen, zoals workflow-orchestratie, wat ervoor zorgt dat processen soepel verlopen van begin tot eind.
Belangrijke functies van Metaflow zijn automatische gegevensversiebeheer, dat veranderingen in je workflows bijhoudt, en ondersteuning voor schaalbare workflows, waarmee gebruikers grotere datasets en complexere taken kunnen verwerken.
Een ander voordeel van Metaflow is dat het gemakkelijk integreert met AWS. Dit betekent dat gebruikers cloudresources kunnen benutten voor opslag en rekenkracht. Bovendien maakt de gebruiksvriendelijke Python API het toegankelijk voor zowel beginners als ervaren gebruikers.
Laten we beginnen met het instellen.
Metaflow instellen
Metaflow raadt aan dat gebruikers Python 3 installeren in plaats van Python 2.7 voor nieuwe projecten. De documentatie stelt dat “Python 3 minder bugs heeft en beter wordt ondersteund dan de verouderde Python 2.7.”
De volgende stap is het creëren van een virtuele omgeving om je projectafhankelijkheden te beheren. Voer de volgende opdracht uit om dit te doen:
python -m venv venv source venv/bin/activate
Dit zal een virtuele omgeving creëren en activeren. Zodra deze is geactiveerd, ben je klaar om Metaflow te installeren.
Metaflow is beschikbaar als een Python-pakket voor MacOS en Linux. De nieuwste versie kan worden geïnstalleerd vanuit de Metaflow Github-repository of PyPi door de volgende opdracht uit te voeren:
pip install metaflow
Helaas biedt Metaflow op het moment van schrijven geen native ondersteuning voor Windows-gebruikers. Gebruikers met Windows 10 kunnen echter WSL (Windows Subsystem for Linux) gebruiken om Metaflow te installeren, waarmee ze een Linux-omgeving binnen hun Windows-besturingssysteem kunnen draaien. Bekijk de documentatie voor een stapsgewijze handleiding voor het installeren van Metaflow op Windows 10.
AWS-integratie (Optioneel)
Metaflow biedt naadloze integratie met AWS, waardoor gebruikers hun workflows kunnen schalen met behulp van cloudinfrastructuur. Om AWS te integreren, moet je je AWS-inloggegevens instellen.
Opmerking: Deze stappen gaan ervan uit dat je al een AWS-account hebt en de AWS CLI is geïnstalleerd. Voor meer details, volg de AWS-documentatie instructies.
- Installeer eerst de AWS CLI door het volgende uit te voeren:
pip install awscli
- Configureer AWS door het volgende uit te voeren
aws configure
Vanaf hier wordt u gevraagd uw AWS Access Key ID en Secret Access Key in te voeren—dit zijn simpelweg de inloggegevens die de AWS CLI gebruikt om uw verzoeken aan AWS te authenticeren. Houd er rekening mee dat u ook gevraagd kunt worden om uw regio en uitvoerformaat in te voeren.
Als u deze gegevens hebt ingevoerd, voila! Metaflow zal automatisch uw AWS-gegevens gebruiken om workflows uit te voeren.
Bouwen van uw eerste workflow met Metaflow
Nu Metaflow is ingesteld, is het tijd om uw eerste workflow te bouwen. In dit gedeelte zal ik u begeleiden door de basisprincipes van het maken van een flow, het uitvoeren ervan en het begrijpen van hoe taken en stappen zijn georganiseerd in Metaflow.
Aan het einde van dit gedeelte zult u een workflow hebben die gegevens verwerkt en eenvoudige bewerkingen uitvoert. Laten we beginnen!
Overzicht van een Metaflow-flow
Metaflow maakt gebruik van het dataflow-paradigma, dat een programma weergeeft als een gerichte grafiek van bewerkingen. Deze aanpak is ideaal voor het bouwen van datapijplijnen, vooral in machine learning.
In Metaflow wordt de grafiek van bewerkingen een flowgenoemd. Een flow bestaat uit een reeks taken die zijn opgedeeld in stappen. Merk op dat elke stap kan worden beschouwd als een bewerking die wordt weergegeven als een knooppunt, met overgangen tussen stappen die fungeren als de randen van de grafiek.
Een Metaflow basis lineaire overgang | Bron: Metaflow documentatie
Er zijn een paar structurele regels voor flows in Metaflow. Zo moet elke flow bijvoorbeeld een start stap en een end stap bevatten. Wanneer een flow wordt uitgevoerd, bekend als een run, begint deze met de start stap en wordt als succesvol beschouwd als de eindstap zonder fouten wordt bereikt.
Wat er gebeurt tussen de start- en eindstappen is volledig aan jou – zoals je in het volgende segment zult zien.
Je eerste flow schrijven
Hier is een eenvoudige flow om mee te beginnen.Opmerking: De code kan worden uitgevoerd in DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Voorbeeld dataset self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Eenvoudige dataverwerking print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
In deze flow:
- De
start()stap initialiseert de workflow en definieert een dataset. - De
process_data()stap verwerkt de gegevens door elk element te verdubbelen. - De
end()stap voltooit de stroom.
Elke stap gebruikt de @step decorator, en je definieert de volgorde van de stroom met self.next() om de stappen te verbinden.
Je stroom uitvoeren
Na het schrijven van je stroom, sla je het op als my_first_flow.py. Voer het uit vanuit de opdrachtregel met:
py -m my_first_flow.py run
Een nieuwe functie is toegevoegd in Metaflow 2.12 waarmee gebruikers stromen kunnen ontwikkelen en uitvoeren in notebooks.
Om een flow in een gedefinieerde cel uit te voeren, hoef je alleen maar de NBRunner one-liner op de laatste regel van dezelfde cel toe te voegen. Bijvoorbeeld:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Voorbeeld dataset self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Eenvoudige gegevensverwerking print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Als je de volgende foutmelding krijgt:
“Metaflow kon je gebruikersnaam niet bepalen op basis van omgevingsvariabelen ($USERNAME enz.)”
Voeg het volgende aan je code toe vóór de uitvoering van Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
In beide gevallen zal Metaflow de flow stap voor stap uitvoeren. Namelijk, het zal de output van elke stap in de terminal als volgt weergeven:
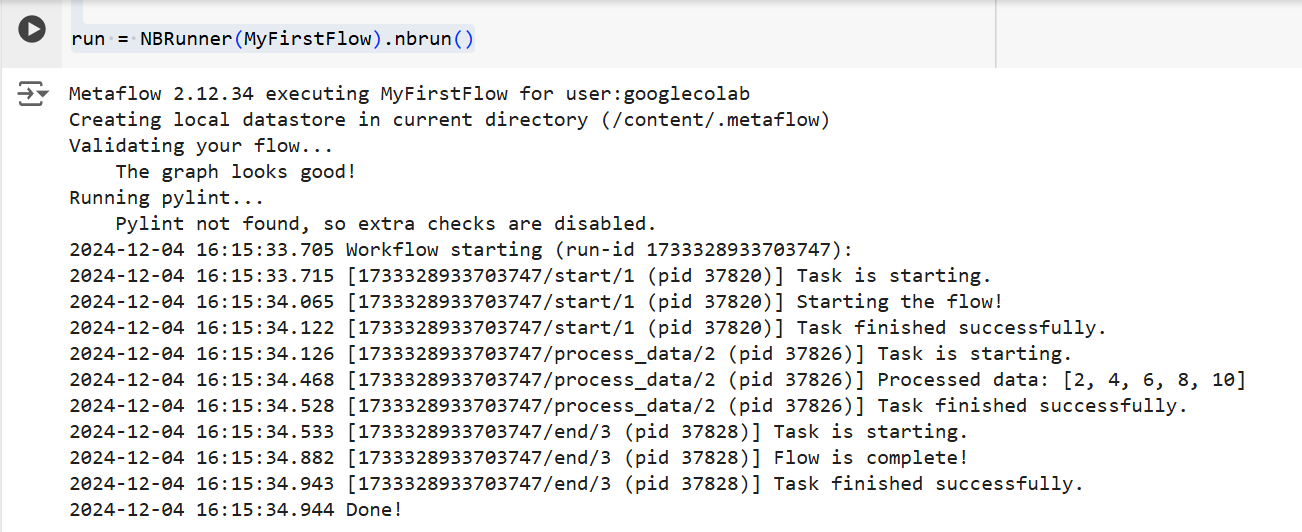
De output van de bovenstaande code | Bron: Afbeelding door auteur
Kernconcepten in Metaflow
Het begrijpen van de kernconcepten van Metaflow is essentieel voor het bouwen van efficiënte en schaalbare dataworkflows. In dit gedeelte behandel ik drie fundamentele concepten:
- Stappen en vertakking
- Data-artikelen
- Versiebeheer
Deze elementen vormen de ruggengraat van de structuur en uitvoering van workflows in Metaflow, waardoor je complexe processen eenvoudig kunt beheren.
Stappen en vertakkingen
We hebben eerder in het artikel kort stappen aangestipt, maar ter verduidelijking zullen we ze opnieuw bekijken. Het belangrijkste om te begrijpen over Metaflow-workflows is dat ze zijn opgebouwd rond stappen.
Stappen vertegenwoordigen elke individuele taak binnen een workflow. Met andere woorden, elke stap voert een specifieke operatie uit (bijv. gegevens laden, verwerken, modelleren, enz.).
Het voorbeeld dat we hierboven hebben gemaakt in “Uw eerste stroom schrijven” was een lineaire transformatie. Naast opeenvolgende stappen stelt Metaflow gebruikers ook in staat omtakken in workflows te maken. Tak workflows stellen u in staat om meerdere taken parallel uit te voeren door afzonderlijke paden voor uitvoering te creëren.
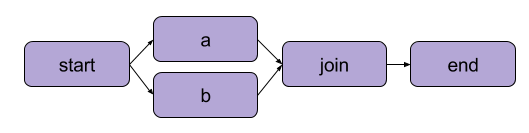
Een voorbeeld van vertakking | Bron: Metaflow-documentatie
Het belangrijkste voordeel van een tak is prestatie. Vertakken betekent dat Metaflow verschillende stappen kan uitvoeren over meerdere CPU-cores of instanties in de cloud.
Dit is hoe een tak eruit zou zien in code:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Voorbeeld dataset self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Code voor tak 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Code voor tak 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Takken samenvoegen print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡TLDR: Takken stellen gebruikers in staat om complexe workflows te ontwerpen die meerdere taken gelijktijdig kunnen verwerken. |
Data-artikelen
Data artikelen zijn variabelen waarmee je gegevens kunt opslaan en doorgeven tussen stappen in een workflow. Deze artikelen behouden de output van de ene stap naar de volgende – zo worden gegevens beschikbaar gemaakt voor daaropvolgende stappen.
In wezen, wanneer je gegevens toewijst aan self binnen een stap in een Metaflow-klasse, sla je het op als een artifact, dat vervolgens door elke andere stap in de flow kan worden benaderd (zie de opmerkingen in de code).
class ArtifactFlow(FlowSpec): @step def start(self): # Stap 1: Gegevens initialiseren print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Voorbeelddataset opgeslagen als een artifact self.next(self.process_data) @step def process_data(self): # Stap 2: Verwerken van de gegevens uit de 'start' stap self.processed_data = [x * 2 for x in self.data] # Verwerken van artifactgegevens print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Stap 3: Opslaan van de verwerkte gegevensartifact self.results = sum(self.processed_data) # Opslaan van het eindresultaat als een artifact print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Laatste stap print("Flow is complete!") print(f"Final result: {self.results}") # Toegang tot artifact in de laatste stap
Waarom zijn artifacts een kernconcept van Metaflow? Omdat ze een aantal toepassingen hebben:
- Automatiseren van gegevensstroombeheer, waardoor de noodzaak om handmatig gegevens te laden en op te slaan, wordt verwijderd.
- Het inschakelen van persistentie (meer hierover zo meteen), wat betekent dat ze gebruikers in staat stellen om later analyses uit te voeren met de Client API, te visualiseren met Kaarten, en herbruikbaar te zijn in verschillende flows.
- Consistentie tussen lokale en cloudomgevingen. Dit elimineert de noodzaak voor expliciete gegevensoverdrachten.
- Gebruikers in staat stellen om gegevens te inspecteren voordat er storingen optreden en de uitvoering te hervatten na het oplossen van bugs.
Versiebeheer en persistentie
Metaflow beheert automatisch versiebeheer voor je workflows. Dit betekent dat elke keer dat een flow wordt uitgevoerd, deze wordt geregistreerd als een unieke uitvoering. Met andere woorden, elke uitvoering heeft zijn eigen versie, waardoor je eenvoudig eerdere uitvoeringen kunt bekijken en reproduceren.
Metaflow doet dit door unieke identificatoren toe te wijzen aan elke uitvoering en de gegevens en artefacten van die uitvoering te behouden. Deze persistentie zorgt ervoor dat er geen gegevens verloren gaan tussen uitvoeringen. Eerdere workflows kunnen eenvoudig worden herzien en geïnspecteerd, en specifieke stappen kunnen indien nodig opnieuw worden uitgevoerd. Als gevolg hiervan is het debuggen en iteratieve ontwikkeling veel efficiënter, en het behouden van reproduceerbaarheid is vereenvoudigd.
Praktisch Voorbeeld: Een Machine Learning Model Trainen
In deze sectie zal ik je begeleiden bij het gebruik van Metaflow om een machine learning model te trainen. Je leert hoe je:
- Definieer een workflow die gegevens laadt
- Train een machine learning model
- Volg de resultaten
Aan het einde begrijp je beter hoe je Metaflow kunt gebruiken om machine learning workflows efficiënt te structureren en uit te voeren. Laten we beginnen!
Om te beginnen, zullen we een basisflow creëren die een dataset laadt, training uitvoert en de resultaten van het model output.
Opmerking: De code kan worden uitgevoerd in DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Laad en splits de dataset print("Loading data...") self.data = [1, 2, 3, 4, 5] # Vervang door de daadwerkelijke logica voor het laden van gegevens self.labels = [0, 1, 0, 1, 0] # Vervang door labels self.next(self.train_model) @step def train_model(self): # Trainen van een eenvoudig model (bijv. lineaire regressie) print("Training the model...") self.model = sum(self.data) / len(self.data) # Vervang door de daadwerkelijke modeltraining print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Laatste stap print("Training complete. Model ready for deployment!")f
In deze code definiëren we drie stappen:
start(): Laadt en splitst de dataset. In een realistisch scenario zou je gegevens laden vanuit een daadwerkelijke bron (bijv. een bestand of database).train_model(): Simuleert de training van een model. Hier wordt een eenvoudige gemiddelde berekening uitgevoerd in plaats van een daadwerkelijk machine learning-algoritme, maar je kunt dit vervangen door elke trainingscode die je nodig hebt.end(): Markeert het einde van de flow en geeft aan dat het model klaar is voor implementatie.
Als je de flow hebt gedefinieerd, kun je deze uitvoeren met de volgende opdracht:
run = NBRunner(TrainModelFlow) run.nbrun()
Let op dat deze code alleen werkt in notebooks (alle code moet in één cel staan).
Als je deze code als script wilt uitvoeren, verwijder dan de NBRunner opdrachten en voeg het volgende toe aan het einde van je script, en sla het op (bijv., “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Om het script uit te voeren, navigeer je naar de opdrachtregel en voer je de volgende opdracht uit:
py -m metaflow_ml_model.py
Metaflow volgt automatisch elke run en stelt je in staat om resultaten te visualiseren via de Metaflow UI.
Beste praktijken voor het gebruik van Metaflow
Hoe halen we het meeste uit de functies van Metaflow? Hier zijn enkele beste praktijken die je kunnen helpen deze prestatie te bereiken terwijl je tegelijkertijd je werkstromen optimaliseert:
Begin met kleine flows
Als je nieuw bent met Metaflow, begin dan met eenvoudige werkstromen om vertrouwd te raken met de API. Klein beginnen helpt je te begrijpen hoe het framework werkt en bouwt vertrouwen op in de mogelijkheden ervan voordat je verder gaat met complexere projecten. Deze aanpak verkort de leercurve en zorgt ervoor dat je basis stevig is.
Maak gebruik van de UI van Metaflow voor debugging
Metaflow bevat een krachtige gebruikersinterface die extreem nuttig kan zijn voor het debuggen en volgen van je workflows. Gebruik de UI om runs te monitoren, de outputs van individuele stappen te controleren en eventuele problemen te identificeren die zich kunnen voordoen. Het visualiseren van je gegevens en logs maakt het gemakkelijker om problemen te identificeren en op te lossen tijdens de uitvoering van je flow.
Maak gebruik van AWS voor schaalbaarheid
Wanneer je Metaflow voor het eerst installeert, werkt het in lokale modus. In deze modus worden artefacten en metadata opgeslagen in een lokale directory, en worden berekeningen uitgevoerd met behulp van lokale processen. Deze setup werkt goed voor persoonlijk gebruik, maar als je project samenwerking of grote datasets omvat, is het raadzaam om Metaflow te configureren om AWS te gebruiken voor betere schaalbaarheid. Het goede nieuws is dat Metaflow uitstekende integratie met AWS biedt.
Conclusie
In deze tutorial hebben we onderzocht hoe je aan de slag kunt met Metaflow, van installatie tot het bouwen van je eerste data science workflow. We hebben de kernconcepten behandeld, zoals het definiëren van stappen, het gebruiken van data-artikelen om gegevens tussen stappen door te geven, en versiebeheer om runs te volgen en te reproduceren. We hebben ook een praktisch voorbeeld doorgelopen van het trainen van een machine learning-model, dat liet zien hoe je je workflow kunt definiëren, uitvoeren en monitoren. Tot slot hebben we enkele best practices besproken om het meeste uit Metaflow te halen.
Om je kennis van MLOps voort te zetten, bekijk de volgende bronnen: