













מטאפלואו הוא מסגרת חזקה לבניית וניהול זרימות עבודה עם נתונים. במדריך זה, תלמד כיצד להתחיל. כלומר, ניגע ב:
- תהליך ההתקנה
- בניית זרימת עבודה בסיסית
- מונחים מרכזיים
- שיטות עבודה מומלצות
בסוף המאמר הזה, יהיו לך המיומנויות הנדרשות לייעל ולהרחיב את זרימות העבודה שלך ביעילות!
מה זה מטאפלואו?

מקור: למה מטפלו?
מטפלו היא מסגרת פייתון שנועדה לעזור בניהול פרויקטי מדע נתונים. נטפליקס פיתחה את הכלי במקור כדי לעזור למדעני נתונים ומהנדסי למידת מכונה להיות פרודוקטיביים יותר. היא משיגה את המטרה הזו על ידי הפSimplification של משימות מורכבות, כמו תיאום זרימות עבודה, שמבטיח שפרוצדורות יתנהלו בצורה חלקה מתחילתו ועד סופו.
תכונות מפתח של מטפלו כוללות ניהול גרסאות אוטומטי של נתונים, שעוקב אחרי שינויים בזרימות העבודה שלך, ותמיכה בזרימות עבודה ניתנות להרחבה, שמאפשרת למשתמשים להתמודד עם מערכי נתונים גדולים יותר ומשימות מורכבות יותר.
יתרון נוסף של Metaflow הוא שהוא משתלב בקלות עם AWS. זה אומר שמשתמשים יכולים לנצל את המשאבים של הענן לאחסון וכוח חישוב. בנוסף, ה-API הידידותי למשתמש ב-Python עושה אותו נגיש גם למתחילים וגם למשתמשים מנוסים.
בואו נתחיל בהגדרה שלו.
הגדרת Metaflow
מטפלו מציע למשתמשים להתקין את Python 3 ולא את Python 2.7 עבור פרויקטים חדשים. התיעוד קובע ש“Python 3 מכיל פחות באגים ומקבל תמיכה טובה יותר מאשר Python 2.7 המיושן.”
השלב הבא הוא ליצור סביבה וירטואלית כדי לנהל את התלויות של הפרויקט שלך. הרץ את הפקודה הבאה כדי לעשות זאת:
python -m venv venv source venv/bin/activate
זה ייצור ויפעיל סביבה וירטואלית. ברגע שהיא מופעלת, אתה מוכן להתקין את Metaflow.
Metaflow זמין כחבילת Python עבור MacOS ולינוקס. הגרסה האחרונה יכולה להיות מותקנת מ-מאגר ה-Github של Metaflow או מ-PyPi על ידי הרצת הפקודה הבאה:
pip install metaflow
לצערי, בזמן כתיבת שורות אלה, Metaflow לא מציעה תמיכה מקורית למשתמשי Windows. עם זאת, משתמשים עם Windows 10 יכולים להשתמש ב-WSL (תת מערכת Windows עבור לינוקס) כדי להתקין את Metaflow, מה שמאפשר להם להריץ סביבה לינוקס בתוך מערכת ההפעלה Windows שלהם. בדוק את התיעוד עבור מדריך שלב אחר שלב להתקנת Metaflow על Windows 10.
אינטגרציית AWS (אופציונלי)
Metaflow מציעה אינטגרציה חלקה עם AWS, המאפשרת למשתמשים להרחיב את זרימות העבודה שלהם באמצעות תשתית ענן. כדי לשלב את AWS, תצטרך להגדיר את האישורים שלך ל-AWS.
הערה: צעדים אלה מניחים שיש לך כבר חשבון AWS ו-AWS CLI מותקן. לפרטים נוספים, עקוב אחרי ההוראות בתיעוד AWS.
- ראשית, התקן את AWS CLI על ידי הרצה:
pip install awscli
- הגדר את AWS על ידי הרצה
aws configure
מכאן, תתבקש להזין את מזהה המפתח שלך ל-AWS ואת המפתח הסודי—אלו הם רק האישורים שה-AWS CLI משתמש בהם כדי לאמת את הבקשות שלך ל-AWS. שים לב שייתכן שתתבקש גם להזין את האזור שלך ואת פורמט הפלט.
ברגע שהזנת את הפרטים הללו, Voilà! Metaflow ישתמש אוטומטית באישורים שלך ל-AWS כדי להריץ את הזרימות.
בנית הזרימה הראשונה שלך עם Metaflow
עכשיו ש-Metaflow מוכן, הגיע הזמן לבנות את הזרימה הראשונה שלך. בחלק הזה, אדריך אותך בבסיסי יצירת זרימה, הרצתה, והבנת כיצד משימות ושלבים מאורגנים ב-Metaflow.
בתום החלק הזה, תהיה לך זרימה שמעבדת נתונים ומבצעת פעולות פשוטות. בוא נתחיל!
סקירה כללית של זרימה ב-Metaflow
Metaflow משתמש ב פרדיגמת זרימת נתונים, אשר מייצגת תוכנית כגרף מכוון של פעולות. גישה זו היא אידיאלית לבניית צינורות עיבוד נתונים, במיוחד ב למידת מכונה.
ב Metaflow, גרף הפעולות נקרא זרימה. זרימה מורכבת מסדרה של משימות המפוצלות לשלבים. שימו לב כי כל שלב יכול להיחשב כפעולה המיוצגת כצומת עם מעברים בין שלבים הפועלים כקצוות של הגרף.
מעבר ליניארי בסיסי במטאפלואו | מקור: תיעוד מטאפלואו
יש כמה כללים מבניים עבור זרמים במטאפלואו. לדוגמה, כל זרם חייב לכלול שלב התחלה ושלב סיום . כאשר זרם מתבצע, הידוע בשם הרצה, הוא מתחיל עם שלב ההתחלה ונחשב כמוצלח אם הוא מגיע לשלב הסיום ללא שגיאות.
מה שקורה בין שלב ההתחלה לשלב הסיום תלוי לגמרי בך – כפי שתראה בס segment הבא.
כתיבת הזרימה הראשונה שלך
הנה זרימה פשוטה כדי להתחיל. הערה: הקוד ניתן להרצה ב DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # דוגמת נתונים self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # עיבוד נתונים פשוט print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
בזרימה זו:
- שלב
start()מאתחל את זרימת העבודה ומגדיר אוסף נתונים. - שלב
process_data()מעבד את הנתונים על ידי הכפלת כל רכיב. - שלב
end()משלים את הזרימה.
כל שלב משתמש בקישוט @step, ואתה מגדיר את רצף הזרימה באמצעות self.next() כדי לחבר את השלבים.
הרצת הזרימה שלך
לאחר שכתבת את הזרימה שלך, שמור אותה כmy_first_flow.py. הרץ אותה משורת הפקודה באמצעות:
py -m my_first_flow.py run
תכונה חדשה נוספה ב-Metaflow 2.12 המאפשרת למשתמשים לפתח ולהריץ זרימות במחברות.
כדי להריץ זרימה בתא מוגדר, כל מה שעליך לעשות הוא להוסיף את השורה NBRunner בשורה האחרונה של אותו תא. לדוגמה:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # דוגמת נתונים self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # עיבוד נתונים פשוט print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
אם אתה מקבל את השגיאה הבאה:
“Metaflow לא הצליח לקבוע את שם המשתמש שלך על סמך משתני סביבה ($USERNAME וכו')”
הוסף את הבא לקוד שלך לפני הרצת Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
בשני המקרים, Metaflow יריץ את הזרימה שלב אחר שלב. כלומר, הוא יציג את פלט כל שלב בטרמינל כך:
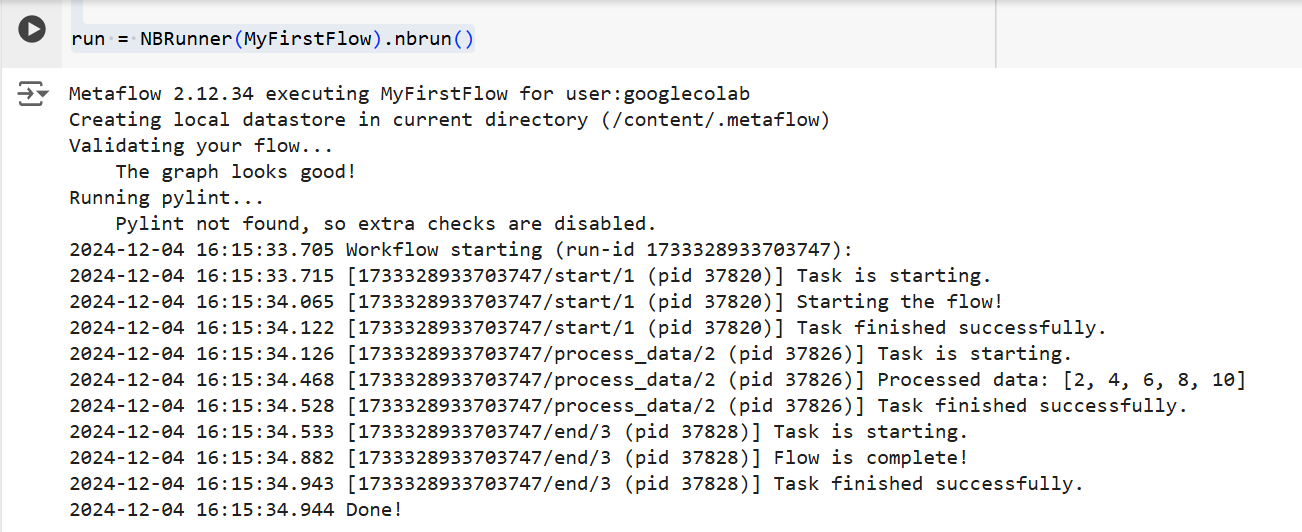
התוצר מהקוד למעלה | מקור: תמונה מאת המחבר
עקרונות בסיסיים במטאפלו
הבנת העקרונות הבסיסיים של מטאפלו היא חיונית לבניית זרימות עבודה נתונים יעילות וסקלאביליות. בסעיף זה, אני אכסה שלושה עקרונות יסוד:
- צעדים והתפצלויות
- מוצרי נתונים
- גרסה
אלמנטים אלו מהווים את עמוד השדרה של מבנה מטפלו וביצוע זרימות עבודה, ומאפשרים לך לנהל תהליכים מורכבים בקלות.
צעדים והתפצלויות
נגענו בקצרה ב-צעדים קודם לכן במאמר, אך לצורך הבהרה, נבקר בהם שוב. הדבר החשוב ביותר להבין על זרימות העבודה של מטפלו הוא שהן בנויות סביב צעדים.
צעדים מייצגים כל משימה אינדיבידואלית בתוך זרימת עבודה. במילים אחרות, כל צעד יבצע פעולה ספציפית (למשל, טעינת נתונים, עיבוד, מודלינג וכו').
הדוגמה שיצרנו למעלה ב"כתיבת הזרם הראשון שלך" הייתה טרנספורמציה ליניארית. בנוסף לצעדים רציפים, מטאפלואו גם מאפשר למשתמשים ל-להתפצל זרמים. זרמי התפצלות מאפשרים לך להריץ מספר משימות במקביל על ידי יצירת דרכים נפרדות לביצוע.
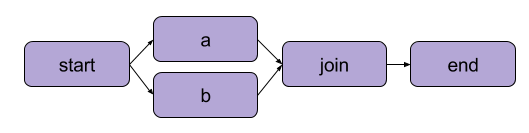
דוגמה להתפצלות | מקור: תיעוד מטאפלואו
היתרון המרכזי של התפצלות הוא ביצועים. התפצלות פירושה שמטאפלואו יכול לבצע צעדים שונים על פני מספר ליבות CPU או מופעים בענן.
הנה איך שהתפצלות תיראה בקוד:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # דוגמת מאגר נתונים self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # קוד עבור סניף 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # קוד עבור סניף 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # מיזוג סניפים חזרה print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡TLDR: סניפוד מאפשר למשתמשים לעצב זרימות עבודה מורכבות שיכולות לעבד בו זמנית משימות רבות. |
ארטיפקטים של נתונים
נתונים ארטיפקטים הם משתנים המאפשרים לך לאחסן ולהעביר נתונים בין שלבים בזרימת עבודה. הארטיפקטים הללו שומרים את הפלט של שלב אחד לשלב הבא—כך נתונים זמינים לשלבים הבאים.
בעצם, כאשר אתה מקצה נתונים לself בתוך צעד במעמד Metaflow, אתה שומר אותם כאובייקט, שניתן לגשת אליו על ידי כל צעד אחר בזרימה (ראה את ההערות בקוד).
class ArtifactFlow(FlowSpec): @step def start(self): # צעד 1: אתחול נתונים print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # קבוצת נתונים לדוגמה שנשמרה כאובייקט self.next(self.process_data) @step def process_data(self): # צעד 2: עיבוד הנתונים מצעד 'התחלה' self.processed_data = [x * 2 for x in self.data] # עיבוד נתוני האובייקט print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # צעד 3: שמירת אובייקט הנתונים המעובדים self.results = sum(self.processed_data) # שמירת התוצאה הסופית כאובייקט print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # צעד סופי print("Flow is complete!") print(f"Final result: {self.results}") # גישה לאובייקט בצעד הסופי
למה אובייקטים הם מושג ליבה של Metaflow? כי יש להם מספר שימושים:
- אוטומציה של ניהול זרימת נתונים, הסרת הצורך לטעון ולשמור נתונים באופן ידני.
- הפעלת התמדה (עוד על כך בהמשך), כלומר הם מאפשרים למשתמשים לבצע ניתוחים מאוחר יותר עם ה-Client API, להמחיש עם כרטיסים, ולנצל מחדש בזרימות.
- עקביות בין סביבות מקומיות לענן. זה מבטל את הצורך בהעברת נתונים מפורשת.
- מאפשר למשתמשים לבדוק נתונים לפני כישלונות ולהמשיך בביצועים לאחר תיקון באגים.
גרסה והתמדה
מטאפלו מטפל אוטומטית ב-גרסאות עבור הזרימות שלך. משמעות הדבר היא שבכל פעם שזרימה מתבצעת, היא מתועדת כריצה ייחודית. במילים אחרות, לכל ריצה יש את הגרסה שלה, מה שמאפשר לך בקלות לעבור על ריצות קודמות ולשחזר אותן.
מטאפלו עושה זאת על ידי הקצאת מזהים ייחודיים לכל ריצה ושימור הנתונים והאובייקטים מהביצוע ההוא. התמדה זו מבטיחה שלא יאבדו נתונים בין ריצות. זרימות קודמות יכולות בקלות להיבדק ולהיבחן, וצעד ספציפי יכול להתבצע מחדש אם יש צורך. כתוצאה מכך, דיבוג ופיתוח איטרטיבי הרבה יותר יעילים, ושמירה על יכולת שחזור הופכת לפשוטה יותר.
דוגמה מעשית: אימון מודל למידת מכונה
בקטע זה, אני אדריך אותך כיצד להשתמש במטאפלו כדי לאמן מודל למידת מכונה. תלמד כיצד:
- הגדר זרימת עבודה שמעמיסה נתונים
- אמן מודל למידת מכונה
- עקוב אחרי התוצאות
בסוף, תבין טוב יותר כיצד להשתמש ב-Metaflow כדי לבנות ולהפעיל זרימות עבודה של למידת מכונה בצורה יעילה. בוא נתחיל!
כדי להתחיל, ניצור זרימה בסיסית שמעמיסה מערך נתונים, מבצעת אימון, ומפיקה את התוצאות של המודל.
הערה: הקוד ניתן להרצה בDataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # טען וחלק את מערך הנתונים print("Loading data...") self.data = [1, 2, 3, 4, 5] # החלף בלוגיקת טעינת נתונים אמיתית self.labels = [0, 1, 0, 1, 0] # החלף עם תוויות self.next(self.train_model) @step def train_model(self): # אימון מודל פשוט (למשל, רגרסיה ליניארית) print("Training the model...") self.model = sum(self.data) / len(self.data) # החלף עם אימון מודל אמיתי print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # שלב סופי print("Training complete. Model ready for deployment!")f
בקוד הזה, אנו מגדירים שלושה שלבים:
start(): טוען ומחלק את מערך הנתונים. בסcenario אמיתי, היית טוען נתונים ממקור אמיתי (למשל, קובץ או מסד נתונים).train_model(): מדמה את אימון המודל. כאן, מתבצע חישוב ממוצע פשוט במקום אלגוריתם למידת מכונה אמיתי, אך תוכל להחליף זאת בכל קוד אימון שאתה צריך.end(): מסמן את סיום הזרימה ומצביע על כך שהמודל מוכן לפריסה.
ברגע שהגדרת את הזרימה, תוכל להריץ אותה באמצעות הפקודה הבאה:
run = NBRunner(TrainModelFlow) run.nbrun()
שים לב שהקוד הזה עובד רק במחברות (כל הקוד חייב להיות בתא אחד).
אם אתה רוצה להריץ את הקוד הזה כסקрипט, הסר את הפקודות NBRunner וחבר את הבא לסוף הסקריפט שלך, ושמור אותו (למשל, “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
לאחר מכן, כדי להריץ את הסקריפט, נווט אל שורת הפקודה והרץ את הפקודה הבאה:
py -m metaflow_ml_model.py
מטאפלו עוקב אוטומטית אחרי כל ריצה ומאפשר לך לדמיין תוצאות באמצעות ממשק המשתמש של מטאפלו.
שיטות עבודה מומלצות לשימוש במטאפלו
אז, איך אנחנו יכולים לנצל את תכונות מטאפלו בצורה הטובה ביותר? הנה כמה שיטות עבודה מומלצות שיכולות לעזור לך להשיג את המטרה הזו תוך אופטימיזציה של זרימות העבודה שלך במקביל:
תחל עם זרימות קטנות
אם אתה חדש במטאפלו, התחל עם זרימות עבודה פשוטות כדי להכיר את ה-API שלה. התחלה קטנה תעזור לך להבין איך המערכת פועלת ולבנות ביטחון ביכולות שלה לפני המעבר לפרויקטים מורכבים יותר. גישה זו מפחיתה את עקומת הלמידה ומבטיחה שהבסיס שלך יהיה יציב.
נצל את ממשק המשתמש של מטאפלו לניפוי שגיאות
מטאפלואו כולל ממשק משתמשחזק שיכול להיות מסייע מאוד לאיתור בעיות ומעקב אחרי זרימות העבודה שלך. השתמש בממשק כדי לנטר ריצות, לבדוק את הפלטים של צעדים בודדים, ולזהות כל בעיה שעשויה להתעורר. חזות הנתונים והיומנים שלך מקלה על זיהוי ותיקון בעיות במהלך ביצוע הזרימה שלך.
נצל את AWS לצורך סקלאביליות
כאשר אתה מתקין לראשונה את Mטאפלואו, הוא פועל במצב מקומי. במצב זה, חפצים ומטאדאטה נשמרים בתיקייה מקומית, וחישובים מתבצעים באמצעות תהליכים מקומיים. הגדרה זו מתאימה היטב לשימוש אישי, אך אם הפרויקט שלך כולל שיתוף פעולה או מערכות נתונים גדולות, מומלץ להגדיר את מטאפלואו להשתמש ב-AWS לצורך סקלאביליות טובה יותר. הדבר הטוב כאן הוא שמטאפלואו מספק אינטגרציה מצוינת עם AWS.
סיכום
במדריך זה, חקרנו כיצד להתחיל עם Metaflow, מההתקנה ועד לבניית זרימת העבודה הראשונה שלך במדע הנתונים. כיסינו את המונחים הבסיסיים, כגון הגדרת שלבים, שימוש בארטיפקטים של נתונים להעברת נתונים בין שלבים, וגרסה כדי לעקוב ולשחזר ריצות. כמו כן, עברנו על דוגמה מעשית של אימון מודל למידת מכונה, שהדגימה כיצד להגדיר, להריץ ולעקוב אחרי זרימת העבודה שלך. לבסוף, נגענו בכמה שיטות עבודה מומלצות שיעזרו לך להפיק את המרב מ-Metaflow.
כדי להמשיך את הלמידה שלך על MLOps, בדוק את המשאבים הבאים: