













ميتافلو هو إطار قوي لبناء وإدارة سير العمل البياني. في هذا الدليل، ستتعلم كيف تبدأ. تحديدًا، سنناقش:
- عملية التثبيت
- بناء سير عمل أساسي
- المفاهيم الأساسية
- أفضل الممارسات
بنهاية هذه المقالة، ستكون لديك المهارات اللازمة لتبسيط وتوسيع سير العمل الخاص بك بكفاءة!
ما هو ميتافلو؟

المصدر: لماذا Metaflow؟
Metaflow هو إطار عمل باللغة Python مصمم لمساعدة في إدارة مشاريع علم البيانات. طورت Netflix الأداة في البداية لمساعدة علماء البيانات ومهندسي التعلم الآلي على زيادة إنتاجيتهم. تحقق ذلك الهدف من خلال تبسيط المهام المعقدة، مثل تنظيم سير العمل، مما يضمن سلامة تشغيل العمليات من البداية إلى النهاية.
تتضمن الميزات الرئيسية لـ Metaflow تتبع التغييرات التلقائي للبيانات، الذي يتتبع التغييرات في سير العمل الخاصة بك، ودعم سير العمل القابل للتوسيع، مما يتيح للمستخدمين التعامل مع مجموعات بيانات أكبر ومهام أكثر تعقيدًا.
ميزة أخرى لـ Metaflow هي أنه يتكامل بسهولة مع AWS. هذا يعني أن المستخدمين يمكنهم استغلال موارد السحابة للتخزين والقوة الحوسبية. بالإضافة إلى ذلك، تجعل واجهة برمجة التطبيقات الودية لـ Python منه متاحًا للمبتدئين والمستخدمين ذوي الخبرة على حد سواء.
لنبدأ في إعداده.
إعداد Metaflow
يقترح Metaflow أن يقوم المستخدمون بتثبيت Python 3 بدلاً من Python 2.7 للمشاريع الجديدة. توضح الوثائق أن “Python 3 يحتوي على أخطاء أقل ويتم دعمه بشكل أفضل من Python 2.7 المهمل.”
الخطوة التالية هي إنشاء بيئة افتراضية لإدارة اعتمادات مشروعك. قم بتشغيل الأمر التالي للقيام بذلك:
python -m venv venv source venv/bin/activate
سيتم إنشاء وتنشيط بيئة افتراضية. بمجرد تنشيطها، أنت الآن جاهز لتثبيت Metaflow.
يتوفر Metaflow كحزمة Python لنظامي التشغيل MacOS و Linux. يمكن تثبيت أحدث إصدار من مستودع Metaflow على Github أو من PyPi عن طريق تشغيل الأمر التالي:
pip install metaflow
على الرغم من عدم توفر دعم طبيعي لمستخدمي Windows في الوقت الحالي، يمكن لمستخدمي Windows 10 استخدام WSL (نظام الإشارة الفرعية لـ Linux) لتثبيت Metaflow، مما يتيح لهم تشغيل بيئة Linux داخل نظامهم التشغيلي Windows. تفضل بالتحقق من الوثائق للحصول على دليل تفصيلي على تثبيت Metaflow على Windows 10.
التكامل مع AWS (اختياري)
يوفر Metaflow تكاملًا سلسًا مع AWS، مما يتيح للمستخدمين توسيع سير العمل الخاص بهم باستخدام بنية تحتية سحابية. لتكامل AWS، ستحتاج إلى إعداد بيانات اعتماد AWS الخاصة بك.
ملاحظة: يفترض هذه الخطوات أن لديك بالفعل حساب AWS و AWS CLI مثبت. لمزيد من التفاصيل، اتبع تعليمات وثائق AWS.
- أولاً، قم بتثبيت AWS CLI عن طريق تشغيل:
pip install awscli
- قم بتكوين AWS عن طريق التشغيل
aws configure
من هنا، سيُطلب منك إدخال معرّف مفتاح الوصول الخاص بـ AWS ومفتاح الوصول السري – هذه هي ببساطة بيانات الاعتماد التي يستخدمها AWS CLI لمصادقة طلباتك إلى AWS. لاحظ أنه قد يُطلب منك أيضًا إدخال منطقتك وشكل الإخراج.
بمجرد إدخال هذه التفاصيل، ها هي! سيستخدم Metaflow بيانات اعتماد AWS الخاصة بك تلقائيًا لتشغيل سير العمل.
بناء سير العمل الأول الخاص بك باستخدام Metaflow
الآن بعد إعداد Metaflow، حان الوقت لبناء سير العمل الأول الخاص بك. في هذا القسم، سأرشدك خلال أساسيات إنشاء تدفق، وتشغيله، وفهم كيفية تنظيم المهام والخطوات في Metaflow.
بنهاية هذا القسم، سيكون لديك سير عمل يعالج البيانات وينفذ عمليات بسيطة. هيا بنا!
نظرة عامة على تدفق Metaflow
ميتافلو تستخدم نموذج تدفق البيانات، الذي يمثل البرنامج كرسمة موجهة من العمليات. هذه الطريقة مثالية لبناء خطوط معالجة البيانات، وخاصة في تعلم الآلة.
في ميتافلو، تُسمى رسمة العمليات بتدفق. يتكون التدفق من سلسلة من المهام مقسمة إلى خطوات. لاحظ أن كل خطوة يمكن اعتبارها عملية تمثل كنقطة مع انتقالات بين الخطوات تعمل كحواف للرسمة.
انتقال خطي أساسي في Metaflow | المصدر: وثائق Metaflow
هناك بعض القواعد الهيكلية للتدفقات في Metaflow. على سبيل المثال، يجب أن تتضمن كل تدفق خطوة start وخطوة end . عندما يتم تنفيذ تدفق، المعروف باسم run، يبدأ بخطوة البداية ويعتبر ناجحًا إذا وصل إلى خطوة النهاية دون أخطاء.
ما يحدث بين الخطوة الابتدائية والنهائية يعتمد تمامًا عليك – كما سترى في القسم التالي.
كتابة تدفقك الأول
هذا تدفق بسيط للبدء. ملاحظة: يمكن تشغيل الكود في DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # مجموعة بيانات مثال self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # معالجة البيانات البسيطة print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
في هذا التدفق:
- تبدأ الخطوة
start()بتهيئة سير العمل وتعريف مجموعة بيانات. - خطوة
process_data()تعالج البيانات عن طريق مضاعفة كل عنصر. - خطوة
end()تكمل التدفق.
كل خطوة تستخدم الزخرفة @step، وتحدد تسلسل التدفق باستخدام self.next() لربط الخطوات.
تشغيل التدفق الخاص بك
بعد كتابة التدفق الخاص بك، احفظه كـ my_first_flow.py. قم بتشغيله من سطر الأوامر باستخدام:
py -m my_first_flow.py run
تمت إضافة ميزة جديدة في Metaflow 2.12 تتيح للمستخدمين تطوير وتنفيذ التدفقات في الدفاتر.
لتنفيذ تدفق في خلية محددة، كل ما عليك فعله هو إضافة سطر NBRunner في السطر الأخير من نفس الخلية. على سبيل المثال:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # مثال على مجموعة البيانات self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # معالجة البيانات البسيطة print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
إذا حصلت على الخطأ التالي:
“لم تتمكن Metaflow من تحديد اسم المستخدم الخاص بك استنادًا إلى متغيرات البيئة ($USERNAME الخ).”
أضف ما يلي إلى كودك قبل تنفيذ Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
في كلتا الحالتين، سيقوم Metaflow بتنفيذ التدفق خطوة بخطوة. وبمعنى آخر، سيعرض إخراج كل خطوة في الطرفية على النحو التالي:
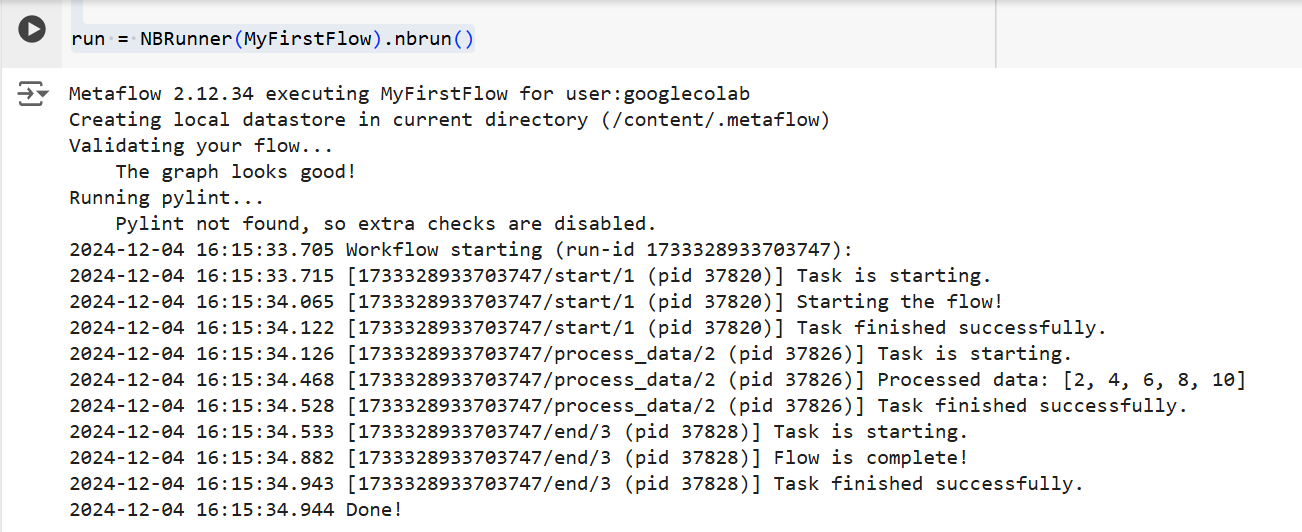
الناتج من الكود أعلاه | المصدر: صورة من تأليف الكاتب
المفاهيم الأساسية في Metaflow
فهم المفاهيم الأساسية لـ Metaflow أمر ضروري لبناء تدفقات بيانات فعالة وقابلة للتوسع. في هذا القسم، سأغطي ثلاثة مفاهيم أساسية:
- الخطوات والتفرع
- التحف البياناتية
- إصدار النسخ
تشكل هذه العناصر العمود الفقري لبنية Metaflow وتنفيذ سير العمل، مما يتيح لك إدارة العمليات المعقدة بسهولة.
الخطوات والتفرع
لقد تطرقنا باختصار إلى الخطوات في وقت سابق من المقالة، ولكن من أجل الوضوح، سنعيد النظر فيها مرة أخرى. أهم شيء يجب فهمه حول سير عمل Metaflow هو أنها مبنية حول الخطوات.
تمثل الخطوات كل مهمة فردية ضمن سير العمل. بعبارة أخرى، ستقوم كل خطوة بتنفيذ عملية محددة (مثل تحميل البيانات، المعالجة، النمذجة، إلخ).
المثال الذي أنشأناه أعلاه في “كتابة تدفقك الأول” كان تحويلًا خطيًا. بالإضافة إلى الخطوات التسلسلية، يُمكن لـ Metaflow أيضًا للمستخدمين فرع سير العمل. تُمكن سير العمل الفرعي من تشغيل مهام متعددة بشكل متوازي من خلال إنشاء مسارات منفصلة للتنفيذ.
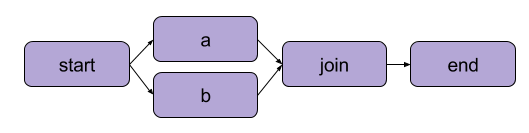
مثال على الفروع | المصدر: وثائق Metaflow
الفائدة الرئيسية للفرع هي الأداء. يعني الفرع أن يمكن لـ Metaflow تنفيذ خطوات مختلفة عبر عدة نوى للمعالج أو حالات في السحابة.
إليك كيف سيبدو الفرع في الشيفرة:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # مجموعة بيانات المثال self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # كود الفرع 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # كود الفرع 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # دمج الفروع مرة أخرى print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡ملخص: يسمح التفرع للمستخدمين بتصميم تدفقات عمل معقدة يمكنها معالجة مهام متعددة في وقت واحد. |
البيانات الأثرية
البيانات الأثرية هي متغيرات تسمح لك بتخزين ونقل البيانات بين الخطوات في تدفق العمل. تستمر هذه الآثار في نقل مخرجات خطوة واحدة إلى الخطوة التالية—وهذا هو كيف تتاح البيانات للخطوات اللاحقة.
بشكل أساسي، عندما تقوم بتعيين بيانات إلى self داخل خطوة في فئة Metaflow، فإنك تحفظها كأثر، والذي يمكن الوصول إليه بعد ذلك من أي خطوة أخرى في التدفق (انظر التعليقات في الكود).
class ArtifactFlow(FlowSpec): @step def start(self): # الخطوة 1: تهيئة البيانات print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # مجموعة بيانات مثالية محفوظة كأثر self.next(self.process_data) @step def process_data(self): # الخطوة 2: معالجة البيانات من خطوة 'البداية' self.processed_data = [x * 2 for x in self.data] # معالجة بيانات الأثر print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # الخطوة 3: حفظ أثر البيانات المعالجة self.results = sum(self.processed_data) # حفظ النتيجة النهائية كأثر print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # الخطوة النهائية print("Flow is complete!") print(f"Final result: {self.results}") # الوصول إلى الأثر في الخطوة النهائية
لماذا تعتبر الآثار مفهومًا أساسيًا في Metaflow؟ لأنها لها عدد من الاستخدامات:
- أتمتة إدارة تدفق البيانات، مما يزيل الحاجة إلى تحميل البيانات وتخزينها يدويًا.
- تمكين الاستمرارية (المزيد عن ذلك لاحقاً)، مما يعني أنهم يسمحون للمستخدمين بإجراء التحليل لاحقاً باستخدام واجهة برمجة التطبيقات العميلة، والتصور باستخدام البطاقات، وإعادة الاستخدام عبر التدفقات.
- الاتساق عبر البيئات المحلية والسحابية. هذا يلغي الحاجة إلى نقل البيانات بشكل صريح.
- تمكين المستخدمين من فحص البيانات قبل حدوث الأخطاء واستئناف التنفيذ بعد إصلاح الأخطاء.
إصدار البيانات والاستمرارية
ميتافلو يدير تلقائيًا إصدار سير العمل الخاص بك. هذا يعني أنه في كل مرة يتم فيها تنفيذ تدفق، يتم تتبعه كتشغيل فريد. بعبارة أخرى، كل تشغيل له إصدار خاص به، مما يتيح لك مراجعة وإعادة إنتاج عمليات التشغيل السابقة بسهولة.
تقوم ميتافلو بذلك من خلال تخصيص معرّفات فريدة لكل تشغيل والحفاظ على البيانات والقطع الفنية من ذلك التنفيذ. هذه الاستمرارية تضمن عدم فقدان أي بيانات بين عمليات التشغيل. يمكن إعادة زيارة سير العمل السابق وفحصه بسهولة، ويمكن إعادة تشغيل خطوات معينة إذا لزم الأمر. ونتيجة لذلك، فإن تصحيح الأخطاء وتطوير النسخ المتكررة يكون أكثر كفاءة بكثير، وتصبح صيانة القابلية للتكرار مبسطة.
مثال عملي: تدريب نموذج تعلم الآلة
في هذا القسم، سأرشدك خلال استخدام ميتافلو لتدريب نموذج تعلم الآلة. ستتعلم كيفية:
- حدد سير العمل الذي يقوم بتحميل البيانات
- تدريب نموذج التعلم الآلي
- تتبع النتائج
بنهاية المطاف، ستفهم بشكل أفضل كيفية استخدام Metaflow لتنظيم وتشغيل سير العمل الخاص بالتعلم الآلي بكفاءة. هيا بنا!
للبدء، سنقوم بإنشاء تدفق أساسي يقوم بتحميل مجموعة بيانات، وإجراء التدريب، وإخراج نتائج النموذج.
ملاحظة: يمكن تشغيل الكود في DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # تحميل وتقسيم مجموعة البيانات print("Loading data...") self.data = [1, 2, 3, 4, 5] # استبدالها بمنطق تحميل البيانات الفعلي self.labels = [0, 1, 0, 1, 0] # استبدالها بالتسميات self.next(self.train_model) @step def train_model(self): # تدريب نموذج بسيط (مثل الانحدار الخطي) print("Training the model...") self.model = sum(self.data) / len(self.data) # استبدالها بتدريب النموذج الفعلي print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # الخطوة النهائية print("Training complete. Model ready for deployment!")f
في هذا الكود، نحدد ثلاث خطوات:
start(): يحمل ويقسم مجموعة البيانات. في سيناريو العالم الواقعي، ستقوم بتحميل البيانات من مصدر فعلي (مثل ملف أو قاعدة بيانات).train_model(): يحاكي تدريب نموذج. هنا، يتم إجراء حساب متوسط بسيط بدلاً من خوارزمية تعلم آلي فعلية، ولكن يمكنك استبدال ذلك بأي كود تدريب تحتاجه.end(): يشير إلى نهاية التدفق ويعني أن النموذج جاهز للنشر.
بمجرد أن تعرف التدفق، يمكنك تشغيله باستخدام الأمر التالي:
run = NBRunner(TrainModelFlow) run.nbrun()
لاحظ أن هذا الكود يعمل فقط في دفاتر الملاحظات (يجب أن يكون كل الكود في خلية واحدة).
إذا كنت تريد تشغيل هذا الكود كبرنامج نصي، قم بإزالة أوامر NBRunner وأضف ما يلي في نهاية البرنامج النصي الخاص بك، واحفظه (على سبيل المثال، “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
ثم، لتشغيل البرنامج النصي، انتقل إلى سطر الأوامر وقم بتشغيل الأمر التالي:
py -m metaflow_ml_model.py
يتتبع Metaflow تلقائيًا كل تشغيل ويتيح لك تصور النتائج من خلال واجهة المستخدم Metaflow.
أفضل الممارسات لاستخدام Metaflow
إذن، كيف يمكننا الاستفادة القصوى من ميزات Metaflow؟ إليك بعض أفضل الممارسات التي يمكن أن تساعدك على تحقيق هذا الإنجاز مع تحسين سير العمل الخاص بك في نفس الوقت:
ابدأ بتدفقات صغيرة
إذا كنت جديدًا على Metaflow، ابدأ بسير العمل البسيطة لتعتاد على واجهة برمجة التطبيقات الخاصة به. البدء بشكل صغير سيساعدك على فهم كيفية عمل الإطار وبناء الثقة في قدراته قبل الانتقال إلى مشاريع أكثر تعقيدًا. يساعد هذا النهج في تقليل منحنى التعلم ويضمن أن أساسك قوي.
استخدم واجهة المستخدم Metaflow لأغراض تصحيح الأخطاء
ميتافلو يتضمن واجهة مستخدم قوية يمكن أن تكون مفيدة للغاية في تصحيح الأخطاء وتتبع سير العمل الخاص بك. استخدم واجهة المستخدم لمراقبة التشغيل، والتحقق من مخرجات الخطوات الفردية، وتحديد أي مشكلات قد تنشأ. إن تصور بياناتك وسجلاتك يجعل من السهل تحديد المشكلات وإصلاحها أثناء تنفيذ سير العمل الخاص بك.
استفد من AWS من أجل القابلية للتوسع
عند تثبيت ميتافلو لأول مرة، يعمل في وضع محلي. في هذا الوضع، يتم حفظ العناصر الفنية والبيانات الوصفية في دليل محلي، وتتم العمليات الحسابية باستخدام عمليات محلية. هذا الإعداد يعمل بشكل جيد للاستخدام الشخصي، ولكن إذا كان مشروعك يتضمن التعاون أو مجموعات بيانات كبيرة، فمن المستحسن تكوين ميتافلو لاستخدام AWS من أجل قابلية أفضل للتوسع. الشيء الجيد هنا هو أن ميتافلو يوفر تكاملاً ممتازاً مع AWS.
الخاتمة
في هذا الدليل، استكشفنا كيفية البدء مع Metaflow، من التثبيت إلى بناء سير العمل الأول في علم البيانات. تناولنا المفاهيم الأساسية، مثل تعريف الخطوات، واستخدام عناصر البيانات لنقل البيانات بين الخطوات، وإصدار النسخ لتتبع وإعادة إنتاج العمليات. كما قمنا بتمرير مثال عملي لتدريب نموذج تعلم الآلة، والذي أظهر كيفية تعريف وتشغيل ومراقبة سير العمل الخاص بك. أخيرًا، تطرقنا إلى بعض الممارسات الجيدة لمساعدتك في الاستفادة القصوى من Metaflow.
لمتابعة تعلمك في MLOps، تحقق من الموارد التالية: