













يقوم استخراج الميزات في تعلم الآلة بتحويل البيانات الخام إلى مجموعة من الخصائص المعنوية، التي تلتقط المعلومات الأساسية مع تقليل التكرار. يمكن أن ينطوي على تقنيات تقليل الأبعاد وطرق إنشاء ميزات جديدة من البيانات الحالية.
تخيل أنك تحاول تحديد الفواكه في سوق. بينما يمكنك أن تنظر إلى عدد لا يحصى من السمات (الوزن، اللون، القوام، الشكل، الرائحة، إلخ)، قد تدرك أن بضع ميزات رئيسية مثل اللون والحجم كافية للتمييز بين التفاح والبرتقال. هذا بالضبط ما يفعله استخراج الميزات. إنه يساعدك على التركيز على الخصائص الأكثر إيضاحًا في بياناتك.
عند أداء استخراج الميزات، تتحول البيانات الأصلية رياضيًا إلى مجموعة جديدة من الميزات. تم تصميم هذه الميزات الجديدة لالتقاط أهم جوانب البيانات بينما يتم تقليل تعقيدها بشكل محتمل. غالبًا ما تمثل الميزات المستخرجة أنماطًا أو هياكلًا أساسية قد لا تكون ظاهرة على الفور في البيانات الأصلية.
استخراج الميزات
في الأقسام القادمة، سنستكشف لماذا يعتبر استخراج الميزات مهمًا جدًا في تعلم الآلة ونلقي نظرة على طرق مختلفة لاستخراج الميزات من أنواع مختلفة من البيانات بالإضافة إلى رموزها. إذا كنت ترغب في بعض الأمثلة التطبيقية، تحقق من دورة تقليل الأبعاد في بايثون لدينا، التي تحتوي على فصل مخصص لاستخراج الميزات.
لماذا يعتبر استخراج الميزات مهمًا في تعلم الآلة؟
يلعب استخراج الميزات دورًا مهمًا في التعلم الآلي. يمكن أن يحدث الفارق بين نموذج يفشل وآخر ينجح. دعنا نرى لماذا هذا أمر أساسي جدًا لبناء نماذج التعلم الآلي الفعالة.
تعزيز دقة النموذج وكفاءته
عند العمل مع البيانات الخام، نماذج التعلم الآلي غالبًا ما تواجه صعوبة في التمييز بين أنماط ذات دلالة والضوضاء. يعمل استخراج الميزات كخطوة معالجة بيانات يمكن أن تحسن بشكل كبير كيفية تعلم وأداء نماذجك.
أداء النموذج مقابل وقت التدريب
على سبيل المثال، عندما يحقق النموذج دقة بنسبة 85٪ باستخدام البيانات الخام، قد يصل نفس النموذج إلى دقة 95٪ عند تدريبه على ميزات مستخرجة بعناية. هذا التحسين لا يأتي من تغيير النموذج وإنما من تزويده ببيانات إدخال ذات جودة أفضل ليتعلم منها.
إدارة مجموعات البيانات العالية الأبعاد
غالبًا ما تأتي مجموعات البيانات الحديثة مع مئات أو آلاف الميزات. وهذا يحمل العديد من التحديات التي يساعد استخراج الميزات في معالجتها.
- لعنة الأبعاد: مع زيادة عدد الميزات، يصبح البيانات أكثر اندفاعا في الفضاء الميزواتي. وهذا يجعل من الصعب على النماذج العثور على أنماط معنوية. يخلق استخراج الميزات تمثيلًا أكثر انضغاطًا يحتفظ بالعلاقات المهمة بينما يقلل من الأبعاد.
- استخدام الذاكرة العالي: تتطلب البيانات ذات الأبعاد العالية مزيدًا من التخزين والذاكرة أثناء المعالجة. من خلال استخراج فقط الميزات الأكثر صلة، يمكننا تقليل بشكل كبير بصمة الذاكرة لمجموعات البيانات الخاصة بنا مع الحفاظ على قيمتها المعلوماتية.
- تصور البيانات: من المستحيل تصوير البيانات التي تحتوي على أكثر من ثلاثة أبعاد مباشرة. يمكن لاستخراج الميزات تقليل الأبعاد إلى ميزتين أو ثلاث ميزات، مما يجعل من الممكن رسم البيانات وفهم هيكلها بصورة بصرية.
يتناول استخراج الميزات هذه التحديات من خلال تقليل الأبعاد مع الحفاظ على المعلومات الأساسية. يحول هذا التقليل البيانات ذات الأبعاد العالية والمتشعبة إلى شكل أكثر انضباطا وإدارة، مما يؤدي إلى زيادة أداء النموذج.
تقليل التعقيد الحسابي ومنع التجاوز
يوفر استخراج الميزات فائدتين حاسمتين لنماذج تعلم الآلة:
- متطلبات حسابية أقل
- تعني السمات الأقل سرعة تدريب أسرع
- استخدام ذاكرة أقل أثناء نشر النموذج
- إنتاج تنبؤ أكثر كفاءة
- تحسين التعميم
- تساعد المساحات البسيطة للميزات على منع الفرط التكيفي
- يتعلم النماذج أنماطًا أكثر قوة
- أداء محسن على البيانات الجديدة غير المرئية
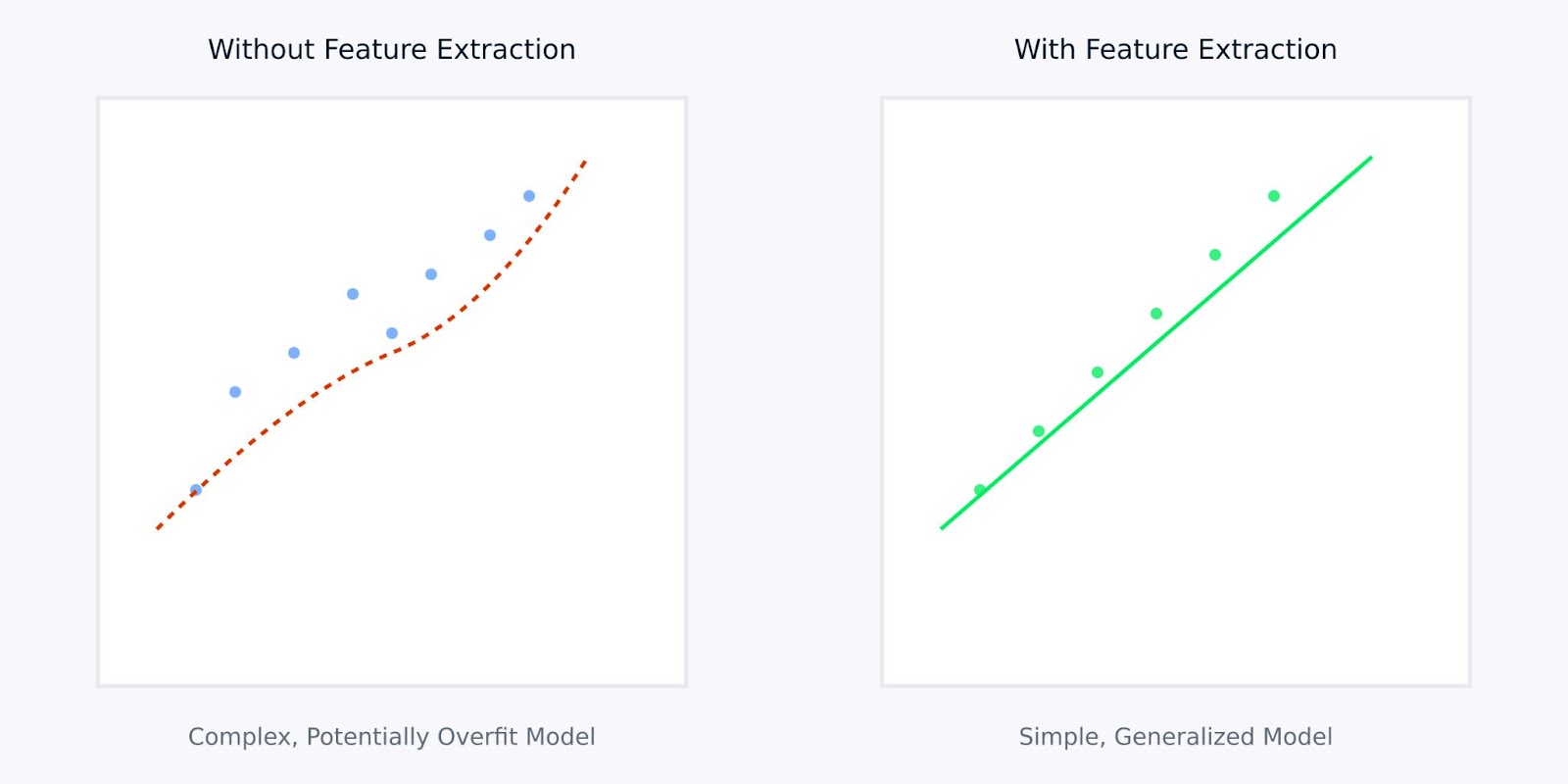
استخراج الميزات مقابل بدون استخراج الميزات
الرسم البياني أعلاه يوضح كيف يمكن لاستخراج الميزات أن يؤدي إلى نماذج أبسط وأكثر قوة. يُظهر الرسم البياني الأيسر نموذجًا معقدًا يحاول تناسب البيانات الضجيجية ذات الأبعاد العالية، بينما يوضح الرسم البياني الأيمن كيف يمكن لاستخراج الميزات كشف نمط أوضح وأكثر تعميمًا.
العمل مع الميزات المستخرجة بدلاً من البيانات الخام يشبه منح النموذج الخاص بك نسخة واضحة، مقتصرة من المعلومات التي يحتاج إلى تعلمها. هذا لا يجعل عملية التعلم أكثر كفاءة فحسب، بل يؤدي أيضًا إلى نماذج من المرجح أن تؤدي بشكل جيد في التطبيقات العملية.
الآن، دعنا نرى أساليب مختلفة لاستخراج الميزات.
أساليب استخراج الميزات
يمكن تصنيف طرق استخراج الميزات بشكل عام إلى نهجين رئيسيين: هندسة الميزات اليدوية واستخراج الميزات التلقائي. دعنا نلقي نظرة على كلتا هاتين الطريقتين لفهم كيف تساعد في تحويل البيانات الخام إلى ميزات ذات دلالة.
هندسة الميزات اليدوية
تنطوي هندسة الميزات اليدوية على استخدام الخبرة في المجال لتحديد وإنشاء ميزات ذات صلة من البيانات الخام. يعتمد هذا النهج العملي على فهمنا للمشكلة والبيانات لابتكار ميزات ذات دلالة.
في معالجة الصور, قد تنطوي الهندسة اليدوية للسمات على تقنيات مثل اكتشاف الحواف لتحديد حدود الكائنات، تاريخ الألوان لالتقاط توزيع الألوان، تحليل القوام لقياس الأنماط، ووصف شكل لتوصيف هندسة الكائنات.
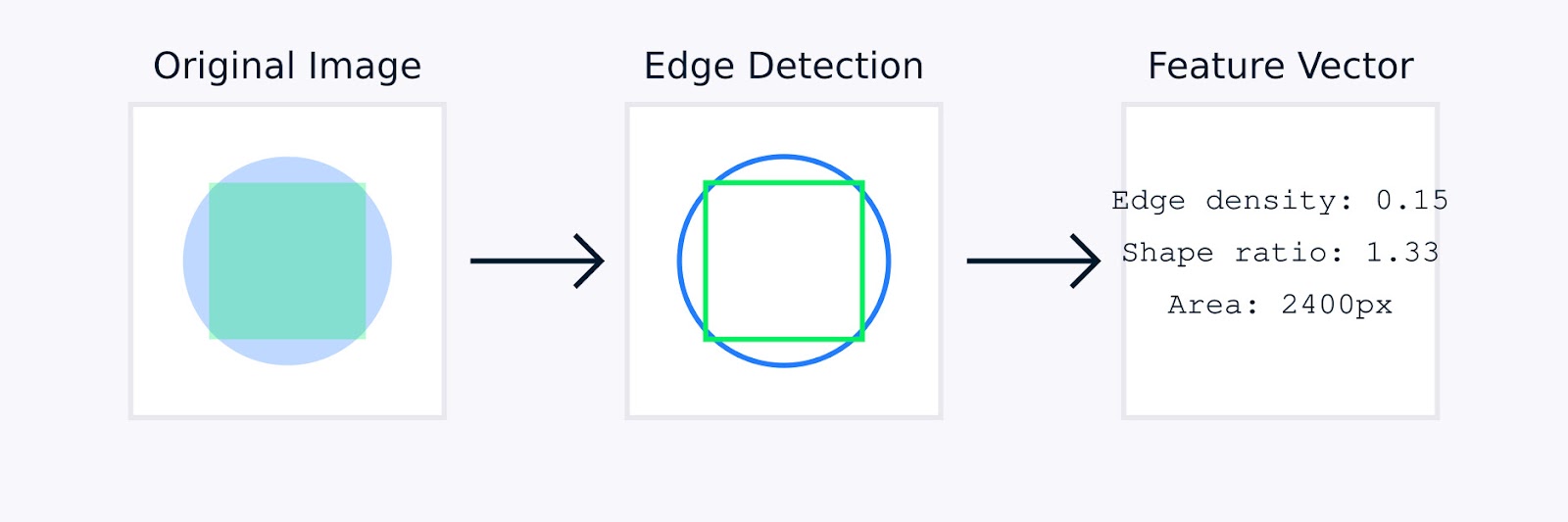
استخراج سمات الصور
بالنسبة للبيانات الجدولية، تنطوي الهندسة اليدوية للسمات على إنشاء مصطلحات تفاعلية بين السمات الحالية، تحويل المتغيرات باستخدام وظائف لوغاريتمية أو متعددة الحدود، تجميع نقاط البيانات في إحصاءات ذات دلالة، وترميز المتغيرات القطعية.
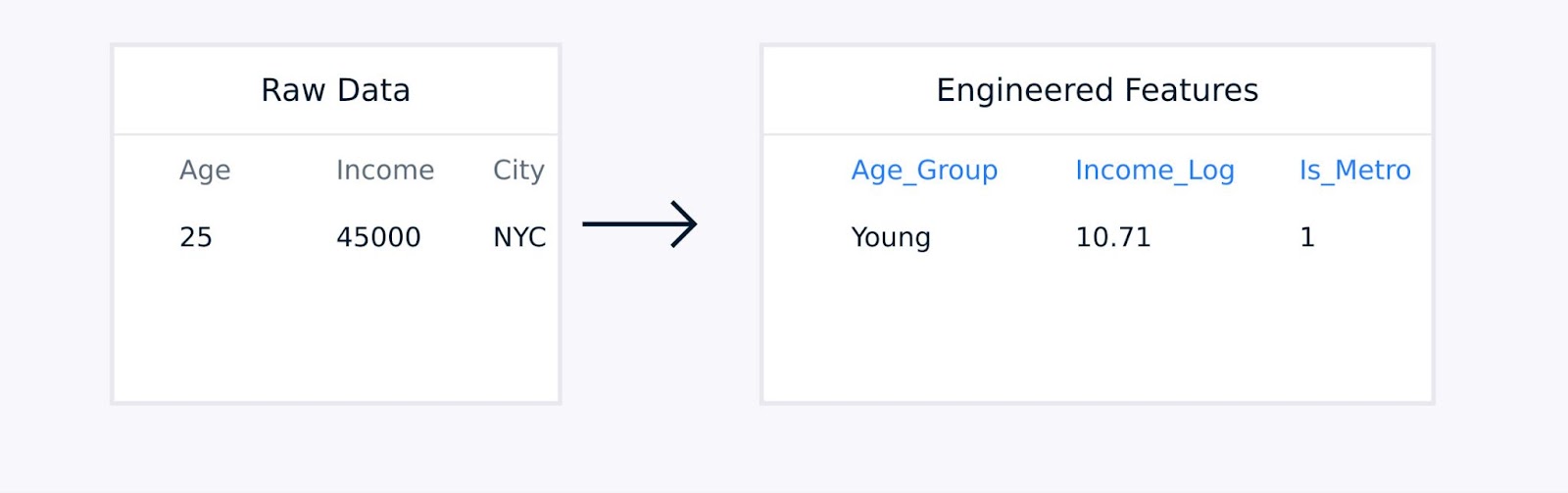
استخراج ميزة البيانات الجدولية
تعمل هذه التقنيات، بتوجيه من الخبراء في المجال، على تحسين جودة تمثيل البيانات ويمكن أن تحسن أداء النموذج بشكل كبير.
استخراج الميزات التلقائي
يستخدم استخراج الميزات التلقائي خوارزميات لاكتشاف وإنشاء الميزات دون توجيه بشري صريح. تكون هذه الطرق مفيدة بشكل خاص عند التعامل مع مجموعات بيانات معقدة حيث يمكن أن يكون تصميم الميزات اليدوي غير عملي أو غير كفء.
النهج التلقائي المشترك يشمل:
تحليل المكونات الرئيسية (PCA): يحول البيانات إلى مجموعة من المكونات غير المترابطة، حيث يتم التقاط الانحراف المتبقي الأقصى في كل مكون. هذا النهج مفيد بشكل خاص لتقليل الأبعاد، حيث يحتفظ بالمعلومات الأساسية داخل البيانات مع تبسيط هيكلها.
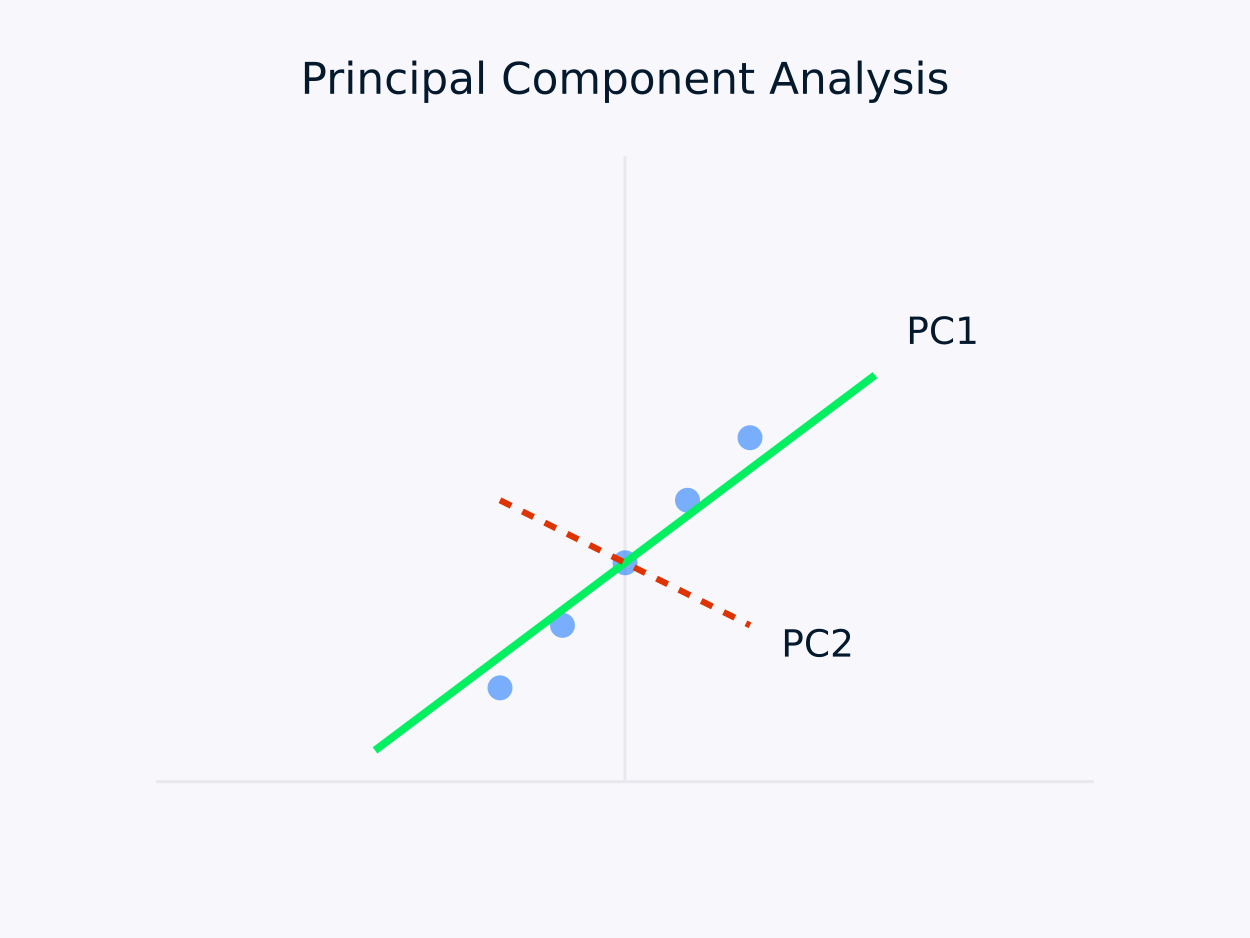
تحليل المكونات الرئيسية (PCA)
المشفرات التلقائية: هذه شبكات عصبية تتعلم التمثيلات المضغوطة للبيانات، تلتقط العلاقات غير الخطية. إنها فعالة بشكل خاص لمجموعات البيانات عالية الأبعاد، حيث قد تفشل الطرق الخطية التقليدية.
ظهرت أدوات ومكتبات مختلفة لتبسيط مهام هندسة الميزات. على سبيل المثال، يوفر وحدة تحلل الانحدار في Scikit-learn مجموعة من الطرق لتقليل الأبعاد، ويوفر PyCaret قدرات اختيار الميزات الآلية.
كل من النهج اليدوي والآلي لهما نقاط قوة. دعنا نلقي نظرة على نقاط قوة كل نهج.
|
الهندسة اليدوية |
الاستخراج التلقائي |
|
دمج المعرفة المجالية |
قابلية التوسع |
|
الميزات التفسيرية |
تتعامل مع الأنماط المعقدة |
|
التحكم دقيق التفاصيل |
تقليل التحيز البشري |
|
مخصص للاحتياجات الخاصة |
اكتشاف العلاقات المخفية |
يعتمد اختيار الطريقة اليدوية أو الآلية غالبًا على عوامل مثل تعقيد مجموعة البيانات، وتوافر الخبرة في المجال، ومتطلبات التفسيرية، والموارد الحسابية، وقيود الوقت.
عندما تكون البيانات معقدة للغاية أو عندما تكون الوقت والموارد محدودة، يمكن للأساليب الآلية إنتاج ميزات مفيدة بسرعة. وعلى الجانب الآخر، قد تكون الأساليب اليدوية مفضلة عند توفر الخبرة في المجال وعندما تكون قابلية التفسير أمرًا مهمًا، مما يسمح بتصميم ميزات مخصصة تتوافق وثيقة مع المشكلة الموجودة.
في الممارسة العملية، تجمع العديد من مشاريع التعلم الآلي الناجحة بين الطريقتين، باستخدام الخبرة في المجال لتوجيه تصميم الميزات بينما يستفيدون من الأساليب الآلية لاكتشاف أنماط إضافية قد لا تكون واضحة على الفور للخبراء البشر.
في القسم القادم، سنلقي نظرة على عدة تقنيات استخراج الميزات في مجالات مختلفة.
تقنيات استخراج الميزات
كل نوع من البيانات يتطلب تقنيات معينة لاستخراج الميزات المُحسَّنة لخصائصها الفريدة. دعونا نلقي نظرة على أكثر التقنيات شيوعًا لأنواع مختلفة من البيانات.

تقنيات استخراج الميزات
استخراج ميزات الصور
يُحول استخراج ميزات الصور البيانات النقطية الخام إلى تمثيلات ذات معنى تلتقط المعلومات البصرية الأساسية. هناك ثلاث فئات رئيسية من التقنيات المستخدمة في رؤية الحاسوب الحديثة. وهي الأساليب التقليدية، والأساليب المعتمدة على التعلم العميق، والأساليب الإحصائية.

أساليب استخراج ميزات الصور
لنلق نظرة على كل من الأساليب.
أساليب الرؤية الحاسوبية التقليدية
تحويل تميز الميزات الثابت (SIFT) هو طريقة قوية تكتشف الميزات المحلية المميزة في الصور. يعمل عن طريق تحديد نقاط مفتاحية وإنشاء وصفوف تكون:
- ثابتة مقايسة الصورة والدوران
- جزئيًا ثابتة لتغيرات الإضاءة
- قوية للانحراف الهندسي المحلي
يعالج خوارزمية SIFT الصور من خلال عدة مراحل. تبدأ بكشف نقاط البؤر في المساحة المقياسية لتحديد نقاط مفتاحية محتملة تكون ثابتة مقياسيًا. بعد ذلك، تقوم عملية تحديد مواقع نقاط المفتاح بتحسين هذه المرشحات عن طريق تحديد مواقعها الدقيقة والتخلص من النقاط غير المستقرة.
بعد ذلك، يحدد تعيين الاتجاه التوجيه المتسق لكل نقطة رئيسية، مما يضمن عدم التأثر بالدوران. وأخيرًا، يتم إنشاء وصف مفتاح النقطة الذي ينشئ وصفوفًا مميزة بناءً على تدرجات الصورة المحلية، مما يسهل العثور على تطابق قوي بين الصور.
طريقة أخرى هي هيستوغرام التدرجات الموجهة (HOG). إنها تلتقط معلومات الشكل المحلية عن طريق تحليل أنماط التدرج عبر الصورة. يبدأ العملية بحساب التدرجات عبر الصورة لتسليط الضوء على تفاصيل الحواف.
ثم يتم تقسيم الصورة إلى خلايا صغيرة، ولكل خلية، يتم إنشاء هستوغرام لاتجاهات التدرج لتلخيص الهيكل المحلي. وأخيرًا، يتم تقييم هذه الهستوغرامات عبر كتل أكبر لضمان القوة ضد التغيرات في الإضاءة والتباين، مما ينتج في وصف ميزة قوي لمهام مثل اكتشاف الكائنات والتعرف عليها.
أساليب التعلم العميق
الشبكات العصبية التصنيفية التناسبية(CNNs) قد غيرت كيفية استخراج الميزات من خلال تعلم التمثيليات التسلسلية تلقائيًا.

استخراج الميزات باستخدام CNN
تتعلم الشبكات العصبية التكرارية المميزات من خلال هيكلها الهرمي. في الطبقات الأولى، تكتشف العناصر البصرية الأساسية مثل الحواف والألوان. تجمع الطبقات الوسطى بين هذه العناصر للتعرف على الأنماط والأشكال، بينما تلتقط الطبقات الأعمق الكائنات المعقدة وتمكن من فهم السياق.
يسمح تقنية نقل التعلم لنا باستخدام هذه المميزات المسبقة المتعلمة من النماذج المدربة على مجموعات بيانات كبيرة، مما يجعلها قيمة بشكل خاص عند العمل مع بيانات محدودة.
الأساليب الإحصائية
تستخرج الأساليب الإحصائية أنماطًا عالمية ومحلية من الصور، مما يسهل تحليل الصور بشكل قوي وتفسيرها.
على سبيل المثال، هيستوغرامات الألوان تمثل توزيع الألوان داخل صورة وتوفر ميزات تدور وتتحجم بشكل مستقل عن التدوير، مما يجعلها مفيدة بشكل خاص لمهام مثل تصنيف الصور والاسترجاع.
تحليل القوام يلتقط الأنماط المتكررة وخصائص السطح باستخدام تقنيات مثل مصفوفات تكرار مستوى اللون (GLCM)، والتي تكون فعالة لتطبيقات تشمل التعرف على المواد وتصنيف المشاهد.
بالإضافة إلى ذلك، كشف الحواف يحدد الحدود والتغييرات الكبيرة في الكثافة من خلال طرق مثل مشغلات Sobel و Canny و Laplacian، مما يلعب دورًا حاسمًا في اكتشاف الكائنات وتحليل الأشكال.
اختيار طريقة استخراج الميزات يعتمد على عدة عوامل. يجب أن تتماشى مع متطلبات مهمتك الخاصة، وتأخذ في الاعتبار الموارد الحسابية المتاحة، وتراعي الحاجة إلى التفسير.
بالإضافة إلى ذلك، تلعب خصائص مجموعة البيانات الخاصة بك – مثل حجمها ومستويات الضوضاء والتعقيد – دورًا حاسمًا، فضلاً عن الخصائص المطلوبة من عدم التغير مثل النطاق والدوران والإضاءة.
استخراج ميزات الصوت
تخيل محاولة تعليم الكمبيوتر فهم الكلام بالطريقة التي يفعلها البشر. هنا تأتي معاملات سيبسترال الترددية الميلانية (MFCC) إلى الصورة.
MFCCs هي ميزات صوتية خاصة تقسم الصوت بطريقة تشبه كيفية معالجة آذاننا له. إنها فعّالة بشكل خاص لأنها تركز على الترددات التي يكون فيها البشر أكثر حساسية. فكر فيها كترجمة الصوت إلى شكل سيجد كل من الكمبيوتر والسمع البشري معنى له.
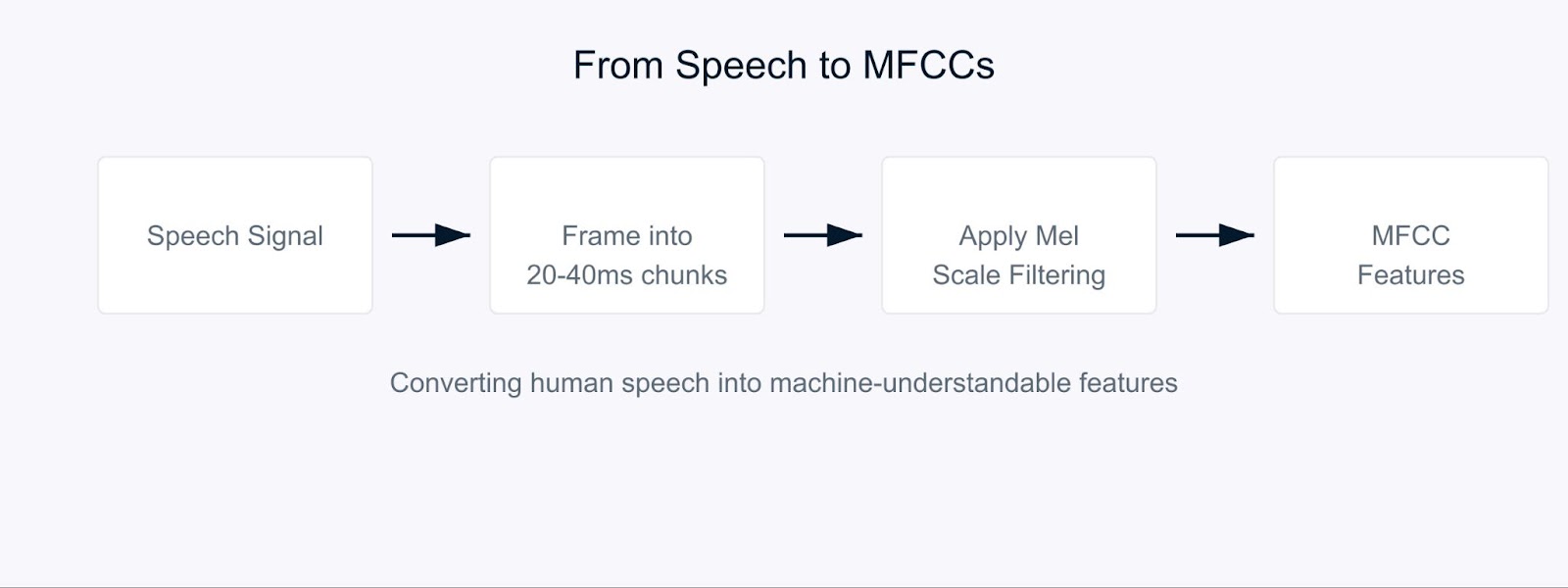
معاملات سيبسترال الترددية الميلانية
يبدأ العملية بتقسيم إشارة الصوت إلى شظايا قصيرة، غالباً ما تكون بطول 20-40 ميللي ثانية. لكل شظية، نقوم بتطبيق سلسلة من التحويلات الرياضية التي تحول الموجات الصوتية الخام إلى مكونات التردد. هنا حيث تصبح الأمور مثيرة. بدلاً من معاملة جميع الترددات على قدم المساواة، نستخدم شيئًا يسمى مقياس ميل.
![]()
قد تبدو هذه الصيغة معقدة، لكنها في الواقع تقوم بتعيين الترددات لمطابقة كيفية تصور البشر للصوت. أذنينا أفضل في اكتشاف الفروق في الترددات المنخفضة أكثر من تلك المرتفعة، ومقياس ميل يأخذ هذا التحيز الطبيعي بعين الاعتبار.
في التعرف على الصوت، تعتبر MFCCs أساس فهم من يتحدث وماذا يقول. عندما تتحدث إلى مساعدك الافتراضي على الهاتف، فمن المحتمل أنه يستخدم MFCCs لمعالجة صوتك. تساعد هذه الضريب في التقاط السمات الفريدة لصوت كل شخص، مما يجعلها لا غنى عنها لأنظمة تحديد الهوية الصوتية.
في تحليل المشاعر في الكلام، تساعد MFCCs في اكتشاف التباينات الدقيقة في الصوت التي تشير إلى العواطف. يمكنها التقاط التغييرات في النبرة واللهجة ومعدل الكلام التي قد تشير ما إذا كان شخص ما سعيدًا، حزينًا، غاضبًا، أو محايدًا. على سبيل المثال، عند تحليل مكالمات خدمة العملاء، يمكن لـ MFCCs المساعدة في تحديد مستويات رضا العملاء استنادًا إلى كيفية تحدثهم، ليس فقط ما يقولونه.
استخراج ميزات السلاسل الزمنية
عند العمل مع سلاسل زمنية، يساعد استخراج الميزات المعنوية في التقاط الأنماط والاتجاهات التي تتطور مع مرور الوقت. دعونا نلقي نظرة على بعض التقنيات الرئيسية المستخدمة لتحويل البيانات الزمنية الخام إلى ميزات مفيدة.

أساليب استخراج ميزات السلاسل الزمنية
تقوم التحويلات الفورية بتحليل بيانات السلاسل الزمنية إلى مكوناتها الترددية، مكشفة الأنماط الدورية المخفية. الصيغة هي:
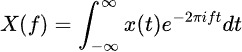
تكمل طرق التحليل الإحصائي التحليل الترددي من خلال التقاط الخصائص الزمنية. تشمل السمات الشائعة المتوسطات المتحركة، والانحرافات المعيارية، ومكونات الاتجاه. تكون هذه التقنيات قوية بشكل خاص في التنبؤ المالي، حيث تساعد في تحديد اتجاهات السوق والشذوذات.
على سبيل المثال، في تحليل سوق الأسهم، يمكن أن يكشف دمج ميزات فورييه مع مقاييس إحصائية كل من الاتجاهات طويلة الأمد والأنماط الدورية. بالمثل، في البيئات الصناعية، تساعد هذه الطرق في اكتشاف الشوائب في المعدات من خلال تحليل أنماط بيانات الاستشعار على مر الزمن.
الأدوات والمكتبات لاستخراج السمات
دعنا نلقي نظرة على بعض الأدوات الأساسية التي تجعل تنفيذ طرق استخراج السمات هذه سهلة وفعالة.
أدوات ومكتبات لاستخراج السمات
بالنسبة لمعالجة الصور، توفر OpenCV وscikit-image أدوات شاملة لتنفيذ مختلف تقنيات استخراج السمات. توفر هذه المكتبات تنفيذات فعالة لتقنيات SIFT وHOG وغيرها من الخوارزميات التي ناقشناها سابقًا. عند العمل مع النهج التعلم العميق، تصبح الأطر البرمجية مثل TensorFlow وPyTorch لا غنى عنها. يمكنك البدء مع دليل OpenCV لمعرفة المزيد.
تُبسط مهام معالجة الصوت باستخدام مكتبات مثل LibROSA، التي تتفوق في استخراج MFCCs وميزات صوتية أخرى. يوسع PyAudioAnalysis هذه القدرات بواجهات عالية المستوى لمهام تحليل الصوت.
بالنسبة لبيانات السلاسل الزمنية، tsfresh وFeaturetools يُتمتعان بقدرة على تلقين عملية استخراج الميزات. يمكن لهذه المكتبات توليد واختيار الميزات ذات الصلة تلقائيًا من البيانات الزمنية الخاصة بك، مما يجعل التركيز على تطوير النماذج أسهل بدلاً من هندسة الميزات.
مثال على استخراج الميزات
لنضع معرفتنا في التطبيق من خلال بعض الأمثلة العملية. سنبدأ باستخراج ميزات الصور، واحدة من أكثر التطبيقات شيوعًا في رؤية الحواسيب.
استخراج ميزات الصور باستخدام OpenCV
أولاً، دعنا نقوم بتوريد المكتبات اللازمة
# قم بتوريد المكتبات المطلوبة import cv2 import numpy as np import matplotlib.pyplot as plt
الآن، دعنا نقوم بتحميل صورة لاستخراج الميزات ذات الصلة. لهذا المثال، سنستخدم صورة لجودزيلا تم تنزيلها من الإنترنت.
# قم بتحميل الصورة image = cv2.imread('godzilla.jpg') # قم بتحويل BGR إلى RGB (OpenCV يحمل بتنسيق BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # عرض الصورة الأصلية plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
الناتج:

قبل تطبيق كشف الحواف، نحتاج إلى معالجة صورتنا. نفعل ذلك على النحو التالي:
# قم بتحويل الصورة إلى درجات الرمادي gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # قم بتطبيق التشويه الغوسي لتقليل الضوضاء blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
أخيرًا، دعنا نطبق خوارزمية كاني لكشف الحواف وتصور النتائج:
# تطبيق كشف حواف Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # عرض النتائج plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
الناتج:

جهاز كشف حواف Canny يساعدنا على تحديد الحدود والميزات الهامة في صورتنا، والتي يمكن استخدامها للتحليل اللاحق أو كإدخال لنماذج التعلم الآلي.
استخراج MFCC من الصوت باستخدام LibROSA
قبل أن نتمكن من بدء معالجة ملفات الصوت، نحتاج إلى تثبيت المكتبات المطلوبة. نظرًا لأن LibROSA ليست مضمنة في مكتبة Python القياسية، سنستخدم pip لتثبيتها:
# تثبيت المكتبات المطلوبة # قم بتشغيل هذه الأوامر في الطرفية الخاصة بك أو في نافذة الأوامر pip install librosa pip install numpy pip install matplotlib
LibROSA هي مكتبة قوية مصممة لتحليل الموسيقى والصوت، لذا دعنا نبدأ بإدخالها بالإضافة إلى المكتبات الأخرى الضرورية:
# استيراد المكتبات المطلوبة import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
تحتوي ملفات الصوت على الكثير من المعلومات بتنسيق موجة. للعمل مع هذه البيانات، نحتاج أولاً إلى تحميلها إلى برنامجنا. تساعدنا LibROSA في القيام بذلك عن طريق تحويل ملف الصوت إلى تنسيق يمكننا تحليله:
# تحميل ملف الصوت # الفترة الزمنية محدودة إلى 10 ثوانٍ لهذا المثال audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # عرض الموجة plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
الناتج:
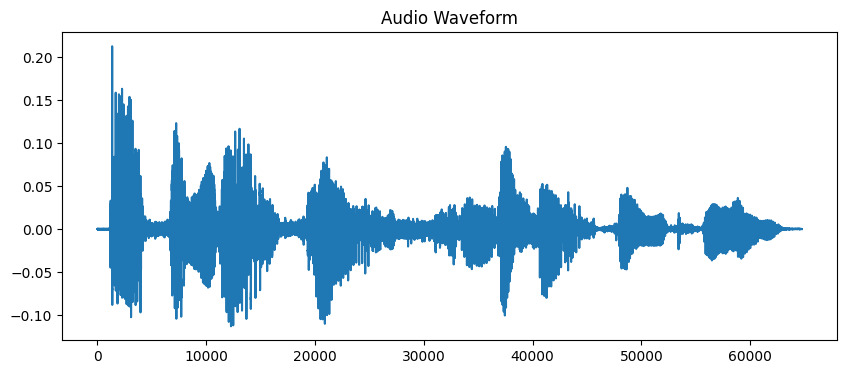
الآن بعد أن قمنا بتحميل الصوت، نحتاج إلى استخراج ميزات معنوية منه. تقوم آذاننا بشكل طبيعي بتقسيم الصوت إلى مكونات ترددية مختلفة، وتقوم MFCC بتقليد هذه العملية. نستخدم وظيفة استخراج الميزات في librosa لحساب هذه الضرائب:
# استخراج ميزات MFCC mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # عرض MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
الناتج:
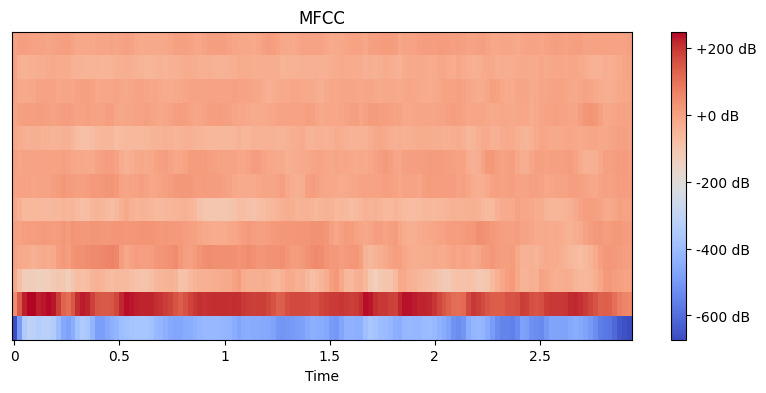
هنا، نقوم بتعيين n_mfcc=13 لأن الـ 13 معامل عادة ما يلتقطان أهم جوانب الصوت التي تساعد في مهام مثل التعرف على الكلام. التصور الناتج يظهر كيفية تغير هذه الميزات مع مرور الوقت، حيث تمثل الألوان الأكثر سطوعًا قيمًا أعلى.
استخراج الميزات من بيانات السلاسل الزمنية باستخدام tsfresh
أولاً، دعنا نقوم بتثبيت المكتبات المطلوبة. سنستخدم yfinance للحصول على البيانات المالية، جنبًا إلى جنب مع tsfresh لاستخراج الميزات:
# تثبيت المكتبات المطلوبة # قم بتشغيل هذه الأوامر في الطرفية أو موجه الأوامر الخاص بك pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
الآن لنقم بإستيراد مكتباتنا واحضار بعض البيانات المالية الحقيقية:
# استيراد المكتبات المطلوبة import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
لنحصل على بعض البيانات الحقيقية لسوق الأسهم. سنستخدم بيانات أسهم شركة آبل كمثال:
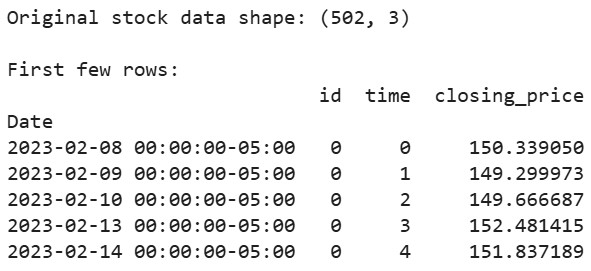
# تنزيل بيانات أسهم آبل للسنتين الماضيتين aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # تحضير البيانات بالشكل الذي يتوقعه tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # كل سلسلة زمنية تحتاج إلى معرف 'time': range(len(df)), 'closing_price': df['Close'] # سنستخدم أسعار الإغلاق }) # عرض الصفوف الأولى من بياناتنا print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
الناتج:
الآن دعنا نستخرج الميزات من بيانات السلاسل الزمنية المالية الخاصة بنا:
# إعداد معلمات استخراج الميزات extraction_settings = MinimalFCParameters() # استخراج الميزات تلقائيًا extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # عرض الميزات المستخرجة print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
الناتج:

هنا، نستخدم MinimalFCParameters() لتحديد الميزات التي نريد استخراجها. وهذا يوفر لنا مجموعة أساسية من الميزات الزمنية المعنوية مثل المتوسط والتباين وسمات الاتجاه، وهي أساسية لفهم الأنماط في بياناتنا.
تحديات في استخراج الميزات
عند العمل في استخراج الميزات، غالبًا ما نواجه تحديات.
غالبًا ما تنشأ المسائل المتعلقة بالأبعاد العالية وقيود الحوسبة عند التعامل مع مجموعات بيانات كبيرة. على سبيل المثال، يمكن أن يستهلك استخراج الميزات من الصور ذات الدقة العالية أو الملفات الصوتية الطويلة ذاكرة كبيرة وقوة معالجة مهمة.
تشكل الإفراط في التعلم بسبب الميزات غير ذات صلة أو زائدة تحديًا شائعًا آخر. عند استخراج الكثير من الميزات، قد يتعلم النماذج الضوضاء بدلاً من الأنماط المعنوية. وهذا يحدث بشكل خاص في معالجة الصور والصوت حيث يمكن إنشاء آلاف الميزات.
للتغلب على هذه التحديات، يُنصح باعتبار الاستراتيجيات التالية:
- استخدام المعرفة المجالية لاختيار الميزات ذات الصلة
- تطبيق طرق اختيار الميزات لتقليل الأبعاد
- تنفيذ تقنيات هندسة الميزات المناسبة بناءً على نوع البيانات الخاص بك
تتطلب هذه التحديات اعتبارًا دقيقًا وتوازنًا بين ثراء الميزات والكفاءة الحسابية.
الاستنتاج
استخراج الميزات مهارة أساسية في تعلم الآلة تحوّل البيانات الخام إلى تمثيلات معنوية. من خلال أمثلتنا العملية باستخدام OpenCV، LibROSA، وtsfresh، رأينا كيفية استخراج الميزات من أنواع مختلفة من البيانات. من خلال فهم هذه التقنيات وتحدياتها، يمكننا بناء نماذج فعّالة لتعلم الآلة.
هل أنت مستعد للمزيد من التفاصيل؟ تحقق من هذه الموارد:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning