













Извлечение признаков в машинном обучении преобразует сырые данные в набор значимых характеристик, захватывая важную информацию и уменьшая избыточность. Это может включать методы уменьшения размерности и методы, которые создают новые признаки из существующих данных.
Представьте, что вы пытаетесь определить фрукты на рынке. Хотя вы могли бы учитывать множество атрибутов (вес, цвет, текстура, форма, запах и т.д.), вы можете осознать, что всего несколько ключевых признаков, таких как цвет и размер, достаточно, чтобы различить яблоки и апельсины. Именно это и делает извлечение признаков. Оно помогает сосредоточиться на самых информативных характеристиках ваших данных.
При выполнении извлечения признаков оригинальные данные математически преобразуются в новый набор признаков. Эти новые признаки разработаны, чтобы захватить самые важные аспекты данных, потенциально уменьшая их сложность. Извлеченные признаки часто представляют собой скрытые закономерности или структуры, которые могут быть не сразу очевидны в оригинальных данных.
Извлечение признаков
В следующих разделах мы рассмотрим, почему извлечение признаков настолько важно в машинном обучении и изучим различные методы извлечения признаков из различных типов данных вместе с их кодом. Если вы хотите примеры практических упражнений, загляните в наш курс по снижению размерности в Python, в котором есть глава, посвященная извлечению признаков.
Почему извлечение признаков важно в машинном обучении?
Извлечение признаков играет важную роль в машинном обучении. Оно может стать решающим фактором между моделью, которая терпит неудачу, и той, которая добивается успеха. Давайте рассмотрим, почему это так важно для создания эффективных моделей машинного обучения.
Повышение точности и эффективности модели
При работе с сырыми данными, машинное обучение часто сталкивается с трудностями в различении значимых паттернов и шума. Извлечение признаков служит этапом предварительной обработки данных, который может значительно улучшить то, как ваши модели обучаются и работают.
Производительность модели против времени обучения
Например, когда модель достигает точности 85% сырых данных, эта же модель может достичь точности 95%, когда обучена на тщательно извлеченных признаках. Улучшение происходит не за счет изменения модели, а за счет предоставления ей качественных входных данных, на которых она может учиться.
Управление высокоразмерными наборами данных
Современные наборы данных часто содержат сотни или тысячи признаков. Это создает несколько проблем, которые помогает решить извлечение признаков.
- Проклятие размерности: С увеличением числа признаков данные становятся все более разреженными в пространстве признаков. Это затрудняет моделям нахождение значимых паттернов. Извлечение признаков создает более компактное представление, которое сохраняет важные взаимосвязи, уменьшая при этом размерность.
- Высокое использование памяти: Данные высокой размерности требуют больше места для хранения и памяти во время обработки. Извлекая только самые релевантные признаки, мы можем значительно сократить объем памяти, занимаемый нашими наборами данных, сохраняя их информативную ценность.
- Визуализация данных: Невозможно непосредственно визуализировать данные с более чем тремя измерениями. Извлечение признаков может снизить размерность до двух или трех признаков, что позволяет построить и понять структуру данных визуально.
Извлечение признаков решает эти проблемы путем снижения размерности, сохраняя при этом важную информацию. Это сокращение преобразует обширные данные высокой размерности в более компактную и управляемую форму, что приводит к улучшению производительности модели.
Снижение вычислительной сложности и предотвращение переобучения
Извлечение признаков обеспечивает два важных преимущества для моделей машинного обучения:
- Меньшие вычислительные требования
- Меньше функций означает более быстрые времена обучения
- Снижение использования памяти во время развертывания модели
- Более эффективная генерация прогнозов
- Лучшая обобщенность
- Пространства более простых функций помогают предотвратить переобучение
- Модели учатся более устойчивым шаблонам
- Улучшение производительности на новых, неизвестных данных
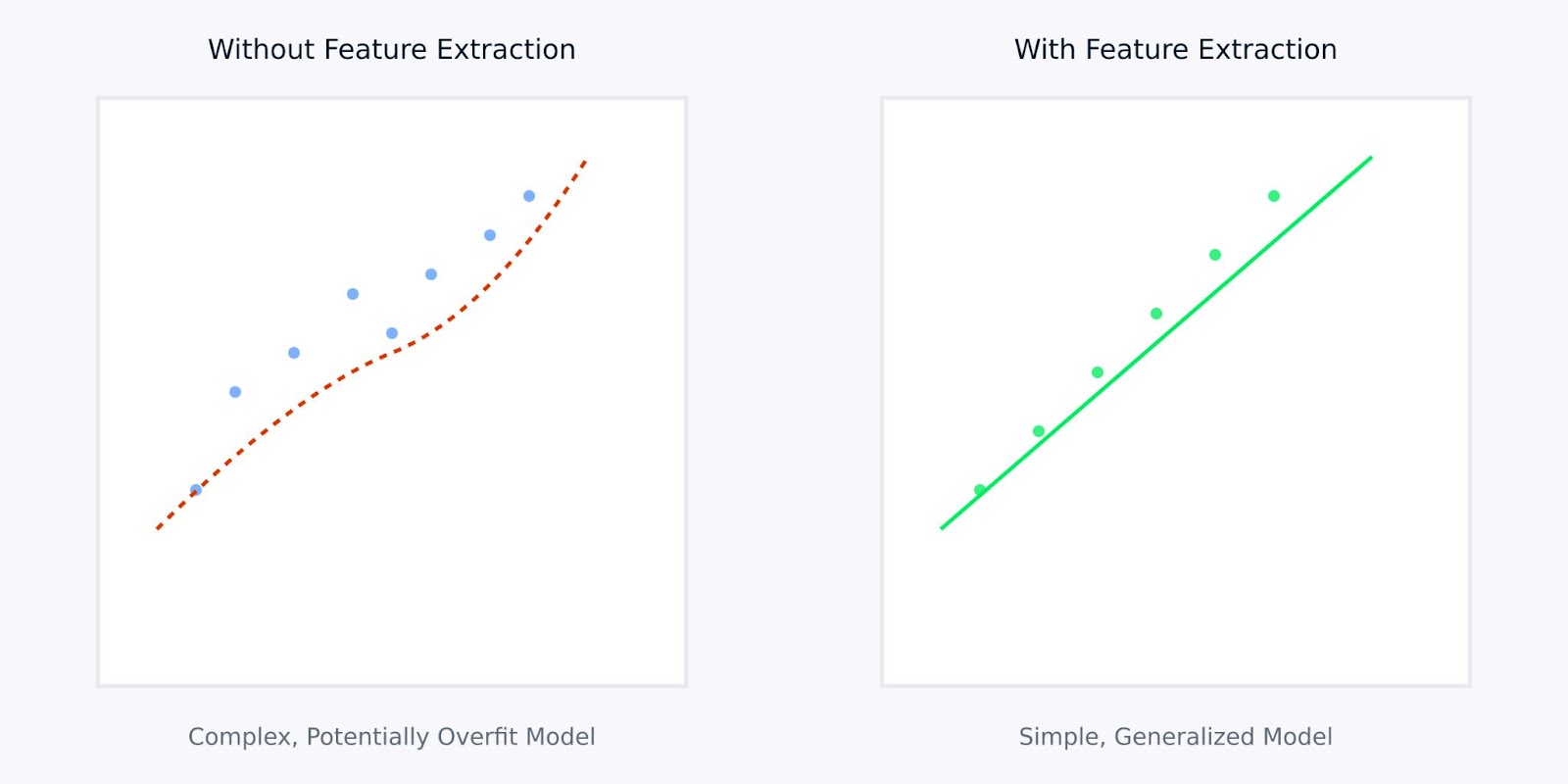
Извлечение признаков по сравнению с работой без извлечения признаков
Визуализация выше иллюстрирует, как извлечение признаков может привести к более простым, более надежным моделям. Левый график показывает сложную модель, пытающуюся подогнать шумные данные высокой размерности, в то время как правый график демонстрирует, как извлечение признаков может раскрывать более ясный, более обобщенный образец.
Работа с извлеченными признаками вместо исходных данных похожа на то, как если бы вы дали вашей модели четкую, упрощенную версию информации, которую ей нужно усвоить. Это не только делает процесс обучения более эффективным, но также приводит к моделям, которые более вероятно будут хорошо себя вести в реальных приложениях.
Далее давайте рассмотрим различные методы извлечения признаков.
Методы извлечения признаков
Методы извлечения признаков можно broadly разделить на два основных подхода: ручная инженерия признаков и автоматизированное извлечение признаков. Давайте рассмотрим оба этих метода, чтобы понять, как они помогают преобразовать сырые данные в значимые признаки.
Ручная инженерия признаков
Ручная инженерия признаков включает в себя использование экспертных знаний для идентификации и создания соответствующих признаков из сырых данных. Этот практический подход основывается на нашем понимании проблемы и данных для разработки значимых признаков.
В обработке изображений, ручная инженерия функций может включать такие техники, как выявление краев для определения границ объектов, цветовые гистограммы для захвата распределения цветов, анализ текстуры для количественной оценки узоров и дескрипторы формы для характеристики геометрии объекта.
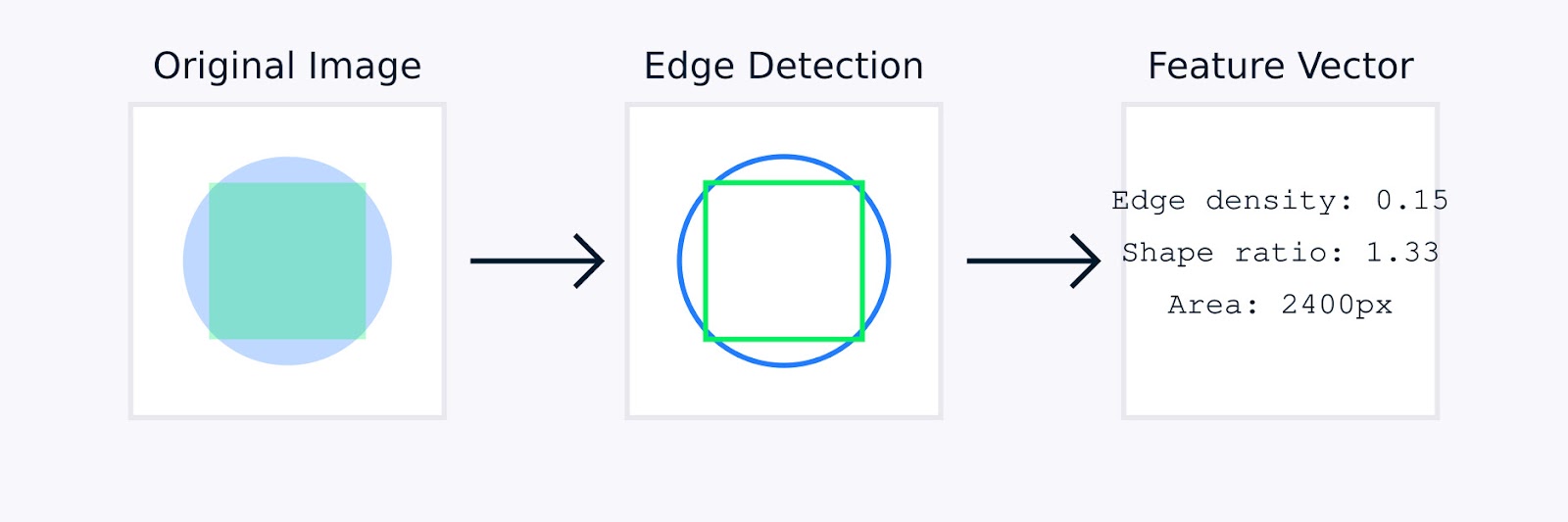
Извлечение признаков изображения
Для табличных данных ручная инженерия функций включает создание взаимодействующих терминов между существующими признаками, преобразование переменных с использованием логарифмических или полиномиальных функций, агрегирование точек данных в содержательные статистические показатели и кодирование категориальных переменных.
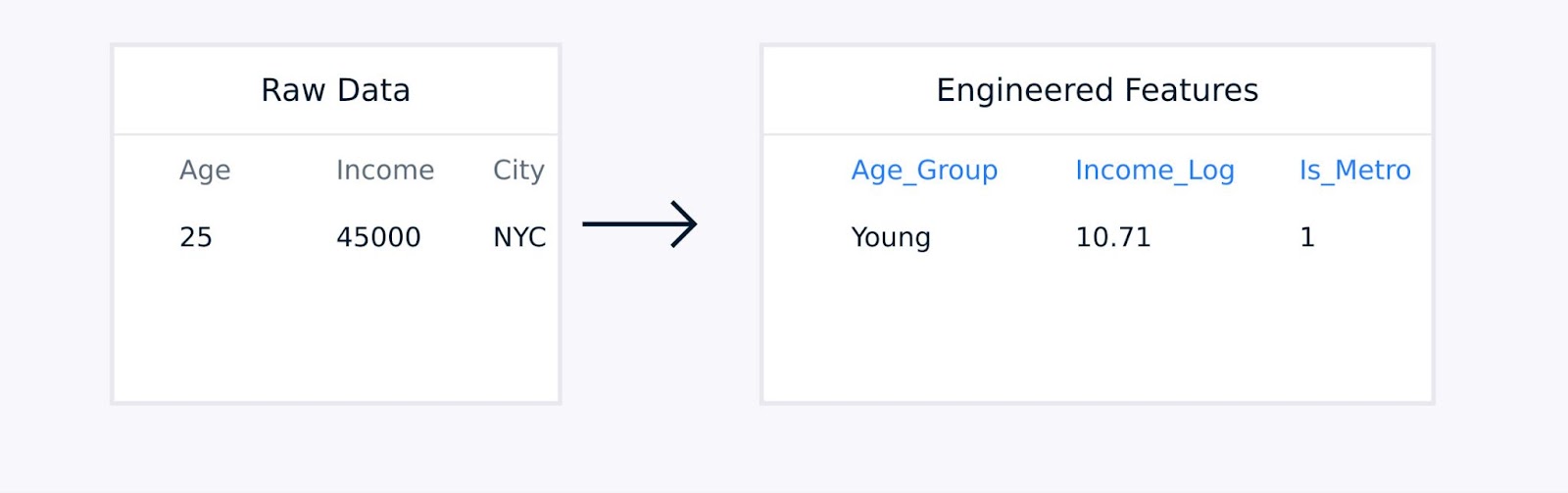
Извлечение признаков из табличных данных
Эти техники, руководствуемые экспертизой в предметной области, улучшают качество представления данных и могут значительно улучшить производительность модели.
Автоматизированное извлечение признаков
Автоматизированное извлечение признаков использует алгоритмы для обнаружения и создания признаков без явного человеческого руководства. Эти методы особенно полезны при работе с комплексными наборами данных, где ручная инженерия признаков может быть неэффективной или невозможной.
Общие автоматизированные подходы включают:
Метод главных компонент (PCA): Преобразует данные в набор некоррелированных компонентов, при этом каждая компонента захватывает максимально оставшуюся дисперсию. Этот подход особенно полезен для снижения размерности, поскольку он сохраняет основную информацию в данных, упрощая их структуру.
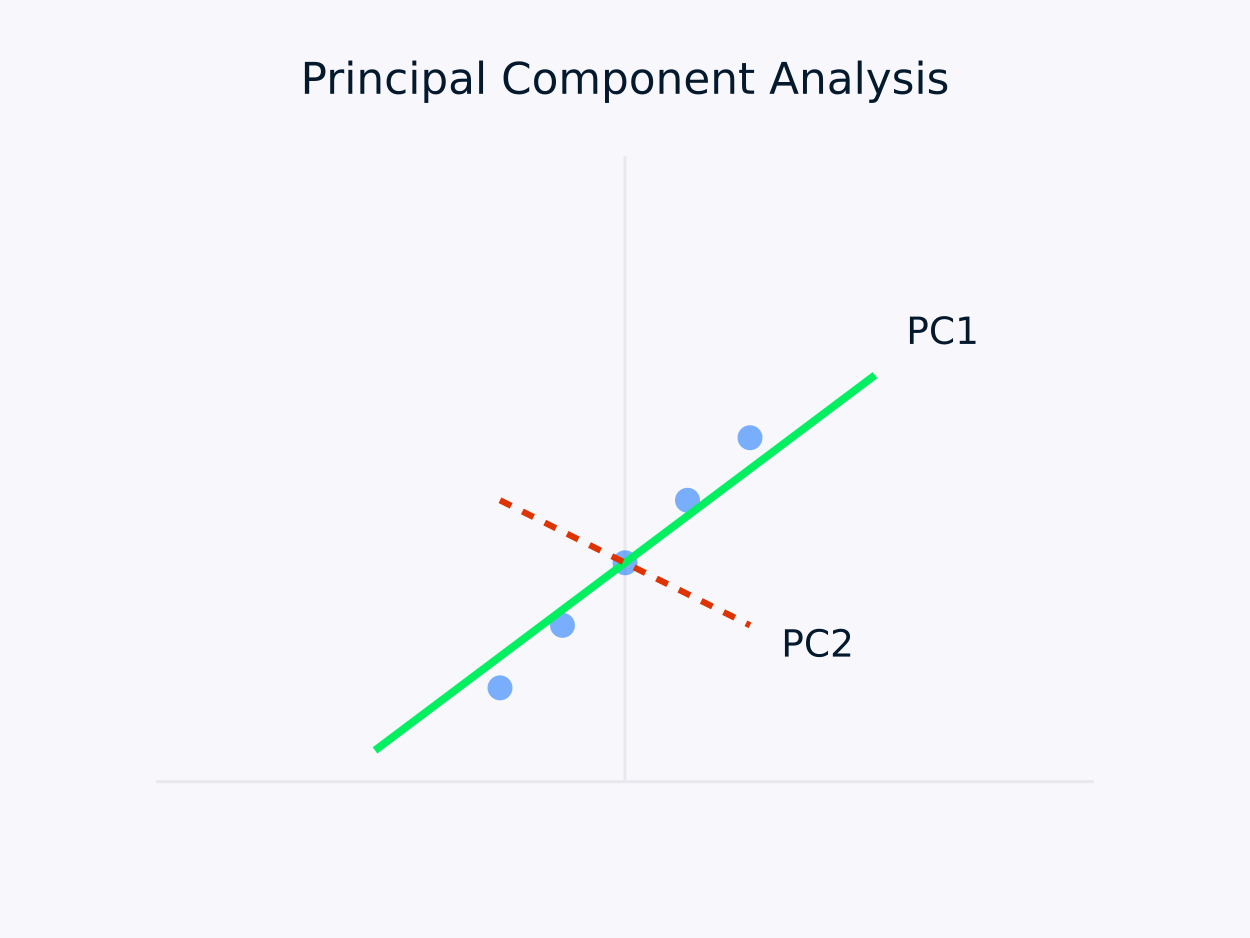
Метод главных компонент (PCA)
Автокодировщики: Это нейронные сети, которые изучают сжатые представления данных, захватывая нелинейные отношения. Они особенно эффективны для высокоразмерных наборов данных, где традиционные линейные методы могут оказаться недостаточными.
Появились различные инструменты и библиотеки, упрощающие задачи по инженерии признаков. Например, модуль декомпозиции Scikit-learn предлагает ряд методов для снижения размерности, а PyCaret обеспечивает возможности автоматического выбора признаков.
У обоих подходов, как ручного, так и автоматизированного, есть свои преимущества. Давайте рассмотрим преимущества каждого подхода.
|
Ручная инженерия |
Автоматизированное извлечение |
|
Интеграция знаний области |
Масштабируемость |
|
Интерпретируемые функции |
Обрабатывает сложные шаблоны |
|
Тонкое управление |
Снижает человеческий предвзятость |
|
Настроен под конкретные потребности |
Находит скрытые отношения |
Выбор между ручными и автоматизированными методами часто зависит от факторов, таких как сложность набора данных, наличие экспертизы в области, требования к интерпретируемости, вычислительные ресурсы и временные ограничения.
Для высоко сложных наборов данных или когда время и ресурсы ограничены, автоматизированные методы могут быстро генерировать полезные признаки. В то же время ручные методы могут быть предпочтительными, если имеется предметная экспертиза и приоритетом является интерпретируемость, что позволяет настраивать процесс создания признаков так, чтобы он тесно соответствовал решаемой проблеме.
На практике многие успешные проекты машинного обучения комбинируют оба подхода, используя предметную экспертизу для направления создания признаков и при этом воспользовавшись автоматизированными методами для обнаружения дополнительных паттернов, которые могли бы быть неочевидны для человеческих экспертов.
В следующем разделе мы рассмотрим несколько методов извлечения признаков в различных областях.
Методы Извлечения Признаков
Каждый тип данных требует специфических методов извлечения признаков, оптимизированных под его уникальные характеристики. Давайте рассмотрим наиболее распространенные методы для различных типов данных.

Методы извлечения признаков
Извлечение признаков изображения
Извлечение признаков изображения преобразует необработанные пиксельные данные в осмысленные представления, которые улавливают основную визуальную информацию. Существуют три основные категории техник, используемых в современном компьютерном зрении. Это традиционные методы, методы, основанные на глубоком обучении, и статистические методы.

Методы извлечения признаков изображения
Давайте рассмотрим каждый из методов.
Традиционные методы компьютерного зрения
Инвариантное преобразование признаков по шкале (SIFT) — это надежный метод, который обнаруживает отличительные локальные признаки на изображениях. Он работает, идентифицируя ключевые точки и генерируя дескрипторы, которые:
- Инвариантны к масштабированию и вращению изображения
- Частично инвариантны к изменениям освещения
- Устойчивы к локальным геометрическим искажениям
Алгоритм SIFT обрабатывает изображения через несколько этапов. Он начинается с обнаружения экстремумов в пространстве масштабов для выявления потенциальных ключевых точек, которые инвариантны к масштабу. Затем локализация ключевых точек уточняет этих кандидатов, определяя их точные местоположения и отбрасывая нестабильные точки.
После этого назначение ориентации определяет согласованную ориентацию для каждой ключевой точки, обеспечивая инвариантность вращения. Наконец, генерация дескрипторов ключевых точек создает отличительные дескрипторы на основе локальных градиентов изображения, облегчая надежное сопоставление между изображениями.
Другой метод – это Гистограмма ориентированных градиентов (HOG). Он захватывает информацию о локальной форме, анализируя градиентные паттерны по всему изображению. Процесс начинается с вычисления градиентов по всему изображению, чтобы выделить детали краев.
Изображение затем делится на маленькие ячейки, и для каждой ячейки создается гистограмма направлений градиентов, чтобы обобщить локальную структуру. В конце эти гистограммы нормализуются по более крупным блокам, чтобы обеспечить устойчивость к изменениям в освещении и контрасте, что приводит к созданию надежного дескриптора признаков для задач, таких как обнаружение и распознавание объектов.
Методы глубокого обучения
Сверточные нейронные сети (CNN) изменили подход к извлечению признаков, автоматически обучаясь иерархическим представлениям.

Извлечение признаков с помощью CNN
Сети CNN изучают признаки через свою иерархическую структуру. На ранних слоях они обнаруживают основные визуальные элементы, такие как края и цвета. Средние слои затем объединяют эти элементы для распознавания узоров и форм, в то время как более глубокие слои захватывают сложные объекты и обеспечивают понимание сцены.
Передача обучения позволяет нам использовать эти заранее изученные признаки из моделей, обученных на больших наборах данных, что делает их особенно ценными при работе с ограниченными данными.
Статистические методы
Статистические методы извлекают как глобальные, так и локальные паттерны из изображений, что способствует надежному анализу и интерпретации изображений.
Например, цветовые гистограммы представляют распределение цветов в изображении и обеспечивают инвариантные к вращению и масштабу признаки, что делает их особенно полезными для задач, таких как классификация и поиск изображений.
Анализ текстуры захватывает повторяющиеся паттерны и характеристики поверхности с использованием таких техник, как матрицы совместного распределения серого уровня (GLCM), которые эффективны для приложений, включая распознавание материалов и классификацию сцен.
Кроме того, выделение краев определяет границы и значительные изменения интенсивности с помощью методов, таких как операторы Собеля, Канни и Лапласа, играя ключевую роль в обнаружении объектов и анализе формы.
Выбор метода извлечения признаков зависит от нескольких факторов. Он должен соответствовать конкретным требованиям вашей задачи, учитывать доступные вычислительные ресурсы и учитывать необходимость интерпретируемости.
Кроме того, характеристики вашего набора данных — такие как его размер, уровни шума и сложность — играют ключевую роль, а также требуемые свойства инвариантности, такие как масштаб, вращение и освещение.
Извлечение аудио-признаков
Представьте себе попытку научить компьютер понимать речь так же, как это делают люди. Вот где на помощь приходят коэффициенты мел-частотных кепстральных коэффициентов (MFCC).
MFCC – это специальные аудиофункции, которые разбивают звук таким образом, как это делают наши уши. Они особенно эффективны, потому что сосредотачиваются на частотах, на которые чувствительны люди. Можно представить себе, что они переводят звук в формат, который был бы значим как для компьютеров, так и для человеческого слуха.
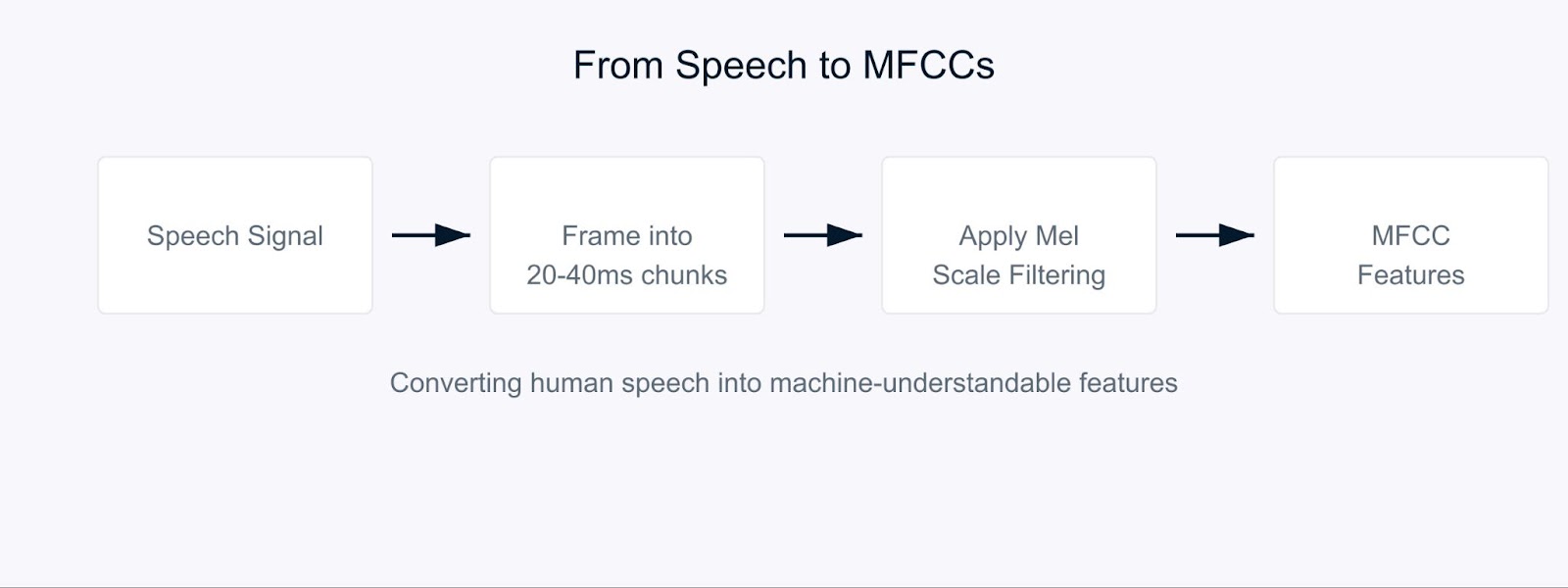
Коэффициенты мел-частотных кепстральных коэффициентов
Процесс начинается с разбиения аудиосигнала на короткие фрагменты, обычно длиной 20-40 миллисекунд. Для каждого фрагмента мы применяем серию математических преобразований, которые преобразуют сырые звуковые волны в частотные компоненты. Здесь происходит интересное. Вместо того чтобы обрабатывать все частоты одинаково, мы используем так называемую мел-шкалу.
![]()
Эта формула может выглядеть сложной, но она просто сопоставляет частоты так, чтобы соответствовать тому, как люди воспринимают звук. Наши уши лучше всего различают разницу в низких частотах, чем в высоких, и шкала Мела учитывает этот естественный эффект.
В распознавании речи МФХ призваны служить основой для понимания, кто говорит, и что он говорит. Когда вы общаетесь с виртуальным ассистентом на своем телефоне, скорее всего, он использует МФХ для обработки вашего голоса. Эти коэффициенты помогают уловить уникальные характеристики голоса каждого человека, что делает их бесценными для систем идентификации дикторов.
Для анализа тональности в речи МФХ помогают обнаруживать тонкие изменения в голосе, указывающие на эмоции. Они могут улавливать изменения высоты, тембра и скорости речи, которые могут указывать на то, счастлив ли кто-то, грустен, злой или нейтрален. Например, при анализе звонков в службу поддержки МФХ могут помочь определить уровень удовлетворенности клиента на основе того, как он говорит, а не только по тому, что он говорит.
Извлечение признаков из временных рядов
При работе с временными рядами данные, извлечение значимых признаков помогает нам захватывать паттерны и тренды, которые развиваются со временем. Давайте рассмотрим некоторые ключевые техники, используемые для преобразования сырых данных временных рядов в полезные признаки.

Методы извлечения признаков временных рядов
Преобразование Фурье разлагает данные временных рядов на их частотные компоненты, выявляя скрытые периодические паттерны. Формула выглядит так:
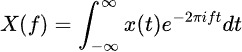
Статистические методы дополняют частотный анализ, фиксируя временные характеристики. Общими чертами являются скользящие средние, стандартные отклонения и трендовые компоненты. Эти техники особенно эффективны в финансовом прогнозировании, где они помогают выявлять рыночные тренды и аномалии.
Например, в анализе фондового рынка сочетание признаков Фурье со статистическими мерами может выявить как долгосрочные тренды, так и циклические паттерны. Аналогично, в промышленной среде эти методы помогают обнаруживать аномалии в работе оборудования, анализируя паттерны данных с датчиков во времени.
Инструменты и библиотеки для извлечения признаков
Давайте рассмотрим несколько важных инструментов, которые облегчают и ускоряют реализацию этих методов извлечения признаков.
Инструменты и библиотеки для извлечения признаков
Для обработки изображений OpenCV и scikit-image предоставляют комплексные инструменты для реализации различных техник извлечения признаков. Эти библиотеки предлагают эффективные реализации SIFT, HOG и других алгоритмов, о которых мы говорили ранее. При работе с подходами глубокого обучения фреймворки, такие как TensorFlow и PyTorch, становятся бесценными. Вы можете начать с нашего учебного пособия по OpenCV, чтобы узнать больше.
Задачи обработки аудио упрощаются с помощью библиотек, таких как LibROSA, которая отлично справляется с извлечением MFCC и других акустических характеристик. PyAudioAnalysis расширяет эти возможности с помощью высокоуровневых интерфейсов для задач анализа аудио.
Для данных временных рядов tsfresh и Featuretools автоматизируют процесс извлечения признаков. Эти библиотеки могут автоматически генерировать и выбирать релевантные признаки из ваших временных данных, что упрощает сосредоточение на разработке модели, а не на инженерии признаков.
Пример извлечения признаков
Давайте применим наши знания на практике с помощью нескольких практических примеров. Начнем с извлечения признаков изображений, одного из самых распространенных приложений в компьютерном зрении.
Извлечение признаков изображений с использованием OpenCV
Сначала давайте импортируем необходимые библиотеки
# Импорт необходимых библиотек import cv2 import numpy as np import matplotlib.pyplot as plt
Теперь давайте загрузим изображение, чтобы извлечь соответствующие особенности. В качестве примера мы будем использовать изображение Годзиллы, загруженное из интернета.
# Загрузка изображения image = cv2.imread('godzilla.jpg') # Преобразование из BGR в RGB (OpenCV загружает в формате BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Отображение исходного изображения plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
Вывод:

Прежде чем применять обнаружение краев, нам нужно предварительно обработать наше изображение. Мы делаем это следующим образом:
# Преобразование изображения в оттенки серого gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Применение гауссовского размытия для уменьшения шума blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
Наконец, давайте применим алгоритм обнаружения краев Canny и визуализируем результаты:
# Примените обнаружение краев Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # Отобразите результаты plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
Вывод:

Детектор краев Canny помогает нам выявить важные границы и особенности на изображении, которые могут быть использованы для дальнейшего анализа или в качестве входных данных для моделей машинного обучения.
Извлечение MFCC из аудио с использованием LibROSA
Прежде чем мы сможем начать обработку аудиофайлов, нам нужно установить необходимые библиотеки. Поскольку LibROSA не входит в стандартную библиотеку Python, мы будем использовать pip для его установки:
# Установка необходимых библиотек # Выполните эти команды в вашем терминале или командной строке pip install librosa pip install numpy pip install matplotlib
LibROSA – мощная библиотека, предназначенная для анализа музыки и звука, поэтому давайте начнем с его импорта вместе с другими необходимыми библиотеками:
# Импорт необходимых библиотек import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
Звуковые файлы содержат много информации в формате волновой формы. Чтобы работать с этими данными, сначала нужно загрузить их в нашу программу. LibROSA помогает нам сделать это, преобразовывая аудиофайл в формат, который мы можем анализировать:
# Загрузить аудиофайл # Продолжительность ограничена 10 секундами для этого примера audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # Отобразить волновую форму plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
Вывод:
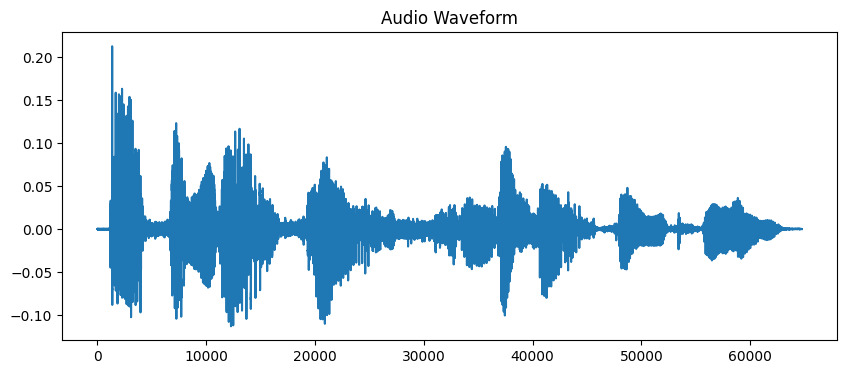
Теперь, когда мы загрузили аудио, нам нужно извлечь из него значимые характеристики. Наши уши естественным образом разбивают звук на различные частотные компоненты, и MFCC имитирует этот процесс. Мы используем функцию извлечения признаков librosa, чтобы вычислить эти коэффициенты:
# Извлечь MFCC характеристики mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # Отобразить MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Вывод:
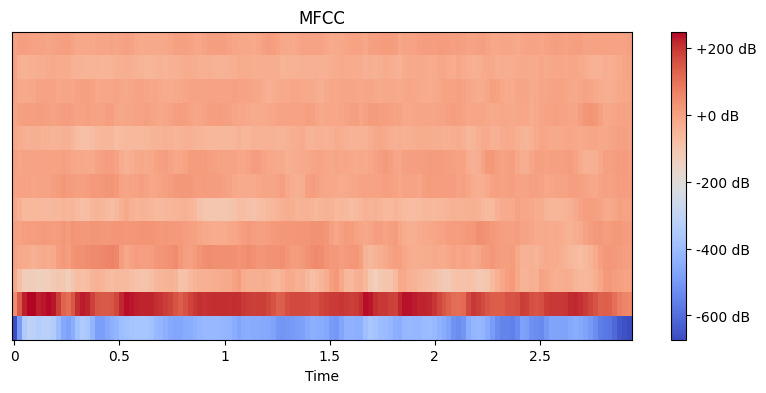
Здесь мы устанавливаем n_mfcc=13, потому что первые 13 коэффициентов обычно захватывают наиболее важные аспекты звука, которые помогают в задачах, таких как распознавание речи. Полученная визуализация показывает, как эти характеристики меняются со временем, где более яркие цвета представляют более высокие значения.
Извлечение признаков из данных временных рядов с помощью tsfresh
Сначала давайте установим необходимые библиотеки. Мы будем использовать yfinance для получения финансовых данных, а также tsfresh для извлечения признаков:
# Установка необходимых библиотек # Выполните эти команды в вашем терминале или командной строке pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
Теперь давайте импортируем наши библиотеки и получим реальные финансовые данные:
# Импортируем необходимые библиотеки import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
Получим реальные данные фондового рынка. В качестве примера используем данные акций Apple:
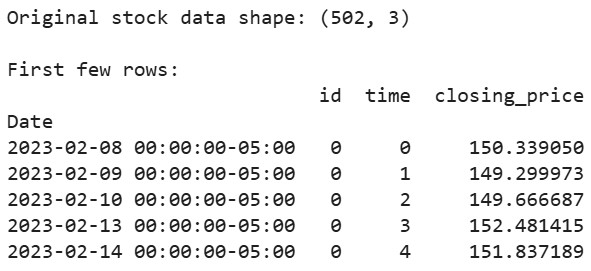
# Скачиваем данные акций Apple за последние 2 года aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # Подготавливаем данные в формате, который ожидает tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # Каждой временной серии нужен идентификатор 'time': range(len(df)), 'closing_price': df['Close'] # Мы будем использовать цены закрытия }) # Отображаем первые несколько строк наших данных print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
Вывод:
Теперь давайте извлечем признаки из наших финансовых временных рядов:
# Устанавливаем параметры извлечения признаков extraction_settings = MinimalFCParameters() # Извлекаем признаки автоматически extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # Отображаем извлеченные признаки print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
Вывод:

Здесь мы используем MinimalFCParameters() для указания извлекаемых функций. Это дает нам базовый набор значимых временных рядов, таких как среднее, дисперсия и характеристики тренда, которые необходимы для понимания закономерностей в наших данных.
Проблемы извлечения признаков
При работе с извлечением признаков мы часто сталкиваемся с проблемами.
Высокая размерность и вычислительные ограничения часто возникают при работе с большими наборами данных. Например, извлечение признаков из изображений высокого разрешения или длинных аудиофайлов может потреблять значительное количество памяти и вычислительной мощности.
Переобучение из-за неактуальных или избыточных функций – еще одна распространенная проблема. Когда извлекается слишком много функций, модели могут учить шум вместо значимых закономерностей. Это особенно распространено в обработке изображений и звука, где может быть сгенерировано тысячи функций.
Для преодоления этих проблем рассмотрите следующие стратегии:
- Используйте предметные знания для выбора актуальных функций
- Примените методы выбора функций для уменьшения размерности
- Примените правильные методы инженерии функций в зависимости от типа ваших данных
Эти задачи требуют тщательного рассмотрения и балансировки между богатством функций и вычислительной эффективностью.
Заключение
Извлечение признаков — это основополагающий навык в машинном обучении, который преобразует сырые данные в значимые представления. Через наши практические примеры с OpenCV, LibROSA и tsfresh мы увидели, как извлекать признаки из различных типов данных. Понимая эти техники и их вызовы, мы можем создавать эффективные модели машинного обучения.
Готовы углубиться? Ознакомьтесь с этими ресурсами:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning