













머신 러닝에서의 특징 추출은 원시 데이터를 의미 있는 특성 집합으로 변환하여 필수적인 정보를 포착하고 중복을 줄입니다. 이는 차원 축소 기술 및 기존 데이터에서 새로운 특성을 생성하는 방법을 포함할 수 있습니다.
시장에서 과일을 식별하려고 한다고 상상해보십시오. 무게, 색상, 질감, 모양, 냄새 등을 고려할 수 있지만, 사과와 오렌지를 구분하는 데 색상과 크기와 같은 몇 가지 주요 특징만으로 충분하다는 것을 깨닫게 될 수 있습니다. 이것이 바로 특징 추출이 하는 일입니다. 이는 데이터의 가장 정보가 풍부한 특성에 집중할 수 있도록 도와줍니다.
특징 추출을 수행할 때, 원본 데이터는 수학적으로 새로운 특성 집합으로 변환됩니다. 이러한 새로운 특성은 데이터의 가장 중요한 측면을 포착하도록 설계되어 복잡성을 줄일 수도 있습니다. 추출된 특성은 종종 원본 데이터에서 즉시 나타나지 않을 수 있는 근본적인 패턴이나 구조를 나타냅니다.
특성 추출
다음 섹션에서는 특성 추출이 기계 학습에서 왜 중요한지 탐색하고 다양한 데이터 유형에서 특성을 추출하는 여러 방법과 그 코드를 살펴볼 것입니다. 실습 예제를 원한다면 당사의 파이썬을 이용한 차원 축소 과정을 확인해보세요. 해당 강좌에는 특성 추출에 대한 챕터가 포함되어 있습니다.
기계 학습에서 특성 추출이 왜 중요한가요?
특성 추출은 기계 학습에서 중요한 역할을 합니다. 이것은 실패하는 모델과 성공하는 모델 간의 차이를 만들어낼 수 있습니다. 효과적인 기계 학습 모델을 구축하는 데 있어서 왜 이것이 그렇게 근본적인 역할을 하는지 살펴봅시다.
모델 정확도와 효율성 향상
원시 데이터를 다룰 때, 기계 학습 모델은 종종 의미 있는 패턴과 잡음을 구별하기 어렵습니다. 특성 추출은 데이터 전처리 단계로 작용하여 모델이 학습하고 수행하는 능력을 크게 향상시킬 수 있습니다.
모델 성능 대 학습 시간
예를 들어, 모델이 원시 데이터로 85%의 정확도를 달성했을 때, 동일한 모델이 신중하게 추출된 특징으로 교육을 받을 때 95%의 정확도에 도달할 수 있습니다. 이 향상은 모델을 변경하는 것이 아니라 학습할 더 나은 품질의 입력 데이터를 제공하는 데서 나옵니다.
고차원 데이터 세트 관리
현대 데이터 세트는 종종 수백 개 또는 수천 개의 기능을 가지고 있습니다. 이는 특징 추출이 해결하는 여러 가지 도전을 가져옵니다.
- 차원의 저주: 피쳐의 수가 증가함에 따라 데이터는 피쳐 공간에서 점점 희소해집니다. 이로 인해 모델이 의미 있는 패턴을 찾기가 더 어려워집니다. 피쳐 추출은 중요한 관계를 보존하면서 차원을 줄이는 더 조밀한 표현을 만듭니다.
- 높은 메모리 사용량: 고차원 데이터는 처리 중에 더 많은 저장 공간과 메모리를 필요로 합니다. 가장 관련성이 높은 피쳐만 추출함으로써 데이터셋의 메모리 사용량을 크게 줄일 수 있으면서도 정보를 유지할 수 있습니다.
- 데이터 시각화: 세 개 이상의 차원을 직접 시각화하는 것은 불가능합니다. 특징 추출을 통해 차원을 두 개 또는 세 개로 줄일 수 있어 데이터 구조를 시각적으로 표현하고 이해하는 것이 가능해집니다.
특징 추출은 이러한 문제에 대응하여 차원을 줄이면서 중요한 정보를 보존합니다. 이 차원 축소는 광범위하고 고차원의 데이터를 더 간결하고 다루기 쉬운 형태로 변환하여 모델 성능을 향상시킵니다.
계산 복잡성 감소 및 오버피팅 방지
특징 추출은 기계 학습 모델에 두 가지 중요한 이점을 제공합니다:
- 낮은 계산 요구사항
- 기능이 적으면 더 빠른 학습 시간
- 모델 배포 중 메모리 사용량 감소
- 보다 효율적인 예측 생성
- 더 나은 일반화
- 간단한 특성 공간은 과적합을 방지하는 데 도움이 됨
- 모델이 더 견고한 패턴을 학습함
- 새로운, 보지 못한 데이터에 대한 성능 향상
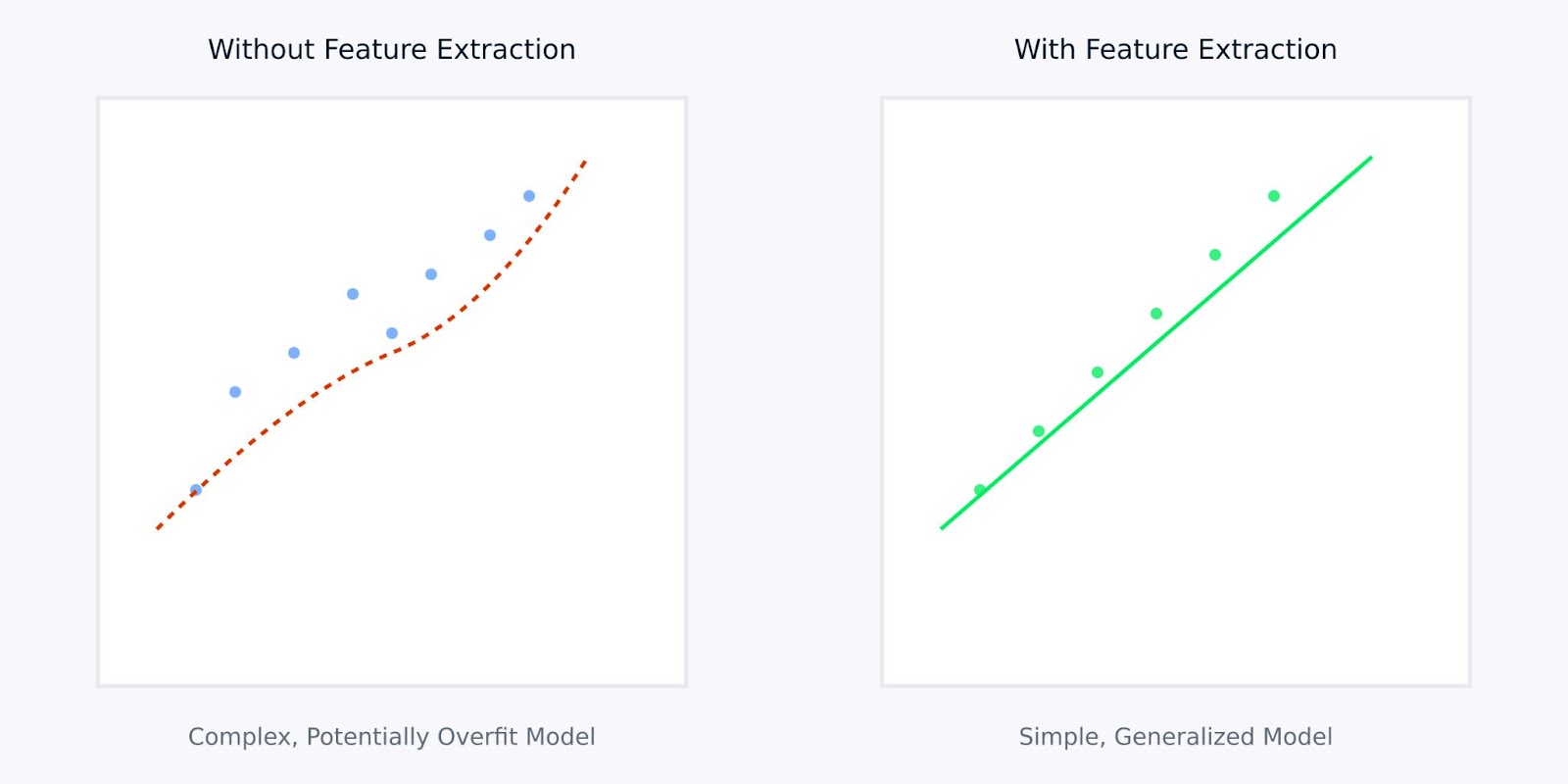
특징 추출 대 특징 추출 없이
위의 시각화는 특징 추출이 더 간단하고 견고한 모델로 이어질 수 있다는 것을 보여줍니다. 왼쪽 그래프는 잡음이 많고 고차원 데이터를 적합하려는 복잡한 모델을 보여주는 반면, 오른쪽 그래프는 특징 추출이 더 명확하고 일반화된 패턴을 드러낼 수 있다는 것을 보여줍니다.
원시 데이터 대신 추출된 특징을 사용하는 것은 모델에 학습할 정보의 명확하고 정제된 버전을 제공하는 것과 같습니다. 이는 학습 프로세스를 보다 효율적으로 만들 뿐만 아니라 실제 응용 프로그램에서 더 잘 수행할 가능성이 있는 모델로 이어집니다.
다음으로, 특징 추출의 다양한 방법을 살펴보겠습니다.
특징 추출 방법
특성 추출 방법은 주로 수동 특성 공학과 자동 특성 추출 두 가지 접근 방식으로 크게 분류될 수 있습니다. 이러한 두 가지 방법을 살펴보고 원시 데이터를 의미 있는 특성으로 변환하는 데 어떻게 도움을 주는지 이해해 봅시다.
수동 특성 공학
수동 특성 공학은 도메인 전문 지식을 활용하여 원시 데이터에서 관련성 있는 특성을 식별하고 생성하는 과정을 말합니다. 이 접근 방식은 문제와 데이터에 대한 이해를 기반으로 의미 있는 특성을 만드는 데 의존합니다.
이미지 처리image processing에서 수동 특징 엔지니어링은 객체 경계를 식별하기 위한 엣지 감지, 색상 분포를 캡처하기 위한 색상 히스토그램, 패턴을 정량화하기 위한 텍스처 분석, 객체 기하학을 특징짓기 위한 형태 설명자와 같은 기술을 포함할 수 있습니다.
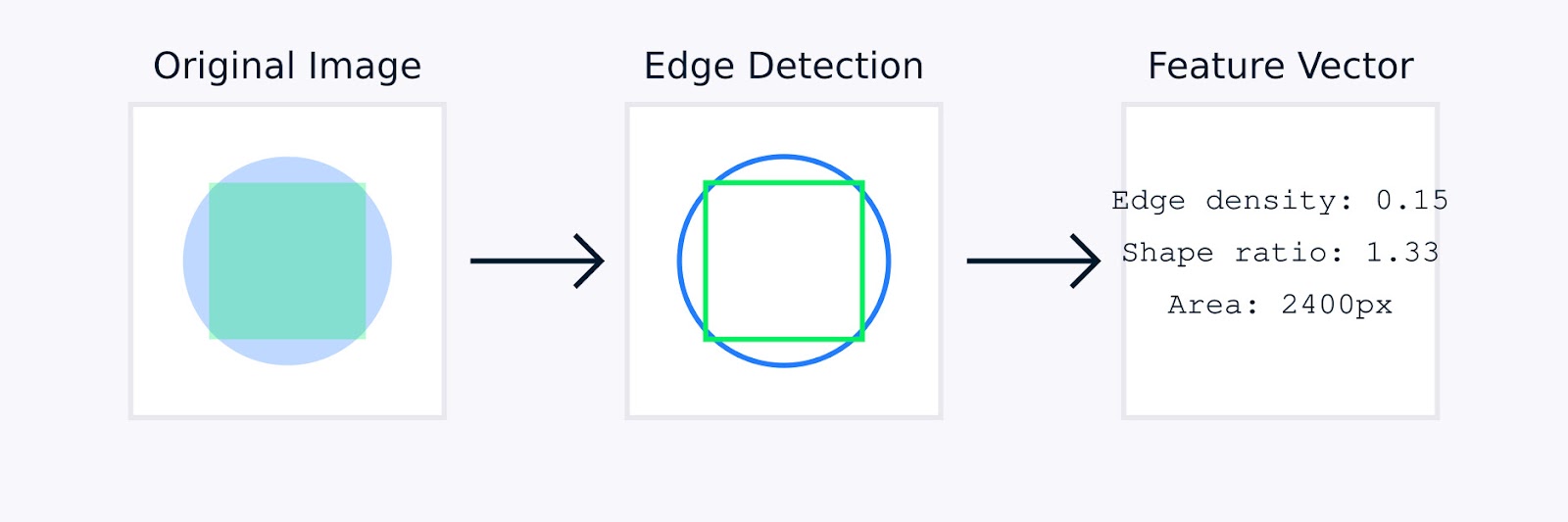
이미지 특징 추출
표 형식 데이터의 경우, 수동 특징 엔지니어링은 기존 특징 간의 상호 작용 항을 생성하고, 로그 또는 다항 함수로 변수를 변환하며, 데이터 포인트를 의미 있는 통계로 집계하고, 범주형 변수를 인코딩하는 작업을 포함합니다.
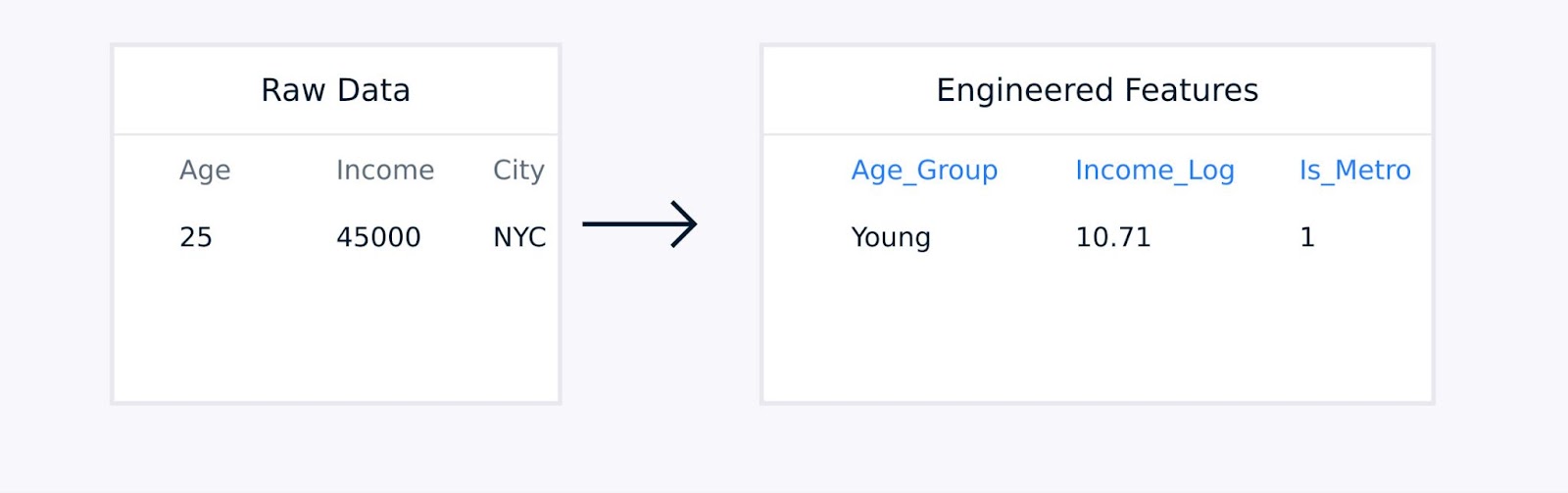
표 데이터 특징 추출
이러한 기술은 도메인 전문지식에 의해 안내되며 데이터 표현의 품질을 향상시키고 모델 성능을 크게 향상시킬 수 있습니다.
자동 특징 추출
자동 특징 추출은 알고리즘을 사용하여 명시적인 인간의 안내 없이 특징을 발견하고 생성합니다. 이러한 방법은 수동 특징 공학이 부적절하거나 비효율적일 수 있는 복잡한 데이터셋을 다룰 때 특히 유용합니다.
일반적인 자동 접근 방법에는 다음이 포함됩니다:
주성분 분석 (PCA):데이터를 상관 관계가 없는 구성 요소 집합으로 변환하며, 각 구성 요소는 최대 잔류 분산을 포착합니다. 이 접근 방식은 특히 차원 축소에 유용하며, 데이터 내의 중요 정보를 보존하면서 구조를 단순화합니다.
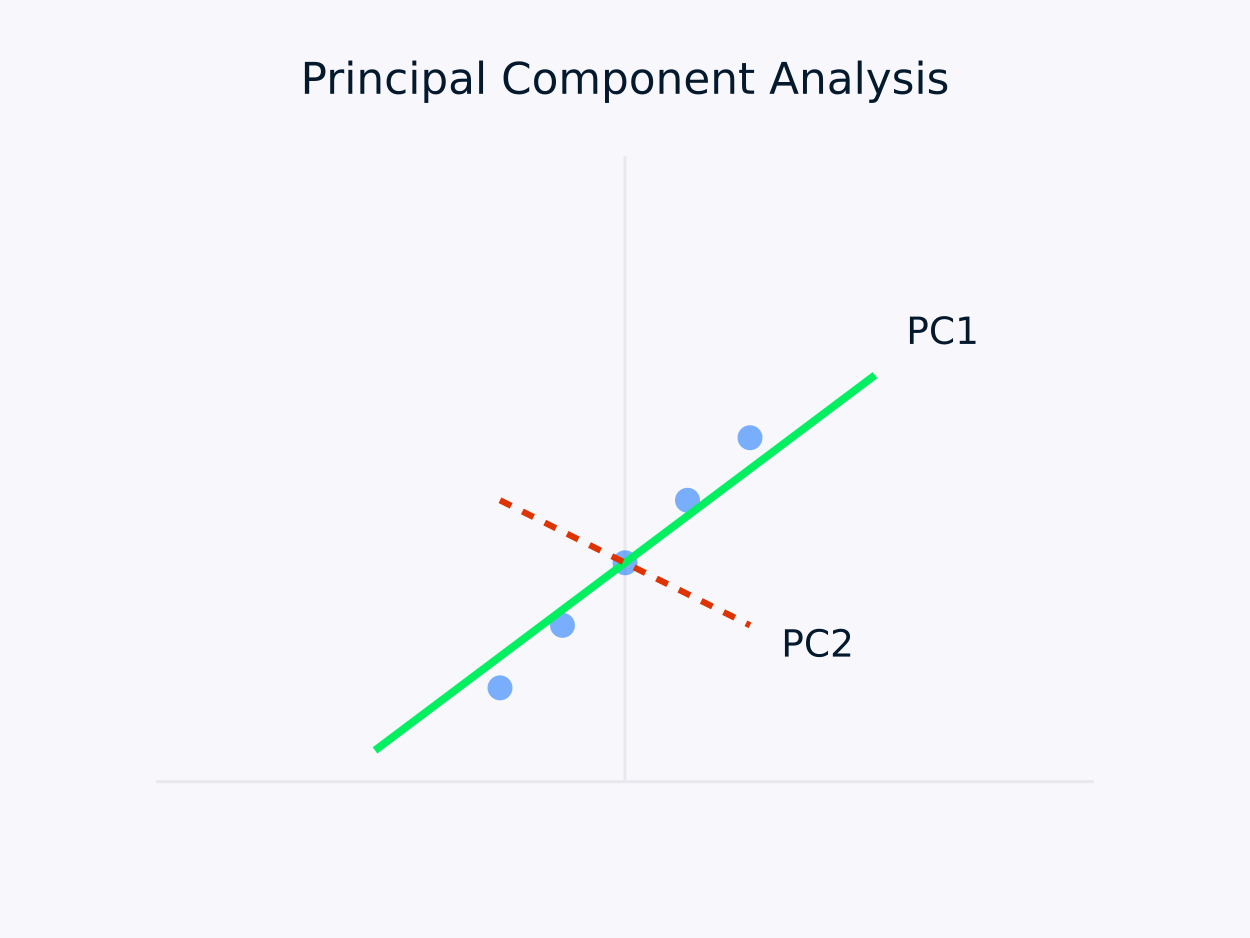
주성분 분석 (PCA)
오토인코더:이것들은 비선형 관계를 포착하는 데이터의 압축된 표현을 학습하는 신경망입니다. 전통적인 선형 방법이 한계에 부딪힐 수 있는 고차원 데이터셋에 특히 효과적입니다.
다양한 도구와 라이브러리가 등장하여 특성 공학 작업을 간소화하고 있습니다. 예를 들어, Scikit-learn의 decomposition 모듈은 차원 축소를 위한 다양한 방법을 제공하며, PyCaret은 자동 특성 선택 기능을 제공합니다.
수동 및 자동 접근 방식 모두 장점을 갖고 있습니다. 각 접근 방식의 장점을 살펴봅시다.
|
수동 공학 |
자동 추출 |
|
도메인 지식 통합 |
확장성 |
|
해석 가능한 기능 |
복잡한 패턴 처리 |
|
세밀한 제어 |
인간의 편견 감소 |
|
특정한 요구에 맞게 맞춤화 |
숨겨진 관계 발견 |
수동 및 자동 방법 중 선택은 데이터셋의 복잡성, 도메인 전문 지식의 가용성, 해석 가능성 요구 사항, 계산 자원 및 시간 제약 같은 요인에 따라 종종 달라집니다.
고도로 복잡한 데이터셋이거나 시간과 자원이 제한적인 경우, 자동화된 방법을 사용하면 유용한 피처를 빠르게 생성할 수 있습니다. 반대로, 도메인 전문 지식이 있고 해석 가능성이 우선시되는 경우 수동 방법이 선호될 수 있으며, 주어진 문제와 밀접하게 일치하는 맞춤형 피처 엔지니어링을 가능하게 합니다.
실제로 많은 성공적인 머신 러닝 프로젝트는 두 가지 접근 방식을 결합하여 사용하며, 도메인 전문 지식을 활용하여 피처 엔지니어링을 안내하면서 자동화된 방법을 활용하여 인간 전문가에게 즉시 명백하지 않은 추가적인 패턴을 발견합니다.
다음 섹션에서는 다양한 도메인에서 여러 피처 추출 기술을 살펴볼 것입니다.
피처 추출 기술
각 유형의 데이터는 고유한 특성에 최적화된 특징 추출 기술이 필요합니다. 각 유형의 데이터에 대해 가장 일반적인 기술을 살펴보겠습니다.

특징 추출 기술
이미지 특징 추출
이미지 특징 추출은 원시 픽셀 데이터를 중요한 시각적 정보를 포착하는 의미 있는 표현으로 변환합니다. 현대 컴퓨터 비전에서 사용되는 기술은 세 가지 주요 범주로 나뉩니다. 전통적인 방법, 심층 학습 기반 방법 및 통계적 방법이 있습니다.

이미지 특징 추출 방법
각 방법을 살펴봅시다.
전통적인 컴퓨터 비전 방법
스케일 불변 특징 변환 (SIFT)은 이미지에서 독특한 지역적인 특징을 감지하는 강력한 방법입니다. 이 방법은 주요 지점을 식별하고 다음과 같은 설명자를 생성함으로써 작동합니다:
- 이미지 스케일링 및 회전에 불변한
- 조명 변화에 대해 부분적으로 불변한
- 지역적인 기하 왜곡에 강건한
SIFT 알고리즘은 여러 단계를 거쳐 이미지를 처리합니다. 먼저 스케일-공간 극값을 감지하여 스케일에 불변한 잠재적인 주요 지점을 식별합니다. 다음으로, 주요점 지역화는 이러한 후보들을 정교하게 지정하고 불안정한 지점을 버리면서 이를 세분화합니다.
이에 따라, 방향 할당은 각 키포인트에 대해 일관된 방향을 결정하여 회전 불변성을 보장합니다. 마지막으로, 키포인트 기술자 생성은 로컬 이미지 그래디언트를 기반으로한 독특한 기술자를 생성하여 이미지 간 강력한 매칭을 용이하게 합니다.
다른 방법은 방향 기울기 히스토그램 (HOG)입니다. 이미지 전체를 통해 그래디언트를 계산하여 가장자리 세부 정보를 강조함으로써 지역 모양 정보를 캡처합니다.
이미지는 작은 셀로 나누어지고, 각 셀마다 경사 방향의 히스토그램이 생성되어 지역 구조를 요약합니다. 마지막으로, 이러한 히스토그램은 조명 및 대비 변동에 대한 강인함을 보장하기 위해 더 큰 블록을 통해 정규화되어 객체 감지 및 인식과 같은 작업을 위한 견고한 특징 설명자를 생성합니다.
딥 러닝 방법
합성곱 신경망 (CNNs)는 계층적 표현을 자동으로 학습함으로써 특징 추출 방식을 변화시켰습니다.

CNN을 사용한 특징 추출
합성곱 신경망은 계층 구조를 통해 특징을 학습합니다. 초기 계층에서는 가장자리와 색상과 같은 기본 시각 요소를 감지합니다. 중간 계층에서는 이러한 요소를 결합하여 패턴과 모양을 인식하고, 더 깊은 계층에서는 복잡한 객체를 포착하고 장면을 이해할 수 있습니다.
전이 학습을 통해 대규모 데이터셋에서 훈련된 모델로부터 미리 학습된 특징을 사용할 수 있어, 데이터가 제한적인 경우에 매우 유용합니다.
통계적 방법
통계적 방법은 이미지에서 전역 및 지역 패턴을 추출하여 견고한 이미지 분석과 해석을 용이하게 합니다.
예를 들어, 색상 히스토그램은 이미지 내 색상의 분포를 나타내며 회전 및 크기 불변 특징을 제공하여 이미지 분류 및 검색과 같은 작업에 특히 유용합니다.
질감 분석은 회전된 패턴 및 표면 특성을 Gray Level Co-occurrence Matrices (GLCM)와 같은 기술을 사용하여 캡처하는데, 이는 재료 인식 및 장면 분류와 같은 응용에 효과적입니다.
또한, 에지 검출은 Sobel, Canny, Laplacian 연산자와 같은 방법을 통해 경계와 중요한 강도 변화를 식별하여 객체 검출 및 모양 분석에 중요한 역할을 합니다.
특징 추출 방법의 선택은 여러 요소에 따라 결정됩니다. 작업의 구체적 요구 사항과 일치해야 하며, 사용 가능한 계산 자원을 고려하고 해석 가능성 요구 사항을 고려해야 합니다.
데이터 집합의 특성 — 크기, 잡음 수준, 복잡성과 같은 — 뿐만 아니라, 규모, 회전, 조명과 같은 필요한 불변성 속성도 중요한 역할을 합니다.
오디오 특징 추출
컴퓨터에게 인간이 하는 방식으로 음성을 이해하도록 가르치려고 시도한다고 상상해보십시오. 이것이 Mel-Frequency Cepstral Coefficients (MFCC)가 필요한 이유입니다.
MFCC는 소리를 우리의 귀가 처리하는 방식과 유사하게 분해하는 특수한 오디오 특성입니다. 인간이 가장 민감하게 반응하는 주파수에 초점을 맞추기 때문에 특히 효과적입니다. 소리를 컴퓨터와 인간 청각 모두에게 의미있는 형식으로 번역한다고 생각하십시오.
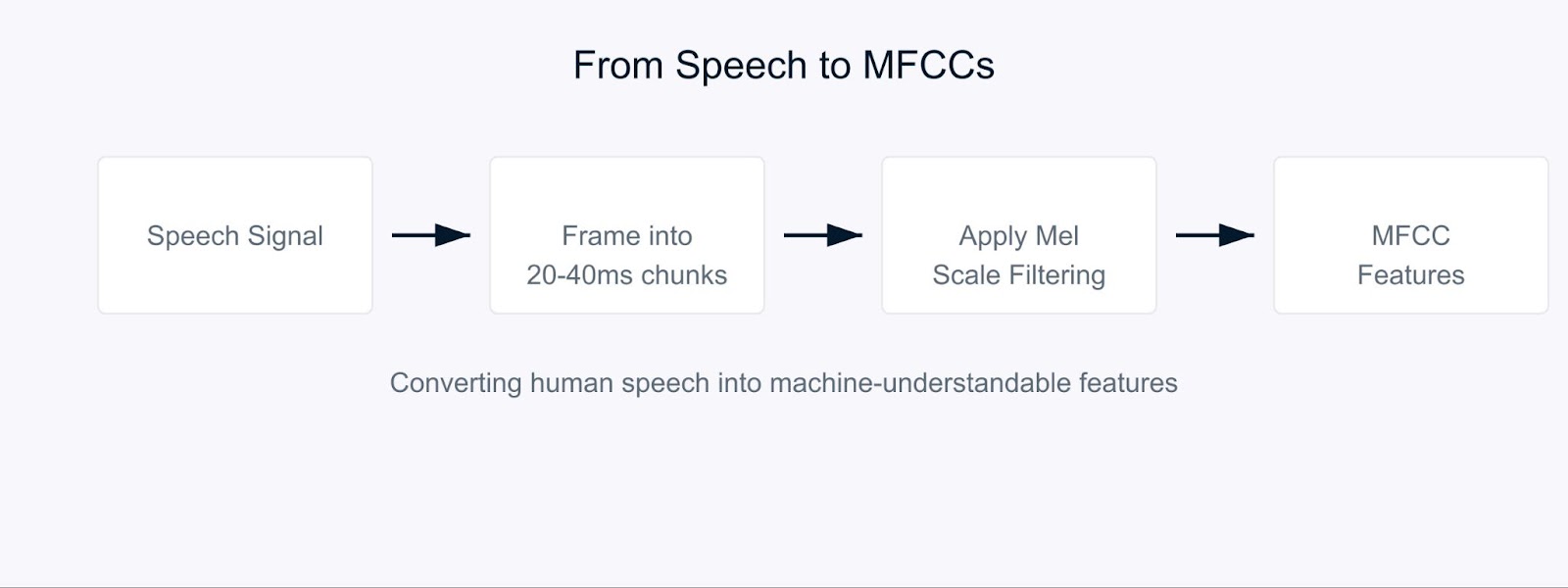
Mel-Frequency Cepstral Coefficients
이 과정은 오디오 신호를 일반적으로 20-40밀리초 길이의 짧은 청크로 분해하는 것부터 시작합니다. 각 청크에 대해 원시 소리파를 주파수 구성 요소로 변환하는 일련의 수학적 변환을 적용합니다. 여기서 재미있는 부분이 시작됩니다. 모든 주파수를 동등하게 처리하는 대신, Mel 스케일이라는 것을 사용합니다.
![]()
이 공식은 복잡해 보일 수 있지만, 단순히 인간이 소리를 인식하는 방식에 맞게 주파수를 매핑하는 것입니다. 우리의 귀는 높은 주파수보다는 낮은 주파수의 차이를 더 잘 감지할 수 있으며, Mel 스케일은 이러한 자연적인 편향을 고려합니다.
음성 인식에서 MFCC는 누가 말하고 있는지와 그들이 무엇을 말하고 있는지를 이해하는 기초 역할을 합니다. 폰의 가상 비서에게 말할 때, MFCC를 사용하여 음성을 처리하는 것이 일반적입니다. 이러한 계수는 각 사람의 음성의 독특한 특징을 포착하여 화자 식별 시스템에 매우 중요합니다.
음성 감정 분석에서 MFCC는 감정을 나타내는 음성의 미묘한 변화를 감지하는 데 도움을 줍니다. 음높이, 음조, 발화 속도의 변화를 포착하여 누군가가 행복한지, 슬픈지, 화난지, 중립적인지를 나타낼 수 있습니다. 예를 들어, 고객 서비스 전화를 분석할 때, MFCC는 고객이 말하는 방식을 통해 고객 만족도 수준을 식별하는 데 도움이 될 수 있습니다. 그들이 말하는 내용뿐만 아니라 어떻게 말하는지에 따라서 말이죠.
시계열 특성 추출
시간 시계열데이터를 다룰 때, 의미 있는 특징을 추출하는 것은 시간이 지남에 따라 발전하는 패턴과 트렌드를 포착하는 데 도움이 됩니다. 원시 시간 시계열 데이터를 유용한 특징으로 변환하는 데 사용되는 몇 가지 주요 기술을 살펴보겠습니다.

시간 시계열 특징 추출 방법
푸리에 변환은 시간 시계열 데이터를 주파수 성분으로 분해하여 숨겨진 주기적 패턴을 드러냅니다. 공식은 다음과 같습니다:
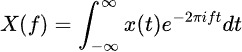
통계적 방법은 빈도 분석을 보완하여 시계열 특성을 포착합니다. 이러한 기법에는 이동 평균, 표준 편차 및 추세 구성 요소가 포함됩니다. 이러한 기술은 재무 예측과 같은 분야에서 특히 강력하며 시장 트렌드와 이상을 식별하는 데 도움이 됩니다.
예를 들어 주식 시장 분석에서, 푸리에 특징과 통계 측정을 결합하면 장기적인 트렌드와 주기적인 패턴을 동시에 확인할 수 있습니다. 비슷하게 산업 환경에서도 이러한 방법들은 시간 경과에 따른 센서 데이터 패턴을 분석하여 장비 이상을 탐지하는 데 도움이 됩니다.
특징 추출을 위한 도구 및 라이브러리
이 기능 추출 방법을 간편하고 효율적으로 구현할 수 있도록 필수 도구 몇 가지를 살펴보겠습니다.
기능 추출을 위한 도구 및 라이브러리
이미지 처리를 위해 OpenCV 및 scikit-image는 다양한 기능 추출 기술을 구현하는 데 포괄적인 도구를 제공합니다. 이러한 라이브러리는 앞서 논의한 SIFT, HOG 등의 알고리즘에 대한 효율적인 구현을 제공합니다. 딥러닝 접근법을 사용할 때는 TensorFlow 및 PyTorch와 같은 프레임워크가 귀중한 도구가 됩니다. 더 알아보려면 OpenCV 자습서를 시작해보세요.
오디오 처리 작업은 LibROSA와 같은 라이브러리를 사용하여 단순화됩니다. 이 라이브러리는 MFCC 및 기타 음향 특성 추출에 뛰어나며, PyAudioAnalysis는 오디오 분석 작업을 위한 고수준 인터페이스를 제공하여 이러한 기능을 확장합니다.
시계열 데이터의 경우, tsfresh와 Featuretools는 특성 추출 프로세스를 자동화합니다. 이러한 라이브러리는 시계열 데이터에서 관련 특성을 자동으로 생성하고 선택하여 특성 엔지니어링보다 모델 개발에 집중하기 쉽도록 도와줍니다.
특성 추출 예시
실전 예제로 지식을 실습해봅시다. 컴퓨터 비전에서 가장 일반적인 응용 프로그램 중 하나인 이미지 특성 추출로 시작해보겠습니다.
OpenCV를 사용한 이미지 특성 추출
먼저 필요한 라이브러리를 가져와봅시다
# 필요한 라이브러리 가져오기 import cv2 import numpy as np import matplotlib.pyplot as plt
이제 관련 특징을 추출하기 위해 이미지를 로드해 보겠습니다. 이 예제에서는 인터넷에서 다운로드한 고질라 이미지를 사용하겠습니다..
# 이미지 로드 image = cv2.imread('godzilla.jpg') # BGR을 RGB로 변환합니다 (OpenCV는 BGR 형식으로 로드) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 원본 이미지 표시 plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
결과:

선 검출을 적용하기 전에 이미지를 전처리해야 합니다. 다음과 같이 수행합니다:
# 이미지를 그레이스케일로 변환 gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 잡음을 줄이기 위해 가우시안 블러 적용 blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
마지막으로 Canny 에지 검출 알고리즘을 적용하고 결과를 시각화해 보겠습니다:
# Canny 엣지 검출을 적용합니다 edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # 결과를 표시합니다 plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
출력:

Canny 엣지 검출기는 이미지에서 중요한 경계와 특징을 식별하는 데 도움이 되며, 이는 추가 분석이나 기계 학습 모델의 입력으로 사용될 수 있습니다.
LibROSA를 사용하여 오디오에서 MFCC 추출하기
오디오 파일을 처리하기 전에 필요한 라이브러리를 설치해야 합니다. Python의 표준 라이브러리에 포함되어 있지 않기 때문에, pip를 사용하여 설치하겠습니다:
# 필요한 라이브러리 설치 # 이 명령을 터미널이나 명령 프롬프트에서 실행하세요 pip install librosa pip install numpy pip install matplotlib
LibROSA는 음악 및 오디오 분석을 위해 설계된 강력한 라이브러리이므로, 필요한 다른 라이브러리와 함께 가져와 시작해봅시다:
# 필요한 라이브러리 가져오기 import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
소리 파일에는 waveform 형식으로 많은 정보가 포함되어 있습니다. 이 데이터를 처리하기 위해 먼저 프로그램으로 불러와야 합니다. LibROSA는 오디오 파일을 분석할 수 있는 형식으로 변환하여 이 작업을 수행하는 데 도움을 줍니다:
# 오디오 파일 불러오기 # 이 예제에서는 10초로 제한된 지속 시간 audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # waveform 표시 plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
결과:
이제 오디오를 불러왔으니 의미 있는 특징을 추출해야 합니다. 우리 귀는 소리를 자연스럽게 다른 주파수 성분으로 분해하며, MFCC는 이 과정을 모방합니다. 이러한 계수를 계산하기 위해 librosa의 특징 추출 함수를 사용합니다:
# MFCC 특징 추출 mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # MFCC 표시 plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Output:
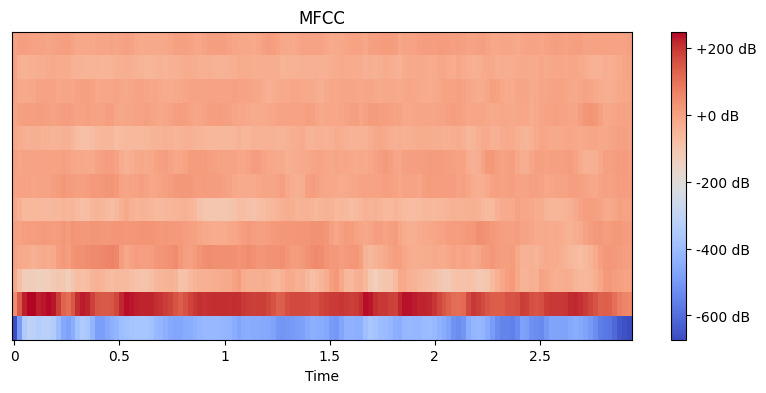
여기서 n_mfcc=13을 설정합니다. 왜냐하면 첫 13개의 계수가 일반적으로 음성 인식과 같은 작업에 도움이 되는 소리의 가장 중요한 측면을 보통 포착하기 때문입니다. 결과 시각화는 이러한 특징이 시간이 지남에 따라 어떻게 변하는지 보여줍니다. 밝은 색상은 더 높은 값으로 나타냅니다.
tsfresh를 사용하여 시계열 데이터에서 특징 추출
먼저 필요한 라이브러리를 설치해 봅시다. 금융 데이터를 가져오기 위해 yfinance와 특징 추출을 위해 tsfresh를 사용할 것입니다:
# 필요한 라이브러리 설치 # 터미널이나 명령 프롬프트에서 다음 명령어를 실행하세요 pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
이제 라이브러리를 가져와 실제 금융 데이터를 얻어봅시다:
# 필요한 라이브러리 가져오기 import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
실제 주식 시장 데이터를 가져와봅시다. 예시로 Apple의 주식 데이터를 사용할 것입니다:
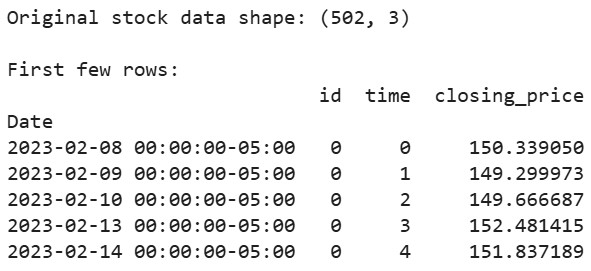
# 지난 2년간의 Apple 주식 데이터 다운로드 aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # tsfresh에서 요구하는 형식으로 데이터 준비 df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # 각 시계열은 ID가 필요합니다 'time': range(len(df)), 'closing_price': df['Close'] # 우리는 종가를 사용할 것입니다 }) # 데이터의 처음 몇 행 표시 print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
결과:
이제 금융 시계열 데이터에서 특징을 추출해봅시다:
# 특징 추출 매개변수 설정 extraction_settings = MinimalFCParameters() # 자동으로 특징 추출 extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # 추출된 특징 표시 print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
출력:

여기서는 MinimalFCParameters()를 사용하여 추출할 기능을 지정합니다. 이를 통해 평균, 분산 및 추세 특성과 같은 기본적인 의미 있는 시계열 특징을 얻을 수 있습니다. 이러한 특징은 데이터의 패턴을 이해하는 데 중요합니다.
특징 추출에서의 도전
특징 추출 작업 시 종종 도전에 직면합니다.
대규모 데이터 세트를 처리할 때 고차원성과 계산 제약이 발생하는 경우가 많습니다. 예를 들어 고해상도 이미지나 긴 오디오 파일에서 특징을 추출하면 상당한 메모리와 처리 능력이 소모될 수 있습니다.
무관한 또는 중복된 특성으로 인한 과적합은 또 다른 일반적인 문제입니다. 너무 많은 특성이 추출되면 모델이 의미 있는 패턴 대신에 잡음을 학습할 수 있습니다. 특히 수천 개의 특성이 생성될 수 있는 이미지 및 오디오 처리에서 이는 특히 흔합니다.
이러한 문제를 극복하기 위해 다음 전략을 고려해보십시오:
- 도메인 지식을 사용하여 관련 있는 특성을 선택
- 차원을 줄이기 위해 특성 선택 방법을 적용
- 데이터 유형에 기반한 적절한 특성 공학 기술을 구현
이러한 도전 과제들은 기능 풍부성과 계산 효율성 사이의 신중한 고려와 균형을 필요로 합니다.
결론
기능 추출은 기계 학습에서 원시 데이터를 의미 있는 표현으로 변환하는 기본적인 기술입니다. OpenCV, LibROSA 및 tsfresh와 함께 실제 예제를 통해 다양한 유형의 데이터에서 기능을 추출하는 방법을 살펴보았습니다. 이러한 기술과 그 도전에 대한 이해를 통해 효과적인 기계 학습 모델을 구축할 수 있습니다.
더 깊이 파고들 준비가 되셨나요? 다음 자료를 확인해보세요:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning