













La extracción de características en el aprendizaje automático transforma datos crudos en un conjunto de características significativas, capturando información esencial mientras se reduce la redundancia. Puede implicar técnicas de reducción de dimensionalidad y métodos que crean nuevas características a partir de datos existentes.
Imagina que estás tratando de identificar frutas en un mercado. Aunque podrías considerar innumerables atributos (peso, color, textura, forma, olor, etc.), podrías darte cuenta de que solo algunas características clave como el color y el tamaño son suficientes para distinguir entre manzanas y naranjas. Esto es exactamente lo que hace la extracción de características. Te ayuda a centrarte en las características más informativas de tus datos.
Al realizar la extracción de características, los datos originales se transforman matemáticamente en un nuevo conjunto de características. Estas nuevas características están diseñadas para capturar los aspectos más importantes de los datos mientras posiblemente se reduce su complejidad. Las características extraídas a menudo representan patrones o estructuras subyacentes que podrían no ser inmediatamente evidentes en los datos originales.
Extracción de Características
En las siguientes secciones, exploraremos por qué la extracción de características es tan importante en el aprendizaje automático y examinaremos varios métodos para extraer características de diferentes tipos de datos junto con su código. Si deseas algunos ejemplos prácticos, echa un vistazo a nuestro curso de Reducción de Dimensionalidad en Python, que tiene un capítulo dedicado a la extracción de características.
¿Por qué es importante la Extracción de Características en el Aprendizaje Automático?
La extracción de características juega un papel importante en el aprendizaje automático. Puede marcar la diferencia entre un modelo que falla y uno que tiene éxito. Veamos por qué esto es tan fundamental para construir modelos de aprendizaje automático efectivos.
Mejorando la precisión y eficiencia del modelo
Al trabajar con datos en bruto, el aprendizaje automático los modelos a menudo tienen dificultades para distinguir entre patrones significativos y ruido. La extracción de características sirve como un paso de preprocesamiento de datos que puede mejorar significativamente cómo aprenden y rinden tus modelos.
Rendimiento del modelo versus tiempo de entrenamiento
Por ejemplo, cuando un modelo alcanza un 85% de precisión con datos en bruto, el mismo modelo podría alcanzar un 95% de precisión cuando se entrena con características cuidadosamente extraídas. Esta mejora no proviene de cambiar el modelo, sino de proporcionarle datos de entrada de mejor calidad de los cuales aprender.
Gestionando conjuntos de datos de alta dimensión
Los conjuntos de datos modernos a menudo vienen con cientos o miles de características. Esto presenta varios desafíos que la extracción de características ayuda a abordar.
- La maldición de la dimensionalidad: A medida que aumenta el número de características, los datos se vuelven cada vez más dispersos en el espacio de características. Esto dificulta que los modelos encuentren patrones significativos. La extracción de características crea una representación más compacta que preserva las relaciones importantes mientras reduce la dimensionalidad.
- Alto uso de memoria: Los datos de alta dimensionalidad requieren más almacenamiento y memoria durante el procesamiento. Al extraer solo las características más relevantes, podemos reducir significativamente la huella de memoria de nuestros conjuntos de datos manteniendo su valor informativo.
- Visualización de datos: Es imposible visualizar datos con más de tres dimensiones directamente. La extracción de características puede reducir la dimensionalidad a dos o tres características, lo que permite trazar y entender la estructura de los datos visualmente.
La extracción de características aborda estos desafíos al reducir la dimensionalidad mientras preserva la información esencial. Esta reducción transforma datos de alta dimensión, extensos y dispersos, en una forma más compacta y manejable, lo que conduce a un aumento en el rendimiento del modelo.
Reducción de la complejidad computacional y prevención del sobreajuste
La extracción de características proporciona dos beneficios críticos para los modelos de aprendizaje automático:
- Menores requisitos computacionales
- Menos características significan tiempos de entrenamiento más rápidos
- Uso reducido de memoria durante la implementación del modelo
- Generación de predicciones más eficiente
- Mejor generalización
- Spaces de características más simples ayudan a prevenir el sobreajuste
- Los modelos aprenden patrones más robustos
- Rendimiento mejorado en datos nuevos, no vistos anteriormente
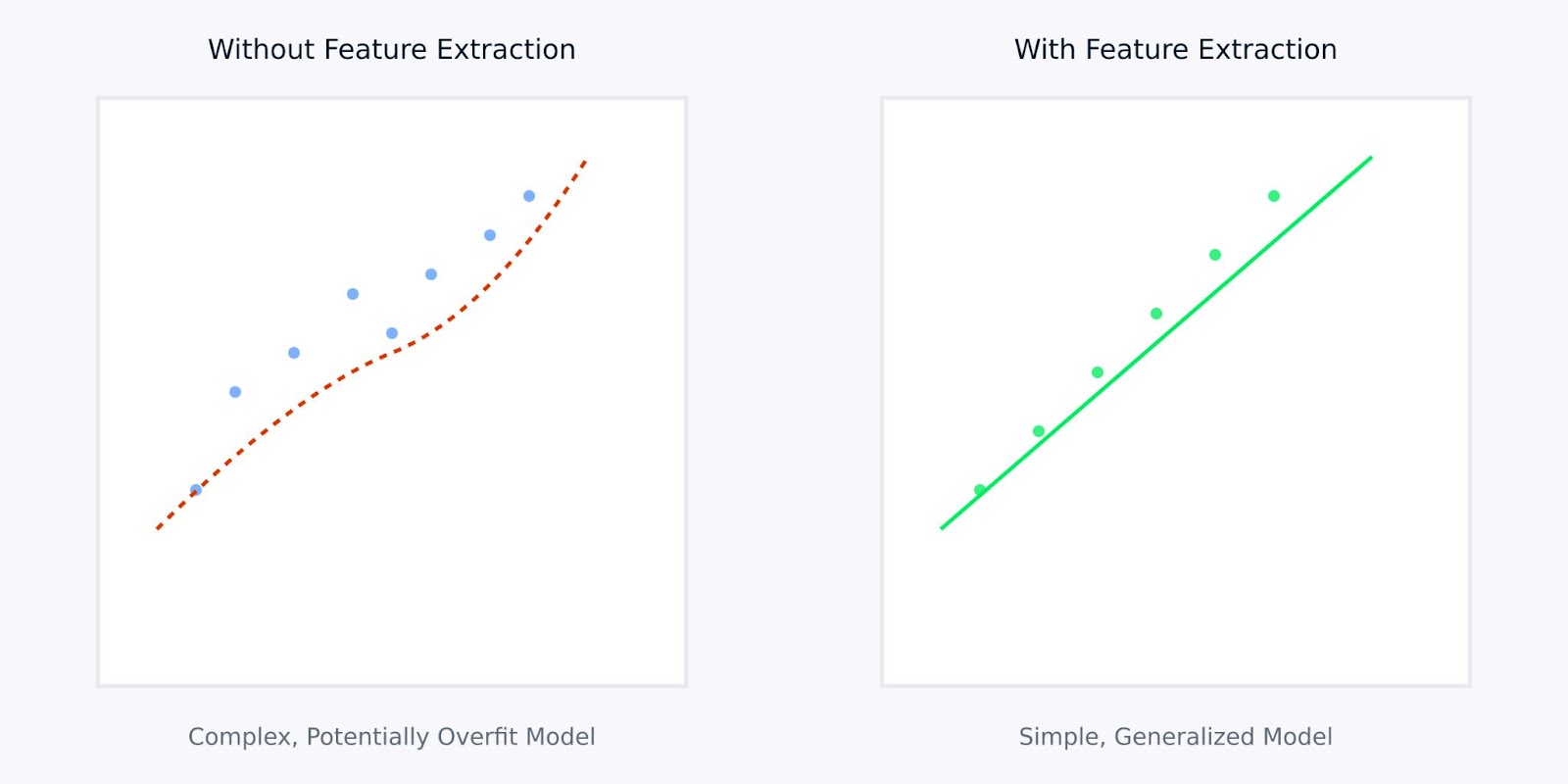
Extracción de características versus Sin extracción de características
La visualización anterior ilustra cómo la extracción de características puede llevar a modelos más simples y robustos. El gráfico izquierdo muestra un modelo complejo tratando de ajustarse a datos ruidosos y de alta dimensión, mientras que el gráfico derecho muestra cómo la extracción de características puede revelar un patrón más claro y generalizable.
Trabajar con características extraídas en lugar de datos crudos es como darle a tu modelo una versión clara y destilada de la información de la que necesita aprender. Esto no solo hace que el proceso de aprendizaje sea más eficiente, sino que también lleva a modelos que tienen más probabilidades de funcionar bien en aplicaciones del mundo real.
A continuación, veamos diferentes métodos de extracción de características.
Métodos de Extracción de Características
Los métodos de extracción de características se pueden clasificar en dos enfoques principales: la ingeniería de características manual y la extracción de características automatizada. Veamos ambos métodos para entender cómo ayudan a transformar datos en bruto en características significativas.
Ingeniería de características manual
La ingeniería de características manual implica utilizar la experiencia en el dominio para identificar y crear características relevantes a partir de datos en bruto. Este enfoque práctico depende de nuestra comprensión del problema y de los datos para elaborar características significativas.
En el procesamiento de imágenes, la ingeniería de características manual puede involucrar técnicas como la detección de bordes para identificar los límites de los objetos, histogramas de color para capturar la distribución del color, análisis de texturas para cuantificar patrones y descriptores de forma para caracterizar la geometría de los objetos.
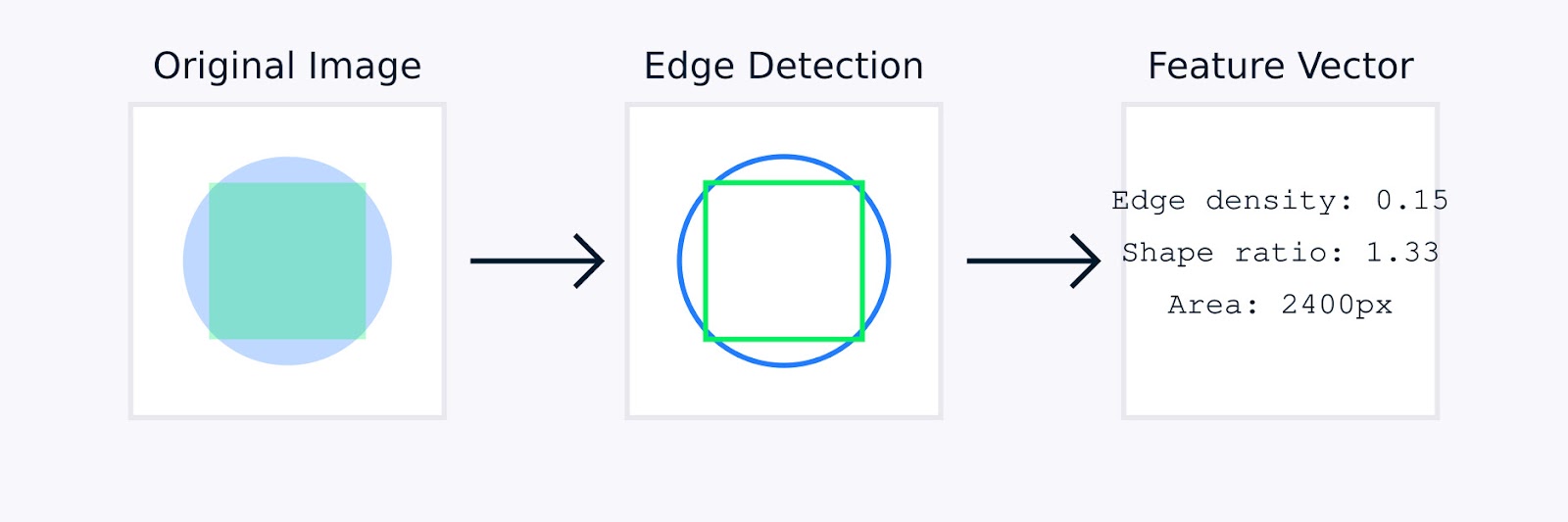
Extracción de Características de Imágenes
Para datos tabulares, la ingeniería de características manual implica crear términos de interacción entre las características existentes, transformar variables utilizando funciones logarítmicas o polinómicas, agregar puntos de datos en estadísticas significativas y codificar variables categóricas.
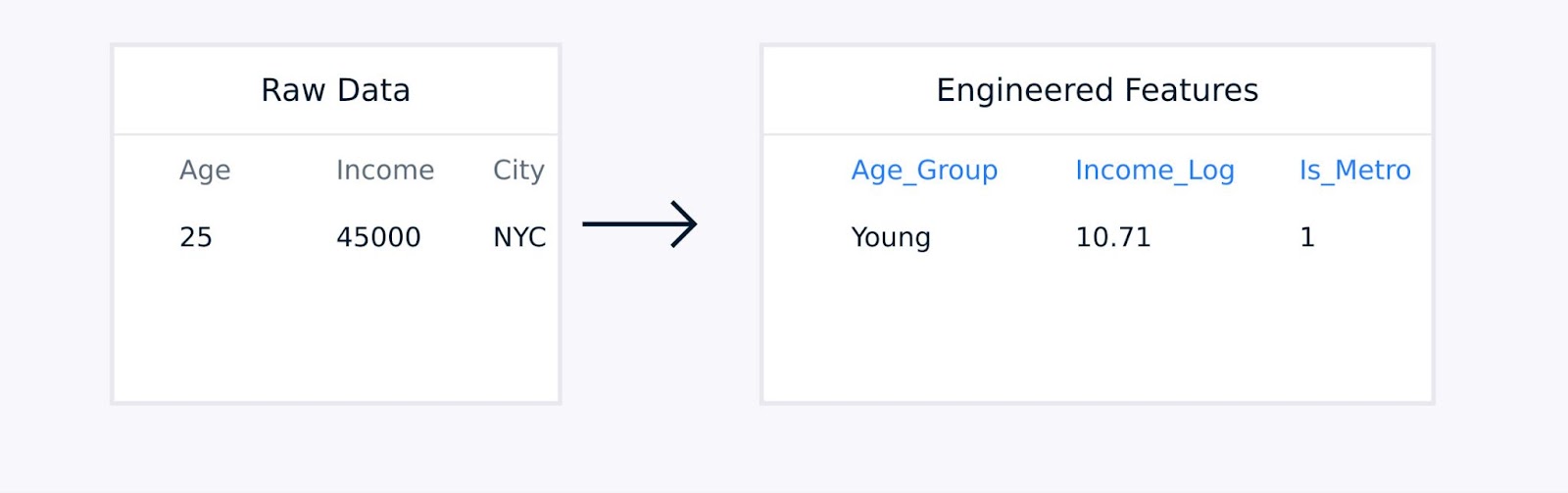
Extracción de características de datos tabulares
Estas técnicas, guiadas por la experiencia en el campo, mejoran la calidad de la representación de los datos y pueden mejorar significativamente el rendimiento del modelo.
Extracción automática de características
La extracción automática de características utiliza algoritmos para descubrir y crear características sin una guía humana explícita. Estos métodos son particularmente útiles cuando se trabaja con conjuntos de datos complejos donde la ingeniería de características manual podría ser poco práctica o ineficiente.
Enfoques automatizados comunes incluyen:
Análisis de Componentes Principales (PCA): Transforma los datos en un conjunto de componentes no correlacionados, donde cada componente captura la máxima varianza restante. Este enfoque es particularmente útil para la reducción de dimensionalidad, ya que preserva la información esencial dentro de los datos mientras simplifica su estructura.
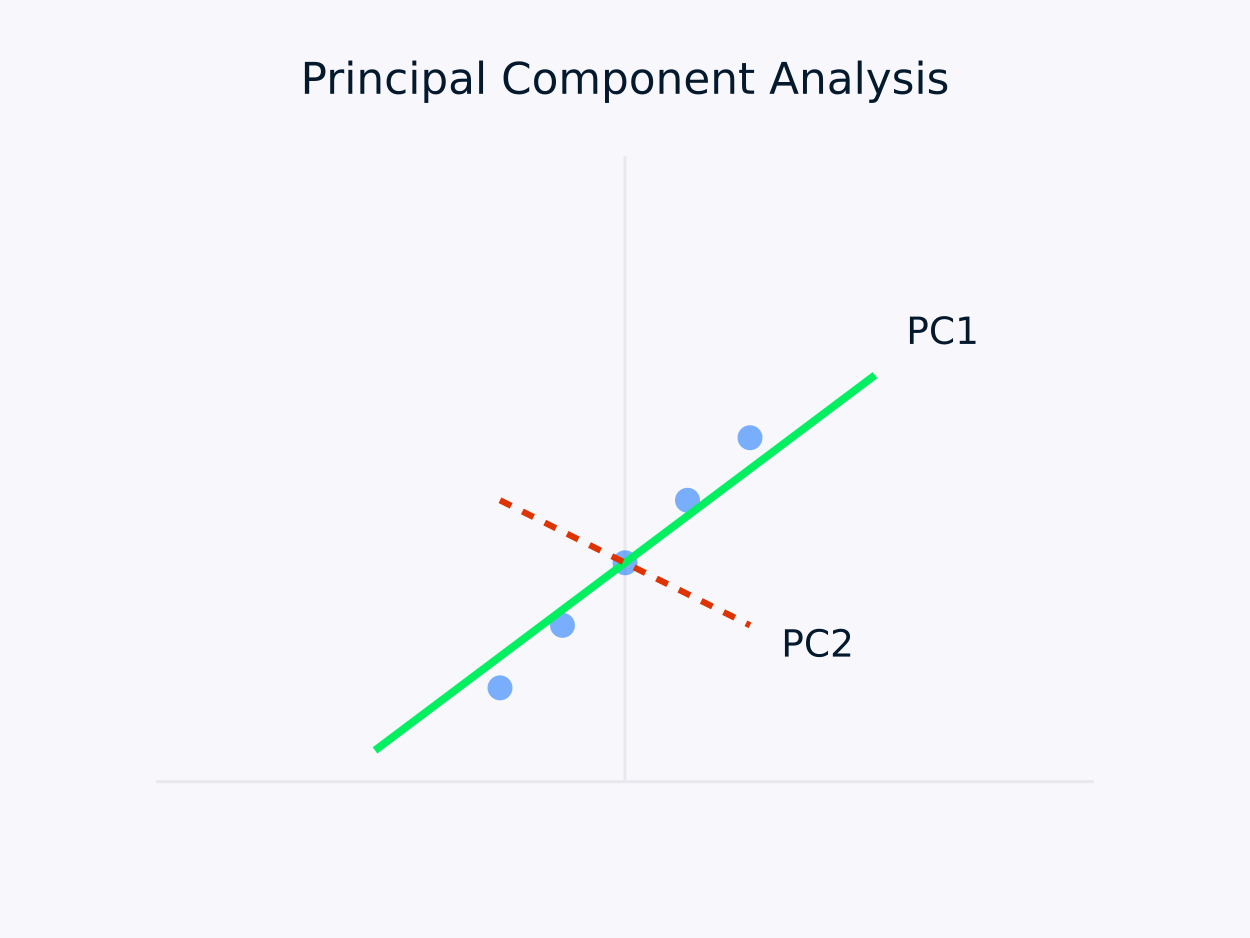
Análisis de Componentes Principales (PCA)
Autoencoders: Estos son redes neuronales que aprenden representaciones comprimidas de datos, capturando relaciones no lineales. Son particularmente efectivos para conjuntos de datos de alta dimensionalidad, donde los métodos lineales tradicionales podrían quedarse cortos.
Han surgido diversas herramientas y bibliotecas para simplificar las tareas de ingeniería de características. Por ejemplo, el módulo de descomposición de Scikit-learn ofrece una variedad de métodos para la reducción de dimensionalidad, y PyCaret proporciona capacidades de selección automática de características.
Ambos enfoques, manual y automatizado, tienen sus fortalezas. Veamos las fortalezas de cada enfoque.
|
Ingeniería Manual |
Extracción Automatizada |
|
Integración de conocimiento de dominio |
Escalabilidad |
|
Características interpretables |
Maneja patrones complejos |
|
Control detallado |
Reduce el sesgo humano |
|
Personalizado a necesidades específicas |
Descubre relaciones ocultas |
La elección entre métodos manuales y automatizados a menudo depende de factores como la complejidad del conjunto de datos, la disponibilidad de experiencia en el dominio, los requisitos de interpretabilidad, los recursos computacionales y las limitaciones de tiempo.
Para conjuntos de datos altamente complejos o cuando el tiempo y los recursos son limitados, los métodos automatizados pueden generar rápidamente características útiles. Por el contrario, los métodos manuales pueden ser preferibles cuando se cuenta con experiencia en el dominio y la interpretabilidad es una prioridad, lo que permite la ingeniería de características personalizada que se alinea estrechamente con el problema en cuestión.
En la práctica, muchos proyectos exitosos de aprendizaje automático combinan ambos enfoques, utilizando la experiencia en el dominio para guiar la ingeniería de características mientras aprovechan los métodos automatizados para descubrir patrones adicionales que pueden no ser inmediatamente evidentes para los expertos humanos.
En la siguiente sección, veremos varias técnicas de extracción de características en diversos dominios.
Técnicas de Extracción de Características
Cada tipo de datos requiere técnicas específicas de extracción de características optimizadas para sus características únicas. Veamos las técnicas más comunes para diferentes tipos de datos.

Técnicas de Extracción de Características
Extracción de características de imágenes
La extracción de características de imágenes transforma los datos de píxeles brutos en representaciones significativas que capturan información visual esencial. Existen tres categorías principales de técnicas utilizadas en la visión por computadora moderna. Son los métodos tradicionales, los métodos basados en aprendizaje profundo y los métodos estadísticos.

Métodos de Extracción de Características de Imágenes
Vamos a analizar cada uno de los métodos.
Métodos tradicionales de visión por computadora
Transformación de Características Invariante a Escala (SIFT) es un método robusto que detecta características locales distintivas en imágenes. Funciona identificando puntos clave y generando descriptores que son:
- Invariantes a la escala y rotación de la imagen
- Parcialmente invariantes a cambios de iluminación
- Robustos a distorsiones geométricas locales
El algoritmo SIFT procesa imágenes a través de varias etapas. Comienza con la detección de extremos en el espacio de escala para identificar posibles puntos clave que son invariantes a la escala. A continuación, la localización de puntos clave refina estos candidatos al determinar sus ubicaciones precisas y descartar puntos inestables.
Después de esto, la asignación de orientación determina una orientación consistente para cada punto clave, asegurando la invariancia a la rotación. Finalmente, la generación de descriptores de puntos clave crea descriptores distintivos basados en los gradientes locales de la imagen, facilitando una coincidencia robusta entre imágenes.
Otro método es el Histograma de Gradientes Orientados (HOG). Captura información local de forma al analizar patrones de gradiente a través de una imagen. El proceso comienza calculando gradientes a lo largo de la imagen para resaltar los detalles de los bordes.
La imagen se divide en pequeñas celdas, y para cada celda se crea un histograma de orientaciones de gradiente para resumir la estructura local. Finalmente, estos histogramas se normalizan en bloques más grandes para garantizar la robustez contra variaciones en la iluminación y el contraste, lo que resulta en un descriptor de características robusto para tareas como la detección y reconocimiento de objetos.
Los métodos de aprendizaje profundo
Redes Neuronales Convolucionales (CNN) han cambiado la forma en que realizamos la extracción de características al aprender automáticamente representaciones jerárquicas.

Extracción de características con CNN
Las CNNs aprenden características a través de su estructura jerárquica. En las capas iniciales, detectan elementos visuales básicos como bordes y colores. Luego, las capas intermedias combinan estos elementos para reconocer patrones y formas, mientras que las capas más profundas capturan objetos complejos y permiten la comprensión de escenas.
El aprendizaje por transferencia nos permite utilizar estas características pre-aprendidas de modelos entrenados en grandes conjuntos de datos, lo que las hace particularmente valiosas al trabajar con datos limitados.
Métodos estadísticos
Los métodos estadísticos extraen tanto patrones globales como locales de las imágenes, facilitando un análisis e interpretación robustos de las imágenes.
Por ejemplo, los histogramas de color representan la distribución de colores dentro de una imagen y proporcionan características invariantes a la rotación y escala, lo que los hace particularmente útiles para tareas como la clasificación y recuperación de imágenes.
El análisis de textura captura patrones repetidos y características de superficie utilizando técnicas como las Matrices de Co-ocurrencia de Niveles de Gris (GLCM), que son efectivas para aplicaciones que incluyen el reconocimiento de materiales y la clasificación de escenas.
Además, la detección de bordes identifica límites y cambios significativos de intensidad a través de métodos como los operadores Sobel, Canny y Laplaciano, desempeñando un papel crucial en la detección de objetos y análisis de formas.
La elección del método de extracción de características depende de varios factores. Debe estar alineada con los requisitos específicos de su tarea, considerar los recursos computacionales disponibles y tener en cuenta la necesidad de interpretabilidad.
Además, las características de su conjunto de datos, como su tamaño, niveles de ruido y complejidad, desempeñan un papel crucial, al igual que las propiedades de invariancia requeridas como la escala, rotación e iluminación.
Extracción de características de audio
Imagina intentar enseñar a una computadora a entender el habla de la manera en que lo hacen los humanos. Aquí es donde entran en juego los Coeficientes Cepstrales de Mel-Frecuencia (MFCC).
Los MFCC son características especiales del audio que descomponen el sonido de una manera similar a como lo procesan nuestros oídos. Son particularmente efectivos porque se centran en las frecuencias a las que los humanos son más sensibles. Piensa en ellos como una forma de traducir el sonido a un formato que tanto las computadoras como la audición humana encontrarían significativo.
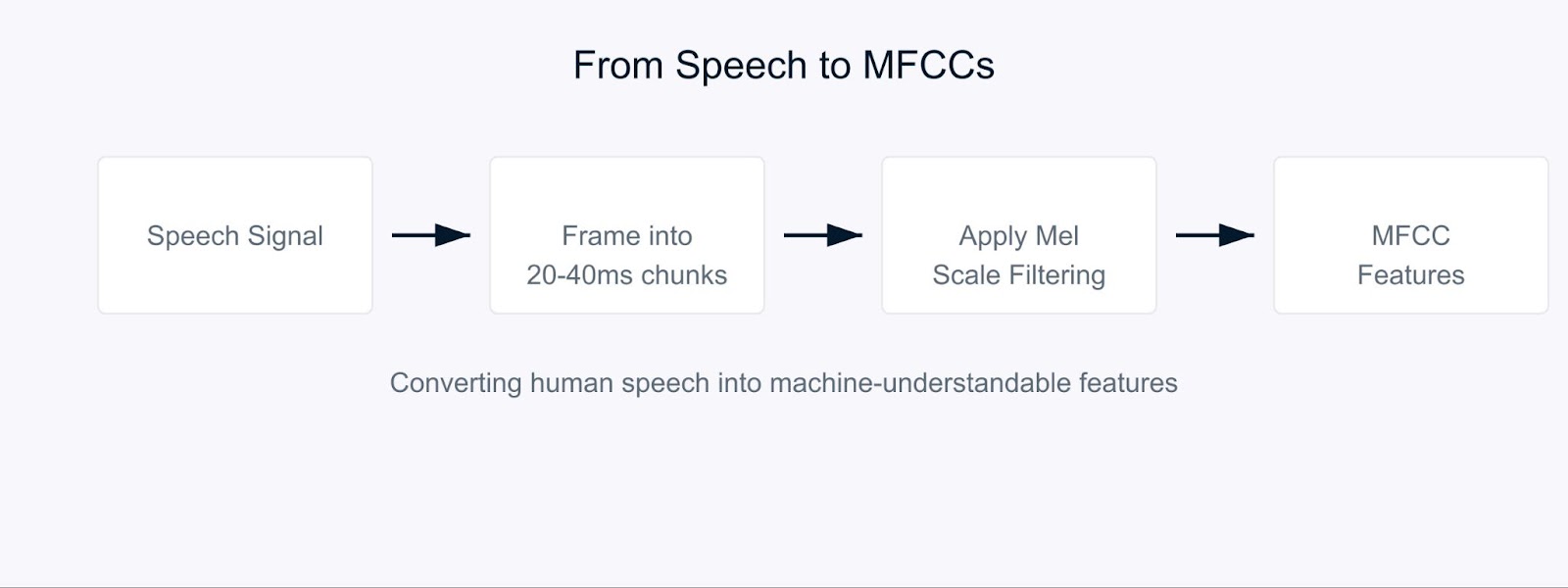
Coeficientes Cepstrales de Mel-Frecuencia
El proceso comienza descomponiendo la señal de audio en fragmentos cortos, típicamente de 20-40 milisegundos de duración. Para cada fragmento, aplicamos una serie de transformaciones matemáticas que convierten las ondas de sonido crudas en componentes de frecuencia. Aquí es donde se vuelve interesante. En lugar de tratar todas las frecuencias por igual, utilizamos algo llamado la escala de Mel.
![]()
Esta fórmula puede parecer compleja, pero simplemente está mapeando frecuencias para coincidir con cómo los humanos perciben el sonido. Nuestros oídos son mejores para detectar diferencias en frecuencias bajas que en las altas, y la escala Mel tiene en cuenta este sesgo natural.
En el reconocimiento de voz, los MFCCs sirven como la base para entender quién está hablando y qué están diciendo. Cuando hablas con el asistente virtual de tu teléfono, es probable que esté utilizando MFCCs para procesar tu voz. Estos coeficientes ayudan a capturar las características únicas de la voz de cada persona, lo que los hace invaluables para los sistemas de identificación de hablantes.
Para el análisis de sentimientos en el habla, los MFCCs ayudan a detectar variaciones sutiles en la voz que indican emociones. Pueden capturar cambios en el tono, la entonación y la velocidad de habla que podrían indicar si alguien está feliz, triste, enojado o neutral. Por ejemplo, al analizar llamadas de servicio al cliente, los MFCCs pueden ayudar a identificar los niveles de satisfacción del cliente basándose en cómo hablan, no solo en lo que dicen.
Extracción de características de series temporales
Al trabajar con series de tiempo los datos, extraer características significativas nos ayuda a capturar patrones y tendencias que evolucionan con el tiempo. Veamos algunas técnicas clave utilizadas para transformar datos de series de tiempo en características útiles.

Métodos de Extracción de Características de Series de Tiempo
La Transformada de Fourier descompone los datos de series de tiempo en sus componentes de frecuencia, revelando patrones periódicos ocultos. La fórmula es:
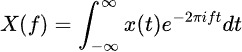
Los métodos estadísticos complementan el análisis de frecuencias al capturar características temporales. Las características comunes incluyen medias móviles, desviaciones estándar y componentes de tendencia. Estas técnicas son particularmente poderosas en pronósticos financieros, donde ayudan a identificar tendencias del mercado y anomalías.
Por ejemplo, en el análisis del mercado de valores, combinar características de Fourier con medidas estadísticas puede revelar tanto tendencias a largo plazo como patrones cíclicos. De manera similar, en entornos industriales, estos métodos ayudan a detectar anomalías en equipos analizando patrones de datos de sensores a lo largo del tiempo.
Herramientas y bibliotecas para la extracción de características
Veamos algunas herramientas esenciales que hacen que la implementación de estos métodos de extracción de características sea sencilla y eficiente.
Herramientas y Bibliotecas para la Extracción de Características
Para el procesamiento de imágenes, OpenCV y scikit-image ofrecen herramientas completas para implementar varias técnicas de extracción de características. Estas bibliotecas ofrecen implementaciones eficientes de SIFT, HOG y otros algoritmos que discutimos anteriormente. Al trabajar con enfoques de aprendizaje profundo, marcos como TensorFlow y PyTorch se vuelven invaluables. Puedes comenzar con nuestro tutorial de OpenCV para aprender más.
Las tareas de procesamiento de audio se simplifican con bibliotecas como LibROSA, que destaca en la extracción de MFCC y otras características acústicas. PyAudioAnalysis amplía estas capacidades con interfaces de alto nivel para tareas de análisis de audio.
Para datos de series temporales, tsfresh y Featuretools automatizan el proceso de extracción de características. Estas bibliotecas pueden generar y seleccionar automáticamente características relevantes de sus datos temporales, lo que facilita centrarse en el desarrollo de modelos en lugar de en la ingeniería de características.
Ejemplo de Extracción de Características
Pongamos en práctica nuestro conocimiento con algunos ejemplos prácticos. Empezaremos con la extracción de características de imágenes, una de las aplicaciones más comunes en visión por computadora.
Extracción de características de imágenes usando OpenCV
Primero, importemos las bibliotecas necesarias
# Importar las bibliotecas necesarias import cv2 import numpy as np import matplotlib.pyplot as plt
Ahora, carguemos una imagen para extraer características relevantes. Para este ejemplo, utilizaremos una imagen de Godzilla descargada de internet.
# Cargar la imagen image = cv2.imread('godzilla.jpg') # Convertir de BGR a RGB (OpenCV carga en formato BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Mostrar la imagen original plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
Salida:

Antes de aplicar la detección de bordes, necesitamos procesar nuestra imagen. Hacemos lo siguiente:
# Convertir la imagen a escala de grises gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Aplicar desenfoque Gaussiano para reducir el ruido blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
Finalmente, apliquemos el algoritmo de detección de bordes Canny y visualicemos los resultados:
# Aplicar detección de bordes Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # Mostrar los resultados plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
Salida:

El detector de bordes Canny nos ayuda a identificar límites y características importantes en nuestra imagen, que pueden ser utilizados para un análisis posterior o como entrada para modelos de aprendizaje automático.
Extrayendo MFCC de audio usando LibROSA
Antes de que podamos comenzar a procesar archivos de audio, necesitamos instalar las bibliotecas requeridas. Dado que LibROSA no está incluida en la biblioteca estándar de Python, usaremos pip para instalarla:
# Instalar bibliotecas requeridas # Ejecuta estos comandos en tu terminal o símbolo del sistema pip install librosa pip install numpy pip install matplotlib
LibROSA es una biblioteca poderosa diseñada para el análisis de música y audio, así que empecemos importándola junto con otras bibliotecas necesarias:
# Importar bibliotecas requeridas import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
Los archivos de sonido contienen mucha información en formato de onda. Para trabajar con estos datos, primero necesitamos cargarlos en nuestro programa. LibROSA nos ayuda a hacer esto convirtiendo el archivo de audio en un formato que podemos analizar:
# Cargar el archivo de audio # La duración está limitada a 10 segundos para este ejemplo audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # Mostrar la forma de la onda plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
Salida:
Ahora que tenemos nuestro audio cargado, necesitamos extraer características significativas de él. Nuestros oídos descomponen naturalmente el sonido en diferentes componentes de frecuencia, y MFCC imita este proceso. Usamos la función de extracción de características de librosa para calcular estos coeficientes:
# Extraer características MFCC mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # Mostrar el MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Salida:
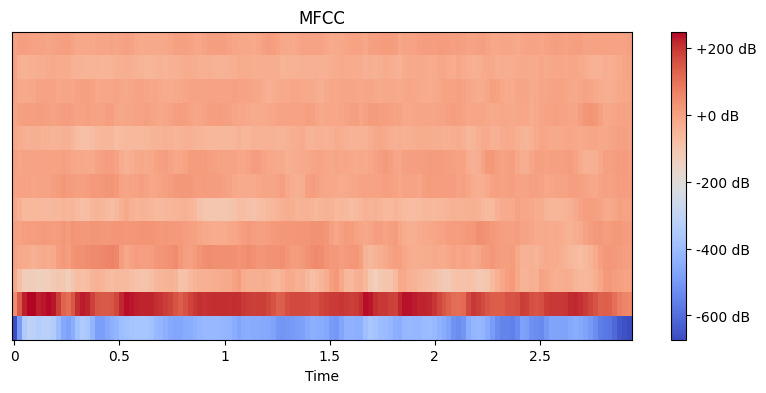
Aquí, establecemos n_mfcc=13 porque los primeros 13 coeficientes suelen capturar los aspectos más importantes del sonido que ayudan en tareas como el reconocimiento de voz. La visualización resultante muestra cómo estos rasgos cambian con el tiempo, donde los colores más brillantes representan valores más altos.
Extracción de características de datos de series temporales con tsfresh
Primero, instalemos las bibliotecas requeridas. Utilizaremos yfinance para obtener datos financieros, junto con tsfresh para la extracción de características:
# Instalar bibliotecas requeridas # Ejecute estos comandos en su terminal o símbolo del sistema pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
Ahora importemos nuestras bibliotecas y obtengamos algunos datos financieros reales:
# Importar bibliotecas requeridas import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
Vamos a obtener algunos datos reales del mercado de valores. Utilizaremos los datos de acciones de Apple como ejemplo:
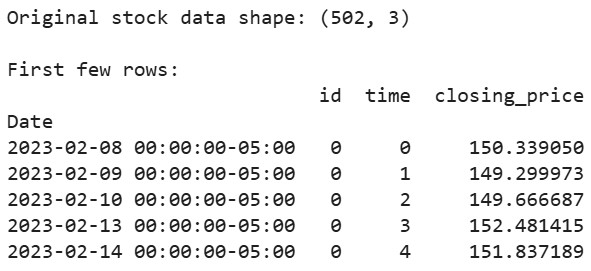
# Descargar los datos de acciones de Apple de los últimos 2 años aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # Preparar los datos en el formato que espera tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # Cada serie temporal necesita un ID 'time': range(len(df)), 'closing_price': df['Close'] # Utilizaremos los precios de cierre }) # Mostrar las primeras filas de nuestros datos print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
Salida:
Ahora vamos a extraer características de nuestros datos de series temporales financieras:
# Configurar los parámetros de extracción de características extraction_settings = MinimalFCParameters() # Extraer características automáticamente extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # Mostrar las características extraídas print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
Salida:

Aquí, usamos MinimalFCParameters() para especificar qué características extraer. Esto nos proporciona un conjunto básico de características de series temporales significativas como la media, la varianza y las características de tendencia, que son esenciales para comprender los patrones en nuestros datos.
Desafíos en la Extracción de Características
Al trabajar con la extracción de características, a menudo encontramos desafíos.
La alta dimensionalidad y las limitaciones computacionales a menudo surgen al tratar con grandes conjuntos de datos. Por ejemplo, extraer características de imágenes de alta resolución o archivos de audio largos puede consumir una cantidad significativa de memoria y potencia de procesamiento.
El sobreajuste debido a características irrelevantes o redundantes es otro desafío común. Cuando se extraen demasiadas características, los modelos pueden aprender ruido en lugar de patrones significativos. Esto es especialmente común en el procesamiento de imágenes y audio, donde se pueden generar miles de características.
Para superar estos desafíos, considera estas estrategias:
- Utiliza el conocimiento del dominio para seleccionar características relevantes
- Aplica métodos de selección de características para reducir la dimensionalidad
- Implementa técnicas adecuadas de ingeniería de características basadas en tu tipo de datos
Estos desafíos requieren una cuidadosa consideración y un equilibrio entre la riqueza de características y la eficiencia computacional.
Conclusión
La extracción de características es una habilidad fundamental en el aprendizaje automático que transforma datos en bruto en representaciones significativas. A través de nuestros ejemplos prácticos con OpenCV, LibROSA y tsfresh, hemos visto cómo extraer características de diferentes tipos de datos. Al comprender estas técnicas y sus desafíos, podemos construir modelos de aprendizaje automático efectivos.
¿Listo para profundizar? Consulta estos recursos:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning