













Metaflow è un potente framework per costruire e gestire flussi di lavoro dati. In questo tutorial, imparerai come iniziare. In particolare, toccheremo:
- Il processo di installazione
- Costruire un flusso di lavoro di base
- Concetti fondamentali
- Migliori pratiche
Alla fine di questo articolo, avrai le competenze necessarie per semplificare e scalare i tuoi flussi di lavoro in modo efficiente!
Che cos’è Metaflow?

Fonte: Perché Metaflow?
Metaflow è un framework Python progettato per aiutare a gestire progetti di data science. Netflix ha inizialmente sviluppato questo strumento per aiutare i data scientist e gli ingegneri di machine learning a essere più produttivi. Raggiunge questo obiettivo semplificando compiti complessi, come l’orchestrazione dei flussi di lavoro, che garantisce che i processi si svolgano senza intoppi dall’inizio alla fine.
Le caratteristiche principali di Metaflow includono il versioning automatico dei dati, che traccia le modifiche ai flussi di lavoro, e il supporto per flussi di lavoro scalabili, che consente agli utenti di gestire set di dati più grandi e compiti più complessi.
Un altro vantaggio di Metaflow è che si integra facilmente con AWS. Questo significa che gli utenti possono sfruttare le risorse cloud per l’archiviazione e la potenza di calcolo. Inoltre, la sua API Python user-friendly lo rende accessibile sia ai principianti che agli utenti esperti.
Iniziamo a configurarlo.
Configurazione di Metaflow
Metaflow suggerisce che gli utenti installino Python 3 piuttosto che Python 2.7 per nuovi progetti. La documentazione afferma che “Python 3 ha meno bug ed è meglio supportato rispetto al deprecato Python 2.7.”
Il passo successivo è creare un ambiente virtuale per gestire le dipendenze del tuo progetto. Esegui il seguente comando per farlo:
python -m venv venv source venv/bin/activate
Questo creerà e attiverà un ambiente virtuale. Una volta attivato, sei pronto per installare Metaflow.
Metaflow è disponibile come pacchetto Python per MacOS e Linux. L’ultima versione può essere installata dal repository Github di Metaflow o PyPi eseguendo il seguente comando:
pip install metaflow
Purtroppo, al momento della scrittura, Metaflow non offre supporto nativo per gli utenti Windows. Tuttavia, gli utenti con Windows 10 possono utilizzare WSL (Windows Subsystem for Linux) per installare Metaflow, il che consente loro di eseguire un ambiente Linux all’interno del loro sistema operativo Windows. Controlla la documentazione per una guida passo passo su come installare Metaflow su Windows 10.
Integrazione AWS (Opzionale)
Metaflow offre un’integrazione senza soluzione di continuità con AWS, che consente agli utenti di scalare i propri flussi di lavoro utilizzando l’infrastruttura cloud. Per integrare AWS, dovrai impostare le tue credenziali AWS.
Nota: Questi passaggi presuppongono che tu abbia già un account AWS e AWS CLI installato. Per ulteriori dettagli, segui le istruzioni della documentazione AWS.
- Per prima cosa, installa l’AWS CLI eseguendo:
pip install awscli
- Configura AWS eseguendo
aws configure
Da qui, ti verrà chiesto di inserire il tuo AWS Access Key ID e Secret Access Key: queste sono semplicemente le credenziali che l’AWS CLI utilizza per autenticare le tue richieste ad AWS. Tieni presente che potresti anche essere invitato a inserire la tua regione e il formato di output.
Una volta inseriti questi dettagli, voilà! Metaflow utilizzerà automaticamente le tue credenziali AWS per eseguire i flussi di lavoro.
Costruire il tuo primo flusso di lavoro con Metaflow
Ora che Metaflow è configurato, è tempo di costruire il tuo primo flusso di lavoro. In questa sezione, ti guiderò attraverso le basi della creazione di un flusso, della sua esecuzione e della comprensione di come i compiti e i passi sono organizzati in Metaflow.
Alla fine di questa sezione, avrai un flusso di lavoro che elabora i dati e esegue operazioni semplici. Andiamo!
Panoramica di un flusso Metaflow
Metaflow utilizza il paradigma del flusso di dati, che rappresenta un programma come un grafo diretto di operazioni. Questo approccio è ideale per costruire pipeline di elaborazione dei dati, specialmente nel machine learning.
In Metaflow, il grafo delle operazioni è chiamato flusso. Un flusso consiste in una serie di attività suddivise in passaggi. Si noti che ogni passaggio può essere considerato un’operazione rappresentata come un nodo con transizioni tra i passaggi che fungono da archi del grafo.
Una transizione lineare di base in Metaflow | Fonte: documentazione di Metaflow
Ci sono alcune regole strutturali per i flussi in Metaflow. Ad esempio, ogni flusso deve includere un passo di inizio e un passo di fine. Quando un flusso viene eseguito, noto come un esecuzione, inizia con il passo di inizio ed è considerato riuscito se raggiunge il passo di fine senza errori.
Ciò che accade tra i passaggi di inizio e fine dipende interamente da te – come vedrai nel segmento successivo.
Scrivere il tuo primo flusso
Ecco un semplice flusso per iniziare. Nota: Il codice può essere eseguito in DataLab.
from metaflow import FlowSpec, step class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Esempio di dataset self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Elaborazione semplice dei dati print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") if __name__ == '__main__': MyFirstFlow()
In questo flusso:
- Il passaggio
start()inizializza il flusso di lavoro e definisce un dataset. - Il passo
process_data()elabora i dati raddoppiando ogni elemento. - Il passo
end()completa il flusso.
Ogni passo utilizza il decoratore @step, e puoi definire la sequenza del flusso usando self.next() per collegare i passi.
Esecuzione del tuo flusso
Dopo aver scritto il tuo flusso, salvalo come my_first_flow.py. Eseguilo dalla riga di comando usando:
py -m my_first_flow.py run
È stata aggiunta una nuova funzionalità in Metaflow 2.12 che consente agli utenti di sviluppare ed eseguire flussi nei notebook.
Per eseguire un flusso in una cella definita, tutto ciò che devi fare è aggiungere la riga NBRunner nell’ultima riga della stessa cella. Ad esempio:
from metaflow import FlowSpec, step, NBRunner class MyFirstFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Esempio di dataset self.next(self.process_data) @step def process_data(self): self.processed_data = [x * 2 for x in self.data] # Elaborazione semplice dei dati print("Processed data:", self.processed_data) self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(MyFirstFlow).nbrun()
Se ricevi il seguente errore:
“Metaflow non è riuscito a determinare il tuo nome utente basandosi sulle variabili d’ambiente ($USERNAME ecc.)”
Aggiungi quanto segue al tuo codice prima dell’esecuzione di Metaflow:
import os if os.environ.get("USERNAME") is None: os.environ["USERNAME"] = "googlecolab"
In entrambi i casi, Metaflow eseguirà il flusso passo dopo passo. In particolare, mostrerà l’output di ciascun passo nel terminale come segue:
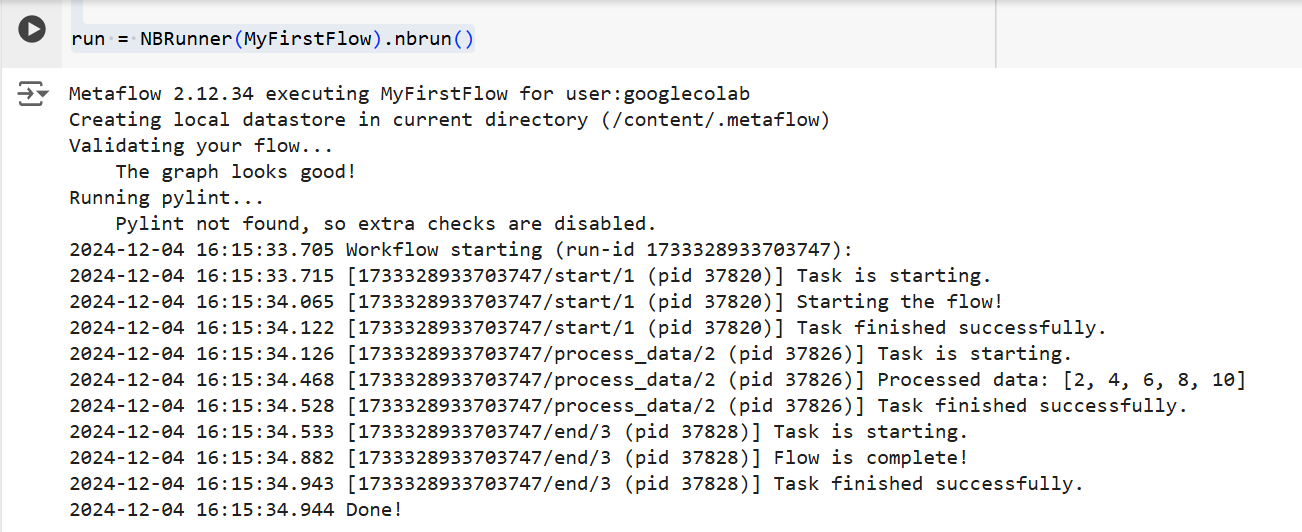
L’output del codice sopra | Fonte: Immagine dell’autore
Concetti fondamentali in Metaflow
Comprendere i concetti fondamentali di Metaflow è essenziale per costruire flussi di lavoro dati efficienti e scalabili. In questa sezione, tratterò tre concetti fondamentali:
- Passaggi e ramificazioni
- Artefatti di dati
- Versioning
Questi elementi formano la spina dorsale della struttura e dell’esecuzione dei flussi di lavoro di Metaflow, consentendoti di gestire facilmente processi complessi.
Passaggi e ramificazioni
Abbiamo brevemente accennato ai passaggi in precedenza nell’articolo, ma per chiarezza, li rivedremo di nuovo. La cosa più importante da capire sui flussi di lavoro di Metaflow è che sono costruiti attorno ai passaggi.
I passaggi rappresentano ciascun compito individuale all’interno di un flusso di lavoro. In altre parole, ogni passaggio eseguirà un’operazione specifica (ad es., caricamento dati, elaborazione, modellazione, ecc.).
L’esempio che abbiamo creato sopra in “Scrivere il tuo primo flusso” era una trasformazione lineare. Oltre ai passaggi sequenziali, Metaflow consente anche agli utenti di diramare i flussi di lavoro. I flussi di lavoro diramati ti permettono di eseguire più attività in parallelo creando percorsi separati per l’esecuzione.
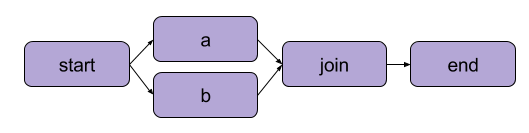
Un esempio di diramazione | Fonte: documentazione di Metaflow
Il principale vantaggio di una diramazione è le prestazioni. La diramazione significa che Metaflow può eseguire vari passaggi su più core CPU o istanze nel cloud.
Ecco come apparirebbe una diramazione in codice:
from metaflow import FlowSpec, step, NBRunner class BranchFlow(FlowSpec): @step def start(self): print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Esempio di dataset self.next(self.split) @step def split(self): self.next(self.branch1, self.branch2) @step def branch1(self): # Codice per ramo 1 print("This is branch 1") self.next(self.join) @step def branch2(self): # Codice per ramo 2 print("This is branch 2") self.next(self.join) @step def join(self, inputs): # Fusione dei rami print("Branches joined.") self.next(self.end) @step def end(self): print("Flow is complete!") run = NBRunner(BranchFlow).nbrun()
|
💡TLDR: Il branching consente agli utenti di progettare flussi di lavoro complessi che possono elaborare simultaneamente più compiti. |
Artifact di dati
Dati artifact sono variabili che consentono di memorizzare e passare dati tra i passaggi in un flusso di lavoro. Questi artifact persistono l’output di un passaggio al successivo—questo è il modo in cui i dati sono resi disponibili per i passaggi successivi.
Fondamentalmente, quando assegni dati a self all’interno di un passaggio in una classe Metaflow, li salvi come un artefatto, che può poi essere accessibile da qualsiasi altro passaggio nel flusso (vedi i commenti nel codice).
class ArtifactFlow(FlowSpec): @step def start(self): # Passaggio 1: Inizializzazione dei dati print("Starting the flow!") self.data = [1, 2, 3, 4, 5] # Esempio di dataset salvato come artefatto self.next(self.process_data) @step def process_data(self): # Passaggio 2: Elaborazione dei dati dal passaggio 'start' self.processed_data = [x * 2 for x in self.data] # Elaborazione dei dati dell'artefatto print("Processed data:", self.processed_data) self.next(self.save_results) @step def save_results(self): # Passaggio 3: Salvataggio dell'artefatto dei dati elaborati self.results = sum(self.processed_data) # Salvataggio del risultato finale come artefatto print("Sum of processed data:", self.results) self.next(self.end) @step def end(self): # Passaggio finale print("Flow is complete!") print(f"Final result: {self.results}") # Accesso all'artefatto nel passaggio finale
Perché gli artefatti sono un concetto fondamentale di Metaflow? Perché hanno una serie di utilizzi:
- Automatizzare la gestione del flusso di dati, rimuovendo la necessità di caricare e memorizzare manualmente i dati.
- Abilitare la persistenza (ne parleremo più avanti), il che significa che consentono agli utenti di effettuare analisi in seguito con l’API Client, visualizzare con le Schede e riutilizzare attraverso i flussi.
- Coerenza tra ambienti locali e nel cloud. Questo elimina la necessità di trasferimenti di dati espliciti.
- Consentire agli utenti di ispezionare i dati prima dei guasti e riprendere le esecuzioni dopo aver risolto i bug.
Versionamento e persistenza
Metaflow gestisce automaticamente il versioning per i tuoi flussi di lavoro. Questo significa che ogni volta che un flusso viene eseguito, viene tracciato come un’esecuzione unica. In altre parole, ogni esecuzione ha la sua versione, permettendoti di rivedere e riprodurre facilmente le esecuzioni passate.
Metaflow fa questo assegnando identificatori unici a ciascuna esecuzione e preservando i dati e gli artefatti di quella esecuzione. Questa persistenza assicura che nessun dato venga perso tra le esecuzioni. I flussi di lavoro passati possono essere facilmente riesaminati e ispezionati, e passaggi specifici possono essere rieseguiti se necessario. Di conseguenza, il debugging e lo sviluppo iterativo sono molto più efficienti, e il mantenimento della riproducibilità è semplificato.
Esempio pratico: Addestramento di un modello di machine learning
In questa sezione, ti guiderò nell’uso di Metaflow per addestrare un modello di machine learning. Imparerai come:
- Definisci un flusso di lavoro che carica i dati
- Allena un modello di apprendimento automatico
- Monitora i risultati
Alla fine, comprenderai meglio come utilizzare Metaflow per strutturare e gestire i flussi di lavoro di apprendimento automatico in modo efficiente. Andiamo!
Per iniziare, creeremo un flusso di base che carica un dataset, esegue l’addestramento e restituisce i risultati del modello.
Nota: Il codice può essere eseguito in DataLab.
from metaflow import FlowSpec, step, Parameter, NBRunner class TrainModelFlow(FlowSpec): @step def start(self): # Carica e suddividi il dataset print("Loading data...") self.data = [1, 2, 3, 4, 5] # Sostituisci con la logica effettiva di caricamento dei dati self.labels = [0, 1, 0, 1, 0] # Sostituisci con le etichette self.next(self.train_model) @step def train_model(self): # Addestramento di un modello semplice (ad esempio, regressione lineare) print("Training the model...") self.model = sum(self.data) / len(self.data) # Sostituisci con l'addestramento effettivo del modello print(f"Model output: {self.model}") self.next(self.end) @step def end(self): # Passaggio finale print("Training complete. Model ready for deployment!")f
In questo codice, definiamo tre passaggi:
start(): Carica e suddivide il dataset. In uno scenario reale, caricheresti i dati da una fonte effettiva (ad esempio, un file o un database).train_model(): Simula l’addestramento di un modello. Qui, viene eseguita una semplice media invece di un vero algoritmo di apprendimento automatico, ma puoi sostituire questo con qualsiasi codice di addestramento di cui hai bisogno.end(): Segna la fine del flusso e indica che il modello è pronto per il deployment.
Una volta definito il flusso, puoi eseguirlo utilizzando il seguente comando:
run = NBRunner(TrainModelFlow) run.nbrun()
Nota che questo codice funziona solo nei notebook (tutto il codice deve essere in una sola cella).
Se vuoi eseguire questo codice come script, rimuovi i comandi NBRunner e aggiungi quanto segue alla fine del tuo script, e salvalo (ad esempio, “metaflow_ml_model.py”):
if __name__ == "__main__": TrainModelFlow()
Poi, per eseguire lo script, naviga nel prompt dei comandi e esegui il seguente comando:
py -m metaflow_ml_model.py
Metaflow tiene traccia automaticamente di ogni esecuzione e ti consente di visualizzare i risultati attraverso l’interfaccia utente di Metaflow.
Best Practices per l’Utilizzo di Metaflow
Quindi, come possiamo sfruttare al meglio le funzionalità di Metaflow? Ecco alcune best practices che possono aiutarti a raggiungere questo obiettivo ottimizzando i tuoi flussi di lavoro contemporaneamente:
Inizia con flussi piccoli
Se sei nuovo in Metaflow, inizia con flussi di lavoro semplici per familiarizzarti con la sua API. Iniziare in piccolo ti aiuterà a capire come funziona il framework e a costruire fiducia nelle sue capacità prima di passare a progetti più complessi. Questo approccio riduce la curva di apprendimento e garantisce che le tue basi siano solide.
Utilizza l’interfaccia utente di Metaflow per il debug
Metaflow include un potente interfaccia utente che può essere estremamente utile per il debug e il monitoraggio dei tuoi flussi di lavoro. Utilizza l’interfaccia per monitorare le esecuzioni, controllare gli output dei singoli passaggi e identificare eventuali problemi che potrebbero sorgere. Visualizzare i tuoi dati e log rende più facile identificare e risolvere problemi durante l’esecuzione del tuo flusso.
Sfrutta AWS per la scalabilità
Quando installi per la prima volta Metaflow, funziona in modalità locale. In questa modalità, artefatti e metadati vengono salvati in una directory locale e i calcoli vengono eseguiti utilizzando processi locali. Questa configurazione funziona bene per uso personale, ma se il tuo progetto coinvolge collaborazione o grandi dataset, è consigliabile configurare Metaflow per utilizzare AWS per una migliore scalabilità. La cosa positiva è che Metaflow offre un’ottima integrazione con AWS.
Conclusione
In questo tutorial, abbiamo esplorato come iniziare con Metaflow, dall’installazione alla costruzione del tuo primo flusso di lavoro in data science. Abbiamo coperto i concetti fondamentali, come definire i passaggi, utilizzare gli artefatti dati per trasferire dati tra i passaggi e il versioning per tracciare e riprodurre le esecuzioni. Abbiamo anche esaminato un esempio pratico di addestramento di un modello di machine learning, che ha dimostrato come definire, eseguire e monitorare il tuo flusso di lavoro. Infine, abbiamo toccato alcune buone pratiche per aiutarti a ottenere il massimo da Metaflow.
Per continuare il tuo apprendimento di MLOps, dai un’occhiata alle seguenti risorse: