













L’estrazione delle caratteristiche nel machine learning trasforma i dati grezzi in un insieme di caratteristiche significative, catturando informazioni essenziali e riducendo la ridondanza. Può coinvolgere tecniche di riduzione della dimensionalità e metodi che creano nuove caratteristiche a partire dai dati esistenti.
Immagina di cercare di identificare frutti in un mercato. Anche se potresti considerare innumerevoli attributi (peso, colore, consistenza, forma, odore, ecc.), potresti renderti conto che solo alcune caratteristiche chiave come il colore e la dimensione sono sufficienti per distinguere tra mele e arance. Questo è esattamente ciò che fa l’estrazione delle caratteristiche. Ti aiuta a concentrarti sulle caratteristiche più informative dei tuoi dati.
Quando si esegue l’estrazione delle caratteristiche, i dati originali vengono trasformati matematicamente in un nuovo insieme di caratteristiche. Queste nuove caratteristiche sono progettate per catturare gli aspetti più importanti dei dati mantenendo potenzialmente ridotta la loro complessità. Le caratteristiche estratte rappresentano spesso schemi o strutture sottostanti che potrebbero non essere immediatamente evidenti nei dati originali.
Estrazione delle Caratteristiche
Nelle prossime sezioni, esploreremo perché l’estrazione delle caratteristiche è così importante nell’apprendimento automatico e esamineremo vari metodi per estrarre le caratteristiche da diversi tipi di dati insieme al relativo codice. Se desideri alcuni esempi pratici, dai un’occhiata al nostro Corso di Riduzione della Dimensionalità in Python, che ha un capitolo dedicato all’estrazione delle caratteristiche.
Perché è importante l’Estrazione delle Caratteristiche nell’Apprendimento Automatico?
L’estrazione delle caratteristiche gioca un ruolo importante nel machine learning. Può fare la differenza tra un modello che fallisce e uno che ha successo. Vediamo perché questo è così fondamentale per costruire modelli di machine learning efficaci.
Potenziare l’accuratezza e l’efficienza del modello
Quando si lavora con dati grezzi, il machine learning i modelli spesso faticano a distinguere tra schemi significativi e rumore. L’estrazione delle caratteristiche funge da fase di preprocessamento dei dati che può migliorare significativamente quanto bene i tuoi modelli apprendono e si comportano.
Performance del modello rispetto al tempo di addestramento
Ad esempio, quando un modello raggiunge un’accuratezza dell’85% con dati grezzi, lo stesso modello potrebbe raggiungere un’accuratezza del 95% quando addestrato su caratteristiche estratte con cura. Questo miglioramento non deriva dal cambiamento del modello ma dal fornirgli dati di input di migliore qualità da apprendere.
Gestione di set di dati ad alta dimensionalità
I set di dati moderni spesso presentano centinaia o migliaia di caratteristiche. Ciò comporta diversi sfide alle quali l’estrazione delle caratteristiche aiuta a far fronte.
- La maledizione della dimensionalità: Man mano che aumenta il numero di caratteristiche, i dati diventano sempre più sparsi nello spazio delle caratteristiche. Questo rende più difficile per i modelli individuare schemi significativi. L’estrazione delle caratteristiche crea una rappresentazione più compatta che preserva le relazioni importanti riducendo al contempo la dimensionalità.
- Utilizzo elevato della memoria: I dati ad alta dimensionalità richiedono più spazio di archiviazione e memoria durante l’elaborazione. Estraendo solo le caratteristiche più rilevanti, possiamo ridurre significativamente l’impronta di memoria dei nostri set di dati mantenendone il valore informativo.
- Visualizzazione dei dati:È impossibile visualizzare direttamente dati con più di tre dimensioni. L’estrazione delle caratteristiche può ridurre la dimensionalità a due o tre caratteristiche, rendendo possibile tracciare e comprendere la struttura dei dati visivamente.
L’estrazione delle caratteristiche affronta queste sfide riducendo la dimensionalità pur preservando informazioni essenziali. Questa riduzione trasforma dati estesi e ad alta dimensionalità in una forma più compatta e gestibile, portando a un miglioramento delle prestazioni del modello.
Reduzione della complessità computazionale e prevenzione dell’overfitting
L’estrazione delle caratteristiche fornisce due benefici critici per i modelli di machine learning:
- Minori requisiti computazionali
- Meno funzionalità significano tempi di addestramento più rapidi
- Ridotto utilizzo della memoria durante il deployment del modello
- Generazione di previsioni più efficiente
- Migliore generalizzazione
- Spazi delle funzionalità più semplici aiutano a prevenire l’overfitting
- I modelli apprendono schemi più robusti
- Miglioramento delle prestazioni su dati nuovi e non visti
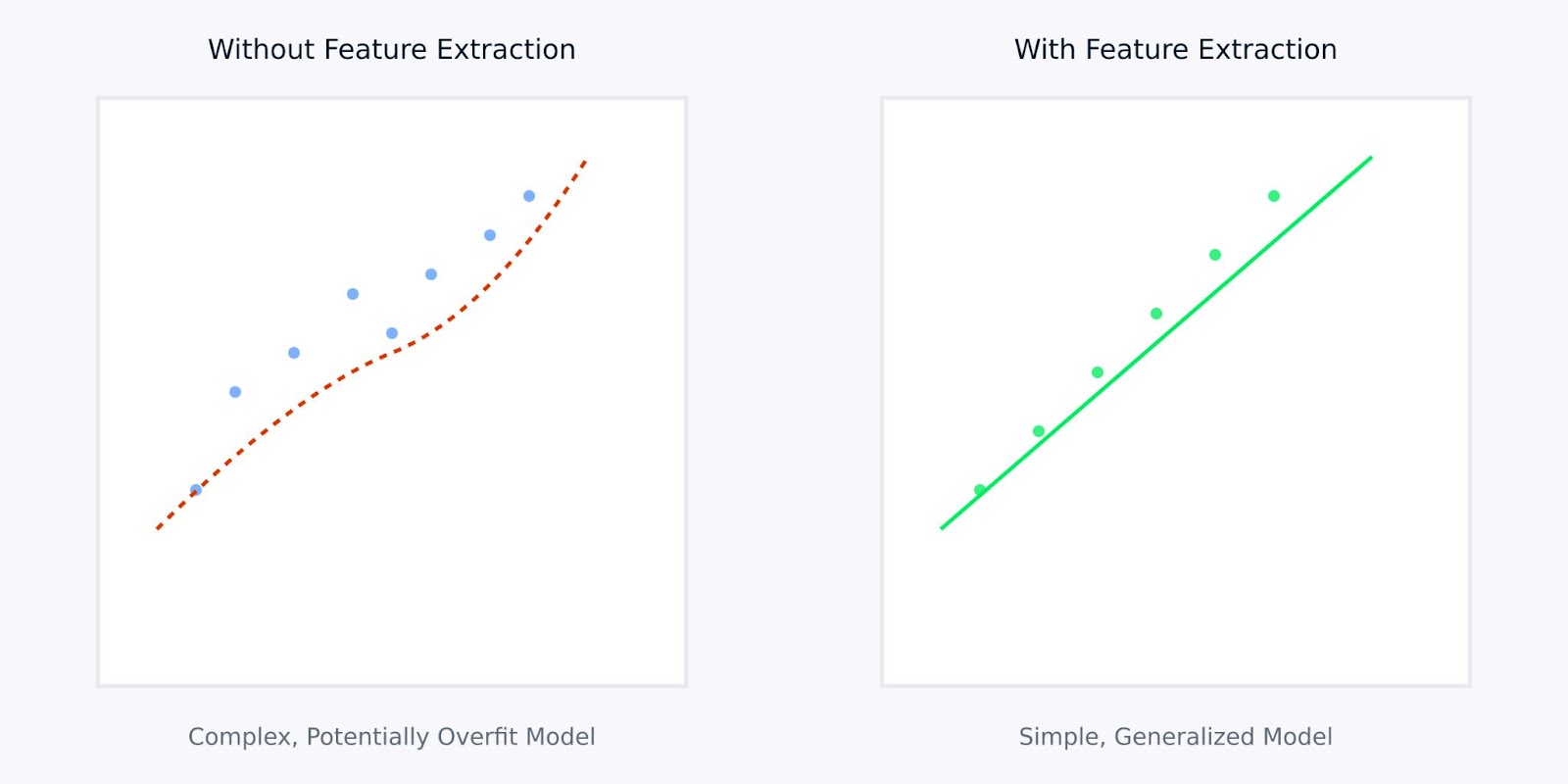
Estrazione delle caratteristiche rispetto a senza estrazione delle caratteristiche
La visualizzazione sopra illustra come l’estrazione delle caratteristiche possa portare a modelli più semplici e robusti. Il grafico a sinistra mostra un modello complesso che cerca di adattarsi a dati rumorosi e ad alta dimensionalità, mentre il grafico a destra mostra come l’estrazione delle caratteristiche possa rivelare un modello più chiaro e generalizzabile.
Lavorare con le caratteristiche estratte anziché con i dati grezzi è come fornire al tuo modello una versione chiara e distillata delle informazioni di cui ha bisogno per imparare. Ciò non solo rende il processo di apprendimento più efficiente, ma porta anche a modelli che sono più inclini a performare bene nelle applicazioni reali.
Successivamente, vediamo diversi metodi di estrazione delle caratteristiche.
Metodi di estrazione delle caratteristiche
I metodi di estrazione delle caratteristiche possono essere ampiamente suddivisi in due approcci principali: ingegnerizzazione manuale delle caratteristiche ed estrazione automatizzata delle caratteristiche. Esaminiamo entrambi questi metodi per capire come aiutano a trasformare i dati grezzi in caratteristiche significative.
Ingegnerizzazione manuale delle caratteristiche
L’ingegnerizzazione manuale delle caratteristiche comporta l’uso di competenze specifiche del dominio per identificare e creare caratteristiche rilevanti dai dati grezzi. Questo approccio pratico si basa sulla nostra comprensione del problema e dei dati per creare caratteristiche significative.
In elaborazione delle immagini, l’ingegneria delle caratteristiche manuale potrebbe includere tecniche come il rilevamento dei bordi per identificare i confini degli oggetti, istogrammi dei colori per catturare la distribuzione dei colori, analisi delle texture per quantificare i modelli e descrittori di forma per caratterizzare la geometria degli oggetti.
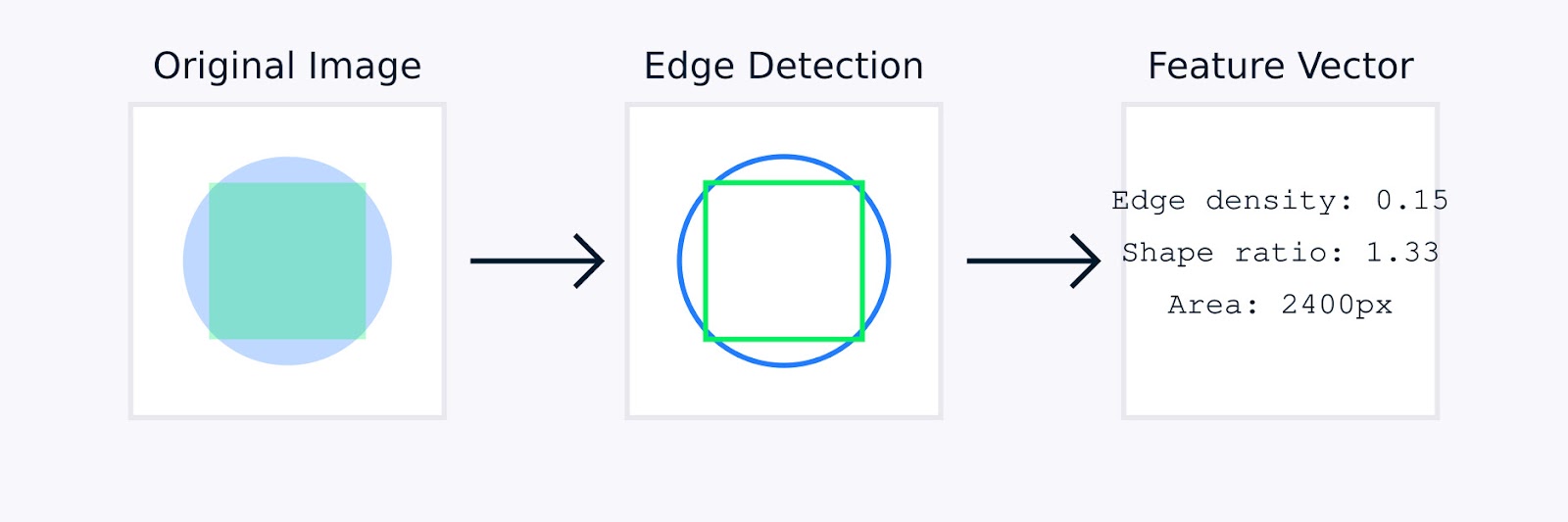
Estrazione delle Caratteristiche delle Immagini
Per i dati tabulari, l’ingegneria delle caratteristiche manuale implica la creazione di termini di interazione tra caratteristiche esistenti, la trasformazione delle variabili utilizzando funzioni logaritmiche o polinomiali, l’aggregazione dei punti dati in statistiche significative e la codifica delle variabili categoriali.
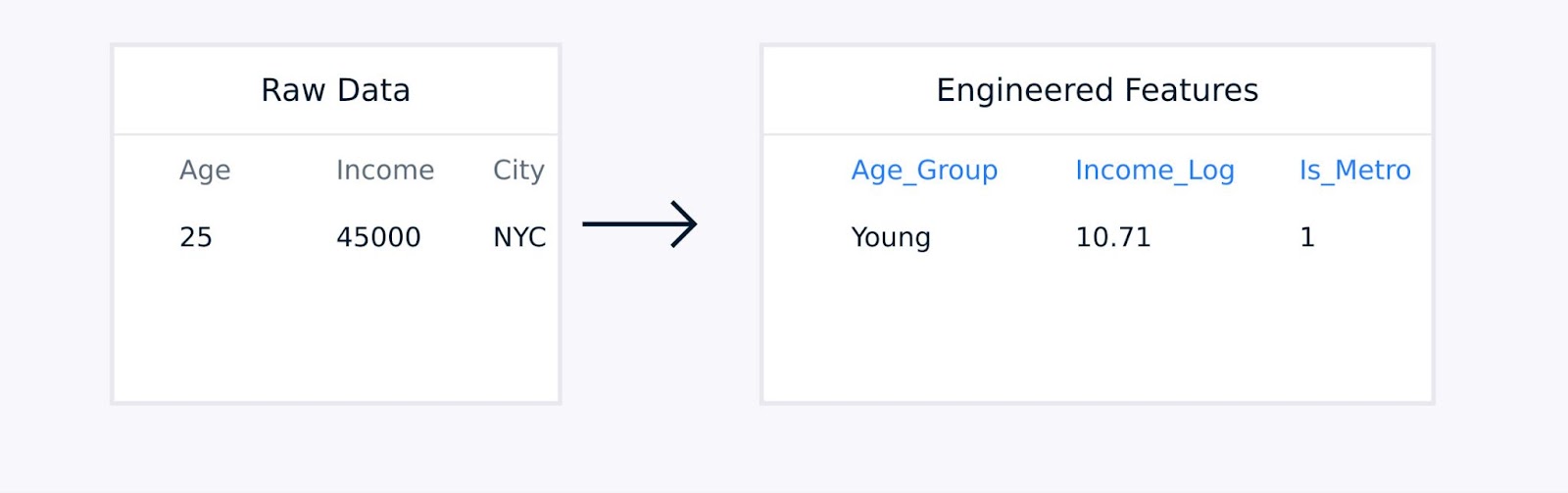
Estrazione delle caratteristiche dai dati tabulari
Queste tecniche, guidate da competenze di dominio, migliorano la qualità della rappresentazione dei dati e possono migliorare significativamente le prestazioni del modello.
Estrazione automatizzata delle caratteristiche
L’estrazione automatizzata delle caratteristiche utilizza algoritmi per scoprire e creare caratteristiche senza una guida esplicita da parte dell’uomo. Questi metodi sono particolarmente utili quando si tratta di dataset complessi in cui l’ingegneria delle caratteristiche manuale potrebbe essere poco pratica o inefficiente.
Le comuni approcci automatizzati includono:
Analisi delle Componenti Principali (PCA): Trasforma i dati in un insieme di componenti non correlate, con ciascuna componente che cattura la massima varianza rimanente. Questo approccio è particolarmente utile per riduzione dimensionale, in quanto preserva le informazioni essenziali all’interno dei dati semplificando al contempo la loro struttura.
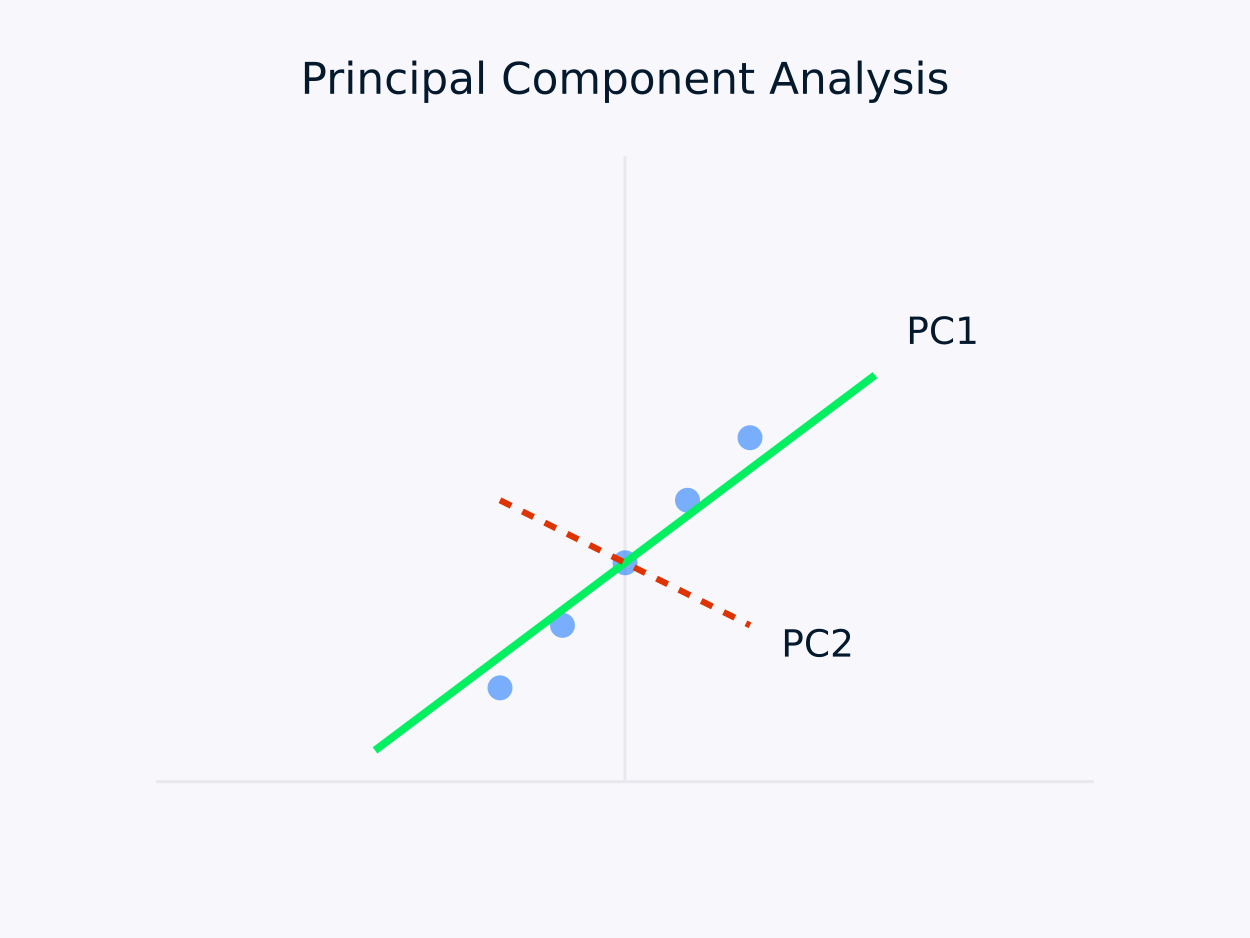
Analisi delle Componenti Principali (PCA)
Autoencoder: Queste sono reti neurali che apprendono rappresentazioni compressate dei dati, catturando relazioni non lineari. Sono particolarmente efficaci per i dataset ad alta dimensionalità, dove i metodi lineari tradizionali potrebbero non essere sufficienti.
Sono emersi vari strumenti e librerie per semplificare i compiti di ingegneria delle caratteristiche. Ad esempio, il modulo di decomposizione di Scikit-learn offre una serie di metodi per la riduzione della dimensionalità, e PyCaret fornisce capacità di selezione automatica delle caratteristiche.
Sia gli approcci manuali che automatizzati hanno i loro punti di forza. Vediamo i punti di forza di ciascun approccio.
|
Ingegneria Manuale |
Estrazione Automatica |
|
Integrazione della conoscenza di dominio |
Scalabilità |
|
Caratteristiche interpretabili |
Gestisce modelli complessi |
|
Controllo dettagliato |
Riduce il bias umano |
|
Personalizzato per esigenze specifiche |
Scopre relazioni nascoste |
La scelta tra metodi manuali e automatizzati dipende spesso da fattori come la complessità del dataset, la disponibilità di competenze di dominio, requisiti di interpretabilità, risorse computazionali e vincoli temporali.
Per dataset altamente complessi o quando il tempo e le risorse sono limitati, i metodi automatizzati possono generare rapidamente funzionalità utili. Al contrario, i metodi manuali possono essere preferibili quando esiste esperienza nel settore e l’interpretabilità è una priorità, consentendo la creazione di funzionalità su misura che si allineano strettamente con il problema in questione.
Nella pratica, molti progetti di successo di apprendimento automatico combinano entrambi gli approcci, utilizzando l’esperienza nel settore per guidare l’ingegneria delle funzionalità e sfruttando i metodi automatizzati per scoprire modelli aggiuntivi che potrebbero non essere immediatamente evidenti agli esperti umani.
Nella sezione successiva, esamineremo diverse tecniche di estrazione delle caratteristiche in vari settori.
Tecniche di Estrazione delle Caratteristiche
Ogni tipo di dato richiede tecniche specifiche di estrazione delle caratteristiche ottimizzate per le sue caratteristiche uniche. Vediamo le tecniche più comuni per tipi diversi di dati.

Tecniche di Estrazione delle Caratteristiche
Estrazione delle caratteristiche dell’immagine
L’estrazione delle caratteristiche dell’immagine trasforma i dati grezzi dei pixel in rappresentazioni significative che catturano informazioni visive essenziali. Esistono tre principali categorie di tecniche utilizzate nella visione artificiale moderna. Esse sono i metodi tradizionali, i metodi basati sull’apprendimento profondo e i metodi statistici.

Metodi di Estrazione delle Caratteristiche dell’Immagine
Esaminiamo ciascuno dei metodi.
Metodi tradizionali di visione artificiale
Scale-Invariant Feature Transform (SIFT) è un metodo robusto che rileva caratteristiche locali distintive nelle immagini. Funziona identificando punti chiave e generando descrittori che sono:
- Invarianti rispetto alla scala e alla rotazione dell’immagine
- Parzialmente invarianti ai cambiamenti di illuminazione
- Robusti alle distorsioni geometriche locali
L’algoritmo SIFT elabora le immagini attraverso diverse fasi. Inizia con la rilevazione degli estremi nello spazio delle scale per identificare punti chiave potenziali che sono invarianti rispetto alla scala. Successivamente, la localizzazione dei punti chiave affina questi candidati individuando le loro posizioni precise e scartando i punti instabili.
Successivamente, l’assegnazione dell’orientamento determina un’orientazione coerente per ogni punto chiave, garantendo l’invarianza alla rotazione. Infine, la generazione del descrittore del punto chiave crea descrittori distintivi basati sui gradienti locali dell’immagine, facilitando un abbinamento robusto tra le immagini.
Un altro metodo è l’Istogramma dei Gradienti Orientati (HOG). Cattura informazioni sulla forma locale analizzando i modelli di gradiente in un’immagine. Il processo inizia calcolando i gradienti in tutta l’immagine per evidenziare i dettagli dei bordi.
L’immagine viene quindi divisa in piccole celle, e per ogni cella viene creato un istogramma delle orientazioni del gradiente per riassumere la struttura locale. Infine, questi istogrammi vengono normalizzati su blocchi più grandi per garantire robustezza contro variazioni nell’illuminazione e nel contrasto, risultando in un robusto descrittore delle caratteristiche per compiti come rilevamento e riconoscimento degli oggetti.
Metodi di apprendimento profondo
Le reti neurali convoluzionali (CNN) hanno cambiato il modo in cui facciamo l’estrazione delle caratteristiche imparando automaticamente rappresentazioni gerarchiche.

Estrazione delle caratteristiche con CNN
Le CNN imparano le caratteristiche attraverso la loro struttura gerarchica. Nelle prime fasi, rilevano elementi visivi di base come bordi e colori. Le fasi intermedie combinano poi questi elementi per riconoscere modelli e forme, mentre le fasi più profonde catturano oggetti complessi e consentono la comprensione della scena.
Il trasferimento di apprendimento ci permette di utilizzare queste caratteristiche pre-apprese da modelli addestrati su grandi set di dati, rendendoli particolarmente preziosi quando si lavora con dati limitati.
Metodi statistici
I metodi statistici estraggono sia modelli globali che locali dalle immagini, facilitando un’analisi e interpretazione robuste delle immagini.
Ad esempio, istogrammi di colore rappresentano la distribuzione dei colori all’interno di un’immagine e forniscono caratteristiche invarianti rispetto a rotazione e scala, rendendoli particolarmente utili per compiti come la classificazione e il recupero delle immagini.
L’analisi della texture cattura pattern ripetuti e caratteristiche superficiali utilizzando tecniche come le Matrici di Co-occorrenza dei Livelli di Grigio (GLCM), che sono efficaci per applicazioni tra cui il riconoscimento dei materiali e la classificazione delle scene.
Inoltre, il rilevamento dei bordi identifica i confini e i cambiamenti significativi di intensità attraverso metodi come gli operatori Sobel, Canny e Laplacian, svolgendo un ruolo cruciale nella rilevazione degli oggetti e nell’analisi delle forme.
La scelta del metodo di estrazione delle caratteristiche dipende da diversi fattori. Dovrebbe essere allineata ai requisiti specifici del tuo compito, considerare le risorse computazionali disponibili e tener conto della necessità di interpretabilità.
Inoltre, le caratteristiche del tuo dataset—come la dimensione, i livelli di rumore e la complessità—giocano un ruolo cruciale, così come le proprietà di invarianza richieste come scala, rotazione e illuminazione.
Estrazione delle caratteristiche audio
Immagina di cercare di insegnare a un computer a comprendere il linguaggio parlato come fanno gli esseri umani. Ecco dove entrano in gioco i coefficienti cepstrali di Mel-Frequency (MFCC).
Gli MFCC sono particolari caratteristiche audio che scompongono il suono in modo simile a come lo elaborano i nostri orecchi. Sono particolarmente efficaci perché si concentrano sulle frequenze alle quali gli esseri umani sono più sensibili. Pensaci come a una traduzione del suono in un formato che sia significativo sia per i computer che per l’udito umano.
Coefficienti Cepstrali di Mel-Frequency
Il processo inizia scomponendo il segnale audio in brevi frammenti, tipicamente lunghi 20-40 millisecondi. Per ciascun frammento, applichiamo una serie di trasformazioni matematiche che convertono le onde sonore grezze in componenti di frequenza. E qui diventa interessante. Invece di trattare tutte le frequenze allo stesso modo, utilizziamo qualcosa chiamato scala Mel.
![]()
Questa formula potrebbe sembrare complessa, ma mappa semplicemente le frequenze per adattarsi a come gli esseri umani percepiscono il suono. Le nostre orecchie sono migliori a rilevare differenze nelle frequenze più basse rispetto a quelle più alte, e la scala Mel tiene conto di questo bias naturale.
Nella riconoscimento vocale, gli MFCC servono come base per capire chi sta parlando e cosa stanno dicendo. Quando parli con l’assistente virtuale del tuo telefono, è probabile che stia usando gli MFCC per elaborare la tua voce. Questi coefficienti aiutano a catturare le caratteristiche uniche della voce di ogni persona, rendendoli inestimabili per i sistemi di identificazione degli oratori.
Per l’analisi del sentiment nel parlato, gli MFCC aiutano a rilevare sottili variazioni nella voce che indicano emozioni. Possono catturare cambiamenti nel tono, nel timbro e nella velocità di parola che potrebbero indicare se qualcuno è felice, triste, arrabbiato o neutro. Ad esempio, nell’analisi delle chiamate al servizio clienti, gli MFCC possono aiutare a identificare i livelli di soddisfazione dei clienti in base a come parlano, non solo a cosa dicono.
Estrazione delle caratteristiche delle serie temporali
Quando si lavora con serie temporali dati, estrarre caratteristiche significative ci aiuta a catturare modelli e tendenze che si evolvono nel tempo. Vediamo alcune tecniche chiave utilizzate per trasformare i dati grezzi delle serie temporali in caratteristiche utili.

Metodi di Estrazione delle Caratteristiche delle Serie Temporali
La Trasformata di Fourier scompone i dati delle serie temporali nei loro componenti di frequenza, rivelando pattern periodici nascosti. La formula è:
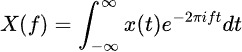
I metodi statistici completano l’analisi delle frequenze catturando le caratteristiche temporali. Le caratteristiche comuni includono medie mobili, deviazioni standard e componenti di tendenza. Queste tecniche sono particolarmente potenti in previsione finanziaria, dove aiutano a identificare le tendenze di mercato e le anomalie.
Ad esempio, nell’analisi del mercato azionario, combinare le caratteristiche di Fourier con misure statistiche può rivelare sia tendenze a lungo termine che modelli ciclici. Allo stesso modo, in contesti industriali, questi metodi aiutano a rilevare anomalie negli impianti analizzando i modelli dei dati dei sensori nel tempo.
Strumenti e librerie per l’estrazione delle caratteristiche
Esaminiamo alcuni strumenti essenziali che rendono l’implementazione di questi metodi di estrazione delle caratteristiche semplice ed efficiente.
Strumenti e Librerie per l’Estrazione delle Caratteristiche
Per l’elaborazione delle immagini, OpenCV e scikit-image forniscono strumenti completi per implementare varie tecniche di estrazione delle caratteristiche. Queste librerie offrono implementazioni efficienti di SIFT, HOG e altri algoritmi di cui abbiamo discusso in precedenza. Quando si lavora con approcci di apprendimento profondo, i framework come TensorFlow e PyTorch diventano inestimabili. Puoi iniziare con il nostro tutorial su OpenCV per saperne di più.
Le attività di elaborazione audio sono semplificate con librerie come LibROSA, che eccelle nell’estrazione di MFCC e altre caratteristiche acustiche. PyAudioAnalysis estende queste capacità con interfacce di alto livello per compiti di analisi audio.
Per i dati in serie temporale, tsfresh e Featuretools automatizzano il processo di estrazione delle caratteristiche. Queste librerie possono generare e selezionare automaticamente le caratteristiche rilevanti dai tuoi dati temporali, rendendo più semplice concentrarsi sullo sviluppo del modello piuttosto che sull’ingegneria delle caratteristiche.
Esempio di Estrazione delle Caratteristiche
Mettiamo in pratica le nostre conoscenze con alcuni esempi pratici. Inizieremo con l’estrazione delle caratteristiche dell’immagine, una delle applicazioni più comuni nella computer vision.
Estrazione delle caratteristiche dell’immagine utilizzando OpenCV
Prima, importiamo le librerie necessarie
# Importa le librerie richieste import cv2 import numpy as np import matplotlib.pyplot as plt
Ora, carichiamo un’immagine per estrarre caratteristiche rilevanti. Per questo esempio, useremo un’immagine di Godzilla scaricata da Internet.
# Carica l'immagine image = cv2.imread('godzilla.jpg') # Converti BGR in RGB (OpenCV carica in formato BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Mostra l'immagine originale plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
Output:

Prima di applicare il rilevamento dei bordi, dobbiamo preprocessare la nostra immagine. Lo facciamo come segue:
# Converti l'immagine in scala di grigi gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Applica il filtro gaussiano per ridurre il rumore blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
Infine, applichiamo l’algoritmo di rilevamento dei bordi di Canny e visualizziamo i risultati:
# Applica il rilevamento dei bordi di Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # Mostra i risultati plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
Output:

Il rilevatore di bordi di Canny ci aiuta a identificare importanti confini e caratteristiche nella nostra immagine, che possono essere utilizzati per ulteriori analisi o come input per modelli di apprendimento automatico.
Estrazione degli MFCC dall’audio utilizzando LibROSA
Prima di poter iniziare a elaborare i file audio, è necessario installare le librerie richieste. Poiché LibROSA non è inclusa nella libreria standard di Python, utilizzeremo pip per installarla:
# Installa le librerie richieste # Esegui questi comandi nel tuo terminale o prompt dei comandi pip install librosa pip install numpy pip install matplotlib
LibROSA è una potente libreria progettata per l’analisi musicale e audio, quindi iniziamo importandola insieme ad altre librerie necessarie:
# Importa le librerie necessarie import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
I file audio contengono molte informazioni in formato onda. Per lavorare con questi dati, dobbiamo prima caricarli nel nostro programma. LibROSA ci aiuta a farlo convertendo il file audio in un formato che possiamo analizzare:
# Carica il file audio # La durata è limitata a 10 secondi per questo esempio audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # Mostra l'onda sonora plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
Output:
Ora che abbiamo caricato il nostro audio, dobbiamo estrarre caratteristiche significative da esso. Le nostre orecchie suddividono naturalmente il suono in diversi componenti di frequenza, e l’MFCC imita questo processo. Utilizziamo la funzione di estrazione delle caratteristiche di librosa per calcolare questi coefficienti:
# Estrai le caratteristiche MFCC mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # Mostra l'MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Output:
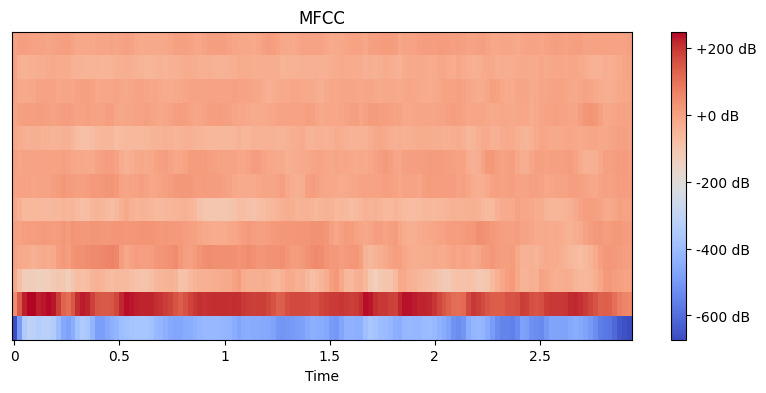
Qui, impostiamo n_mfcc=13 perché i primi 13 coefficienti catturano tipicamente gli aspetti più importanti del suono che aiutano in compiti come il riconoscimento vocale. La visualizzazione risultante mostra come queste caratteristiche cambiano nel tempo, dove i colori più luminosi rappresentano valori più alti.
Estrazione delle caratteristiche dai dati di serie temporali con tsfresh
Prima di tutto, installiamo le librerie necessarie. Utilizzeremo il yfinance per ottenere dati finanziari, insieme a tsfresh per l’estrazione delle caratteristiche:
# Installa le librerie necessarie # Esegui questi comandi nel terminale o prompt dei comandi pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
Ora importiamo le nostre librerie e recuperiamo alcuni dati finanziari reali:
# Importa le librerie richieste import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
Prendiamo alcuni dati reali del mercato azionario. Utilizzeremo i dati delle azioni di Apple come esempio:
# Scarica i dati delle azioni di Apple degli ultimi 2 anni aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # Prepara i dati nel formato richiesto da tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # Ogni serie temporale ha bisogno di un ID 'time': range(len(df)), 'closing_price': df['Close'] # Utilizzeremo i prezzi di chiusura }) # Mostra le prime righe dei nostri dati print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
Output:
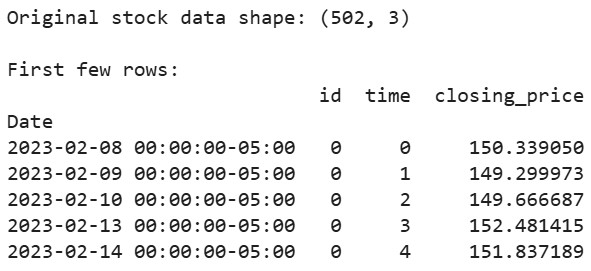
Ora estraiamo le caratteristiche dai nostri dati temporali finanziari:
# Imposta i parametri per l'estrazione delle caratteristiche extraction_settings = MinimalFCParameters() # Estrai automaticamente le caratteristiche extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # Mostra le caratteristiche estratte print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
Output:

Qui, utilizziamo MinimalFCParameters() per specificare quali caratteristiche estrarre. Questo ci fornisce un insieme di base di caratteristiche significative delle serie temporali come media, varianza e caratteristiche di tendenza, che sono essenziali per comprendere i modelli nei nostri dati.
Sfide nell’estrazione delle caratteristiche
Quando si lavora con l’estrazione delle caratteristiche, ci si imbatte spesso in sfide.
Alta dimensionalità e vincoli computazionali sorgono spesso quando si lavora con grandi set di dati. Ad esempio, l’estrazione di caratteristiche da immagini ad alta risoluzione o file audio lunghi può consumare una quantità significativa di memoria e potenza di elaborazione.
Il sovradattamento dovuto a caratteristiche irrilevanti o ridondanti è un’altra sfida comune. Quando vengono estratte troppe caratteristiche, i modelli potrebbero apprendere rumore invece di schemi significativi. Questo è particolarmente comune nell’elaborazione di immagini e audio, dove possono essere generate migliaia di caratteristiche.
Per superare queste sfide, considera queste strategie:
- Utilizza la conoscenza del dominio per selezionare caratteristiche rilevanti
- Applica metodi di selezione delle caratteristiche per ridurre la dimensionalità
- Implementa tecniche di ingegneria delle caratteristiche appropriate in base al tuo tipo di dati
Queste sfide richiedono un’attenta considerazione e un equilibrio tra ricchezza delle funzionalità ed efficienza computazionale.
Conclusione
L’estrazione delle caratteristiche è una competenza fondamentale nell’apprendimento automatico che trasforma i dati grezzi in rappresentazioni significative. Attraverso i nostri esempi pratici con OpenCV, LibROSA e tsfresh, abbiamo visto come estrarre caratteristiche da diversi tipi di dati. Comprendendo queste tecniche e le loro sfide, possiamo costruire modelli di apprendimento automatico efficaci.
Pronto ad approfondire? Dai un’occhiata a queste risorse:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning