













Metaflow é uma poderosa estrutura para construir e gerenciar fluxos de trabalho de dados. Neste tutorial, você aprenderá como começar. Ou seja, abordaremos:
- O processo de instalação
- Construindo um fluxo de trabalho básico
- Conceitos fundamentais
- Melhores práticas
No final deste artigo, você terá as habilidades necessárias para otimizar e escalar seus fluxos de trabalho de forma eficiente!
O que é Metaflow?

Fonte: Por que Metaflow?
Metaflow é um framework em Python projetado para ajudar na gestão de projetos de ciência de dados. A Netflix desenvolveu inicialmente a ferramenta para ajudar cientistas de dados e engenheiros de machine learning a serem mais produtivos. Ela alcança esse objetivo simplificando tarefas complexas, como a orquestração de fluxos de trabalho, que garante que os processos ocorram de forma fluida do início ao fim.
Os principais recursos do Metaflow incluem versionamento automático de dados, que rastreia alterações em seus fluxos de trabalho, e suporte para fluxos de trabalho escaláveis, que permite aos usuários lidar com conjuntos de dados maiores e tarefas mais complexas.
Outra vantagem do Metaflow é que ele se integra facilmente com a AWS. Isso significa que os usuários podem aproveitar os recursos em nuvem para armazenamento e poder de computação. Além disso, sua API Python amigável a usuários torna-o acessível tanto para iniciantes quanto para usuários experientes.
Vamos começar a configurá-lo.
Configurando o Metaflow
O Metaflow sugere que os usuários instalem o Python 3 em vez do Python 2.7 para novos projetos. A documentação afirma que “o Python 3 tem menos bugs e é melhor suportado do que o Python 2.7, que está obsoleto.”
O próximo passo é criar um ambiente virtual para gerenciar as dependências do seu projeto. Execute o seguinte comando para fazer isso:
python -m venv venv source venv/bin/activate
Isso criará e ativará um ambiente virtual. Uma vez ativado, você está pronto para instalar o Metaflow.
O Metaflow está disponível como um pacote Python para MacOS e Linux. A versão mais recente pode ser instalada a partir do repositório do Metaflow no Github ou PyPi executando o seguinte comando:
pip install metaflow
Infelizmente, no momento da escrita, o Metaflow não oferece suporte nativo para usuários do Windows. No entanto, usuários com Windows 10 podem usar o WSL (Subsistema Windows para Linux) para instalar o Metaflow, o que permite que eles executem um ambiente Linux dentro do sistema operacional Windows. Veja a documentação para um guia passo a passo sobre como instalar o Metaflow no Windows 10.
Integração com AWS (Opcional)
O Metaflow oferece integração perfeita com a AWS, que permite aos usuários dimensionar seus fluxos de trabalho usando infraestrutura em nuvem. Para integrar a AWS, você precisará configurar suas credenciais da AWS.
Nota: Esses passos assumem que você já possui uma conta da AWS e o AWS CLI instalado. Para mais detalhes, siga as instruções da documentação da AWS.
- Primeiro, instale o AWS CLI executando:
pip install awscli
- Configure a AWS executando
aws configure
A partir daqui, você será solicitado a inserir sua AWS Access Key ID e Secret Access Key—esses são simplesmente as credenciais que o AWS CLI usa para autenticar suas solicitações ao AWS. Observe que você também pode ser solicitado a inserir sua região e formato de saída.
Depois de inserir esses detalhes, voilà! O Metaflow usará automaticamente suas credenciais da AWS para executar fluxos de trabalho.
Construindo Seu Primeiro Fluxo de Trabalho com Metaflow
Agora que o Metaflow está configurado, é hora de construir seu primeiro fluxo de trabalho. Nesta seção, vou guiá-lo pelos conceitos básicos de criação de um fluxo, executá-lo e entender como as tarefas e etapas são organizadas no Metaflow.
No final desta seção, você terá um fluxo de trabalho que processa dados e realiza operações simples. Vamos lá!
Visão Geral de um Fluxo do Metaflow
Metaflow usa o paradigma de fluxo de dados, que representa um programa como um grafo direcionado de operações. Essa abordagem é ideal para construir pipelines de processamento de dados, especialmente em aprendizado de máquina.
No Metaflow, o grafo de operações é chamado de fluxo. Um fluxo consiste em uma série de tarefas divididas em etapas. Note que cada etapa pode ser considerada uma operação representada como um nó com transições entre as etapas atuando como as arestas do grafo.
Uma transição linear básica do Metaflow | Fonte: Documentação do Metaflow
Existem algumas regras estruturais para fluxos no Metaflow. Por exemplo, todo fluxo deve incluir um início e um fim etapa. Quando um fluxo é executado, conhecido como um execução, ele começa com a etapa de início e é considerado bem-sucedido se chegar à etapa de fim sem erros.
O que acontece entre os passos de início e fim é totalmente com você – como você verá no próximo segmento.
Escrevendo seu primeiro fluxo
Aqui está um fluxo simples para começar. Nota: O código pode ser executado em DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de dados de exemplo self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Processamento de dados simples print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
Neste fluxo:
- O passo
start()inicializa o fluxo de trabalho e define um conjunto de dados. - A etapa
process_data()processa os dados dobrando cada elemento. - A etapa
end()completa o fluxo.
Cada etapa usa o decorador @step, e você define a sequência do fluxo usando self.next() para conectar as etapas.
Executando seu fluxo
Após escrever seu fluxo, salve-o como my_first_flow.py. Execute-o a partir da linha de comando usando:
py -m my_first_flow.py run
Um novo recurso foi adicionado no Metaflow 2.12 que permite aos usuários desenvolver e executar fluxos em notebooks.
Para executar um fluxo em uma célula definida, tudo o que você deve fazer é adicionar a linha única NBRunner na última linha da mesma célula. Por exemplo:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de dados de exemplo self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Processamento de dados simples print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Se você receber o seguinte erro:
“Metaflow não conseguiu determinar seu nome de usuário com base nas variáveis de ambiente ($USERNAME etc.)”
Adicione o seguinte ao seu código antes da execução do Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
Em ambos os casos, o Metaflow executará o fluxo passo a passo. Ou seja, ele exibirá a saída de cada etapa no terminal da seguinte forma:
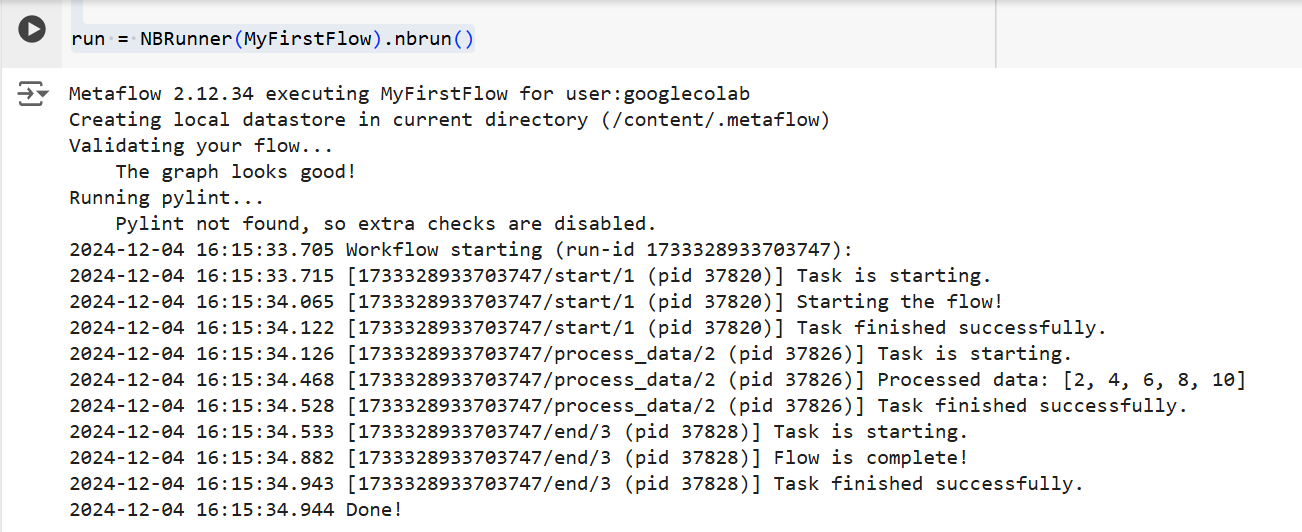
A saída do código acima | Fonte: Imagem do autor
Conceitos Principais no Metaflow
Entender os conceitos principais do Metaflow é essencial para construir fluxos de trabalho de dados eficientes e escaláveis. Nesta seção, abordarei três conceitos fundamentais:
- Etapas e ramificações
- Artefatos de dados
- Versionamento
Esses elementos formam a espinha dorsal da estrutura e execução dos fluxos de trabalho do Metaflow, permitindo que você gerencie processos complexos com facilidade.
Etapas e ramificação
Abordamos brevemente as etapas anteriormente no artigo, mas para maior clareza, vamos revisitá-las novamente. A coisa mais importante a entender sobre os fluxos de trabalho do Metaflow é que eles são construídos em torno de etapas.
As etapas representam cada tarefa individual dentro de um fluxo de trabalho. Em outras palavras, cada etapa realizará uma operação específica (por exemplo, carregamento de dados, processamento, modelagem, etc.).
O exemplo que criamos acima em “Escrevendo seu primeiro fluxo” foi uma transformação linear. Além de etapas sequenciais, o Metaflow também permite que os usuários dividam fluxos de trabalho. Fluxos de trabalho divididos permitem que você execute várias tarefas em paralelo, criando caminhos separados para a execução.
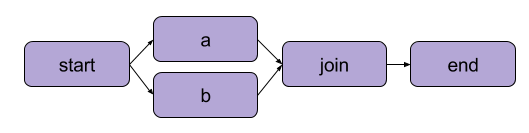
Um exemplo de divisão | Fonte: documentação do Metaflow
O principal benefício de uma divisão é o desempenho. Dividir significa que o Metaflow pode executar várias etapas em múltiplos núcleos de CPU ou instâncias na nuvem.
Aqui está como uma divisão pareceria no código:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Exemplo de conjunto de dados self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Código para o ramo 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Código para o ramo 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Unindo os ramos novamente print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡TLDR: O branching permite que os usuários projetem fluxos de trabalho complexos que podem processar várias tarefas simultaneamente. |
Artefatos de dados
Dados artefatos são variáveis que permitem armazenar e passar dados entre etapas em um fluxo de trabalho. Esses artefatos persistem a saída de uma etapa para a próxima—é assim que os dados são disponibilizados para etapas subsequentes.
Essencialmente, quando você atribui dados a self dentro de um passo em uma classe Metaflow, você os salva como um artefato, que pode ser acessado por qualquer outro passo no fluxo (veja os comentários no código).
class ArtifactFlow(FlowSpec): @step def start(self): # Passo 1: Inicializando dados print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de dados de exemplo salvo como um artefato self.next(self.process_data) @step def process_data(self): # Passo 2: Processando os dados do passo 'início' self.processed_data = [x * 2 for x in self.data] # Processando dados do artefato print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Passo 3: Salvando o artefato de dados processados self.results = sum(self.processed_data) # Salvando o resultado final como um artefato print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Passo final print("Flow is complete!") print(f"Final result: {self.results}") # Acessando artefato no passo final
Por que os artefatos são um conceito central do Metaflow? Porque eles têm uma série de usos:
- Automatizando o gerenciamento do fluxo de dados, eliminando a necessidade de carregar e armazenar dados manualmente.
- Habilitando persistência (mais sobre isso a seguir), o que significa que permite aos usuários realizar análises posteriormente com a API do Cliente, visualizar com Cartões e reutilizar em fluxos.
- Consistência entre ambientes locais e na nuvem. Isso elimina a necessidade de transferências de dados explícitas.
- Permitindo que os usuários inspecionem dados antes de falhas e retomem execuções após corrigir bugs.
Versionamento e persistência
O Metaflow gerencia automaticamente versionamento para seus fluxos de trabalho. Isso significa que cada vez que um fluxo é executado, ele é rastreado como uma execução única. Em outras palavras, cada execução tem sua própria versão, permitindo que você revise e reproduza facilmente execuções passadas.
O Metaflow faz isso atribuindo identificadores únicos a cada execução e preservando os dados e artefatos daquela execução. Essa persistência garante que nenhum dado seja perdido entre as execuções. Fluxos de trabalho passados podem ser facilmente revisitados e inspecionados, e etapas específicas podem ser reexecutadas, se necessário. Como resultado, a depuração e o desenvolvimento iterativo são muito mais eficientes, e a manutenção da reprodutibilidade é simplificada.
Exemplo Prático: Treinamento de um Modelo de Aprendizado de Máquina
Nesta seção, vou guiá-lo através do uso do Metaflow para treinar um modelo de aprendizado de máquina. Você aprenderá como:
- Defina um fluxo de trabalho que carrega dados
- Treine um modelo de aprendizado de máquina
- Acompanhe os resultados
No final, você entenderá melhor como usar o Metaflow para estruturar e executar fluxos de trabalho de aprendizado de máquina de forma eficiente. Vamos lá!
Para começar, criaremos um fluxo básico que carrega um conjunto de dados, realiza o treinamento e apresenta os resultados do modelo.
Nota: O código pode serexecutado no DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Carregar e dividir o conjunto de dados print("Loading data...") self.data = [1, 2, 3, 4, 5] # Substituir pela lógica real de carregamento de dados self.labels = [0, 1, 0, 1, 0] # Substituir pelos rótulos self.next(self.train_model) @step def train_model(self): # Treinando um modelo simples (por exemplo, regressão linear) print("Training the model...") self.model = sum(self.data) / len(self.data) # Substituir pelo treinamento real do modelo print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Etapa final print("Training complete. Model ready for deployment!")f
Neste código, definimos três etapas:
start(): Carrega e divide o conjunto de dados. Em um cenário do mundo real, você carregaria dados de uma fonte real (por exemplo, um arquivo ou banco de dados).train_model(): Simula o treinamento de um modelo. Aqui, uma simples cálculo de média é realizado em vez de um algoritmo real de aprendizado de máquina, mas você pode substituir isso por qualquer código de treinamento que precisar.end(): Marca o fim do fluxo e sinaliza que o modelo está pronto para implantação.
Uma vez que você tenha definido o fluxo, você pode executá-lo usando o seguinte comando:
run = NBRunner(TrainModelFlow) run.nbrun()
Observe que este código funciona apenas em notebooks (todo o código deve estar em uma única célula).
Se você quiser executar este código como um script, remova os comandos NBRunner e anexe o seguinte ao final do seu script, e salve-o (por exemplo, “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Então, para executar o script, navegue até a linha de comando e execute o seguinte comando:
py -m metaflow_ml_model.py
A Metaflow rastreia automaticamente cada execução e permite que você visualize os resultados através da interface Metaflow.
Melhores Práticas para Usar o Metaflow
Então, como podemos aproveitar ao máximo os recursos do Metaflow? Aqui estão algumas melhores práticas que podem ajudá-lo a alcançar esse objetivo enquanto otimiza seus fluxos de trabalho simultaneamente:
Comece com fluxos pequenos
Se você é novo no Metaflow, comece com fluxos de trabalho simples para se familiarizar com sua API. Começar pequeno ajudará você a entender como o framework funciona e a ganhar confiança em suas capacidades antes de passar para projetos mais complexos. Essa abordagem reduz a curva de aprendizado e garante que sua base esteja sólida.
Utilize a interface do Metaflow para depuração
Metaflow inclui uma interface do usuário poderosa que pode ser extremamente útil para depuração e rastreamento dos seus fluxos de trabalho. Use a interface para monitorar execuções, verificar as saídas de etapas individuais e identificar quaisquer problemas que possam surgir. Visualizar seus dados e logs facilita a identificação e a correção de problemas durante a execução do seu fluxo.
Aproveite a AWS para escalabilidade
Quando você instala o Metaflow pela primeira vez, ele opera em modo local. Nesse modo, artefatos e metadados são salvos em um diretório local, e os cálculos são realizados usando processos locais. Essa configuração funciona bem para uso pessoal, mas se o seu projeto envolve colaboração ou grandes conjuntos de dados, é recomendável configurar o Metaflow para utilizar a AWS para melhor escalabilidade. O bom aqui é que Metaflow fornece excelente integração com a AWS.
Conclusão
Neste tutorial, exploramos como começar com o Metaflow, desde a instalação até a construção do seu primeiro fluxo de trabalho em ciência de dados. Abordamos os conceitos principais, como definir etapas, usar artefatos de dados para passar dados entre etapas e versionamento para rastrear e reproduzir execuções. Também percorremos um exemplo prático de treinamento de um modelo de aprendizado de máquina, que demonstrou como definir, executar e monitorar seu fluxo de trabalho. Por fim, tocamos em algumas melhores práticas para ajudá-lo a aproveitar ao máximo o Metaflow.
Para continuar seu aprendizado sobre MLOps, confira os seguintes recursos: