













AWS CLIとAWS S3の設定
S3とファイルを同期する前に、AWS CLIを適切に設定しておく必要があります。これは、AWSが初めての方には少し intimidating に聞こえるかもしれませんが、数分で済みます。
CLIの設定には、ツールのインストールと構成の2つの主要なステップがあります。次に、両方のステップについて説明します。
AWS CLIのインストール
AWS CLIのインストール方法は、使用しているオペレーティングシステムによってわずかに異なります。
Windowsシステムの場合:
- AWS CLIのダウンロードページにアクセスしてください。
- Windowsインストーラー(64ビット)をダウンロードします。
- インストーラーを実行し、指示に従ってください。
Linuxシステムの場合:
次の3つのコマンドをターミナルで実行します:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
macOSシステムの場合:
Homebrewがインストールされていると仮定して、次の1行をターミナルから実行します:
brew install awscli
Homebrewを持っていない場合は、代わりに次の2つのコマンドを使用してください:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
すべてのオペレーティングシステムでaws --versionコマンドを実行して、AWS CLIがインストールされていることを確認できます。以下に表示されるはずです:
画像1 – AWS CLIのバージョン
AWS CLIの構成
CLIがインストールされたら、AWSの資格情報を使用して設定する必要があります。
AWSアカウントを持っていると仮定し、IAMサービスにログインしてください。そこで新しいプログラムアクセス用のユーザーを作成します。ユーザーには、最低限S3アクセス権限を割り当てる必要があります:
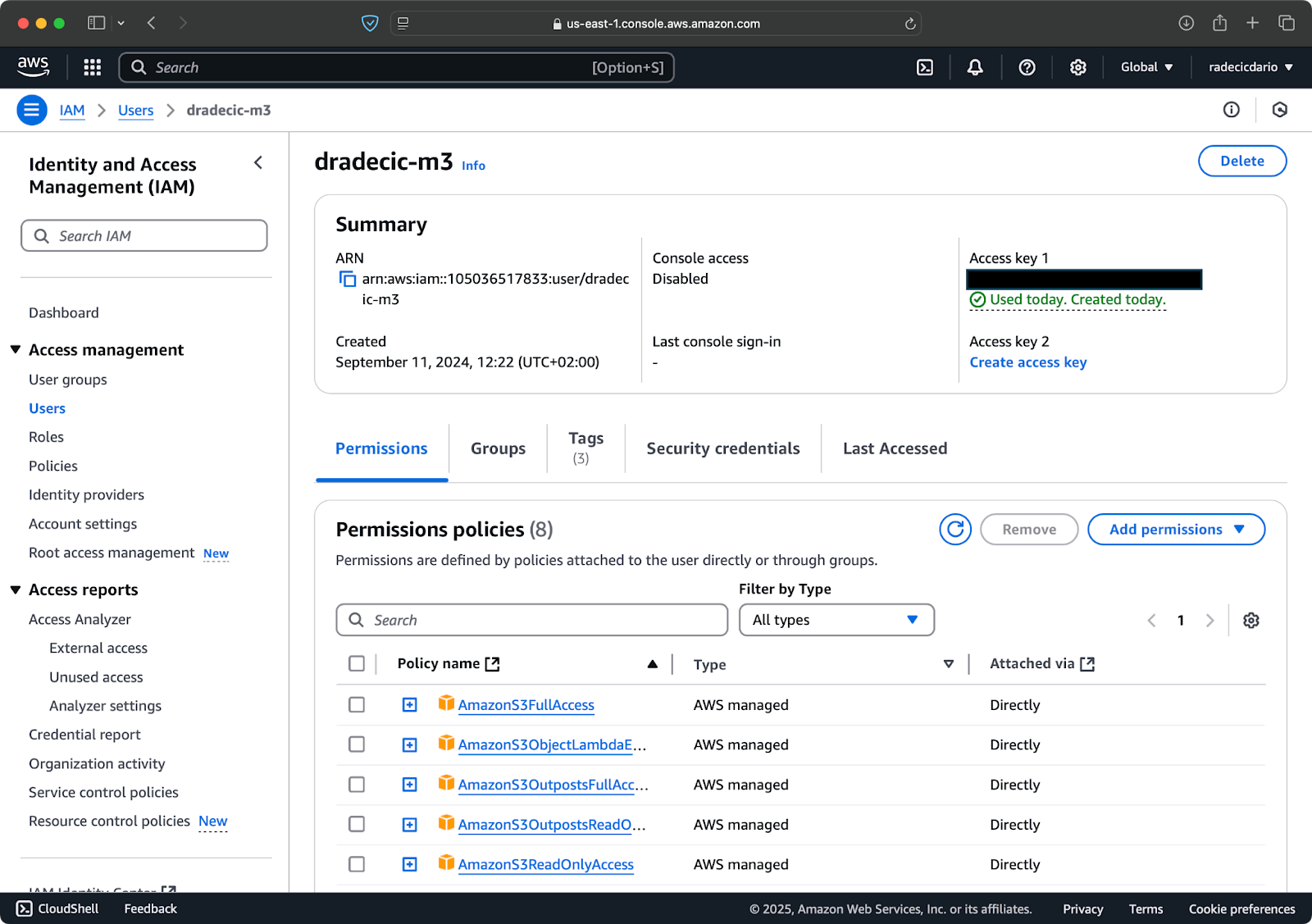
画像2 – AWS IAMユーザー
完了したら、「セキュリティ資格情報」に移動して新しいアクセスキーを作成します。作成した後、アクセスキーIDとシークレットアクセスキーが両方手に入ります。将来アクセスできなくなるため、安全な場所にメモしてください:
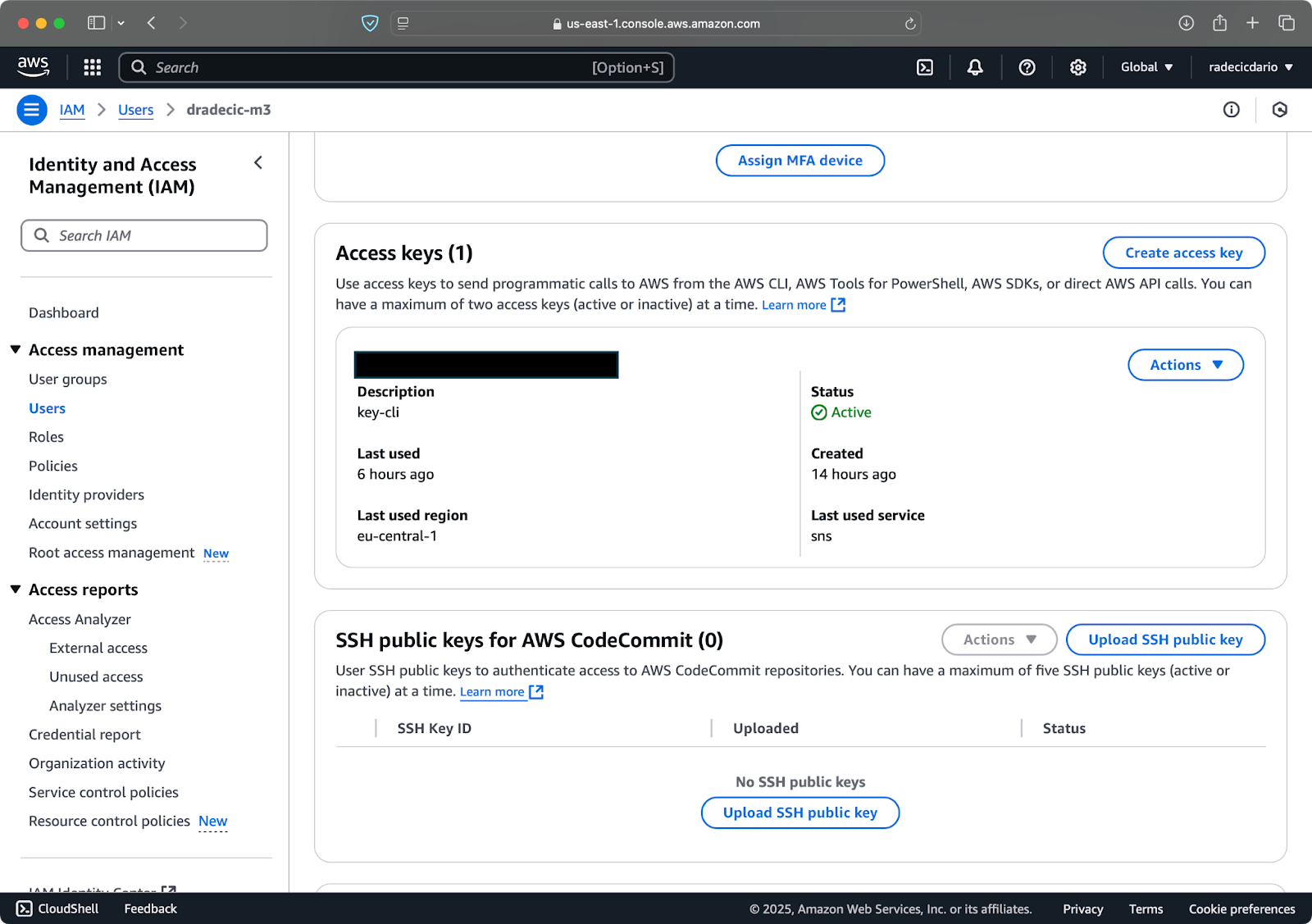
画像3 – AWS IAMユーザー資格情報
ターミナルで、aws configureコマンドを実行します。アクセスキーID、シークレットアクセスキー、リージョン(私の場合はeu-central-1)、および希望の出力形式(json)を入力するように求められます。
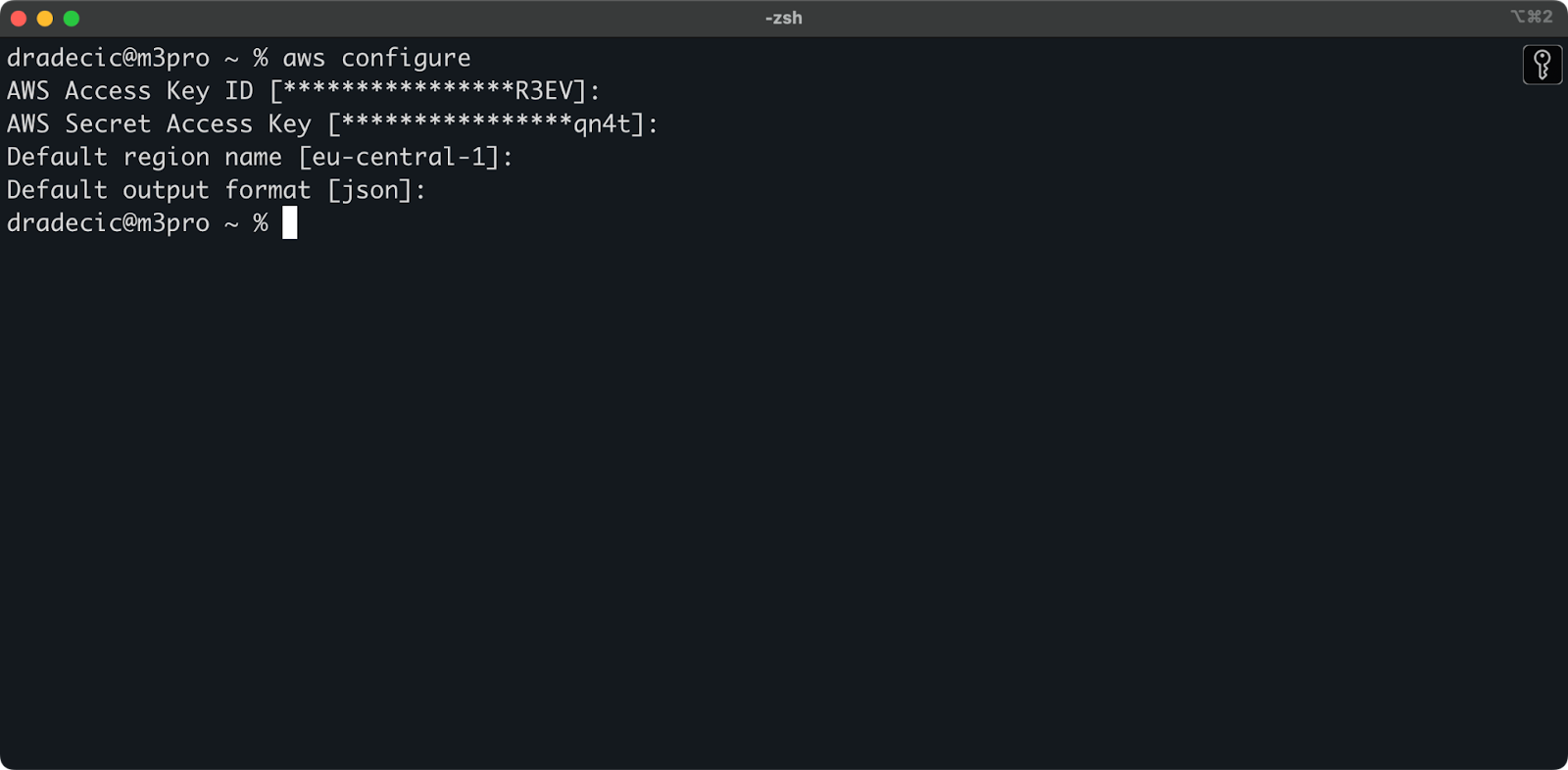
画像4 – AWS CLIの設定
CLIからAWSアカウントに正常に接続されていることを確認するには、次のコマンドを実行します:
aws sts get-caller-identity
表示される出力:
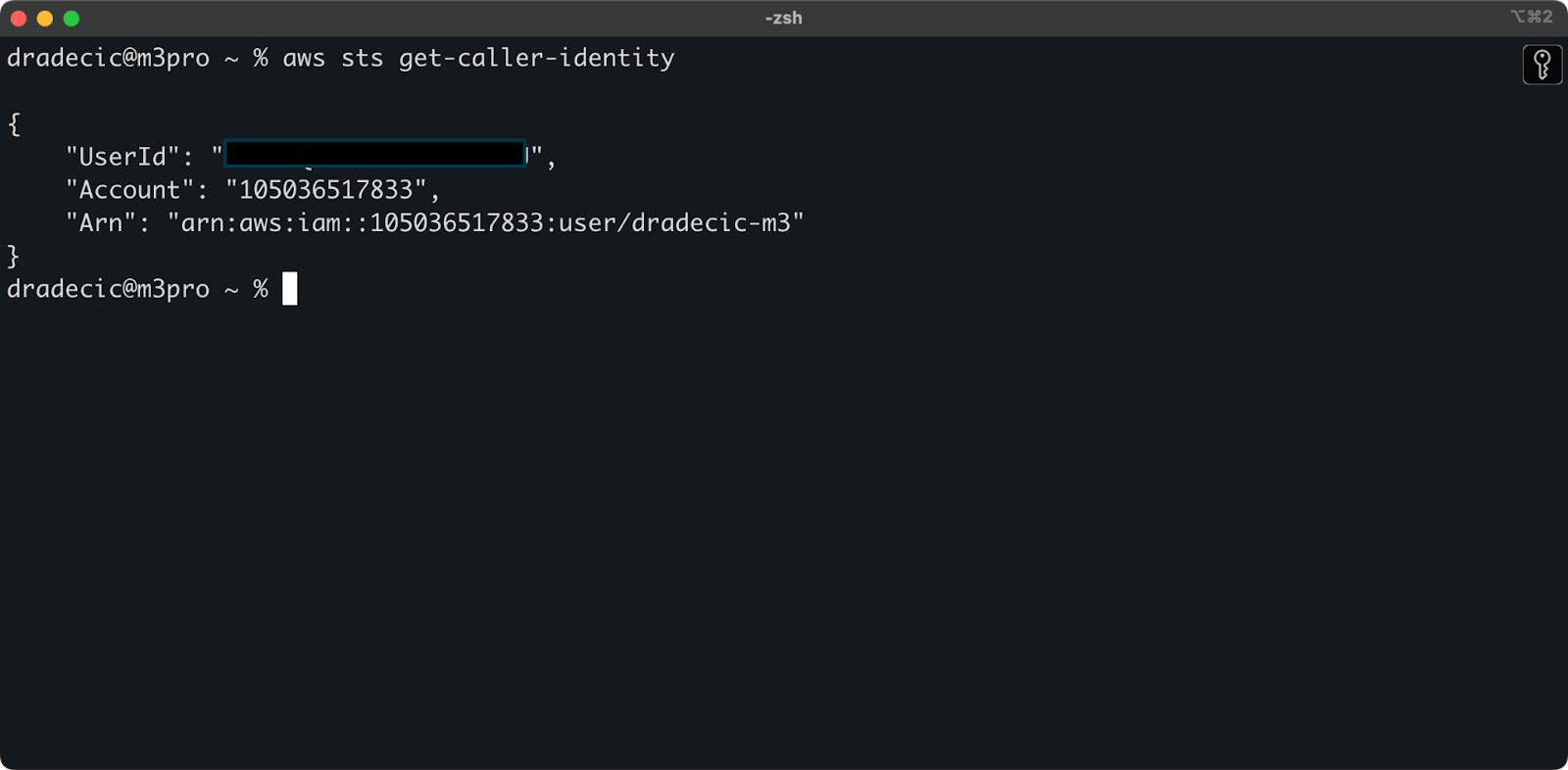
画像5 – AWS CLIテスト接続コマンド
以上で、S3同期コマンドを使用する前に行うべき最後のステップが1つだけ残っています!
AWS S3バケットの設定
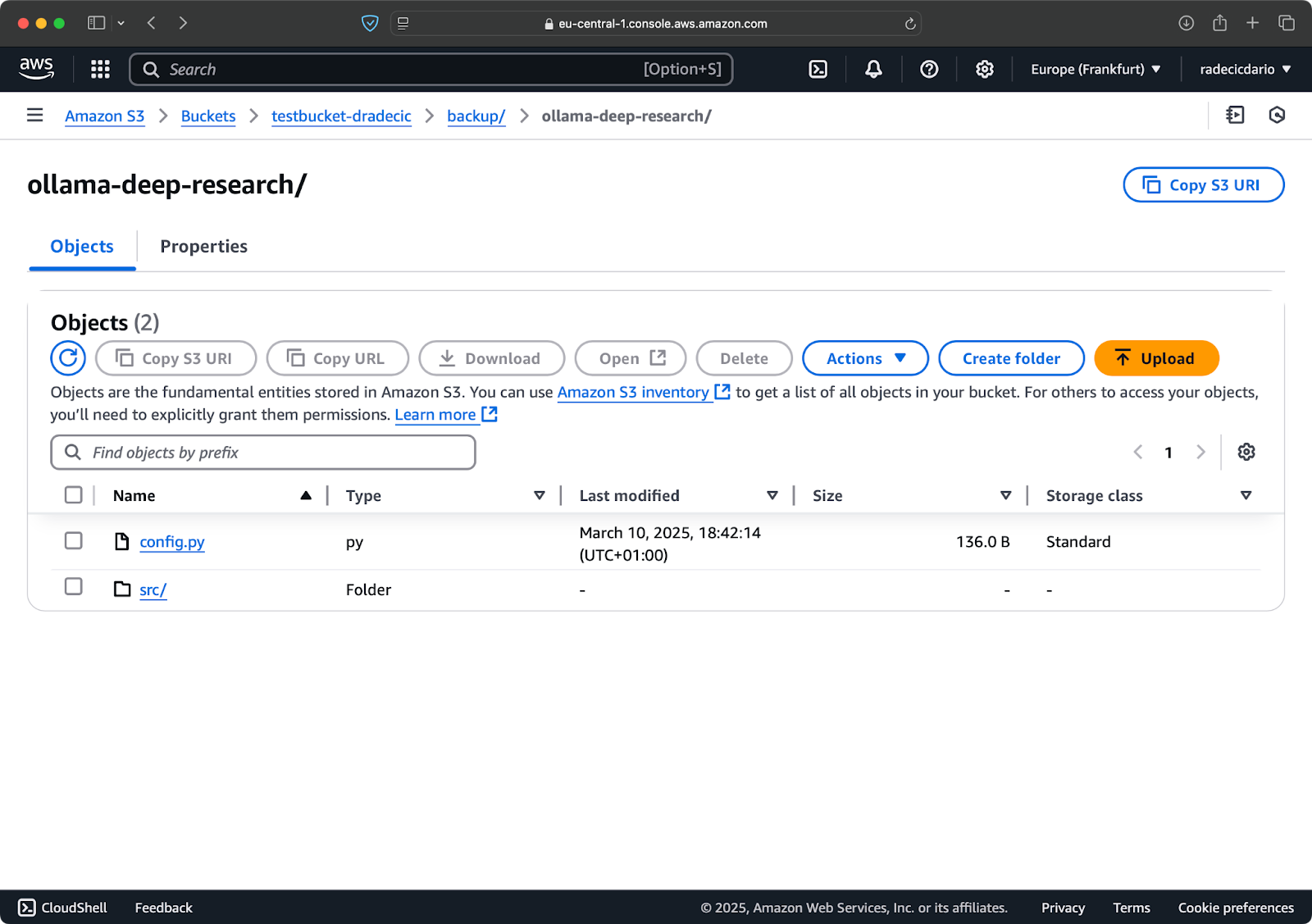
最後のステップは、同期されたファイルを保存するS3バケットを作成することです。CLIまたはAWSマネジメントコンソールから行うことができます。私は後者を選択します。
まず、管理コンソールのS3サービスページに移動し、「バケットの作成」ボタンをクリックします。そこで、ユニークなバケット名(AWS全体でグローバルにユニーク)を選択し、画面の一番下にスクロールして「作成」ボタンをクリックします:
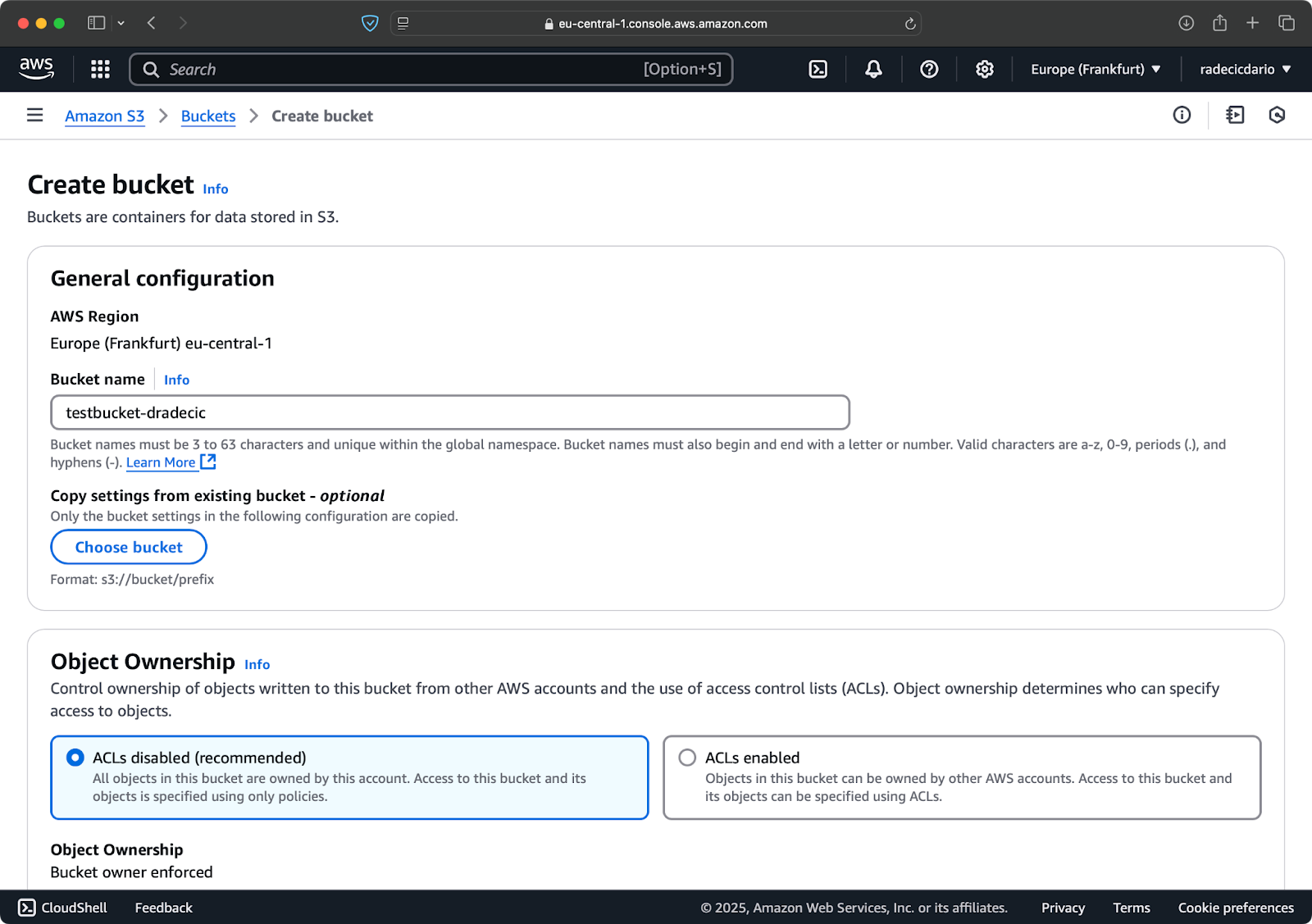
画像6 – AWSバケット作成
バケットが作成されました。マネジメントコンソールで即座に確認できます。CLIを使用して作成されたことを確認することもできます:
aws s3 ls
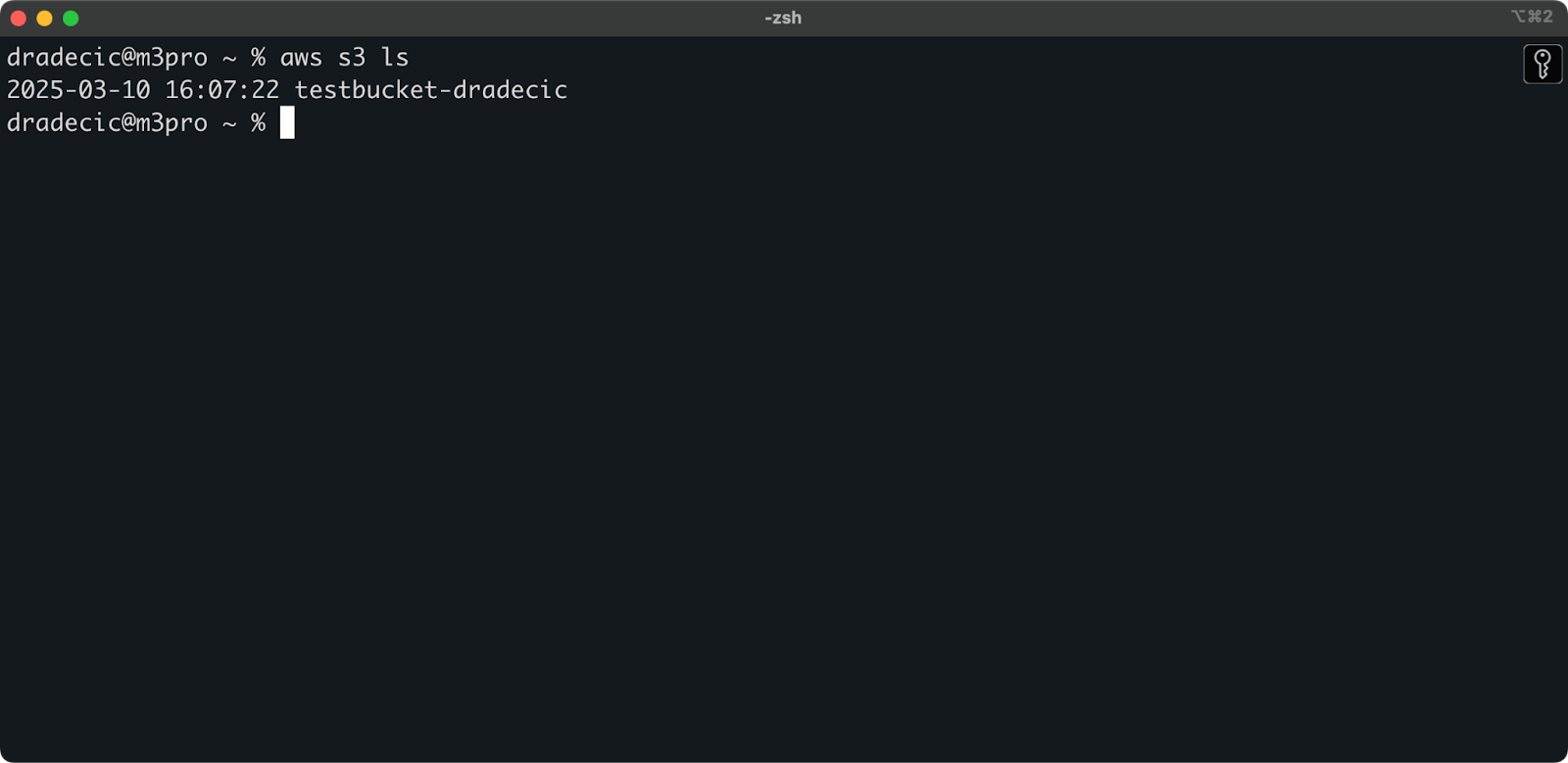
画像7 – 利用可能なすべてのS3バケット
デフォルトでは、S3 バケットはプライベートです。ウェブサイトのアセットなどの公開ファイルをホスティングする予定がある場合は、バケットポリシーとアクセス許可を適切に調整する必要があります。
これで準備が整い、ローカルマシンとAWS S3間でファイルを同期する準備が整いました!
基本的なAWS S3同期コマンド
AWS CLIがインストールされ、構成され、S3バケットが準備されたので、同期を開始する準備が整いました! AWS S3同期コマンドの基本的な構文は非常にわかりやすいです。それがどのように機能するかを示しましょう。
S3同期コマンドはこのシンプルなパターンに従います:
aws s3 sync <source> <destination> [options]
ソースと宛先は、ローカルディレクトリパスまたはS3 URI(s3://で始まる)のいずれかにすることができます。同期したい方法に応じて、これらを異なる方法で配置します。
ローカルからS3バケットへのファイルの同期
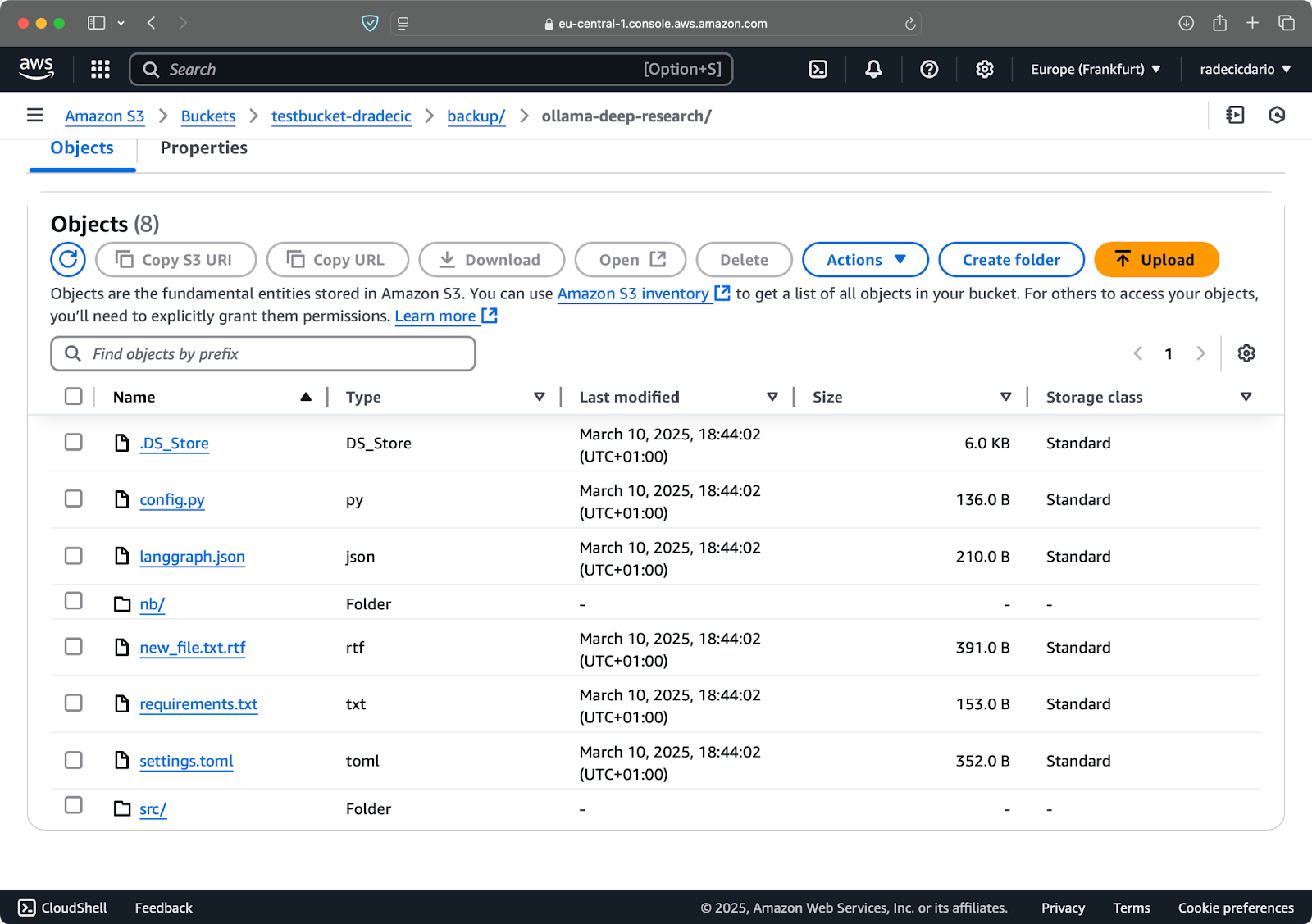
最近Ollama deep researchを試していました。これをS3に同期したいとします。メインディレクトリはDocumentsフォルダの下にあります。以下はその構造です:
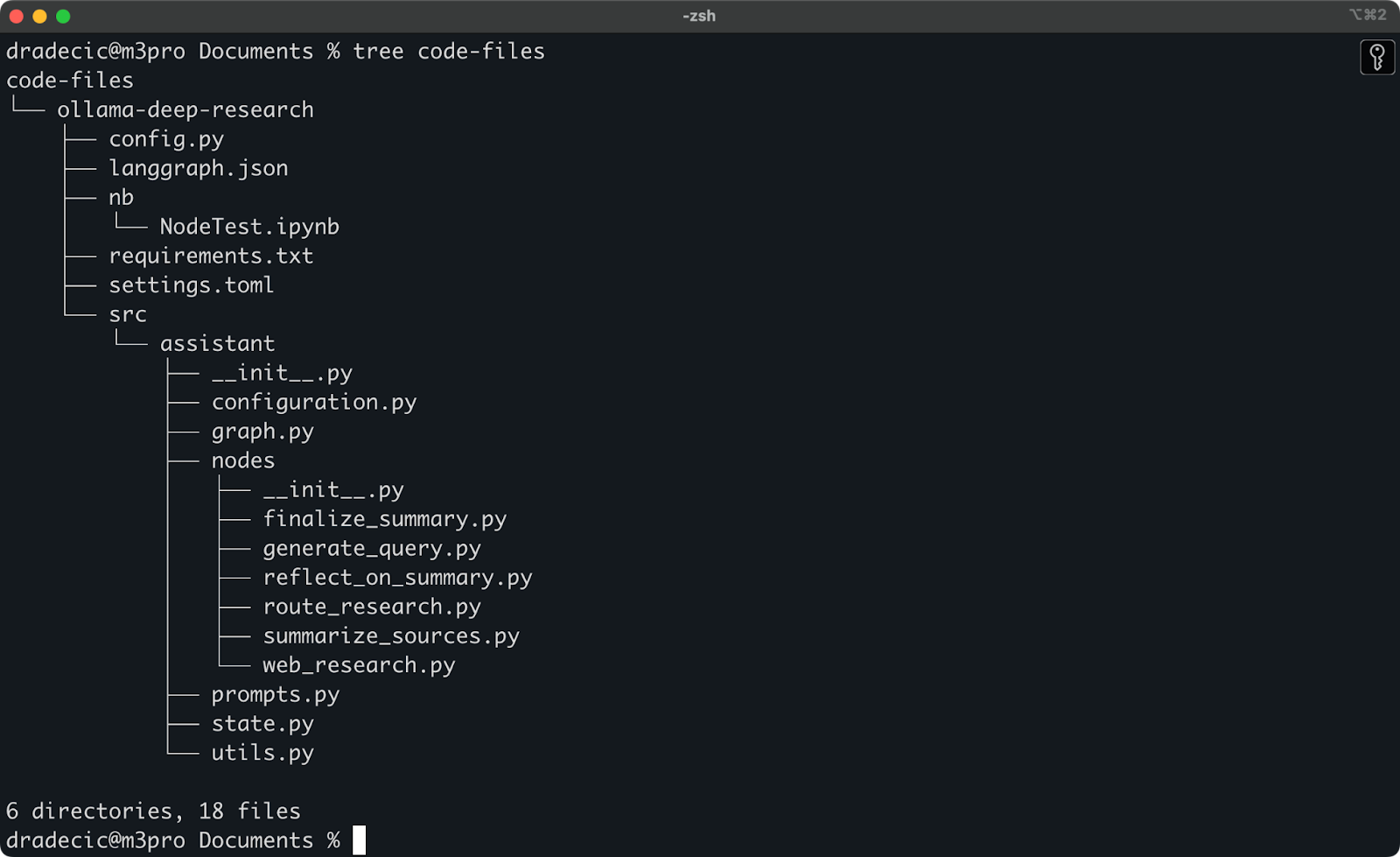
ローカルフォルダの内容
ローカルのcode-filesフォルダをS3バケットのbackupフォルダと同期するために実行する必要のあるコマンドです:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup
backupフォルダが存在しない場合、S3バケット上のbackupフォルダは自動的に作成されます。
コンソールに印刷される内容は次のとおりです:
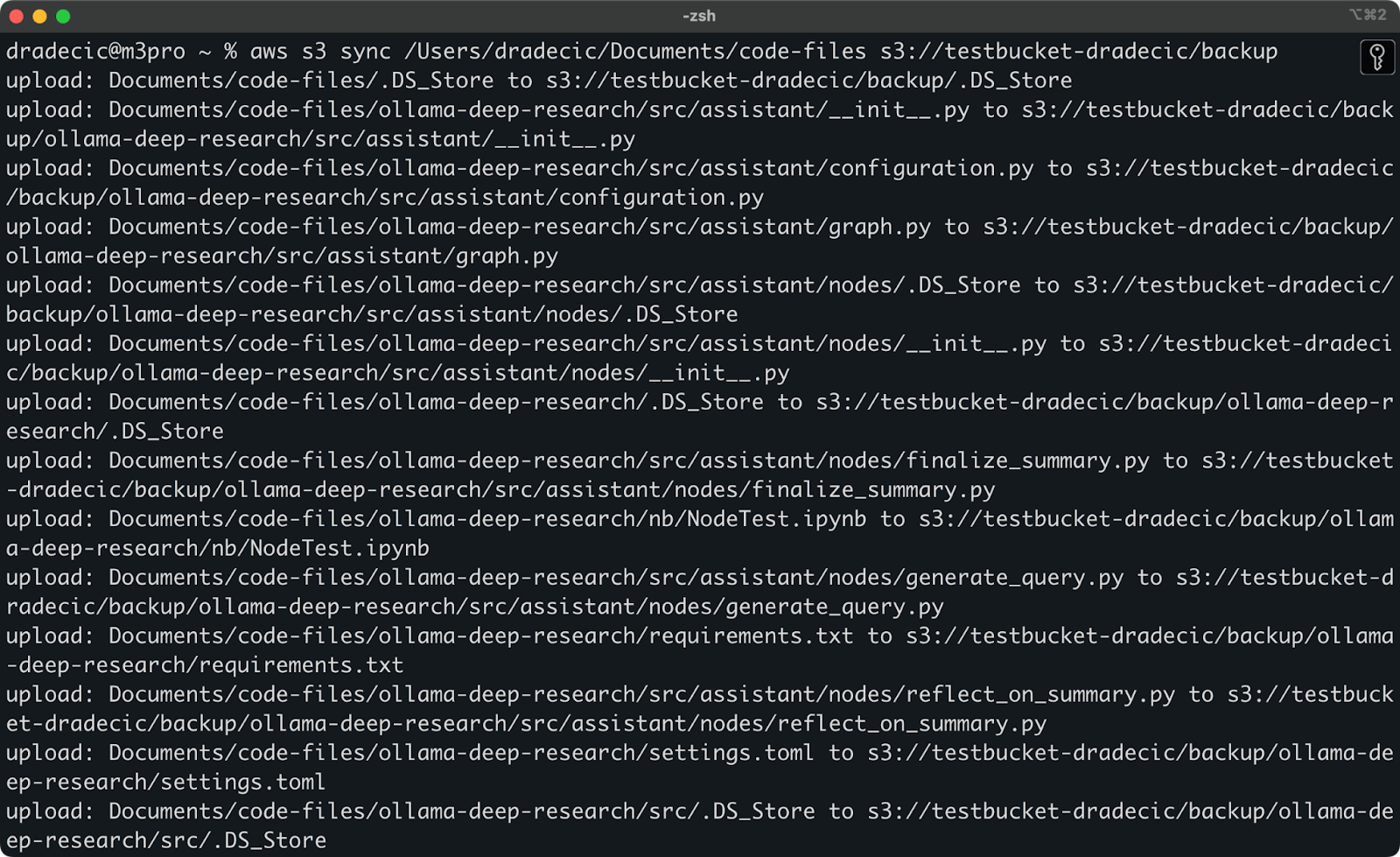
画像9 – S3同期プロセス
数秒後、ローカルcode-filesフォルダの内容がS3バケットで利用可能になります:
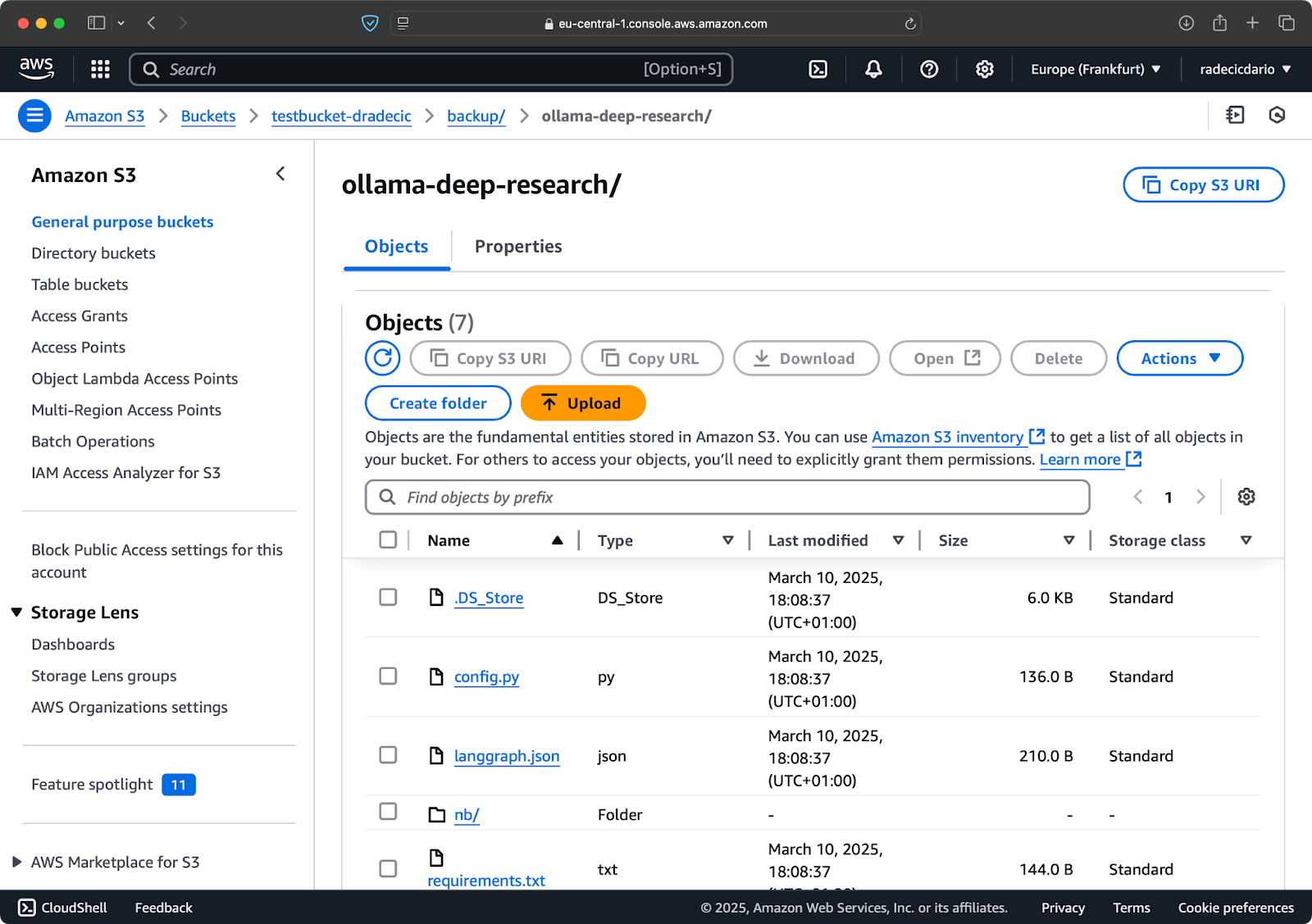
画像10 – S3バケットの内容
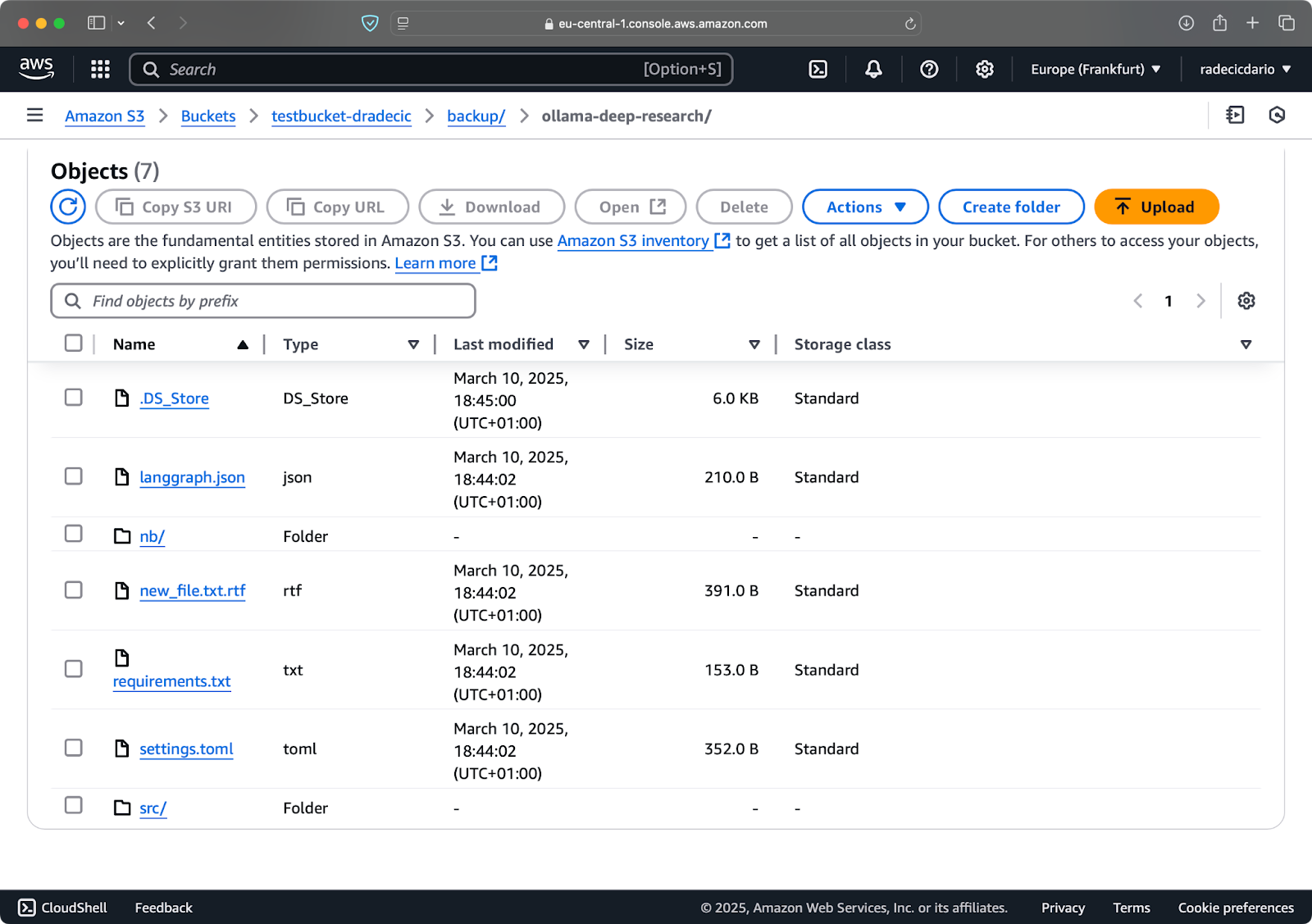
S3同期の美しいところは、宛先に存在しないファイルをアップロードするか、ローカルで変更されたファイルのみをアップロードすることです。同じコマンドを変更せずに再度実行すると、何も表示されません。これは、AWS CLIがすべてのファイルがすでに同期されて最新であることを検出したためです。
さて、2つの小さな変更を加えます – 新しいファイル(new_file.txt)を作成し、既存のファイル(requirements.txt)を更新します。同期コマンドを再度実行すると、新しいまたは変更されたファイルのみがアップロードされます:
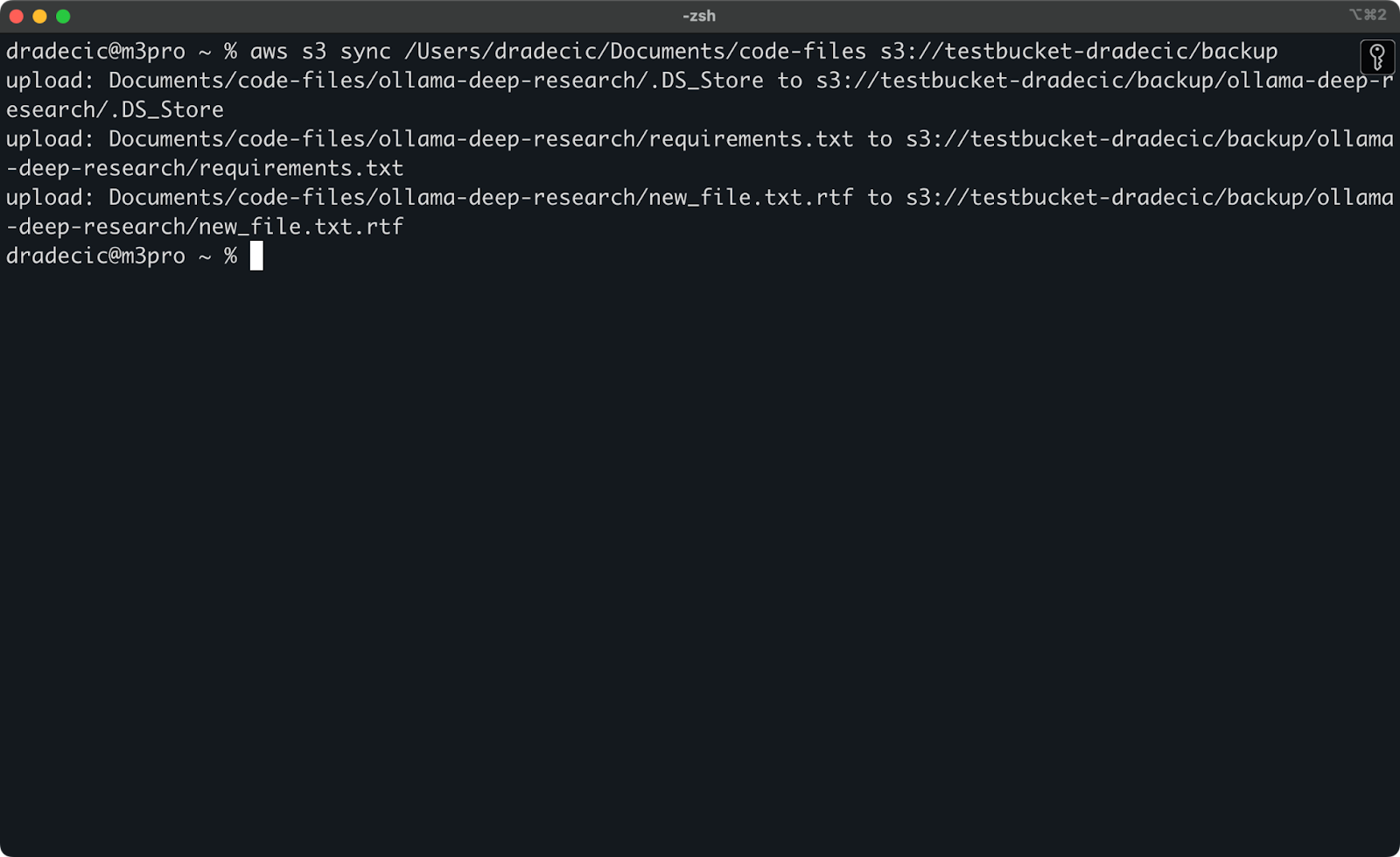
画像11 – S3同期プロセス(2)
ローカルフォルダをS3に同期する際に知っておくべきことはこれだけです。しかし、逆の方法はどうすればいいでしょうか?
S3バケットからローカルディレクトリにファイルを同期する
S3バケットからファイルをローカルマシンにダウンロードしたい場合は、ソースと宛先を入れ替えるだけです:
aws s3 sync s3://testbucket-dradecic/backup /Users/dradecic/Documents/code-files-from-s3
このコマンドは、S3バケット内のbackupフォルダ内のすべてのファイルをcode-files-from-s3という名前のローカルフォルダにダウンロードします。ローカルフォルダが存在しない場合、CLIが自動的に作成します:
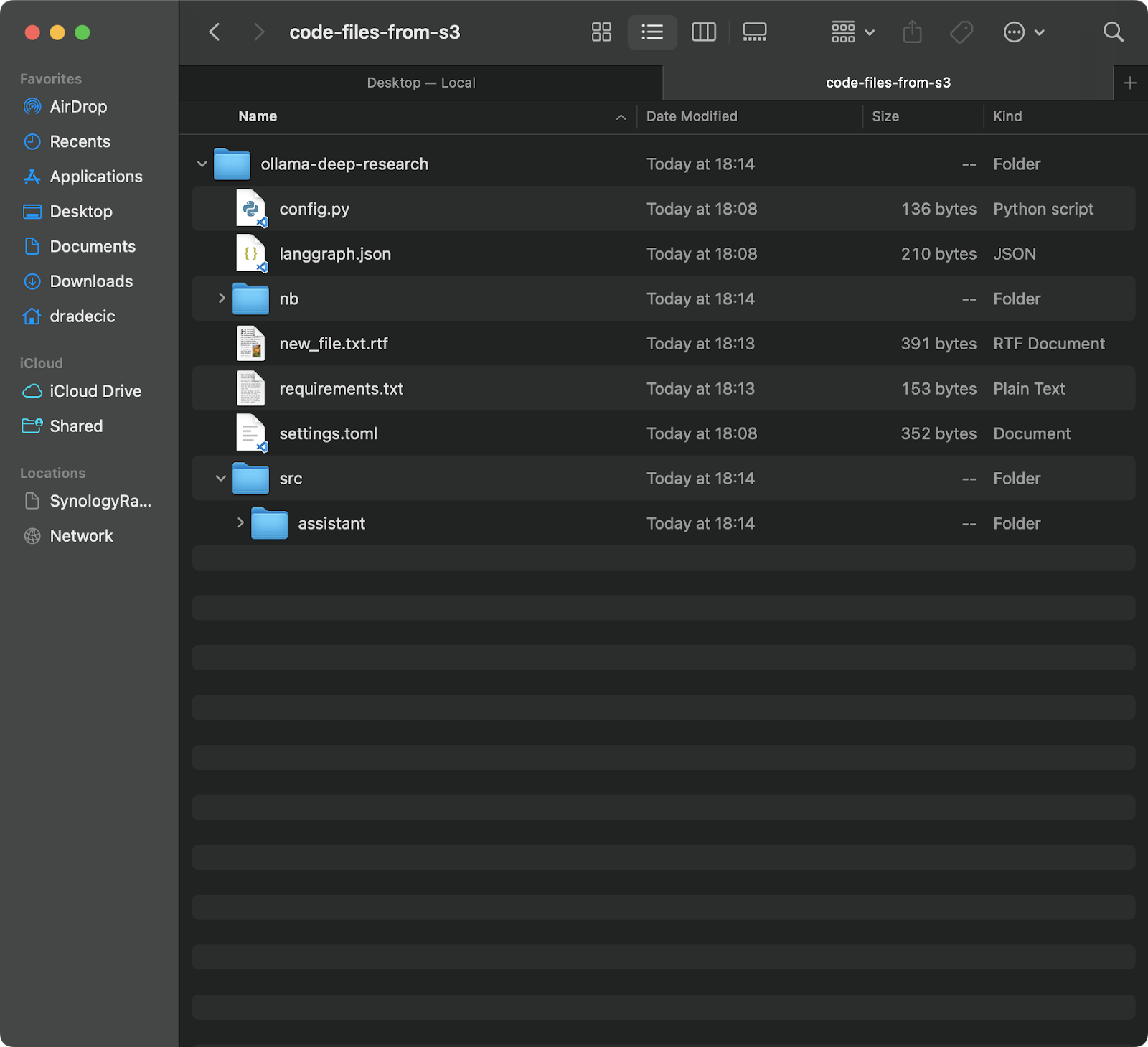
画像12 – S3からローカルへの同期
重要な点は、S3の同期は双方向ではないことです。ソースから宛先に向かうだけで、宛先をソースに一致させます。ローカルでファイルを削除してからそれをS3に同期しても、S3にはまだ存在します。同様に、S3でファイルを削除してからS3からローカルに同期した場合、ローカルのファイルはそのまま残ります。
宛先をソースとまったく一致させたい場合(削除を含む)、--deleteフラグを使用する必要があります。これについては、詳細なオプションセクションで説明します。
高度なAWS S3同期オプション
以前に探索した基本的なS3同期コマンドはそれ自体で強力ですが、AWSは同期プロセスをより細かく制御するための追加オプションを詰め込んでいます。
このセクションでは、基本コマンドに追加できる最も便利なフラグをいくつか紹介します。
新規または変更されたファイルの同期
デフォルトでは、S3同期はファイルサイズと変更時刻をチェックする基本的な比較メカニズムを使用してファイルが同期する必要があるかどうかを判断します。ただし、このアプローチは、特にサイズは同じでも変更されたファイルを扱う場合など、すべての変更を常にキャプチャできるわけではありません。
より正確な同期のために、--exact-timestampsフラグを使用できます:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exact-timestamps
これにより、S3の同期がミリ秒単位でタイムスタンプを比較することが強制されます。このフラグを使用すると、より詳細な比較が必要になるため、同期プロセスがわずかに遅くなることに注意してください。
特定のファイルの除外または含めること
時々、ディレクトリ内のすべてのファイルを同期したくない場合があります。おそらく、一時ファイル、ログ、または特定のファイルタイプ(私の場合は.DS_Storeなど)を除外したいと思うでしょう。そこで、--excludeおよび--includeフラグが役立ちます。
しかし、例を示すために、私がコードディレクトリを同期したいが、すべてのPythonファイルを除外したいとしましょう:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*.py"
今、S3に同期されるファイルははるかに少なくなりました:
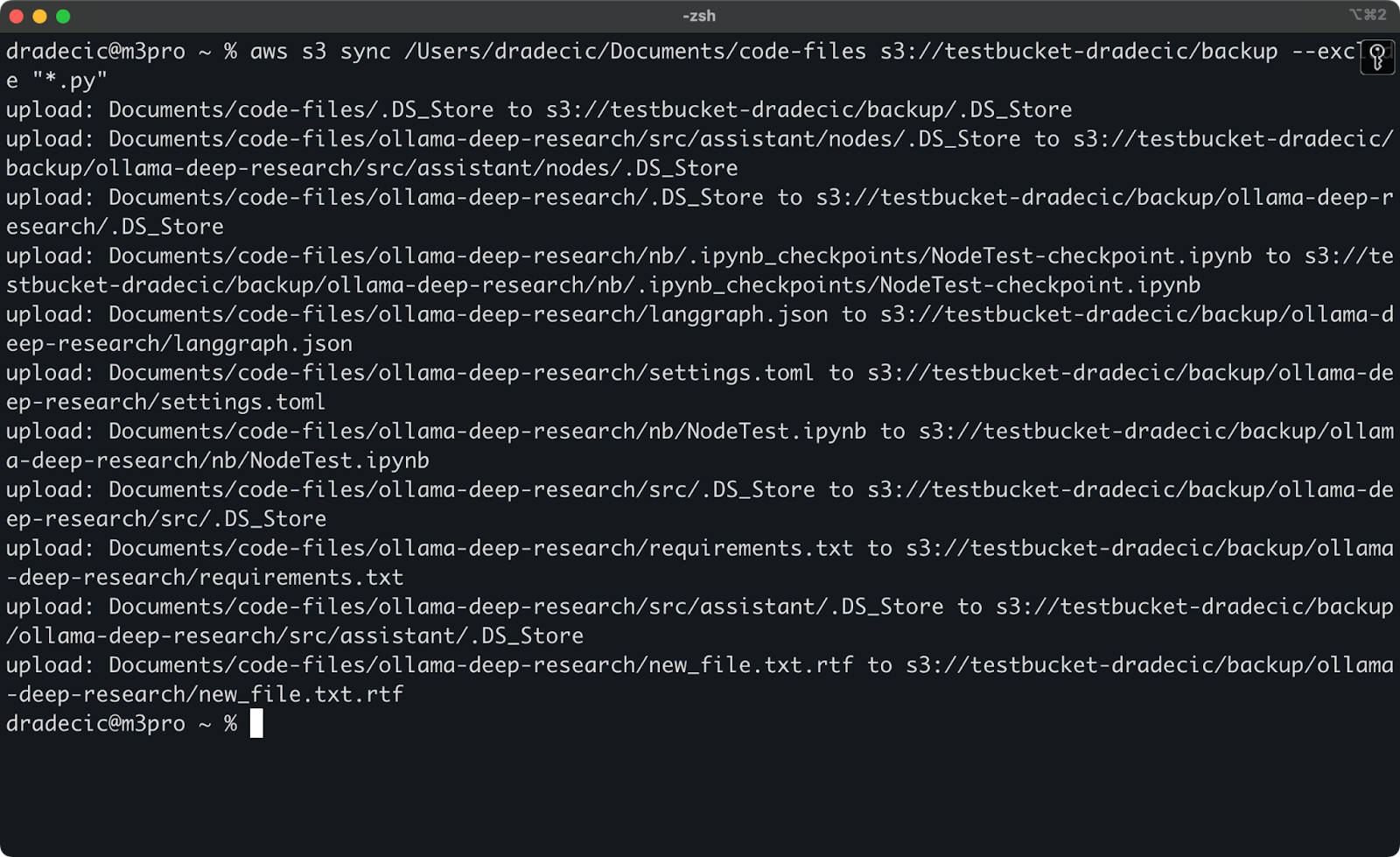
画像13 – Pythonファイルを除外したS3同期
--excludeと--includeを組み合わせて、より複雑なパターンを作成することもできます。例えば、Pythonファイル以外をすべて除外します:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --exclude "*" --include "*.py"
パターンは指定された順序で評価されるため、順序が重要です!これらのフラグを使用すると、次のようなものが表示されます:
画像14 – 除外と含めるフラグ
今、Pythonファイルのみが同期され、重要な設定ファイルが欠落しています。
宛先からファイルを削除
デフォルトでは、S3同期は宛先にファイルを追加または更新するだけで、ファイルを削除しません。つまり、ソースからファイルを削除しても、同期後には宛先にそのファイルが残ります。
削除を含むソースと宛先を完全にミラーリングするには、--deleteフラグを使用します。
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete
これを最初に実行すると、すべてのローカルファイルがS3に同期されます。
画像15 – 削除フラグ
これは、ディレクトリの正確なレプリカを維持するのに特に役立ちます。ただし、注意してください – このフラグを誤って使用するとデータが失われる可能性があります。
--deleteフラグを使用して同期コマンドを実行して、ローカルフォルダからconfig.pyを削除したとしましょう。
イメージ16 – 削除フラグ(2)
ご覧のとおり、このコマンドは新しいファイルと変更されたファイルだけでなく、ローカルディレクトリに存在しないファイルもS3バケットから削除します。
安全な同期のためのドライランの設定
最も危険なS3同期操作は、--deleteフラグを使用するものです。重要なファイルを誤って削除することを避けるために、--dryrunフラグを使用して、実際に変更を加えることなく操作をシミュレートできます:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --delete --dryrun
デモンストレーションとして、ローカルフォルダからrequirements.txtとsettings.tomlファイルを削除し、次のコマンドを実行しました:
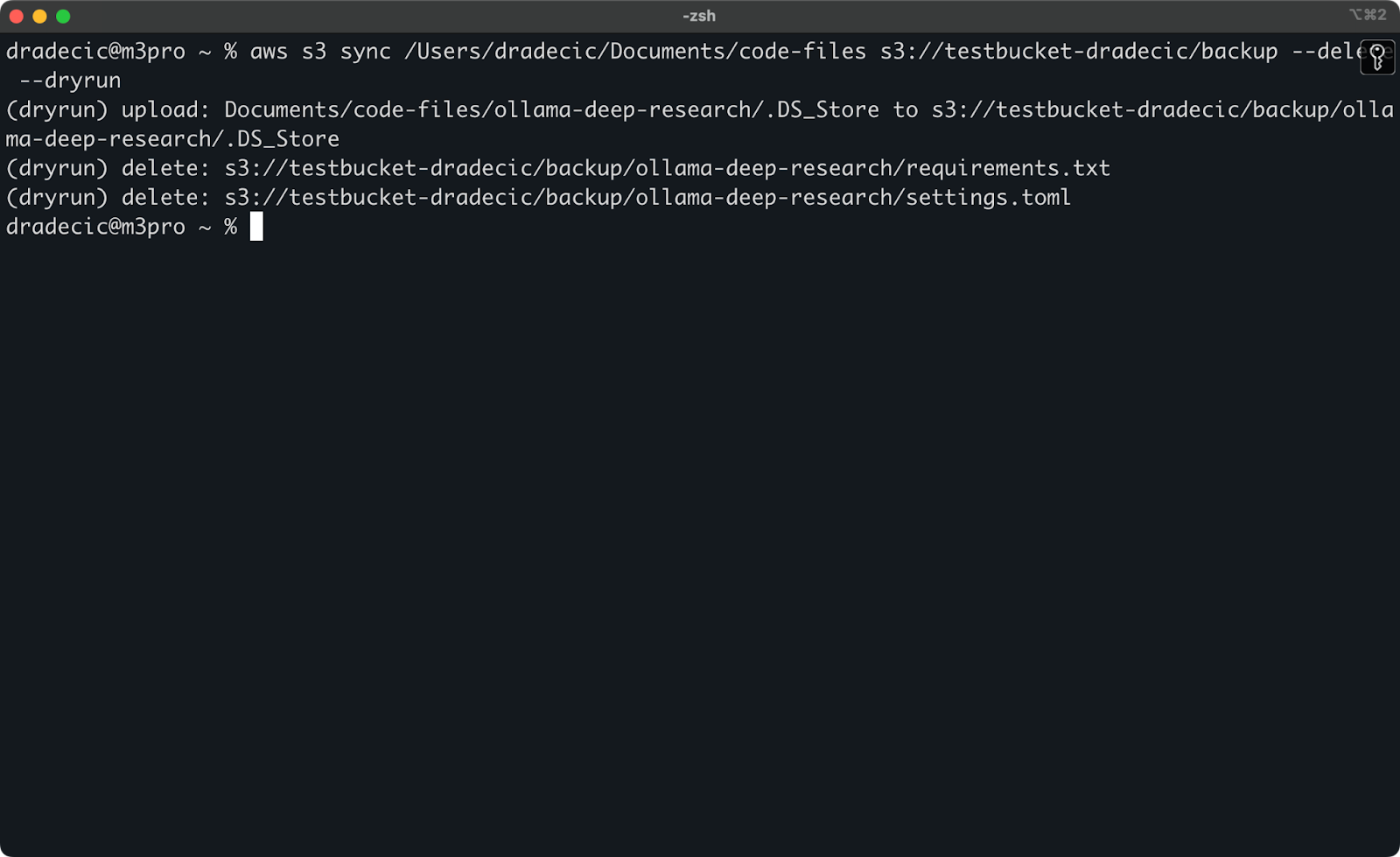
画像17 – ドライラン
これにより、コマンドを実際に実行した場合にどのファイルがアップロード、ダウンロード、または削除されるかなどが正確に表示されます。
重要なデータを扱う場合は特に、--deleteフラグを使用したS3同期コマンドを実行する前に常に--dryrunの使用をお勧めします。
S3 syncコマンドには、--aclを使用してアクセス権を設定するための他のオプションがたくさんあり、--storage-classを使用してS3ストレージティアを選択するためのオプションや、--recursiveを使用してサブディレクトリを移動するためのオプションなどがあります。完全なオプションリストは、公式AWS CLIドキュメントを確認してください。
基本的なおよび高度なS3同期オプションに精通したら、これらのコマンドをバックアップやリストアなどの実践的なシナリオにどのように使用するかを見てみましょう。
AWS S3をバックアップおよびリストアに使用する
AWS S3 syncの最も一般的な使用シナリオの1つは、重要なファイルのバックアップを作成し、必要に応じてそれらを復元することです。シンクコマンドを使用して簡単なバックアップおよびリストア戦略を実装する方法を探ってみましょう。
S3へのバックアップの作成
S3シンクを使用したバックアップの作成は簡単です。ローカルディレクトリからS3バケットへのシンクコマンドを実行するだけです。ただし、効果的なバックアップを行うためにはいくつかのベストプラクティスを遵守する必要があります。
まず、日付やバージョンごとにバックアップを整理するのが良い考えです。S3パスにタイムスタンプを使用したシンプルなアプローチをご紹介します:
# タイムスタンプ変数の作成 TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S) # バックアップの実行 aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP
これにより、2025-03-10-18-56-42のようなタイムスタンプが付いた新しいフォルダがそれぞれのバックアップごとに作成されます。S3上で表示される内容は以下の通りです:
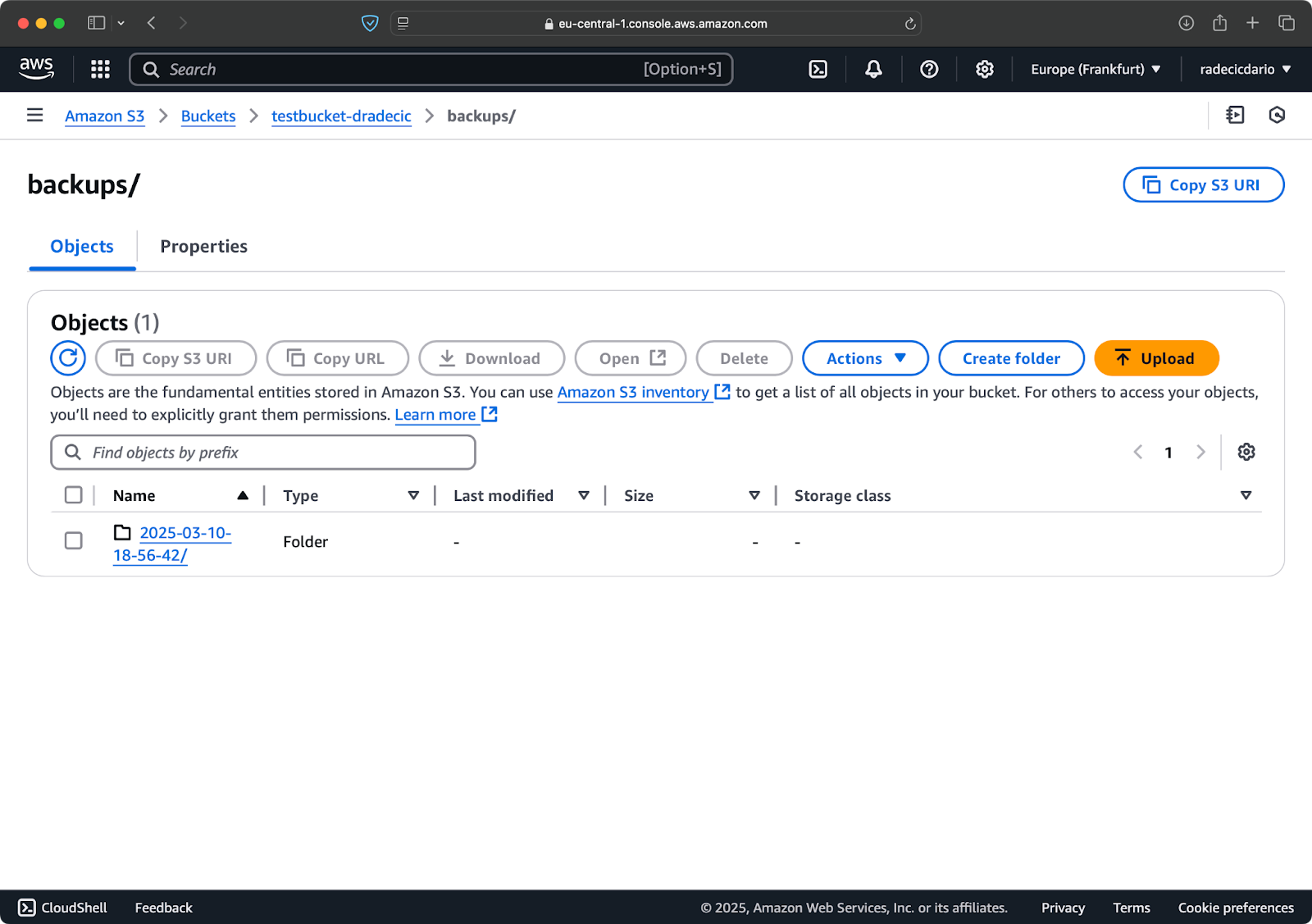
イメージ18 – タイムスタンプ付きバックアップ
重要なデータについては、複数のバックアップバージョンを保持することが望ましい場合があります。これは、タイムスタンプベースのバックアップを定期的に実行するだけで簡単に行うことができます。
--storage-classオプションを使用して、バックアップ用により費用対効果の高いストレージクラスを指定することもできます。バックアップ:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class STANDARD_IA
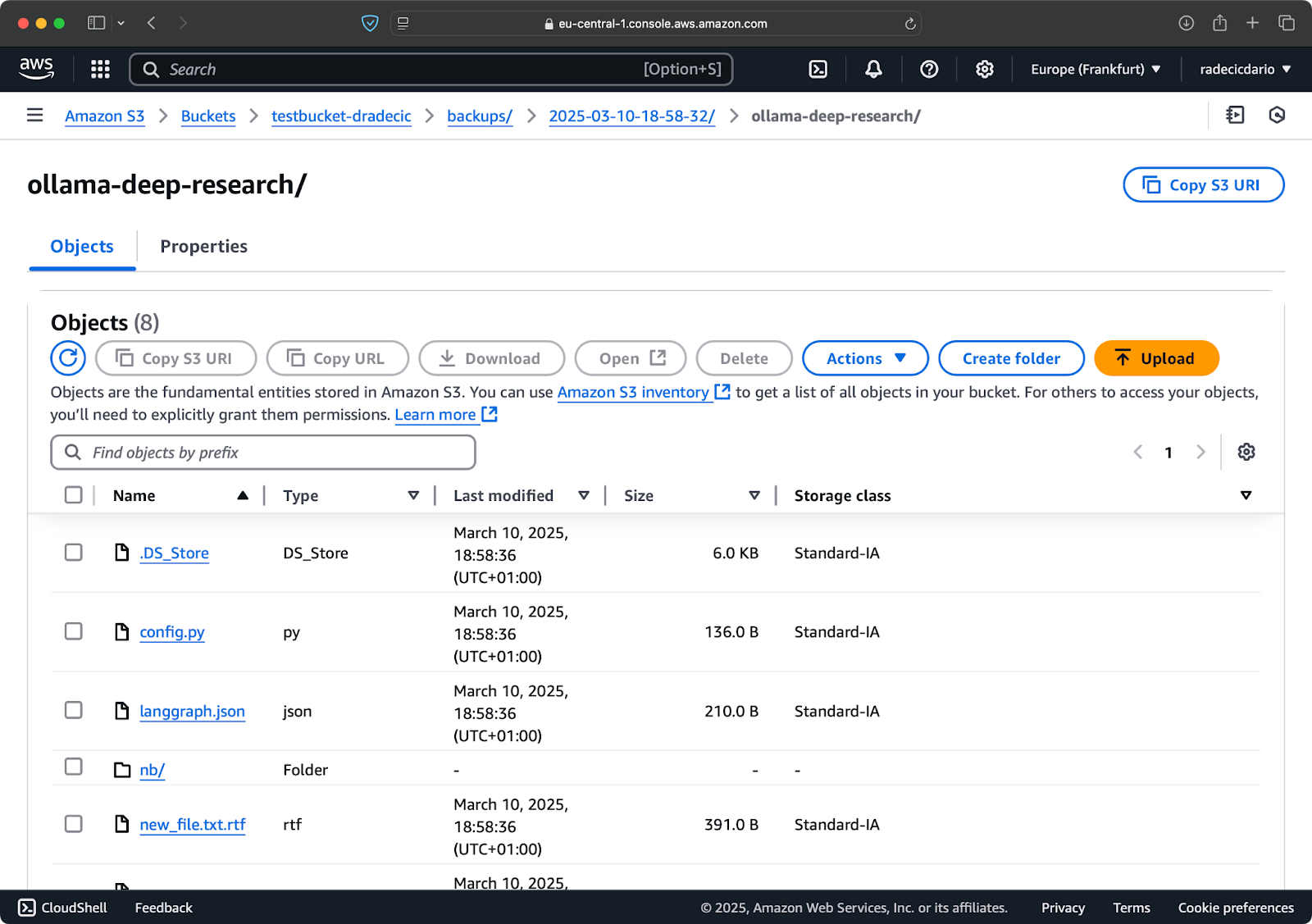
イメージ19 – カスタムストレージクラスを使用したバックアップ内容
これは S3 の低頻度アクセスストレージクラスを使用しており、コストは安くなりますが、若干の取り出し料金がかかります。長期アーカイブ用には、Glacier ストレージクラスを使用することもできます:
aws s3 sync /Users/dradecic/Documents/important-data s3://testbucket-dradecic/backups/$TIMESTAMP --storage-class GLACIER
ただし、Glacier に保存されたファイルの取得には時間がかかるため、迅速に必要なデータには適していません。
S3 からファイルを復元する
バックアップからの復元も同様に簡単です – 単に同期コマンドでソースと宛先を逆に指定するだけです:
# 最新のバックアップから復元する場合(タイムスタンプを知っていると仮定) aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-data
特定のバックアップからすべてのファイルをローカルのrestored-dataディレクトリにダウンロードします:
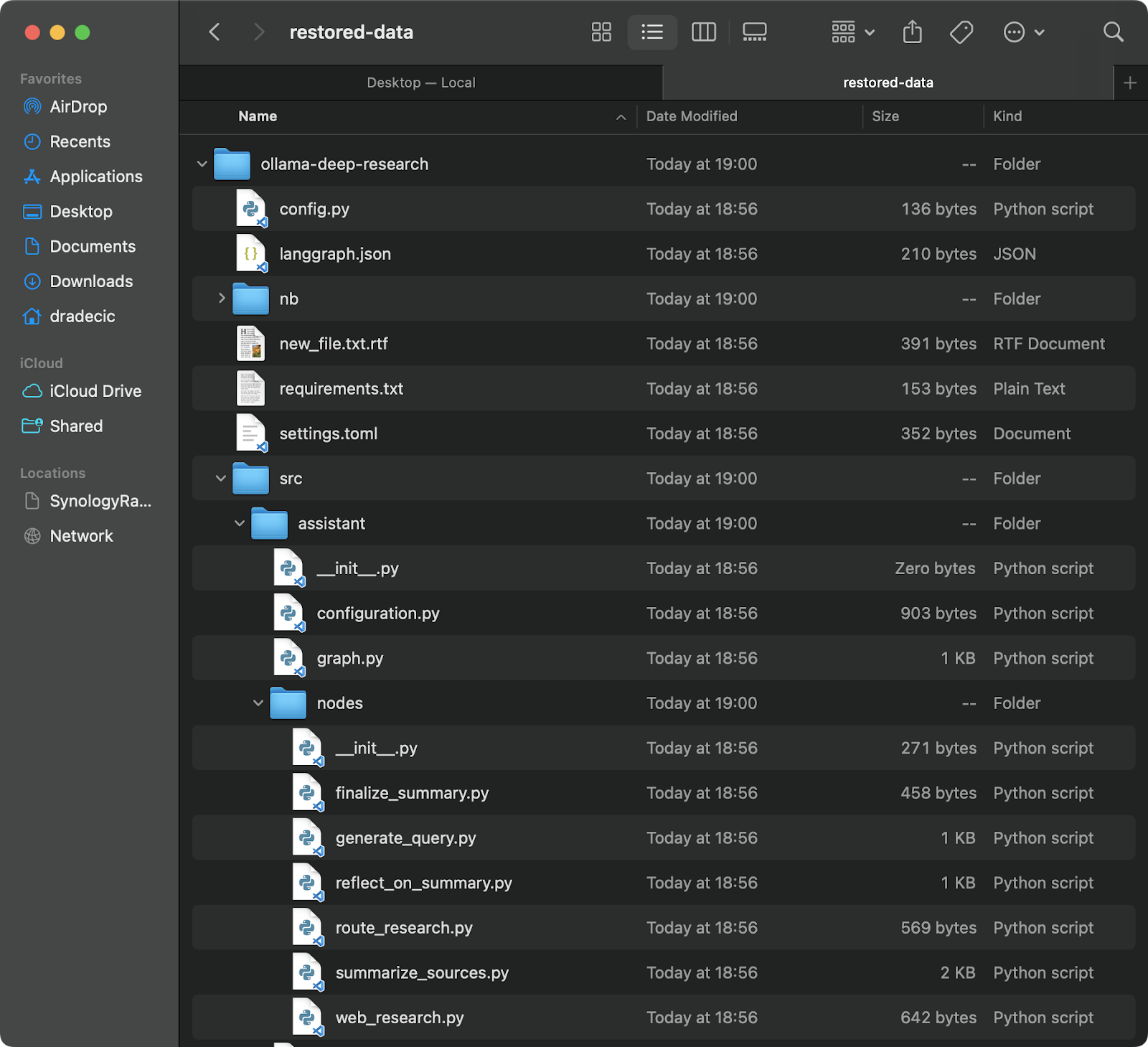
画像20 – S3からファイルを復元する
正確なタイムスタンプを覚えていない場合は、まずすべてのバックアップをリストアップできます:
aws s3 ls s3://testbucket-dradecic/backups/
次のようなものが表示されます:
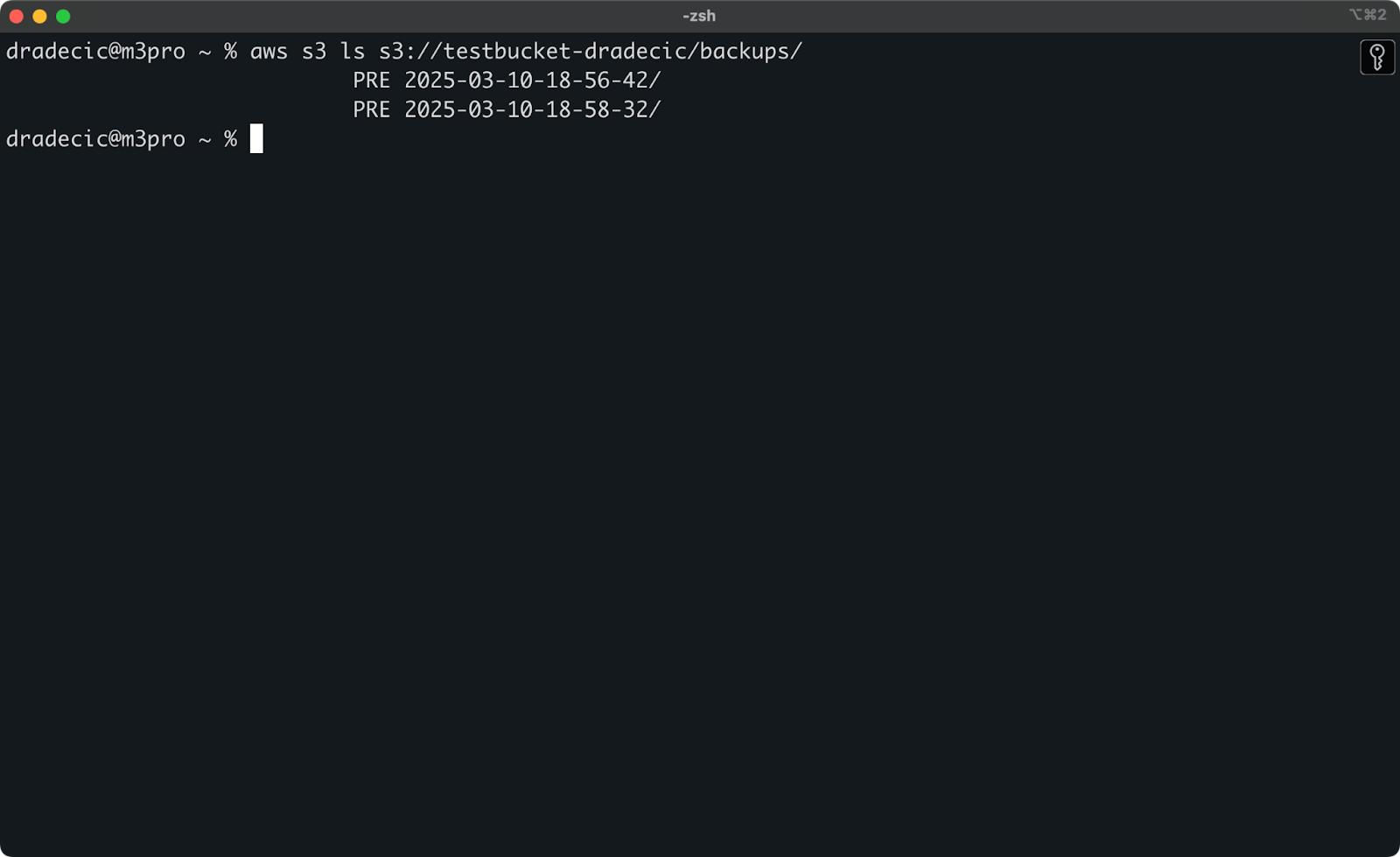
画像21 – バックアップのリスト
以前に議論したexclude/includeフラグを使用して、バックアップから特定のファイルやディレクトリを復元することもできます:
# 設定ファイルのみを復元する aws s3 sync s3://testbucket-dradecic/backups/2025-03-10-18-56-42 /Users/dradecic/Documents/restored-configs --exclude "*" --include "*.config" --include "*.toml" --include "*.yaml"
ミッションクリティカルなシステムでは、スケジュールされたタスク(Linux/macOSのcronジョブやWindowsのタスクスケジューラなど)を使用してバックアップを自動化することをお勧めします。これにより、手動で行う必要がなく、データのバックアップを一貫して行うことができます。
AWS S3 Syncのトラブルシューティング
AWS S3 syncは信頼性のあるツールですが、時折問題が発生することがあります。ただし、ほとんどのエラーは人為的なものです。
一般的な同期エラー
一般的な問題とそれらの解決策について見ていきましょう。
- アクセスが拒否されたエラーは、通常、IAMユーザーがS3バケットにアクセスしたり特定の操作を実行するために必要な権限を持っていないことを意味します。これを修正するには、以下のいずれかを試してみてください。
- IAMユーザーが適切なS3アクセス権限(
s3:ListBucket、s3:GetObject、s3:PutObject)を持っているか確認してください。 - バケットポリシーがユーザーアクセスを明示的に拒否していないことを確認してください。
- パブリック操作が必要な場合、バケット自体がパブリックアクセスをブロックしていないことを確認してください。
- そのようなファイルやディレクトリは存在しませんエラーは、同期コマンドで指定したソースパスが存在しないときに通常表示されます。解決策は簡単です – パスを再確認し、存在することを確認してください。バケット名やローカルディレクトリのタイポに特に注意してください。
- ファイルサイズ制限大きなファイルを同期したい場合にエラーが発生することがあります。デフォルトでは、S3の同期はサイズが5GBまでのファイルを処理できます。それ以上の大きなファイルでは、タイムアウトや転送が不完全なものが表示されます。
- 5GBより大きなファイルの場合、
--only-show-errorsフラグと--size-onlyフラグを組み合わせるべきです。この組み合わせにより、出力を最小限に抑え、ファイルサイズのみを比較することで大きなファイルの転送を助けます。
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/large-files --only-show-errors --size-only
同期パフォーマンスの最適化
S3の同期が予想よりも遅い場合、いくつかの調整を行うことで処理を高速化できます。
- 並列転送を使用する。デフォルトでは、S3同期は限られた数の並列操作を使用します。これを
--max-concurrent-requestsパラメータで増やすことができます:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --max-concurrent-requests 20
- チャンクサイズを調整する。大きなファイルの場合、チャンクサイズを調整することで転送速度を最適化できます。これにより、大きなファイルがデフォルトの8MBではなく16MBのチャンクに分割され、良好なネットワーク接続の場合に速くなる可能性があります:
aws s3 sync /Users/dradecic/large-files s3://testbucket-dradecic/backup --cli-read-timeout 120 --multipart-threshold 64MB --multipart-chunksize 16MB
- スクリプト用に
--no-progressを使用する。自動化スクリプトでS3同期を実行している場合は、--no-progressフラグを使用して出力を削減し、パフォーマンスを向上させます:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --no-progress
- ローカルエンドポイントを使用します。AWSのリソースが同じリージョンにある場合、リージョンエンドポイントを指定するとレイテンシを低減できます:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --endpoint-url https://s3.eu-central-1.amazonaws.com
これらの最適化は、特に大容量データ転送や性能の低いマシンで実行する場合に同期パフォーマンスを大幅に向上させることができます。
これらの解決策を試した後も問題が解決しない場合、AWS CLIには組み込みのデバッグオプションがあります。同期プロセス中に何が起こっているかの詳細情報を表示するには、コマンドに--debugを追加してください:
aws s3 sync /Users/dradecic/Documents/code-files s3://testbucket-dradecic/backup --debug
次のような詳細なログメッセージが多数表示されることがあります:
画像22 – デバッグモードでの同期実行
AWS S3 syncのトラブルシューティングに関する内容は以上です。他にも発生する可能性があるエラーはありますが、99%の場合、解決策はこのセクションにあります。
AWS S3 Syncのまとめ
要約すると、AWS S3 Syncは使用が簡単で非常に強力なツールの1つです。基本的なコマンドから高度なオプション、バックアップ戦略、トラブルシューティングのヒントまで、すべてを学びました。
開発者、システム管理者、またはAWSを使用しているすべての人にとって、S3 Syncコマンドは重要なツールです。時間を節約し、帯域幅の使用を削減し、必要な場所にファイルを必要な時に配置します。
重要なデータのバックアップ、Webアセットの展開、さまざまな環境を同期させるだけでも、AWS S3 Syncを使用するとプロセスが簡単で信頼性があります。
S3同期を使いこなす最良の方法は、実際に使ってみることです。自分のファイルで簡単な同期操作をセットアップしてから、徐々に高度なオプションを探り、特定のニーズに合わせて調整していきます。
重要なデータを扱う際には常に最初に--dryrunを使用するようにしてください。特に--deleteフラグを使用する場合は、重要なファイルを誤って削除することを防ぐため、何が起こるかを確認するための余分な1分を取る方が良いです。
AWSについて詳しく学ぶには、DataCampの以下のコースをチェックしてください:
- Introduction to AWS
- AWS Cloud Technology and Services
- AWS Security and Cost Management
- PythonでのAWS Botoの紹介
DataCampを使用してAWS認定試験の準備をすることもできます – AWS Cloud Practitioner (CLF-C02)。