













Metaflow — это мощный фреймворк для создания и управления рабочими процессами с данными. В этом руководстве вы узнаете, как начать. А именно, мы коснемся:
- Процесса установки
- Создания базового рабочего процесса
- Основных концепций
- Лучших практик
К концу этой статьи у вас будут необходимые навыки для эффективной оптимизации и масштабирования ваших рабочих процессов!
Что такое Metaflow?

Источник: Почему Metaflow?
Metaflow – это фреймворк на Python, разработанный для управления проектами в областиData Science. Инструмент был изначально разработан компанией Netflix, чтобы помочь специалистам по данным и инженерам машинного обучения повысить свою продуктивность. Он достигает этой цели, упрощая сложные задачи, такие как оркестрация рабочих процессов, что гарантирует, что процессы проходят гладко от начала до конца.
Ключевые особенности Metaflow включают автоматическую версионирование данных, которое отслеживает изменения в ваших рабочих процессах, и поддержку масштабируемых рабочих процессов, что позволяет пользователям обрабатывать более крупные наборы данных и более сложные задачи.
Еще одно преимущество Metaflow заключается в том, что он легко интегрируется с AWS. Это означает, что пользователи могут использовать облачные ресурсы для хранения и вычислительной мощности. Кроме того, его удобный Python API делает его доступным как для начинающих, так и для опытных пользователей.
Давайте начнем с его настройки.
Настройка Metaflow
Metaflow рекомендует пользователям устанавливать Python 3 вместо Python 2.7 для новых проектов. Документация утверждает, что «Python 3 имеет меньше ошибок и лучше поддерживается, чем устаревший Python 2.7.»
Следующий шаг — создать виртуальное окружение для управления зависимостями вашего проекта. Выполните следующую команду для этого:
python -m venv venv source venv/bin/activate
Это создаст и активирует виртуальную среду. После активации вы готовы установить Metaflow.
Metaflow доступен как пакет Python для MacOS и Linux. Последнюю версию можно установить из репозитория Metaflow на Github или PyPi, выполнив следующую команду:
pip install metaflow
К сожалению, на момент написания Metaflow не предлагает нативной поддержки для пользователей Windows. Однако пользователи Windows 10 могут использовать WSL (Подсистема Windows для Linux) для установки Metaflow, что позволяет им запускать среду Linux внутри своей операционной системы Windows. Ознакомьтесь с документацией для пошагового руководства по установке Metaflow на Windows 10.
Интеграция с AWS (по желанию)
Metaflow предлагает бесшовную интеграцию с AWS, что позволяет пользователям масштабировать свои рабочие процессы с использованием облачной инфраструктуры. Для интеграции с AWS вам необходимо настроить свои учетные данные AWS.
Примечание: Эти шаги предполагают, что у вас уже есть учетная запись AWS и установленный AWS CLI. Для получения дополнительной информации следуйте инструкциям в документации AWS.
- Сначала установите AWS CLI, выполнив:
pip install awscli
- Настройте AWS, выполнив
aws configure
С этого момента вам будет предложено ввести ваш AWS Access Key ID и Secret Access Key — это просто учетные данные, которые AWS CLI использует для аутентификации ваших запросов к AWS. Обратите внимание, что вам также может быть предложено ввести ваш регион и формат вывода.
Как только вы введете эти данные, вуаля! Metaflow автоматически использует ваши учетные данные AWS для выполнения рабочих процессов.
Создание вашего первого рабочего процесса с Metaflow
Теперь, когда Metaflow настроен, пора создать ваш первый рабочий процесс. В этом разделе я проведу вас через основы создания потока, его выполнения и понимания того, как задачи и шаги организованы в Metaflow.
К концу этого раздела у вас будет рабочий процесс, который обрабатывает данные и выполняет простые операции. Поехали!
Обзор потока Metaflow
Metaflow использует парадигму потоков данных, которая представляет программу в виде направленного графа операций. Этот подход идеально подходит для построения конвейеров обработки данных, особенно в машинном обучении.
В Metaflow граф операций называется потоком. Поток состоит из серии задач, разбитых на этапы. Обратите внимание, что каждый этап можно рассматривать как операцию, представленную в виде узла, а переходы между этапами действуют как ребра графа.
Основной линейный переход Metaflow | Источник: Документация Metaflow
Существуют несколько структурных правил для потоков в Metaflow. Например, каждый поток должен включать шаг start и шаг end. Когда поток выполняется, что называется run, он начинается с шага start и считается успешным, если достигает шага end без ошибок.
Что происходит между начальным и конечным шагами, полностью зависит от вас – как вы увидите в следующем сегменте.
Написание вашего первого потока
Вот простой поток, чтобы начать.Примечание: Код может быть выполнен в DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Пример набора данных self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Простая обработка данных print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
В этом потоке:
- Шаг
start()инициализирует рабочий процесс и определяет набор данных. - Шаг
process_data()обрабатывает данные, удваивая каждый элемент. - Шаг
end()завершает поток.
Каждый шаг использует декоратор @step, и вы определяете последовательность шагов, используя self.next() для соединения шагов.
Запуск вашего потока
После написания вашего потока сохраните его как my_first_flow.py. Запустите его из командной строки, используя:
py -m my_first_flow.py run
В Metaflow 2.12 была добавлена новая функция, которая позволяет пользователям разрабатывать и выполнять потоки в блокнотах.
Чтобы выполнить поток в определенной ячейке, вам нужно просто добавить однострочный код NBRunner в последней строке той же ячейки. Например:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Пример набора данных self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Простой процесс обработки данных print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Если вы получите следующую ошибку:
“Metaflow не смог определить ваше имя пользователя на основе переменных окружения ($USERNAME и т.д.)”
Добавьте следующее в ваш код перед выполнением Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
В обоих случаях Metaflow будет выполнять поток шаг за шагом. А именно, он будет отображать вывод каждого шага в терминале следующим образом:
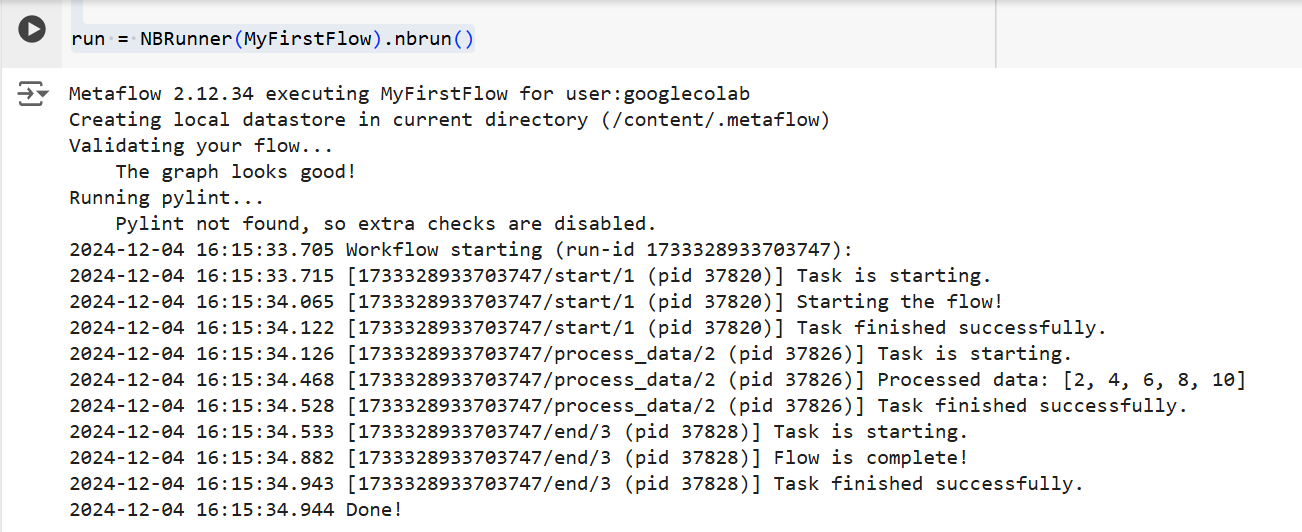
Вывод из приведенного выше кода | Источник: Изображение авторства
Основные концепции в Metaflow
Понимание основных концепций Metaflow имеет важное значение для создания эффективных и масштабируемых рабочих процессов с данными. В этом разделе я рассмотрю три основных концепции:
- Шаги и ветвление
- Артефакты данных
- Версионирование
Эти элементы составляют основу структуры Metaflow и выполнения рабочих процессов, позволяя вам легко управлять сложными процессами.
Этапы и ветвление
Мы кратко упоминали о этапах ранее в статье, но для ясности мы снова к ним вернемся. Самое важное, что нужно понять о рабочих процессах Metaflow, это то, что они строятся вокруг этапов.
Этапы представляют собой каждую отдельную задачу в рамках рабочего процесса. Другими словами, каждый этап выполняет конкретную операцию (например, загрузка данных, обработка, моделирование и т.д.).
Пример, который мы создали выше в разделе «Написание вашего первого потока», был линейной трансформацией. В дополнение к последовательным шагам Metaflow также позволяет пользователям разветвлять рабочие процессы. Разветвленные рабочие процессы позволяют вам выполнять несколько задач параллельно, создавая отдельные пути для выполнения.
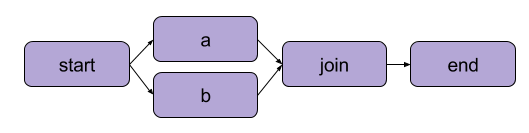
Пример разветвления | Источник: Документация Metaflow
Основное преимущество разветвления – это производительность. Разветвление означает, что Metaflow может выполнять различные шаги на нескольких ядрах CPU или экземплярах в облаке.
Вот как будет выглядеть разветвление в коде:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Пример набора данных self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Код для ветки 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Код для ветки 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Слияние веток print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡Кратко: Ветвление позволяет пользователям разрабатывать сложные рабочие процессы, которые могут одновременно обрабатывать несколько задач. |
Артефакты данных
Данные артефакты — это переменные, которые позволяют хранить и передавать данные между этапами рабочего процесса. Эти артефакты сохраняют вывод одного шага для следующего — так данные становятся доступными для последующих шагов.
По сути, когда вы присваиваете данные self в шаге класса Metaflow, вы сохраняете их в качестве артефакта, к которому затем может получить доступ любой другой шаг в потоке (см. комментарии в коде).
class ArtifactFlow(FlowSpec): @step def start(self): # Шаг 1: Инициализация данных print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Пример набора данных, сохраненного как артефакт self.next(self.process_data) @step def process_data(self): # Шаг 2: Обработка данных из шага 'start' self.processed_data = [x * 2 for x in self.data] # Обработка данных артефакта print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Шаг 3: Сохранение обработанного артефакта данных self.results = sum(self.processed_data) # Сохранение конечного результата как артефакта print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Заключительный шаг print("Flow is complete!") print(f"Final result: {self.results}") # Доступ к артефакту на заключительном шаге
Почему артефакты являются ключевым понятием Metaflow? Потому что они имеют ряд применений:
- Автоматизация управления потоком данных, исключая необходимость вручную загружать и хранить данные.
- Включение постоянства (подробности об этом далее), что означает, что они позволяют пользователям проводить анализ позже с помощью Client API, визуализировать с помощью карт и повторно использовать в потоках.
- Согласованность между локальными и облачными средами. Это устраняет необходимость в явной передаче данных.
- Позволяет пользователям проверять данные перед сбоями и возобновлять выполнение после исправления ошибок.
Версионирование и постоянство
Metaflow автоматически управляет версионированием ваших рабочих процессов. Это означает, что каждый раз, когда поток выполняется, он отслеживается как уникальный запуск. Другими словами, каждый запуск имеет свою версию, что позволяет вам легко просматривать и воспроизводить предыдущие запуски.
Metaflow делает это, присваивая уникальные идентификаторы каждому запуску и сохраняя данные и артефакты этого выполнения. Эта постоянная доступность гарантирует, что данные не теряются между запусками. Прошлые рабочие процессы можно легко пересмотреть и проверить, а конкретные шаги можно повторно выполнить при необходимости. В результате отладка и итеративная разработка становятся гораздо более эффективными, а поддержание воспроизводимости упрощается.
Практический пример: Обучение модели машинного обучения
В этом разделе я покажу вам, как использовать Metaflow для обучения модели машинного обучения. Вы узнаете, как:
- Определите поток работы, который загружает данные
- Обучите модель машинного обучения
- Отслеживайте результаты
В конце вы лучше поймете, как использовать Metaflow для структурирования и эффективного выполнения рабочих процессов машинного обучения. Давайте начнем!
Сначала мы создадим базовый поток, который загружает набор данных, выполняет обучение и выводит результаты модели.
Примечание: Код можно выполнить в DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Загрузка и разделение набора данных print("Loading data...") self.data = [1, 2, 3, 4, 5] # Замените на фактическую логику загрузки данных self.labels = [0, 1, 0, 1, 0] # Замените на метки self.next(self.train_model) @step def train_model(self): # Обучение простой модели (например, линейная регрессия) print("Training the model...") self.model = sum(self.data) / len(self.data) # Замените на фактическое обучение модели print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Финальный шаг print("Training complete. Model ready for deployment!")f
В этом коде мы определяем три шага:
start(): Загружает и разделяет набор данных. В реальном сценарии вы бы загружали данные из фактического источника (например, файла или базы данных).train_model(): Симулирует обучение модели. Здесь выполняется простое вычисление среднего вместо фактического алгоритма машинного обучения, но вы можете заменить это на любой код обучения, который вам нужен.end(): Обозначает конец потока и указывает, что модель готова к развертыванию.
После того как вы определили поток, вы можете запустить его, используя следующую команду:
run = NBRunner(TrainModelFlow) run.nbrun()
Обратите внимание, что этот код работает только в ноутбуках (весь код должен быть в одной ячейке).
Если вы хотите запустить этот код как скрипт, удалите команды NBRunner и добавьте следующее в конец вашего скрипта, затем сохраните его (например, “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Затем, чтобы запустить скрипт, перейдите в командную строку и выполните следующую команду:
py -m metaflow_ml_model.py
Metaflow автоматически отслеживает каждую сессию и позволяет вам визуализировать результаты через интерфейс Metaflow.
Лучшие практики использования Metaflow
Итак, как мы можем максимально использовать возможности Metaflow? Вот несколько лучших практик, которые могут помочь вам достичь этой цели, одновременно оптимизируя ваши рабочие процессы:
Начните с небольших потоков
Если вы новичок в Metaflow, начните с простых рабочих процессов, чтобы ознакомиться с его API. Начало с малого поможет вам понять, как работает фреймворк, и повысить уверенность в его возможностях, прежде чем переходить к более сложным проектам. Этот подход уменьшает кривую обучения и гарантирует, что ваша основа прочна.
Используйте интерфейс Metaflow для отладки
Metaflow включает в себя мощный интерфейс пользователя, который может быть крайне полезным для отладки и отслеживания ваших рабочих процессов. Используйте интерфейс для мониторинга запусков, проверки выходных данных отдельных шагов и выявления любых проблем, которые могут возникнуть. Визуализация ваших данных и логов упрощает идентификацию и исправление проблем во время выполнения вашего потока.
Используйте AWS для масштабируемости
Когда вы впервые устанавливаете Metaflow, он работает в локальном режиме. В этом режиме артефакты и метаданные сохраняются в локальном каталоге, а вычисления выполняются с помощью локальных процессов. Эта настройка хорошо подходит для личного использования, но если ваш проект связан с совместной работой или большими наборами данных, рекомендуется настроить Metaflow для использования AWS для лучшей масштабируемости. Хорошая новость в том, что Metaflow предоставляет отличную интеграцию с AWS.
Заключение
В этом руководстве мы рассмотрели, как начать работу с Metaflow, от установки до создания вашего первого рабочего процесса в области науки о данных. Мы обсудили основные концепции, такие как определение шагов, использование артефактов данных для передачи данных между шагами и версионирование для отслеживания и воспроизведения запусков. Мы также прошли через практический пример обучения модели машинного обучения, который продемонстрировал, как определить, запустить и контролировать ваш рабочий процесс. Наконец, мы затронули некоторые лучшие практики, которые помогут вам максимально эффективно использовать Metaflow.
Чтобы продолжить изучение MLOps, ознакомьтесь со следующими ресурсами: