













機械学習における特徴抽出は、生データを意味のある特性の集合に変換し、冗長性を減少させながら重要な情報を捉えます。次元削減技術や既存データから新しい特徴を作成する方法が関わることがあります。
市場でフルーツを識別しようとしていると想像してみてください。重さ、色、質感、形状、匂いなど無数の属性を考慮することができますが、色やサイズなどわずかな特徴だけでリンゴとオレンジを区別するのに十分であることに気づくかもしれません。これが特徴抽出が行うことです。データの最も情報量の多い特性に焦点を当てるのを支援します。
特徴抽出を行う際、元のデータは数学的に新しい特徴の集合に変換されます。これらの新しい特徴は、データの最も重要な側面を捉えるように設計されており、その複雑さを軽減する可能性があります。抽出された特徴は、元のデータではすぐには明らかにならない基本的なパターンや構造を表すことがよくあります。
特徴量抽出
次のセクションでは、特徴量抽出が機械学習においてなぜ重要なのかを探求し、さまざまなデータタイプから特徴量を抽出するためのさまざまな方法とそのコードを調べます。実践例をお探しの場合は、弊社のPythonにおける次元削減コースをご覧ください。このコースには特徴量抽出に特化した章があります。
機械学習において特徴量抽出が重要な理由は何ですか?
特徴抽出は機械学習において重要な役割を果たします。モデルの成功と失敗の違いを生み出すことができます。なぜこれが効果的な機械学習モデルの構築にとって基本的な要素であるかを見てみましょう。
モデルの精度と効率を向上させる
生データを扱う際、機械学習モデルはしばしば意味のあるパターンとノイズを区別するのに苦労します。特徴抽出はデータの前処理ステップとして機能し、モデルが学習し、実行する能力を大幅に向上させることができます。
モデルのパフォーマンスとトレーニング時間
たとえば、あるモデルが生データで85%の精度を達成した場合、同じモデルが注意深く抽出された特徴で訓練されると95%の精度に達する可能性があります。この改善は、モデルを変更するのではなく、学習するためのより質の高い入力データを与えることで得られます。
高次元データセットの管理
現代のデータセットには、数百または数千の特徴が付属していることがよくあります。これには、特徴抽出が対処するのに役立ついくつかの課題が伴います。
- 次元の呪い: 特徴量の数が増えるにつれて、データは特徴空間でますます疎になります。これにより、モデルが意味のあるパターンを見つけるのが難しくなります。特徴抽出は、重要な関係性を保存しながら次元を削減するよりコンパクトな表現を作り出します。
- メモリ使用量の増加: 高次元データは処理中により多くのストレージとメモリを必要とします。最も関連性の高い特徴のみを抽出することで、データセットのメモリフットプリントを大幅に削減しながら情報価値を維持できます。
- データ可視化:3次元以上のデータを直接可視化することは不可能です。特徴抽出により次元を2つまたは3つに削減することで、データ構造を視覚的にプロットして理解することが可能になります。
特徴抽出は、次元を削減しながら重要な情報を保持することでこれらの課題に対処します。この削減により、広がりのある高次元データがよりコンパクトで管理しやすい形式に変換され、モデルの性能向上につながります。
計算の複雑さを軽減し、過学習を防ぐ
特徴抽出は、機械学習モデルにとって2つの重要な利点を提供します:
- 低い計算要件
- 機能が少ないほどトレーニング時間が短くなります
- モデル展開時のメモリ使用量が削減されます
- より効率的な予測生成
- より良い一般化
- 単純な特徴空間は過学習を防ぐのに役立ちます
- モデルはより堅牢なパターンを学習します
- 新しい未知のデータでのパフォーマンスが向上します
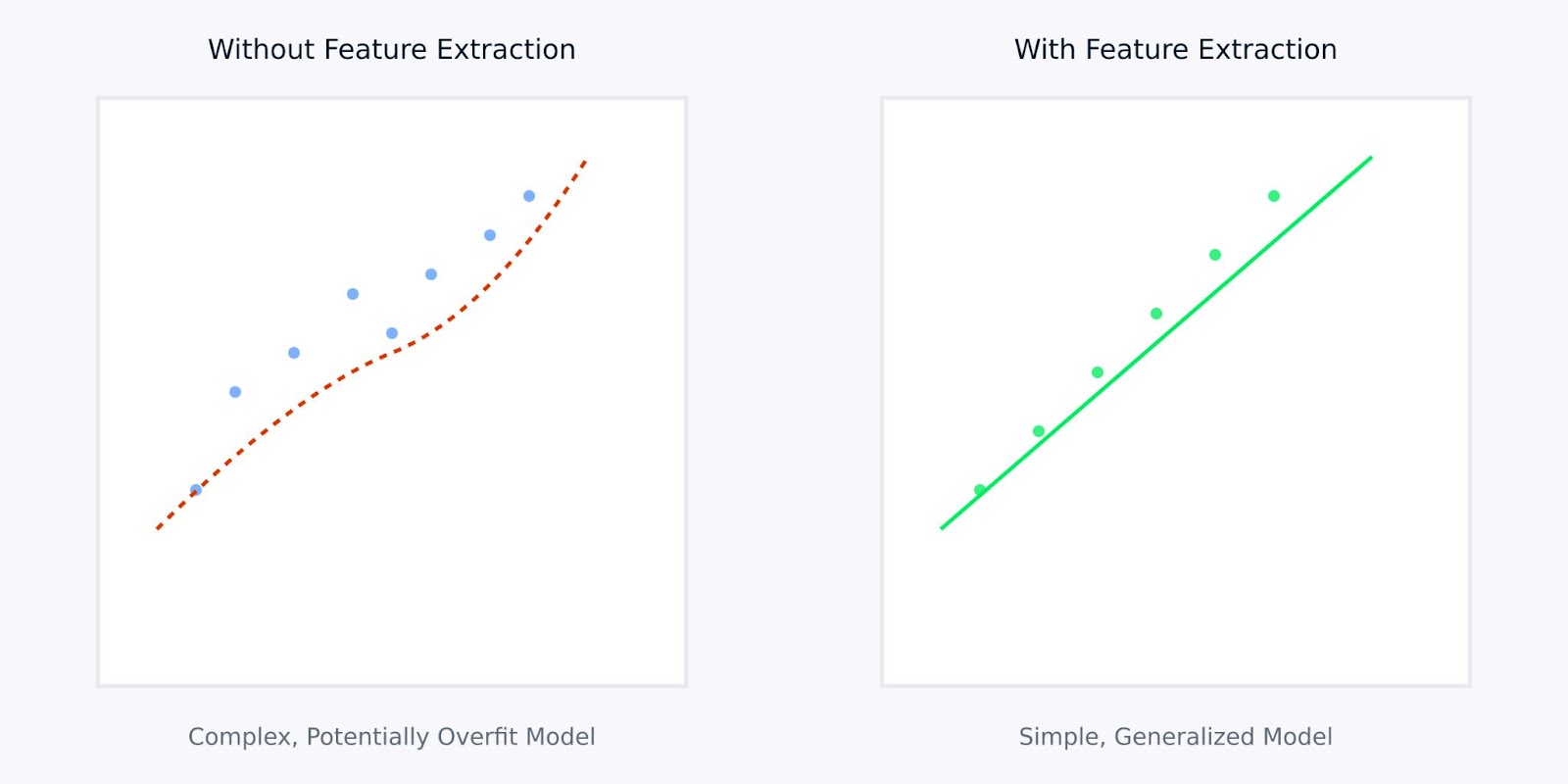
特徴抽出対特徴抽出なし
上記の可視化は、特徴抽出がよりシンプルで堅牢なモデルにつながる方法を示しています。左側のプロットは、ノイズが多く、高次元のデータに適合しようとする複雑なモデルを示しています。一方、右側のプロットは、特徴抽出がより明確で一般化可能なパターンを明らかにする方法を示しています。
生データではなく抽出された特徴量を使用することは、モデルに学習すべき情報の明確で蒸留されたバージョンを提供することと同等です。これにより、学習プロセスがより効率的になるだけでなく、実世界の応用でうまく機能する可能性のあるモデルが生まれます。
次に、特徴抽出の異なる方法を見てみましょう。
特徴抽出の方法
特徴抽出手法は、手動特徴エンジニアリングと自動特徴抽出の2つの主要なアプローチに大きく分類されます。両方の方法を見て、生データを意味のある特徴に変換するのにどのように役立つかを理解しましょう。
手動特徴エンジニアリング
手動特徴エンジニアリングは、ドメインの専門知識を活用して生データから関連する特徴を特定および作成することを含みます。この手作業のアプローチは、問題とデータの理解に依存して、意味のある特徴を作成します。
画像処理において、手動特徴量エンジニアリングには、オブジェクトの境界を識別するためのエッジ検出、色分布を捉えるためのカラーヒストグラム、パターンを数量化するためのテクスチャ分析、オブジェクトのジオメトリを特徴付けるための形状記述子などの技術が含まれることがあります。
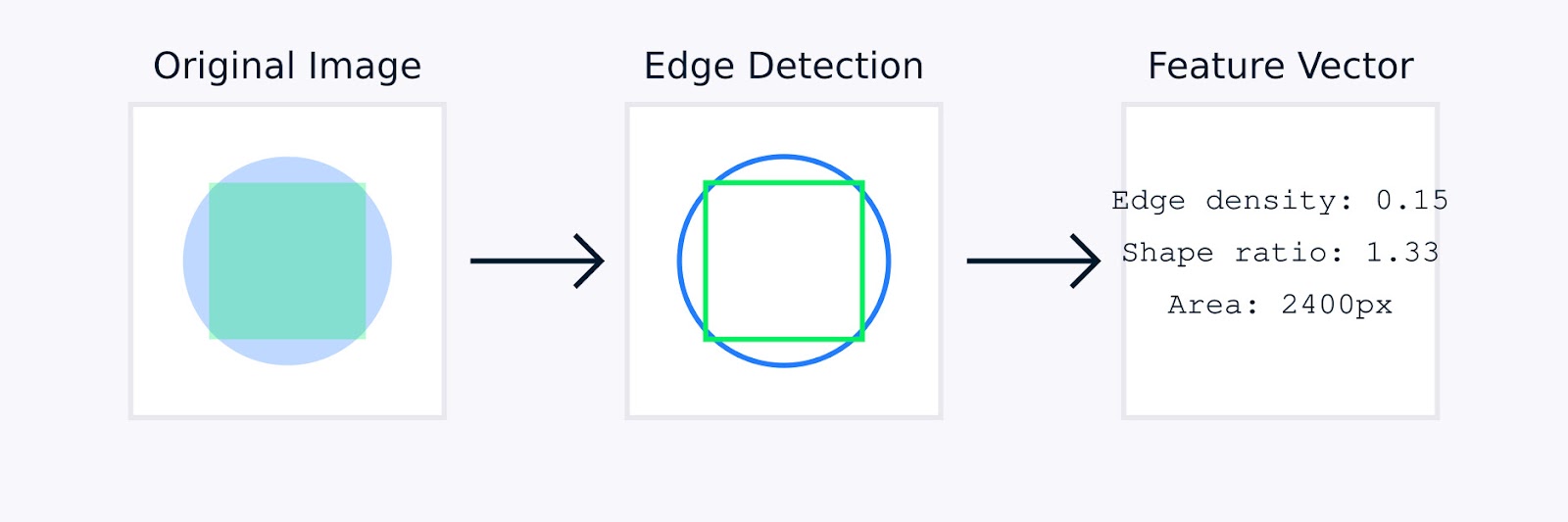
画像特徴抽出
表形式データの場合、手動特徴量エンジニアリングには、既存の特徴量間の相互作用項の作成、対数関数や多項式関数を使用した変数の変換、データポイントを意味のある統計量に集約すること、カテゴリカル変数のエンコーディングなどが含まれることがあります。
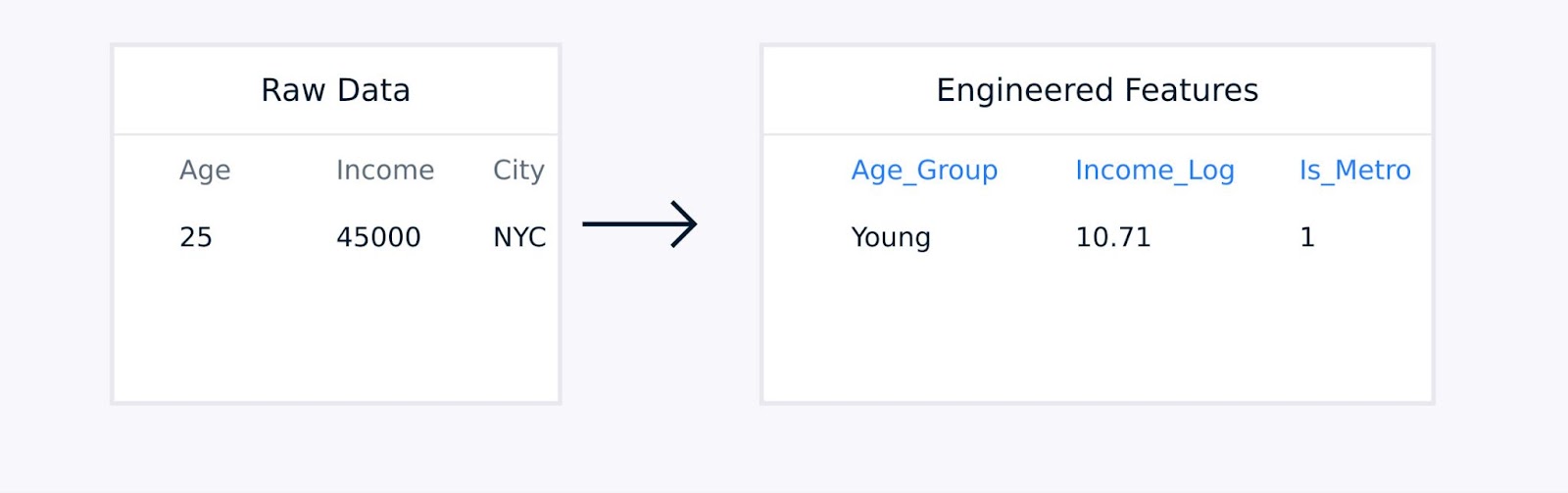
表形式データの特徴抽出
これらの技術は、ドメインの専門知識によってガイドされ、データ表現の品質を向上させ、モデルのパフォーマンスを大幅に向上させることができます。
自動特徴抽出
自動特徴抽出は、明示的な人間のガイダンスなしに特徴を発見して作成するためのアルゴリズムを使用します。これらの方法は、手動の特徴エンジニアリングが不適切または効率的でない複雑なデータセットを扱うときに特に有用です。
一般的な自動化アプローチには、以下が含まれます:
主成分分析(PCA):データを相関のない成分のセットに変換し、各成分が残存分散を最大限に捉えます。このアプローチは特に次元削減に役立ちます。データ内の本質的な情報を保存しながら、その構造を単純化します。
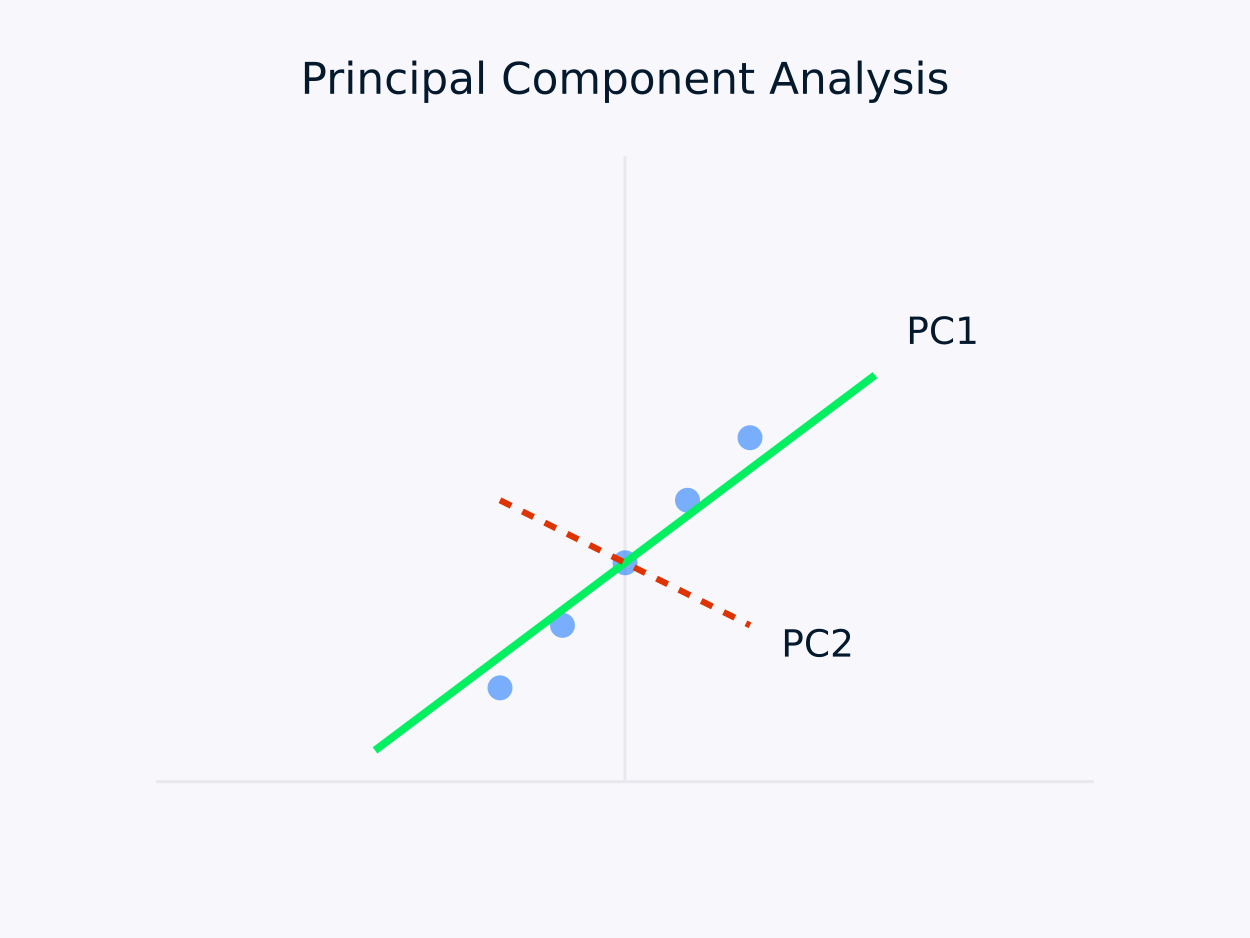
主成分分析(PCA)
オートエンコーダー:これらはデータの圧縮された表現を学習し、非線形関係を捉えるニューラルネットワークです。従来の線形手法が不十分な場合に特に効果的です。
様々なツールやライブラリが登場して、特徴量エンジニアリングのタスクが簡素化されています。例えば、Scikit-learnの分解モジュールには次元削減のための様々な手法が提供されており、PyCaretは自動特徴選択機能を提供しています。
手動および自動化アプローチの両方にはそれぞれの強みがあります。それぞれのアプローチの強みを見てみましょう。
|
手動エンジニアリング |
自動抽出 |
|
ドメイン知識の統合 |
拡張性 |
|
解釈可能な特徴 |
複雑なパターンを処理する |
|
細かい制御 |
人間の偏見を減らす |
|
特定のニーズにカスタマイズ |
隠れた関係を発見する |
手動と自動の方法の選択は、データセットの複雑さ、ドメイン知識の可用性、解釈要件、計算リソース、および時間制約などの要因に依存することがよくあります。
高度に複雑なデータセットや時間とリソースに制約がある場合、自動化された方法は迅速に有用な特徴量を生成できます。逆に、ドメインの専門知識が利用可能で解釈可能性が重要な場合、手動方法が好ましい場合があります。これにより、問題に密接に合わせたカスタマイズされた特徴量エンジニアリングが可能になります。
実践では、多くの成功した機械学習プロジェクトは両方のアプローチを組み合わせ、ドメインの専門知識を活用して特徴量エンジニアリングをガイドし、同時に自動化された方法を活用して、人間の専門家にはすぐには明らかにならない追加のパターンを発見します。
次のセクションでは、さまざまなドメインでいくつかの特徴抽出技術を見ていきます。
特徴抽出技術
各種のデータには、それぞれ固有の特性に最適化された特徴抽出技術が必要です。異なるタイプのデータに対する最も一般的な技術を見てみましょう。

特徴抽出技術
画像の特徴抽出
画像の特徴抽出は、生のピクセルデータを意味のある表現に変換し、重要な視覚情報を捉えるものです。現代のコンピュータビジョンで使用される技術には、伝統的な方法、ディープラーニングベースの方法、統計的方法の3つの主要なカテゴリがあります。

画像の特徴抽出方法
それぞれの方法を見てみましょう。
伝統的なコンピュータビジョンの方法
スケール不変特徴変換(SIFT)は、画像内の特徴的なローカル特徴を検出する堅牢な方法です。これは、キーポイントを識別してディスクリプタを生成することによって機能します。これらのディスクリプタは次のようになっています:
- 画像のスケーリングおよび回転に不変
- 照明の変化に部分的に不変
- ローカル幾何学的歪みに対して堅牢
SIFTアルゴリズムは、複数の段階を経て画像を処理します。まず、スケール空間の極値検出から始め、スケールに不変な潜在的なキーポイントを特定します。次に、キーポイントの局所化により、これらの候補を洗練し、安定していないポイントを破棄します。
この後、方向割り当ては各キーポイントに一貫した方向を決定し、回転不変性を確保します。最後に、キーポイント記述子生成は、ローカル画像の勾配に基づいた独特な記述子を作成し、画像間の堅牢なマッチングを容易にします。
別の方法は、方向勾配ヒストグラム(HOG)です。これは、画像全体を通じた勾配パターンを分析することで局所形状情報を捉えます。プロセスは、エッジの詳細を強調するために画像全体で勾配を計算することから始まります。
その後、画像は小さなセルに分割され、各セルに対して勾配方向のヒストグラムが作成され、ローカルな構造を要約します。最後に、これらのヒストグラムはより大きなブロック全体で正規化され、照明やコントラストの変動に対して頑健性が確保され、物体検出や認識などのタスクに対する堅牢な特徴記述子が得られます。
深層学習手法
畳み込みニューラルネットワーク(CNN)は、階層的な表現を自動的に学習することで特徴抽出の方法を変えました。

CNNによる特徴抽出
CNNは階層構造を通じて特徴を学習します。初期の層では、エッジや色などの基本的な視覚要素を検出します。中間層はこれらの要素を組み合わせてパターンや形状を認識し、さらに深い層では複雑なオブジェクトを捉えてシーン理解を可能にします。
転移学習を使用することで、大規模なデータセットで訓練されたモデルから事前学習された特徴を使用できるため、データが限られている場合に特に価値があります。
統計的手法
統計的手法は画像からグローバルおよびローカルなパターンを抽出し、頑健な画像分析と解釈を容易にします。
例えば、カラーヒストグラムは画像内の色の分布を表し、回転やスケールによらない特徴を提供し、画像分類や検索などのタスクに特に役立ちます。
テクスチャ解析は、Gray Level Co-occurrence Matrices(GLCM)などの技術を使用して繰り返しパターンと表面特性を捉え、材料認識やシーン分類などのアプリケーションに効果的です。
さらに、エッジ検出は、Sobel、Canny、Laplacianオペレータなどの方法によって境界や強度の変化を特定し、物体検出や形状解析に重要な役割を果たします。
特徴抽出方法の選択は、いくつかの要因に依存します。特定のタスクの要件に合わせる必要があり、利用可能な計算リソースを考慮し、解釈可能性の必要性を考慮する必要があります。
さらに、データセットの特性(サイズ、ノイズレベル、複雑さなど)や、スケール、回転、照明などの必要な不変性の特性も重要です。
オーディオ特徴抽出
人間と同じように音声を理解するコンピュータを教えようとしていると想像してみてください。これがMel周波数ケプストラル係数(MFCC)が登場する場面です。
MFCCは、音を私たちの耳が処理する方法に類似した方法で音を分解する特別なオーディオ特徴です。人間が最も感度が高い周波数に焦点を当てているため、特に効果的です。音をコンピュータと人間の聴覚の両方が意味を見出せる形式に変換すると考えてください。
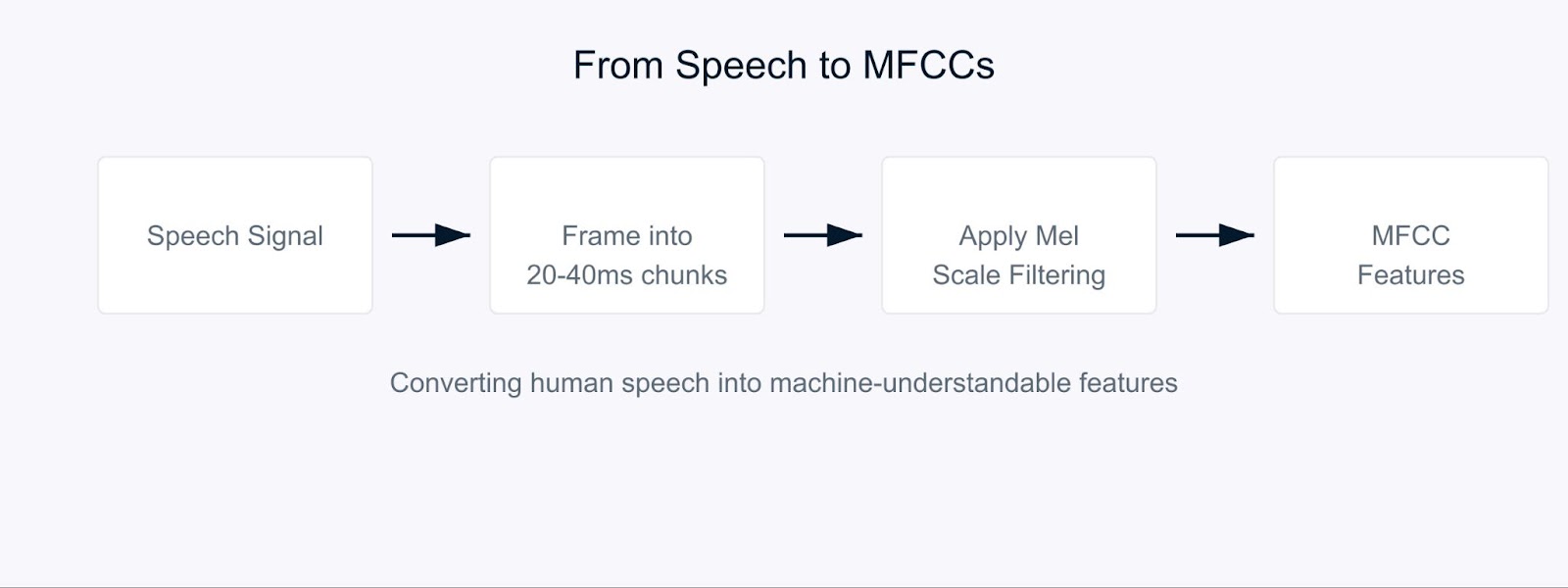
Mel周波数ケプストラル係数
このプロセスは、オーディオ信号を通常20〜40ミリ秒の短いチャンクに分割することから始まります。各チャンクに対して、生の音波を周波数成分に変換する一連の数学的変換を適用します。ここで興味深いことが起こります。すべての周波数を等しく扱うのではなく、Melスケールと呼ばれるものを使用します。
![]()
この式は複雑に見えるかもしれませんが、実際には人間が音を知覚する方法に周波数をマッピングしています。私たちの耳は、高い周波数よりも低い周波数の違いを検出するのが得意であり、メル尺度はこの自然なバイアスを考慮しています。
音声認識では、MFCCが話者を理解し、話者が何を言っているかを把握する基盤として機能します。スマートフォンの仮想アシスタントに話しかけるとき、MFCCがあなたの声を処理するのに使用されている可能性が高いです。これらの係数は、各人の声の特徴を捉えるのに役立ち、話者識別システムにとって非常に重要です。
音声における感情分析では、MFCCが声の微妙な変化を検出し、感情を示すのに役立ちます。ピッチ、トーン、話す速さの変化を捉えることができ、その変化から誰かが幸せか悲しいか怒っているか中立かを示すことができます。たとえば、顧客サービスの電話を分析する際、MFCCは、話し方だけでなく発言内容に基づいて顧客の満足度レベルを特定するのに役立ちます。
時間系列の特徴抽出
時間系列データを扱う際、意味のある特徴を抽出することで、時間と共に進化するパターンやトレンドを捉えることができます。生の時間系列データを有用な特徴に変換するために使用される主な技術を見てみましょう。

時間系列特徴抽出方法
フーリエ変換は、時間系列データを周波数成分に分解し、隠れた周期パターンを明らかにします。その式は次のとおりです:
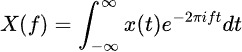
統計手法は、周波数分析を補完することで、時間的特性を捉えます。移動平均、標準偏差、トレンド要素などの一般的な特徴が含まれます。これらの技術は、特に財務予測において非常に強力であり、市場のトレンドや異常を特定するのに役立ちます。
たとえば、株価分析では、フーリエ特徴を統計的指標と組み合わせることで、長期的なトレンドや周期的なパターンを明らかにすることができます。同様に、産業現場では、これらの手法が、時間経過に伴うセンサーデータのパターンを分析することで、機器の異常を検出するのに役立ちます。
特徴抽出用のツールとライブラリ
これらの特徴抽出手法を実装するのに役立ついくつかの必須ツールを見てみましょう。
特徴抽出のためのツールとライブラリ
画像処理においては、OpenCVとscikit-imageがさまざまな特徴抽出手法を実装するための包括的なツールを提供しています。これらのライブラリは、先に議論したSIFT、HOG、およびその他のアルゴリズムの効率的な実装を提供しています。深層学習アプローチを使用する場合、TensorFlowやPyTorchなどのフレームワークが非常に有用となります。詳細は、OpenCVチュートリアルを参照してください。
オーディオ処理タスクは、LibROSAなどのライブラリを使用することで簡素化されます。LibROSAはMFCCやその他の音響特徴を抽出するのに優れています。PyAudioAnalysisは、オーディオ解析タスクのための高レベルなインターフェースを備え、これらの機能を拡張します。
時系列データに対しては、tsfreshやFeaturetoolsが特徴抽出プロセスを自動化します。これらのライブラリは、一連のデータから関連する特徴を自動的に生成および選択し、特徴エンジニアリングではなくモデル開発に集中しやすくします。
特徴抽出の例
実践的な例を通じて知識を活用しましょう。コンピュータビジョンにおける最も一般的なアプリケーションの1つである画像特徴抽出から始めます。
OpenCVを使用した画像特徴抽出
まず、必要なライブラリをインポートしましょう
# 必要なライブラリをインポート import cv2 import numpy as np import matplotlib.pyplot as plt
さて、画像を読み込んで関連する特徴を抽出しましょう。この例では、インターネットからダウンロードしたゴジラの画像を使用します。
# 画像を読み込む image = cv2.imread('godzilla.jpg') # BGR形式でロードされるため、BGRからRGBに変換する image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # オリジナルの画像を表示する plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
出力:

エッジ検出を適用する前に、画像を前処理する必要があります。以下のように行います:
# 画像をグレースケールに変換する gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # ノイズを減らすためにガウシアンぼかしを適用する blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
最後に、Cannyエッジ検出アルゴリズムを適用して結果を可視化しましょう:
# Cannyエッジ検出を適用 edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # 結果を表示 plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
出力:

Cannyエッジ検出器は、画像内の重要な境界や特徴を特定するのに役立ち、さらなる分析や機械学習モデルへの入力として使用できます。
LibROSAを使用してオーディオからMFCCを抽出する
オーディオファイルを処理する前に、必要なライブラリをインストールする必要があります。LibROSAはPython標準ライブラリに含まれていないため、pipを使用してインストールします:
# 必要なライブラリをインストール # これらのコマンドをターミナルまたはコマンドプロンプトで実行 pip install librosa pip install numpy pip install matplotlib
LibROSAは音楽やオーディオ解析のために設計された強力なライブラリですので、他の必要なライブラリと共にインポートを開始しましょう:
# 必要なライブラリをインポート import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
音声ファイルには波形形式で多くの情報が含まれています。このデータで作業するために、最初にプログラムにロードする必要があります。LibROSAは、オーディオファイルを分析可能な形式に変換してくれることで、これを実現します:
# オーディオファイルをロード # この例では、期間は10秒までに制限されています audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # 波形を表示 plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
出力:
今、オーディオをロードしたので、それから意味のある特徴を抽出する必要があります。私たちの耳は音を自然に異なる周波数成分に分解しますが、MFCCはこのプロセスを模倣します。これらの係数を計算するために、librosaの特徴抽出関数を使用します:
# MFCC特徴を抽出 mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # MFCCを表示 plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
出力:
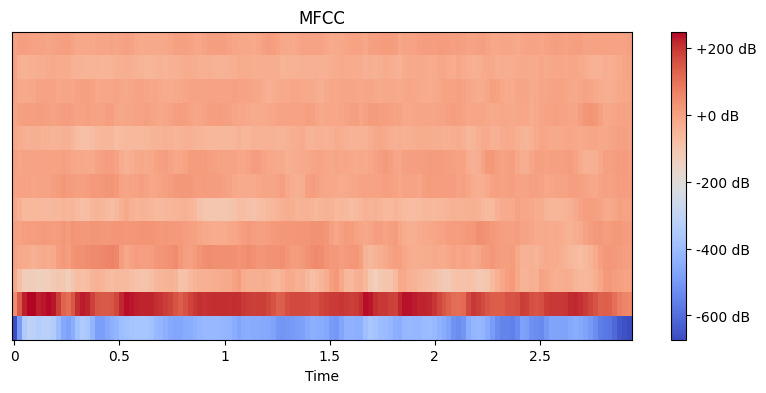
ここでは、n_mfcc=13を設定します。なぜなら、最初の13個の係数が通常、音声認識などのタスクに役立つ音の最も重要な側面を捉えるからです。結果の可視化では、これらの特徴が時間とともにどのように変化するかが示されます。 より明るい色ほど値が高いことを表します。
tsfreshを使用した時系列データからの特徴抽出
まず、必要なライブラリをインストールしましょう。金融データを取得するためにyfinanceを使用し、特徴抽出にtsfreshを使用します:
# 必要なライブラリをインストール # これらのコマンドをターミナルまたはコマンドプロンプトで実行します pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
次に、ライブラリをインポートして実際の金融データを取得しましょう:
# 必要なライブラリをインポート import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
実際の株式市場データを取得しましょう。例としてAppleの株式データを使用します:
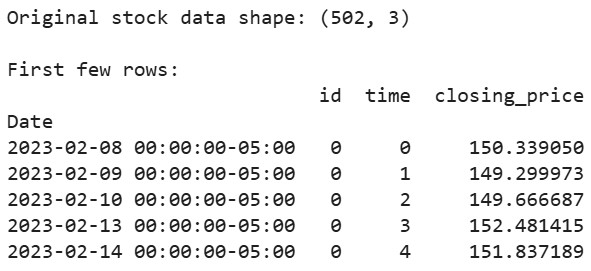
# 過去2年間のAppleの株価データをダウンロード aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # tsfreshが期待する形式でデータを準備 df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # 各時系列にはIDが必要です 'time': range(len(df)), 'closing_price': df['Close'] # 終値を使用します }) # データの最初の数行を表示 print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
出力:
さて、金融時系列データから特徴量を抽出しましょう:
# 特徴抽出パラメータを設定 extraction_settings = MinimalFCParameters() # 自動的に特徴量を抽出 extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # 抽出された特徴量を表示 print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
出力:

ここでは、MinimalFCParameters()を使用して、抽出する特徴を指定します。これにより、平均値、分散、傾向特性などの基本的な意味のある時系列特徴が得られ、データのパターンを理解するのに重要です。
特徴抽出の課題
特徴抽出を行う際には、しばしば課題に直面します。
大規模データセットを扱う際には、高次元性と計算上の制約が頻繁に発生します。たとえば、高解像度画像や長いオーディオファイルから特徴を抽出する場合、大量のメモリと処理能力を消費する可能性があります。
無関連または冗長な特徴による過学習は、別の一般的な課題です。特徴が多すぎると、モデルは意味のあるパターンではなくノイズを学ぶ可能性があります。これは、数千の特徴が生成される画像処理や音声処理で特に一般的です。
これらの課題を克服するために、次の戦略を考慮してください:
- 関連する特徴を選択するためにドメイン知識を使用する
- 次元削減のための特徴選択手法を適用する
- データタイプに基づいた適切な特徴エンジニアリング技術を実装する
これらの課題には、機能の豊富さと計算効率のバランスを考慮する必要があります。
結論
特徴抽出は、機械学習における基本的なスキルであり、生データを意味のある表現に変換します。OpenCV、LibROSA、tsfreshを使用した実践的な例を通じて、さまざまなタイプのデータから特徴を抽出する方法を見てきました。これらの技術とそれらが直面する課題を理解することで、効果的な機械学習モデルを構築することができます。
さらに詳しく知りたいですか? 以下のリソースをチェックしてみてください:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning