













Metaflow es un marco poderoso para construir y gestionar flujos de trabajo de datos. En este tutorial, aprenderás cómo empezar. Específicamente, abordaremos:
- El proceso de instalación
- Construir un flujo de trabajo básico
- Conceptos clave
- Mejores prácticas
Al final de este artículo, tendrás las habilidades necesarias para optimizar y escalar tus flujos de trabajo de manera eficiente!
¿Qué es Metaflow?

Fuente: ¿Por qué Metaflow?
Metaflow es un marco de trabajo en Python diseñado para ayudar a gestionar proyectos de ciencia de datos. Netflix desarrolló inicialmente la herramienta para ayudar a los científicos de datos y a los ingenieros de aprendizaje automático a ser más productivos. Logra este objetivo simplificando tareas complejas, como la orquestación de flujos de trabajo, lo que asegura que los procesos se desarrollen sin problemas de principio a fin.
Las características clave de Metaflow incluyen la versionado automático de datos, que rastrea los cambios en tus flujos de trabajo, y el soporte para flujos de trabajo escalables, que permite a los usuarios manejar conjuntos de datos más grandes y tareas más complejas.
Otra ventaja de Metaflow es que se integra fácilmente con AWS. Esto significa que los usuarios pueden aprovechar los recursos de la nube para almacenamiento y potencia de cálculo. Además, su API de Python fácil de usar lo hace accesible tanto para principiantes como para usuarios experimentados.
Comencemos a configurarlo.
Configurando Metaflow
Metaflow sugiere que los usuarios instalen Python 3 en lugar de Python 2.7 para nuevos proyectos. La documentación indica que “Python 3 tiene menos errores y está mejor soportado que el obsoleto Python 2.7.”
El siguiente paso es crear un entorno virtual para gestionar las dependencias de tu proyecto. Ejecuta el siguiente comando para hacerlo:
python -m venv venv source venv/bin/activate
Esto creará y activará un entorno virtual. Una vez activado, estás listo para instalar Metaflow.
Metaflow está disponible como un paquete de Python para MacOS y Linux. La última versión se puede instalar desde el repositorio de Metaflow en Github o PyPi ejecutando el siguiente comando:
pip install metaflow
Desafortunadamente, en el momento de escribir esto, Metaflow no ofrece soporte nativo para usuarios de Windows. Sin embargo, los usuarios con Windows 10 pueden usar WSL (Subsistema de Windows para Linux) para instalar Metaflow, lo que les permite ejecutar un entorno Linux dentro de su sistema operativo Windows. Consulta la documentación para una guía paso a paso sobre cómo instalar Metaflow en Windows 10.
Integración de AWS (Opcional)
Metaflow ofrece integración sin problemas con AWS, lo que permite a los usuarios escalar sus flujos de trabajo utilizando infraestructura en la nube. Para integrar AWS, necesitarás configurar tus credenciales de AWS.
Nota: Estos pasos asumen que ya tienes una cuenta de AWS y AWS CLI instalado. Para más detalles, sigue las instrucciones de la documentación de AWS.
- Primero, instala AWS CLI ejecutando:
pip install awscli
- Configura AWS ejecutando
aws configure
A partir de aquí, se le pedirá que ingrese su ID de clave de acceso de AWS y su clave de acceso secreta; estas son simplemente las credenciales que la AWS CLI utiliza para autenticar sus solicitudes a AWS. Tenga en cuenta que también se le puede solicitar que ingrese su región y formato de salida.
Una vez que haya ingresado estos detalles, ¡voilà! Metaflow utilizará automáticamente sus credenciales de AWS para ejecutar flujos de trabajo.
Construyendo Su Primer Flujo de Trabajo con Metaflow
Ahora que Metaflow está configurado, es hora de construir su primer flujo de trabajo. En esta sección, le guiaré a través de los conceptos básicos para crear un flujo, ejecutarlo y entender cómo se organizan las tareas y los pasos en Metaflow.
Al final de esta sección, tendrá un flujo de trabajo que procesa datos y realiza operaciones simples. ¡Vamos!
Descripción general de un flujo de Metaflow
Metaflow utiliza el paradigma de flujo de datos, que representa un programa como un gráfico dirigido de operaciones. Este enfoque es ideal para construir tuberías de procesamiento de datos, especialmente en aprendizaje automático.
En Metaflow, el gráfico de operaciones se llama flujo. Un flujo consiste en una serie de tareas divididas en pasos. Ten en cuenta que cada paso puede considerarse una operación representada como un nodo, con transiciones entre pasos que actúan como los bordes del gráfico.
Una transición lineal básica de Metaflow | Fuente: documentación de Metaflow
Existen algunas reglas estructurales para los flujos en Metaflow. Por ejemplo, cada flujo debe incluir un inicio y un fin paso. Cuando un flujo se ejecuta, conocido como un ejecución, comienza con el paso de inicio y se considera exitoso si alcanza el paso de fin sin errores.
Lo que sucede entre los pasos de inicio y final es completamente tu decisión, como verás en el siguiente segmento.
Escribiendo tu primer flujo
Aquí tienes un flujo simple para empezar.Nota: El código se puede ejecutar en DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de datos de ejemplo self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Procesamiento de datos simple print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
En este flujo:
- El paso
start()inicializa el flujo de trabajo y define un conjunto de datos. - El paso
process_data()procesa los datos duplicando cada elemento. - El paso
end()completa el flujo.
Cada paso utiliza el decorador @step, y defines la secuencia del flujo utilizando self.next() para conectar los pasos.
Ejecutando tu flujo
Después de escribir tu flujo, guárdalo como my_first_flow.py. Ejecútalo desde la línea de comandos usando:
py -m my_first_flow.py run
Se añadió una nueva función en Metaflow 2.12 que permite a los usuarios desarrollar y ejecutar flujos en notebooks.
Para ejecutar un flujo en una celda definida, todo lo que debes hacer es agregar la línea única NBRunner en la última línea de la misma celda. Por ejemplo:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de datos de ejemplo self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Procesamiento de datos simple print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Si obtienes el siguiente error:
“Metaflow no pudo determinar tu nombre de usuario basado en las variables de entorno ($USERNAME, etc.)”
Agrega lo siguiente a tu código antes de la ejecución de Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
En ambos casos, Metaflow ejecutará el flujo paso a paso. Es decir, mostrará la salida de cada paso en la terminal de la siguiente manera:
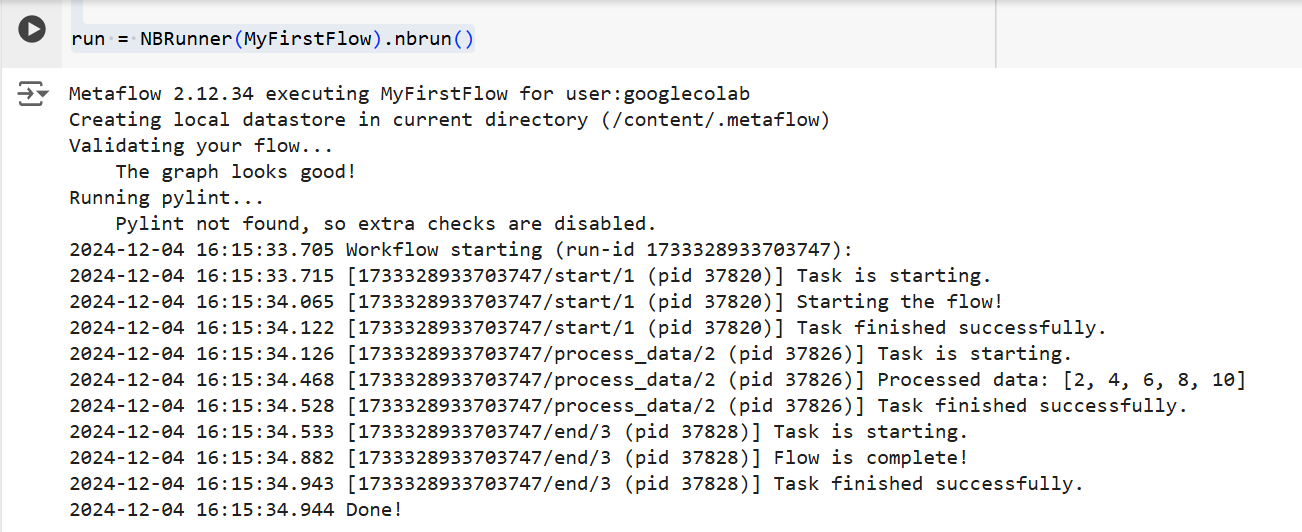
La salida del código anterior | Fuente: Imagen por el autor
Conceptos clave en Metaflow
Entender los conceptos básicos de Metaflow es esencial para construir flujos de trabajo de datos eficientes y escalables. En esta sección, cubriré tres conceptos fundamentales:
- Pasos y ramificación
- Artefactos de datos
- Versionado
Estos elementos forman la columna vertebral de la estructura y ejecución de flujos de trabajo de Metaflow, permitiéndote gestionar procesos complejos con facilidad.
Pasos y ramificación
Hemos tocado brevemente los pasos anteriormente en el artículo, pero para mayor claridad, los revisaremos nuevamente. Lo más importante que hay que entender sobre los flujos de trabajo de Metaflow es que están construidos en torno a pasos.
Los pasos representan cada tarea individual dentro de un flujo de trabajo. En otras palabras, cada paso realizará una operación específica (por ejemplo, carga de datos, procesamiento, modelado, etc.).
El ejemplo que creamos arriba en “Escribiendo tu primer flujo” fue una transformación lineal. Además de los pasos secuenciales, Metaflow también permite a los usuarios dividir flujos de trabajo. Los flujos de trabajo divididos te permiten ejecutar múltiples tareas en paralelo creando caminos separados para la ejecución.
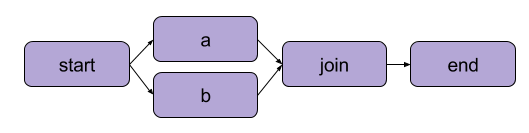
Un ejemplo de división | Fuente: documentación de Metaflow
El principal beneficio de una división es el rendimiento. Dividir significa que Metaflow puede ejecutar varios pasos en múltiples núcleos de CPU o instancias en la nube.
Así es como se vería una división en código:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de datos de ejemplo self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Código para la rama 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Código para la rama 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Fusionando ramas de nuevo print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡Resumen: La ramificación permite a los usuarios diseñar flujos de trabajo complejos que pueden procesar múltiples tareas simultáneamente. |
Artefactos de datos
Datos artefactos son variables que te permiten almacenar y pasar datos entre pasos en un flujo de trabajo. Estos artefactos persisten la salida de un paso al siguiente; así es como los datos están disponibles para pasos posteriores.
Esencialmente, cuando asignas datos a self dentro de un paso en una clase de Metaflow, los guardas como un artefacto, que luego puede ser accedido por cualquier otro paso en el flujo (ver los comentarios en el código).
class ArtifactFlow(FlowSpec): @step def start(self): # Paso 1: Inicializando datos print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Conjunto de datos de ejemplo guardado como un artefacto self.next(self.process_data) @step def process_data(self): # Paso 2: Procesando los datos del paso 'inicio' self.processed_data = [x * 2 for x in self.data] # Procesando datos del artefacto print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Paso 3: Guardando el artefacto de datos procesados self.results = sum(self.processed_data) # Guardando el resultado final como un artefacto print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Paso final print("Flow is complete!") print(f"Final result: {self.results}") # Accediendo al artefacto en el paso final
¿Por qué son los artefactos un concepto central de Metaflow? Porque tienen una serie de usos:
- Automatizando la gestión del flujo de datos, eliminando la necesidad de cargar y almacenar datos manualmente.
- Habilitar la persistencia (más sobre esto a continuación), lo que significa que permiten a los usuarios realizar análisis más tarde con la API del Cliente, visualizar con Tarjetas y reutilizar en flujos.
- Consistencia entre entornos locales y en la nube. Esto elimina la necesidad de transferencias de datos explícitas.
- Permitir a los usuarios inspeccionar datos antes de errores y reanudar ejecuciones después de corregir fallos.
Versionado y persistencia
Metaflow maneja automáticamente versiones para tus flujos de trabajo. Esto significa que cada vez que se ejecuta un flujo, se registra como una ejecución única. En otras palabras, cada ejecución tiene su propia versión, lo que te permite revisar y reproducir fácilmente ejecuciones pasadas.
Metaflow hace esto asignando identificadores únicos a cada ejecución y preservando los datos y artefactos de esa ejecución. Esta persistencia asegura que no se pierda ningún dato entre ejecuciones. Los flujos de trabajo pasados pueden revisitarse e inspeccionarse fácilmente, y se pueden volver a ejecutar pasos específicos si es necesario. Como resultado, la depuración y el desarrollo iterativo son mucho más eficientes, y mantener la reproducibilidad se simplifica.
Ejemplo práctico: Entrenamiento de un modelo de aprendizaje automático
En esta sección, te guiaré a través del uso de Metaflow para entrenar un modelo de aprendizaje automático. Aprenderás cómo:
- Define un flujo de trabajo que carga datos
- Entrena un modelo de aprendizaje automático
- Rastrea los resultados
Al final, comprenderás mejor cómo usar Metaflow para estructurar y ejecutar flujos de trabajo de aprendizaje automático de manera eficiente. ¡Vamos!
Para comenzar, crearemos un flujo básico que carga un conjunto de datos, realiza el entrenamiento y genera los resultados del modelo.
Nota: El código se puede ejecutar en DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Cargar y dividir el conjunto de datos print("Loading data...") self.data = [1, 2, 3, 4, 5] # Reemplazar con la lógica de carga de datos real self.labels = [0, 1, 0, 1, 0] # Reemplazar con etiquetas self.next(self.train_model) @step def train_model(self): # Entrenando un modelo simple (por ejemplo, regresión lineal) print("Training the model...") self.model = sum(self.data) / len(self.data) # Reemplazar con el entrenamiento real del modelo print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Paso final print("Training complete. Model ready for deployment!")f
En este código, definimos tres pasos:
start(): Carga y divide el conjunto de datos. En un escenario del mundo real, cargarías datos de una fuente real (por ejemplo, un archivo o base de datos).train_model(): Simula el entrenamiento de un modelo. Aquí, se realiza un cálculo de promedio simple en lugar de un algoritmo de aprendizaje automático real, pero puedes reemplazar esto con cualquier código de entrenamiento que necesites.end(): Marca el final del flujo y señala que el modelo está listo para su implementación.
Una vez que hayas definido el flujo, puedes ejecutarlo utilizando el siguiente comando:
run = NBRunner(TrainModelFlow) run.nbrun()
Ten en cuenta que este código solo funciona en notebooks (todo el código debe estar en una celda).
Si deseas ejecutar este código como un script, elimina los comandos NBRunner y adjunta lo siguiente al final de tu script, y guárdalo (por ejemplo, “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Luego, para ejecutar el script, navega a la línea de comandos y ejecuta el siguiente comando:
py -m metaflow_ml_model.py
Metaflow rastrea automáticamente cada ejecución y te permite visualizar los resultados a través de la interfaz de usuario de Metaflow.
Mejores Prácticas para Usar Metaflow
Entonces, ¿cómo podemos aprovechar al máximo las características de Metaflow? Aquí hay algunas mejores prácticas que pueden ayudarte a lograr esto mientras optimizas tus flujos de trabajo simultáneamente:
Comienza con flujos pequeños
Si eres nuevo en Metaflow, comienza con flujos de trabajo simples para familiarizarte con su API. Comenzar pequeño te ayudará a entender cómo funciona el marco y a construir confianza en sus capacidades antes de pasar a proyectos más complejos. Este enfoque reduce la curva de aprendizaje y garantiza que tu base sea sólida.
Utiliza la interfaz de usuario de Metaflow para depurar
Metaflow incluye una interfaz de usuario potente que puede ser extremadamente útil para depurar y rastrear tus flujos de trabajo. Usa la interfaz para monitorear ejecuciones, verificar las salidas de pasos individuales e identificar cualquier problema que pueda surgir. Visualizar tus datos y registros facilita la identificación y solución de problemas durante la ejecución de tu flujo.
Aprovecha AWS para escalabilidad
Cuando instalas Metaflow por primera vez, opera en modo local. En este modo, los artefactos y metadatos se guardan en un directorio local, y los cálculos se realizan utilizando procesos locales. Esta configuración funciona bien para uso personal, pero si tu proyecto implica colaboración o grandes conjuntos de datos, es recomendable configurar Metaflow para utilizar AWS para una mejor escalabilidad. Lo bueno aquí es que Metaflow proporciona una excelente integración con AWS.
Conclusión
En este tutorial, exploramos cómo empezar con Metaflow, desde la instalación hasta la creación de tu primer flujo de trabajo en ciencia de datos. Cubrimos los conceptos básicos, como definir pasos, utilizar artefactos de datos para pasar datos entre pasos y versionado para rastrear y reproducir ejecuciones. También recorrimos un ejemplo práctico de entrenamiento de un modelo de aprendizaje automático, que demostró cómo definir, ejecutar y monitorear tu flujo de trabajo. Por último, tocamos algunas mejores prácticas para ayudarte a aprovechar al máximo Metaflow.
Para continuar tu aprendizaje de MLOps, consulta los siguientes recursos: