













Metaflowは、データワークフローを構築および管理するための強力なフレームワークです。このチュートリアルでは、始める方法を学びます。具体的には、以下の内容について触れます:
- インストールプロセス
- 基本的なワークフローの構築
- コア概念
- ベストプラクティス
この記事の終わりまでに、あなたはワークフローを効率的に合理化し、スケールアップするために必要なスキルを身につけるでしょう!
メタフローとは何ですか?

出典: なぜMetaflowなのか?
Metaflowはデータサイエンスプロジェクトを管理するために設計されたPythonフレームワークです。Netflixはこのツールを、データサイエンティストや機械学習エンジニアがより生産的になるために開発しました。この目的を達成するために、ワークフローオーケストレーションのような複雑なタスクを簡素化し、プロセスが始まりから終わりまでスムーズに実行されることを保証します。
Metaflowの主な機能には、ワークフローの変更を追跡する自動データバージョン管理や、ユーザーがより大きなデータセットやより複雑なタスクを扱えるようにするスケーラブルなワークフローのサポートが含まれています。
Metaflowのもう一つの利点は、AWSとの統合が容易であることです。これにより、ユーザーはストレージやコンピューティングパワーのためにクラウドリソースを活用できます。さらに、使いやすいPython APIにより、初心者から経験豊富なユーザーまでアクセスしやすくなっています。
設定を始めましょう。
Metaflowの設定
Metaflowは、新しいプロジェクトにはPython 2.7ではなくPython 3のインストールを推奨しています。ドキュメントには「Python 3はバグが少なく、廃止されたPython 2.7よりもサポートが優れています」と記載されています。
次のステップは、プロジェクトの依存関係を管理するための仮想環境を作成することです。次のコマンドを実行してください:
python -m venv venv source venv/bin/activate
これにより、仮想環境が作成され、アクティブ化されます。アクティブ化されたら、Metaflowをインストールする準備が整います。
Metaflowは、MacOSおよびLinux用のPythonパッケージとして利用可能です。 最新版は、MetaflowのGitHubリポジトリまたはPyPiから、次のコマンドを実行することでインストールできます:
pip install metaflow
残念ながら、執筆時点では、MetaflowはWindowsユーザーに対するネイティブサポートを提供していません。しかし、Windows 10を使用しているユーザーはWSL(Windows Subsystem for Linux)を使用してMetaflowをインストールでき、これによりWindowsオペレーティングシステム内でLinux環境を実行できます。Windows 10にMetaflowをインストールするためのステップバイステップガイドについては、ドキュメントを確認してください。
AWS統合(オプション)
MetaflowはAWSとのシームレスな統合を提供します。これにより、ユーザーはクラウドインフラストラクチャを使用してワークフローをスケールすることができます。AWSを統合するには、AWSの資格情報を設定する必要があります。
注意:これらの手順は、すでにAWSアカウントとAWS CLIがインストールされていることを前提としています。詳細については、 AWSドキュメントの指示に従ってください。
- まず、次のコマンドを実行してAWS CLIをインストールします:
pip install awscli
- AWSを設定するには、次のコマンドを実行します
aws configure
ここから、AWSアクセスキーIDとシークレットアクセスキーを入力するように求められます。これらは、AWS CLIがAWSへのリクエストを認証するために使用する資格情報です。地域や出力形式を入力するように求められることもありますので注意してください。
これらの詳細を入力すると、はい!Metaflowは自動的にAWSの資格情報を使用してワークフローを実行します。
Metaflowでの最初のワークフローの構築
Metaflowの設定が完了したので、最初のワークフローを構築する時が来ました。このセクションでは、フローの作成、実行、そしてMetaflowにおけるタスクとステップの整理方法について基本を説明します。
このセクションの終わりまでには、データを処理し、簡単な操作を行うワークフローを持つことになります。さあ、始めましょう!
Metaflowフローの概要
Metaflow は、データフローパラダイムを使用しており、プログラムを操作の有向グラフとして表現します。このアプローチは、特に機械学習においてデータ処理パイプラインを構築するのに最適です。
Metaflowでは、操作のグラフをフローと呼びます。フローは、ステップに分けられた一連のタスクで構成されます。各ステップは、ノードとして表される操作と考えられ、ステップ間の遷移がグラフのエッジとして機能します。
Metaflowの基本的なリニア遷移 | 出典: Metaflowドキュメント
Metaflowのフローにはいくつかの構造的ルールがあります。例えば、すべてのフローには startステップと endステップが含まれている必要があります。フローが実行される際、それは runと呼ばれ、startステップから始まり、エラーなくendステップに到達すれば成功と見なされます。
開始と終了のステップの間に何が起こるかは完全にあなた次第です – 次のセグメントで見ることができます。
最初のフローを書く
ここから始めるためのシンプルなフローがあります。注意: コードは DataLabで実行できます。
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # サンプルデータセット self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # シンプルなデータ処理 print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
このフローでは:
-
start()ステップがワークフローを初期化し、データセットを定義します。 - この
process_data()ステップは、各要素を倍にすることでデータを処理します。 - この
end()ステップはフローを完了します。
各ステップは@stepデコレーターを使用し、self.next()を使ってステップを接続することでフローの順序を定義します。
フローを実行する
フローを書いた後は、my_first_flow.pyとして保存します。コマンドラインから次のように実行します:
py -m my_first_flow.py run
Metaflow 2.12では、ユーザーがノートブックでフローを開発および実行できる新機能が追加されました。
定義されたセルでフローを実行するには、同じセルの最後の行に NBRunner のワンライナーを追加するだけです。例えば:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # サンプルデータセット self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # シンプルなデータ処理 print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
以下のエラーが発生した場合:
「Metaflowは環境変数($USERNAME等)に基づいてユーザー名を決定できませんでした」
Metaflowを実行する前に、以下をコードに追加してください:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
いずれの場合も、Metaflowはフローをステップバイステップで実行します。つまり、各ステップの出力をターミナルに次のように表示します:
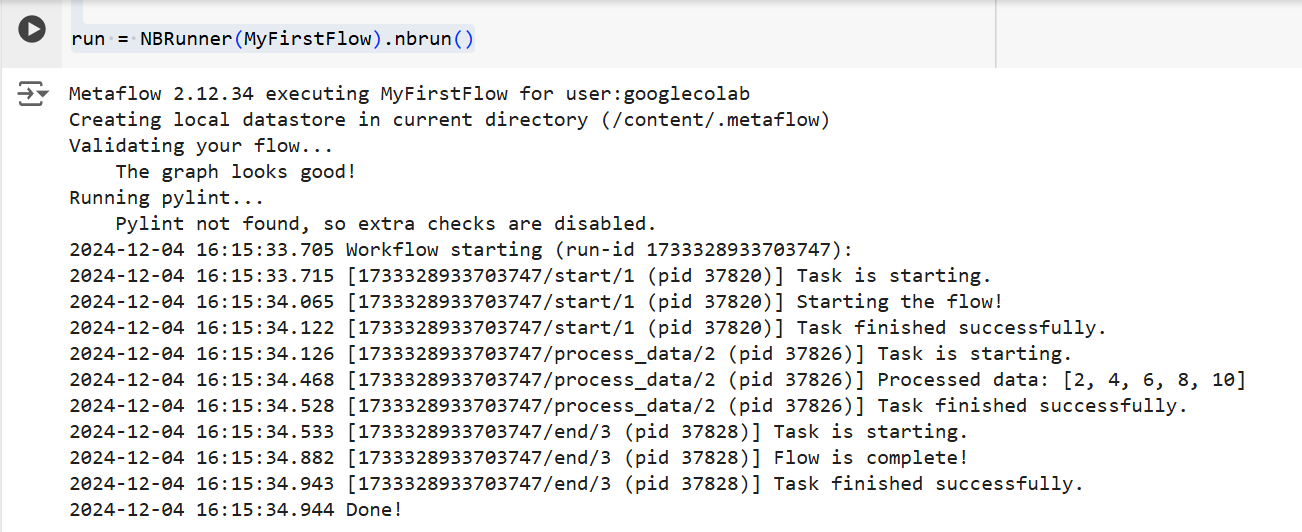
上記のコードからの出力 | 出典: 著者による画像
メタフローのコアコンセプト
メタフローのコアコンセプトを理解することは、効率的でスケーラブルなデータワークフローを構築するために不可欠です。このセクションでは、3つの基本的な概念について説明します:
- ステップと分岐
- データアーティファクト
- バージョン管理
これらの要素は、Metaflowの構造とワークフローの実行の骨組みを形成しており、複雑なプロセスを簡単に管理できるようにします。
ステップと分岐
この記事では ステップについて簡単に触れましたが、明確にするために再度取り上げます。Metaflowのワークフローについて理解すべき最も重要なことは、それらがステップを中心に構築されているということです。
ステップは、ワークフロー内の各タスクを表します。言い換えれば、各ステップは特定の操作(例:データの読み込み、処理、モデリングなど)を実行します。
「最初のフローを書く」で作成した例は線形変換でした。逐次的なステップに加えて、Metaflowはユーザーが分岐ワークフローを作成することも可能にします。分岐ワークフローでは、実行のために別々のパスを作成することで、複数のタスクを並行して実行できます。
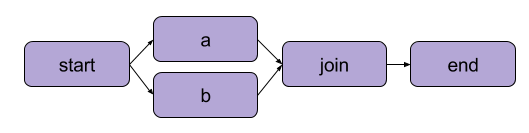
分岐の例 | 出典: Metaflow ドキュメント
分岐の主な利点はパフォーマンスです。分岐により、Metaflowはクラウド内の複数のCPUコアやインスタンスにわたってさまざまなステップを実行できます。
以下は、コード内での分岐の例です:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # 例のデータセット self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # ブランチ1のコード print("This is branch 1") self.next(self.join) @step def branch2(self): # ブランチ2のコード print("This is branch 2") self.next(self.join) @step def join(self, inputs): # ブランチの統合 print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡要点: ブランチ機能を使用すると、ユーザーは複雑なワークフローを設計し、同時に複数のタスクを処理できます。 |
データアーティファクト
データ アーティファクトは、ワークフロー内のステップ間でデータを保存し、渡すための変数です。これらのアーティファクトは、1つのステップの出力を次のステップに持続させます。これにより、データが後続のステップで利用可能になります。
基本的に、Metaflowクラスのステップ内でselfにデータを割り当てると、それはアーティファクトとして保存され、フロー内の他のステップからアクセスできるようになります(コード内のコメントを参照してください)。
class ArtifactFlow(FlowSpec): @step def start(self): # ステップ1: データの初期化 print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # アーティファクトとして保存された例のデータセット self.next(self.process_data) @step def process_data(self): # ステップ2: 'start'ステップからデータを処理する self.processed_data = [x * 2 for x in self.data] # アーティファクトデータの処理 print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # ステップ3: 処理されたデータアーティファクトの保存 self.results = sum(self.processed_data) # 最終結果をアーティファクトとして保存 print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # 最終ステップ print("Flow is complete!") print(f"Final result: {self.results}") # 最終ステップでアーティファクトにアクセスする
アーティファクトはMetaflowのコア概念である理由は何ですか?それは、多くの用途があるからです:
- データフロー管理の自動化、データを手動でロードおよび保存する必要を排除します。
- 永続性を有効にする(次で詳しく説明します)、つまり、ユーザーがクライアント API を使用して後で分析を行い、カードで視覚化し、フロー間で再利用できるようにすることを意味します。
- ローカル環境とクラウド環境間の一貫性。これにより、明示的なデータ転送の必要がなくなります。
- ユーザーが障害が発生する前にデータを検査し、バグを修正した後に実行を再開できるようにします。
バージョン管理と永続性
Metaflowは自動的にバージョン管理をワークフローに対して行います。これは、フローが実行されるたびに、それがユニークな実行として追跡されることを意味します。言い換えれば、各実行には独自のバージョンがあり、過去の実行を簡単にレビューし再現することができます。
Metaflowは、各実行にユニークな識別子を割り当て、その実行からのデータとアーティファクトを保持することでこれを実現します。この永続性により、実行間でデータが失われることはありません。過去のワークフローは簡単に再訪して検査でき、必要に応じて特定のステップを再実行できます。その結果、デバッグや反復開発が非常に効率的になり、再現性の維持が簡素化されます。
実用例:機械学習モデルのトレーニング
このセクションでは、Metaflowを使用して機械学習モデルをトレーニングする方法を案内します。以下のことを学びます:
- データをロードするワークフローを定義します
- 機械学習モデルをトレーニングします
- 結果を追跡します
最後には、Metaflowを使用して機械学習ワークフローを効率的に構築し、実行する方法をよりよく理解できるようになります。さあ、始めましょう!
まず、データセットをロードし、トレーニングを行い、モデルの結果を出力する基本的なフローを作成します。
注意: コードはDataLabで実行できます。
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # データセットをロードして分割します print("Loading data...") self.data = [1, 2, 3, 4, 5] # 実際のデータ読み込みロジックに置換 self.labels = [0, 1, 0, 1, 0] # ラベルに置換 self.next(self.train_model) @step def train_model(self): # 単純なモデルのトレーニング(例:線形回帰) print("Training the model...") self.model = sum(self.data) / len(self.data) # 実際のモデルトレーニングに置換 print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # 最終ステップ print("Training complete. Model ready for deployment!")f
このコードでは、3つのステップを定義しています:
start(): データセットをロードして分割します。実際のシナリオでは、実際のソース(たとえば、ファイルやデータベース)からデータを読み込みます。train_model(): モデルのトレーニングをシミュレートします。ここでは、実際の機械学習アルゴリズムの代わりに単純な平均計算が行われますが、必要なトレーニングコードに置換できます。end(): フローの終了を示し、モデルのデプロイ準備が整ったことを示します。
フローを定義したら、以下のコマンドを使用して実行できます:
run = NBRunner(TrainModelFlow) run.nbrun()
このコードはノートブック内でのみ動作することに注意してください(すべてのコードは1つのセル内に含める必要があります)。
このコードをスクリプトとして実行したい場合は、NBRunner コマンドを削除し、スクリプトの最後に以下を追加して保存してください(例:「metaflow_ml_model.py」):
if __name__ == "__main__": TrainModelFlow()
スクリプトを実行するには、コマンドラインに移動し、以下のコマンドを実行します:
py -m metaflow_ml_model.py
Metaflowは各実行を自動的に追跡し、結果を視覚化することができます。Metaflow UIを通じて。
Metaflowの利用に関するベストプラクティス
では、Metaflowの機能を最大限に活用するにはどうすればよいでしょうか?ワークフローを最適化しながら、この目標を達成するのに役立ついくつかのベストプラクティスを以下に示します:
小さなフローから始める
Metaflowが初めての場合は、シンプルなワークフローから始めてAPIに慣れてください。小さく始めることで、フレームワークの動作を理解し、より複雑なプロジェクトに進む前にその機能に自信を持つことができます。このアプローチにより、学習曲線が緩やかになり、基盤がしっかりと築かれます。
デバッグにはMetaflowのUIを活用する
Metaflowには強力なユーザーインターフェースが含まれており、ワークフローのデバッグやトラッキングに非常に役立ちます。UIを使用して実行を監視し、個々のステップの出力を確認し、発生する可能性のある問題を特定します。データやログを可視化することで、フローの実行中に問題を特定して修正しやすくなります。
AWSを活用してスケーラビリティを向上させる
Metaflowを初めてインストールすると、ローカルモードで動作します。このモードでは、アーティファクトとメタデータがローカルディレクトリに保存され、計算はローカルプロセスを使用して実行されます。この設定は個人使用には適していますが、プロジェクトにコラボレーションや大規模データセットが含まれる場合は、MetaflowをAWSを利用するように設定することをお勧めします。ここでの利点は、MetaflowがAWSとの優れた統合を提供していることです。
結論
このチュートリアルでは、インストールから最初のデータサイエンスワークフローの構築まで、Metaflowの始め方を探りました。ステップの定義、ステップ間でデータを渡すためのデータアーティファクトの使用、実行を追跡および再現するためのバージョン管理など、コアコンセプトをカバーしました。また、ワークフローを定義、実行、および監視する方法を示す機械学習モデルのトレーニングの実践例も紹介しました。最後に、Metaflowを最大限に活用するためのベストプラクティスについても触れました。
MLOpsの学習を続けるために、以下のリソースをチェックしてください: