













機器學習中的特徵提取將原始數據轉換為一組有意義的特徵,捕捉到必要的信息同時減少冗餘。它可以涉及降維技術和從現有數據創建新特徵的方法。
想像一下,你正在市場上試圖辨別水果。雖然你可以考慮無數屬性(重量、顏色、質地、形狀、氣味等),但你可能會意識到僅僅考慮顏色和大小等少數關鍵特徵就足以區分蘋果和橙子。這正是特徵提取所做的事情。它幫助你專注於數據中最具信息量的特徵。
在執行特徵提取時,原始數據被數學上轉換為一組新特徵。這些新特徵旨在捕捉數據最重要的方面,同時可能減少其複雜性。提取出的特徵通常代表著原始數據中可能不會立即顯示的潛在模式或結構。
特徵提取
在接下來的部分中,我們將探討為什麼特徵提取在機器學習中如此重要,並研究從不同類型的數據中提取特徵的各種方法以及它們的程式碼。如果你想要一些實際示例,請查看我們的Python中的降維課程,其中有一章專門介紹特徵提取。
為什麼特徵提取在機器學習中如此重要?
特徵提取在機器學習中扮演著重要角色。它可以決定模型是成功還是失敗。讓我們看看為什麼這對於建立有效的機器學習模型如此重要。
增強模型的準確性和效率
在處理原始數據時,機器學習模型往往難以區分有意義的模式和噪音。特徵提取作為數據預處理的步驟,可以顯著改善模型的學習和表現。
模型性能與訓練時間
例如,當一個模型使用原始數據達到85%的準確率時,同一個模型在精心提取特徵的訓練下可能達到95%的準確率。這種改善不是來自改變模型,而是來自為其提供更高質量的輸入數據來進行學習。
管理高維數據集
現代數據集通常具有數百或數千個特徵。這帶來了一些挑戰,而特徵提取有助於應對這些挑戰。
- 維度詛咒: 隨著特徵數量的增加,數據在特徵空間中變得越來越稀疏。這使模型更難找到有意義的模式。特徵提取創建了一個更緊湊的表示,保留了重要的關係,同時降低了維度。
- 高內存使用率: 高維數據在處理過程中需要更多的存儲空間和內存。通過僅提取最相關的特徵,我們可以顯著降低數據集的內存佔用,同時保持其信息價值。
- 數據可視化:無法直接可視化超過三個維度的數據。特徵提取可以將維度降低到兩個或三個特徵,使得可以以圖形方式理解和展示數據結構。
特徵提取通過降低維度的同時保留基本信息來應對這些挑戰。這種降維轉換了庞大、高維度的數據為更緊湊、易管理的形式,從而提高了模型性能。
降低計算複雜度和防止過度擬合
特徵提取為機器學習模型提供了兩個關鍵好處:
- 降低計算要求
- 功能越少,訓練時間越快
- 模型部署時減少記憶體使用
- 更有效率的預測生成
- 更好的泛化能力
- 簡化的特徵空間有助於防止過度擬合
- 模型學習更健壯的模式
- 在新的、未見過的數據上表現更好
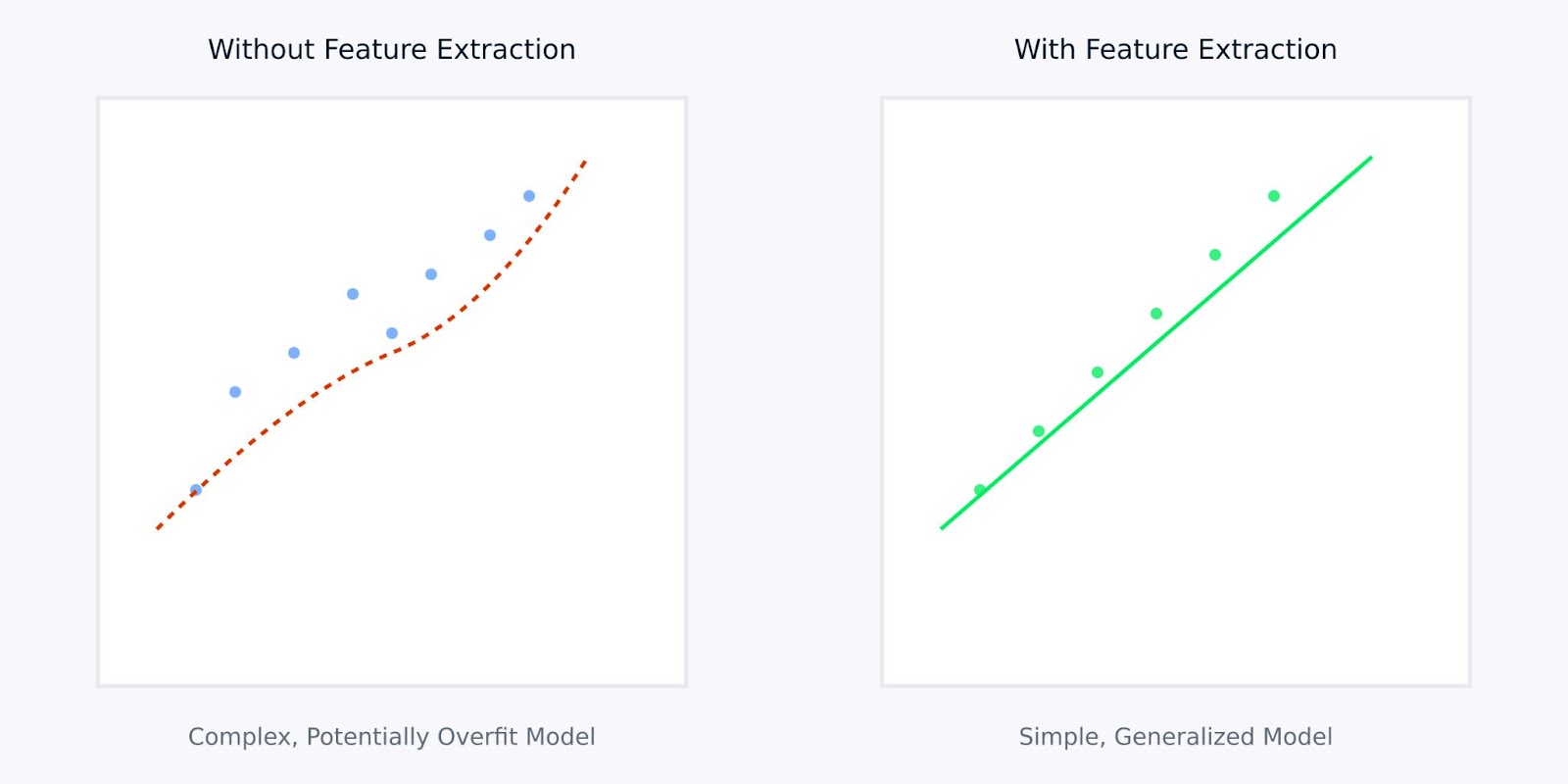
特徵提取與不使用特徵提取
上面的可視化圖表說明了特徵提取如何帶來更簡單、更穩健的模型。左圖顯示了一個複雜模型試圖擬合嘈雜的高維數據,而右圖顯示了特徵提取如何揭示出更清晰、更具泛化能力的模式。
使用提取的特徵而不是原始數據,就像給予你的模型信息的一個清晰、精煉版本,這不僅使學習過程更有效率,還導致模型更有可能在現實應用中表現良好。
接下來,讓我們看看不同的特徵提取方法。
特徵提取方法
特徵提取方法可以大致分為兩種主要方法:手動特徵工程和自動特徵提取。讓我們來看看這兩種方法,了解它們如何幫助將原始數據轉換為有意義的特徵。
手動特徵工程
手動特徵工程涉及使用領域專業知識從原始數據中識別和創建相關特徵。這種實踐方法依賴於我們對問題和數據的理解,以創建有意義的特徵。
在图像处理中,手动特征工程可能涉及诸如边缘检测以识别对象边界、颜色直方图以捕获颜色分布、纹理分析以量化图案、以及形状描述符以表征对象几何形状等技术。
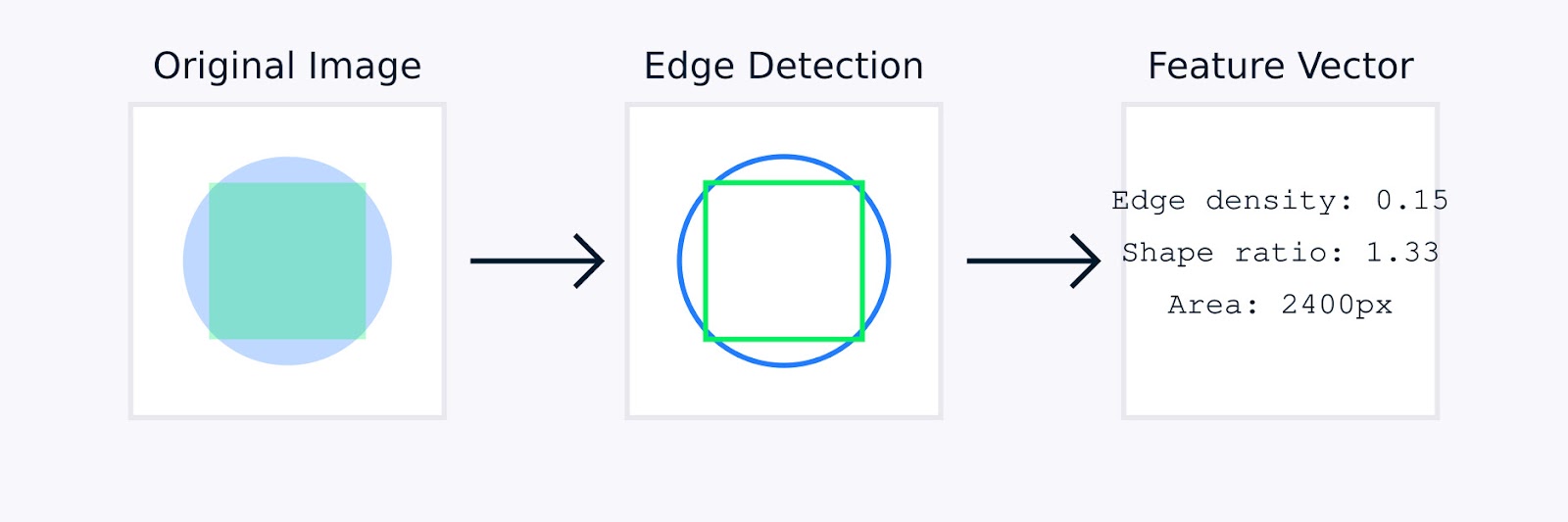
图像特征提取
对于表格数据,手动特征工程涉及创建现有特征之间的交互项,使用对数或多项式函数转换变量,将数据点聚合为有意义的统计信息,并对分类变量进行编码。
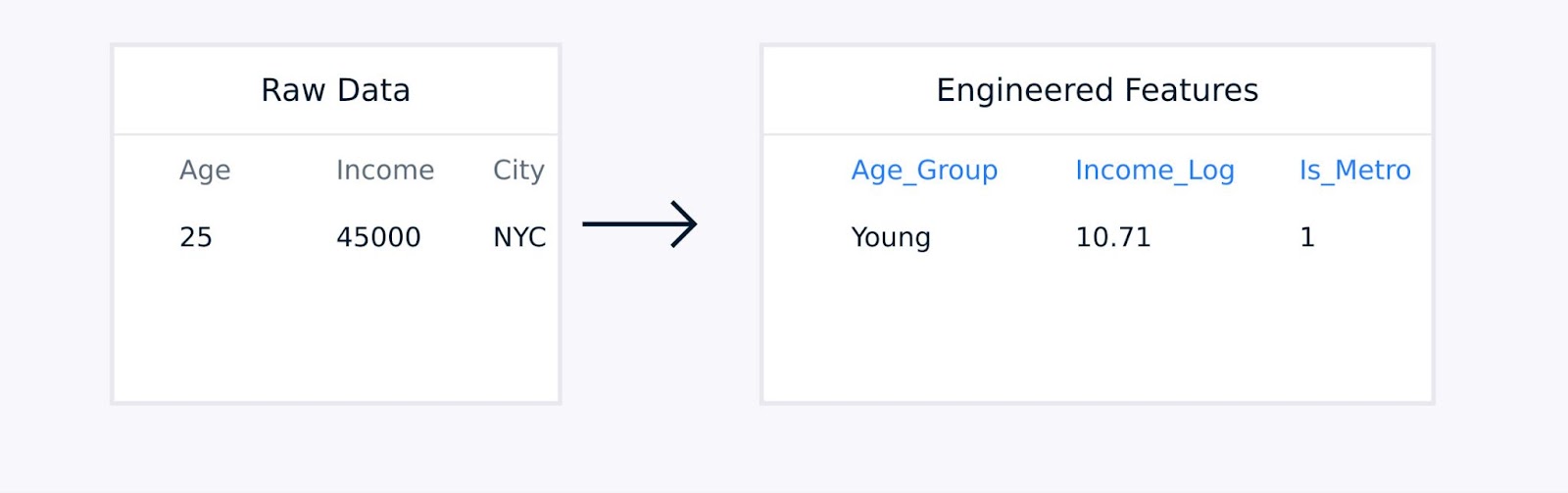
表格數據特徵提取
這些技術在領域專業知識的指導下,增強了數據表示的質量,可以顯著提高模型性能。
自動特徵提取
自動特徵提取使用算法發現和創建特徵,無需明確的人類指導。這些方法在處理複雜數據集時特別有用,手動特徵工程可能不切實際或低效。
常見的自動化方法包括:
主成分分析(PCA):將數據轉換為一組不相關的成分,每個成分捕捉最大剩餘方差。這種方法尤其適用於降維,因為它在簡化數據結構的同時保留了數據中的基本信息。
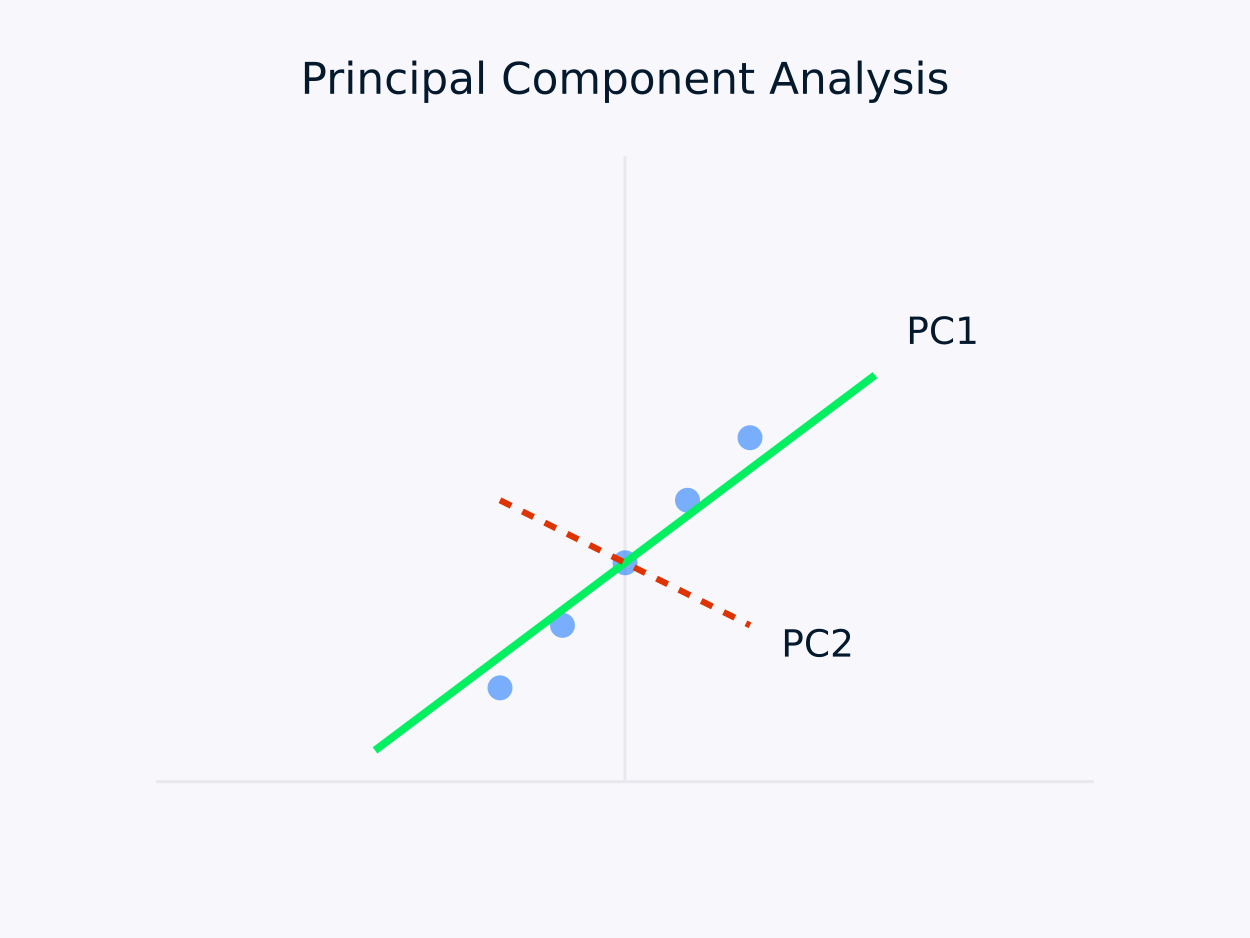
主成分分析(PCA)
自編碼器:這些是神經網絡,學習壓縮數據的表示,捕捉非線性關係。它們特別適用於高維數據集,傳統的線性方法可能會出現問題。
出現了各種工具和庫,簡化特徵工程任務。例如,Scikit-learn的分解模塊提供了一系列降維方法,而PyCaret提供了自動特徵選擇功能。
手動和自動化方法都有其優勢。讓我們來看看每種方法的優勢。
|
手動工程 |
自動提取 |
|
領域知識整合 |
可擴展性 |
|
可解釋特徵 |
處理複雜模式 |
|
精細控制 |
減少人為偏見 |
|
定制以滿足特定需求 |
發現隱藏關係 |
手動和自動方法之間的選擇通常取決於數據集的複雜性、領域專業知識的可用性、可解釋性要求、計算資源和時間限制等因素。
對於高度複雜的數據集或當時間和資源有限時,自動化方法可以快速生成有用的特徵。相反,當具有領域專業知識並且可解釋性是首要考慮因素時,手動方法可能更可取,允許量身定制的特徵工程與手頭問題緊密對齊。
在實踐中,許多成功的機器學習項目結合了兩種方法,利用領域專業知識來指導特徵工程,同時利用自動化方法來發現人類專家可能不會立即注意到的附加模式。
在下一節中,我們將探討各個領域中的幾種特徵提取技術。
特徵提取技術
每種類型的數據都需要針對其獨特特徵進行優化的特徵提取技術。讓我們來看看不同類型數據的最常見技術。

特徵提取技術
圖像特徵提取
圖像特徵提取將原始像素數據轉換為捕獲基本視覺信息的有意義的表示。現代計算機視覺中使用的技術主要分為三大類,分別是傳統方法、基於深度學習的方法和統計方法。

圖像特徵提取方法
讓我們來看看每種方法。
傳統計算機視覺方法
尺度不變特徵變換(SIFT)是一種強大的方法,用於檢測圖像中的獨特局部特徵。它通過識別關鍵點並生成描述符來工作,這些描述符是:
- 對圖像的縮放和旋轉不變
- 對光線變化部分不變
- 對局部幾何變形具有魯棒性
SIFT算法通過幾個階段處理圖像。它從尺度空間極值檢測開始,以識別對尺度不變的潛在關鍵點。接下來,關鍵點定位通過精確定位並丟棄不穩定點來優化這些候選點。
隨之而來的方向分配確定了每個關鍵點的一致方向,確保旋轉不變性。最後,關鍵點描述符生成基於局部圖像梯度的獨特描述符,促進圖像之間的強健匹配。
另一種方法是定向梯度直方圖(HOG)。通過分析圖像上的梯度模式,它捕捉局部形狀信息。該過程始於計算整個圖像的梯度以突出邊緣細節。
然後將圖像分成小單元,對於每個單元,創建梯度方向的直方圖來總結局部結構。最後,這些直方圖在較大的區塊中進行歸一化,以確保抵抗照明和對比度變化,從而產生用於目標檢測和識別等任務的強大特徵描述符。
深度學習方法
卷積神經網絡(CNNs)已經改變了我們通過自動學習分層表示來進行特徵提取的方式。

使用CNN進行特徵提取
卷積神經網絡通過其分層結構來學習特徵。在早期層中,它們檢測基本的視覺元素,如邊緣和顏色。中間層然後結合這些元素來識別模式和形狀,而更深層則捕捉複雜的對象並實現場景理解。
遷移學習使我們能夠使用從在大型數據集上訓練的模型中預先學習的特徵,使其在處理有限數據時尤為寶貴。
統計方法
統計方法從圖像中提取全局和局部模式,促進強大的圖像分析和解釋。
例如,色彩直方圖代表圖像中顏色的分佈,並提供旋轉和尺度不變特徵,使其在圖像分類和檢索等任務中特別有用。
紋理分析利用灰度共生矩陣(GLCM)等技術捕捉重複的紋理和表面特徵,對於包括材料識別和場景分類在內的應用非常有效。
此外,邊緣檢測通過Sobel、Canny和Laplacian等方法識別界限和顯著的強度變化,在物體檢測和形狀分析中發揮著至關重要的作用。
特徵提取方法的選擇取決於幾個因素。它應該與任務的具體要求保持一致,考慮到可用的計算資源,並考慮到對可解釋性的需求。
此外,您的數據集的特徵——如大小、噪音水平和複雜性——起著至關重要的作用,以及所需的不變性屬性,如尺度、旋轉和照明。
音頻特徵提取
想像一下試圖教導電腦像人類一樣理解語音。這就是梅爾頻率倒頻譜係數(MFCC)發揮作用的地方。
MFCC是特殊的音頻特徵,以一種類似於我們的耳朵處理聲音的方式將聲音分解。它們特別有效,因為它們專注於人類最敏感的頻率。可以把它們想像為將聲音轉換為一種電腦和人類聽覺都能理解的格式。
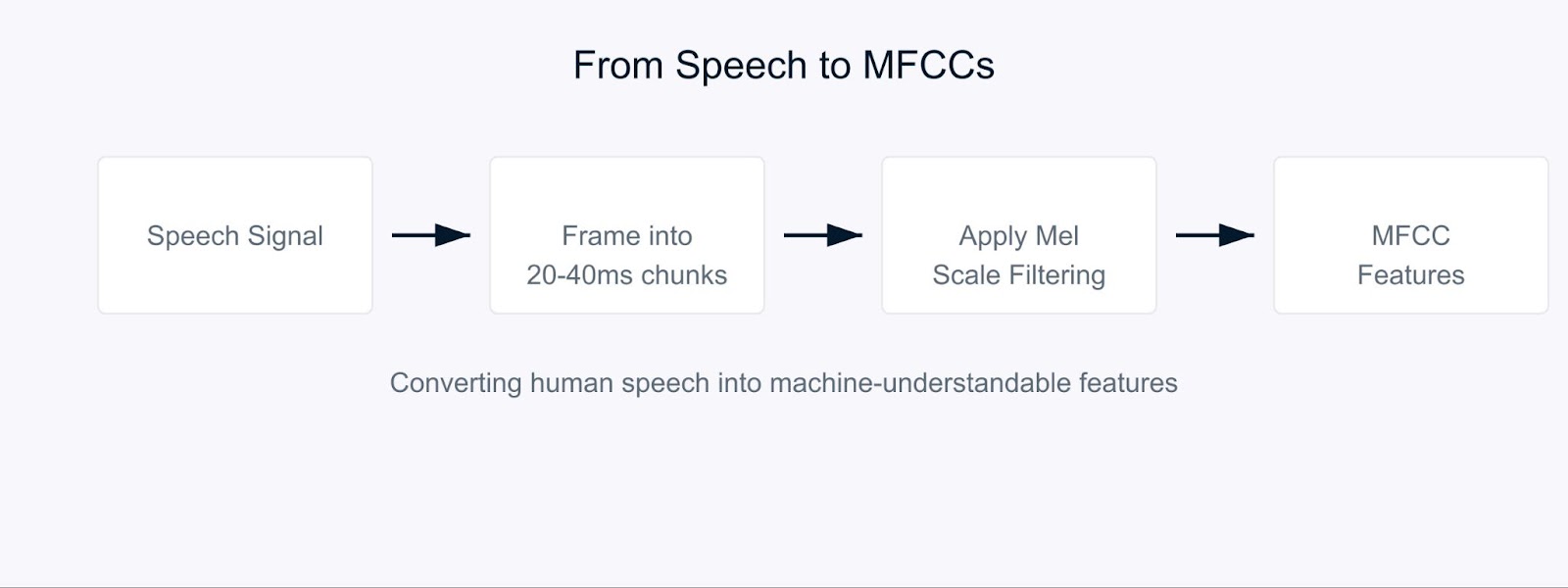
梅爾頻率倒頻譜係數
該過程始於將音頻信號分解為短片段,通常為20-40毫秒長。對於每個片段,我們應用一系列數學轉換,將原始聲波轉換為頻率成分。這就是有趣的地方。我們不是將所有頻率一視同仁,而是使用一種叫做梅爾刻度的東西。
![]()
這個公式看起來可能很複雜,但其實只是將頻率映射成人類感知聲音的方式。我們的耳朵較容易察覺低頻的差異,而梅爾刻度考慮了這種自然偏見。
在語音識別中,MFCCs 是理解說話者和其說了什麼的基礎。當你與手機的虛擬助手交談時,它可能在使用 MFCCs 處理你的聲音。這些係數有助於捕捉每個人聲音的獨特特徵,對語音識別系統非常重要。
對於語音情感分析,MFCCs 有助於檢測表達情緒的微妙變化。它們可以捕捉音高、音調和說話速度的變化,這些變化可能表明某人是快樂、悲傷、生氣還是中立。例如,在分析客戶服務電話時,MFCCs 可以幫助根據說話方式而不僅僅是內容來識別客戶的滿意度水平。
時間序列特徵提取
在處理時間序列數據時,提取有意義的特徵有助於捕捉隨時間演變的模式和趨勢。讓我們來看看將原始時間序列數據轉換為有用特徵的一些關鍵技術。

時間序列特徵提取方法
傅立葉變換將時間序列數據分解為其頻率分量,揭示隱藏的周期模式。公式如下:
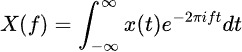
統計方法通過捕捉時間特徵來補充頻率分析。常見特徵包括移動平均、標準差和趨勢成分。這些技術在財務預測中特別強大,有助於識別市場趨勢和異常。
例如,在股市分析中,將傅立葉特徵與統計量結合可以揭示長期趨勢和周期模式。同樣,在工業環境中,這些方法通過分析隨時間變化的傳感器數據模式有助於檢測設備異常。
特徵提取的工具和庫
讓我們看看一些重要工具,使得實現這些特徵提取方法變得簡單和高效。
特徵提取的工具和庫
對於圖像處理,OpenCV 和 scikit-image 提供了全面的工具,用於實現各種特徵提取技術。這些庫提供了我們之前討論的 SIFT、HOG 和其他算法的高效實現。當使用深度學習方法時,像 TensorFlow 和 PyTorch 這樣的框架變得非常寶貴。您可以開始閱讀我們的OpenCV 教程以獲取更多資訊。
使用LibROSA等庫簡化音頻處理任務,該庫在提取MFCC和其他聲學特徵方面表現優異。 PyAudioAnalysis 通過高級介面擴展這些功能,用於音頻分析任務。
對於時間序列數據,tsfresh和Featuretools 可自動執行特徵提取過程。這些庫可以自動從您的時間數據中生成並選擇相關特徵,使您更容易專注於模型開發而不是特徵工程。
特徵提取示例
讓我們通過一些實際示例將知識付諸實踐。我們將從圖像特徵提取開始,這是計算機視覺中最常見的應用之一。
使用OpenCV進行圖像特徵提取
首先,讓我們導入必要的庫
# 導入所需的庫 import cv2 import numpy as np import matplotlib.pyplot as plt
現在,讓我們加載一個圖像來提取相關特徵。在這個例子中,我們將使用從互聯網上下載的哥斯拉圖像。
# 加載圖像 image = cv2.imread('godzilla.jpg') # 將 BGR 轉換為 RGB(OpenCV 以 BGR 格式加載) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 顯示原始圖像 plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
輸出:

在應用邊緣檢測之前,我們需要對圖像進行預處理。我們按照以下步驟進行:
# 將圖像轉換為灰度 gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 應用高斯模糊以減少噪音 blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
最後,讓我們應用 Canny 邊緣檢測算法並可視化結果:
#應用Canny邊緣檢測 edges = cv2.Canny(blurred, threshold1=100, threshold2=200) #顯示結果 plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
輸出:

Canny邊緣檢測器幫助我們識別圖像中的重要邊界和特徵,這些可以用於進一步分析或作為機器學習模型的輸入。
從音頻中提取MFCC使用LibROSA
在我們開始處理音頻文件之前,我們需要安裝所需的庫。由於LibROSA不包含在Python的標準庫中,我們將使用pip來安裝它:
#安裝所需的庫 #在您的終端機或命令提示字元中運行這些命令 pip install librosa pip install numpy pip install matplotlib
LibROSA是一個強大的音樂和音頻分析庫,所以讓我們從導入它以及其他必要的庫開始:
# 導入所需的庫 import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
聲音文件以波形格式包含大量信息。要處理這些數據,我們首先需要將其加載到我們的程序中。LibROSA 通過將音頻文件轉換為我們可以分析的格式來幫助我們:
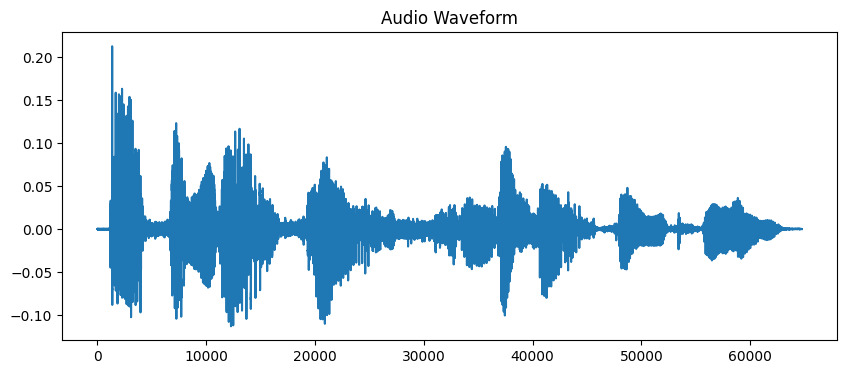
# 加載音頻文件 # 本示例中持續時間限制為 10 秒 audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # 顯示波形 plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
輸出:
現在我們已經加載了音頻,我們需要從中提取有意義的特徵。我們的耳朵自然地將聲音分解為不同頻率成分,而 MFCC 模擬了這一過程。我們使用 librosa 的特徵提取函數來計算這些係數:
# 提取 MFCC 特徵 mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # 顯示 MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
輸出:
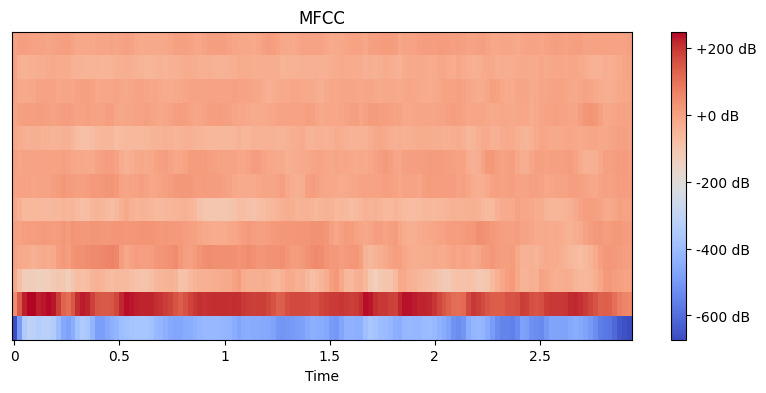
在這裡,我們設置n_mfcc=13,因為通常前13個係數捕捉到聲音中最重要的部分,有助於語音識別等任務。結果的可視化顯示了這些特徵隨時間的變化,其中較亮的顏色代表較高的值。
使用tsfresh從時間序列數據中提取特徵
首先,讓我們安裝所需的庫。我們將使用yfinance獲取金融數據,以及tsfresh進行特徵提取:
# 安裝所需的庫 # 在您的終端機或命令提示字元中運行這些命令 pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
現在讓我們導入我們的庫並獲取一些真實的金融數據:
#匯入所需的庫 import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
讓我們獲取一些真實的股票市場數據。我們將以蘋果的股票數據作為例子:
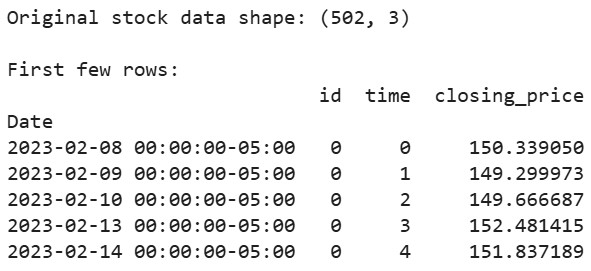
#下載蘋果過去2年的股票數據 aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") #準備數據以符合tsfresh的期望格式 df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), #每個時間序列都需要一個ID 'time': range(len(df)), 'closing_price': df['Close'] #我們將使用收盤價 }) #顯示我們數據的前幾行 print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
輸出:
現在讓我們從我們的金融時間序列數據中提取特徵:
#設置特徵提取參數 extraction_settings = MinimalFCParameters() #自動提取特徵 extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) #顯示提取的特徵 print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
輸出:

在這裡,我們使用 MinimalFCParameters() 來指定要提取的特徵。這為我們提供了一組基本的有意義的時間序列特徵,如平均值、變異數和趨勢特徵,這些是理解我們數據中的模式所必需的。
特徵提取中的挑戰
在進行特徵提取時,我們常常遇到挑戰。
當處理大型數據集時,往往會出現高維度和計算限制。例如,從高解析度圖像或長音頻文件中提取特徵可能會消耗大量內存和處理能力。
由於不相關或多餘的特徵而造成過度擬合是另一個常見的挑戰。當提取太多特徵時,模型可能學習到噪聲而非有意義的模式。這在圖像和音頻處理中特別常見,可能會生成成千上萬個特徵。
要克服這些挑戰,請考慮以下策略:
- 使用領域知識選擇相關特徵
- 應用特徵選擇方法來降低維度
- 根據數據類型實施適當的特徵工程技術
這些挑戰需要仔細考慮和平衡功能豐富性與計算效率之間的關係。
結論
特徵提取是機器學習中的一項基本技能,它將原始數據轉換為有意義的表示。通過我們在OpenCV、LibROSA和tsfresh中的實際示例,我們看到了如何從不同類型的數據中提取特徵。通過理解這些技術及其挑戰,我們可以構建有效的機器學習模型。
準備深入了解?請查看以下資源:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning