













Die Merkmalsextraktion im maschinellen Lernen wandelt Rohdaten in eine Reihe von sinnvollen Merkmalen um, die wesentliche Informationen erfassen und Redundanzen reduzieren. Sie kann Techniken zur Dimensionsreduzierung und Methoden umfassen, die neue Merkmale aus vorhandenen Daten erstellen.
Stellen Sie sich vor, Sie versuchen, Früchte auf einem Markt zu identifizieren. Während Sie unzählige Attribute in Betracht ziehen könnten (Gewicht, Farbe, Textur, Form, Geruch usw.), könnten Sie feststellen, dass nur wenige Schlüsselmerkmale wie Farbe und Größe ausreichen, um Äpfel und Orangen zu unterscheiden. Genau das macht die Merkmalsextraktion. Sie hilft Ihnen, sich auf die informativsten Merkmale Ihrer Daten zu konzentrieren.
Bei der Durchführung der Merkmalsextraktion wird die ursprüngliche Daten mathematisch in einen neuen Satz von Merkmalen transformiert. Diese neuen Merkmale sind darauf ausgelegt, die wichtigsten Aspekte der Daten zu erfassen, während möglicherweise deren Komplexität reduziert wird. Die extrahierten Merkmale repräsentieren oft zugrunde liegende Muster oder Strukturen, die in den ursprünglichen Daten möglicherweise nicht sofort erkennbar sind.
Feature Extraction
In den nächsten Abschnitten werden wir untersuchen, warum die Merkmalsextraktion im maschinellen Lernen so wichtig ist, und verschiedene Methoden zur Extraktion von Merkmalen aus verschiedenen Datentypen sowie den entsprechenden Code betrachten. Wenn Sie einige praktische Beispiele möchten, schauen Sie sich unseren Dimensionalitätsreduktionskurs in Python an, der ein Kapitel zur Merkmalsextraktion hat.
Warum ist die Merkmalsextraktion im maschinellen Lernen wichtig?
Die Merkmalsextraktion spielt eine wichtige Rolle im maschinellen Lernen. Sie kann den Unterschied zwischen einem Modell, das scheitert, und einem, das erfolgreich ist, ausmachen. Schauen wir uns an, warum dies so grundlegend für den Aufbau effektiver maschineller Lernmodelle ist.
Verbesserung der Modellgenauigkeit und -effizienz
Bei der Arbeit mit Rohdaten im maschinellen Lernen haben Modelle oft Schwierigkeiten, zwischen sinnvollen Mustern und Rauschen zu unterscheiden. Die Merkmalsextraktion dient als Datenvorverarbeitungsschritt, der maßgeblich dazu beitragen kann, wie gut Ihre Modelle lernen und abschneiden.
Modellleistung versus Trainingszeit
Zum Beispiel erreicht ein Modell mit Rohdaten eine Genauigkeit von 85%, während das gleiche Modell eine Genauigkeit von 95% erreichen könnte, wenn es auf sorgfältig extrahierten Merkmalen trainiert wird. Diese Verbesserung erfolgt nicht durch Änderung des Modells, sondern durch die Bereitstellung von qualitativ hochwertigeren Eingabedaten, aus denen es lernen kann.
Verwaltung hochdimensionaler Datensätze
Moderne Datensätze kommen oft mit Hunderten oder Tausenden von Merkmalen. Dies bringt mehrere Herausforderungen mit sich, die die Merkmalsextraktion zu bewältigen hilft.
- Der Fluch der Dimensionalität: Wenn die Anzahl der Merkmale zunimmt, wird die Datenmenge im Merkmalsraum zunehmend spärlicher. Dies erschwert es den Modellen, bedeutungsvolle Muster zu finden. Die Merkmalsverarbeitung schafft eine kompaktere Darstellung, die wichtige Beziehungen bewahrt und gleichzeitig die Dimensionalität reduziert.
- Hoher Speicherverbrauch: Hochdimensionale Daten erfordern während der Verarbeitung mehr Speicherplatz und Arbeitsspeicher. Durch die Extraktion nur der relevantesten Merkmale können wir den Speicherbedarf unserer Datensätze erheblich reduzieren, während wir deren Informationswert beibehalten.
- Datenvisualisierung: Es ist unmöglich, Daten mit mehr als drei Dimensionen direkt zu visualisieren. Die Merkmalsextraktion kann die Dimensionalität auf zwei oder drei Merkmale reduzieren, was es ermöglicht, die Datenstruktur visuell darzustellen und zu verstehen.
Die Merkmalsextraktion geht diese Herausforderungen an, indem sie die Dimensionalität reduziert und gleichzeitig wesentliche Informationen bewahrt. Diese Reduktion verwandelt ausufernde, hochdimensionale Daten in eine kompaktere und handhabbare Form, was zu einer verbesserten Modellleistung führt.
Reduzierung der Rechenkomplexität und Vermeidung von Overfitting
Die Merkmalsextraktion bietet zwei entscheidende Vorteile für maschinelles Lernen:
- Geringere Rechenanforderungen
- Weniger Funktionen bedeuten schnellere Schulungszeiten
- Reduzierter Speicherverbrauch während der Modellbereitstellung
- Effizientere Vorhersagegenerierung
- Bessere Verallgemeinerung
- Einfachere Merkmalsräume helfen, Überanpassung vorzubeugen
- Modelle lernen robustere Muster
- Verbesserte Leistung bei neuen, unbekannten Daten
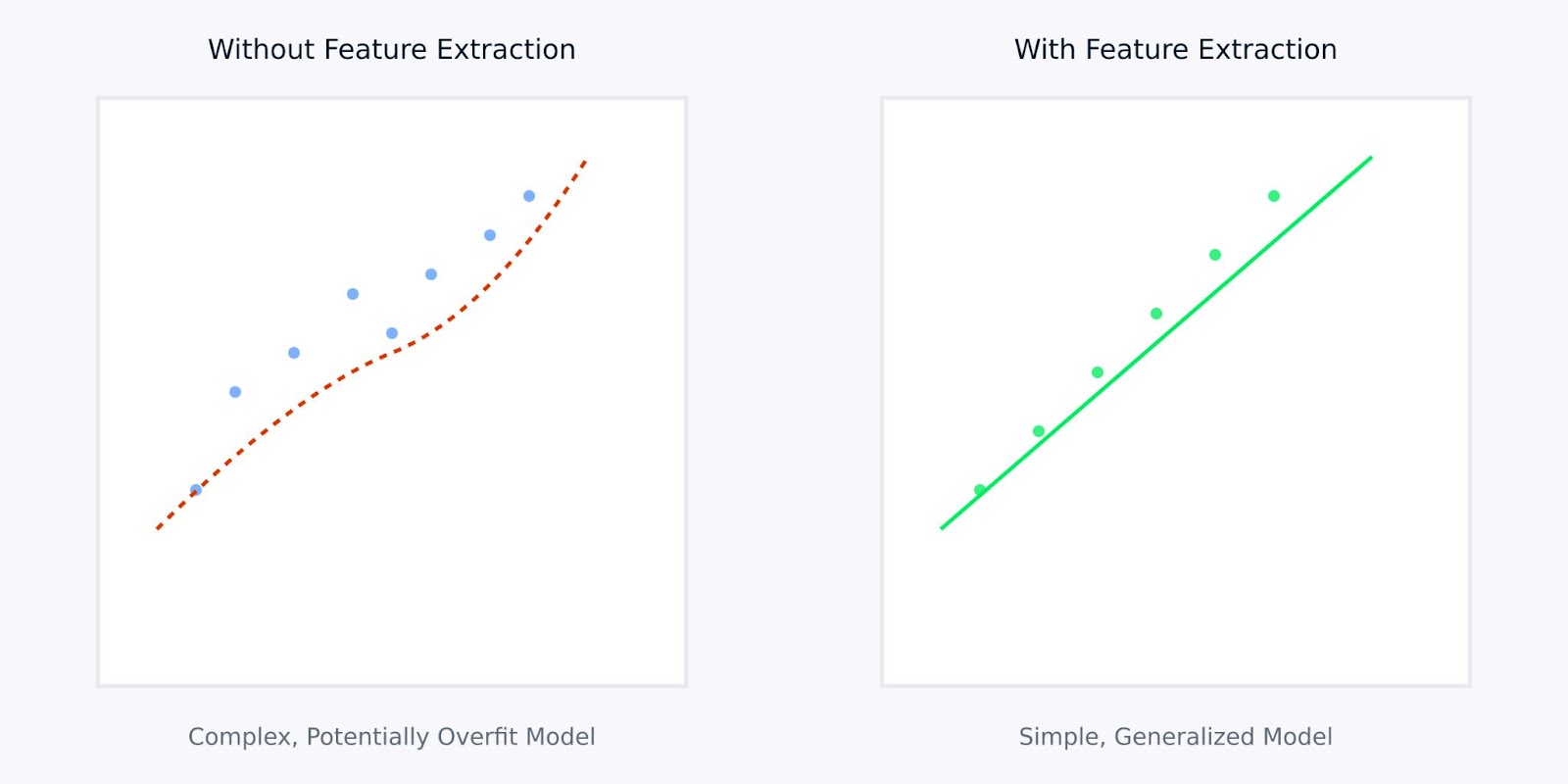
Merkmal-Extraktion versus ohne Merkmal-Extraktion
Die obige Visualisierung zeigt, wie Merkmal-Extraktion zu einfacheren, robusteren Modellen führen kann. Das linke Diagramm zeigt ein komplexes Modell, das versucht, rauschige, hochdimensionale Daten anzupassen, während das rechte Diagramm zeigt, wie Merkmal-Extraktion ein klareres, verallgemeinerbares Muster offenbaren kann.
Mit extrahierten Merkmalen zu arbeiten, anstatt mit Rohdaten, ist wie dem Modell eine klare, destillierte Version der Informationen zu geben, die es lernen muss. Dies macht nicht nur den Lernprozess effizienter, sondern führt auch zu Modellen, die wahrscheinlicher gut in realen Anwendungen abschneiden.
Als Nächstes sehen wir uns verschiedene Methoden der Merkmal-Extraktion an.
Methoden der Merkmal-Extraktion
Merkmalextraktionsmethoden können grob in zwei Hauptansätze kategorisiert werden: manuelle Merkmalsentwicklung und automatisierte Merkmalsextraktion. Lassen Sie uns beide Methoden betrachten, um zu verstehen, wie sie rohe Daten in aussagekräftige Merkmale umwandeln.
Manuelle Merkmalsentwicklung
Die manuelle Merkmalsentwicklung umfasst die Nutzung von Fachexpertise, um relevante Merkmale aus Rohdaten zu identifizieren und zu erstellen. Dieser praktische Ansatz basiert auf unserem Verständnis des Problems und der Daten, um bedeutungsvolle Merkmale zu entwickeln.
Bei der Bildverarbeitung kann die manuelle Merkmalsextraktion Techniken wie die Kantenerkennung zur Identifizierung von Objektgrenzen, Farbhistogramme zur Erfassung der Farbverteilung, Texturanalyse zur Quantifizierung von Mustern und Formdeskriptoren zur Charakterisierung der Objektgeometrie umfassen.
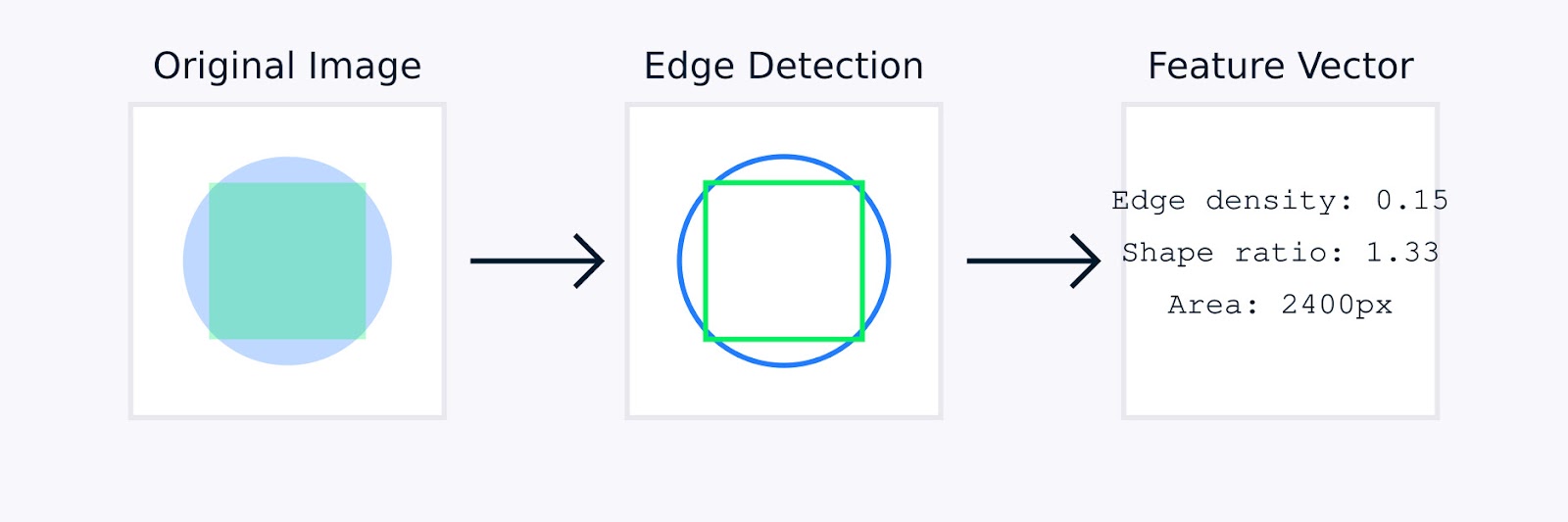
Extraktion von Bildmerkmalen
Bei tabellarischen Daten umfasst die manuelle Merkmalsextraktion das Erstellen von Interaktionstermen zwischen vorhandenen Merkmalen, die Transformation von Variablen mithilfe logarithmischer oder polynomialer Funktionen, die Aggregation von Datenpunkten in aussagekräftige Statistiken und die Kodierung kategorischer Variablen.
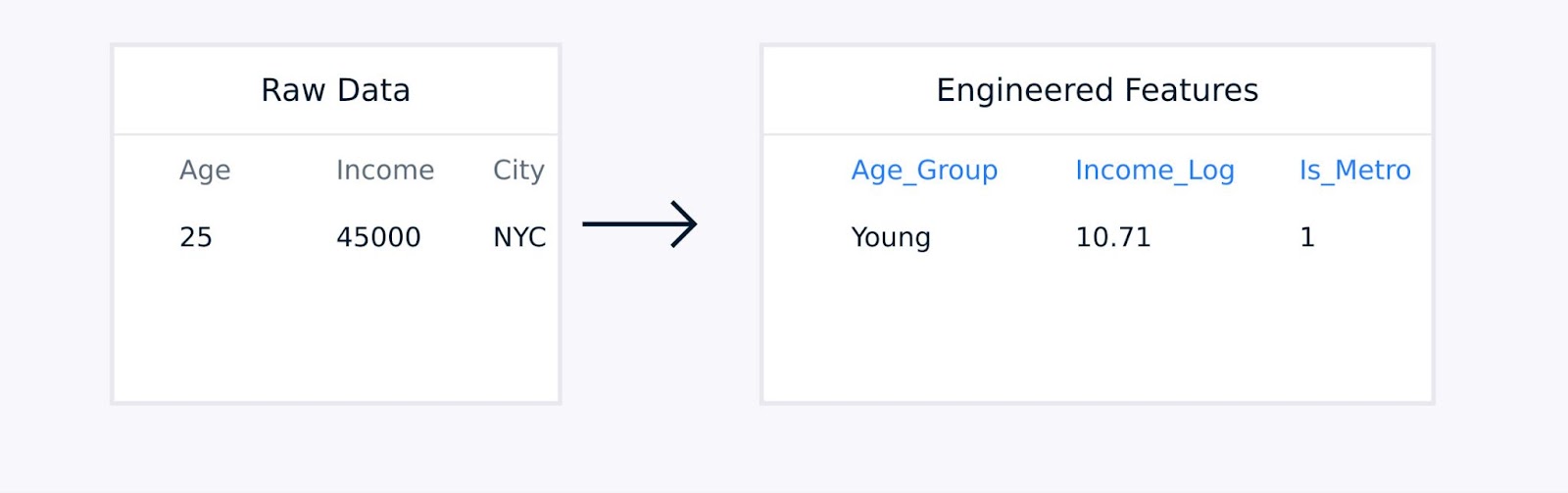
Tabellendaten Merkmalsextraktion
Diese Techniken, die von der Fachkenntnis geleitet werden, verbessern die Qualität der Datenrepräsentation und können die Modellleistung signifikant verbessern.
Automatisierte Merkmalsextraktion
Die automatisierte Merkmalsextraktion verwendet Algorithmen, um Merkmale ohne explizite menschliche Anleitung zu entdecken und zu erstellen. Diese Methoden sind besonders nützlich, wenn es um komplexe Datensätze geht, bei denen manuelle Merkmalskonstruktion unpraktisch oder ineffizient sein könnte.
Gängige automatisierte Ansätze umfassen:
Hauptkomponentenanalyse (PCA): Transformiert Daten in eine Reihe unkorrelierter Komponenten, wobei jede Komponente die maximale verbleibende Varianz erfasst. Dieser Ansatz ist besonders nützlich für Dimensionsreduzierung, da er die wesentlichen Informationen in den Daten bewahrt und gleichzeitig deren Struktur vereinfacht.
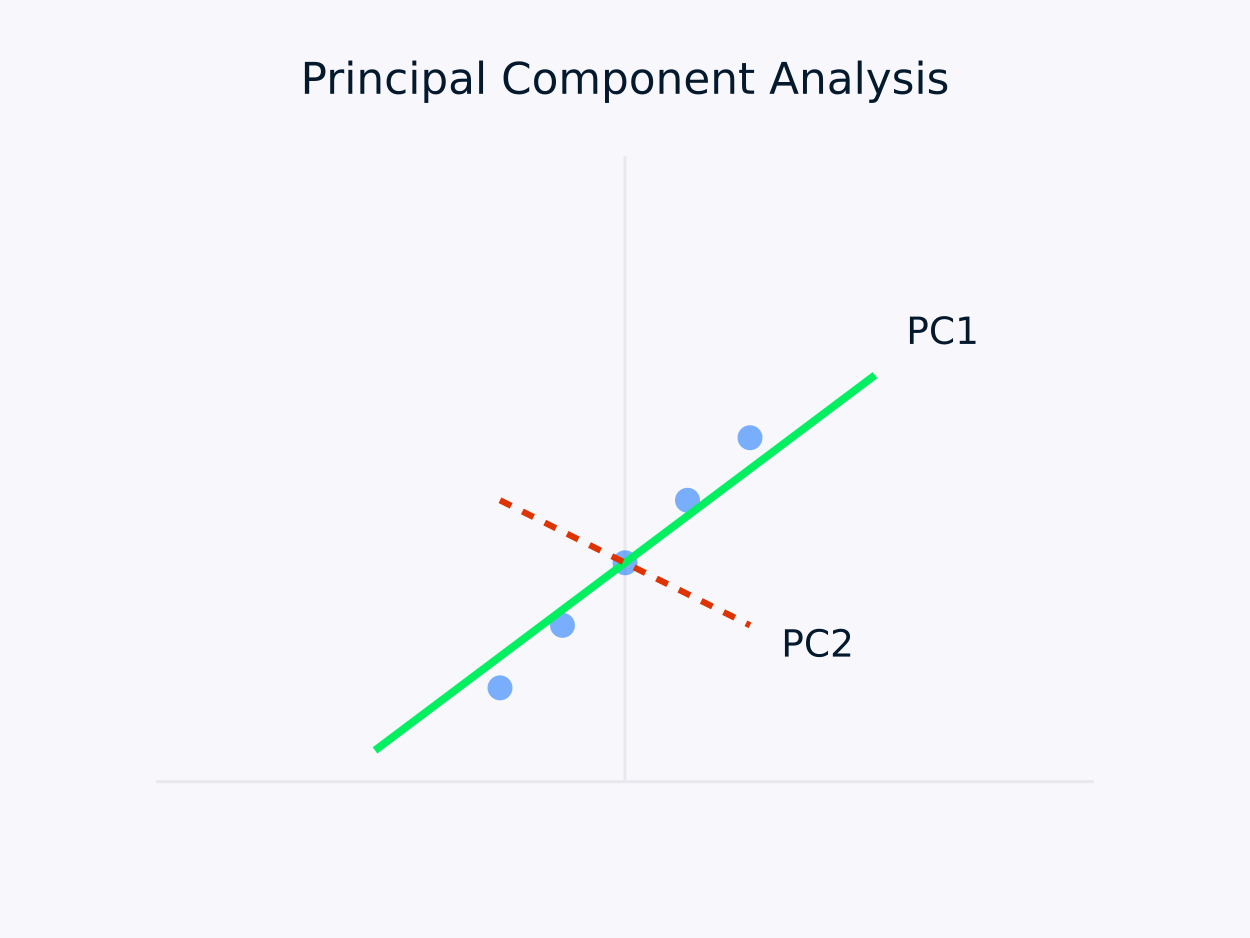
Hauptkomponentenanalyse (PCA)
Autoencoder:Dies sind neuronale Netzwerke, die komprimierte Darstellungen von Daten lernen und nichtlineare Beziehungen erfassen. Sie sind besonders effektiv für hochdimensionale Datensätze, bei denen herkömmliche lineare Methoden möglicherweise nicht ausreichen.
Verschiedene Tools und Bibliotheken wurden entwickelt, um die Feature-Engineering-Aufgaben zu vereinfachen. Zum Beispiel bietet das Zerlegungsmodul von Scikit-learn eine Reihe von Methoden zur Dimensionsreduzierung, und PyCaret bietet automatisierte Funktion zur Merkmalsauswahl.
Sowohl manuelle als auch automatisierte Ansätze haben ihre Stärken. Schauen wir uns die Stärken jedes Ansatzes an.
|
Manuelle Entwicklung |
Automatisierte Extraktion |
|
Integration von Fachwissen |
Skalierbarkeit |
|
Interpretierbare Features |
Behandelt komplexe Muster |
|
Feingranulare Steuerung |
Reduziert menschliche Vorurteile |
|
Maßgeschneidert auf spezifische Bedürfnisse |
Entdeckt versteckte Beziehungen |
Die Wahl zwischen manuellen und automatisierten Methoden hängt oft von Faktoren wie der Komplexität des Datensatzes, der Verfügbarkeit von Fachwissen, den Anforderungen an die Interpretierbarkeit, den Rechenressourcen und den zeitlichen Einschränkungen ab.
Für hochkomplexe Datensätze oder wenn Zeit und Ressourcen begrenzt sind, können automatisierte Methoden schnell nützliche Merkmale generieren. Im Gegensatz dazu können manuelle Methoden vorzuziehen sein, wenn Fachwissen verfügbar ist und Interpretierbarkeit Priorität hat, was eine maßgeschneiderte Merkmalsentwicklung ermöglicht, die eng mit dem vorliegenden Problem übereinstimmt.
In der Praxis kombinieren viele erfolgreiche Projekte im Bereich maschinelles Lernen beide Ansätze, indem sie Fachwissen zur Steuerung der Merkmalsentwicklung nutzen und gleichzeitig automatisierte Methoden verwenden, um zusätzliche Muster zu entdecken, die für menschliche Experten möglicherweise nicht sofort erkennbar sind.
Im nächsten Abschnitt werden wir uns mehrere Techniken zur Merkmalsextraktion in verschiedenen Bereichen ansehen.
Techniken zur Merkmalsextraktion
Jede Art von Daten erfordert spezifische Techniken zur Merkmalsextraktion, die für ihre einzigartigen Eigenschaften optimiert sind. Lassen Sie uns die häufigsten Techniken für verschiedene Datentypen betrachten.

Merkmalextraktionstechniken
Bildmerkmale extrahieren
Die Extraktion von Bildmerkmalen wandelt rohe Pixel-Daten in bedeutungsvolle Darstellungen um, die wesentliche visuelle Informationen erfassen. Es gibt drei Hauptkategorien von Techniken, die in der modernen Computer Vision verwendet werden. Diese sind die traditionellen Methoden, tiefenlernbasierte Methoden und statistische Methoden.

Methoden zur Bildmerkmaleextraktion
Schauen wir uns jede der Methoden an.
Traditionelle Methoden der Computer Vision
Skaleninvariante Merkmaltransformation (SIFT) ist eine robuste Methode, die charakteristische lokale Merkmale in Bildern erkennt. Sie funktioniert, indem sie Schlüsselstellen identifiziert und Deskriptoren generiert, die:
- Invarianz gegenüber Bildskalierung und -rotation
- Teilweise invarianz gegenüber Beleuchtungsänderungen
- Robust gegenüber lokalen geometrischen Verzerrungen
Der SIFT-Algorithmus verarbeitet Bilder in mehreren Phasen. Er beginnt mit der Erkennung von Extrema im Skalenraum, um potenzielle Schlüsselstellen zu identifizieren, die skaleninvariant sind. Anschließend verfeinert die Schlüsselstellenlokalisierung diese Kandidaten, indem sie deren genaue Positionen bestimmt und instabile Punkte verwirft.
Nachfolgend bestimmt die Orientierungszuweisung eine konsistente Ausrichtung für jeden Schlüsselpunkt und gewährleistet Rotationsinvarianz. Schlussendlich erzeugt die Generierung von Schlüsselpunktbeschreibungen eindeutige Deskriptoren auf Basis lokaler Bildgradienten, die ein robustes Matching zwischen Bildern ermöglichen.
Eine weitere Methode ist die Histogramm von Orientierten Gradienten (HOG). Sie erfasst lokale Forminformationen, indem sie Gradientenmuster über ein Bild analysiert. Der Prozess beginnt mit der Berechnung von Gradienten im gesamten Bild, um Kanteninformationen hervorzuheben.
Das Bild wird dann in kleine Zellen unterteilt, und für jede Zelle wird ein Histogramm der Gradientenorientierungen erstellt, um die lokale Struktur zusammenzufassen. Schließlich werden diese Histogramme über größere Blöcke normalisiert, um Robustheit gegen Variationen in Beleuchtung und Kontrast sicherzustellen, was zu einem robusten Merkmalsdeskriptor für Aufgaben wie Objekterkennung und -erkennung führt.
Methoden des Deep Learning
Faltungsneuronale Netzwerke (CNNs) haben verändert, wie wir Merkmalsextraktion durch automatisches Erlernen hierarchischer Repräsentationen durchführen.

Merkmalsextraktion mit CNN
CNNs lernen durch ihre hierarchische Struktur Merkmale. In den frühen Schichten erkennen sie grundlegende visuelle Elemente wie Kanten und Farben. Die mittleren Schichten kombinieren dann diese Elemente, um Muster und Formen zu erkennen, während die tieferen Schichten komplexe Objekte erfassen und Szenenverständnis ermöglichen.
Transferlernen ermöglicht es uns, diese vorgelernten Merkmale aus Modellen, die auf großen Datensätzen trainiert wurden, zu nutzen, was sie besonders wertvoll macht, wenn mit begrenzten Daten gearbeitet wird.
Statistische Methoden
Statistische Methoden extrahieren sowohl globale als auch lokale Muster aus Bildern, was eine robuste Bildanalyse und Interpretation ermöglicht.
Zum Beispiel Farbhistogramme repräsentieren die Verteilung von Farben innerhalb eines Bildes und bieten rotations- und maßstabsinvariante Merkmale, was sie besonders nützlich für Aufgaben wie Bildklassifizierung und -retrieval macht.
Texturanalyse erfasst wiederkehrende Muster und Oberflächenmerkmale mithilfe von Techniken wie Grauwert-Kooccurrence-Matrizen (GLCM), die effektiv für Anwendungen wie Materialerkennung und Szenenklassifizierung sind.
Zusätzlich Kantenerkennung identifiziert Grenzen und signifikante Intensitätsänderungen durch Methoden wie Sobel-, Canny- und Laplace-Operatoren, die eine entscheidende Rolle bei der Objekterkennung und Formanalyse spielen.
Die Wahl der Methode zur Merkmalsextraktion hängt von mehreren Faktoren ab. Sie sollte mit den spezifischen Anforderungen Ihrer Aufgabe übereinstimmen, die verfügbaren Rechenressourcen berücksichtigen und die Notwendigkeit der Interpretierbarkeit berücksichtigen.
Zusätzlich spielen die Eigenschaften Ihres Datensatzes – wie Größe, Geräuschpegel und Komplexität – eine entscheidende Rolle, ebenso wie die erforderlichen Invarianz-Eigenschaften wie Maßstab, Rotation und Beleuchtung.
Audio-Merkmalsextraktion
Stellen Sie sich vor, versuchen einem Computer beizubringen, Sprache so zu verstehen wie Menschen es tun. Hier kommen Mel-Frequency Cepstral Coefficients (MFCC) ins Spiel.
MFCCs sind besondere Audio-Merkmale, die den Klang auf ähnliche Weise wie unsere Ohren verarbeiten. Sie sind besonders effektiv, weil sie sich auf die Frequenzen konzentrieren, auf die Menschen am empfindlichsten reagieren. Denken Sie an sie als Übersetzung von Klang in ein Format, das sowohl für Computer als auch für menschliches Gehör sinnvoll ist.
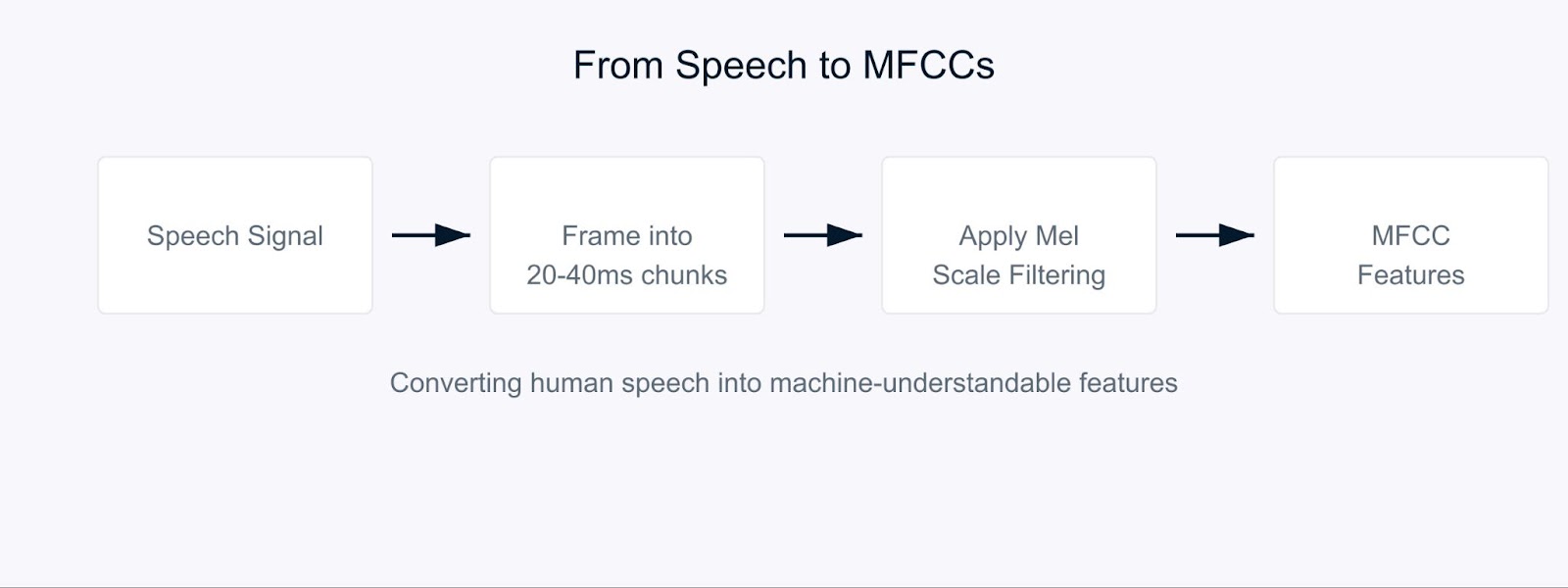
Mel-Frequency Cepstral Coefficients
Der Prozess beginnt damit, das Audiosignal in kurze Abschnitte aufzuteilen, die typischerweise 20-40 Millisekunden lang sind. Für jeden Abschnitt wenden wir eine Reihe mathematischer Transformationen an, die die rohen Schallwellen in Frequenzkomponenten umwandeln. Hier wird es interessant. Anstatt alle Frequenzen gleich zu behandeln, verwenden wir etwas, das als Mel-Skala bezeichnet wird.
![]()
Diese Formel mag komplex erscheinen, aber sie ordnet Frequenzen zu, um zu entsprechen, wie Menschen Geräusche wahrnehmen. Unsere Ohren sind besser darin, Unterschiede bei niedrigeren Frequenzen als bei höheren zu erkennen, und die Mel-Skala berücksichtigt diese natürliche Verzerrung.
In der Spracherkennung dienen MFCCs als Grundlage für das Verständnis, wer spricht und was gesagt wird. Wenn Sie mit dem virtuellen Assistenten Ihres Telefons sprechen, verwendet dieser wahrscheinlich MFCCs, um Ihre Stimme zu verarbeiten. Diese Koeffizienten helfen dabei, die einzigartigen Merkmale der Stimme jeder Person zu erfassen, was sie für Systeme zur Sprecheridentifikation von unschätzbarem Wert macht.
Für die Sentimentanalyse in der Sprache helfen MFCCs, subtile Variationen in der Stimme zu erkennen, die Emotionen anzeigen. Sie können Veränderungen in Tonhöhe, Klangfarbe und Sprechgeschwindigkeit erfassen, die darauf hindeuten könnten, ob jemand glücklich, traurig, wütend oder neutral ist. Zum Beispiel können MFCCs bei der Analyse von Kundenservice-Anrufen helfen, die Kundenzufriedenheit basierend darauf zu identifizieren, wie sie sprechen, nicht nur was sie sagen.
Zeitreihenmerkmale extrahieren
Bei der Arbeit mit Zeitreihen Daten hilft es, aussagekräftige Merkmale zu extrahieren, um Muster und Trends zu erfassen, die sich im Laufe der Zeit entwickeln. Schauen wir uns einige Schlüsseltechniken an, die verwendet werden, um rohe Zeitreihendaten in nützliche Merkmale zu transformieren.

Methoden zur Extraktion von Zeitreihenmerkmalen
Die Fourier-Transformation zerlegt Zeitreihendaten in ihre Frequenzkomponenten und offenbart verborgene periodische Muster. Die Formel lautet:
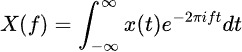
Statistische Methoden ergänzen die Frequenzanalyse durch Erfassung zeitlicher Eigenschaften. Zu den häufig verwendeten Merkmalen gehören gleitende Durchschnitte, Standardabweichungen und Trendkomponenten. Diese Techniken sind besonders leistungsfähig bei der Finanzprognose, wo sie helfen, Marktrends und Anomalien zu identifizieren.
Zum Beispiel können in der Aktienmarktanalyse die Kombination von Fourier-Merkmalen mit statistischen Maßen sowohl langfristige Trends als auch zyklische Muster aufzeigen. Ebenso helfen diese Methoden in industriellen Umgebungen, Auffälligkeiten an Geräten zu erkennen, indem sie Sensordatenmuster im Laufe der Zeit analysieren.
Werkzeuge und Bibliotheken für Merkmalsextraktion
Schauen wir uns einige wesentliche Tools an, die die Umsetzung dieser Merkmalsextraktionsmethoden einfach und effizient machen.
Tools und Bibliotheken für die Merkmalsextraktion
Für die Bildverarbeitung bieten OpenCV und scikit-image umfassende Tools zur Implementierung verschiedener Merkmalsextraktionstechniken. Diese Bibliotheken bieten effiziente Implementierungen von SIFT, HOG und anderen Algorithmen, über die wir zuvor gesprochen haben. Bei der Arbeit mit Deep-Learning-Ansätzen werden Frameworks wie TensorFlow und PyTorch unverzichtbar. Sie können mit unserem OpenCV-Tutorial mehr erfahren.
Audioverarbeitungsaufgaben werden durch Bibliotheken wie LibROSA vereinfacht, die sich hervorragend für die Extraktion von MFCCs und anderen akustischen Merkmalen eignet. PyAudioAnalysis erweitert diese Fähigkeiten mit hochgradigen Schnittstellen für Audioanalyseaufgaben.
Für Zeitreihendaten automatisieren tsfresh und Featuretools den Prozess der Merkmals-Extraktion. Diese Bibliotheken können automatisch relevante Merkmale aus Ihren zeitlichen Daten generieren und auswählen, was es einfacher macht, sich auf die Modellentwicklung statt auf die Merkmalstechnik zu konzentrieren.
Beispiel für die Merkmals-Extraktion
Lasst uns unser Wissen mit einigen praktischen Beispielen anwenden. Wir beginnen mit der Extraktion von Bildmerkmalen, einer der häufigsten Anwendungen in der Computer Vision.
Bildmerkmals-Extraktion mit OpenCV
Zuerst importieren wir die notwendigen Bibliotheken
# Erforderliche Bibliotheken importieren import cv2 import numpy as np import matplotlib.pyplot as plt
Jetzt laden wir ein Bild, um relevante Merkmale zu extrahieren. In diesem Beispiel verwenden wir ein Bild von Godzilla, das aus dem Internet heruntergeladen wurde.
# Bild laden image = cv2.imread('godzilla.jpg') # BGR in RGB umwandeln (OpenCV lädt im BGR-Format) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Originalbild anzeigen plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
Ausgabe:

Vor der Kantenentdeckung müssen wir unser Bild vorverarbeiten. Das machen wir wie folgt:
# Bild in Graustufen umwandeln gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Gaussian Blur anwenden, um Rauschen zu reduzieren blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
Zuletzt wenden wir den Canny-Kantenentdeckungsalgorithmus an und visualisieren die Ergebnisse:
# Wenden Sie die Canny-Kantenerkennung an edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # Zeigen Sie die Ergebnisse an plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
Ausgabe:

Der Canny-Kantendetektor hilft uns, wichtige Grenzen und Merkmale in unserem Bild zu identifizieren, die für weitere Analysen oder als Eingabe für maschinelles Lernen verwendet werden können.
Extrahieren von MFCC aus Audio mit LibROSA
Bevor wir mit der Verarbeitung von Audiodateien beginnen können, müssen wir die erforderlichen Bibliotheken installieren. Da LibROSA nicht in der Standardbibliothek von Python enthalten ist, verwenden wir pip, um es zu installieren:
# Erforderliche Bibliotheken installieren # Führen Sie diese Befehle in Ihrem Terminal oder Eingabeaufforderung aus pip install librosa pip install numpy pip install matplotlib
LibROSA ist eine leistungsstarke Bibliothek, die für Musik- und Audioanalysen entwickelt wurde. Beginnen wir also mit dem Importieren von LibROSA zusammen mit anderen erforderlichen Bibliotheken:
# Import erforderliche Bibliotheken import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
Sounddateien enthalten viele Informationen im Wellenformformat. Um mit diesen Daten zu arbeiten, müssen wir sie zuerst in unser Programm laden. LibROSA hilft uns dabei, die Audiodatei in ein Format umzuwandeln, das wir analysieren können:
# Lade die Audiodatei # Die Dauer ist in diesem Beispiel auf 10 Sekunden begrenzt audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # Zeige die Wellenform an plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
Ausgabe:
Jetzt, da unser Audio geladen ist, müssen wir sinnvolle Merkmale daraus extrahieren. Unsere Ohren zerlegen natürlicherweise den Klang in verschiedene Frequenzkomponenten, und MFCC ahmt diesen Prozess nach. Wir verwenden die Feature-Extraktionsfunktion von librosa, um diese Koeffizienten zu berechnen:
# Extrahiere MFCC-Merkmale mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # Zeige die MFCC an plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Ausgabe:
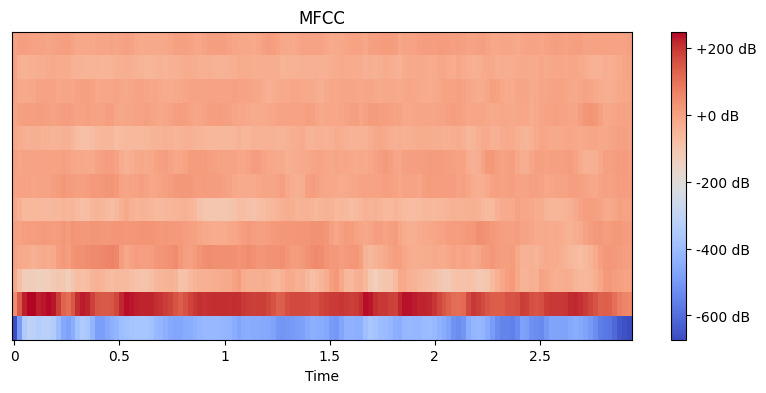
Hier setzen wir n_mfcc=13, weil die ersten 13 Koeffizienten in der Regel die wichtigsten Aspekte des Klangs erfassen, die bei Aufgaben wie der Spracherkennung helfen. Die resultierende Visualisierung zeigt, wie sich diese Merkmale im Laufe der Zeit ändern, wobei hellere Farben höhere Werte repräsentieren.
Merkmalsextraktion aus Zeitreihendaten mit tsfresh
Zuerst installieren wir die erforderlichen Bibliotheken. Wir werden yfinance zur Beschaffung von Finanzdaten verwenden, zusammen mit tsfresh für die Merkmalsextraktion:
# Erforderliche Bibliotheken installieren # Führen Sie diese Befehle in Ihrem Terminal oder Ihrer Eingabeaufforderung aus pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
Importieren wir nun unsere Bibliotheken und holen einige echte Finanzdaten ab:
# Import erforderliche Bibliotheken import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
Lassen Sie uns einige echte Börsendaten erhalten. Wir verwenden die Aktiendaten von Apple als Beispiel:
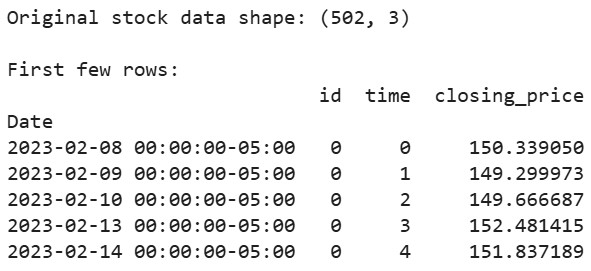
# Laden Sie die Aktiendaten von Apple der letzten 2 Jahre herunter aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # Bereiten Sie die Daten im Format vor, das von tsfresh erwartet wird df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # Jede Zeitreihe benötigt eine ID 'time': range(len(df)), 'closing_price': df['Close'] # Wir verwenden Schlusskurse }) # Zeigen Sie die ersten Zeilen unserer Daten an print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
Ausgabe:
Extrahieren wir jetzt Merkmale aus unseren Finanzzeitreihendaten:
# Legen Sie die Parameter für die Merkmalsextraktion fest extraction_settings = MinimalFCParameters() # Extrahieren Sie automatisch Merkmale extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # Zeigen Sie die extrahierten Merkmale an print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
Ausgabe:

Hier verwenden wir MinimalFCParameters(), um anzugeben, welche Merkmale extrahiert werden sollen. Dies gibt uns ein grundlegendes Set von bedeutenden Zeitreihenmerkmalen wie Mittelwert, Varianz und Trendmerkmale, die entscheidend sind, um Muster in unseren Daten zu verstehen.
Herausforderungen bei der Merkmalsextraktion
Bei der Merkmalsextraktion stoßen wir oft auf Herausforderungen.
Hohe Dimensionalität und rechnerische Einschränkungen treten häufig auf, wenn man mit großen Datensätzen arbeitet. Zum Beispiel kann das Extrahieren von Merkmalen aus hochauflösenden Bildern oder langen Audiodateien erheblichen Speicher- und Rechenaufwand erfordern.
Overfitting aufgrund irrelevanter oder redundanter Merkmale ist eine weitere häufige Herausforderung. Wenn zu viele Merkmale extrahiert werden, könnten Modelle anstelle von sinnvollen Mustern Rauschen lernen. Dies tritt besonders häufig bei der Bild- und Audioverarbeitung auf, wo Tausende von Merkmalen generiert werden können.
Um diese Herausforderungen zu überwinden, sollten Sie diese Strategien in Betracht ziehen:
- Verwenden Sie Fachwissen, um relevante Merkmale auszuwählen
- Wenden Sie Methoden zur Merkmalsauswahl an, um die Dimensionalität zu reduzieren
- Implementieren Sie geeignete Techniken zur Merkmalsextraktion basierend auf Ihrem Datentyp
Diese Herausforderungen erfordern eine sorgfältige Abwägung zwischen Funktionsvielfalt und rechnerischer Effizienz.
Schlussfolgerung
Die Merkmalsextraktion ist eine grundlegende Fähigkeit im maschinellen Lernen, die Rohdaten in bedeutungsvolle Darstellungen umwandelt. Anhand unserer praktischen Beispiele mit OpenCV, LibROSA und tsfresh haben wir gesehen, wie man Merkmale aus verschiedenen Datentypen extrahiert. Durch das Verständnis dieser Techniken und ihrer Herausforderungen können wir effektive Modelle des maschinellen Lernens erstellen.
Bereit, tiefer in das Thema einzutauchen? Schauen Sie sich diese Ressourcen an:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning