













חילוץ תכונות בלמידת מכונה ממיר נתונים גולמיים לסט של תכונות משמעותיות, שלופות מידע חיוני ומפחיתות חסימות. זה עשוי לכלול טכניקות להפחתת ממדיות ושיטות שיוצרות תכונות חדשות מהנתונים הקיימים.
תדמיינו שאתם מנסים לזהות פירות בשוק. במקום לשקול מאפיינים לא סופיים (משקל, צבע, מרקם, צורה, ריח וכו '), תכולו שרק מספר קטן של תכונות מרכזיות כמו צבע וגודל מספיקים כדי להבחין בין תפוחים ותפוחים ירוקים. זה בדיוק מה שעשה חילוץ תכונות. זה עוזר לך להתמקד בתכונות המידעיות ביותר של הנתונים שלך.
בעת ביצוע חילוץ תכונות, הנתונים המקוריים מומרים באופן מתמטי לסט חדש של תכונות. התכונות החדשות הללו מיועדות ללכוד את הנקודות החשובות ביותר של הנתונים תוך שיכולות להפחית את מורכבותו. התכונות המחולצות מייצגות לעתים תתי תבניות או מבנים האולי לא יהיו מיידיים בנתונים המקוריים.
ייבוט תכונות
במקטעים הבאים, נחקור למה ייבוט תכונות כה חשוב בלמידת מכונה ונתמקד בשיטות שונות להפקת תכונות מסוגי נתונים שונים יחד עם הקודים שלהם. אם ברצונך בדוגמאות מעשיות, כדאי לבדוק את ה-קורס להפחתת ממדים בפייתון שלנו, שכולל פרק מוקדש לייבוט תכונות.
למה ייבוט תכונות חשוב בלמידת מכונה?
חילוץ תכונות משחק תפקיד חשוב בלמידת מכונה. זה עשוי לעשות את ההבדל בין מודל שנכשל ואחד שמצליח. בואו נראה למה זה נחוץ כל כך לבניית מודלים יעילים בלמידת מכונה.
שיפור הדיוק והיעילות של המודל
כאשר עובדים עם נתונים גולמיים, למידת מכונה נתונים לעתים קרובות נתקלים בקושי להבחין בין תבניות משמעותיות לרעש. חילוץ תכונות משמש כשלב עיבוד נתונים שיכול לשפר באופן משמעותי איך המודלים שלך לומדים ובוצעים.
ביצוע המודל לעומת זמן האימון
לדוגמה, כאשר דגם מגיע לדיוק של 85% עם נתונים גולמיים, יתכן ואותו דגם יגיע לדיוק של 95% כאשר הוא מאומן על ייחודיות מאוחסנות בזהירות. שיפור זה אינו בא משינוי בדגם אלא מן הנתונים הטובים יותר שהועברו לו ומהם יכול ללמוד.
ניהול סטים גבוהים ממדים
סטים מודרניים מגיעים לעיתים עם מאות או אלפי ייחודיות. זה מביא מספר אתגרים אשר ייחודיות מאוחסנות עוזרות לטפל בהם.
- קללת הממדיות: ככל שמספר המאפיינים גדל, הנתונים הופכים יותר רזים במרחב המאפיינים. זה עשוי להקשות על המודלים לזהות תבניות משמעותיות. חילוץ מאפיינים יוצר תיאור יותר צפה ששומר על קשרים חשובים ובו זמנית מפחית את הממדיות.
- שימוש גבוה בזיכרון: נתונים בממדיות גבוהה דורשים יותר מקום אחסון וזיכרון בעת העיבוד. על ידי חילוץ רק של המאפיינים הרלוונטיים ביותר, אנו יכולים להפחית באופן משמעותי את גודל הזיכרון שמוקצה לנתונים שלנו תוך שמירה על ערכם המידעי.
- ויזואליזצית נתונים: אי אפשר לוויזואליזציה של נתונים עם יותר משלוש ממדים ישירות. חילוץ תכונות יכול להפחית את הממדיות לשתי או שלוש תכונות, מה שהופך אפשרי לערוך ולהבין את מבנה הנתונים ויזואלית.
חילוץ תכונות פותר את האתגרים הללו על ידי הפחתת הממדיות תוך שמירה על מידע חיוני. ההפחתה הזו ממירה נתונים מעטרים עם ממדיות גבוהות לצורה יותר קומפקטית וניתנת לניהול, מה שמביא לשיפור בביצועי המודל.
הפחתת הרכיבה החישובית ומניעת התאמה מופרזת
חילוץ תכונות מספק שני תועלות עיקריות למודלי למידת מכונה:
- דרישות חישוב נמוכות יותר
- פחות תכונות מביאות לזמני האימון המהירים יותר
- שימוש זכרון נמוך בזמן הפיתוח של המודל
- ייצור תחזיות יעיל יותר
- גנרליזציה טובה יותר
- מרחבי תכונות פשוטים עוזרים למנוע על-הפסקה
- המודלים לומדים רגעים יותר חזקים
- ביצועים משופרים על נתונים חדשים ולא נראים קודם
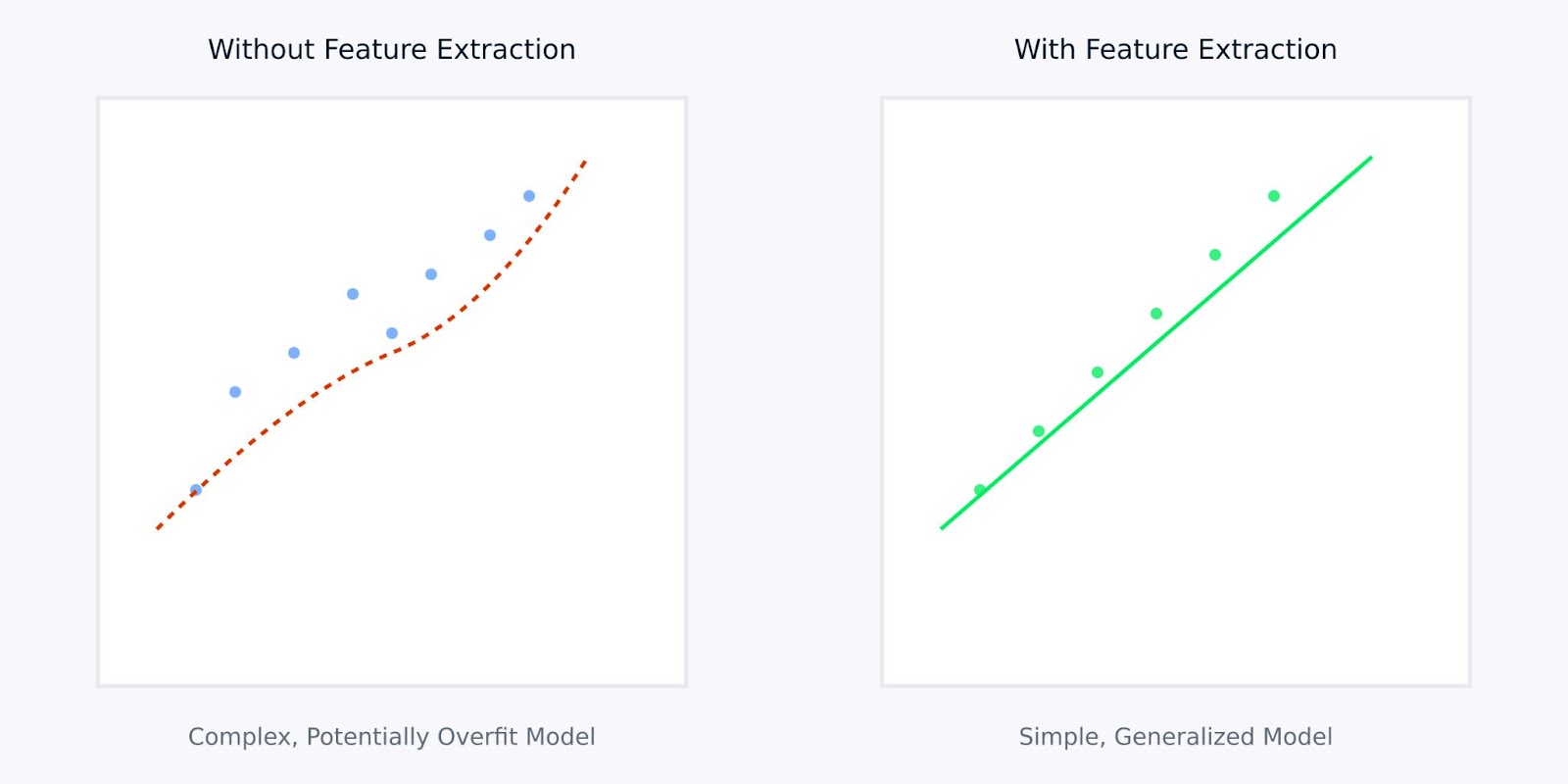
חילוץ תכונות לעומת בלעדי חילוץ תכונות
הויזואליזציה לעיל ממחישה כיצד חילוץ תכונות עשוי להוביל למודלים פשוטים ועמידים יותר. הגרף השמאלי מראה דוגמה מורכבת שמנסה להתאים לנתונים רעשניים בממדים גבוהים, בניגוד לגרף הימני שמראה כיצד חילוץ תכונות יכול לחשוף תבנית יותר ברורה וניתנת לכלל.
עבודה עם תכונות שחולצו במקום נתונים גולמיים דומה לתת למודל שלך גרסה מוקשטת וברורה של המידע שהוא זקוק ללמידה ממנו. זה לא רק הופך את תהליך הלמידה ליעיל יותר, אלא גם מוביל למודלים שיתכן יבצעו בצורה טובה יותר ביישומים בעולם האמיתי.
הבא, בואו נראה שיטות שונות של חילוץ תכונות.
שיטות של חילוץ תכונות
שיטות חילוץ תכונות ניתן לסווג באופן כללי לשני גישות עיקריות: הנדסת תכונות ידנית וחילוץ תכונות אוטומטי. בואו נבחן שתי השיטות אלו כדי להבין כיצד הן עוזרות להמיר נתונים גולמיים לתכונות משמעותיות.
הנדסת תכונות ידנית
הנדסת תכונות ידנית משתמשת בידע מתחום כדי לזהות וליצור תכונות רלוונטיות מנתונים גולמיים. גישה זו מבוססת על הבנה שלנו של הבעיה והנתונים כדי ליצור תכונות משמעותיות.
בעיבוד תמונה, הפיתוח הידני של תכונות עשוי לכלול טכניקות כמו זיהוי קצוות כדי לזהות גבולות של עצם, היסטוגרמות צבע כדי ללכוד את ההפצת הצבע, ניתוח טקסטורה כדי למדוד תבניות, ותיאורי צורה כדי לאפיין את הגאומטריה של העצם.
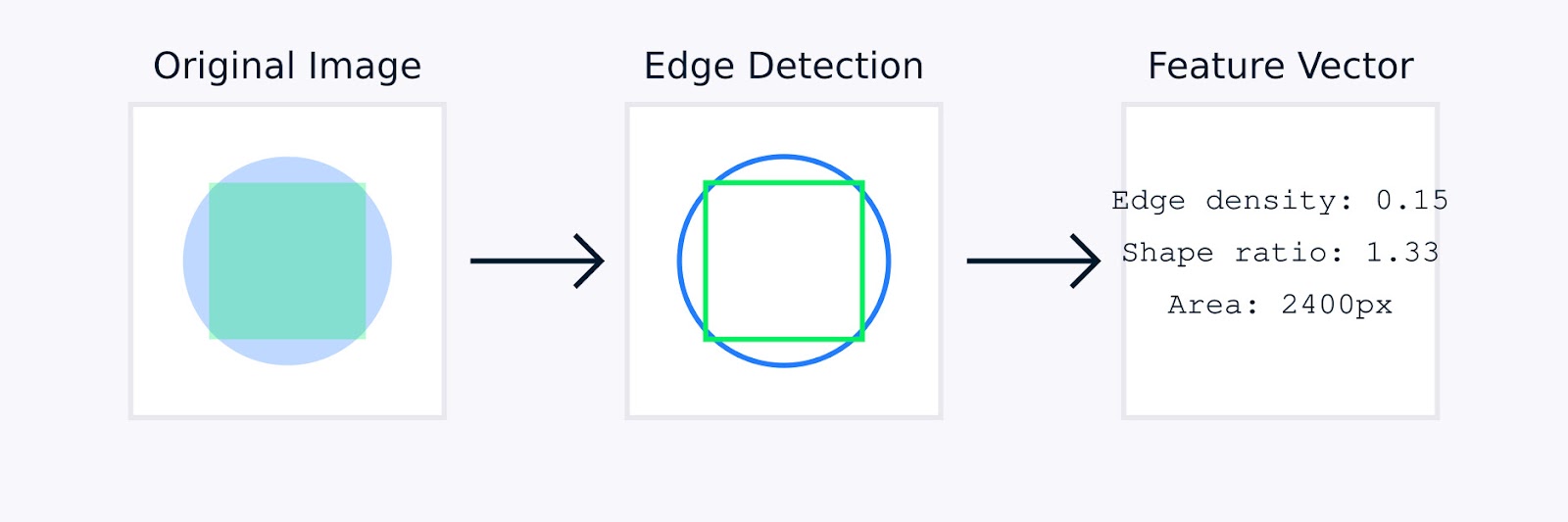
חילוץ תכונות מתמונה
לנתוני טבלה, הפיתוח הידני של תכונות כולל יצירת מונחים אינטראקטיביים בין תכונות קיימות, המרת משתנים באמצעות פונקציות לוגריתמיות או פולינומיאליות, איגוד נקודות נתונים לסטטיסטיקות משמעותיות, והצפנת משתנים קטגוריאליים.
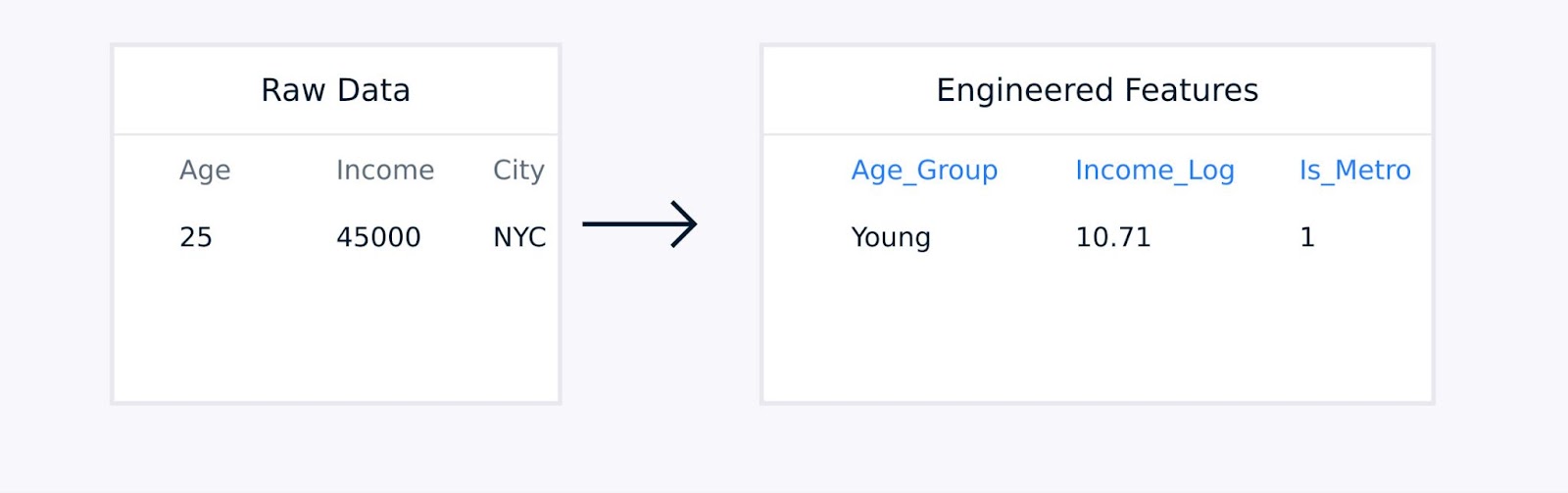
חילוץ תכונות מהטבלה
טכניקות אלו, המודרכות על ידי הידע התחום, משפרות את איכות הייצוג של הנתונים ויכולות לשפר משמעותית את ביצועי המודל.
חילוץ תכונות אוטומטי
חילוץ תכונות אוטומטי משתמש באלגוריתמים לגילוי ויצירת תכונות בלי הדרכה אנושית ספציפית. שיטות אלו מועילות במיוחד כאשר מתמודדים עם קבוצות נתונים מורכבות שבהן תכנות ידני של תכונות עשוי להיות לא יעיל או לא יתיר.
השיטות האוטומטיות הנפוצות כוללות:
ניתוח ראשי של רכיבים (PCA): מעביר נתונים לסט של רכיבים שאינם מקורלים, עם כל רכיב שומר על השואה המירבית השותרת. שיטה זו מועילה במיוחד ל-הפחתת ממדיות, מכיוון שהיא שומרת על המידע המהותי בנתונים בעוד מפשטת את מבנה הנתונים.
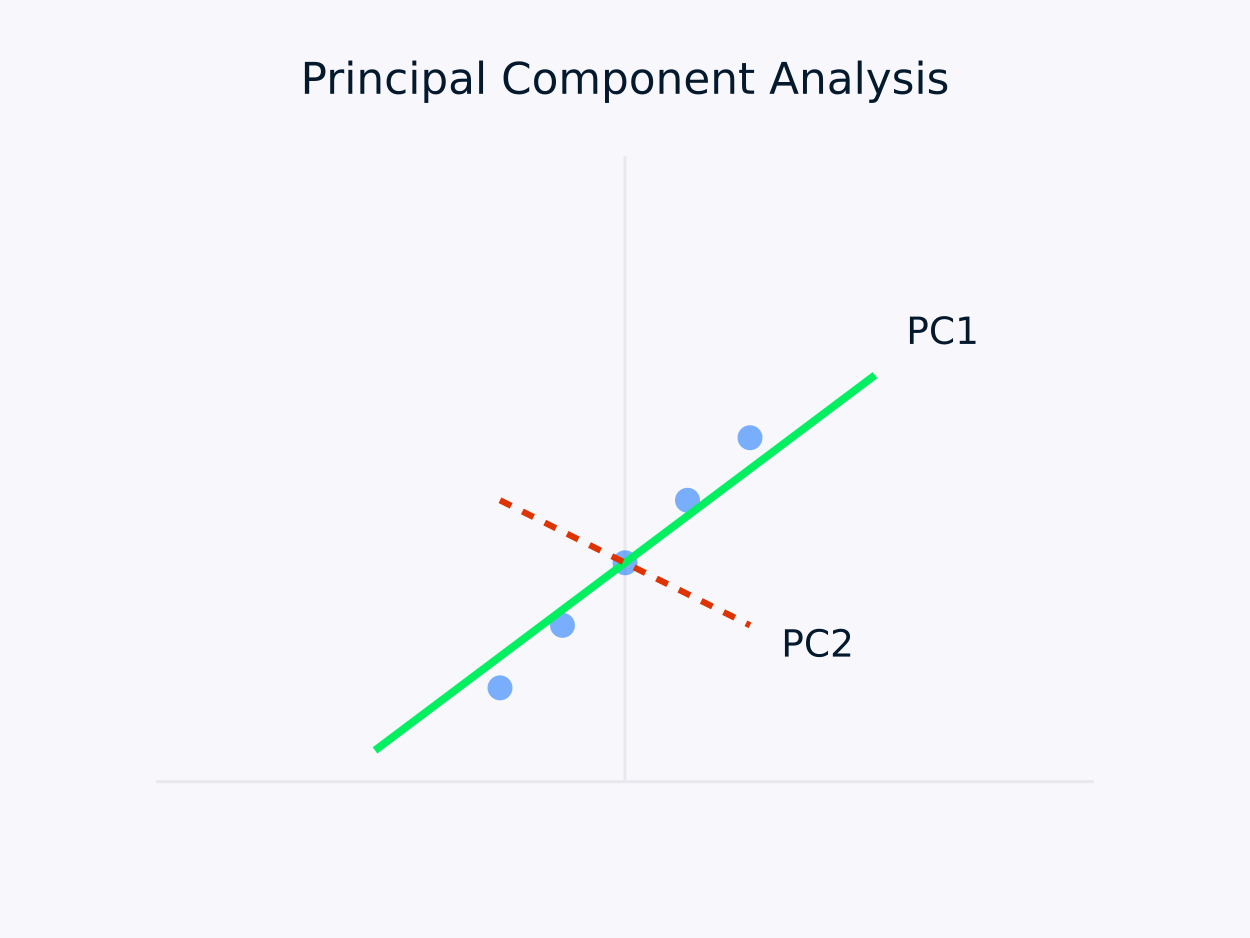
ניתוח ראשי של רכיבים (PCA)
אוטואנקודרים: אלו רשתות עצבים שלומדות ייצוגים דחוסים של נתונים, שומרות על קשרים לא לינאריים. הן יעילות במיוחד עבור סט נתונים עשוי מממדים גבוהים, שבהם שיטות לינאריות יכולות להפליא.
כלים וספריות שונים צץו לפני כדי לפשט את משימות ההנדסת תכונות. לדוגמה, מודול ההפשטה של Scikit-learn מציע מגוון שיטות להפחתת ממדיות, ו-PyCaret מספקת יכולויות בחירת תכונות אוטומטיות.
שיטות ידניות ואוטומטיות יש להן כוחות משלהן. בואו נבחן את היתרונות של כל שיטה.
|
הנדסה ידנית |
חילוץ אוטומטי |
|
אינטגרציה של ידע תחום |
קידמה |
|
תכונות ניתנות לפרשות |
מטפל בתבניות מורכבות |
|
שליטה בפרטים |
מפחית את הדעת האנושית |
|
מותאם לצרכים ספציפיים |
מגלה קשרים נסתרים |
הבחירה בין שיטות ידניות ואוטומטיות תלויה לעיתים קרובות בגורמים כגון מורכבות המערכת, זמינות הידע בתחום, דרישות הפרשנות, משאבי חישוב והגבלות זמן.
עבור סט נתונים מורכב ביותר או כאשר הזמן והמשאבים מוגבלים, שיטות אוטומטיות יכולות ליצור במהירות תכונות שימושיות. לעומת זאת, שיטות ידניות עשויות להיות מועדפות כאשר ישנה מומחות בתחום וניתן לפרש את המידע המתקבל, מאפשרות הנדסת תכונות המותאמת אישית שתואמת באופן צמוד את הבעיה המועדפת.
בפועל, רבים מפרויקטי למידת המכונה המוצלחים משלבים שני גישות, משתמשים במומחות בתחום כדי להנחות את הנדסת התכונות ובו זמנית מנצלים שיטות אוטומטיות כדי לגלות תבניות נוספות שאינן מובנות מיד למומחים.
במקטע הבא, נסתכל על מספר שיטות חילוץ תכונות שונות בתחומים שונים.
שיטות חילוץ תכונות
כל סוג של נתונים מחייב טכניקות חילוץ תכונות ספציפיות המותאמות למאפייניה הייחודיים. בואו נסתכל על הטכניקות הנפוצות ביותר עבור סוגי נתונים שונים.

טכניקות חילוץ תכונות
חילוץ תכונות של תמונות
חילוץ תכונות של תמונות ממיר נתוני פיקסלים גולמיים לייצוגים משמעותיים המכילים מידע חזותי עיקרי. יש שלושה קטגוריות עיקריות של טכניקות המשמשות בראיית מחשב מודרנית. אלו הן השיטות המסורתיות, המבוססות על למידה עמוקה, והשיטות הסטטיסטיות.

שיטות חילוץ תכונות של תמונות
בואו נסתכל על כל אחת מהשיטות.
שיטות ראיית מחשב מסורתיות
המרת מאפייני זיהוי תמונה קבועת (SIFT) היא שיטה עמידה המזהה מאפיינים מקומיים בולטים בתמונות. היא עובדת על ידי זיהוי נקודות מפתח ויצירת תיאורים שהם:
- קבועים לשינוי גודל וסיבוב של התמונה
- חלקית קבועים לשינויים בהארה
- עמידים בפני אי סדר גיאומטרי מקומי
אלגוריתם SIFT מעבד תמונות דרך מספר שלבים. הוא מתחיל עם זיהוי שיאי רוחב-קנה מידה כדי לזהות נקודות מפתח פוטנציאליות שהן קבועות לגודל. לאחר מכן, המיקום של נקודת המפתח מתואם אותן על ידי קידוד מיקומם המדויק ופינוי הנקודות הבלתי יציבות.
בעקבות זאת, מטלת היישום שוקלת כיוון קבוע עבור כל נקודת מפתח, מבטיחה אי-תלות בסיבוב. לבסוף, יצירת התיאור של נקודת המפתח יוצרת תיאורים דומיננטיים בהתבסס על הגדים מקומיים של גרידי התמונה, תורמת להתאמה חזקה בין תמונות.
שיטה נוספת היא היסטוגרמת של גרדינטים מכוונים (HOG). היא תופסת מידע על צורה מקומית על ידי ניתוח דפוסי גרדיינטים באורך תמונה. התהליך מתחיל בחישוב גרדינטים בכל רחבי התמונה כדי להדגיש פרטי קצה.
התמונה מחולקת לתאים קטנים, ולכל תא יוצרים היסטוגרמה של כיווני הגרדיאנט כדי לסכם את המבנה המקומי. לבסוף, ההיסטוגרמות הללו מונורמלות על בלוקים גדולים יותר כדי להבטיח עמידות נגד שינויים בתאורה ובניגודיות, בתוצאה תיאור מאפיינים עמיד למשימות כמו זיהוי וזיהוי אובייקטים.
שיטות למידה עמוקה
רשתות נוירוניות קונבולוציוניות (CNNs) שינו את דרך בה אנו עושים חילוץ מאפיינים על ידי למידת מייצגים היררכיים באופן אוטומטי.

חילוץ מאפיינים עם CNN
רשתות CNN לומדות תכונות דרך מבנה היררכי שלהן. בשכבות הראשונות, הן זוהות איברים חזותיים בסיסיים כמו קצוות וצבעים. השכבות האמצעיות משלבות את האיברים הללו כדי לזהות דפוסים וצורות, בעוד השכבות העמוקות יודעות לקפל אובייקטים מורכבים ולאפשר הבנה של סצנות.
העברת למידה מאפשרת לנו להשתמש בתכונות שכבר למדו ממודלים שהוכשרו על ידי מערכות נתונים גדולים, מה שהופך אותן למיוחדות במיוחד כאשר עובדים עם נתונים מוגבלים.
שיטות סטטיסטיות
שיטות סטטיסטיות משלימות גם דפוסים גלובליים וגם דפוסים מקומיים מתוך תמונות, מקלות על ניתוח תמונות ועל פירוש.
לדוגמה, היסטוגרמת צבע מייצגת את ההתפלגות של צבעים בתמונה ומספקת תכונות שאינן תלויות בסיבוב ומידה, ולכן מועילה במיוחד למשימות כמו סיווג תמונות ואחזור.
ניתוח טקסטורה תופס דפוסים חוזרים ותכונות של פני המשטח באמצעות טכניקות כמו מטריצות הקואורנציה של רמות האפור, המועילות לזיהוי חומרים ולסיווג סצנות.
בנוסף, זיהוי קצוות מזהה גבולות ושינויי עוצמה משמעותיים דרך שיטות כמו אופרטורי Sobel, Canny, ו־Laplacian, ושומר תפקיד קריטי בזיהוי אובייקטים ובנית צורות.
בחירת שיטת חילוץ תכונות תלויה במספר גורמים. עליה להתאים לדרישות הספציפיות של המשימה שלך, לשקול את המשאבים החישוביים הזמינים, ולקחת בחשבון את הצורך בניטור.
בנוסף, תכונות הסט הנתונים שלך—כמו גודלו, רמות הרעש, והמורכבות—שומרות תפקיד קריטי, כמו גם תכונות האינווריאנס הנדרשות כמו סקייל, רוטציה, והארה.
חילוץ תכונות של קול
דמיין ניסיון ללמד מחשב להבין דיבור בדרך שבה אנשים עושים זאת. זהו המקום שבו כביכול מגיעים לידי ביטוי קואפיציילים ספסטרליים בקצב המל (MFCC).
MFCCs הם תכונות שממפצים קול בדרך דומה לכיצד האוזניים שלנו מעבדות אותו. הם יעילים במיוחד מאחר והם מתמקדים בתדרים שבהם אנשים רגישים ביותר. חשוב לחשוב עליהם כמתרגמים של קול לתבנית שגם מחשבים ושמיעה אנושית ימצאו משמעותית.
קואפיציילים ספסטרליים בקצב המל
התהליך מתחיל על ידי פיצול אות הקול לחתיכות קצרות, אורכן בדרך כלל 20-40 מילישניות. עבור כל חתיכה, אנו מחילים סדרה של המרת מתמטיות שממירות את גלי הקול הגולמיים לרכיבי תדר. כאן הדברים מתעניינים. במקום להתייחס לכל התדרים באותה מידה, אנו משתמשים במשהו שנקרא סולם מל.
![]()
הנוסחה הזו עשויה להיראות מורכבת, אך בפועל היא פשוטה מכיוון שהיא מטמיעה תדרים כדי להתאים לאיך שהבני אדם תופסים קול. האוזניים שלנו יותר טובות בזיהוי הבדלים בתדרים נמוכים מאשר בתדרים גבוהים, וסולמת ה-Mel מתחשבת בגישה הטבעית הזו.
בזיהוי קול, מקדי ה- MFCC משמשים כיסוד להבנת מי מדבר ומה הם אומרים. כאשר אתה מדבר עם העוזר הווירטואלי של הטלפון שלך, סביר שהוא משתמש ב-MFCC כדי לעבד את הקול שלך. המקדים האלו עוזרים לתפוס את המאפיינים הייחודיים של הקול של כל אדם, ובכך הם חשובים מאוד למערכות זיהוי דוברים.
בניתוח רגשות בדיבור, ה-MFCC עוזרים לזהות שינויים עדינים בקול המציינים רגשות. הם יכולים לתפוס שינויים בגובה, טון וקצב הדיבור שעשויים לציין האם מישהו שמח, עצוב, כועס או ניטרלי. לדוגמה, בניתוח שיחות שירות לקוחות, MFCC יכולים לעזור לזהות את רמות השביעות רצון של הלקוחות על סמך איך הם מדברים, ולא רק על פי מה שהם אומרים.
חילוץ מאפייני סדרות זמן
כאשר עובדים עם סדרות זמן מידע, חילוץ תכונות משמעותיות עוזר לנו לקפות רעיונות וטרנדים שמתפתחים במהלך הזמן. בואו נסתכל על כמה טכניקות מרכזיות המשמשות להמרת מידע גולמי של סדרות זמן לתכונות שימושיות.

שיטות חילוץ תכונות של סדרות זמן
ההמרה הפורייה מפשטת את המידע של סדרות זמן לרכיבי התדר שלה, חושפת רעיונות מחזוריים נסתרים. הנוסחה היא:
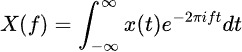
שיטות סטטיסטיות משלימות את ניתוח התדירויות על ידי דגימת המאפיינים הזמניים. תכונות נפוצות כוללות ממוצעים נעים, סטיית תקן ורכיבי מגמה. טכניקות אלו עוצמתיות במיוחד בתחזית פיננסית, שבהן הן עוזרות לזהות מגמות שוק ואנומליות.
לדוגמה, בניתוח שוק המניות, שילוב של תכונות פורייה עם מדדים סטטיסטיים עשוי לחשוף גם מגמות ארוכות טווח ותבניות ציקליות. באופן דומה, בהגדרות תעשייתיות, שיטות אלו עוזרות לזהות אנומליות בציוד על ידי ניתוח תבניות נתוני חיישנים לאורך זמן.
כלים וספריות לחילוץ תכונות
בואו נסתכל על כלים עיקריים שמקלים על יישום שיטות אלו לחילוץ תכונות והם יעילים.
כלים וספריות לחילוץ תכונות
בעיבוד תמונה, OpenCV ו־scikit-image מספקים כלים מקיפים ליישום של מגוון שיטות לחילוץ תכונות. ספריות אלו מציעות יישומים יעילים של SIFT, HOG ואלגוריתמים אחרים שדיברנו עליהם בעבר. כאשר עובדים עם גישות למידת עמוק, מסגרות כמו TensorFlow ו־PyTorch הופכות ליקרות. ניתן להתחיל עם המדריך של OpenCV שלנו כדי ללמוד עוד.
משימות עיבוד הקול נפשטות עם ספריות כמו LibROSA, שמתבררת בחידוש MFCCs ותכונות אקוסטיות נוספות. PyAudioAnalysis מרחיב את היכולות הללו עם ממשקים ברמה גבוהה למשימות ניתוח הקול.
לנתוני סדרות זמן, tsfresh ו-Featuretools מאופטימים את תהליך חילוץ התכונות. ספריות אלו יכולות ליצור ולבחור באופן אוטומטי תכונות רלוונטיות מהנתונים הזמניים שלך, מה שהופך קל יותר להתמקד בפיתוח מודלים במקום בהנדסת תכונות.
דוגמה לחילוץ תכונות
בואו נשים את הידע שלנו לפועל עם דוגמאות מעשיות. נתחיל עם חילוץ תכונות של תמונה, אחת היישומים הנפוצים ביישום ראיית המחשב.
חילוץ תכונות של תמונה באמצעות OpenCV
ראשית, נייבא את הספריות הנחוצות
# יבוא ספריות נדרשות import cv2 import numpy as np import matplotlib.pyplot as plt
כעת, נטען תמונה כדי לחלץ תכונות רלוונטיות. לדוגמה זו, נשתמש בתמונת גודזילה שהורדנו מהאינטרנט.
# טען את התמונה image = cv2.imread('godzilla.jpg') # המר מ- BGR ל- RGB (OpenCV טוען בפורמט BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # הצג את התמונה המקורית plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
פלט:

לפני להחיל זיהוי קצוות, עלינו לעבד את התמונה שלנו. אנו עושים זאת באופן הבא:
# המר את התמונה לגווני אפור gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # החל טשטוש גאוסיין כדי להפחית רעש blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
לבסוף, נחיל את אלגוריתם זיהוי הקצוות של Canny ונחזור את התוצאות:
# החלת זיהוי קצוות Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # הצגת התוצאות plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
פלט:

מזהה קצוות Canny עוזר לנו לזהות גבולות חשובים ותכונות בתמונה שלנו, שניתן להשתמש בהם לניתוח נוסף או כקלט למודלי למידת מכונה.
חילוץ MFCC מקובץ שמע באמצעות LibROSA
לפני שנוכל להתחיל בעיבוד קבצי שמע, עלינו להתקין את הספריות הנדרשות. בהתחשב בכך ש-LibROSA אינו כלול בספריית הסטנדרטית של פייתון, נשתמש ב-pip כדי להתקין אותו:
# התקנת ספריות הנדרשות # הריצו את הפקודות הללו בטרמינל או בפקודה pip install librosa pip install numpy pip install matplotlib
LibROSA היא ספריית עוצמתית המיועדת לניתוח מוזיקה ושמע, אז נתחיל על ידי יבואה יחד עם ספריות נדרשות נוספות:
# יבוא ספריות נדרשות import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
קבצי קול מכילים המון מידע בפורמט גל. כדי לעבוד עם המידע הזה, נצטרך תחילה לטעון אותו אל תוך התוכנית שלנו. LibROSA עוזרת לנו לעשות זאת על ידי המרת קובץ השמע לפורמט שבו נוכל לנתח אותו:
# טעינת קובץ השמע # המשך השמע מוגבל ל-10 שניות לדוגמה זו audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # הצגת הגל plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
פלט:
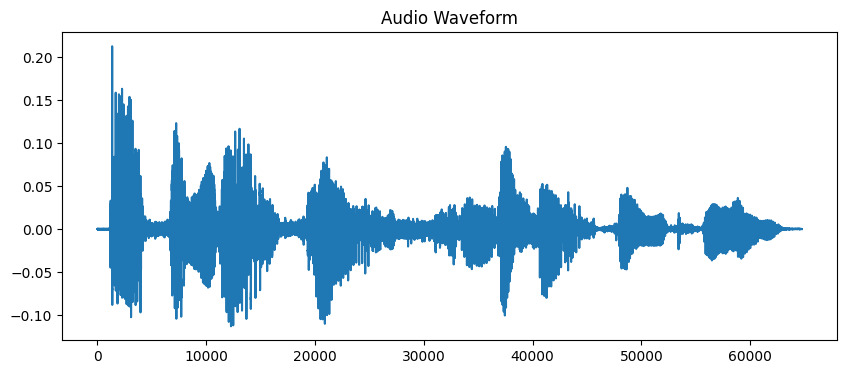
עכשיו שיש לנו את השמע שלנו טעון, אנו צריכים לחלץ מאפיינים משמעותיים ממנו. האוזניים שלנו מפרקות באופן טבעי קול לרכיבים שונים בתדרים שונים, ו-MFCC מדמה את התהליך הזה. אנו משתמשים בפונקציית חילוץ תכונות של librosa כדי לחשב את מקדמי הקורלציה של אלו:
# חילוץ תכונות MFCC mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # הצגת ה-MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
פלט:
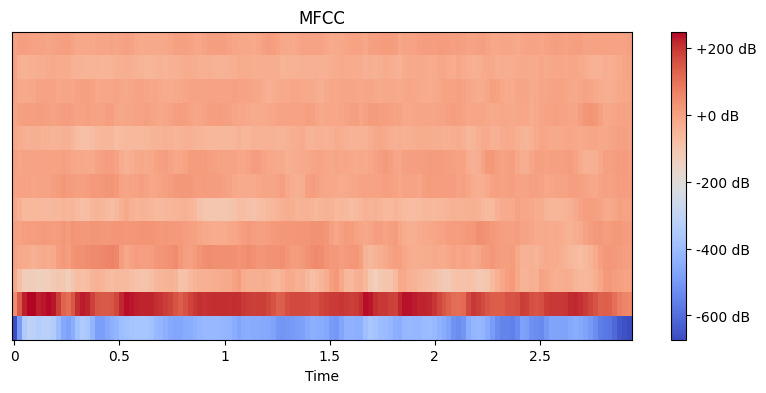
כאן, אנו מגדירים n_mfcc=13 מכיוון שהמקדמים הראשונים 13 בדרך כלל תופסים את הנקודות החשובות ביותר של הצליל שמסייעות במשימות כמו זיהוי דיבור. הויזואליזציה התוצאת מראה כיצד התכונות הללו משתנות לאורך הזמן, כאשר צבעים בהירים מייצגים ערכים גבוהים.
חילוץ מאפיינים מנתוני סדרות זמן עם tsfresh
ראשית, בואו נתקין את הספריות הנדרשות. נשתמש ב־yfinance כדי לקבל נתונים פיננסיים, יחד עם tsfresh לחילוץ מאפיינים:
# התקן את הספריות הנדרשות # הרץ את הפקודות הללו בטרמינל או בפקודה pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
כעת בואו נייבא את הספריות שלנו ונביא נתוני פיננסיים אמיתיים:
# יבוא ספריות נדרשות import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
בואו נקבל נתוני שוק אמיתיים. נשתמש בנתוני המניות של Apple כדוגמה:
# הורדת נתוני המניות של Apple ל-2 השנים האחרונות aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # הכנת הנתונים בפורמט שצפוי על ידי tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # כל סדרת זמן צריכה זיהוי 'time': range(len(df)), 'closing_price': df['Close'] # נשתמש במחירי הסגירה }) # הצגת מספר שורות ראשונות של הנתונים שלנו print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
פלט:
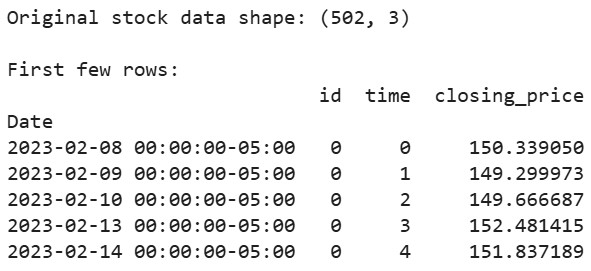
כעת נחלץ תכונות מנתוני סדרת הזמן הפיננסיים שלנו:
# הגדרת פרמטרים לחילוץ תכונות extraction_settings = MinimalFCParameters() # חילוץ תכונות אוטומטית extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # הצגת התכונות שחולצו print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
פלט:

כאן, אנו משתמשים ב-MinimalFCParameters() כדי לציין אילו תכונות לחשיב. זה נותן לנו מערך בסיסי של תכונות סדרת זמן משמעותיות כמו ממוצע, שונות ומאפייני מגמה, שחיוניים להבנת התבניות בנתונים שלנו.
אתגרים בחילוץ תכונות
כאשר אנו עובדים עם חילוץ תכונות, לעתים קרובות אנו נתקלים באתגרים.
הממדיות הגבוהה והאילוצים החישוביים צומחים לעיתים קרובות בעת התמודדות עם מערכות נתונים גדולות. לדוגמה, חילוץ תכונות מתמונות ברזולוציה גבוהה או קבצי שמע ארוכים יכול לצרוך זיכרון וכוח עיבוד משמעותיים.
העליון ביותר עקביות בשל תכונות לא רלוונטיות או מיותרות הוא אתגר נפוץ נוסף. כאשר מתווצצים יותר מדי תכונות, ייתכן כי המודלים ילמדו רעש במקום תבניות משמעותיות. התופעה הזו נפוצה במיוחד בעיבוד תמונה ושמע, שם ניתן ליצור אלפי תכונות.
על מנת להתגבר על אתגרים אלה, שקול לשקול אסטרטגיות אלו:
- השתמש בידע מתחום כדי לבחור תכונות רלוונטיות
- החל כלים לבחירת תכונות כדי להפחית את הממדיות
- הטמע טכניקות תכנות תכונות מתאימות בהתאם לסוג הנתונים שלך
אלה האתגרים מחייבים שקילות ואיזון בין עשירון התכונות ויעילות חישובית.
מסקנה
חילוץ תכונות הינו מיומנות בסיסית בלמידת מכונה שממירה נתונים גולמיים לייצוגים משמעותיים. דרך הדוגמאות המעשיות שלנו עם OpenCV, LibROSA, ו־tsfresh, ראינו כיצד לחלץ תכונות מסוגים שונים של נתונים. על ידי הבנתם של טכניקות אלו והאתגרים שלהן, אנו יכולים לבנות מודלי למידת מכונה אפקטיביים.
מוכן לעמוק יותר? בדוק את המשאבים האלו:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning