













Настройка AWS CLI и AWS S3
Прежде чем начать синхронизацию файлов с S3, вам нужно правильно настроить и настроить AWS CLI. Это может показаться сложным, если вы новичок в AWS, но на это уйдет всего несколько минут.
Настройка CLI включает два основных шага: установку инструмента и его настройку. Далее я рассмотрю оба шага.
Установка AWS CLI
Установка AWS CLI немного отличается в зависимости от вашей операционной системы.
Для систем Windows:
- Перейдите на страницу загрузкиWS CLI
- Скачайте установщик для Windows (64-разрядная версия)
- Запустите установщик и следуйте инструкциям
Для систем Linux:
Выполните следующие три команды через Терминал:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Для систем macOS:
Предполагая, что у вас установлен Homebrew, выполните эту команду из Терминала:
brew install awscli
Если у вас нет Homebrew, используйте вместо этого эти две команды:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Вы можете запустить команду aws --version на всех операционных системах, чтобы убедиться, что AWS CLI установлен. Вот что вы должны увидеть:
Изображение 1 – Версия AWS CLI
Настройка AWS CLI
Теперь, когда у вас установлен CLI, вам нужно его сконфигурировать с вашими учетными данными AWS.
Предполагая, что у вас уже есть учетная запись AWS, войдите в нее и перейдите в службу IAM. После этого создайте нового пользователя с программным доступом. Вы должны назначить пользователю соответствующие разрешения, которые как минимум включают доступ к S3:
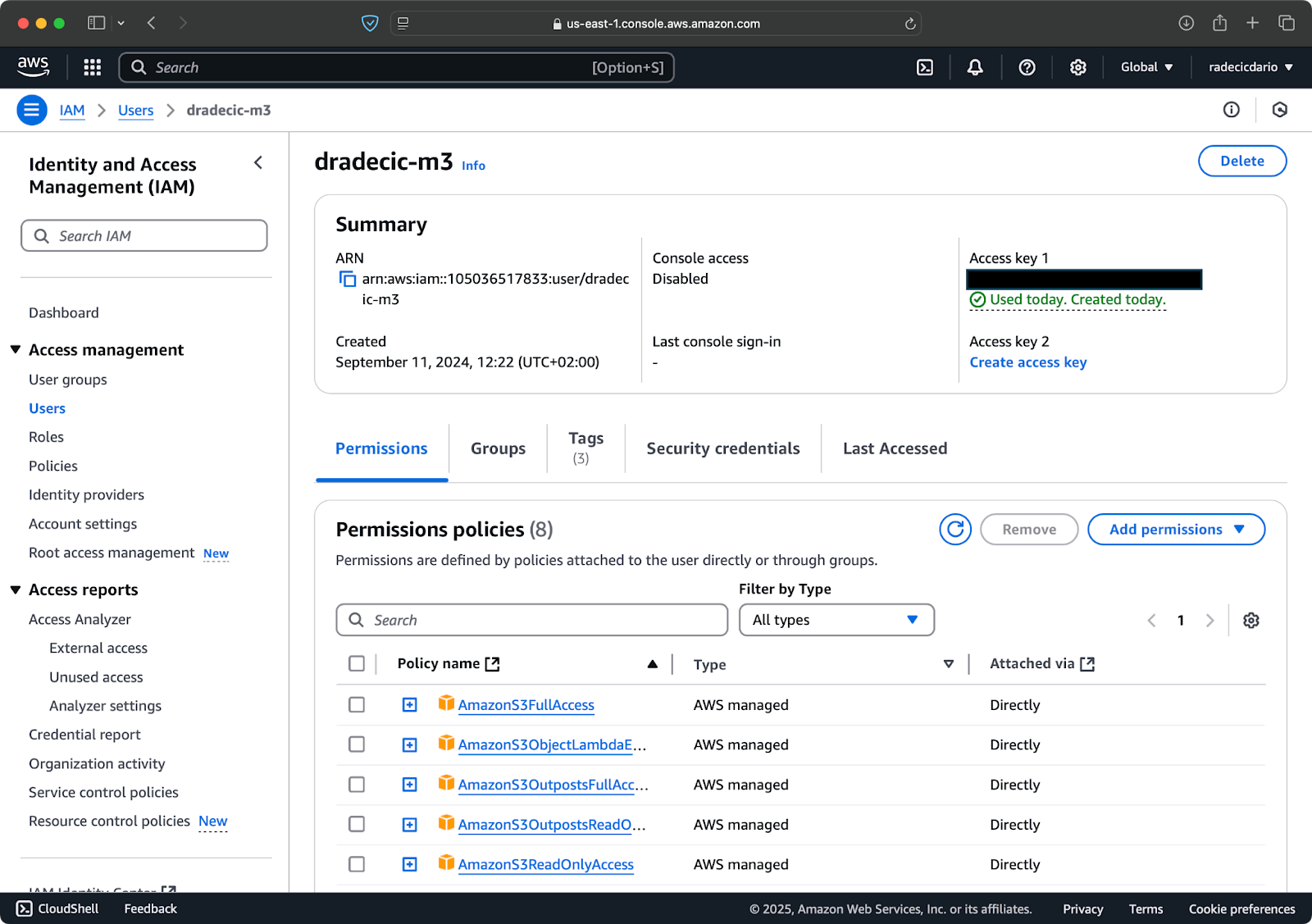
Изображение 2 – Пользователь AWS IAM
После этого перейдите в раздел “Учетные данные безопасности”, чтобы создать новый ключ доступа. После создания у вас будет как Идентификатор ключа доступа, так и Секретный ключ доступа. Запишите их где-то в безопасном месте, так как в будущем вы не сможете получить к ним доступ:
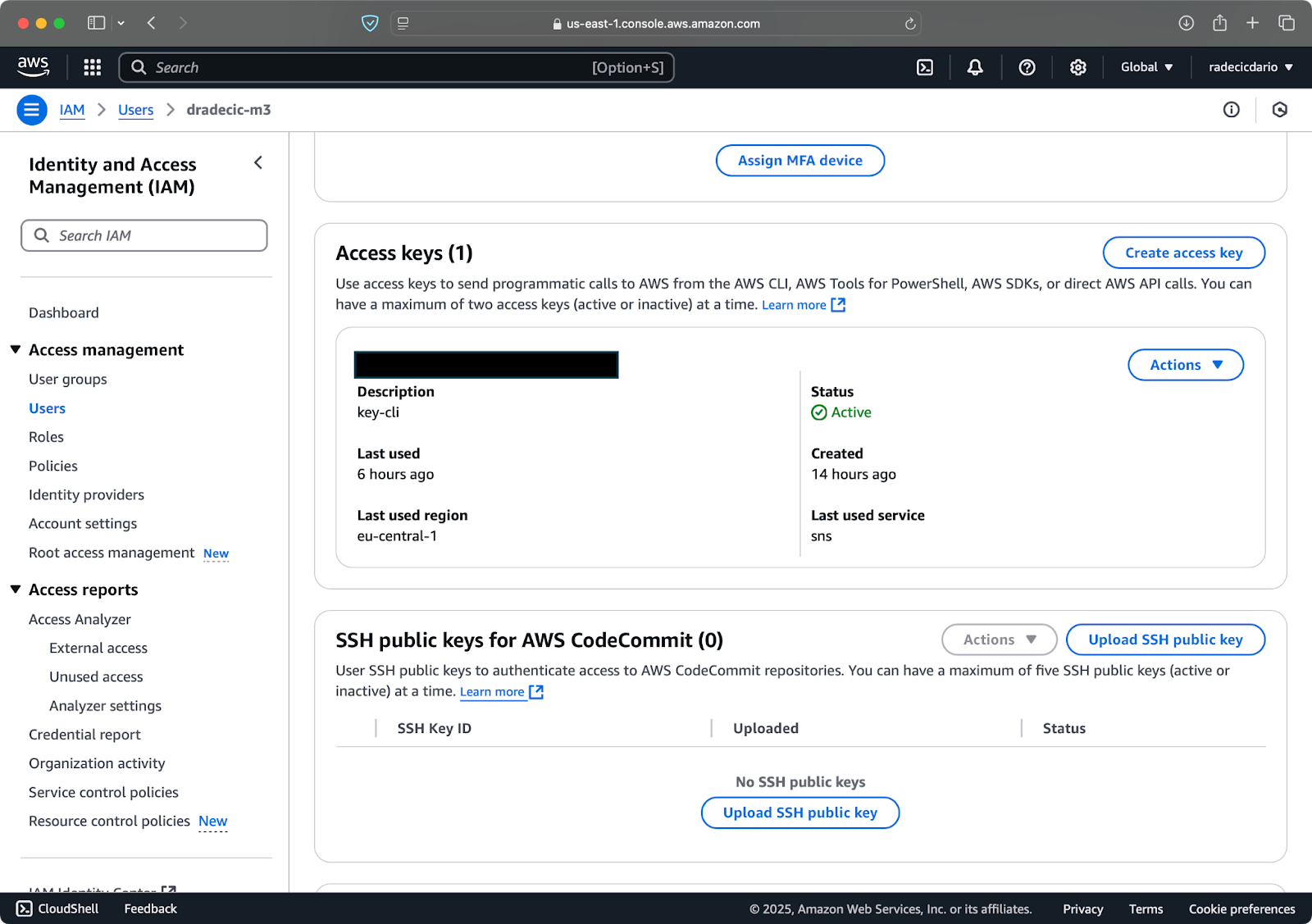
Изображение 3 – Учетные данные пользователя AWS IAM
Вернитесь в терминал и выполните команду aws configure. Она запросит вас ввести свой идентификационный ключ доступа, секретный ключ доступа, регион (eu-central-1 в моем случае) и предпочтительный формат вывода (json):
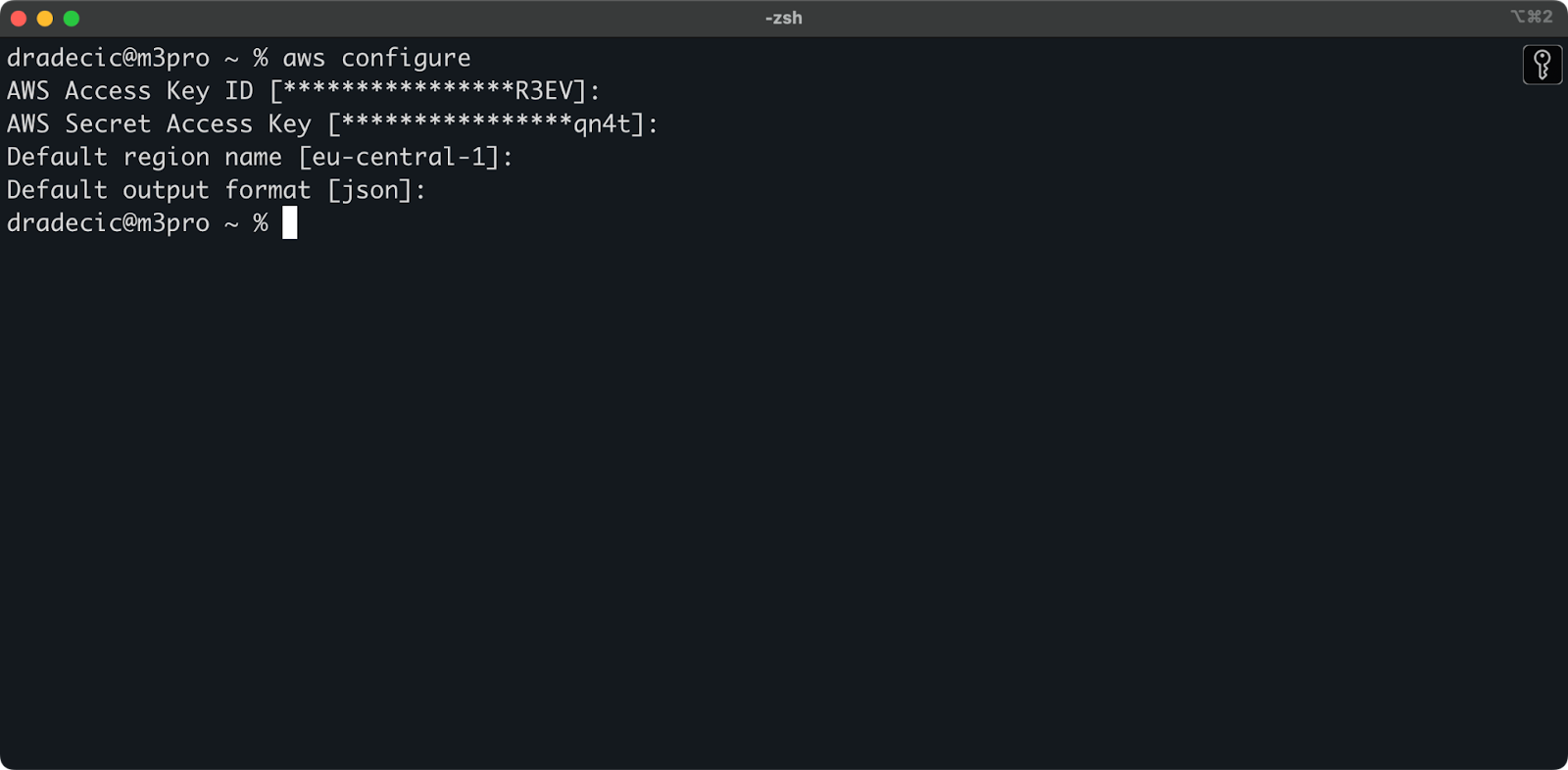
Изображение 4 – настройка AWS CLI
Чтобы убедиться, что вы успешно подключились к своей учетной записи AWS из CLI, выполните следующую команду:
aws sts get-caller-identity
Это вывод, который вы должны увидеть:
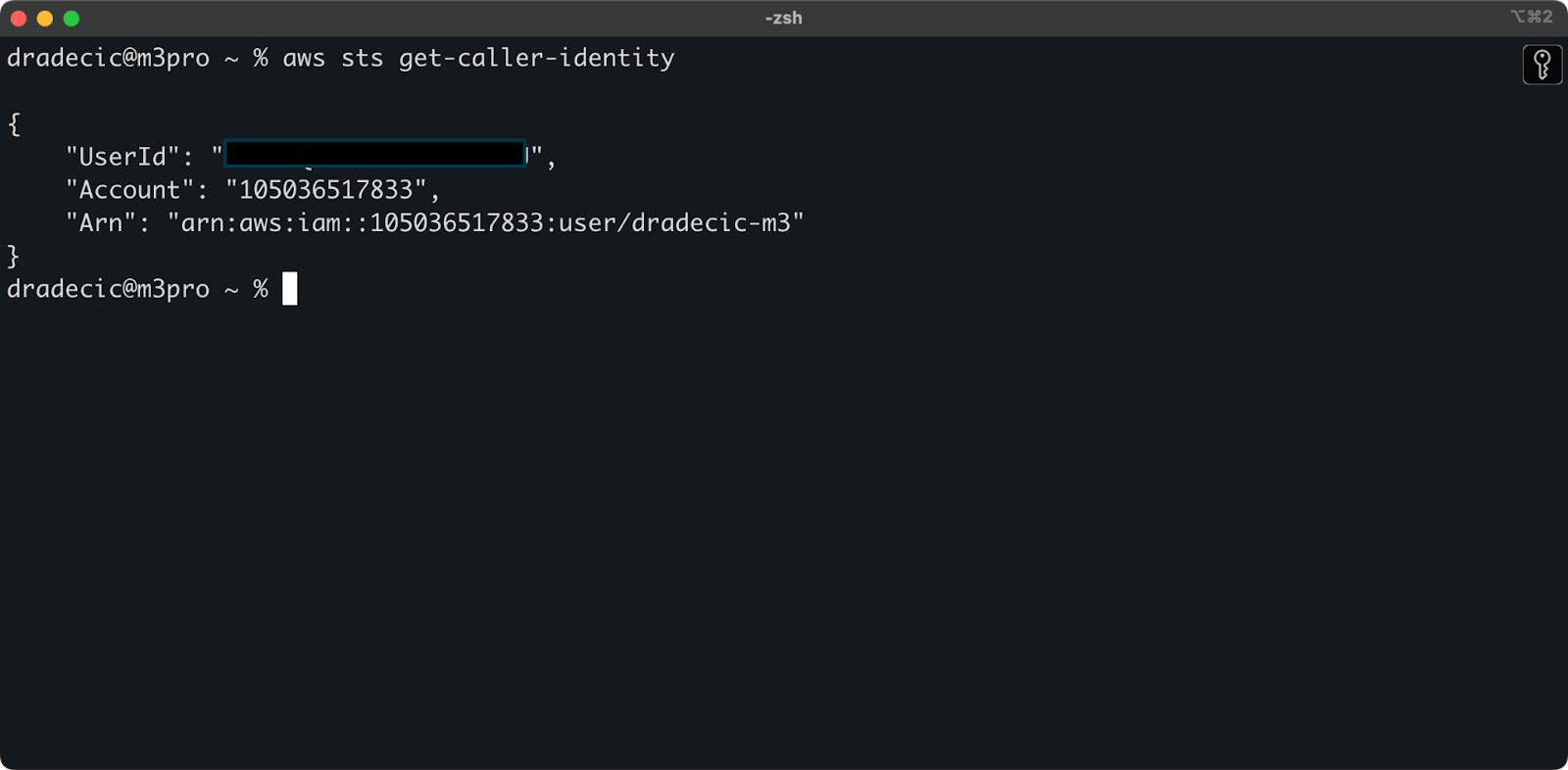
Изображение 5 – команда проверки подключения AWS CLI
И вот оно – всего один шаг остался перед тем, как вы сможете начать использовать команду синхронизации S3!
Настройка бакета AWS S3
Последний шаг – создать бакет S3, который будет хранить ваши синхронизированные файлы. Вы можете сделать это из CLI или из консоли управления AWS. Я выберу последнее, чтобы немного разнообразить.
Для начала перейдите на страницу услуги S3 в консоли управления и нажмите кнопку “Создать бакет”. После этого выберите уникальное имя бакета (уникальное глобально во всем AWS) и затем прокрутите вниз и нажмите кнопку “Создать”:
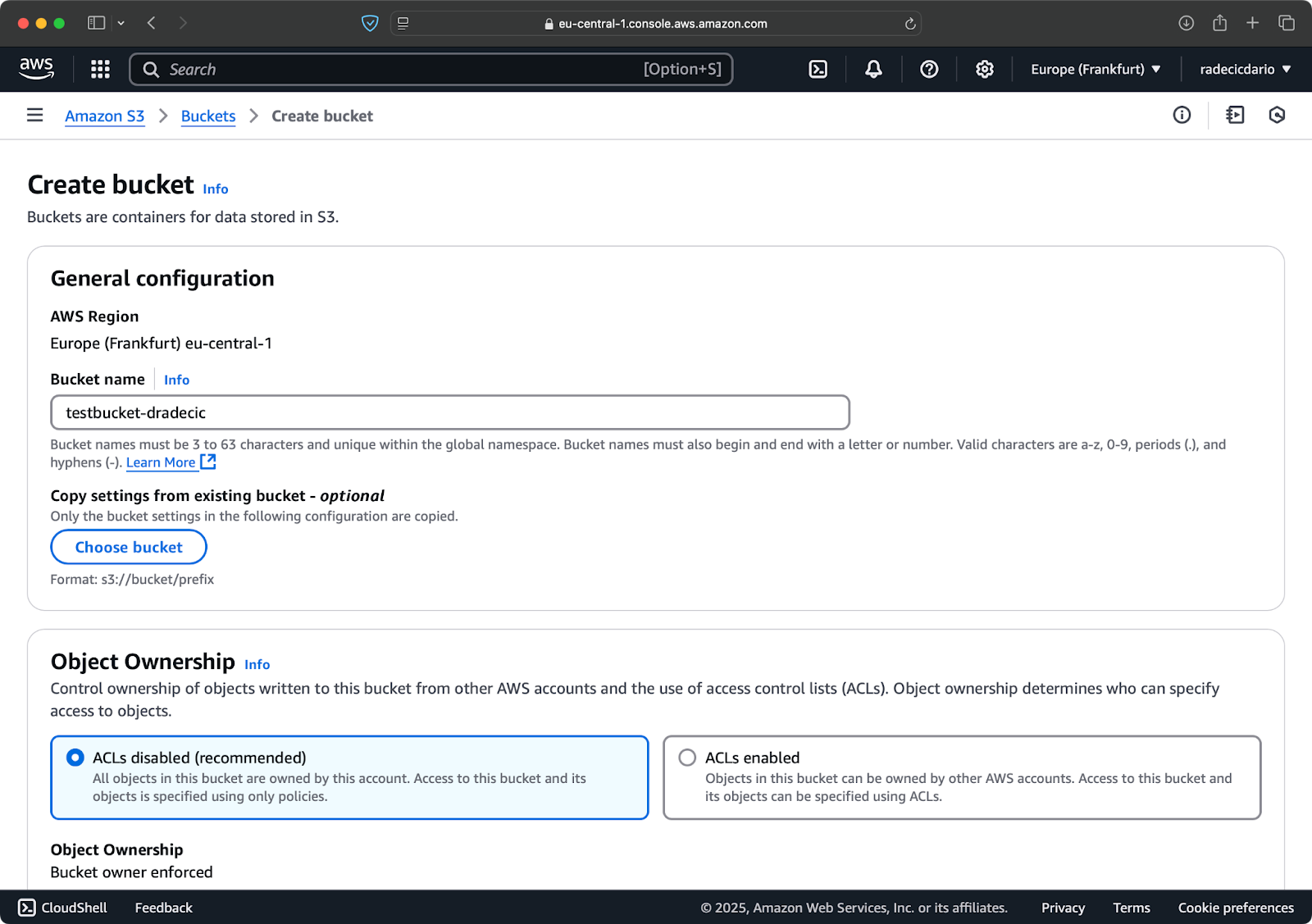
Изображение 6 – Создание бакета AWS
Бакет теперь создан, и вы сразу увидите его в консоли управления. Вы также можете проверить, что он был создан через CLI:
aws s3 ls
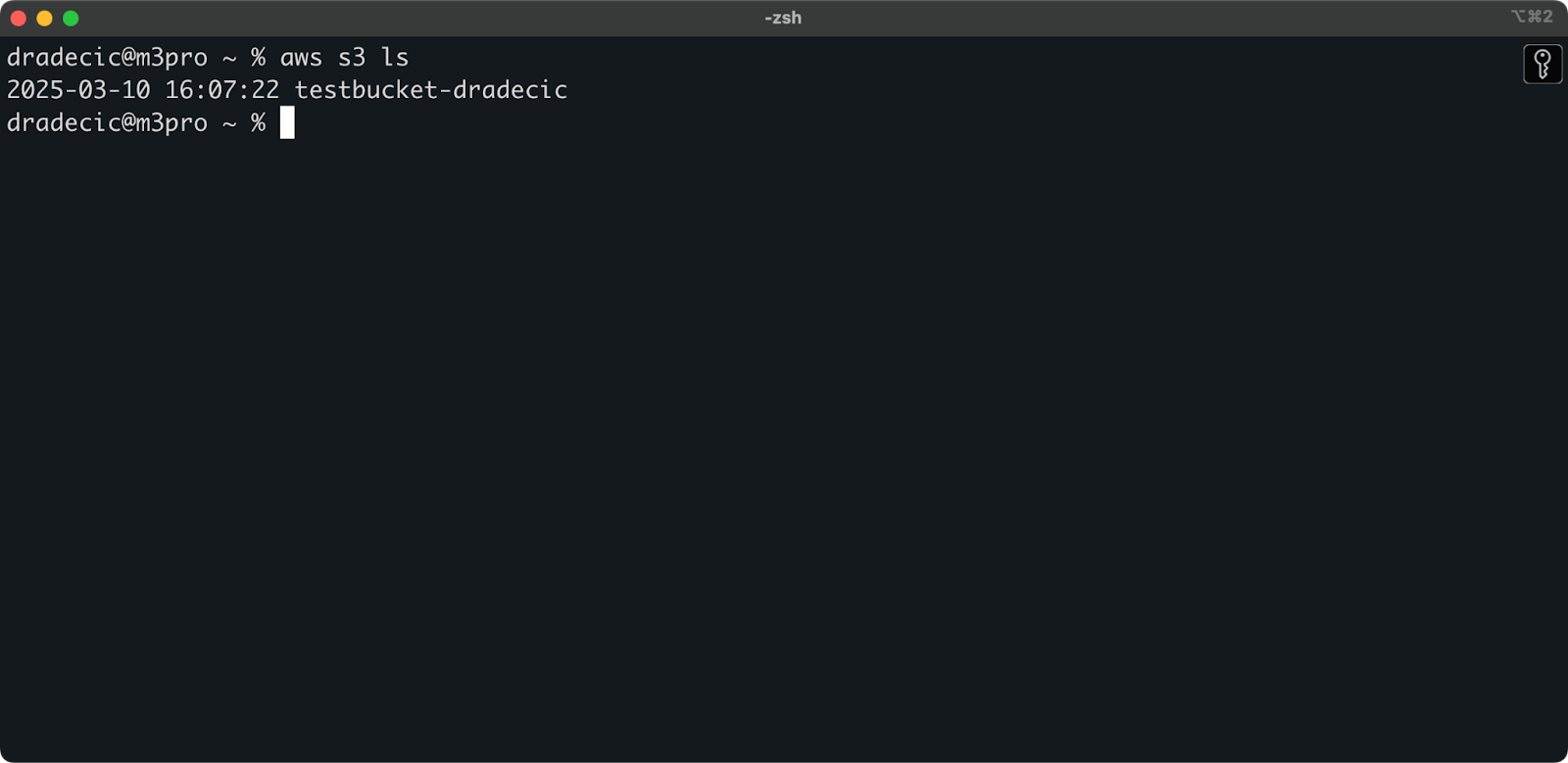
Изображение 7 – Все доступные бакеты S3
Имейте в виду, что ведра S3 по умолчанию являются частными. Если вы планируете использовать ведро для размещения публичных файлов (например, ресурсов веб-сайта), вам нужно будет соответствующим образом настроить политики и разрешения ведра.
Теперь вы готовы начать синхронизацию файлов между локальной машиной и AWS S3!
Основная команда синхронизации AWS S3
Теперь, когда у вас установлен AWS CLI, настроен и готов к работе ведро S3, пришло время начать синхронизацию! Основной синтаксис команды синхронизации AWS S3 довольно простой. Позвольте мне показать вам, как это работает.
Команда синхронизации S3 следует этому простому шаблону:
aws s3 sync <source> <destination> [options]
Исходный и конечный пункты могут быть как локальным путем к каталогу, так и URI S3 (начинающимся с s3://). В зависимости от того, каким образом вы хотите синхронизировать, вы их будете организовывать по-разному.
Синхронизация файлов с локального диска на корзину S3
Недавно я экспериментировал с глубоким исследованием Ollama. Допустим, это каталог, который я хочу синхронизировать с S3. Основной каталог находится внутри папки Documents. Вот как это выглядит:
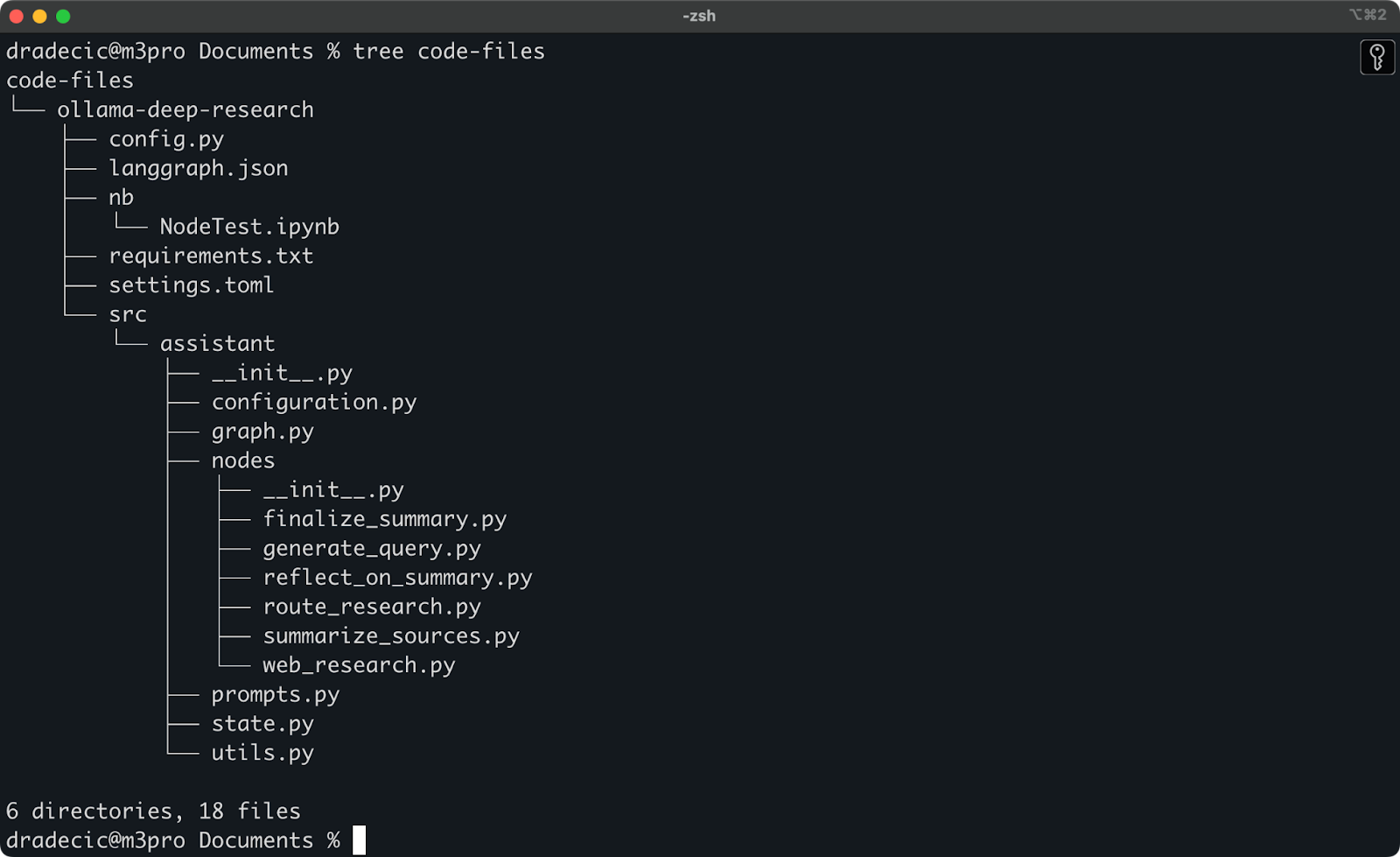
Содержимое локальной папки
Это команда, которую мне нужно выполнить, чтобы синхронизировать локальную папку code-files с папкой backup на корзине S3:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
Папка backup на корзине S3 будет автоматически создана, если ее не существует.
Вот что вы увидите на экране:
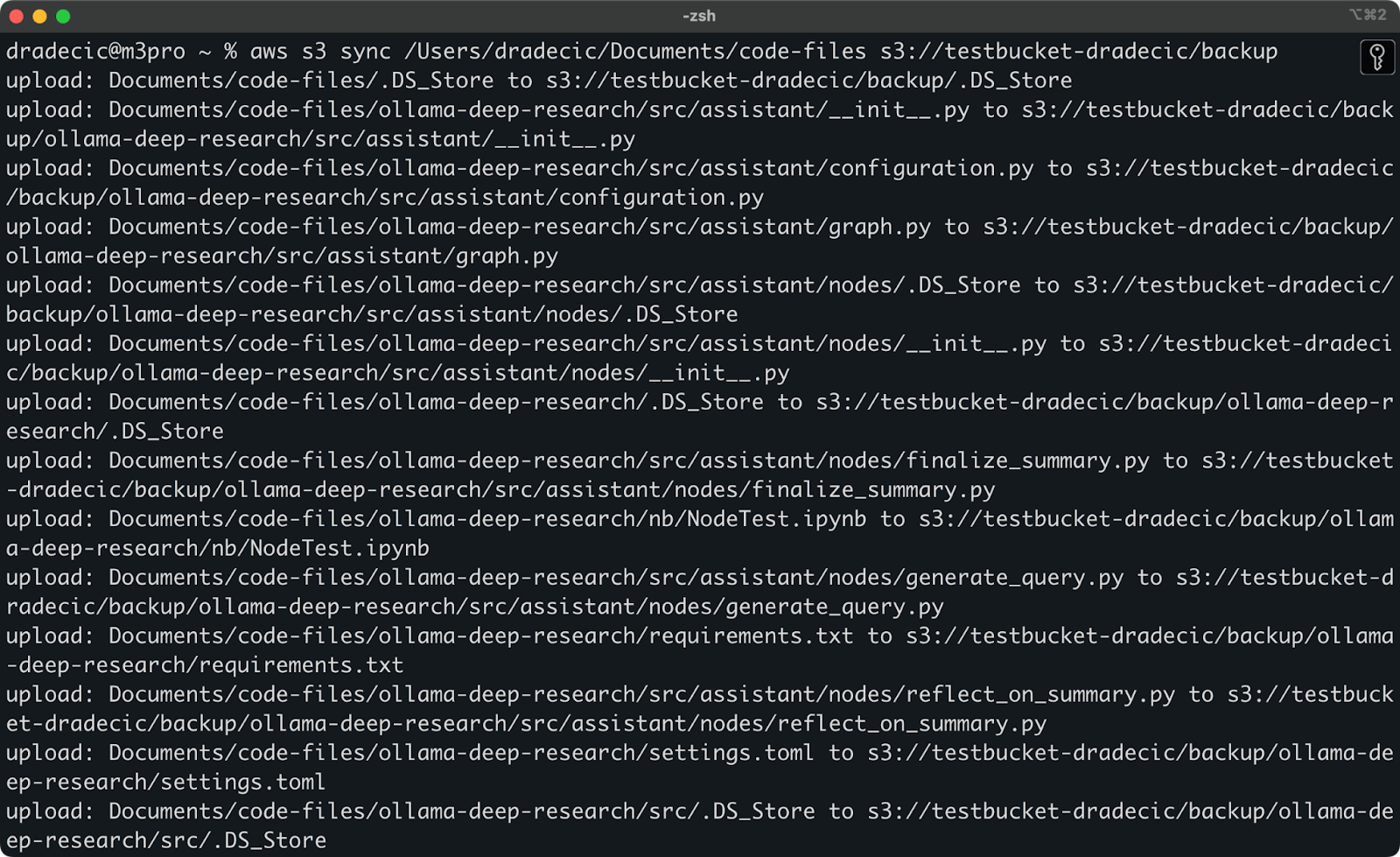
Изображение 9 – Процесс синхронизации S3
Через несколько секунд содержимое локальной папки code-files станет доступным в хранилище S3:
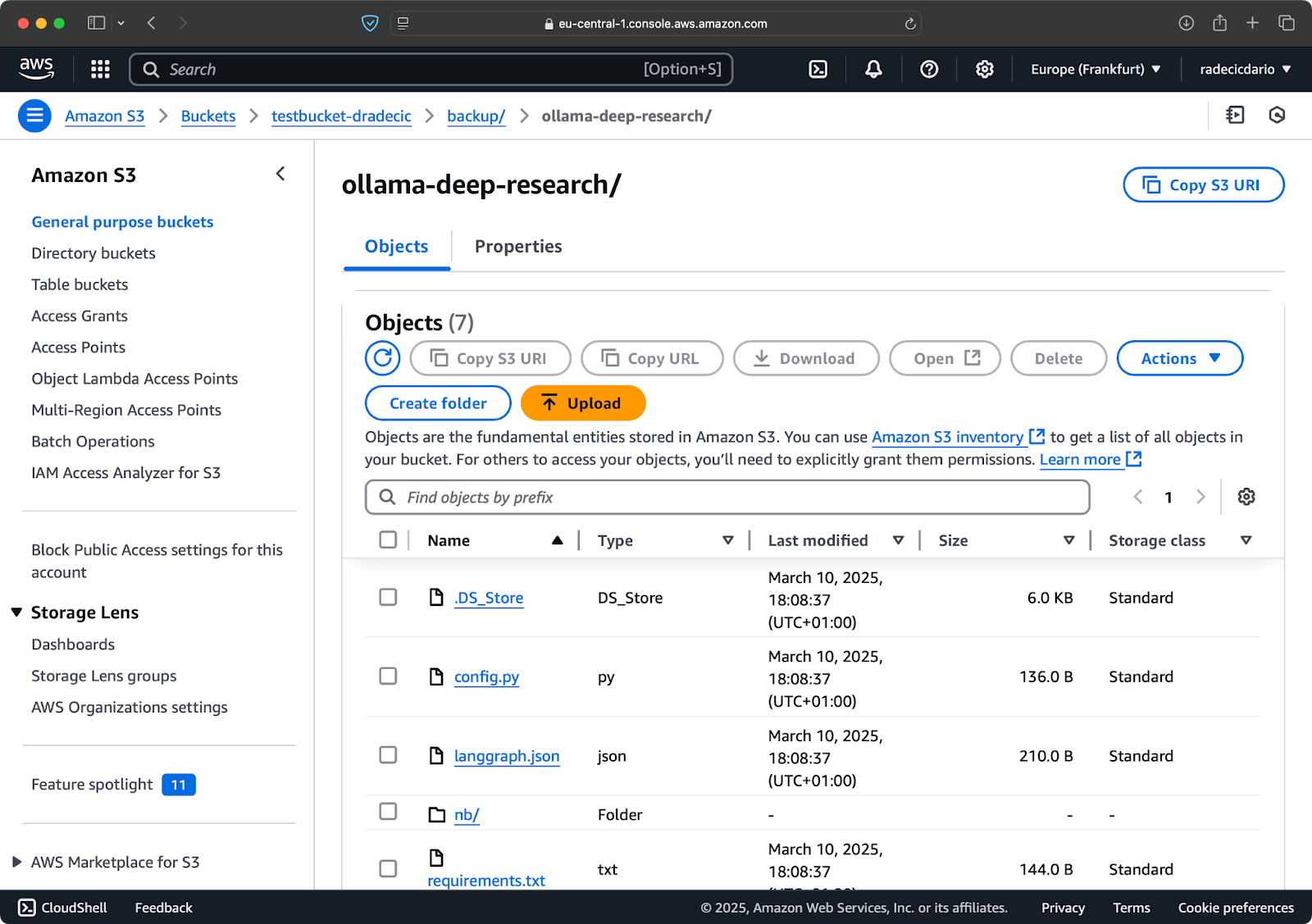
Изображение 10 – Содержимое бакета S3
Красота синхронизации S3 заключается в том, что загружаются только файлы, которых нет в пункте назначения или которые были изменены локально. Если вы запустите ту же команду снова, ничего не увидите! Это потому, что AWS CLI обнаружил, что все файлы уже синхронизированы и актуальны.
Теперь я внесу два небольших изменения – создам новый файл (new_file.txt) и обновлю существующий (requirements.txt). При повторном запуске команды синхронизации будут загружены только новые или измененные файлы:
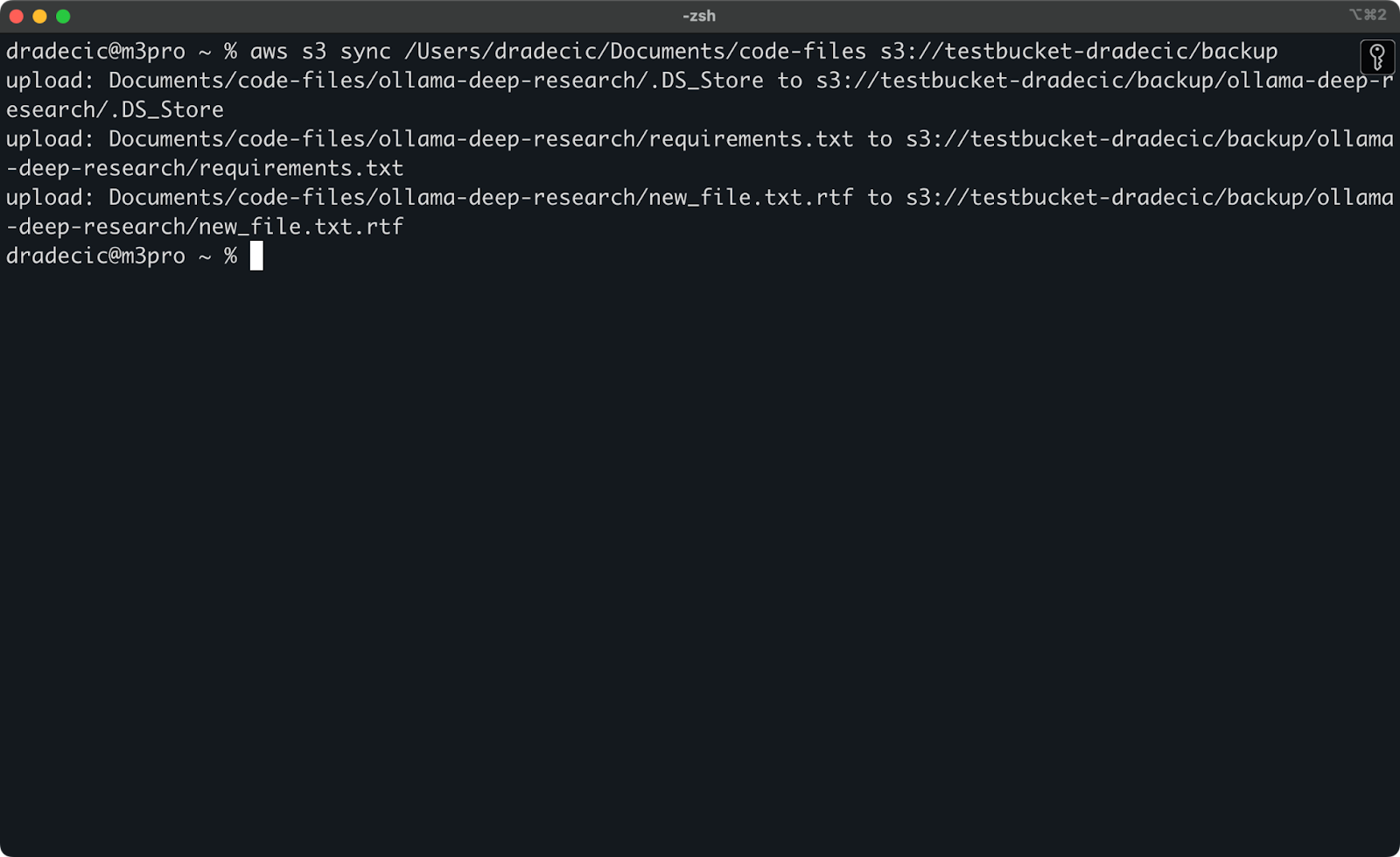
Изображение 11 – Процесс синхронизации S3 (2)
И это все, что вам нужно знать при синхронизации локальных папок с S3. Но что, если вы хотите сделать наоборот?
Синхронизация файлов из корзины S3 в локальный каталог
Если вы хотите загрузить файлы из своей корзины S3 на локальную машину, просто поменяйте местами исходное и конечное местоположение:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
Эта команда загрузит все файлы из папки backup в вашей корзине S3 в локальную папку с именем code-files-from-s3 . Опять же, если локальная папка не существует, интерфейс командной строки создаст ее для вас:
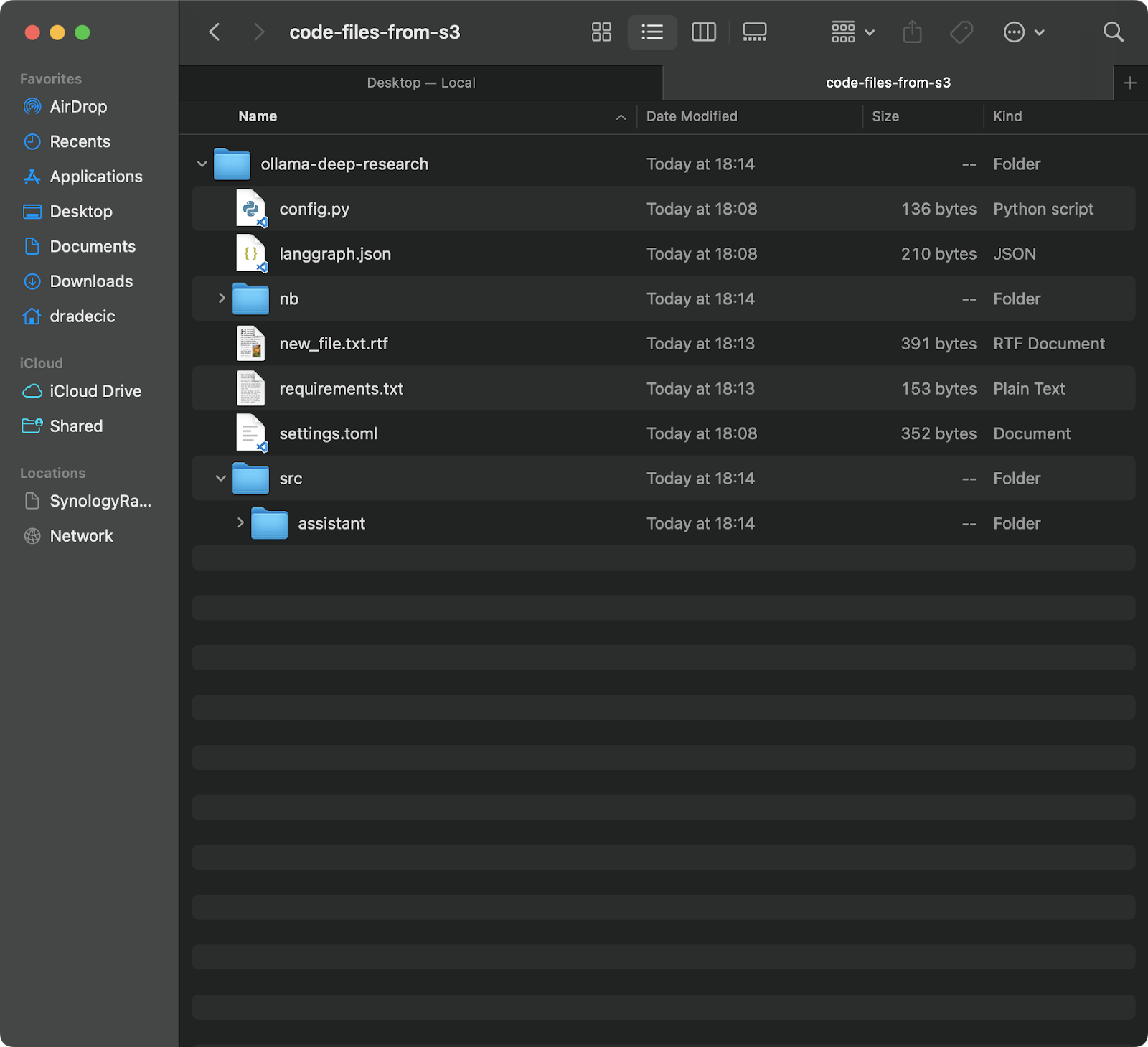
Изображение 12 – Синхронизация S3 с локальным хранилищем
Следует отметить, что S3 синхронизация не является двусторонней. Она всегда происходит от источника к месту назначения, приводя место назначения в соответствие с источником. Если вы удалите файл локально, а затем синхронизируете его с S3, он все равно будет существовать в S3. Аналогично, если вы удалите файл в S3 и выполните синхронизацию с S3 на локальный компьютер, локальный файл останется нетронутым.
Если вы хотите добиться полного соответствия места назначения источнику (включая удаления), вам нужно использовать флаг --delete, о котором я расскажу в разделе продвинутых параметров.
Дополнительные параметры синхронизации AWS S3
Базовая команда синхронизации S3, исследованная ранее, уже сама по себе мощный инструмент, но AWS упаковал ее с дополнительными параметрами, которые предоставляют больший контроль над процессом синхронизации.
В этом разделе я покажу вам некоторые из наиболее полезных флагов, которые вы можете добавить к базовой команде.
Синхронизация только новых или измененных файлов
По умолчанию синхронизация S3 использует базовый механизм сравнения, который проверяет размер файла и время модификации, чтобы определить, нужно ли синхронизировать файл. Однако этот подход не всегда улавливает все изменения, особенно при работе с файлами, которые были изменены, но остались тем же размером.
Для более точной синхронизации вы можете использовать флаг --exact-timestamps:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
Это заставляет синхронизацию S3 сравнивать отметки времени с точностью до миллисекунд. Имейте в виду, что использование этого флага может замедлить процесс синхронизации немного, поскольку требуется более детальное сравнение.
Исключение или включение конкретных файлов
Иногда вам не нужно синхронизировать каждый файл в каталоге. Возможно, вы хотите исключить временные файлы, журналы или определенные типы файлов (например, .DS_Store в моем случае). В этом случае пригодны флаги --exclude и --include.
Но для иллюстрации, допустим, я хочу синхронизировать каталог с моим кодом, исключив все файлы Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
Теперь значительно меньше файлов синхронизировано с S3:
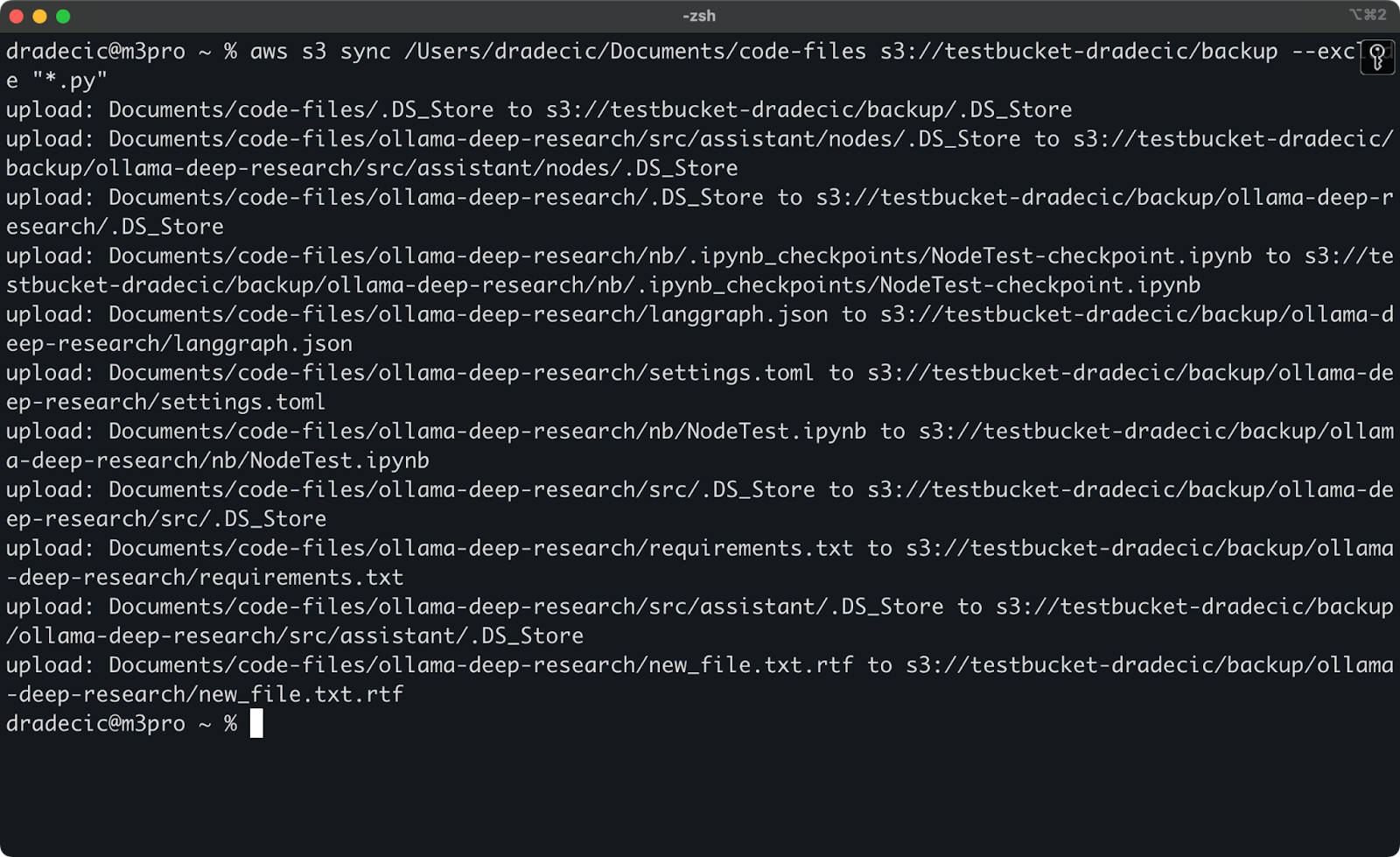
Изображение 13 – Синхронизация с S3 с исключенными файлами Python
Вы также можете объединить флаги --exclude и --include, чтобы создавать более сложные шаблоны. Например, исключить все, кроме файлов Python:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
Шаблоны оцениваются в указанном порядке, поэтому порядок имеет значение! Вот что вы увидите при использовании этих флагов:
Изображение 14 – Флаги исключения и включения
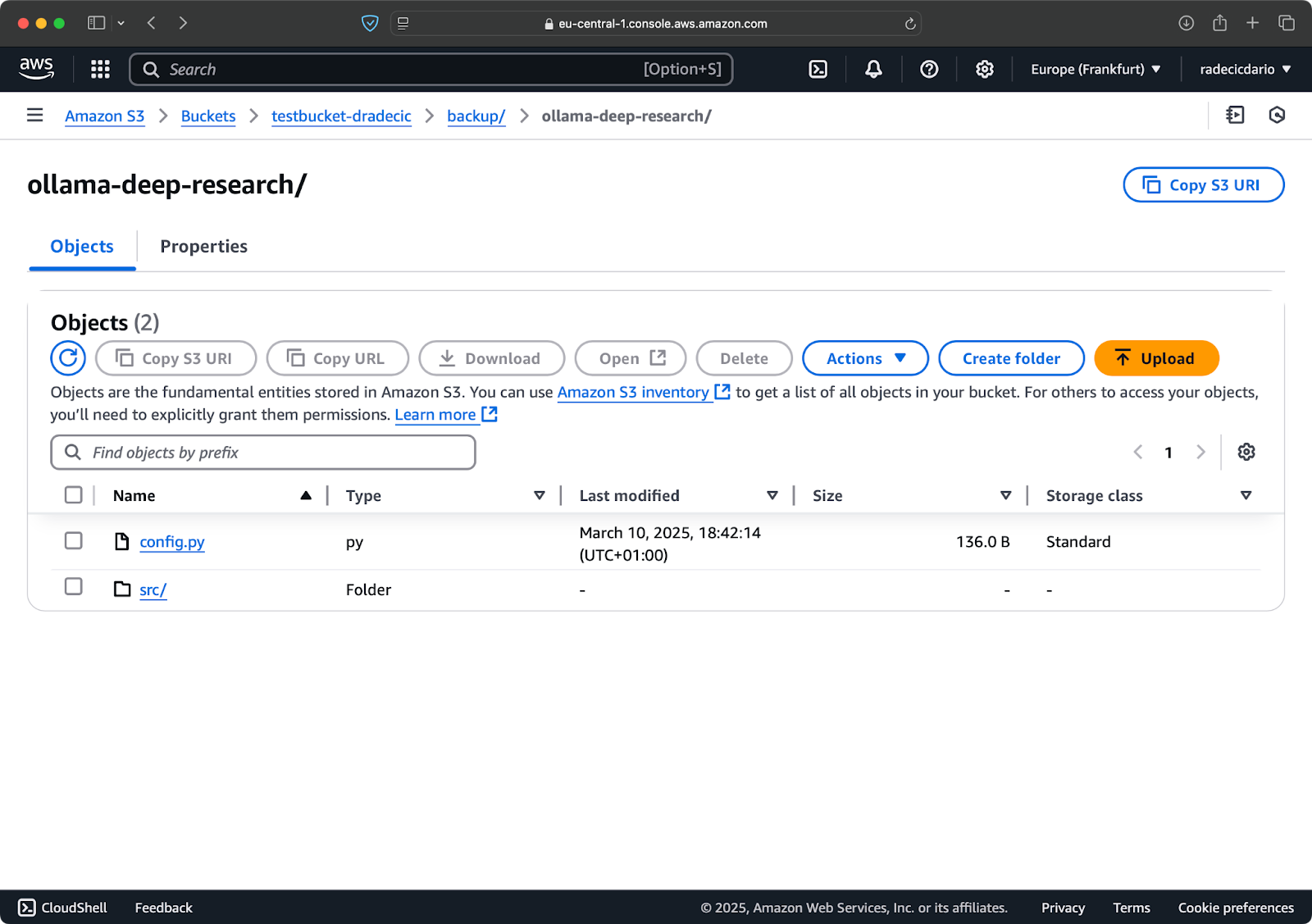
Теперь синхронизированы только файлы Python, и важные конфигурационные файлы отсутствуют.
Удаление файлов из пункта назначения
По умолчанию синхронизация S3 добавляет или обновляет файлы только в пункте назначения — она никогда их не удаляет. Это означает, что если вы удалите файл из источника, он все равно останется в пункте назначения после синхронизации.
Чтобы сделать пункт назначения точной копией источника, включая удаления, используйте флаг --delete:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
Если вы запустите это в первый раз, все локальные файлы будут синхронизированы с S3:
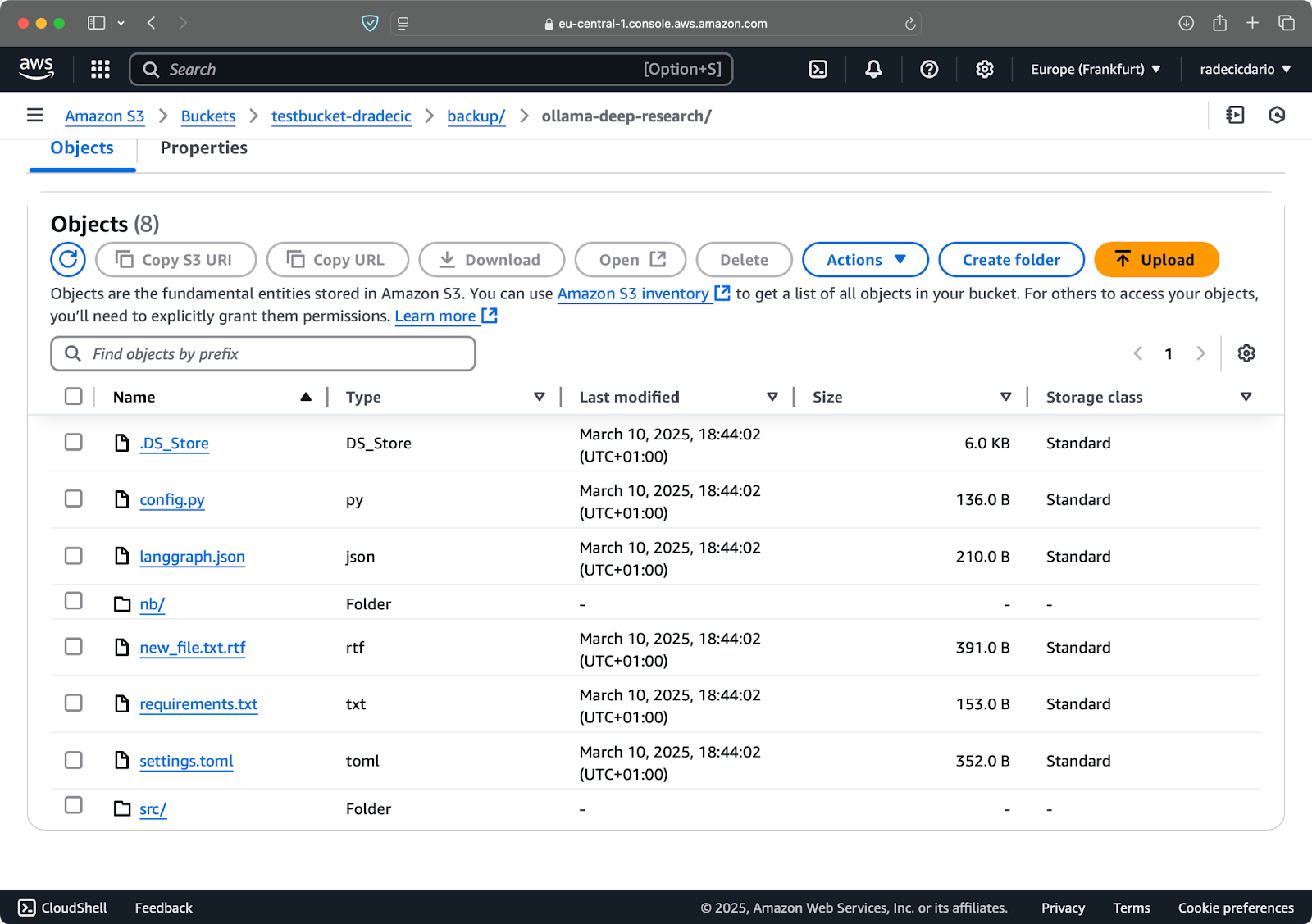
Изображение 15 – Флаг удаления
Это особенно полезно для поддержания точных реплик каталогов. Но будьте осторожны – этот флаг может привести к потере данных при неправильном использовании.
Допустим, я удаляю config.py из моей локальной папки и запускаю команду синхронизации с флагом --delete:
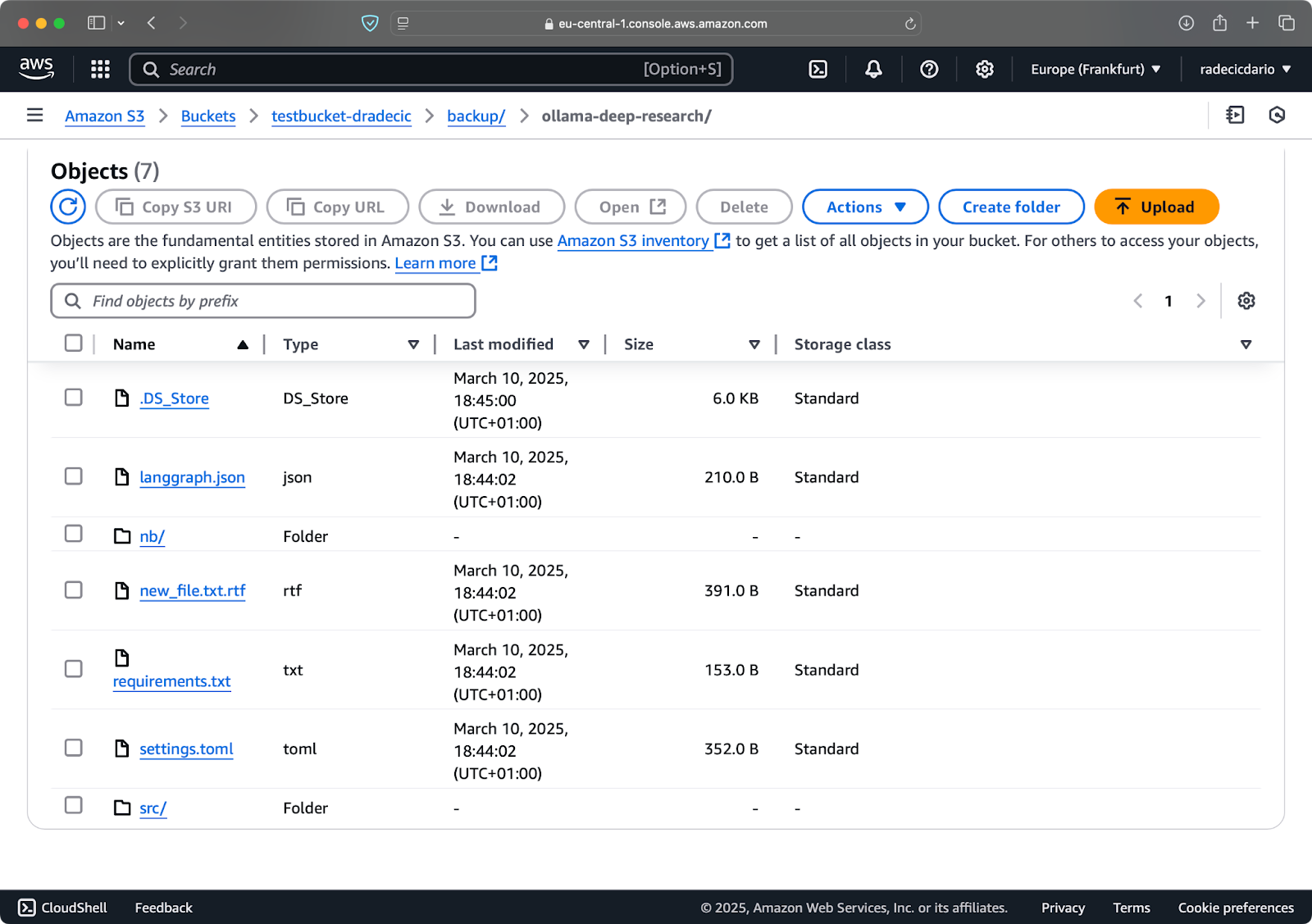
Изображение 16 – Флаг удаления (2)
Как вы можете видеть, команда не только синхронизирует новые и измененные файлы, но также удаляет файлы из корзины S3, которых больше нет в локальном каталоге.
Настройка пробного запуска для безопасной синхронизации
Самые опасные операции синхронизации S3 – это те, которые включают флаг --delete. Чтобы избежать случайного удаления важных файлов, вы можете использовать флаг --dryrun для симуляции операции без фактического внесения изменений:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
Для демонстрации я удалил файлы requirements.txt и settings.toml из локальной папки, а затем выполнил команду:
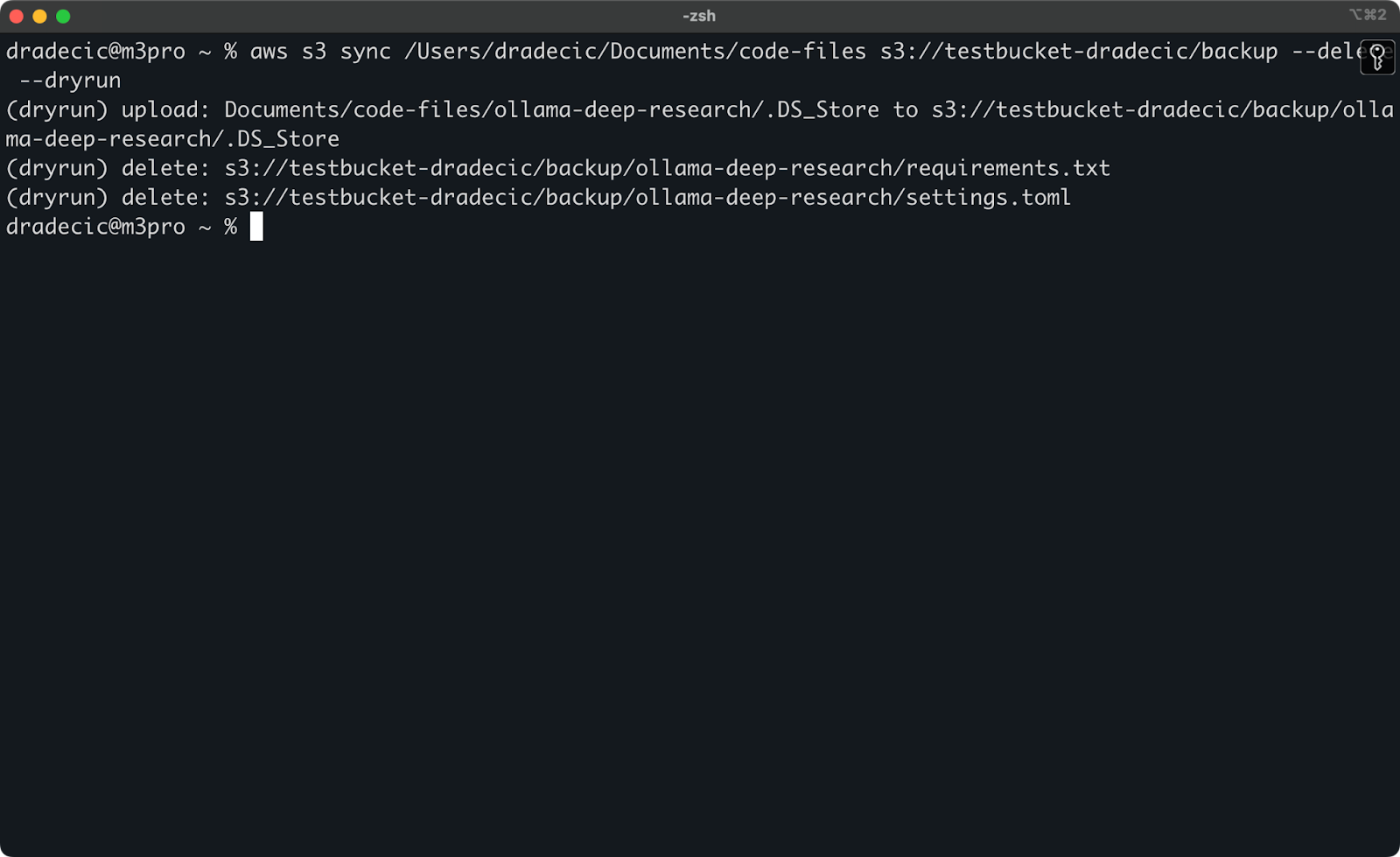
Изображение 17 – Пробный запуск
Это покажет вам точно, что произойдет, если бы вы запустили команду на самом деле, включая какие файлы будут загружены, загружены или удалены.
Я всегда рекомендую использовать --dryrun перед выполнением любой команды синхронизации S3 с флагом --delete, особенно при работе с важными данными.
Для команды синхронизации S3 доступно множество других параметров, таких как --acl для установки разрешений, --storage-class для выбора уровня хранения S3 и --recursive для обхода подкаталогов. Ознакомьтесь с официальной документацией AWS CLI для получения полного списка параметров.
Теперь, когда вы знакомы с основными и продвинутыми параметрами синхронизации S3, давайте рассмотрим, как использовать эти команды для практических сценариев, таких как резервное копирование и восстановление.
Использование синхронизации AWS S3 для резервного копирования и восстановления
Одним из наиболее популярных вариантов использования синхронизации S3 в AWS является создание резервных копий важных файлов и их восстановление по мере необходимости. Давайте рассмотрим, как вы можете реализовать простую стратегию резервного копирования и восстановления с помощью команды синхронизации.
Создание резервных копий в S3
Создание резервных копий с помощью синхронизации S3 просто — вам просто нужно выполнить команду синхронизации из вашего локального каталога в корзину S3. Однако есть несколько bewt bewt практик, которые следует соблюдать для эффективного создания резервных копий.
Во-первых, хорошей идеей будет организовать ваши резервные копии по дате или версии. Вот простой подход с использованием временной метки в пути S3:
# Создание переменной временной метки TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # Запуск резервного копирования aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
Это создает новую папку для каждой резервной копии с временной меткой вроде 2025-03-10-18-56-42. Вот что вы увидите на S3:
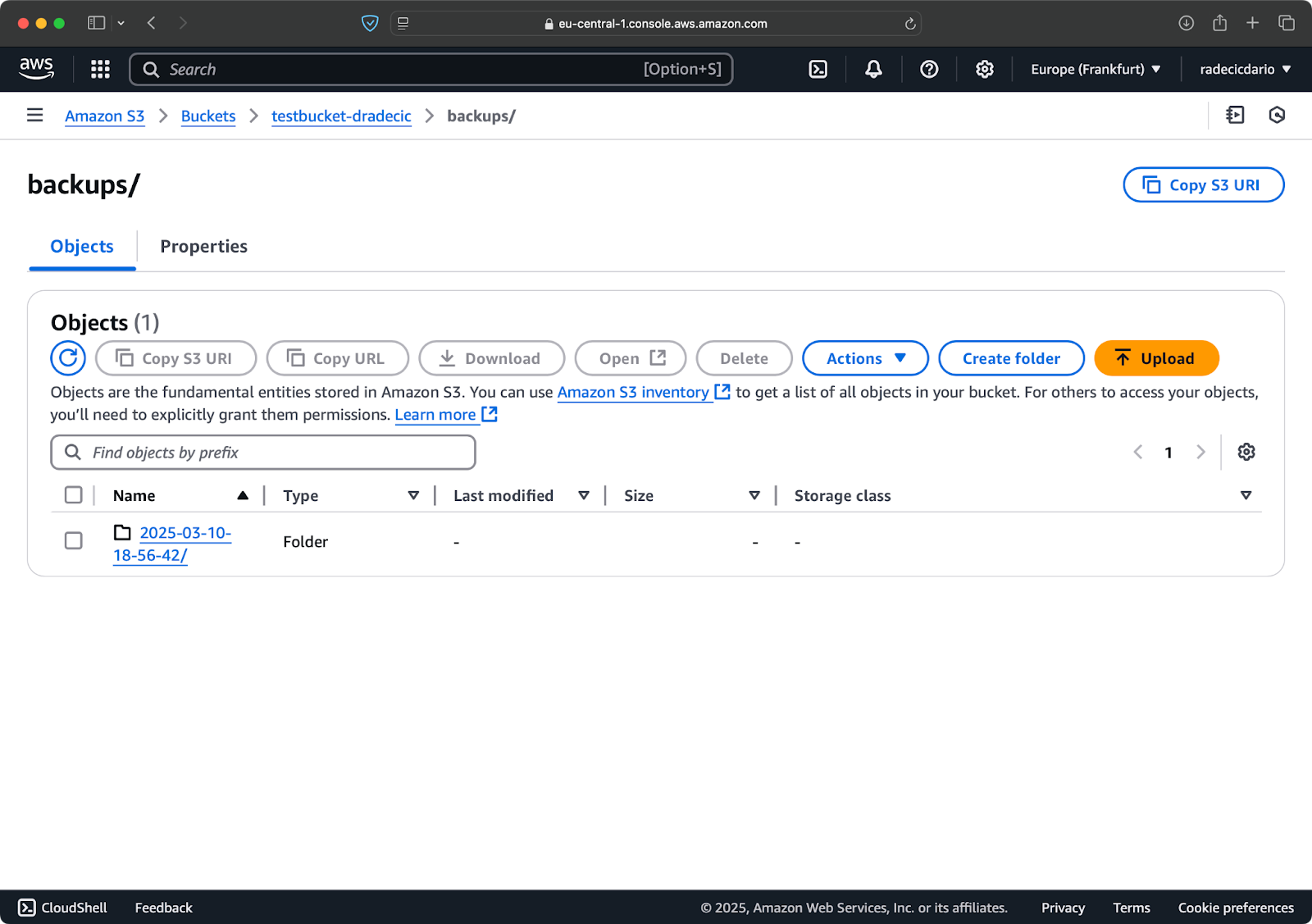
Изображение 18 – Резервные копии с меткой времени
Для критически важных данных вам может потребоваться хранить несколько версий резервных копий. Это легко сделать, просто запуская резервное копирование на основе времени регулярно.
Вы также можете использовать опцию --storage-class для указания более экономичного класса хранилища для ваших резервных копий:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
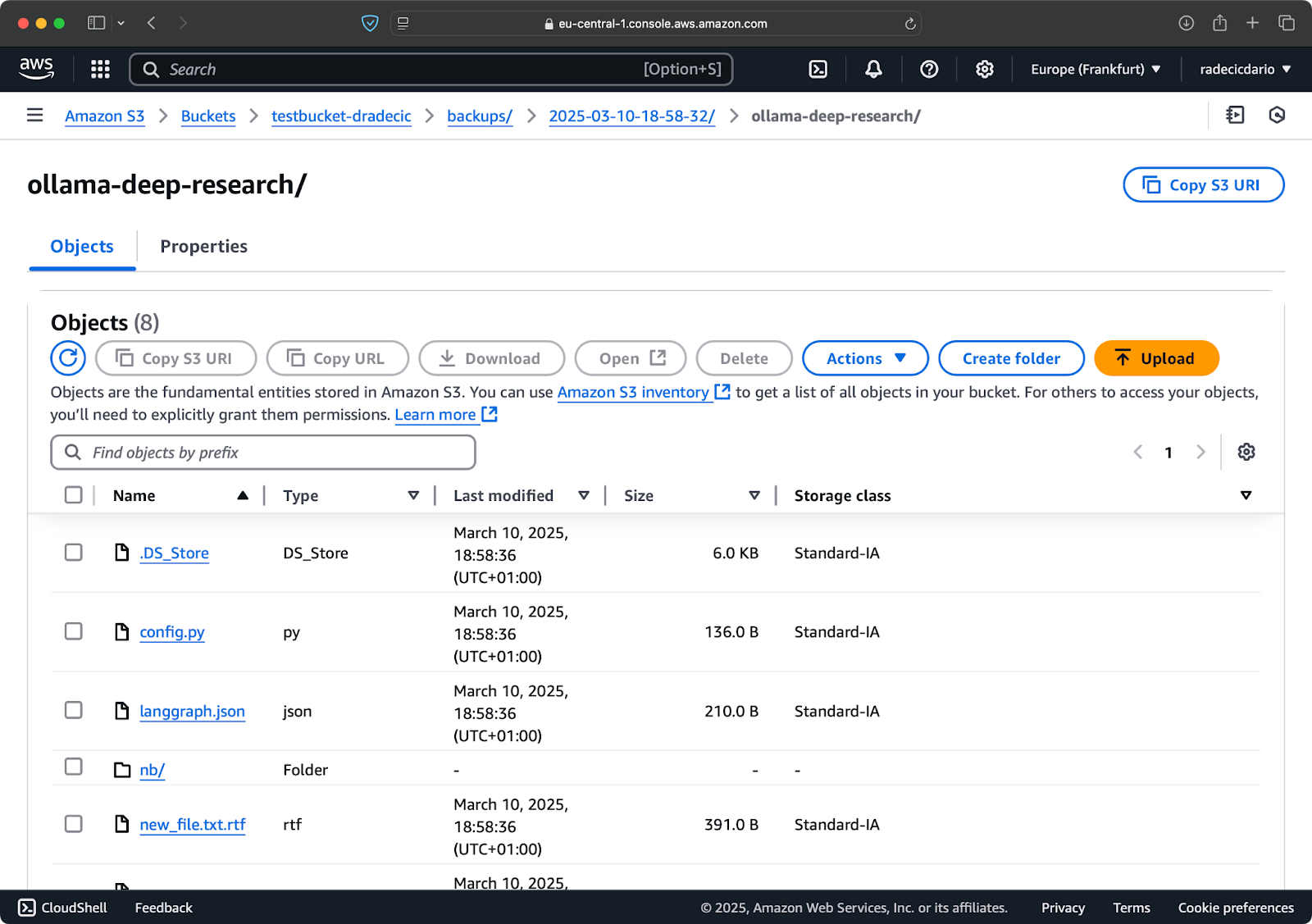
Изображение 19 – Содержимое резервной копии с пользовательским классом хранения
Это использует класс хранения S3 Infrequent Access, который стоит дешевле, но имеет небольшую плату за извлечение. Для долгосрочного архивирования вы даже можете использовать класс хранения Glacier:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
Просто помните, что файлы, хранящиеся в Glacier, требуют нескольких часов для извлечения, поэтому они не подходят для данных, к которым вам может понадобиться быстрый доступ.
Восстановление файлов из S3
Восстановление из резервной копии также просто – просто поменяйте местами исходный и целевой каталоги в вашей команде синхронизации:
# Восстановление из самой свежей резервной копии (при условии, что вы знаете временную метку) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
Это загрузит все файлы из этой конкретной резервной копии в ваш локальный каталог restored-data:
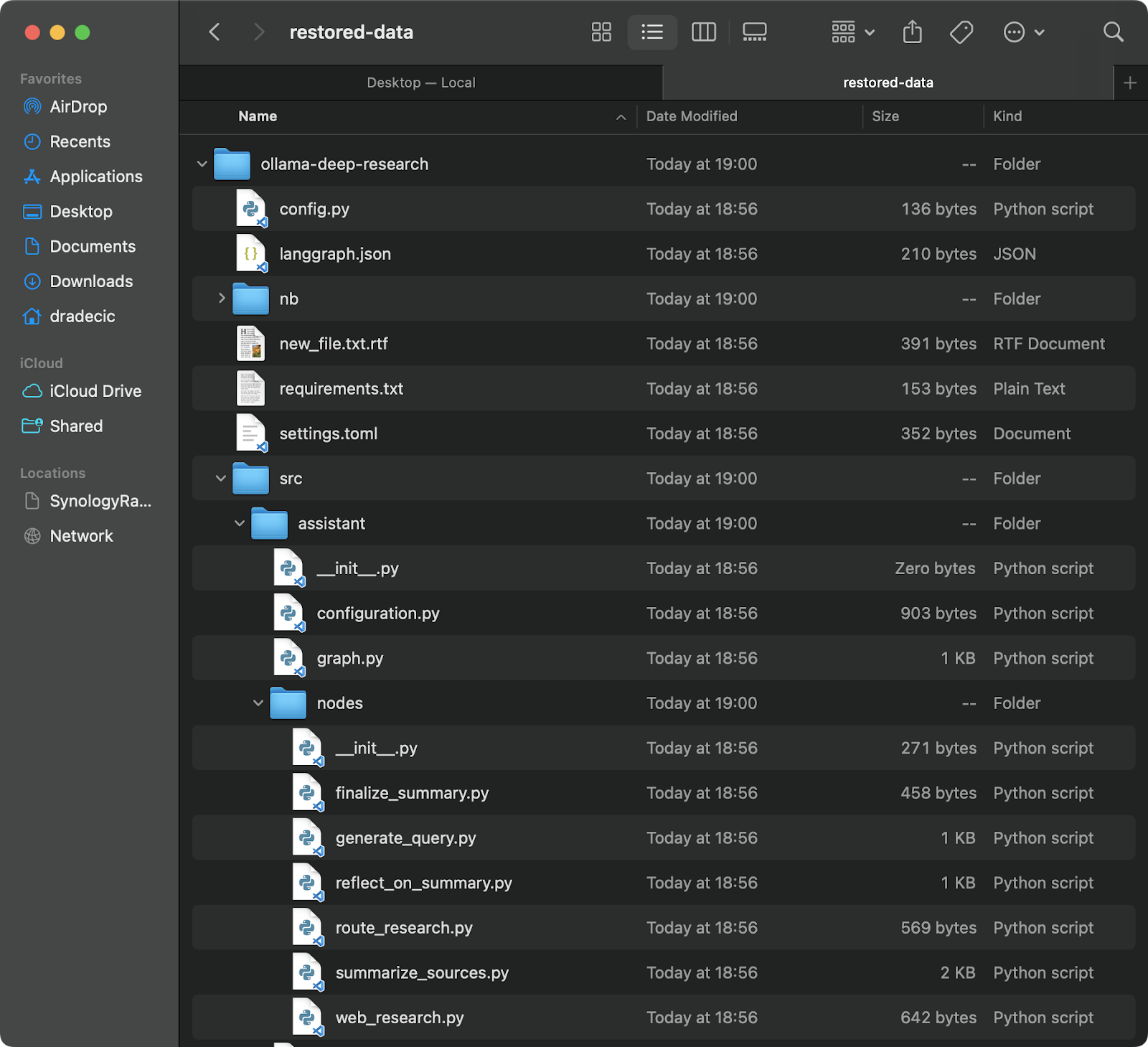
Изображение 20 – Восстановление файлов из S3
Если вы не помните точный момент времени, вы можете сначала перечислить все свои резервные копии:
aws s3 ls s3://testbucket-dradecic/backups/
Что покажет вам что-то вроде:
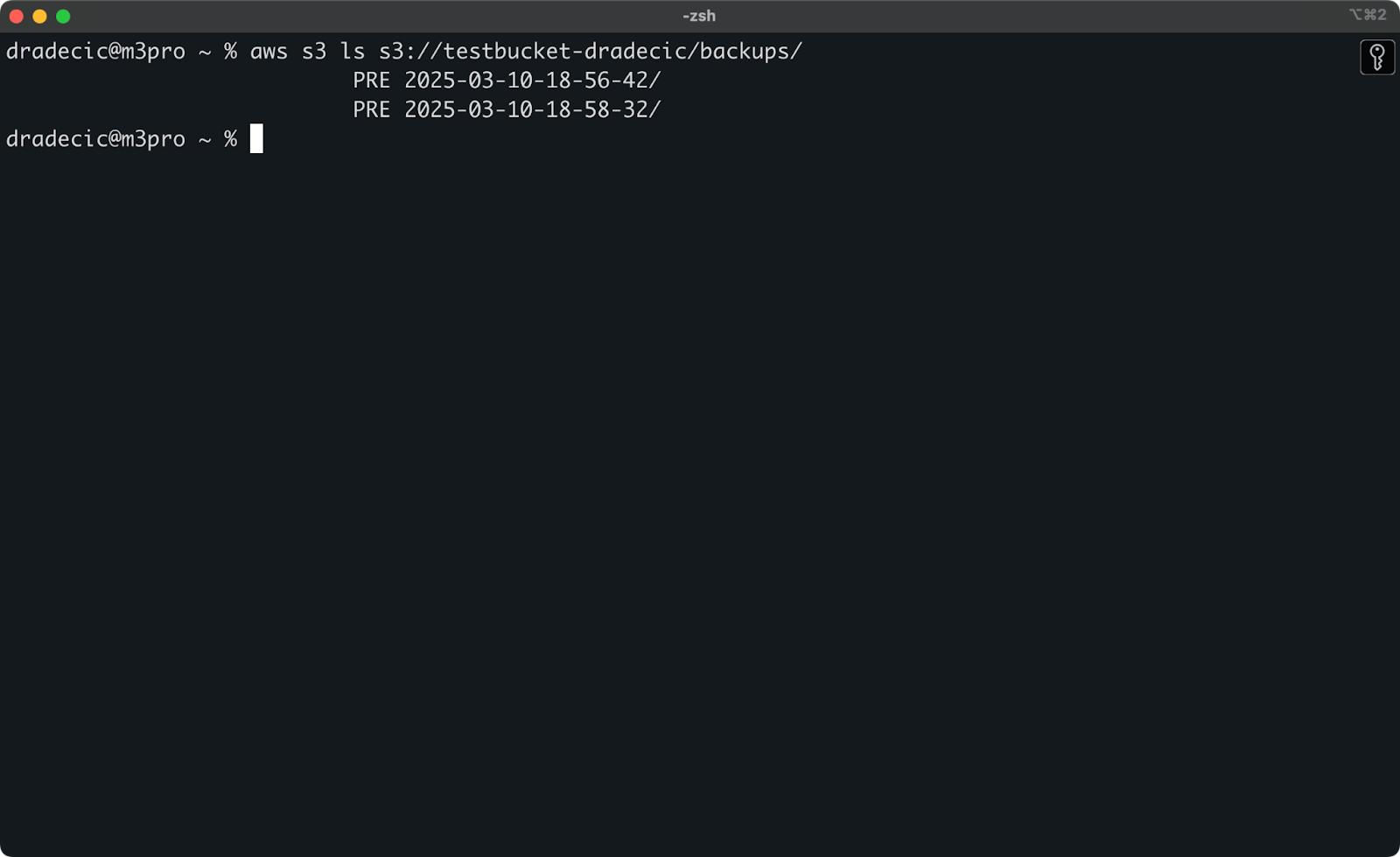
Изображение 21 – Список резервных копий
Вы также можете восстановить конкретные файлы или каталоги из резервной копии, используя флаги исключения/включения, о которых мы говорили ранее:
# Восстановить только файлы конфигурации aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
Для систем, критически важных для миссии, я рекомендую автоматизировать резервное копирование с помощью запланированных задач (например, через cron jobs в Linux/macOS или Планировщик задач в Windows). Это гарантирует, что вы регулярно делаете резервное копирование данных, не забывая делать это вручную.
Устранение неполадок синхронизации AWS S3
Синхронизация AWS S3 – надежный инструмент, но иногда могут возникать проблемы. Тем не менее, большинство ошибок, с которыми вы столкнетесь, обусловлены человеческим фактором.
Общие ошибки синхронизации
Давайте рассмотрим некоторые распространенные проблемы и их решения.
- Ошибка доступа запрещена обычно означает, что ваш пользователь IAM не имеет необходимых разрешений для доступа к ведру S3 или выполнения определенных операций. Чтобы исправить это, попробуйте одно из следующих действий:
- Проверьте, имеет ли ваш IAM-пользователь соответствующие разрешения S3 (
s3:ListBucket,s3:GetObject,s3:PutObject). - Убедитесь, что политика ведра явно не запрещает доступ вашему пользователю.
- Убедитесь, что само ведро не блокирует общедоступный доступ, если вам нужны публичные операции.
- Ошибка “No such file or directory” обычно появляется, когда указанный вами путь источника в команде синхронизации не существует. Решение проблемы простое – перепроверьте ваши пути и убедитесь, что они существуют. Уделите особое внимание опечаткам в названиях ведер или локальных каталогах.
- Ограничение размера файла ошибки могут возникать, когда вы хотите синхронизировать большие файлы. По умолчанию синхронизация S3 может обрабатывать файлы размером до 5 ГБ. Для файлов большего размера вы увидите тайм-ауты или неполные передачи.
- Для файлов размером более 5 ГБ следует использовать флаг
--only-show-errorsв сочетании с флагом--size-only. Это сочетание помогает при передаче больших файлов, минимизируя вывод и сравнивая только размеры файлов:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
Оптимизация производительности синхронизации
Если ваша синхронизация S3 работает медленнее, чем ожидалось, можно внести некоторые настройки для увеличения скорости.
- Используйте параллельные передачи. По умолчанию, синхронизация S3 использует ограниченное количество параллельных операций. Вы можете увеличить это с помощью параметра
--max-concurrent-requests:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- Настройте размер блока. Для больших файлов вы можете оптимизировать скорость передачи, изменив размер блока. Это разбивает большие файлы на блоки размером 16 МБ вместо 8 МБ по умолчанию, что может быть быстрее при хорошем сетевом подключении:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- Используйте
--no-progressдля скриптов. Если вы запускаете синхронизацию S3 в автоматизированном скрипте, используйте флаг--no-progress, чтобы уменьшить вывод и улучшить производительность:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- Используйте локальные конечные точки. Если ваши ресурсы AWS находятся в одном регионе, указание региональной конечной точки может снизить задержку:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
Эти оптимизации могут значительно улучшить производительность синхронизации, особенно при передаче больших объемов данных или при работе на менее мощных машинах.
Если проблемы сохраняются даже после попыток использования этих решений, у AWS CLI есть встроенная опция отладки. Просто добавьте --debug к вашей команде, чтобы увидеть подробную информацию о том, что происходит во время процесса синхронизации:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
Ожидайте увидеть много подробных сообщений журнала, подобных этим:
Изображение 22 – Запуск синхронизации в режиме отладки
И вот в основном все, что касается устранения неполадок синхронизации AWS S3. Конечно, могут возникнуть и другие ошибки, но в 99% случаев вы найдете решение в этом разделе.
Подводя итоги синхронизации AWS S3
В заключение, синхронизация AWS S3 – это один из тех редких инструментов, которые одновременно просты в использовании и невероятно мощны. Вы узнали все, начиная от базовых команд до расширенных опций, стратегий резервного копирования и советов по устранению неполадок.
Для разработчиков, системных администраторов или всех, кто работает с AWS, команда S3 sync – это неотъемлемый инструмент, который экономит время, снижает использование полосы пропускания и обеспечивает наличие ваших файлов там, где вам это нужно, когда вам это нужно.
Будь то резервное копирование критически важных данных, развертывание веб-ресурсов или просто синхронизация различных сред, AWS S3 sync делает процесс простым и надежным.
Лучший способ освоить синхронизацию S3 – начать использовать ее. Попробуйте настроить простую операцию синхронизации с собственными файлами, затем постепенно изучайте расширенные опции, чтобы подстроить их под ваши конкретные потребности.
Не забудьте всегда использовать --dryrun сначала при работе с важными данными, особенно при использовании флага --delete. Лучше потратить лишнюю минуту на проверку того, что произойдет, чем случайно удалить важные файлы.
Чтобы узнать больше о AWS, ознакомьтесь с этими курсами от DataCamp:
- Введение в AWS
- Технологии и сервисы облака AWS
- Безопасность и управление затратами в AWS
- Введение в AWS Boto на Python
Вы даже можете использовать DataCamp для подготовки к экзаменам на сертификацию AWS – AWS Cloud Practitioner (CLF-C02).