













Metaflow ist ein leistungsstarkes Framework für den Aufbau und die Verwaltung von Datenworkflows. In diesem Tutorial erfahren Sie, wie Sie beginnen können. Insbesondere werden wir folgende Punkte behandeln:
- Der Installationsprozess
- Erstellung eines grundlegenden Workflows
- Kernkonzepte
- Best Practices
Am Ende dieses Artikels werden Sie über die erforderlichen Fähigkeiten verfügen, um Ihre Workflows effizient zu optimieren und zu skalieren!
Was ist Metaflow?

Quelle: Warum Metaflow?
Metaflow ist ein Python-Framework, das entwickelt wurde, um das Management von Data-Science-Projekten zu unterstützen. Netflix hat das Tool ursprünglich entwickelt, um Data Scientists und Machine Learning Engineers produktiver zu machen. Dies wird erreicht, indem komplexe Aufgaben wie die Orchestrierung von Workflows vereinfacht werden, was sicherstellt, dass die Prozesse reibungslos von Anfang bis Ende ablaufen.
Zu den Hauptmerkmalen von Metaflow gehören automatische Datenversionierung, die Änderungen an Ihren Workflows verfolgt, und Unterstützung für skalierbare Workflows, die es den Nutzern ermöglicht, größere Datensätze und komplexere Aufgaben zu bewältigen.
Ein weiterer Vorteil von Metaflow ist, dass es sich leicht in AWS integrieren lässt. Das bedeutet, dass Benutzer Cloud-Ressourcen für Speicher und Rechenleistung nutzen können. Darüber hinaus macht die benutzerfreundliche Python-API es sowohl für Anfänger als auch für erfahrene Benutzer zugänglich.
Lasst uns mit der Einrichtung beginnen.
Metaflow einrichten
Metaflo empfiehlt, dass Benutzer Python 3 anstelle von Python 2.7 für neue Projekte installieren. Die Dokumentation besagt, dass „Python 3 weniger Fehler hat und besser unterstützt wird als das veraltete Python 2.7.“
Der nächste Schritt besteht darin, eine virtuelle Umgebung zu erstellen, um die Abhängigkeiten Ihres Projekts zu verwalten. Führen Sie den folgenden Befehl aus, um dies zu tun:
python -m venv venv source venv/bin/activate
Dies wird eine virtuelle Umgebung erstellen und aktivieren. Sobald aktiviert, können Sie Metaflow installieren.
Metaflow ist als Python-Paket für macOS und Linux verfügbar. Die neueste Version kann aus dem Metaflow Github-Repository oder über PyPi durch Ausführen des folgenden Befehls installiert werden:
pip install metaflow
Zum Zeitpunkt des Verfassens bietet Metaflow leider keine native Unterstützung für Windows-Benutzer an. Benutzer mit Windows 10 können jedoch WSL (Windows-Subsystem für Linux) verwenden, um Metaflow zu installieren, was es ihnen ermöglicht, eine Linux-Umgebung innerhalb ihres Windows-Betriebssystems auszuführen. Schauen Sie sich die Dokumentation für eine schrittweise Anleitung zur Installation von Metaflow unter Windows 10 an.
AWS-Integration (Optional)
Metaflow bietet nahtlose Integration mit AWS, was es Benutzern ermöglicht, ihre Workflows mit Cloud-Infrastruktur zu skalieren. Um AWS zu integrieren, müssen Sie Ihre AWS-Anmeldeinformationen einrichten.
Hinweis: Diese Schritte setzen voraus, dass Sie bereits ein AWS-Konto und die AWS CLI installiert haben. Für weitere Details, folgen Sie den Anweisungen in der AWS-Dokumentation.
- Zuerst installieren Sie die AWS CLI, indem Sie Folgendes ausführen:
pip install awscli
- Konfigurieren Sie AWS, indem Sie Folgendes ausführen
aws configure
Von hier aus werden Sie aufgefordert, Ihre AWS Access Key ID und Secret Access Key einzugeben – dies sind einfach die Anmeldeinformationen, die die AWS CLI verwendet, um Ihre Anfragen an AWS zu authentifizieren. Beachten Sie, dass Sie möglicherweise auch aufgefordert werden, Ihre Region und das Ausgabeformat einzugeben.
Sobald Sie diese Angaben eingegeben haben, voila! Metaflow wird automatisch Ihre AWS-Anmeldeinformationen verwenden, um Workflows auszuführen.
Erstellen Ihres ersten Workflows mit Metaflow
Jetzt, da Metaflow eingerichtet ist, ist es Zeit, Ihren ersten Workflow zu erstellen. In diesem Abschnitt werde ich Sie durch die Grundlagen der Erstellung eines Flows, dessen Ausführung und das Verständnis, wie Aufgaben und Schritte in Metaflow organisiert sind, führen.
Am Ende dieses Abschnitts werden Sie einen Workflow haben, der Daten verarbeitet und einfache Operationen durchführt. Los geht’s!
Überblick über einen Metaflow-Flow
Metaflow verwendet das Datenfluss-Paradigma, das ein Programm als einen gerichteten Graphen von Operationen darstellt. Dieser Ansatz ist ideal für den Aufbau von Datenverarbeitungs-Pipelines, insbesondere im Bereich Maschinelles Lernen.
In Metaflow wird der Graph der Operationen als Flowbezeichnet. Ein Flow besteht aus einer Reihe von Aufgaben, die in Schritte unterteilt sind. Beachten Sie, dass jeder Schritt als eine Operation betrachtet werden kann, die als Knoten dargestellt wird, wobei die Übergänge zwischen den Schritten als die Kanten des Graphen fungieren.
Eine grundlegende lineare Übergang in Metaflow | Quelle: Metaflow-Dokumentation
Es gibt einige strukturelle Regeln für Flows in Metaflow. Zum Beispiel muss jeder Flow einen start Schritt und einen end Schritt enthalten. Wenn ein Flow ausgeführt wird, auch bekannt als ein run, beginnt er mit dem Startschritt und wird als erfolgreich angesehen, wenn er den Endschritt ohne Fehler erreicht.
Was zwischen den Start- und Endschritten passiert, liegt ganz bei Ihnen – wie Sie im nächsten Segment sehen werden.
Schreiben Ihres ersten Flows
Hier ist ein einfacher Flow, um zu beginnen.Hinweis: Der Code kann in DataLab ausgeführt werden.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Beispiel-Datensatz self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Einfache Datenverarbeitung print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
In diesem Flow:
- Der
start()-Schritt initialisiert den Workflow und definiert einen Datensatz. - Der
process_data()-Schritt verarbeitet die Daten, indem er jedes Element verdoppelt. - Der
end()-Schritt beendet den Ablauf.
Jeder Schritt verwendet den @step-Dekorator, und Sie definieren die Ablaufsequenz mit self.next(), um die Schritte zu verbinden.
Ausführen Ihres Ablaufs
Nachdem Sie Ihren Ablauf geschrieben haben, speichern Sie ihn als my_first_flow.py. Führen Sie ihn über die Befehlszeile aus mit:
py -m my_first_flow.py run
Eine neue Funktion wurde in Metaflow 2.12 hinzugefügt, die es Benutzern ermöglicht, Abläufe in Notebooks zu entwickeln und auszuführen.
Um einen Flow in einer definierten Zelle auszuführen, müssen Sie lediglich die NBRunner Einzeile in die letzte Zeile derselben Zelle einfügen. Zum Beispiel:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Beispiel-Datensatz self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Einfache Datenverarbeitung print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Wenn Sie den folgenden Fehler erhalten:
„Metaflow konnte Ihren Benutzernamen nicht basierend auf Umgebungsvariablen ($USERNAME usw.) bestimmen“
Fügen Sie Folgendes zu Ihrem Code hinzu, bevor Sie Metaflow ausführen:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
In beiden Fällen wird Metaflow den Flow Schritt für Schritt ausführen. Nämlich, es wird die Ausgabe jedes Schrittes im Terminal wie folgt anzeigen:
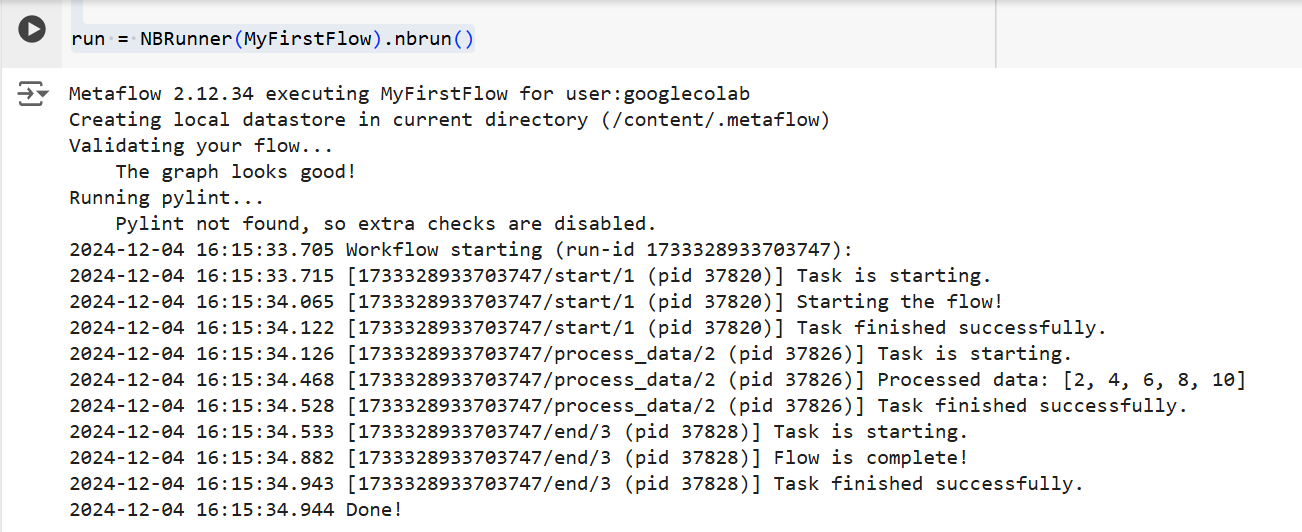
Die Ausgabe des obigen Codes |Quelle:Bild von Autor
Kernkonzepte in Metaflow
Das Verständnis der Kernkonzepte von Metaflow ist entscheidend für den Aufbau effizienter und skalierbarer Datenworkflows. In diesem Abschnitt werde ich drei grundlegende Konzepte behandeln:
- Schritte und Verzweigungen
- Datenartefakte
- Versionierung
Diese Elemente bilden das Rückgrat der Struktur und Ausführung von Workflows in Metaflow und ermöglichen es Ihnen, komplexe Prozesse einfach zu verwalten.
Schritte und Verzweigungen
Wir haben Schritte bereits kurz im Artikel angesprochen, aber zur Klarheit werden wir sie erneut betrachten. Das Wichtigste, was man über Metaflow-Workflows verstehen sollte, ist, dass sie um Schritte herum aufgebaut sind.
Schritte repräsentieren jede einzelne Aufgabe innerhalb eines Workflows. Mit anderen Worten, jeder Schritt führt eine spezifische Operation aus (z. B. Datenladen, Verarbeitung, Modellierung usw.).
Das Beispiel, das wir oben in „Schreiben Sie Ihren ersten Flow“ erstellt haben, war eine lineare Transformation. Neben sequenziellen Schritten ermöglicht Metaflow den Benutzern auch, Zweige von Workflows zu erstellen. Zweig-Workflows ermöglichen es Ihnen, mehrere Aufgaben parallel auszuführen, indem Sie separate Ausführungswege erstellen.
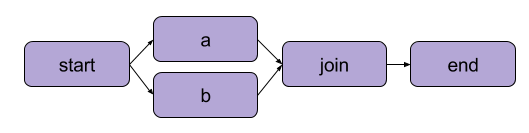
Ein Beispiel für einen Zweig | Quelle: Metaflow-Dokumentation
Der größte Vorteil eines Zweigs ist die Leistung. Branching bedeutet, dass Metaflow verschiedene Schritte über mehrere CPU-Kerne oder Instanzen in der Cloud ausführen kann.
So würde ein Zweig im Code aussehen:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Beispiel-Datensatz self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Code für Branch 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Code für Branch 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Zusammenführen von Branches print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡Zusammenfassung: Branching ermöglicht es Benutzern, komplexe Workflows zu entwerfen, die gleichzeitig mehrere Aufgaben verarbeiten können. |
Datenartefakte
Daten artefakte sind Variablen, die es Ihnen ermöglichen, Daten zwischen den Schritten in einem Workflow zu speichern und weiterzugeben. Diese Artefakte bewahren die Ausgabe eines Schrittes für den nächsten—so wird Daten für nachfolgende Schritte verfügbar gemacht.
Im Wesentlichen speichern Sie Daten als Artefakt, wenn Sie sie in einem Schritt in einer Metaflow-Klasse self zuweisen, und können dann von jedem anderen Schritt im Ablauf darauf zugegriffen werden (siehe die Kommentare im Code).
class ArtifactFlow(FlowSpec): @step def start(self): # Schritt 1: Initialisierung der Daten print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Beispiel-Datensatz als Artefakt gespeichert self.next(self.process_data) @step def process_data(self): # Schritt 2: Verarbeitung der Daten aus dem Schritt 'start' self.processed_data = [x * 2 for x in self.data] # Verarbeitung von Artefaktdaten print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Schritt 3: Speichern des verarbeiteten Datenartefakts self.results = sum(self.processed_data) # Speichern des endgültigen Ergebnisses als Artefakt print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Letzter Schritt print("Flow is complete!") print(f"Final result: {self.results}") # Zugriff auf Artefakte im letzten Schritt
Warum sind Artefakte ein Kernkonzept von Metaflow? Weil sie eine Reihe von Anwendungen haben:
- Automatisierung des Datenflussmanagements, Beseitigung der Notwendigkeit, Daten manuell zu laden und zu speichern.
- Die Aktivierung der Persistenz (mehr dazu gleich), was bedeutet, dass sie es den Benutzern ermöglicht, später mit der Client-API Analysen durchzuführen, mit Karten zu visualisieren und in verschiedenen Flows wiederzuverwenden.
- Konsistenz zwischen lokalen und Cloud-Umgebungen. Dies eliminiert die Notwendigkeit für explizite Datenübertragungen.
- Benutzern zu ermöglichen, Daten vor Fehlern zu inspizieren und die Ausführungen nach der Behebung von Fehlern fortzusetzen.
Versionierung und Persistenz
Metaflow verwaltet automatisch Versionierung für Ihre Workflows. Das bedeutet, dass jede Ausführung eines Flows als ein einzigartiger Lauf verfolgt wird. Mit anderen Worten, jeder Lauf hat seine eigene Version, sodass Sie vergangene Läufe leicht überprüfen und reproduzieren können.
Metaflow erreicht dies, indem es jedem Lauf einzigartige Identifikatoren zuweist und die Daten und Artefakte aus dieser Ausführung bewahrt. Diese Persistenz stellt sicher, dass keine Daten zwischen den Läufen verloren gehen. Vergangene Workflows können leicht erneut besucht und inspiziert werden, und spezifische Schritte können bei Bedarf wiederholt werden. Infolgedessen sind Debugging und iterative Entwicklung wesentlich effizienter, und die Aufrechterhaltung der Reproduzierbarkeit wird vereinfacht.
Praktisches Beispiel: Training eines Machine Learning Modells
In diesem Abschnitt werde ich Sie durch die Verwendung von Metaflow führen, um ein Machine Learning Modell zu trainieren. Sie werden lernen, wie man:
- Definieren Sie einen Workflow, der Daten lädt
- Ein Machine-Learning-Modell trainieren
- Die Ergebnisse verfolgen
Am Ende werden Sie besser verstehen, wie Sie Metaflow verwenden können, um Machine-Learning-Workflows effizient zu strukturieren und auszuführen. Los geht’s!
Zu Beginn werden wir einen grundlegenden Ablauf erstellen, der ein Dataset lädt, das Training durchführt und die Ergebnisse des Modells ausgibt.
Hinweis: Der Code kann in DataLab ausgeführt werden.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Laden und Aufteilen des Datensatzes print("Loading data...") self.data = [1, 2, 3, 4, 5] # Ersetzen durch die tatsächliche Logik zum Laden von Daten self.labels = [0, 1, 0, 1, 0] # Ersetzen durch Labels self.next(self.train_model) @step def train_model(self): # Training eines einfachen Modells (z.B. lineare Regression) print("Training the model...") self.model = sum(self.data) / len(self.data) # Ersetzen durch das tatsächliche Modelltraining print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Letzter Schritt print("Training complete. Model ready for deployment!")f
In diesem Code definieren wir drei Schritte:
start(): Lädt und teilt den Datensatz auf. In einem realen Szenario würden Sie Daten aus einer tatsächlichen Quelle laden (z.B. einer Datei oder Datenbank).train_model(): Simuliert das Training eines Modells. Hier wird anstelle eines tatsächlichen Machine-Learning-Algorithmus eine einfache Durchschnittsberechnung durchgeführt, aber Sie können dies durch jeden benötigten Trainingscode ersetzen.end(): Markiert das Ende des Flows und zeigt an, dass das Modell bereit für die Bereitstellung ist.
Sobald Sie den Flow definiert haben, können Sie ihn mit dem folgenden Befehl ausführen:
run = NBRunner(TrainModelFlow) run.nbrun()
Bitte beachten Sie, dass dieser Code nur in Notebooks funktioniert (der gesamte Code muss in einer Zelle sein).
Wenn Sie diesen Code als Skript ausführen möchten, entfernen Sie die NBRunner-Befehle und fügen Sie Folgendes an das Ende Ihres Skripts an und speichern Sie es (z.B. “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Um das Skript dann auszuführen, navigieren Sie zur Eingabeaufforderung und führen Sie den folgenden Befehl aus:
py -m metaflow_ml_model.py
Metaflow verfolgt automatisch jeden Lauf und ermöglicht es Ihnen, Ergebnisse durch die Metaflow-Benutzeroberfläche zu visualisieren.
Beste Praktiken für die Nutzung von Metaflow
Wie können wir die Funktionen von Metaflow optimal nutzen? Hier sind einige bewährte Praktiken, die Ihnen helfen können, dies zu erreichen und gleichzeitig Ihre Arbeitsabläufe zu optimieren:
Beginnen Sie mit kleinen Flows
Wenn Sie neu bei Metaflow sind, beginnen Sie mit einfachen Arbeitsabläufen, um sich mit der API vertraut zu machen. Klein anzufangen hilft Ihnen, zu verstehen, wie das Framework funktioniert, und das Vertrauen in seine Fähigkeiten aufzubauen, bevor Sie zu komplexeren Projekten übergehen. Dieser Ansatz verringert die Lernkurve und stellt sicher, dass Ihre Grundlagen solide sind.
Nutzen Sie die UI von Metaflow zum Debuggen
Metaflow umfasst eine mächtige Benutzeroberfläche, die äußerst hilfreich für das Debugging und die Verfolgung Ihrer Workflows sein kann. Nutzen Sie die UI, um Ausführungen zu überwachen, die Ausgaben einzelner Schritte zu überprüfen und etwaige Probleme zu identifizieren, die auftreten könnten. Die Visualisierung Ihrer Daten und Protokolle erleichtert es, Probleme während der Ausführung Ihres Flows zu erkennen und zu beheben.
Nutzen Sie AWS für Skalierbarkeit
Wenn Sie Metaflow zum ersten Mal installieren, arbeitet es im lokalen Modus. In diesem Modus werden Artefakte und Metadaten in einem lokalen Verzeichnis gespeichert, und Berechnungen werden mit lokalen Prozessen durchgeführt. Diese Konfiguration eignet sich gut für die persönliche Nutzung, aber wenn Ihr Projekt Zusammenarbeit oder große Datensätze umfasst, ist es ratsam, Metaflow so zu konfigurieren, dass es AWS für bessere Skalierbarkeit nutzt. Der Vorteil hierbei ist, dass Metaflow eine hervorragende Integration mit AWS bietet.
Fazit
In diesem Tutorial haben wir erkundet, wie man mit Metaflow beginnt, von der Installation bis zum Aufbau Ihres ersten Data-Science-Workflows. Wir haben die Kernkonzepte behandelt, wie das Definieren von Schritten, die Verwendung von Datenartefakten, um Daten zwischen den Schritten weiterzugeben, und das Versionieren, um Ausführungen zu verfolgen und zu reproduzieren. Außerdem haben wir ein praktisches Beispiel für das Training eines maschinellen Lernmodells durchgearbeitet, das demonstrierte, wie man seinen Workflow definiert, ausführt und überwacht. Zuletzt haben wir einige bewährte Praktiken angesprochen, die Ihnen helfen, das Beste aus Metaflow herauszuholen.
Um Ihr Wissen über MLOps fortzusetzen, schauen Sie sich die folgenden Ressourcen an: